
«I have 700 000 TIFF files that need to be converted to PDF in a single run», — such a request we got from David Shanton, a senior software developer of TSI Healthcare.
TLDR: we faced several major issues, but made two crucial fixes which helped us:
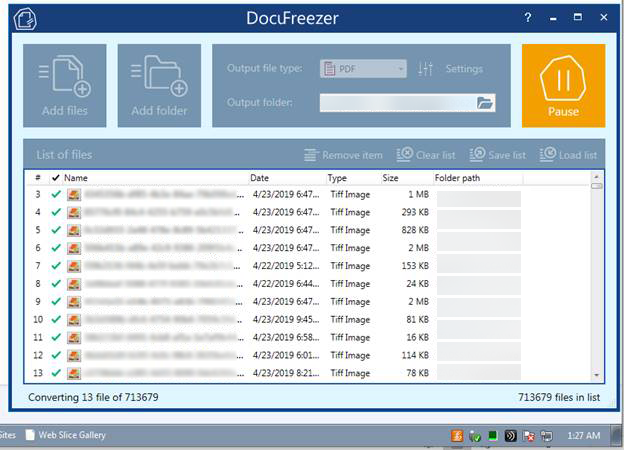
The client already had DocuFreezer installed. Just importing a list of 714 000 files took a whole day! Also, the speed of adding new files (list generation) decreased over time.
Then there were problems with RAM — memory load sometimes reached 5-7 GB. Pausing and resuming the program eased-off the load, but this did not solve the problem in general.
We offered David our fCoder 2PDF command-line utility. According to the initial tests, 2PDF coped with the task better. However, there was a problem similar to the work of DocuFreezer. In the beginning, the processing was smooth but then slowed down.
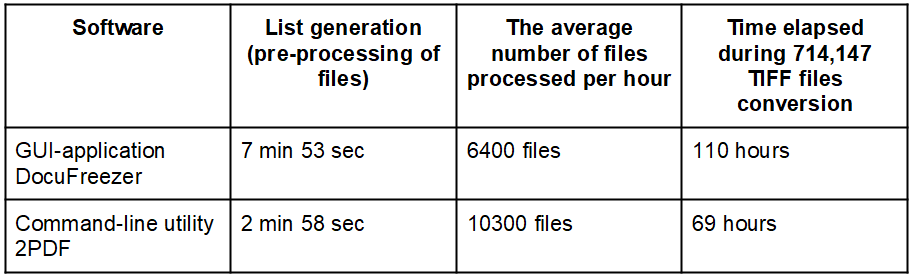
Initially, processing of 104 000 TIFF files took 50 and 15 hours via 2PDF and DocuFreezer respectively. 2PDF quickly created a list of documents, but the conversion process slowed down over time. Creating a list of documents with DocuFreezer was slow, but the conversion itself was at a steady pace (about 7000 files per hour). However, the processing in both cases took a very long while, and this was unacceptable.
At first, we assumed that the bottleneck in the case is the Microsoft .NET Framework. Imagine that you have not 10, not 100, but 700 000 files contained within a standard Windows folder. And try to do something simple with them, e.g. sort them by name in Windows File Explorer or Total Commander — the system will have a hard time. It's about the same here.
But this was not the major issue.
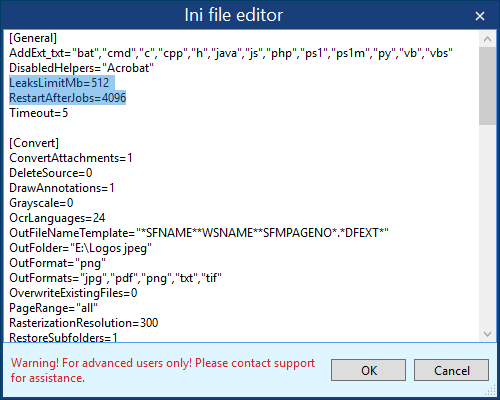
Parts of the program working in different threads lose performance due to the accumulative effect of memory and resource leaks. Because of this, a drop in performance becomes noticeable after processing about 120K files. When this was discovered, we implemented a fix that makes the program restart the conversion engine when a memory leak issue happens. At the same time, the overall operation of the application doesn't stop. We set a limit of 512Mb and a «silent» restart every 4096 files:
Another problem was happening in the very beginning. At the stage of forming the list, the program checked each file for uniqueness. As a result, determining the filename and whether a file is unique or not took resources and much time. We replaced the sequential search of the file path in the list with a hash table search (using the Dictionary class). Thus, checking filenames got much more stable.

After all rounds of tests, David sent us the final results:
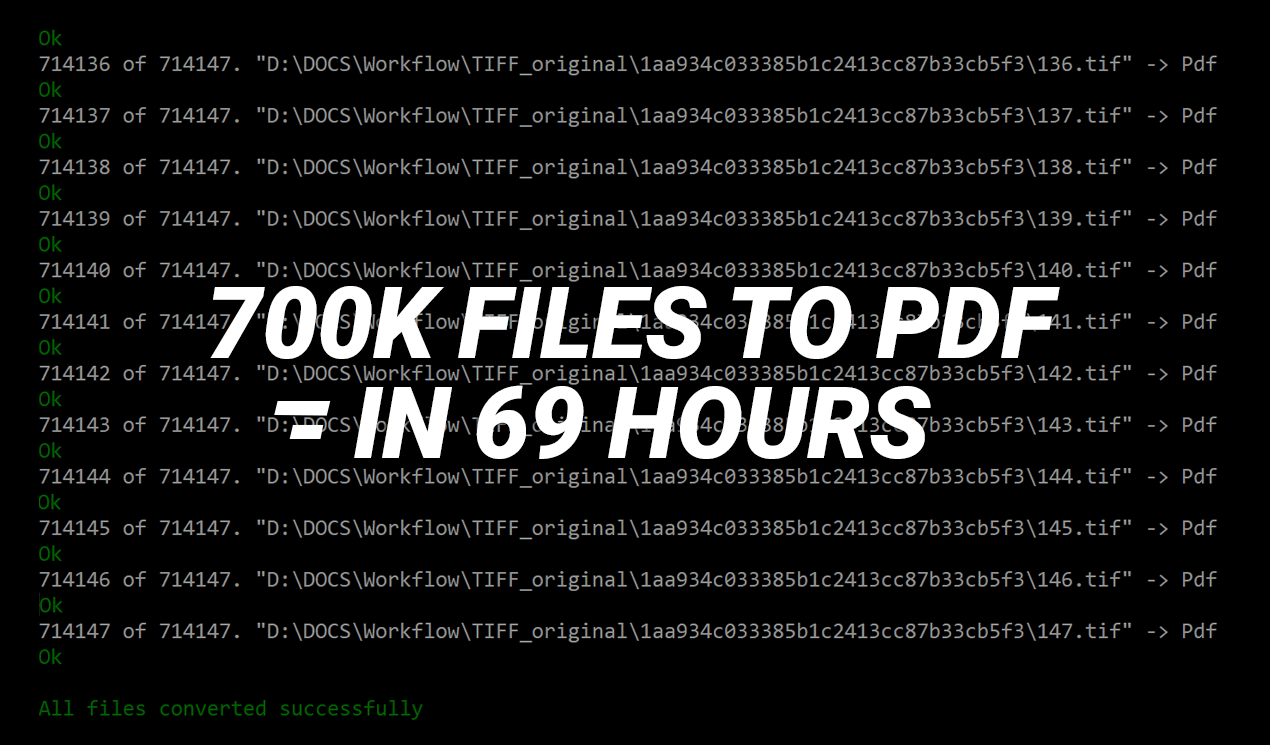
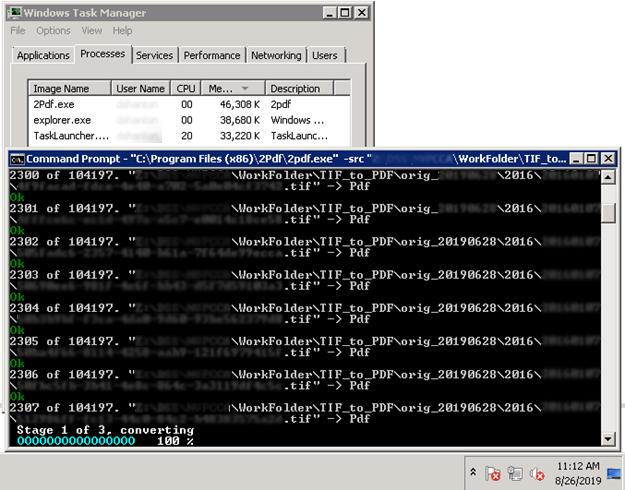
Through the command-line tool, it is possible to process an average of 172 files per minute. Not bad.
As a result, the option of using 2PDF was more suitable for our customer, because, thanks to the command-line interface, he would then be able to integrate the 2PDF functionality into his C# program. Besides, 2PDF is better suited for server applications.
TLDR: we faced several major issues, but made two crucial fixes which helped us:
- speed up importing files to the program's list from a whole day to 7 min 53 seconds
- make the program's processing core restart automatically to avoid memory leaks
- achieve the file processing speed of approximately 10 300 per hour
1. Testing a GUI application
The client already had DocuFreezer installed. Just importing a list of 714 000 files took a whole day! Also, the speed of adding new files (list generation) decreased over time.
Then there were problems with RAM — memory load sometimes reached 5-7 GB. Pausing and resuming the program eased-off the load, but this did not solve the problem in general.
2. Testing a command-line tool
We offered David our fCoder 2PDF command-line utility. According to the initial tests, 2PDF coped with the task better. However, there was a problem similar to the work of DocuFreezer. In the beginning, the processing was smooth but then slowed down.
3. Fixing performance and stability issues of both apps
Initially, processing of 104 000 TIFF files took 50 and 15 hours via 2PDF and DocuFreezer respectively. 2PDF quickly created a list of documents, but the conversion process slowed down over time. Creating a list of documents with DocuFreezer was slow, but the conversion itself was at a steady pace (about 7000 files per hour). However, the processing in both cases took a very long while, and this was unacceptable.
At first, we assumed that the bottleneck in the case is the Microsoft .NET Framework. Imagine that you have not 10, not 100, but 700 000 files contained within a standard Windows folder. And try to do something simple with them, e.g. sort them by name in Windows File Explorer or Total Commander — the system will have a hard time. It's about the same here.
But this was not the major issue.
Parts of the program working in different threads lose performance due to the accumulative effect of memory and resource leaks. Because of this, a drop in performance becomes noticeable after processing about 120K files. When this was discovered, we implemented a fix that makes the program restart the conversion engine when a memory leak issue happens. At the same time, the overall operation of the application doesn't stop. We set a limit of 512Mb and a «silent» restart every 4096 files:
The main problem was the cumulative effect of adding a large number of files
Another problem was happening in the very beginning. At the stage of forming the list, the program checked each file for uniqueness. As a result, determining the filename and whether a file is unique or not took resources and much time. We replaced the sequential search of the file path in the list with a hash table search (using the Dictionary class). Thus, checking filenames got much more stable.
As a result, adding 714 thousand files took only 7 min 53 sec instead of about a day (on a mid-range Intel Core i7 PC)
Final tests
After all rounds of tests, David sent us the final results:
Through the command-line tool, it is possible to process an average of 172 files per minute. Not bad.
As a result, the option of using 2PDF was more suitable for our customer, because, thanks to the command-line interface, he would then be able to integrate the 2PDF functionality into his C# program. Besides, 2PDF is better suited for server applications.
Summary
- If you have a massive lot of files in the queue, then memory leaks should be expected. This can only be avoided without using other people's components (GDI Plus, NET Framework, etc.). Writing all the code from scratch and debugging it is very long and expensive. It is much more effective if the engine of your program is implemented as a separate EXE, and you restart it, for example, after processing every 4000 files.
- Use the Dictionary class to control the uniqueness of the file list. This will avoid time and resource wasting on checking each and every new file.