
В предыдущей статье я рассказывала про структуру Data Science-проекта по материалам методологии IBM: как он устроен, из каких этапов состоит, какие задачи решаются на каждой стадии. Теперь я бы хотела сделать обзор самой трудоемкой стадии, которая может занимать до 90% общего времени проекта: это этапы, связанные с подготовкой данных -сбор, анализ и очистка.
В оригинальном описании методологии Data Science-проект сравнивается с приготовлением блюда, а аналитик - с шеф поваром. Соответственно, этап подготовки данных сравнивается с подготовкой продуктов: после того, как на этапе анализа бизнес-задачи мы определились с рецептом блюда, которое будем готовить, необходимо найти, собрать в одном месте, очистить и нарезать ингредиенты. Соответственно, от того, насколько качественно был выполнен этот этап, будет зависеть вкус блюда (предположим, что с рецептом мы угадали, тем более рецептов в открытом доступе полно). Работа с ингредиентами, то есть подготовка данных - это всегда ювелирное, трудоемкое и ответственное дело: один испорченный или недомытый продукт - и весь труд впустую.
Сбор данных
После того, как мы получили список ингредиентов, которые нам могут понадобится, мы приступаем к поиску данных для решения задачи и формируем выборку, с которой в дальнейшем будем работать. Напомним, для чего нам нужна выборка: во-первых, по ней мы составляем представление о характере данных на этапе подготовки данных, а во-вторых из нее мы будем формировать тестовую и обучающую выборки на этапах разработки и настройки модели.

Мы, конечно, не берем случаи, когда вы под угрозой
- отражала все нужные свойства генеральной совокупности
- была удобной в работе, то есть не слишком большой.
Казалось бы, зачем ограничивать себя в объеме данных в эпоху big data? Это в социологии, как правило, генеральная совокупность недоступна: когда мы исследуем общественное мнение, опросить всех людей невозможно даже в теории. Или в медицине, где проводится исследование нового лекарства на некотором количестве подопытных кроликов/мышек/мушек: каждый дополнительный объект в исследуемой группе — это дорого, хлопотно и сложно. Однако даже если нам фактически доступна вся генеральная совокупность, большие данные требуют соответствующей инфраструктуры для вычислений, а её развертывание само по себе дорогое удовольствие (мы не говорим о случаях, когда готовая и настроенная инфраструктура у вас под рукой). То есть даже если теоретически можно обсчитать все данные, то обычно оказывается, что это долго, дорого и вообще зачем, ведь без всего этого можно обойтись, если подготовить качественную, пусть и небольшую выборку, состоящую, например, из нескольких тысяч записей.
Время и усилия, потраченные на создание выборки, позволяют уделить больше времени разведке данных: например, выбросы или отсутствующие данные могут содержать ценную информацию, но среди миллионов записей найти их невозможно, а среди нескольких тысяч - вполне.
Как оценить репрезентативность данных?
Для того, чтобы понять, насколько наша выборка репрезентативна, нам пригодится здравый смысл и статистика. Для категориальных данных мы должны убедиться, что в нашей выборке каждый признак, который имеет значение с точки зрения бизнес-задачи, представлен в тех же пропорциях, что и в генеральной совокупности. Например, если мы исследуем данные пациентов клиники и вопрос касается людей всех возрастов, нам не подойдет выборка, в которую вошли только дети. Для исторических данных стоит проверить, что данные охватывают репрезентативный интервал времени, на котором исследуемые признаки принимают все возможные значения. Например, если мы анализируем обращения в госорганы, нам скорее всего не подойдут данные за первую неделю января, потому что на это время приходится спад обращений. Для числовых признаков имеет смысл вычислить основные статистики (как минимум точечные: среднее, медиану, вариабельность и сравнить с аналогичными статистиками генеральной совокупности, если это возможно, конечно).
Проблемы при сборе данных
Часто бывает так, что нам не хватает данных. Например, произошла смена информационной системы и данные из старой системы недоступны, или отличается структура данных: используются новые ключи и связь между старыми и новыми данными невозможно установить. Также нередки проблемы организационного характера, когда данные находятся у различных владельцев и не все могут быть настроены тратить время и ресурсы на то, чтобы сделать выгрузку для стороннего проекта.
Как быть в таком случае? Иногда получается найти замену: если нет свежих томатов, то могут подойти консервированные. А если морковка оказалась вся гнилая, нужно идти на рынок за новой порцией. Так что вполне может случиться такое, что на этом этапе нам нужно будет вернуться на предыдущую стадию, где мы анализировали бизнес-задачу и подумать, нельзя ли как то переформулировать вопрос: например, мы не можем явно определить, какой вариант страницы интернет-магазина лучше продает товар (допустим, не хватает данных по продажам), но можем сказать, на какой странице пользователи проводят больше времени и на какой меньше отказов (совсем коротких сеансов просмотра длиной в несколько секунд).
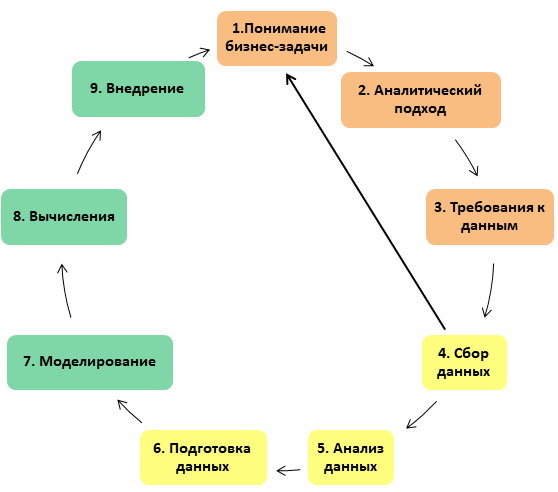
Разведочный анализ данных
Допустим, данные получены, и есть уверенность, что они отражают генеральную совокупность и содержат ответ на поставленную бизнес-задачу. Теперь их необходимо исследовать, чтобы понять, какого качества

Оценка центрального положения
На первом этапе исследования хорошо бы понять, какие значения для каждого признака являются типичными. Самой простой оценкой является среднее арифметическое: простой и всем известный показатель. Однако, если разброс данных большой, то среднее мало что скажет нам о типичных значениях: например, мы хотим понять уровень зарплаты в больнице. Для этого сложим зарплату всех сотрудников, включая директора, который получает в несколько раз больше, чем санитарка. Полученное среднее арифметическое будет выше, чем зарплата любого из сотрудников (кроме директора) и ничего не скажет нам о типичной зарплате. Такой показатель годится только для отчета в министерство здравоохранения, которое гордо будет рапортовать о росте зарплат. Полученная величина слишком подвержена влиянию предельных значений. Для того, чтобы избежать влияния выбросов (нетипичных, предельных значений), используется другая статистика: медиана, которая вычисляется как центральное значение в отсортированных значениях.
Если данные двоичные или категориальные, стоит узнать, какие значения встречаются чаще, а какие реже. Для этого используется мода: наиболее распространенное значение или категория. Это полезно в том числе для понимания репрезентативности выборки: например, мы исследовали данные медицинских карт пациентов и обнаружили что ? карт принадлежат женщинам. Это заставит задуматься, не было ли ошибки при формировании выборки. Чтобы отобразить соотношений категорий относительно друг друга полезно графическое представление данных, например в виде столбчатых или круговых диаграмм.
Оценка вариабельности данных
После того, как мы определились с типичными значениями нашей выборки, можно посмотреть на нетипичные значения — выбросы. Выбросы могут нам что-то сказать о качестве данных: например, могут быть признаками ошибок: смешения размерности, потери десятичных знаков или кривой кодировки. Также они говорят о том, насколько сильно варьируют данные, каковы предельные значения исследуемых признаков.
Далее можно переходить к общей оценке того, как сильно варьируют данные. Вариабельность (она же дисперсность) показывает, насколько сильно различаются между собой значения признака. Один из способов измерения вариабельности - это это оценка типичных отклонений признаков от центрального значения. Понятно, что усреднение этих отклонений нам мало что даст, так как отрицательные отклонений нейтрализуют положительные. Самые известные оценки вариабельности - это дисперсия и стандартное отклонение, учитывающие абсолютное значение отклонений (дисперсия — это среднее квадратических отклонений, а стандартное отклонение — это квадратный корень из дисперсии).
Другой подход основывается на рассмотрении разброса сортированных данных (для больших наборов данных эти меры не используются, так как нужно сначала выполнить сортировку значений, что само по себе затратно). Например, оценка с помощью процентилей (также можно встретить просто центили). N-ный процентиль — это такие значения, что по крайней мере N процентов данных принимает такое значение или большее. Для того, чтобы предотвратить чувствительность к выбросам, можно отбросить значения с каждого конца. Общепринятая мера вариабельности - это разница между 25 и 75 процентилем - межквартильный размах.
Обследование распределения данных
После того, как мы оценили данные с помощью обобщенных числовых характеристик, можно прикинуть, как выглядит распределение данных в целом. Это удобней всего делать с помощью инструментов визуального моделирования - графиков.
Наиболее часто используются следующие виды диаграмм: коробчатая диаграмма (или ящик с усами) и гистограммы. Ящик с усами - удобное компактное представление о выборке, позволяет на одном изображении увидеть несколько исследуемых признаков, а значит, сравнить их друг с другом. Иначе этот вид графика называется диаграмма размаха (англ. box-and-whiskers diagram or plot, box plot). Такой вид диаграммы в понятной форме показывает медиану (или, если нужно, среднее), нижний и верхний квартили, минимальное и максимальное значение выборки и выбросы. Несколько таких ящиков можно нарисовать бок о бок, чтобы визуально сравнивать одно распределение с другим; их можно располагать как горизонтально, так и вертикально. Расстояния между различными частями ящика позволяют определить степень разброса (дисперсии), асимметрии данных и выявить выбросы.

Также полезным инструментом является хорошо всем знакомая гистограмма - визуализация частотной таблицы, где частотные интервалы откладываются на оси Х, а количество данных - на оси Y. Для исследования исторических данных также будет полезна столбчатая диаграмма: она позволит понять, как записи были распределены по времени и можно ли им доверять. С помощью графика можно выявить как ошибки формирования выборки, так и битые данные: всплески в неожиданных местах или наличие записей, относящихся к будущему, могут позволить обнаружить проблемы с форматом данных, например, смешение форматов даты в части выборки.
Корреляция
После того, как мы посмотрели на все переменные, нужно понять, нет ли среди них лишних. Для этого применяется коэффициент корреляции - метрический показатель, который измеряет степень, с какой числовые переменные связаны друг с другой и принимает значения в диапазон от 1 до -1. Корреляционная матрица - таблица, в которой строки и столбцы - это переменные. а значения ячеек — корреляции между этими переменными. Диаграмма рассеяния - по оси x значения одной переменной, по оси y- другой.
Очистка данных
После того, как мы исследовали данные, их необходимо очистить и, возможно, преобразовать. На этом этапе мы должны получить ответ на вопрос: каким образом нам нужно подготовить данные, чтобы использовать их максимально эффективно? Мы должны избавиться от ошибочных данных, обработать отсутствующие записи, удалить дубликаты и убедиться, что все отформатировано надлежащим образом. Также на этом этапе мы определяем набор признаков, на которых далее будет строиться машинное обучение. Именно от качества выполнения этого этапа будет зависеть, будет ли сигнал в данных различим для алгоритма машинного обучения. Если мы работаем с текстом, могут потребоваться дополнительные шаги, чтобы превратить неструктурированные данные в набор признаков, пригодных для использования в модели. Подготовка данных - это фундамент, на котором будут строиться следующие этапы. Как и в кулинарии, всего один испорченный или неочищенный ингредиент может испортить все блюдо. Любая небрежность в обращении с данными может привести к тому, что модель не покажет хороших результатов и придется возвращаться на несколько шагов назад.

Удаление ненужных записей
Одна из первых операций по очистке данных — это удаление ненужных записей. Она включает в себя два шага: удаление дублирующихся или ошибочные записей. Ошибочные значения мы нашли на предыдущем этапе, когда исследовали выбросы и нетипичные значения. Дублирующиеся данные мы могли получить при получении сходных данных из различных источников.
Исправление структурных ошибок
Нередки случаи, когда одни и те же категории могут быть названы по-разному (хуже, когда разные категории имеют одинаковые названия): например, в открытых данных правительства Москвы данные по строительству представлены поквартально, но суммарный объем за год подписан как год, а в некоторых записях обозначен как 4 квартал. В таком случае мы восстанавливаем правильные значения категорий (если возможно это сделать).
Если приходится работать с текстовыми данными, то как минимум нужно провести следующие манипуляции: удалить пробелы, убрать все форматирование, выровнять регистр, исправить орфографические ошибки.
Удаление выбросов
Для задач машинного обучения данные в выборке не должны содержать выбросов и быть максимально стандартизированы, так что единичные предельные значения необходимо удалить.
Управление отсутствующими данными
Работа с отсутствующими данными — один из наиболее сложных шагов в очистке данных. Отсутствие части данных, как правило, является проблемой для большинства алгоритмов, поэтому приходится либо вообще не использовать записи, где часть данных отсутствует, либо пытаться восстановить недостающие на основе каких-либо предположений о характере данных. При этом мы понимаем, что заполнение пробелов в данных (неважно, насколько изощренным способом мы это делаем) — это не добавление новой информации, а просто костыль, который позволяет эффективней использовать остальную информацию. Оба подхода не так чтобы огонь, потому что в любом случае мы теряем информацию. При этом отсутствие данных может быть сигналом само по себе. Например, мы исследуем данные с заправки и отсутствие данных датчика может быть явными признаком нарушения.
При работе с категориальными данными лучшее, что мы можем сделать с отсутствующими данными такого типа - это пометить их как “отсутствующие”. Это шаг фактически подразумевает добавление нового класса категориальных данных. Аналогичным образом стоит поступить и с отсутствующими данными численного типа: нужно как то пометить отсутствующие данные, например, заменить отсутствующие данные нулем. Но нужно иметь в виду, что ноль не всегда подходит. Например, наши данные представляют собой показания счетчиков и отсутствие показаний нельзя смешивать с настоящими нулями в значениях данных.
Инструменты очистки данных
Как правило, очистка данных - это не разовое мероприятие, скорее всего нам придется добавлять в выборку новые данные, которые придется снова пропускать через разработанные процедуры очистки. Для оптимизации процесса неплохо использовать специализированные приложения (помимо, само собой, Excel' я, который тоже вполне может быть полезен), например:
- Talend Data Preparation - бесплатное дескотпное приложение с визуальным интерфейсом, которое упрощает и автоматизирует задачи очистки данных: оно позволяет строить настраиваемый конвейер обработки данных. С Talend можно использовать различные источники данных, в том числе csv файлы или данные Excel.
- OpenRefine. Раньше этот инструмент назывался Google Refine или Freebase Gridworks. Сейчас OpenRefine — популярное десктопное приложение для очистки и преобразования форматов данных.
- Trifacta Wrangler - десктопное приложение, которое позволяет работать со сложными типами данных, полезно также для разведочного анализа данных. Не требует особой подготовки пользователя.
Ну и само собой, конвейер очистки данных может быть реализован на любом удобном языке программирования — от Питона до Scala, главное, чтобы обработка занимала приемлемое время.

И, наконец...
После того, как мы очистили и преобразовали данные может оказаться, что данных осталось как-то маловато, так что нормально, если с этого этапа придется вернуться на шаг получения данных, добавить еще значений в выборку или поискать новые источники данных. Это нормально.
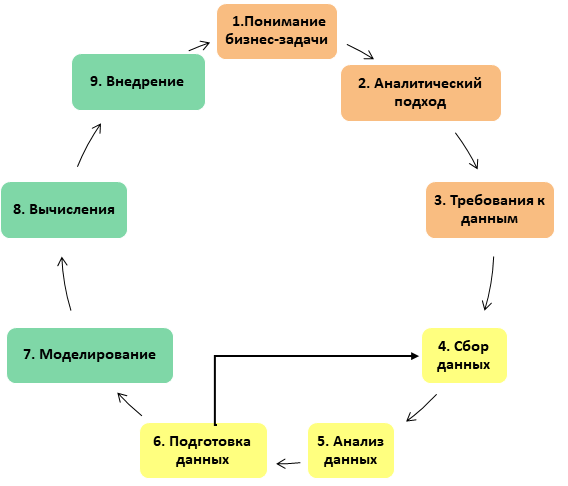
Заключение
Да, подготовка данных - непростое дело, иногда даже мучительное, но усилия, затраченные на этом этапе, вернутся сторицей при запуске модели: нередки случаи, когда даже простые модели довольно быстро показывают отличный результат и требуют минимальной калибровки, если работают на хорошо подготовленных данных.
Надеюсь, статья была полезна.
P.S.: Продукты, использованные для иллюстраций, не пострадали, а были использованы по назначению!
TonyClifton
Фаршированные перцы без мяса? Хм…
openalex
Уоу-уоу, а как же бедро индейки на первом фото? Очень вкусно, кстати, получилось ;)
TonyClifton
Действительено. Не заметил, пардоньте.