Новый подход может помочь нам избавиться от вычислений с плавающей запятой
Posit-арифметика: победа над floating point на его собственном поле. Часть 1
Posit-арифметика: победа над floating point на его собственном поле. Часть 2
Испытания Posit по-взрослому
Думаю многие из вас могут с ходу вспомнить хотя бы один случай из истории, когда революционные идеи на момент своего становления наталкивались на неприятие сообществом экспертов. Как правило, виной такому поведению выступает обширный багаж уже накопленных знаний, не позволяющий взглянуть на старую проблему в новом свете. Таким образом, новая идея проигрывает по характеристикам устоявшимся подходам, ведь оценивается она только теми метриками, которые считались важными на предыдущем этапе развития.
Именно с таким неприятием сегодня сталкивается формат Posit: критикующие зачастую просто “не туда смотрят“ и даже банально неправильно используют Posit в своих экспериментах. В данной статье я попытаюсь объяснить почему.
О достоинствах Posit было сказано уже не мало: математическая элегантность, высокая точность на значениях с низкой экспонентой, широкий диапазон значений, только одно бинарное представление NaN и нуля, отсутствие субнормальных значений, борьба с overflow/underflow. Не мало было высказано и критики: никудышная точность для очень больших или очень маленьких значений, сложный формат бинарного представления и, конечно, отсутствие аппаратной поддержки.
Я не хочу повторять уже сказанные аргументы, вместо этого постараюсь сосредоточиться на том аспекте, который как правило упускают из виду.
Правила игры изменились
Стандарт IEEE 754 описывает числа с плавающей запятой, реализованный в Intel 8087 почти 40 лет назад. По меркам нашей индустрии это невероятный срок; с тех пор изменилось все: производительность процессоров, стоимость памяти, объемы данных и масштабы вычислений. Формат Posit был разработан не просто как лучшая версия IEEE 754, а как подход к работе с числами, отвечающий новым требованиям времени.
Высокоуровневая задача осталась прежней – всем нам требуются эффективные вычисления над полем рациональных чисел с минимальной потерей точности. Но условия, в которой решается поставленная задача радикально изменились.
Во-первых, изменились приоритеты для оптимизации. 40 лет назад производительность компьютеров почти полностью зависела от производительности процессора. Сегодня производительность большинства вычислений упираются в память. Чтобы убедиться в этом, достаточно взглянуть на ключевые направления развития процессоров последних десятилетий: трёхуровневое кеширование, спекулятивное выполнение, конвейеризация вычислений, предсказывание ветвлений. Все эти подходы направлены на достижение высокой производительности в условиях быстрых вычислений и медленного доступа к памяти.
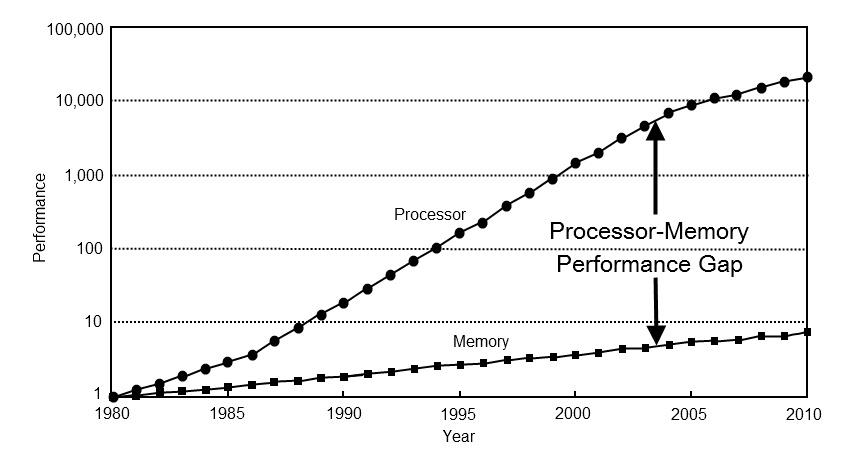
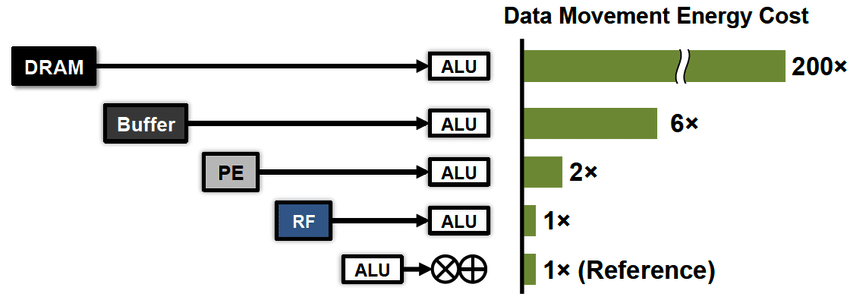
Во-вторых, на первый план вышло новое требование – эффективное энергопотребление. За последние десятилетия технологии горизонтального масштабирования вычислений продвинулись вперед настолько, что нас начала волновать не столько скорость этих вычислений, сколько счет за электричество. Здесь мне следует подчеркнуть важную для понимания деталь. С точки зрения энергоэффективности вычисления стоят дешево, ведь регистры процессора находятся очень близко к его вычислителям. Гораздо дороже прийдется расплачиваться за передачу данных, как между процессором и памятью (x100), так и на дальние расстояния (x1000...).
Вот лишь один из примеров научного проекта, который планирует использовать Posit:

Эта сеть телескопов генерирует 200 петабайт данных в секунду, на обработку которых уходит мощность небольшой электростанции – 10 мегаватт. Очевидно, что для таких проектов сокращение объемов данных и энергопотребления является критическим.
В самое начало
Так что же предлагает стандарт Posit? Чтобы понять это, нужно вернуться в самое начало рассуждений и понять, что подразумевается под точностью чисел с плавающей запятой.
На самом деле существует два разных аспекта имеющих отношение к точности. Первый аспект, это точность вычислений – то, насколько сильно отклоняются результаты вычислений во время выполнения различных операций. Второй аспект, это точность представления – то, насколько сильно искажается исходное значение в момент преобразования из поля рациональных чисел в поле чисел с плавающей запятой конкретного формата.
Теперь будет важный для осознания момент. Posit – это в первую очередь формат представления рациональных чисел, а не способ выполнения операций над ними. Другими словами, Posit – это формат сжатия рациональных чисел с потерями. Вы могли слышать утверждение, что 32-битные Posit – это хорошая альтернатива 64-битным Float. Так вот, речь идет именно о сокращении необходимого объема данных в два раза для хранения и передачи одного и того же набора чисел. В два раза меньше памяти – почти в 2 раза меньше энергопотребления и высокая производительность процессора благодаря меньшим ожиданиям доступа к памяти.
Второй конец палки
Здесь у вас должен был возникнуть закономерный вопрос: какой смысл от эффективного представления рациональных чисел, если он не позволяет производить вычисления с высокой точностью.
На самом деле, способ выполнения точных вычислений есть, и он называется Quire. Это другой формат представления рациональных чисел, неразрывно связанный с Posit. В отличии от Posit, формат Quire предназначен именно для вычислений и для хранения промежуточных значений в регистрах, а не в основной памяти.

Если в вкратце, то Quire представляют из себя не что иное, как широкий целочисленный аккумулятор (fixed point arithmetic). Единице, как бинарному представлению Quire соответствует минимальное положительное значение Posit. Максимальное значение Quire соответствует максимальному значению Posit. Каждое значение Posit имеет однозначное представление в Quire без потери точности, но не каждое значение Quire может быть представлено в Posit без потери точности.
Преимущества Quire очевидны. Они позволяют выполнять операции с несравнимо более высокой точностью чем Float, а для операций сложения и умножения какой-либо потери точности не будет вообще. Цена, которую за это приходится платить – широкие регистры процессора (32-битным Posit с es=2 соответствуют 512-битные Quire), но для современных процессоров это не является серьезной проблемой. И если 40 лет назад вычисления над 512 битными целыми числами казались неприемлемой роскошью, то сегодня это является скорее адекватной альтернативой широкому доступу к памяти.
Собираем пазл
Таким образом, Posit предлагают не просто новый стандарт в виде альтернативы Float/Double, а скорее новый подход по работе с числами. В отличии от Float – который является единым представлением, пытающимся найти компромис между и точностью, и эффективностью хранения, и эффективностью вычислений, Posit предлагает использовать два различных формата представления, один для хранения и передачи чисел – собственно Posit, и другой для вычислений и их промежуточных значений – Quire.
Когда мы решаем практические задачи с применением чисел с плавающей запятой, с точки зрения процессора работу с ними можно представить в виде набора следующих действий:
- Прочитать значения чисел из памяти.
- Выполнить некоторую последовательность операций. Иногда количество операций является достаточно большим. При этом, все промежуточные значения вычислений хранятся в регистрах.
- Записать результат операций в память.
В случае применения Float/Double точность теряется на каждой операции. В случае применения Posit+Quire потеря точности во время вычислений ничтожна. Она теряется только на последнем этапе, в момент преобразования значения Quire в Posit. Именно по-этому большинство проблем “накопления ошибки” для Posit+Quire просто не актуальны.
В отличии от Float/Double, при применения Posit+Quire мы как правило можем позволить себе более компактное представления чисел. Как результат – более быстрый доступ к данным из памяти (лучше производительность) и более эффективное хранение и передача информации.
Соотношение Мюллера
В качестве наглядной демонстрации, я приведу лишь один пример – классическое рекуррентное соотношение Мюллера, придуманное специально для того, чтобы демонстрировать, как накопление ошибки при вычислениях с плавающей запятой радикально искажает результат вычислений.

В случае применения арифметики с произвольной точностью, рекуррентная последовательность должна сводиться к значению 5. В случае арифметики с плавающей запятой вопрос лишь в том, на какой именно итерации результаты вычислений начнут иметь неадекватно большое отклонение.
Я провел эксперимент для IEEE 754 с одинарной и двойной точностью, а также для 32-битных Posit+Quire. Вычисления проводились в арифметике Quire, но каждое значение в таблице преобразовано в Posit.
# float(32) double(64) posit(32) ------------------------------------------------ 0 4.000000 4.000000 4 1 4.250000 4.250000 4.25 2 4.470589 4.470588 4.470588237047195 3 4.644745 4.644737 4.644736856222153 4 4.770706 4.770538 4.770538240671158 5 4.859215 4.855701 4.855700701475143 6 4.983124 4.910847 4.91084748506546 7 6.395432 4.945537 4.94553741812706 8 27.632629 4.966962 4.966962575912476 9 86.993759 4.980042 4.980045706033707 10 99.255508 4.987909 4.98797944188118 11 99.962585 4.991363 4.992770284414291 12 99.998131 4.967455 4.99565589427948 13 99.999908 4.429690 4.997391253709793 14 100.000000 -7.817237 4.998433947563171 15 100.000000 168.939168 4.9990600645542145 16 100.000000 102.039963 4.999435931444168 17 100.000000 100.099948 4.999661535024643 18 100.000000 100.004992 4.999796897172928 19 100.000000 100.000250 4.999878138303757 20 100.000000 100.000012 4.999926865100861 21 100.000000 100.000001 4.999956130981445 22 100.000000 100.000000 4.999973684549332 23 100.000000 100.000000 4.9999842047691345 24 100.000000 100.000000 4.999990522861481 25 100.000000 100.000000 4.999994307756424 26 100.000000 100.000000 4.999996602535248 27 100.000000 100.000000 4.999997943639755 28 100.000000 100.000000 4.999998778104782 29 100.000000 100.000000 4.99999925494194 30 100.000000 100.000000 4.999999552965164 31 100.000000 100.000000 4.9999997317790985 32 100.000000 100.000000 4.999999850988388 33 100.000000 100.000000 4.999999910593033 34 100.000000 100.000000 4.999999940395355 35 100.000000 100.000000 4.999999970197678 36 100.000000 100.000000 4.999999970197678 37 100.000000 100.000000 5 38 100.000000 100.000000 5 39 100.000000 100.000000 5 40 100.000000 100.000000 5 41 100.000000 100.000000 5 42 100.000000 100.000000 5 43 100.000000 100.000000 5 44 100.000000 100.000000 5 45 100.000000 100.000000 5 46 100.000000 100.000000 5 47 100.000000 100.000000 5 48 100.000000 100.000000 5 49 100.000000 100.000000 5 50 100.000000 100.000000 5 51 100.000000 100.000000 5 52 100.000000 100.000000 5.000000059604645 53 100.000000 100.000000 5.000000983476639 54 100.000000 100.000000 5.000019758939743 55 100.000000 100.000000 5.000394910573959 56 100.000000 100.000000 5.007897764444351 57 100.000000 100.000000 5.157705932855606 58 100.000000 100.000000 8.057676136493683 59 100.000000 100.000000 42.94736957550049 60 100.000000 100.000000 93.35784339904785 61 100.000000 100.000000 99.64426326751709 62 100.000000 100.000000 99.98215007781982 63 100.000000 100.000000 99.99910736083984 64 100.000000 100.000000 99.99995517730713 65 100.000000 100.000000 99.99999809265137 66 100.000000 100.000000 100 67 100.000000 100.000000 100 68 100.000000 100.000000 100 69 100.000000 100.000000 100 70 100.000000 100.000000 100
Как видно из таблицы, 32-битные Float сдаются уже на седьмом значении, а 64-битные Float продержались до 14 итерации. В тоже время, вычисления для Posit с применением Quire возвращают стабильный результат вплоть до 58 итерации!
Мораль
Для многих практических случаев и при правильном применении формат Posit действительно позволит с одной стороны экономить на памяти, сжимая числа лучше, чем это делает Float, с другой стороны обеспечивать лучшую точность вычислений благодаря применению Quire.
Но это только теория! Когда дело касается точности или производительности, всегда делайте тесты прежде чем слепо довериться тому или иному подходу. Ведь на практике конкретно ваш случай будет оказываться исключительным гораздо чаще, чем в теории.
Ну и не забывайте первый закон Кларка (вольная интерпретация): Когда уважаемый и опытный эксперт утверждает, что новая идея будет работать, то он почти наверняка прав. Когда он утверждает, что новая идея работать не будет — то он, весьма вероятно, ошибается. Я не считаю себя опытным экспертом, чтобы позволить вам полагаться на мое мнение, но прошу вас с настороженностью относиться к критике даже опытных и уважаемых людей. Ведь дьявол кроется в деталях, и даже опытные люди могут их упустить.
Комментарии (72)

AntonSor
18.09.2019 18:58+1А в следующей статье будет про недостатки 512-битных Quire и двухкратное преимущество 1024-битных Quire+ :)

defuz Автор
18.09.2019 19:00Вы почти угадали. Не знаю на счет 1024-битных Quire, но 2048-битные Quire существуют как эквивалент 64-битных Posit. Наверное, кому-то может быть нужна даже такая точность.

KvanTTT
18.09.2019 19:05Хм, а есть формат BigQuire с произвольной точностью? Как BigInteger, только для чисел с плавающей точкой. Применение найдется: теоретическая математика, расчет фундаментальных констант типа PI и подобных.
defuz Автор
18.09.2019 19:15Формат Posit не накладывает ограничения на размер чисел – можно начинать использовать хоть 2-битные posit (NaN, 0, 1, -1) и расти с масштабе до бесконечности.
И хотя большинство реализаций предполагают фиксированный размер используемого типа, преимуществом Posit как формата является то, что бинарное представление значения более низкой точности всегда является префиксом бинарного представления более точного значения. Так что да, Posit может расти как вектор в куче, произвольно долго накапливая точность одного и того же значения от итерации к итерации.
Ivanii
18.09.2019 19:01А аппаратно это формат где-то поддерживается?
defuz Автор
18.09.2019 19:10В массовом производстве пока нигде, и, честно говоря, пока этого не произойдет – нам как разработчикам нет особого смысла их использовать.
Насколько мне известно, пока существуют только наработки в комбинировании RISC-V и Posit. Основное применение – HPC.aamonster
18.09.2019 19:27Можно посмотреть, есть ли реализации на verilog/vhdl и результаты синтеза/симуляции по ним (благо, сейчас средства разработки позволяют оценить доступную тактовую частоту).
defuz Автор
18.09.2019 19:51Убедительной реализации Quire на Verilog/VHDL я не видел, но могу сказать что аналогичный подход (Kulisch exact accumulators) ранее уже был реализован и синтезирован для float, давая в 3-6 раз более высокую производительность с гораздо лучшей точностью.
kasyachitche
18.09.2019 19:12+1Ждем поста в котором будет описано проектирование процессора для Quire на плис и сравнение в железе c процессором для Float.

DrSmile
18.09.2019 20:05В одной из прошлых статей была ссылка. Там пробовали это делать:
In our current implementation targeting FPGAs, summing two products of Posit32 in the hardware quire has more than 10x the area and 8x the latency of summing them using a posit adder and a posit multiplier
Если еще учесть, что поситы сами по себе медленнее флоатов, то можно заключить, что идея использовать quire никуда не годится. И это не удивительно, ибо в современных ядрах половину площади занимают регистровые файлы, а самый дефицитный ресурс — это порты доступа к этому файлу. Сразу становится понятно, что увеличение разрядности в 16 раз на ровном месте ни к чему хорошему привести не может.defuz Автор
18.09.2019 20:20Если еще учесть, что поситы сами по себе медленнее флоатов...
Подождите секунду, какие именно Posit медленнее каких именно Float? Если мы заменяем 64-битные Float на 32-битные Posit, то сравнивать по производительности нужно именно их, и там уже все далеко не так однозначно.
Для реализации арифметики на Quire используются аккумуляторы Kulisch, которые в целом позволяют работать на той же тактовой частоте, что и обычные вычисления. Вы правы, ценой значительного увеличения площади вычислителей. Но для современных процессоров увеличение площади арифметики на фоне всего остального все равно потеряется в долях процентов.
picul
18.09.2019 19:59+4На счет того, что Posit — это формат храниния данных — ОК, уяснили.
Но Quire — серьезно? Правильно ли я понимаю, предлагается завезти в процессоры 512-битные регистры (сейчас в пользовательском сегменте они есть только в ксеонах) и вместо векторных операций выполнять на них скалярные, с очевидно огромными latency потому-что 512 бит. Понимаю, для некоторых специальных ситуаций это имеет смысл, но в повседневных задачах точность float'ов лично меня не настолько беспокоит.defuz Автор
18.09.2019 20:27C latency не все так однозначно. Ключевая операция – a*b+c очень хорошо пайплайнится с помощью аккумулятора Kulisch, позволяя работать на той же тактовой частоте, что и обычные вычисления над float/posit.
Конечно, если сравнивать задержку одиного цикла a*b для Float и Quire, то ситуация будет не в пользу последних, не только из-за 512-битного регистра, но и из-за задержки на преобразование из/в Posit. Но для тех случаев, когда вычисления производятся по цепочке производительность скорее всего будет даже выше.
Таких ситуаций на самом деле множество. Самый типичный пример – сумма большего количества произведений. Используется буквально везде где необходимо умножение матриц – физика, machine learning и т.д.picul
18.09.2019 20:41+1из-за задержки на преобразование из/в Posit
Стоп, вроде же решили, что posit — это для компактного хранения? Так зачем все время конвертировать туда-сюда, лучше только при сохранении значения в память. Хотя, на фоне 512-битных операций конвертация, скорее всего, будет незаметна.
будет даже выше
Это как это даже выше? Не вижу никаких предпосылок к тому, что бы 512-битные вычисления были быстрее 32-битных.defuz Автор
18.09.2019 20:52Так зачем все время конвертировать туда-сюда, лучше только при сохранении значения в память.
Все время не нужно, но если делать бенчмарк с учетом чтения и записи в память и только с одной операцией, то конвертация будет отнимать значимое время.
Не вижу никаких предпосылок к тому, что бы 512-битные вычисления были быстрее 32-битных.
А они есть. Обработка сабнормальных чисел и сдвиги при выравнивании экспонент обходятся не бесплатно, да еще и не паралелятся с остальными вычислениями. Вот вам пример из аналогичного подхода, реализованного для float (там даже 640 битные регистры):
The accelerator successfully saturates the SoC’s memory system, achieving the same per-element efficiency (1 cycle-per-element) as Intel MKL running on an x86 machine with a similar cache configuration.
Такие регистры как правило делятся на слова, которые вычисляются отдельно, и благодаря этому хорошо пайплайнятся.
FGV
18.09.2019 20:12+1Новизна подхода в том, что используется два различных формата представления, один для хранения и передачи чисел – Posit, и другой для вычислений и их промежуточных значений – Quire.
Так вроде еще 8087 имел внутренние регистры по 80 бит. Так понимаю вся новизна в том что вместо 80бит расширяется аж до 512, ну да, свежо, современно :))
hhba
18.09.2019 20:27Дадада, то же самое хотел написать. ФПУ-стек 8087 состоит из восьми 80-битных регистров, которые потом ужимаются до 32/64. Так что по сути речь про ещё большее расширение (причем сразу так радикально, без потери точности) и другой формат упаковки. И вот в первом пункте есть проблема....

red_andr
19.09.2019 00:04Вспомнил как программировал для 8087, само собой на ассемблере, ибо ни один компилятор тогда не мог нормально использовать все возможности сопроцессора. Собственно говоря, я не уверен, что даже сейчас можно было бы создать такой компилятор, который эффективно использовал стековую архитектуру 8087. А иначе действительно смысла нет в регистрах большей точности, если при каждой операции операнды из регистров преобразуются обратно в память в меньшую точность. Поэтому лично для меня Quire звучит как чистая теория малоприменимая на практике.
defuz Автор
19.09.2019 00:11А иначе действительно смысла нет в регистрах большей точности, если при каждой операции операнды из регистров преобразуются обратно в память в меньшую точность.
Смысла действительно мало, но при чем здесь стековая архитектура? Современные компиляторы достаточно умны, чтобы понимать что переменная совсем не обязательно должна занимать область в памяти и может жить только в регистрах.red_andr
19.09.2019 23:51+1Тут дело даже не в «умности» компилятора, а в том, что регистров мало. Поэтому какие то переменные придётся переносить в память с потерей точности.
hhba
19.09.2019 10:41А иначе действительно смысла нет в регистрах большей точности, если при каждой операции операнды из регистров преобразуются обратно в память в меньшую точность
Э, ну нет. Многие классические задачки отлично целиком помещаются на FPU-стеке, в пределах классических восьми регистров расширенной точности, и когда наружу в переупакованном виде выходит только результат — это хорошо (хотя само по себе такое программирование может быть изунряющим). Так что сама по себе идея правильная, и если регистров сделать больше, а компилятор научить их использовать, то вообще-то можно отлично жить.0serg
19.09.2019 11:50+1Компилятор не в состоянии знать что от него ожидает разработчик — надо ли делать округление и где именно. Разные варианты могут давать разные результаты и не всегда попытка округлять как можно меньше даст правильный ответ.
hhba
19.09.2019 11:50Не понял, что вы хотели сказать и как это относится к написанному выше.
0serg
19.09.2019 12:44Компилятор нельзя «научить использовать quire / FPU-стек». Точнее сказать, ему можно разрешить это делать, но разработчик должен явно дать ему добро на это и понимать что результат может быть непредсказуем. В силу этого обычно на это идут не для повышения точности а наоборот — там где точность не очень важна. А для «повышения точности» — указывают порядок округлений вручную. Например оперируя long double в аккумуляторах и промежуточных значениях вычислений.
hhba
19.09.2019 13:08Все равно ничего не понял.
Мы выше обсуждали как раз тот факт, что если писать на ассемблере (или если есть умный компилятор), то некоторые вычисления могут делаться без выгрузки промежуточных результатов в память, при этом точность каждого числа в стеке FPU x87 — тот самый long double. И это многолетняя практика, следовательно идея длинных регистров Quire — по сути лишь совершенствование этой практики, кажется вполне эффективное (с чем не все выше согласны). С чем из написанного вы не согласны?0serg
19.09.2019 14:08Если Вы пишете long double то компилятор использует стек x87. Если Вы пишете double, то компилятор обязан каждый раз округлять число до double. Аналогичным образом он обязан гарантировать строго тот порядок вычислений (и соответственно округлений после каждой операции) который Вы указали. Если компилятору разрешить делать операции (и следовательно округления) в другой последовательности или не делать округления вообще, то результат вычислений непредсказуемо меняется, иногда с очень забавными последствиями. Поэтому x87 регистры, собственно, обычно компилятором и не используются а в настройках x87 есть опция автоматического округления результатов FPU-регистров к double. С quire будет та же история — если long double не используют то quire тоже не будут.
hhba
19.09.2019 14:44Вот чертовщина какая-то, ей Богу: все, что вы пишете, я понимаю по сути (банальные вещи потому что), но какую в точности генеральную идею вы хотите высказать — не могу понять. :(
Единственная фраза, за которую я могу ухватиться — "если long double не используют то quire тоже не будут". Вы таким образом хотите сказать, что идея вычислений на увеличенных регистрах на самом деле не имеет соответствующей success story и стало быть Quire тоже не взлетит? Я правильно вас понял? Если да, то я должен заметить: вы свое утверждение базируете на постулате о том, что во-первых никто не юзает long double, и во-вторых компилятор С/С++ ничего не может сделать с предложенным ему кодом в части перестановки операций (и не может даже в том числе убрать «лишние» пересылки в память с соответствующим округлением). И если с первым я просто не согласен (ну, да, кому не надо — те не используют, много кто и double не использует), то второе — вопрос оптимизации. Повторюсь, немало вещей с использованием FPU-стека прямо на ассемблере херачилось, ну, потому что так надо, и получаемые результаты (в том числе эффекты округления) принимал на себя программист. Если мы постулируем, что создать достаточно умный компилятор невозможно (ну или мы не хотим этого во имя сохранения целостности некоторых базовых вещей), а кроме того любой программист с удовольствием пренебрежет такой возможностью в пользу более простого и переносимого кода, то тогда конечно и Posit/Quire не взлетит. Но это аргумент, знаете ли, из серии «и это тоже делать не надо, не взлетит, слишком революционно», так можно отказ от любых новшеств обосновать.0serg
19.09.2019 14:521. Вам не надо использовать ассемблер чтобы работать со стеком x87. Пишите long double и компилятор все отлично сам соберет
2. Тем не менее количество использующих long double мало.
3. Компилятор не имеет права выполнять описанную оптимизацию без явного одобрения программиста, т.к. это приводит к непредсказуемому результату. В лучшем случае у Вас программа собранная разными версии компилятора будет давать немного разный результат, в худшем — код который совершенно явно для программиста должен был давать число >= 0 сгенерирует отрицательное.hhba
19.09.2019 15:06Вам не надо использовать ассемблер чтобы работать со стеком x87. Пишите long double и компилятор все отлично сам соберет
Речь не шла о том, что работать со стеком х87 можно только на ассемблере, но для эффективного его использования — людям приходилось. Как-то вот не всегда компилятор мог удачно расположить переменные в регистрах. Поэтому среди прочего поднимается вопрос о том, что в Quire должно быть побольше регистров.
Компилятор не имеет права выполнять описанную оптимизацию без явного одобрения программиста, т.к. это приводит к непредсказуемому результату
Вот это и есть предмет обсуждения, начатого этим постом. Типа (в определенных случаях) описанных неожиданностей с новым форматом должно стать меньше.0serg
19.09.2019 15:29На ассемблере можно было только ускорить код, не более того. Результат должен был бы быть тем же а мы говорим именно о результате
Неожиданностей может быть меньше только если можно гарантировать какой-то новый детерминированных их порядок — к примеру, полное отсутствие округлений. Но для подавляющего большинства задач ожидать что результаты будут все время храниться в quire-регистрах нереально. Время от времени их понадобится выгружать в память и тут сразу возникнет вопрос — как гарантировать что выгрузки (и возникающие округления) будут детерминированными. У long double это хотя бы решается тем что ldouble таки туда выгружабелен, но если у quire такой возможности не будет, то компилятор просто не сможет не делать округления столкнувшись с нехваткой регистров.hhba
19.09.2019 15:36На ассемблере можно было только ускорить код, не более того
Ну, не только. В зависимости от того, как в целях оптимизации разложены переменные по регистрам и как сделан алгоритм, пересылок в память (с округлением, если оно нужно) могло быть больше или меньше. Результат при этом конечно будет отличаться (если его эквивалентность — на самоцель, например).
Неожиданностей может быть меньше только если можно гарантировать какой-то новый детерминированных их порядок — к примеру, полное отсутствие округлений
И именно на это уповает автор поста.
Но для подавляющего большинства задач ожидать что результаты будут все время храниться в quire-регистрах нереально. Время от времени их понадобится выгружать в память и тут сразу возникнет вопрос — как гарантировать что выгрузки (и возникающие округления) будут детерминированными.
Ну выше как раз и говорится о том, что надо больше регистров богу регистров. И конечно вы правы, что когда-то их не хватит (да и за имеющиеся придется неслабо так заплатить), и тогда мы вернемся на круги своя.
У long double это хотя бы решается тем что ldouble таки туда выгружабелен, но если у quire такой возможности не будет, то компилятор просто не сможет не делать округления столкнувшись с нехваткой регистров.
И в конечном итоге потребуется некая оптимизация (коей по сути и является 64-битный Posit), чтобы все-таки и выгружать, и точность при округлении терять поменьше. То есть… ну, да, очередной long double получится, только более точный. Об этом и говорят те комментаторы, которые пишут про «те же яйца, только в профиль».0serg
19.09.2019 16:38пересылок в память (с округлением, если оно нужно) могло быть больше или меньше
Пересылка в память ничего же не меняет в результате вычислений. Вот округление — меняет, но компилятор его сам вставлять не будет, поэтому если разработчик его явно не вставит то результат у компилятора будет тот же.hhba
19.09.2019 17:09Пересылка в память ничего же не меняет в результате вычислений
Конечно. Но в обычной жизни оно сопровождается округлением (с 80 бит регистра до 64/32 бит в памяти). Я об этом говорил.
если разработчик его явно не вставит то результат у компилятора будет тот же
Я же говорил о сравнении сгенерированного компилятором и написанного урками ассемблерного кода.0serg
19.09.2019 17:20Конечно. Но в обычной жизни оно сопровождается округлением (с 80 бит регистра до 64/32 бит в памяти). Я об этом говорил.
Не-а. В память можно 80-бит писать и компилятор именно FSTP в код вставит если там long double. Соответственно если программист явно не вставил округление (стал писать в 64 или тем более 32 бита) то у него результат будет тем же что у компилятораhhba
19.09.2019 17:29В память можно 80-бит писать и компилятор именно FSTP в код вставит если там long double
Да, да, да — если там long double. Выше уже сто раз про это написали друг другу )))
у него результат будет тем же что у компилятора
Нет, не будет, банально потому, что он порядок вычислений на ассемблере по-другому сделает. Иначе зачем бы он вообще полез в ассемблер?0serg
19.09.2019 17:38Нет, не будет, банально потому, что он порядок вычислений на ассемблере по-другому сделает
Порядок вычислений компилятор тоже не меняет
Иначе зачем бы он вообще полез в ассемблер?
Очевидно для того чтобы сделать код быстрее. Не точнее а быстрее. Точность же будет одной и той же. Возвращаемся к
На ассемблере можно было только ускорить код, не более того. Результат должен был бы быть тем же а мы говорим именно о результате.
Это я все в контексте «создания умного компилятора» пишу. Компилятор уже умный, там ничего нового появиться не может. А значит если long double используется редко то и quire едва ли будет большую полезность.hhba
19.09.2019 17:43Порядок вычислений компилятор тоже не меняет
В моем сообщении «он» — программист. На ассемблере.
Очевидно для того чтобы сделать код быстрее. Не точнее а быстрее. Точность же будет одной и той же.
Не обязательно. Вот вы написали некий код, переменные таки объявили как long double, они легли в регистры, но порядок вычислений был один, стало быть и результат один. А потом вы написали аналогичный по сути алгоритм напрямую, и ради каких-то соображений об эффективности сделали другой порядок вычислений. Результат будем другим, хотя это все те же лонгдаблы (не углубляясь в то, когда это различие в результатах вообще станет значимым).

progmachine
18.09.2019 20:29+4Если вдруг внезапно подвезли Quire, и делают сравнительные вычисления именно в нём, а не в Posit, т.е. по сути вычисления ведутся на самом деле с 512 бит точностью, то сравнивать это с вычислениями на прямую в float/double — не корректно. Эдак можно создать железку, которая будет так-же хранить числа в IEEE 754, а внутри иметь очень широкие регистры, к примеру те же 512 бит, и вычисления производить только в них.
Если сравнивать форматы корректно, то и нужно сравнивать честно — т.е. сопоставлять вычисления в float/double соответствующим Posit (именно posit, а не quire — с выгрузкой и последующей загрузкой значений в регистры при каждой математической операции).
Просто у IEEE 754 сейчас по сути нет аналога Quire. Хотя раньше что-то подобное было — до появления SSE, вычисления велись с 80-и битной точностью в регистрах математического сопроцессора, даже если в памяти числа представлялись 32/64-х битными.defuz Автор
18.09.2019 20:33Если вдруг внезапно подвезли Quire, и делают сравнительные вычисления именно в нём, а не в Posit, т.е. по сути вычисления ведутся на самом деле с 512 бит точностью, то сравнивать это с вычислениями на прямую в float/double — не корректно.
Отчасти согласен, но тут важно понимать, что Quire – часть стандарта Posit, а для Float любая поделка в этом направлении будет собственным велосипедом.
Эдак можно создать железку, которая будет так-же хранить числа в IEEE 754, а внутри иметь очень широкие регистры, к примеру те же 512 бит, и вычисления производить только в них.
Можно, только регистры прийдется делать не 512-битными, а уже 640-битными. Проблема в том, что формат представления Float не очень хорошо подходит для реализации «Quire для Float».progmachine
18.09.2019 20:40+1Отчасти согласен, но тут важно понимать, что Quire – часть стандарта Posit, а для Float любая поделка в этом направлении будет собственным велосипедом.
Ну раньше примерно так и было — все вычисления внутри процессора велись в 80-и разрядных регистрах с плавающей запятой(а не fixed point). Но когда пришло время SSE2, то решили, что скорость вычислений гораздо важнее точности, для процессоров массового потребительского сегмента. Для 3D игрушек, рендеринга и прочего — достаточно.defuz Автор
18.09.2019 20:55Для игрушек и рендеринга я бы рассмотрел Posit16 – диапазон значений 2^-28...2^28, размер Quire – всего 128 бит, точность будет скорее всего выше чем у Float32, а гонять по периферии нужно в два раза меньше данных.
progmachine
18.09.2019 21:15+21) Если будем молотить 128-и битными регистрами — то встанет вопрос о скорости, энергопотреблении и размерах кристалла с его ценой. К примеру, соверемнные процессоры имеют в регистрах место для 16*8=128 float чисел, всего 4096 бит регистровой памяти, а с Quire будет 16 384 бит. А стоит ли оно того? Это ещё вопрос дискуссионный.
2) Если вспомнить рекламное описание Posit, о том что Posit вдвое меньшего размера сопоставим с float/double — то там говорилось, что «сопоставим в определённых use cases», т.е. далеко не всегда. Если говорить о 3D играх, то там с float на расстояниях ~16км от центра координат, уже начинают наблюдаться серьёзные погрешности, вполне отличимые на глаз. Posit как мы знаем, более точен чем float (при одинаковом размере, скажем 32 бита) как раз возле центра координат, а не на периферии. Как с этим будут обстоять дела у Posit?
3) Из-за того, что указано в п.2, по сути не получится использовать Posit16 там где используется Float32, кроме узко специализированных случаев (к примеру нейросетей).
Из-за всего вышеперечисленного делаю вывод, что этот Posit — в чём-то лучше, в чём-то хуже чем IEEE 754, но преимущества не так уж значительны. А всё остальное лишь волна хайпа.defuz Автор
18.09.2019 21:35Сразу говорю, что я не эксперт в графике, но позволю себе порассуждать:
Если будем молотить 128-и битными регистрами — то встанет вопрос о скорости, энергопотреблении и размерах кристалла с его ценой.
Скорость должна быть высокой, при правильной реализации, потому что fixed-point арифметика хорошо пайплайнится – нам не нужны все 128 бит результата для того чтобы начать вычислять следующую операцию. Если разбить вычисления на 4 шага по 32 бита, то появится небольшая общая задержка, но общая производительность будет выше (как 32-битные integer против 32-битных float).
Основной пожиратель энергии, как правило – это память и передача данных. Насколько я понимаю, для видеокарт это даже более актуально, чем для процессоров. Так что повышенное потребление на вычислениях должно с лихвой компенсироваться в 2 раза меньшими объемами данных. То же самое и с площадью – получается что нам нужно в 2 раза меньше видеопамяти для тех же вычислений (ценой увеличения площади вычислителей). Тут нужно смотреть какое соотношение площади в видеокартах.
Если говорить о 3D играх, то там с float на расстояниях ~16км от центра координат, уже начинают наблюдаться серьёзные погрешности, вполне отличимые на глаз. Posit как мы знаем, более точен чем float (при одинаковом размере, скажем 32 бита) как раз возле центра координат, а не на периферии. Как с этим будут обстоять дела у Posit?
Не совсем понимаю, чем именно вызываются погрешности, чтобы точно ответить на ваш вопрос. Если погрешностями вычислений – то quire должны радикально решить этот вопрос. Если погрешностями представления значений, то стандарт предполагает, что Quire можно представить в виде суммы одного, двух или трех Posit. При этом с каждым шагом точность возрастает радикально. Я думаю что для специфических случаев это можно использовать.
Из-за того, что указано в п.2, по сути не получится использовать Posit16 там где используется Float32, кроме узко специализированных случаев (к примеру нейросетей)
Для нейросетей хватает даже 8-битных posit (с quire), в большинстве случаев.progmachine
18.09.2019 21:50+1Вы совершенно упустили из виду п.2 — Posit16 эквивалентен Float32 далеко не всегда. Так что в общем случае всё равно придётся использовать Posit32 там где используется Float32. Т.к. posit16 может выдать в любом случае не более 16 бит информации, в то время как в float32 только мантисса уже 24 бита.
И да, речь идёт именно о представлении в памяти, а не о вычислениях внутри процессора, т.к. когда речь идёт о многих тысячах или миллионах точек в виртуальном пространстве — у процессора просто не может быть такого количества регистров.
Таким образом утверждения об экономии на передаче данных — не более чем маркетинг, и актуально только для узкого круга специфических вычислений. Но мы же как всегда, видим жёлтый заголовок новости, о том что Posit16 эквивалентен Float32, видим только это и верим, забывая что это утверждение истинно только для узкого круга задач, а не везде.
Основной пожиратель энергии, как правило – это память и передача данных.
Самый большой куллер в системнике, стоит на процессоре, а на памяти вообще нет вентилятора… Это как бы должно вызывать вопросы…defuz Автор
18.09.2019 22:07Т.к. posit16 может выдать в любом случае не более 16 бит информации, в то время как в float32 только мантисса уже 24 бита.
Представление одного значения в виде суммы двух posit16 дадут вам те же самые 32 бита информации, а мантиссу вплоть до 28 бит, поскольку quire представляется в виде суммы нескольких posit не абы как, именно так чтобы дать максимальную точность.
При этом в тех случаях где такая точность не нужна, можно вполне обойтись одним значением. Обратите внимание, что такой подход требует минимальной дополнительной логики в железе, в отличии от одновременной поддержки float16/float32/float64.
И да, речь идёт именно о представлении в памяти, а не о вычислениях внутри процессора, т.к. когда речь идёт о многих тысячах или миллионах точек в виртуальном пространстве — у процессора просто не может быть такого количества регистров.
Я предполагаю, что эти точки обрабатываются последовательно, и потому не так уж важно тысячи их или миллионы – все равно вам достаточно будет разумно конечного количества регистров. В конечном итоге нас интересует проекция всех этих точек на экран, и тут размерности и точности одного posit16 должно хватить вполне.
Но мы же как всегда, видим жёлтый заголовок новости, о том что Posit16 эквивалентен Float32, видим только это и верим, забывая что это утверждение истинно только для узкого круга задач, а не везде.
Аналогичными словами я закончил и свою статью. Я даже не сомневаюсь что есть задачи, где float будет вести себя лучше именно из-за своих характеристик.
Самый большой куллер в системнике, стоит на процессоре, а на памяти вообще нет вентилятора… Это как бы должно вызывать вопросы…
Тут вы делаете неверные выводы. Куллер стоит на процессоре потому что там самая высокая плотность транзисторов с частыми переключениями. Так что плотность энергопотребления – выше, а само энергопотребление – не факт. И нужно учитывать потребление не только самой памяти (хранение информации), но и ее передачи, за которую отвечает в том числе процессор (и вся его иерархия кешей).progmachine
18.09.2019 22:50Представление одного значения в виде суммы двух posit16 дадут вам те же самые 32 бита информации, а мантиссу вплоть до 28 бит, поскольку quire представляется в виде суммы нескольких posit не абы как, именно так чтобы дать максимальную точность.
Т.е. так и есть — в общем случае там где был Float32, будет Posit32. И ни какого выигрыша по передаче данных.
Там где Posit16 сопоставим с Float32 — там да, выигрыш есть, но это специфические случаи. Для тех-же радиоастрономов, передающих гигабиты измерений в секунду по своим кластерам, оно актуально. Или для нейросетей. Но это не о процессорах общего назначения и массового сегмента, это специфические задачи, и для специфических задач, специальная аппаратура и специальные форматы данных действительно дают лучший результат. Для этих целей Posit хорош.
При этом в тех случаях где такая точность не нужна, можно вполне обойтись одним значением. Обратите внимание, что такой подход требует минимальной дополнительной логики в железе, в отличии от одновременной поддержки float16/float32/float64.
Нативная поддержка форматов float16/float32/float64 в кремнии делается для максимизации производительности вычислений. Если речь должна идти о максимизации точности вычислений, то внутри себя процессор может оперировать одним вычислительным конвеером шириной 64 бита, или даже больше, не зависимо от входного формата данных, собственно как и было раньше, пока Intel не выпилила математический сопроцессор, оставив только SSE/AVX.
Я предполагаю, что эти точки обрабатываются последовательно, и потому не так уж важно тысячи их или миллионы – все равно вам достаточно будет разумно конечного количества регистров. В конечном итоге нас интересует проекция всех этих точек на экран, и тут размерности и точности одного posit16 должно хватить вполне.
Именно важно точное и равномерное их местоположение в виртуальном обширном пространстве, и тут posit16 уже окажется недостаточен. И ряд трансформаций с перемножениями матриц 4x4 (координата точки, координата и направление камеры и комбинация их погрешностей, Quire здесь не спасёт, т.к. погрешности уже в представлении чисел), тоже должен обладать высокой точностью, перед тем как точки окажутся в screen space координатах, где да, posit16 уже достаточно, но там это уже по сути не имеет значения.
Тут вы делаете неверные выводы. Куллер стоит на процессоре потому что там самая высокая плотность транзисторов с частыми переключениями. Так что плотность энергопотребления – выше, а само энергопотребление – не факт.
Самая главная печка — блок вычислений SIMD, а не память, как только он включается на полную — начинается ад и пекло :)
И да, очень много энергии тратится внутри процессора на передачу данных — но внутри процессора, на конвейерах вычислений и не будет уже posit-а с его плюшками. Там будет суровый мегатранзисторный ад.
А самый главный профит от posit-а декларируется именно на передаче данных между вычислительными узлами по сети в кластерных вычислениях, и только в тех узких задачах где это применимо.
А в общем случае, Posit не является уж сильно лучше, чем IEEE754. Здесь больше фанатизма чем здравого анализа, и честного не эмоционального подхода.defuz Автор
18.09.2019 23:08Самая главная печка — блок вычислений SIMD, а не память, как только он включается на полную — начинается ад и пекло :)
Подозреваю, что это связано с тем, что выполнение SIMD требует чтения 512 бит из памяти на операцию, а значит и более агрессивного обновления кешей.progmachine
19.09.2019 07:22На одно переключение транзистора в кэше ЦП, при вычислениях будут десятки, если не сотни переключений транзисторов в конвейере вычислений. Так что хоть и кэш является очень громоздкой и тяжёлой по энергопотреблению конструкцией в ЦП, но далеко не он является главным по энергопотреблению вообще.
У вас прочно засел в сознании маркетинговый хайп, что Posit16 == Float32. Хотя это вообще то не так, за исключением редких и специфических случаев. В общем случае можно рассматривать, что Posit32 == Float32, при том, где-то лучше, где то хуже.
На мой взгляд единственными недостатками IEEE754 по сравнению с Posit как формата данных, является то, что -0 != +0, и достаточно широкое пространство NaN. Всё остальное хайп и фанатизм. И стоит ли оно того, что бы переворачивать всю индустрию с ног на голову — вопрос очень спорный. Но это не значит, что Posit для нас вообще не нужен — он будет с успехом использоваться, там где действительно того стоит, в специфических научных вычислениях, в нейропроцессорах и т.п., т.е. займёт свою специализированную нишу.
ShadowTheAge
19.09.2019 02:29GPU оптимизирована для вычислений с 4-мерными векторами из 32-битных float
Основное место на кристалле занимают регистры (4-мерные) и АЛУ (для 4-мерных операндов)
Если заменить АЛУ и регистры из 4х32 бит на 4х512 бит то энергоэффективности это не повысит никак
На мобилках вообще рекомендуют использовать для вычислений на gpu half (float16) потому что они энергоэффективны и на мобилках это важно (время работы от батареи, throttling). И речь тут именно про вычисления, не текстуры и т.п. память (текстуры в подавляющем большинстве случаев вообще 8 бит на канал fixed-point)picul
19.09.2019 12:054-мерными? Вообще-то на современных GPU процессоры оперируют 32-мерными регистрами. Или Вы о каких-то мобильных чипах говорите?
picul
18.09.2019 21:15+1Для графики posit может и зайдет, а вот quire совершенно бесполезен. На GPU и 64-bit float используют только в научных вычислениях на high-end видеокартах.
defuz Автор
18.09.2019 21:40Так ведь никто не мешает взять Posit меньшей битности, чтобы точность была примерно такой же, а объем данных меньше (см. мой ответ автору выше). Вполне себе могу представить ситуацию, что видеокарты на posit показывают лучше производительность. Другой дело, чтобы это дошло до массового использования нужно всего лишь обновить весь стек от самого нутра железа, компиляторов и до игровых движков с учетом специфики Posit.
picul
19.09.2019 00:12+1Если posit идет в связке с quire, то не покажут posit-вычисления лучшую производительность никогда. Касаясь нашей дискуссии, можно достигнуть лучшей производительности путем уменьшения нагрузки на шину памяти за счет упаковки данных (а во избежание потери точности использовать posit-формат), и можно достигнуть большей точности за счет выполнения многобитных вычислений в по quire-принципу. Так вот я говорю, что если первая идея в некоторых ситуациях может оказаться здравой, то вторая в принципе невозможна без серьезной деградации общей производительности видеопроцессора, которая в современных реалиях графических приложений не стоит даже идеально точных вычислений. Но, еще раз, это я говорю о GPU. Если речь идет о центральном процессоре, то это вполне можно добавить как дополнительную возможность, главное что бы это не мешало основным инструкциям.
oam2oam
18.09.2019 20:32мне, как математику, всегда интересно — понимают ли люди, считающие что-нибудь нецелое, что они пытаются расширить результаты, полученные на множестве меры ноль (рациональные числа) на множество не-нулевой меры (действительные числа)?
Не проще ли использовать целочисленную арифметику, если так уж нужна точность? Ну или — целочисленные дроби?FGV
18.09.2019 20:35Не проще ли использовать целочисленную арифметику, если так уж нужна точность? Ну или — целочисленные дроби?
Целочисленная арифметика — это ад для программиста, т.к. цены мл. разрядов операндов надо выравнивать вручную.oam2oam
18.09.2019 20:52не очень понимаю, почему ад для программистов именно, я думал — ад для математиков-вычислителей ;) А для программистов там все просто — если числа маленькие, то что-то типа алгоритмов Брезенхама, если бесконечные — то соответствующие библиотеки и системы…
FGV
19.09.2019 06:06не очень понимаю, почему ад для программистов именно именно, я думал — ад для математиков-вычислителей
Ну мну с фиксированной запятой познакомился будучи программистом на "автокоде" — аля асм с выхлопом в виде бинарника, очень весело было пересобирать все (и всем), после того как математики диапазоны чисел уточняли :)
defuz Автор
18.09.2019 20:38Внезапно, quire – это и есть целочисленная арифметика (на самом деле с фиксированной точкой, но большой разницы я тут не вижу), как раз на случай, когда «так нужна точность».
oam2oam
18.09.2019 20:51нет уж, давайте не будем путать целочисленную (над полем целых чисел) и арифметику с фиксированной точкой. В целочисленной нет ошибки, от слова совсем. Ну, например, поделить 1 на 3 в ней — это значит взять обратный элемент от 3 — в общем случае невозможно. И переформулировка задач в целочисленных терминах очень трудна и не всегда возможна. Но, если уж возможна, то обычно считается очень быстро и, главное, надежно.
KvanTTT
18.09.2019 22:18И переформулировка задач в целочисленных терминах очень трудна и не всегда возможна.
Я бы сказал, почти всегда невозможна, потому что точные вычисления замкнуты только относительно примитивных операций:
+,-,*,/. Как, например, без потери точности взятьsqrt(2)илиsin(pi/ 4)? А такие операции сплошь и рядом в компьютерной графике.
Может тогда сразу в аналитические вычисления перейти, где корень будет представляться именно корнем, а не приблизительным числом.
bopoh13
19.09.2019 18:56Думаю, исходя из арифметики вычисления корней, вопрос нужно ставить по-другому, т. к. точность вычислений напрямую зависит от количества разрядов дробной части (зависит и Muller's Recurrence в комментах ниже). Математики говорят: "
прямоугольник изоляции".
0serg
18.09.2019 20:52+4По-моему описываемый quire полностью ортогонален posit. Я с тем же успехом могу заявить что float-ы обеспечивают long double точность, т.к. я могу в качестве аккумулятора использовать стек x87 и ошибка округления возникнет лишь на этапе записи посчитанного в память. Имхо — это бред. Идея quire вполне обсуждаема, но явно независимо от posit-ов.
defuz Автор
18.09.2019 21:04Не совсем ортогонален. Для Float и Double точные аккумуляторы требуют 640 и 4288 бит регистров, а для Posit32 и Posit64 – только 512 и 2048 соответственно. Конечно, вычислять можно с произвольной точностью на произвольно больших регистрах, но еще есть вопрос как хранить значения с минимальной потерей при сжатии. У тут float не лучший вариант, поскольку создавался как компромис между эффективностью хранения и эффективностью вычислений.

Refridgerator
19.09.2019 06:10Я провел эксперимент для IEEE 754 с одинарной и двойной точностью, а также для 32-битных Posit+Quire. Вычисления проводились в арифметике Quire, но каждое значение в таблице преобразовано в Posit.
Я правильно понял — в самом вычислении Posit вообще никак не участвовал? просто вместо того, чтобы сразу привести Quire к символьному виду, вы его сначала преобразовали в Posit? Но почему вы не сделали того же самого с float и double? Опять на подтасовку фактов смахивает.

lamerok
19.09.2019 09:43И все таки, было бы интересно посмотреть на таблицу сходимости рекуррентного соотношения Мюллера, при расчёте на чистом Posit. Сдаётся мне, что сдадутся они ещё раньше.
Refridgerator
19.09.2019 10:04+1Делал уже:
4.47059
4.64475
4.77073
4.85972
4.99343
6.59878
30.0151
88.4203
99.3479
99.9673
99.9984
99.9999
100
100
100

worldmind
19.09.2019 10:30Эта сеть телескопов генерирует 200 петабайт данных в секунду
ну для таких случаев всякие хитрые оптимизации могут понадобиться, а тем кто не числодробилки делает может уже на рациональные числа можно переходить? Они Мюллера не бояться, правда производительность в реальности трудно измерить.
ads83
19.09.2019 14:19Вы не могли бы выложить в открытый доступ код с тестом формулы Мюллера?
Во-первых, хотелось бы увидеть как правильно делать вычисления на posit/quire
Во-вторых, это позволит интересующимся поиграться с новым форматом.
aamonster
Сдаётся мне, главная проблема posit – его евангелисты.