Топология современных дата-центров и устройства в них уже не позволяют довольствоваться исключительно whitebox-мониторингом. С течением времени понадобился инструмент, который покажет работоспособность конкретных устройств, исходя из реальной ситуации с передачей трафика (dataplane) в любом месте Clos-сети. Несколько недель назад на конференции Next Hop сетевой инженер Яндекса Александр Клименко поделился опытом решения этой проблемы.
— Я работаю в отделе эксплуатации и развития сети Яндекса, и меня иногда заставляют решать какие-то проблемы, вместо того чтобы рисовать на листочках красивые облачка или изобретать светлое будущее. Приходят люди и говорят, что у них что-то не работает. Если это дело мониторить, если наши дежурные инженеры будут видеть, что именно не работает, то мне самому будет легче. Так что эти полчаса будут посвящены мониторингу.

К идее мониторинга рано или поздно приходят все. То есть сначала вы можете собирать обращения самих пользователей, они будут стучаться к вам и говорить, что у них что-то не работает. Но понятно, что такая система плохо масштабируется. Если у вас больше одного коммутатора, если у вас достаточно большая сеть, то с таким вариантом мониторинга далеко не уйти.
И все рано или поздно приходят к тому, что необходимо собирать какие-то данные от оборудования. Это самый первый шаг. Это могут быть логи, различные данные по SNMP, дропы, вы можете строить топологии по LLDP и т. д. Здесь есть понятный минус — всю эту информацию вам предоставляет само устройство. Оно может что-то недоговаривать, обманывать вас и т. п.
Логичный этап развития вашего мониторинга — это мониторинг на хостах. Можно сказать, что тут есть небольшое ответвление. Если вам повезло — или не повезло — иметь сеть на одном вендоре, то вендор вам может предложить какой-то из собственных вариантов мониторинга. Но в прошлом году на Next Hop Дима Ершов рассказывал, что у нас фабрика создана из двух базовых вендоров и мы себе такую роскошь позволить не можем. Или можем, но только частично.
Наконец, последний вариант, до которого все так или иначе доходят с развитием сети. Это мониторинг на конечных хостах. В Яндексе такой мониторинг есть. Называется он Netmon.

Внизу на слайде есть ссылка с подробной презентацией о том, как работает Netmon. Я расскажу буквально в пределах одного слайда. Если кто-то хочет, пожалуйста, прочитайте доклад с другой конференции про Netmon.
Netmon — это агенты, которые устанавливаются у нас практически на каждом хосте в сети. В агенты поступает задача: отправить на какой-то узел сети какие-то пакеты. Они могут быть совершенно разными: UDP, TCP, ICMP. Это могут быть как разные краски, то есть DSCP, так и destination. Source— и destination-порты тоже могут быть разными.
Эти данные агрегируются, выгружаются в отдельное хранилище, и мы получаем вот такой срез, как справа на рисунке. Срез может быть более агрегированным либо менее агрегированным, в зависимости от того, что именно мы хотим посмотреть. Например, здесь, насколько я вижу, у нас срез всей дата-центровой связанности, то есть между всеми нашими дата-центрами. Мы можем провалиться глубже в квадратики — посмотреть связанность между POD или внутри здания одного дата-центра; еще глубже — внутри POD между стойками; и еще глубже — даже в пределах стойки.

Что тут может пойти не так? Небольшое лирическое отступление для тех, кто не смотрел прошлогодний Next Hop.
У нас использовалось 400 гигабит на ToR, и в первый момент внедрения этой фабрики мы включили только 200, потому что были более важные задачи. Неважно, почему. Включили 200, пришли сервисы и сказали: почему 200? Хотим 400! Начали включать. И так совпало, что вторая часть фабрики, которую мы включали, имела некоторый брак в памяти карточек. В результате мы включаем фабрику и видим вот такую картинку:

У нас горит этот самый Netmon, красные квадраты. Мы понимаем, что все пропало. Хватаемся за голову, как Гомер, и пытаемся что-то судорожно нажать. А что нажимать, что выключать, мы не понимаем. То есть Netmon нам показывает наличие проблемы, но не показывает где, собственно, проблема в сети находится.

Мы пришли к задаче, которую нам нужно выполнить. Что нужно сделать? Определить, с каким устройством в сети наблюдается проблема и вывести его из эксплуатации — либо автоматически, либо силами, например, дежурных инженеров.
При этом начальные условия таковы, что у нас достаточно регулярная топология, то есть нет каких-то странных линков между спайнами второго уровня или между торами. У нас большая часть трафика — TCP, есть центральное место, про него уже рассказали, и сервера более-менее централизовано администрируются. Мы можем прийти в это центральное место и обоснованно заявить: ребята, мы хотим сделать так-то, пожалуйста, сделайте.
Какие варианты действий мы рассмотрели?

Первое, что приходит в голову, — трассировка. Почему? Потому что тот самый Netmon выгружает неудавшиеся пары source и destination в отдельный коллектор. Соответственно, мы можем этот 5-tuple взять, посмотреть на него и сделать трассировку с такими же параметрами. И агрегировать данные о том, через какой линк или через какие устройства проходит наибольшее количество трассировок.
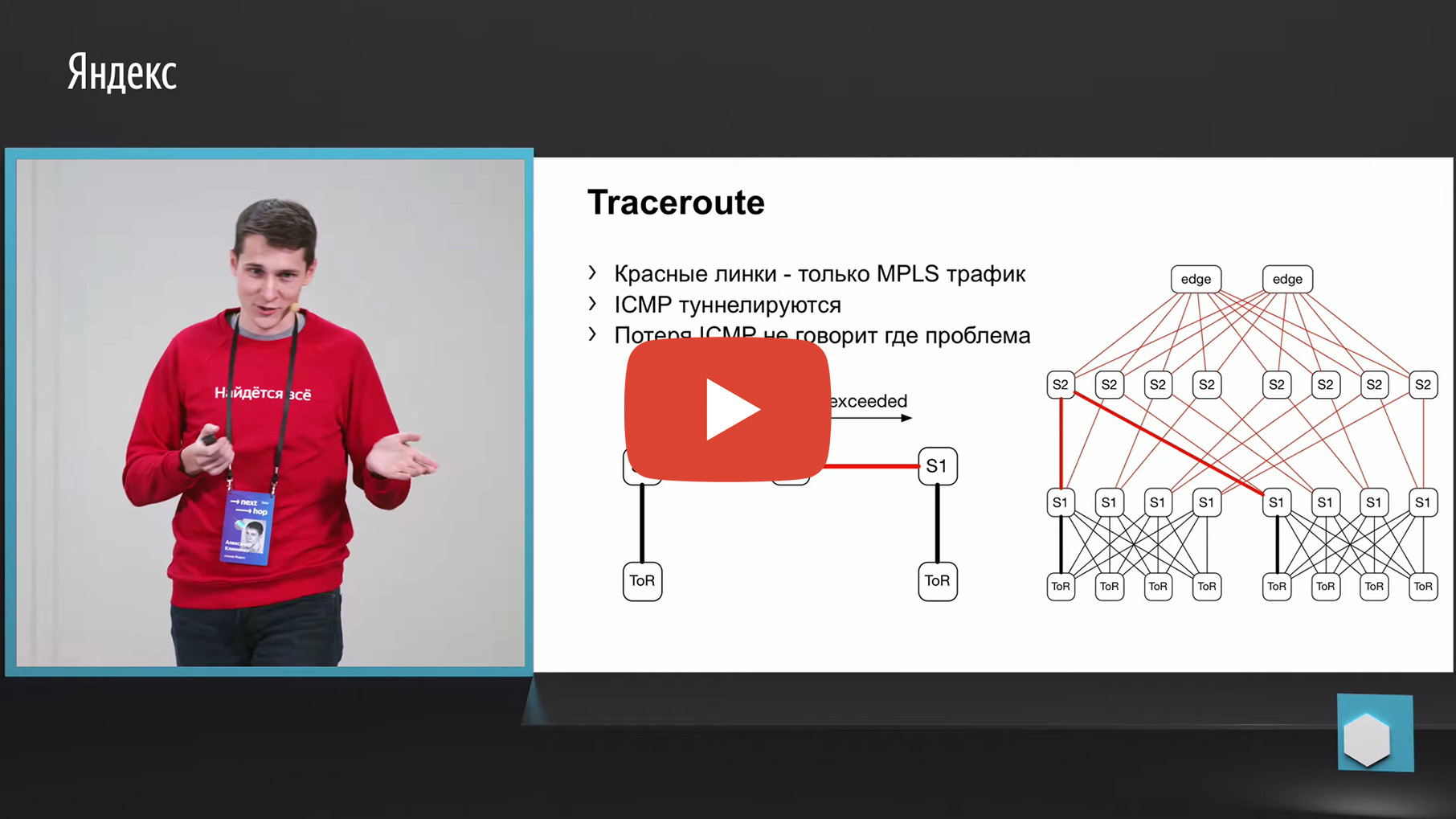
Но к сожалению, у нас в фабрике используется MPLS (сейчас мы двигаемся в другую сторону от MPLS, но мониторить старые фабрики, в общем-то, тоже как-то надо, не выкидывать же, собственно, их). У нас на фабрике есть MPLS и проблема с MPLS и трассировкой в том, что там необходимо туннелировать ICMP-сообщение TTL exceeded, которое лежит в основе работы трассировки. Потеряв такое сообщение от ingress до egress, мы можем потерять тот самый мониторинг. То есть мы не поймем, через какие узлы прошло это сообщение. Для мониторинга нам это не подошло.
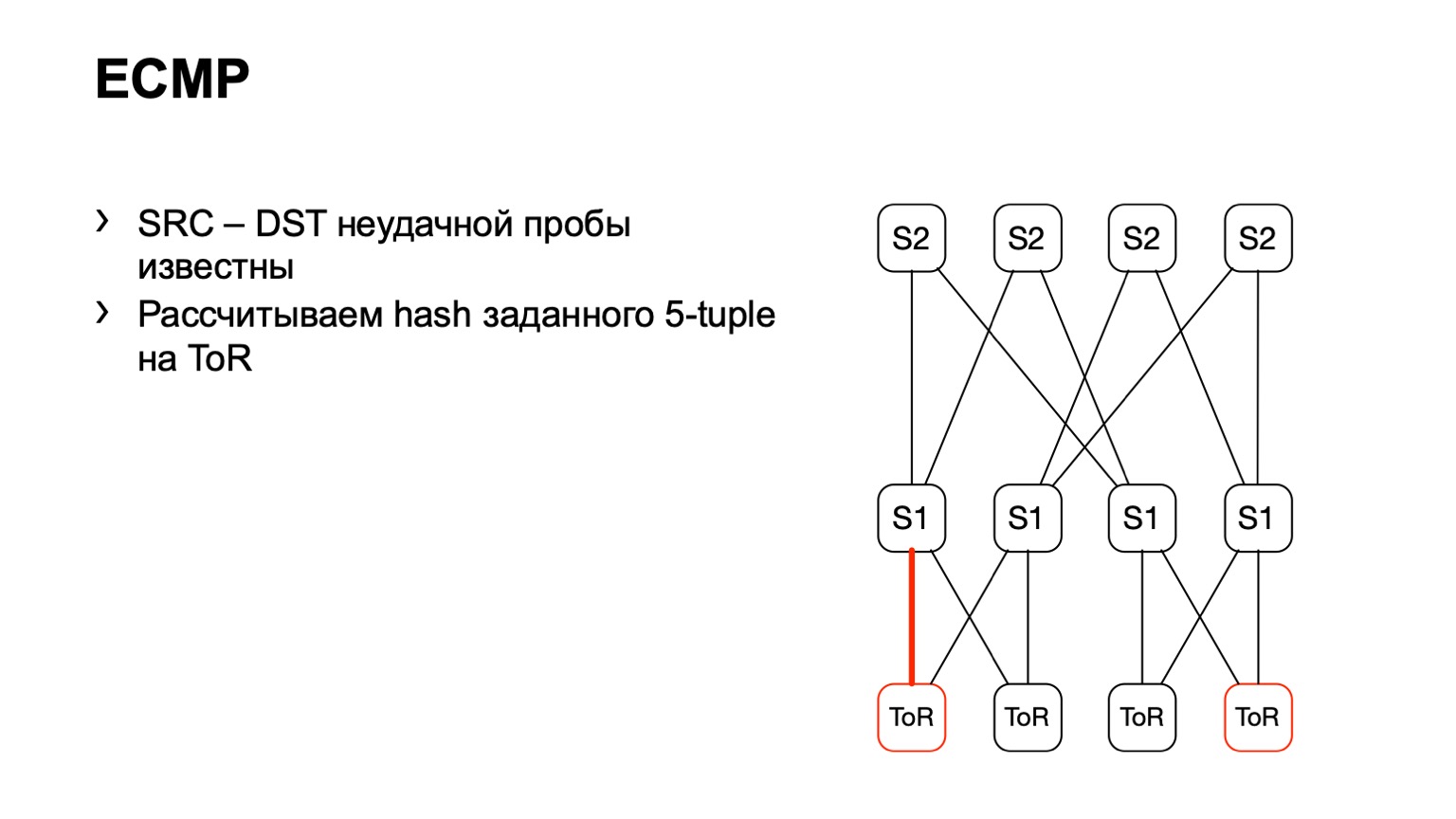
Есть второй вариант, связанный с ECMP. Мы берем ту же самую пару source и destination, в дополнение source-порт destination-порт. Приходим на одну железку, через API или через CLI скармливаем железке эти данные, и получаем выходной интерфейс. Многие устройства поддерживают получение подобного рода вывода.
Мы приходим на ToR, смотрим, что ToR выбрал левый или правый линк. В данном случае левый линк в сторону левого S1.
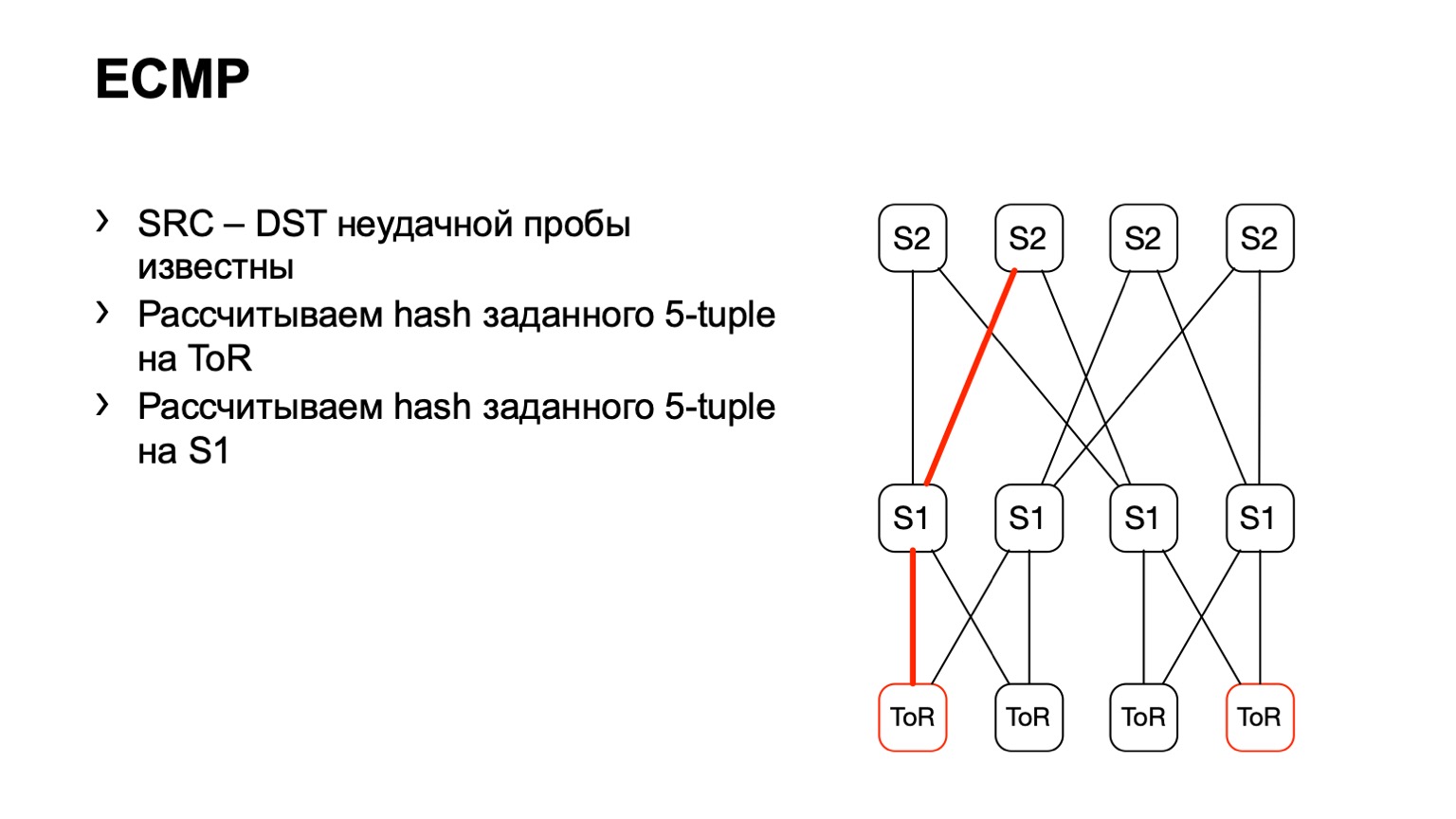
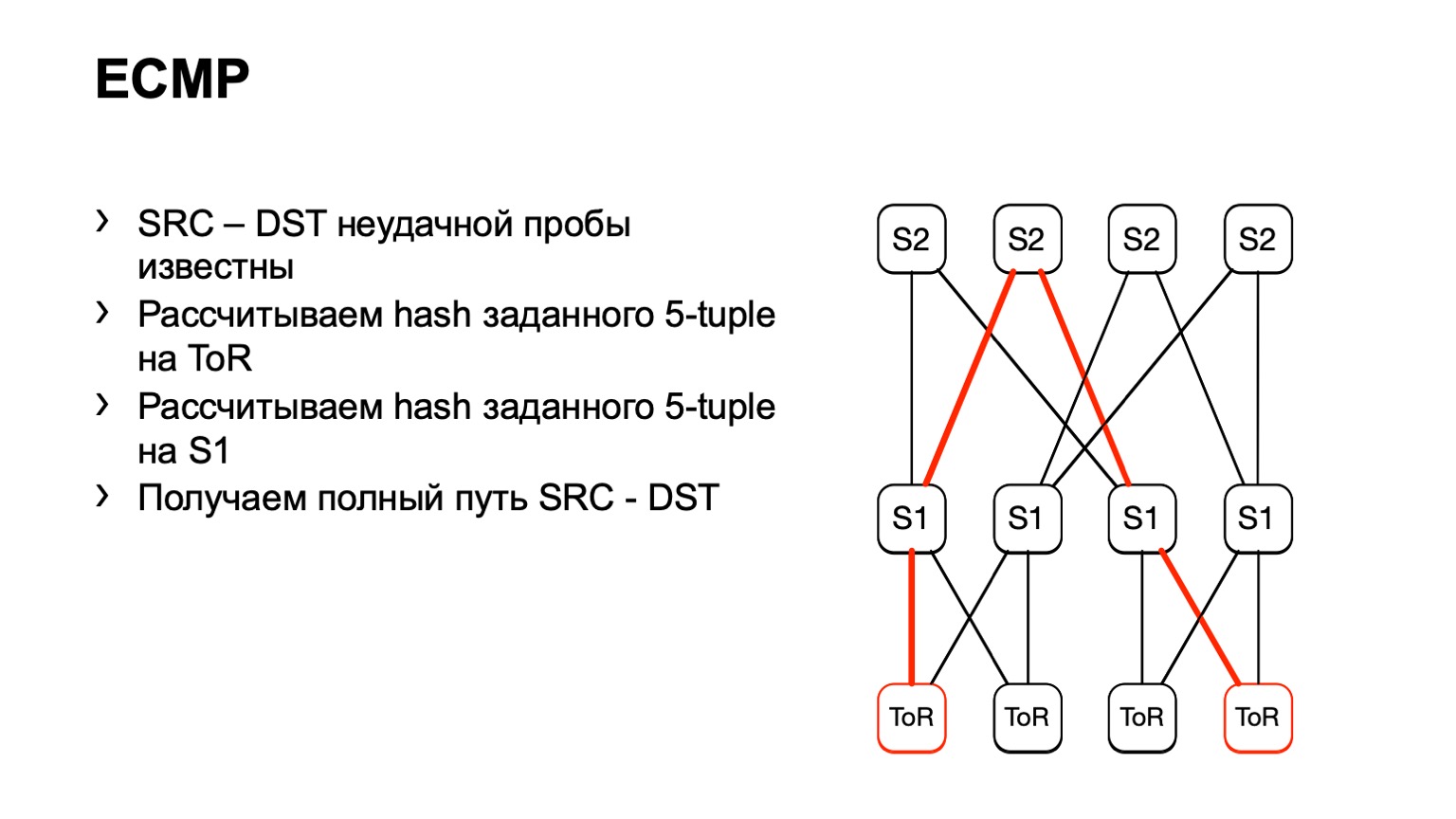
Пришли на этот S1, посмотрели, правый S2, и таким образом сложился готовый путь.
Тут есть некоторые минусы. Во-первых, не все устройства могут нормально принять вот эти входные данные, которые мы им даем. Это связано с тем, что у нас IPv6 и MPLS, а также с тем, что некоторые вендоры просто этого не реализовали. Второй минус такого решения: мы опять опираемся на то, что нам скажет железка, вместо того чтобы смотреть, что происходит на хостах. И, наконец, третий минус — за время, пока вы сходите и посмотрите, что там происходит, в сети уже может что-то поменяться, и ваши данные будут не актуальными.

Дальше нам на глаза попалась интересная презентация, которую делал Facebook. Идея, которую предложил Facebook, нам понравилась, мы решили попробовать сделать что-то похожее.
Какая была основная идея? Использовать eBPF-программу на хосте, чтобы покрасить TCP retransmit и потом посчитать количество таких пакетов. К сожалению, мы не смогли это сделать как у Facebook, пришлось изобретать свой велосипед. О пути боли и страданий, который мы прошли, я сейчас попытаюсь вам рассказать.
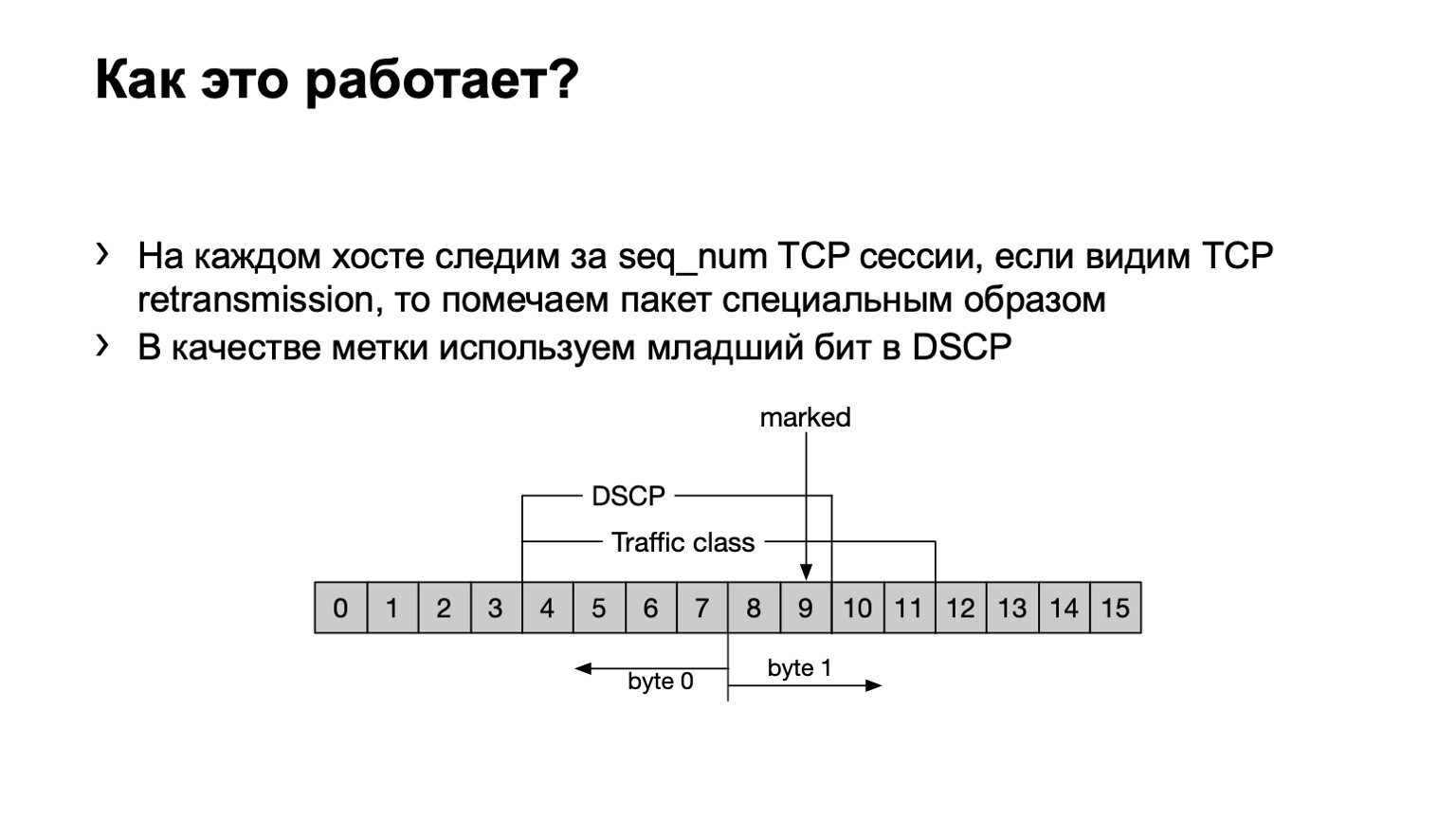
Что мы сделали? На всякий случай укажу, что TCP retransmit — это сообщения TCP, которые повторяются несколько раз вследствие того, что их получение не подтвердили. У нас есть eBPF-программа устанавливается на хосте и смотрит, какое это сообщение TCP — retransmit или не retransmit. Оно делает это банально — по sequence number. Если в TCP-сессии передается один и тот же sequence number, то это retransmit.
Что мы делаем с такими пакетами? Мы выставляем последний бит в поле DSCP в единицу, чтобы дальше все это дело посчитать.
Вообще говоря, DSCP как-то связано с QoS, правильно? И с QoS история у нас в сети достаточно сложная и давняя. У нас есть определенные политики, которые контролируются на ToR-свитчах. К этим политикам мы просто добавили необходимость посчитать еще и вот эти покрашенные пакеты.
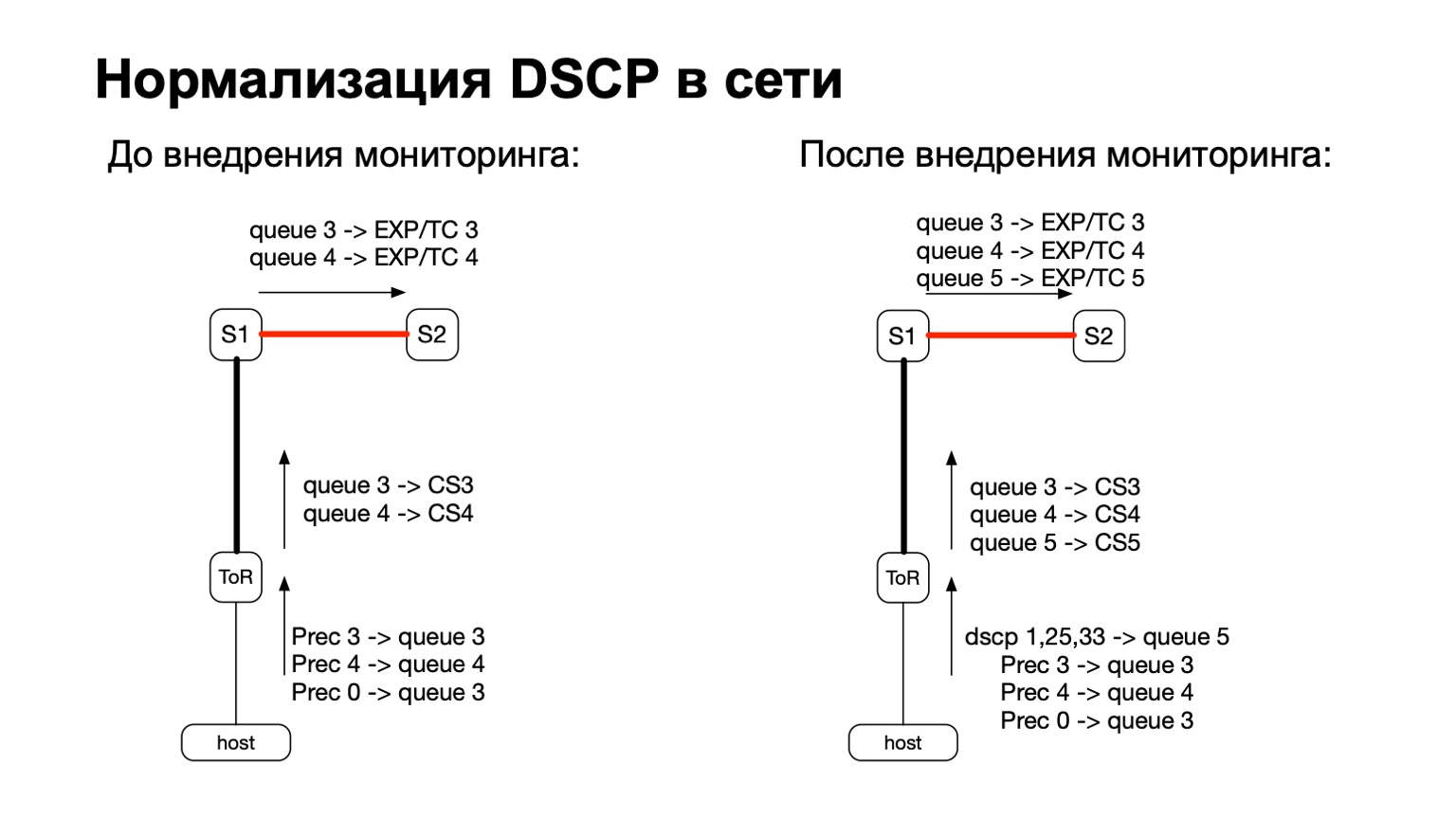
Таким образом, для покрашенных пакетов (читай: для TCP retransmit-пакетов с хоста) мы просто добавили еще одну QoS-очередь. Сделать это было достаточно легко, потому что у нас оставались свободные очереди. Плюс это удобно, потому что на этапе перехода между IPv6 и MPLS на фабрике, то есть на этапе, когда пакет пролетает S1 и уходит в нашу MPLS-часть фабрики, удобно для каждой конкретной очереди взять и перекрасить EXP/TC в MPLS-заголовке пакетов.
Что мы делаем с этими данными? Мы их собираем стандартными фильтрами ACL, traffic class. То есть это работает, в принципе, на любом вендоре. Мы везде можем собрать и посчитать количество таких пакетов.
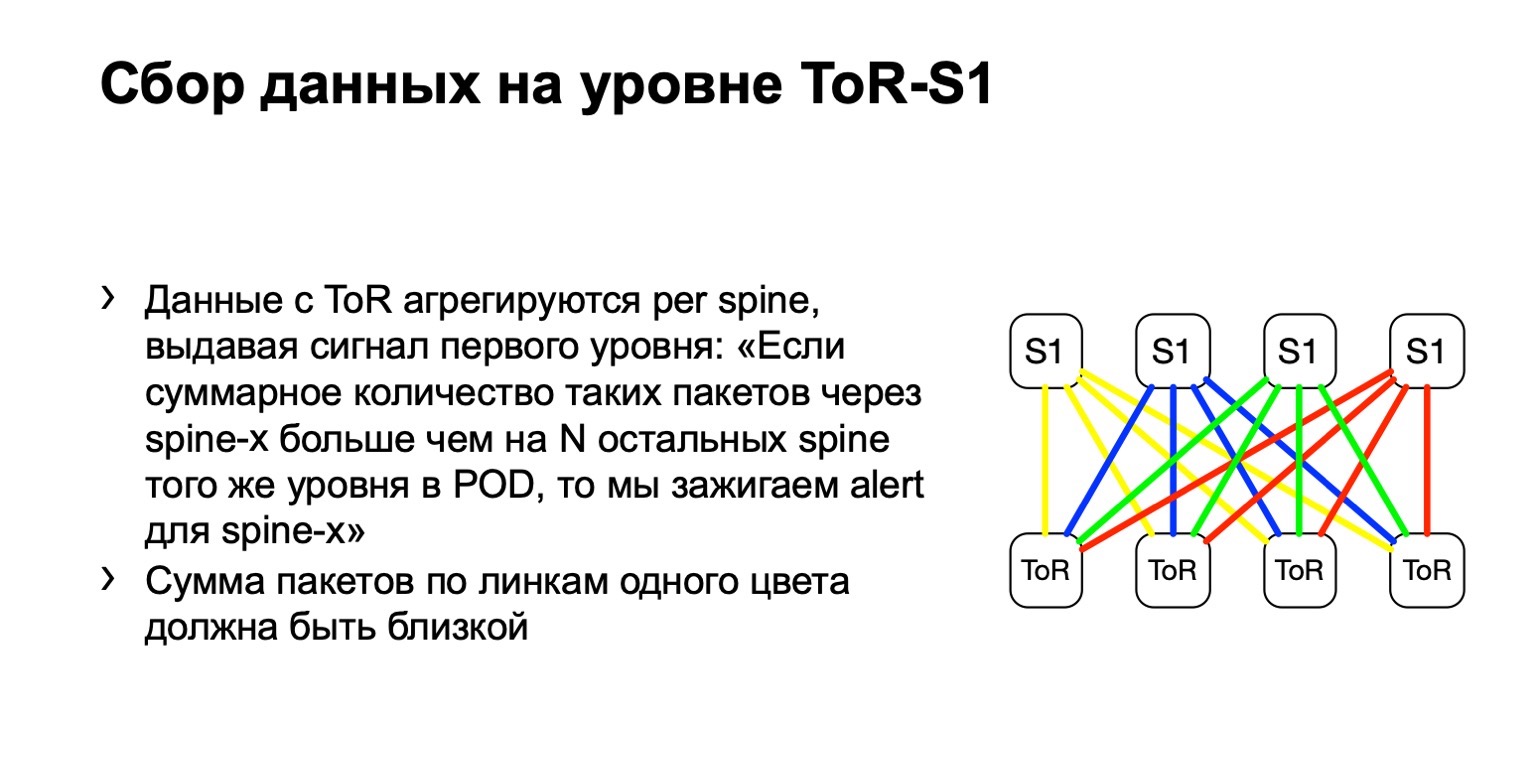
Далее мы смотрим на неравномерность распределения подобных пакетов, на POD. В нем, например, четыре spine, как на картинке. Если количество пакетов по желтым линкам, по синим, по зеленым и по красным одинаковое, то мы считаем, что все более-менее хорошо. Если в какой-то момент времени мы видим прирост, скажем, на самом крайнем правом, spine первого уровня — мы понимаем, что это устройство притягивает retransmit, с ним что-то не так. Дальше мы пытаемся или вывести его из эксплуатации, или хотя бы подебажить. По крайней мере, когда мы будем видеть на Netmon проблемы, мы будем знать, с каким устройством они могли возникнуть.
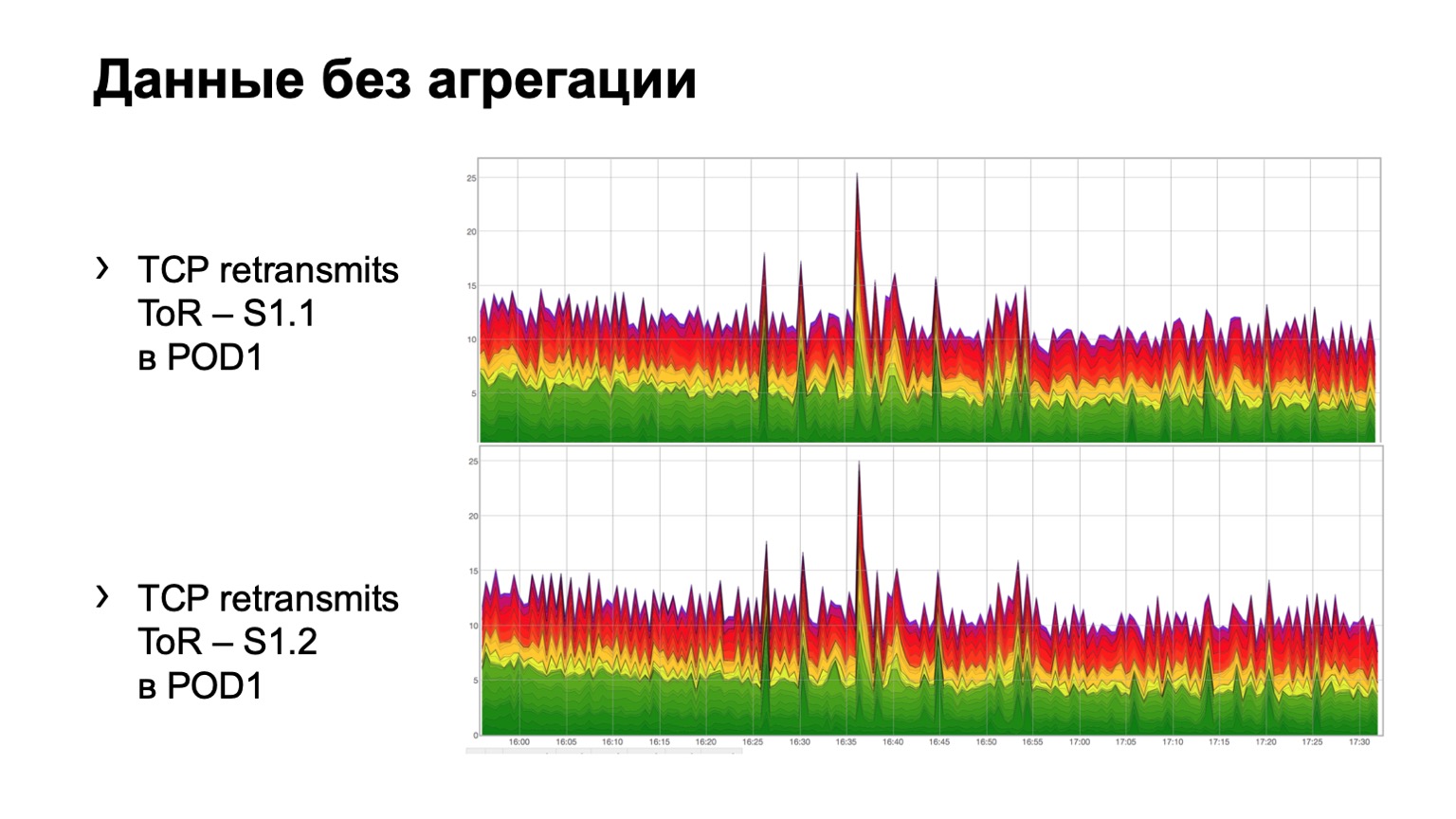
Как это выглядит на простых сырых данных? Вот два графика. По сути, это графики retransmits с ToR в сторону spine первого уровня. В примере два spine в модуле. Верхний график — это агрегация по первому spine, нижний график — по второму spine. Смотреть это в таком виде не очень удобно, поэтому мы добавили агрегацию этой информации.
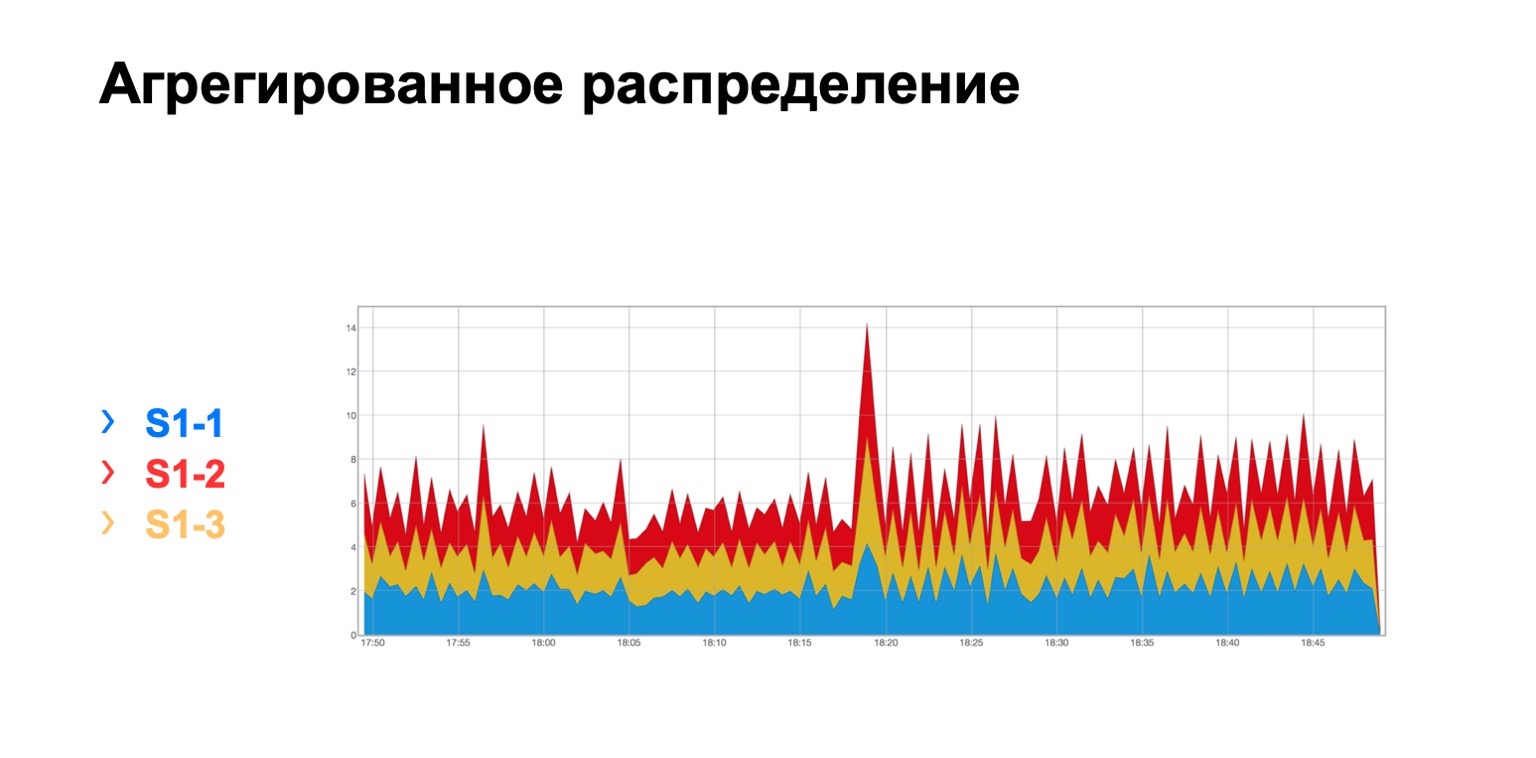
Выглядит она вот так. Есть модуль, в котором три spine, по какой-то причине, неважно, какой, и мы видим вот такое суммарное распределение retransmits до трех spine. Оно в принципе, достаточно равномерное.
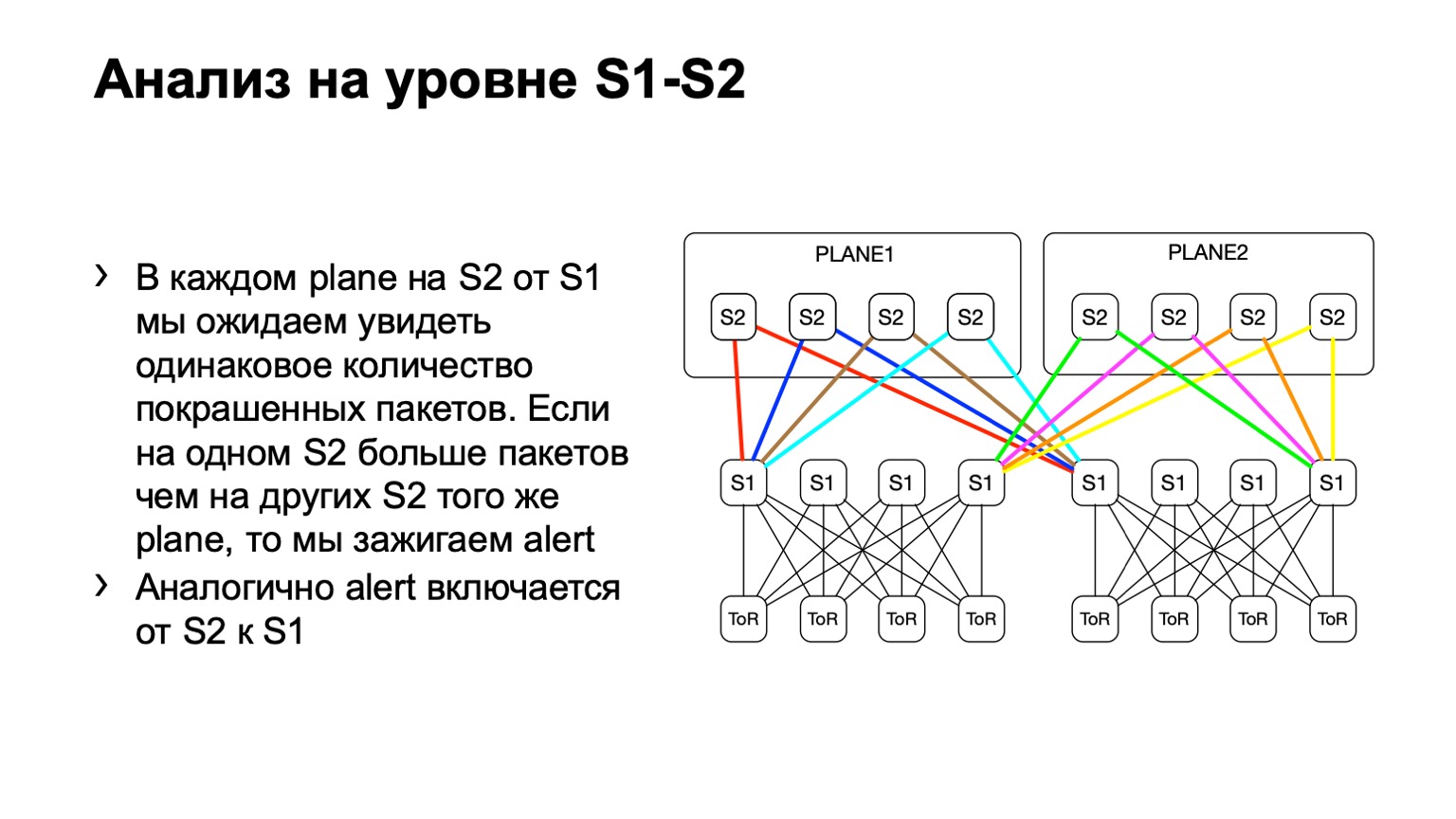
Для spine второго уровня у нас могут быть различные отклонения, назовем их так. Топология все равно остается регулярная, но в зависимости от data-центра мы можем использовать или не использовать плейновую архитектуру. Суть здесь точно такая же. На одном уровне у нас должно быть примерно одинаковое распределение покрашенных пакетов.
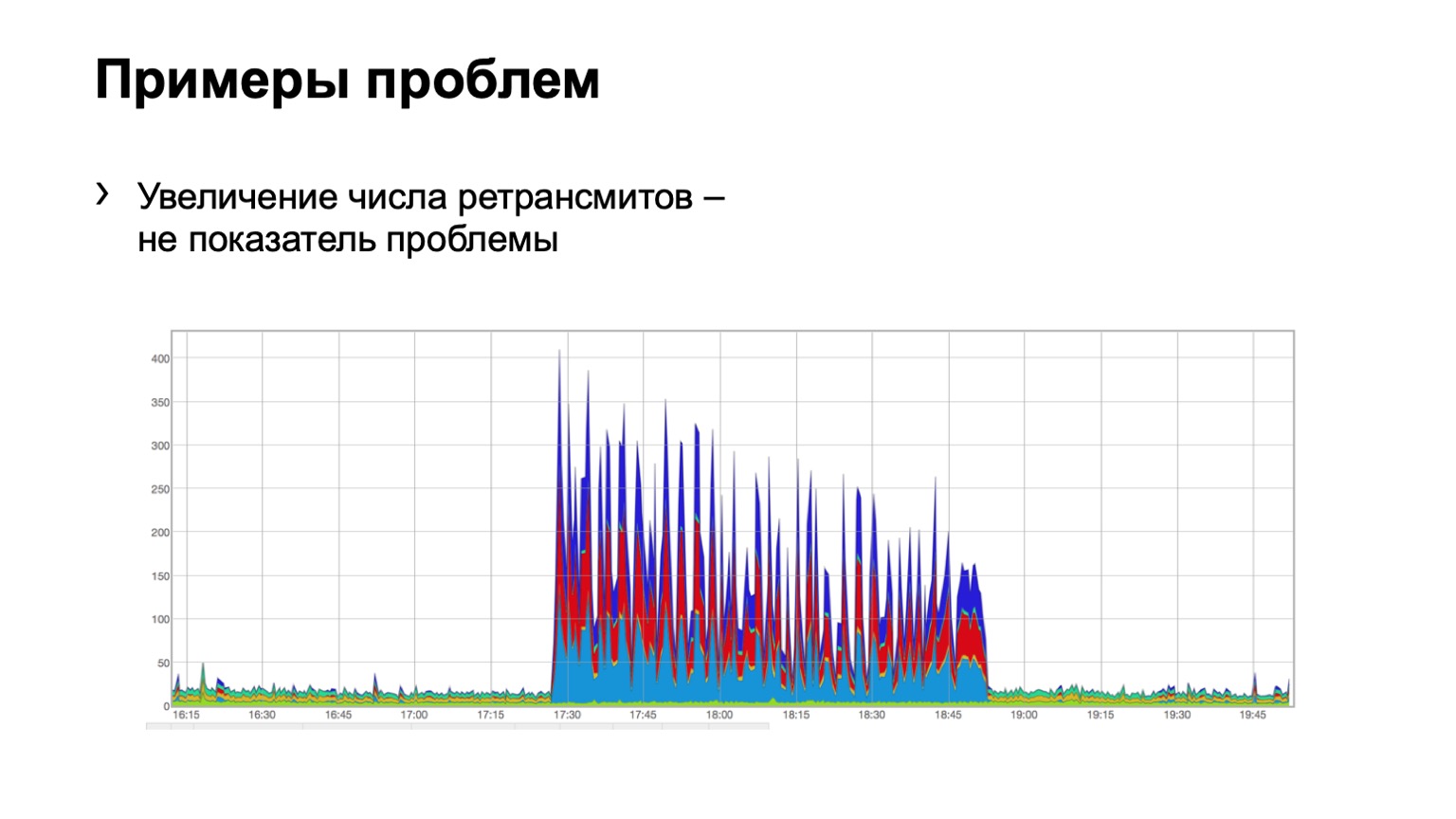
Посмотрим на примерах. Видит ли кто-нибудь проблему на таком графике? Проблема здесь есть, но ее одновременно нет. Да, вот такая проблема Шредингера. Почему она есть и нет? Потому что мы видим рост количества retransmits, это прямо очевидно, у нас что-то произошло. Но в то же время мы видим, что рост этот достаточно равномерный. То есть три spine голубенькие, красненькие, синенькие, по ним равномерное распределение. Что это означает? Что в сети была какая-то проблема, но она не связана с этим уровнем агрегации данных. Она где-то еще.
Может быть, кто-то закрыл порт на firewalls, отключил какой-то кластер, то есть что-то произошло. Но нам вообще не интересно, что там было и почему. То есть мы даже не рассматриваем такую проблему.
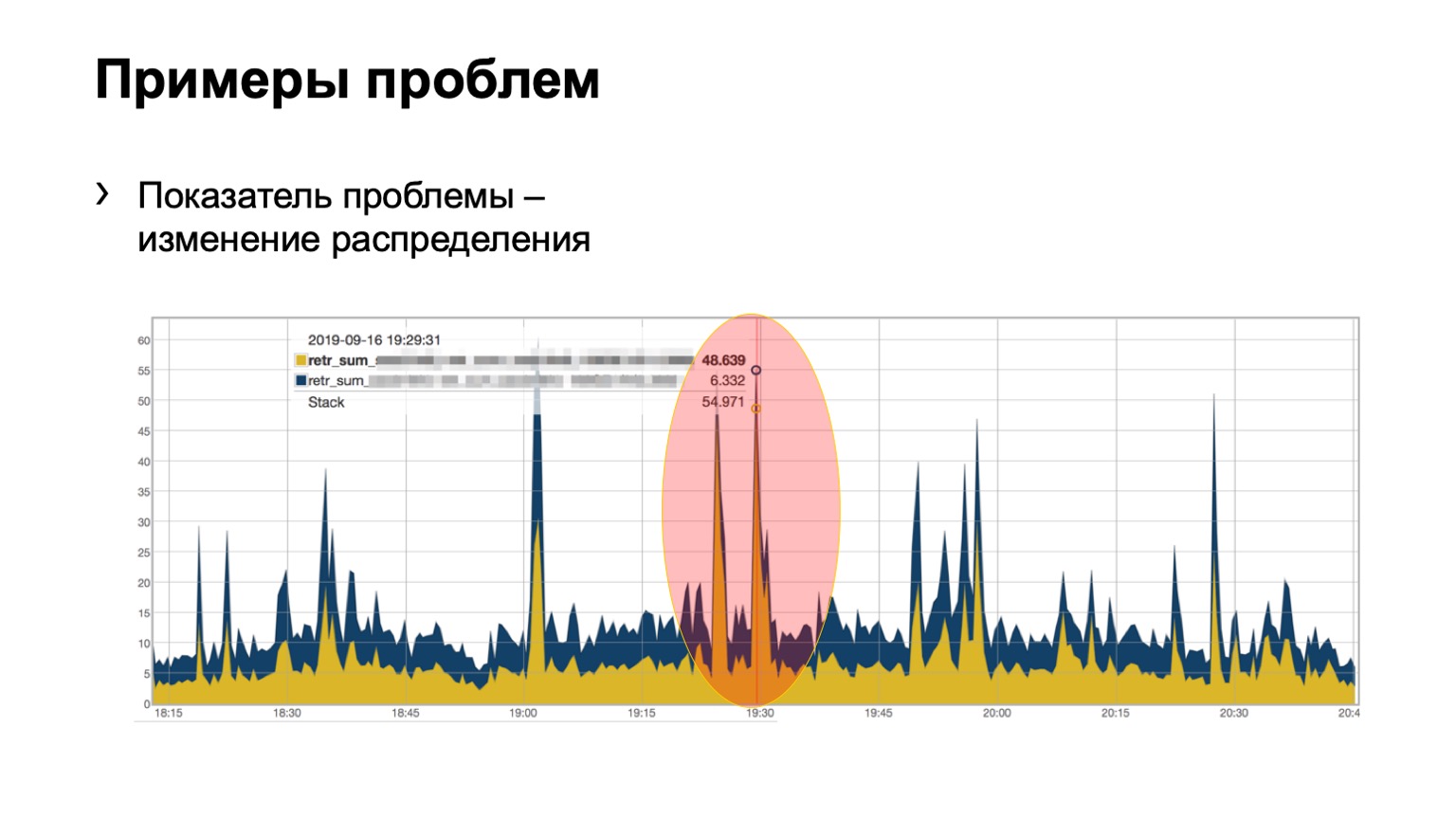
А здесь уже, может быть, не так наглядно, но видна проблема. Два spine в модуле, на один прилетело 46 покрашенных пакетов, на второй совсем чуть-чуть. Мы понимаем, что с каким-то spine в сети у нас проблема, мы с этим должны что-то сделать.
Почему вначале я сказал про путь боли и страдания? Потому что достаточно много проблем с таким решением. Главная проблема это, конечно же, проблема любого мониторинга, это false positive. False positive было достаточно много. В основном из-за того, что мы используем DSCP и в общем-то привязаны к QoS.

Мы обнаружили, что в нашей краске летают чужие пакеты и алертят нам наш мониторинг. То есть мы-то думаем, что это retransmit, а туда кто-то другой засовывает свои пакеты и, в общем, портит нам картинку. Естественно, мы стали разбираться, нашли очень много мест, где мы думали, что оно работает, но оно, на самом деле, работает не так, как мы думаем. Например, входящий в сеть трафик, казалось бы, должен был перекрашиваться, трафик с классом CS6 и CS7 на бордерах не должен попадать в нашу сеть. Но в некоторых местах были, скажем, огрехи, и мы их успешно полечили.
Некоторые производители преподносили сюрпризы в виде того, что вот вы считаете счетчики на исходящем направлении таких пакетов, а чип работает таким образом, что он, на самом деле, для обработки исходящего access listа заворачивает трафик еще раз через себя, откусывая половинку от пропускной способности чипа. Было 900 гигабит на чип, стало в два раза меньше.
И мы сделали некоторое улучшение, связанное с тем, что настройки на хосте могут быть разные. То есть какой-то хост может чаще отправлять retransmits, какой-то хост может реже, какой-то два, какой-то пять, и все это алертит наш мониторинг, все это false positive.
Во-первых, мы отказались от идеи красить каждый TCP retransmit. Мы поняли, что в принципе, не нужен нам каждый retransmit для того, чтобы понять, где проблема. Мы стали красить только SYN-retransmit. SYN — это первый пакет в сессии, нам этого достаточно, для получения сигнала. SYN-ACL мы тоже красим.
Все равно это давало некоторое количество false positive. Мы пошли еще чуть-чуть дальше. Мы стали красить только первые TCP SYN-retransmit в сессии. То есть их отправляется, на самом деле, несколько, мы красили каждый, — стали красить только один. Так мы пришли к тому, что имеем сейчас.
Итого есть Netmon, есть агенты на хостах, которые красят первый SYN-retransmit в сессии, и эти retransmits мы считаем на каждом устройстве, практически на каждом линке в нашей сети.

Но смотреть глазами на картинку, которую я раньше показывал, не очень удобно. То есть дежурным это не продашь, потому что в каждом срезе вам придется это все оценивать глазами. И мы пришли к тому, что хочется иметь alert. Хочется, чтобы зажигалась лампочка: устройство такое-то — проблема; другое устройство — проблема.
Давайте вспомним немного математической статистики. Идея с alert такова, что каждое устройство, по сути, — корзинка. У нас есть вероятность успеха и вероятность неуспеха для четырех устройств. Вероятность попадания retransmit в корзинку, то бишь успех, это ¼. Получается биномиальное распределение.
В чем сложность сделать здесь alert? В том, что мы не можем сделать пороги статическими, не можем сказать: если на одно устройство прилетает десять retransmits, а на другое девять, то проблемы нет. А если десять и пять, то проблема есть. Потому что если мы это масштабируем до тысячи PPS, то такие данные будут уже не актуальными. 1000 PPS и 800 PPS между разными устройствами — это точно проблема.
Мы не можем задать статические пороги в PPS или байтах, не можем их задать в процентах — с ними та же проблема. Поэтому нам нужно решение, которое этот порог сделает более-менее динамическим, в зависимости от числа пакетов.
А прелесть биноминального распределения в том, что на приросте PPS оно стремится к нормальному, и для нормального распределения мы можем уже посчитать матожидание, дисперсию и вычислить доверительный интервал, что мы и сделали. Доверительный интервал у нас 3NPQ, то есть он зависит от числа пакетов через устройство. В итоге у нас получился динамический сдвигающийся порог.
Вот так выглядит на картинке наш сигнал. Если какое-то устройство выбивается из распределения, то мы поднимаем на нем флажочек — с ним что-то не так.

Куда мы хотим развиваться дальше, что мы хотим здесь улучшить, помимо, конечно, борьбы с false positive? В первую очередь, нам было бы интересно посмотреть, а что там в момент проблемы? Для этого у нас в агенте есть такая опция — Debug. Мы можем выгрузить то, что именно ретрансмитнулось, то есть 5-tuple пакета, например, в отдельный коллектор, и потом на него посмотреть. Но это дает некоторую нагрузку на хосты, поэтому нам иногда запрещают так делать. Мы хотим прикрутить ERSPAN и выгружать такие пакеты на коллектор с самих железок, потому что на железке нам никто не запрещает это делать.
Дима Афанасьев рассказывал, как мы будем развивать наши фабрики, и одним из пунктов был переход от MPLS-фабрики к IPv6 only. Что это нам дает? В MPLS три бита для QoS-маркировки. В IPv6 — как минимум шесть. В нашей сети сейчас реально используется только три бита. То есть у нас остается еще три бита, в которые мы можем заложить, по сути, любую информацию с хоста.
Например, сейчас мы красим только первый SYN-retransmit в сессии. А второй бит можем покрасить, например, если пакет уходит во внешнюю сеть. И мы можем ретрансмититься, то есть выделить еще один сигнал, который мы потом будем рассматривать отдельно.
Кроме того, переход к дизайну с edge pod, когда у нас DCI выполнен в каком-то отдельном месте, грозит нам тем, что в этом месте мы можем более точно контролировать наш diffserv-домен. То есть перекрашивать и делать что-то с красками, чтобы отсечь false positive.
Как итог — делать все перечисленное оказалось достаточно больно, но интересно. Ничего страшного не было. Мы, по сути, разработали решение, которое может использовать каждый. Оно проверено фактически на каждом вендоре, это работает, это не сложно. И оно действительно показывает, с каким устройством в сети возникла проблема. Поэтому мой посыл — не бойтесь делать так же, и пусть мониторинги у вас остаются зелеными. Спасибо, что послушали.
— Я работаю в отделе эксплуатации и развития сети Яндекса, и меня иногда заставляют решать какие-то проблемы, вместо того чтобы рисовать на листочках красивые облачка или изобретать светлое будущее. Приходят люди и говорят, что у них что-то не работает. Если это дело мониторить, если наши дежурные инженеры будут видеть, что именно не работает, то мне самому будет легче. Так что эти полчаса будут посвящены мониторингу.
К идее мониторинга рано или поздно приходят все. То есть сначала вы можете собирать обращения самих пользователей, они будут стучаться к вам и говорить, что у них что-то не работает. Но понятно, что такая система плохо масштабируется. Если у вас больше одного коммутатора, если у вас достаточно большая сеть, то с таким вариантом мониторинга далеко не уйти.
И все рано или поздно приходят к тому, что необходимо собирать какие-то данные от оборудования. Это самый первый шаг. Это могут быть логи, различные данные по SNMP, дропы, вы можете строить топологии по LLDP и т. д. Здесь есть понятный минус — всю эту информацию вам предоставляет само устройство. Оно может что-то недоговаривать, обманывать вас и т. п.
Логичный этап развития вашего мониторинга — это мониторинг на хостах. Можно сказать, что тут есть небольшое ответвление. Если вам повезло — или не повезло — иметь сеть на одном вендоре, то вендор вам может предложить какой-то из собственных вариантов мониторинга. Но в прошлом году на Next Hop Дима Ершов рассказывал, что у нас фабрика создана из двух базовых вендоров и мы себе такую роскошь позволить не можем. Или можем, но только частично.
Наконец, последний вариант, до которого все так или иначе доходят с развитием сети. Это мониторинг на конечных хостах. В Яндексе такой мониторинг есть. Называется он Netmon.
Внизу на слайде есть ссылка с подробной презентацией о том, как работает Netmon. Я расскажу буквально в пределах одного слайда. Если кто-то хочет, пожалуйста, прочитайте доклад с другой конференции про Netmon.
Netmon — это агенты, которые устанавливаются у нас практически на каждом хосте в сети. В агенты поступает задача: отправить на какой-то узел сети какие-то пакеты. Они могут быть совершенно разными: UDP, TCP, ICMP. Это могут быть как разные краски, то есть DSCP, так и destination. Source— и destination-порты тоже могут быть разными.
Эти данные агрегируются, выгружаются в отдельное хранилище, и мы получаем вот такой срез, как справа на рисунке. Срез может быть более агрегированным либо менее агрегированным, в зависимости от того, что именно мы хотим посмотреть. Например, здесь, насколько я вижу, у нас срез всей дата-центровой связанности, то есть между всеми нашими дата-центрами. Мы можем провалиться глубже в квадратики — посмотреть связанность между POD или внутри здания одного дата-центра; еще глубже — внутри POD между стойками; и еще глубже — даже в пределах стойки.
Что тут может пойти не так? Небольшое лирическое отступление для тех, кто не смотрел прошлогодний Next Hop.
У нас использовалось 400 гигабит на ToR, и в первый момент внедрения этой фабрики мы включили только 200, потому что были более важные задачи. Неважно, почему. Включили 200, пришли сервисы и сказали: почему 200? Хотим 400! Начали включать. И так совпало, что вторая часть фабрики, которую мы включали, имела некоторый брак в памяти карточек. В результате мы включаем фабрику и видим вот такую картинку:
У нас горит этот самый Netmon, красные квадраты. Мы понимаем, что все пропало. Хватаемся за голову, как Гомер, и пытаемся что-то судорожно нажать. А что нажимать, что выключать, мы не понимаем. То есть Netmon нам показывает наличие проблемы, но не показывает где, собственно, проблема в сети находится.
Мы пришли к задаче, которую нам нужно выполнить. Что нужно сделать? Определить, с каким устройством в сети наблюдается проблема и вывести его из эксплуатации — либо автоматически, либо силами, например, дежурных инженеров.
При этом начальные условия таковы, что у нас достаточно регулярная топология, то есть нет каких-то странных линков между спайнами второго уровня или между торами. У нас большая часть трафика — TCP, есть центральное место, про него уже рассказали, и сервера более-менее централизовано администрируются. Мы можем прийти в это центральное место и обоснованно заявить: ребята, мы хотим сделать так-то, пожалуйста, сделайте.
Какие варианты действий мы рассмотрели?
Первое, что приходит в голову, — трассировка. Почему? Потому что тот самый Netmon выгружает неудавшиеся пары source и destination в отдельный коллектор. Соответственно, мы можем этот 5-tuple взять, посмотреть на него и сделать трассировку с такими же параметрами. И агрегировать данные о том, через какой линк или через какие устройства проходит наибольшее количество трассировок.
Но к сожалению, у нас в фабрике используется MPLS (сейчас мы двигаемся в другую сторону от MPLS, но мониторить старые фабрики, в общем-то, тоже как-то надо, не выкидывать же, собственно, их). У нас на фабрике есть MPLS и проблема с MPLS и трассировкой в том, что там необходимо туннелировать ICMP-сообщение TTL exceeded, которое лежит в основе работы трассировки. Потеряв такое сообщение от ingress до egress, мы можем потерять тот самый мониторинг. То есть мы не поймем, через какие узлы прошло это сообщение. Для мониторинга нам это не подошло.
Есть второй вариант, связанный с ECMP. Мы берем ту же самую пару source и destination, в дополнение source-порт destination-порт. Приходим на одну железку, через API или через CLI скармливаем железке эти данные, и получаем выходной интерфейс. Многие устройства поддерживают получение подобного рода вывода.
Мы приходим на ToR, смотрим, что ToR выбрал левый или правый линк. В данном случае левый линк в сторону левого S1.
Пришли на этот S1, посмотрели, правый S2, и таким образом сложился готовый путь.
Тут есть некоторые минусы. Во-первых, не все устройства могут нормально принять вот эти входные данные, которые мы им даем. Это связано с тем, что у нас IPv6 и MPLS, а также с тем, что некоторые вендоры просто этого не реализовали. Второй минус такого решения: мы опять опираемся на то, что нам скажет железка, вместо того чтобы смотреть, что происходит на хостах. И, наконец, третий минус — за время, пока вы сходите и посмотрите, что там происходит, в сети уже может что-то поменяться, и ваши данные будут не актуальными.
Дальше нам на глаза попалась интересная презентация, которую делал Facebook. Идея, которую предложил Facebook, нам понравилась, мы решили попробовать сделать что-то похожее.
Какая была основная идея? Использовать eBPF-программу на хосте, чтобы покрасить TCP retransmit и потом посчитать количество таких пакетов. К сожалению, мы не смогли это сделать как у Facebook, пришлось изобретать свой велосипед. О пути боли и страданий, который мы прошли, я сейчас попытаюсь вам рассказать.
Что мы сделали? На всякий случай укажу, что TCP retransmit — это сообщения TCP, которые повторяются несколько раз вследствие того, что их получение не подтвердили. У нас есть eBPF-программа устанавливается на хосте и смотрит, какое это сообщение TCP — retransmit или не retransmit. Оно делает это банально — по sequence number. Если в TCP-сессии передается один и тот же sequence number, то это retransmit.
Что мы делаем с такими пакетами? Мы выставляем последний бит в поле DSCP в единицу, чтобы дальше все это дело посчитать.
Вообще говоря, DSCP как-то связано с QoS, правильно? И с QoS история у нас в сети достаточно сложная и давняя. У нас есть определенные политики, которые контролируются на ToR-свитчах. К этим политикам мы просто добавили необходимость посчитать еще и вот эти покрашенные пакеты.
Таким образом, для покрашенных пакетов (читай: для TCP retransmit-пакетов с хоста) мы просто добавили еще одну QoS-очередь. Сделать это было достаточно легко, потому что у нас оставались свободные очереди. Плюс это удобно, потому что на этапе перехода между IPv6 и MPLS на фабрике, то есть на этапе, когда пакет пролетает S1 и уходит в нашу MPLS-часть фабрики, удобно для каждой конкретной очереди взять и перекрасить EXP/TC в MPLS-заголовке пакетов.
Что мы делаем с этими данными? Мы их собираем стандартными фильтрами ACL, traffic class. То есть это работает, в принципе, на любом вендоре. Мы везде можем собрать и посчитать количество таких пакетов.
Далее мы смотрим на неравномерность распределения подобных пакетов, на POD. В нем, например, четыре spine, как на картинке. Если количество пакетов по желтым линкам, по синим, по зеленым и по красным одинаковое, то мы считаем, что все более-менее хорошо. Если в какой-то момент времени мы видим прирост, скажем, на самом крайнем правом, spine первого уровня — мы понимаем, что это устройство притягивает retransmit, с ним что-то не так. Дальше мы пытаемся или вывести его из эксплуатации, или хотя бы подебажить. По крайней мере, когда мы будем видеть на Netmon проблемы, мы будем знать, с каким устройством они могли возникнуть.
Как это выглядит на простых сырых данных? Вот два графика. По сути, это графики retransmits с ToR в сторону spine первого уровня. В примере два spine в модуле. Верхний график — это агрегация по первому spine, нижний график — по второму spine. Смотреть это в таком виде не очень удобно, поэтому мы добавили агрегацию этой информации.
Выглядит она вот так. Есть модуль, в котором три spine, по какой-то причине, неважно, какой, и мы видим вот такое суммарное распределение retransmits до трех spine. Оно в принципе, достаточно равномерное.
Для spine второго уровня у нас могут быть различные отклонения, назовем их так. Топология все равно остается регулярная, но в зависимости от data-центра мы можем использовать или не использовать плейновую архитектуру. Суть здесь точно такая же. На одном уровне у нас должно быть примерно одинаковое распределение покрашенных пакетов.
Посмотрим на примерах. Видит ли кто-нибудь проблему на таком графике? Проблема здесь есть, но ее одновременно нет. Да, вот такая проблема Шредингера. Почему она есть и нет? Потому что мы видим рост количества retransmits, это прямо очевидно, у нас что-то произошло. Но в то же время мы видим, что рост этот достаточно равномерный. То есть три spine голубенькие, красненькие, синенькие, по ним равномерное распределение. Что это означает? Что в сети была какая-то проблема, но она не связана с этим уровнем агрегации данных. Она где-то еще.
Может быть, кто-то закрыл порт на firewalls, отключил какой-то кластер, то есть что-то произошло. Но нам вообще не интересно, что там было и почему. То есть мы даже не рассматриваем такую проблему.
А здесь уже, может быть, не так наглядно, но видна проблема. Два spine в модуле, на один прилетело 46 покрашенных пакетов, на второй совсем чуть-чуть. Мы понимаем, что с каким-то spine в сети у нас проблема, мы с этим должны что-то сделать.
Почему вначале я сказал про путь боли и страдания? Потому что достаточно много проблем с таким решением. Главная проблема это, конечно же, проблема любого мониторинга, это false positive. False positive было достаточно много. В основном из-за того, что мы используем DSCP и в общем-то привязаны к QoS.
Мы обнаружили, что в нашей краске летают чужие пакеты и алертят нам наш мониторинг. То есть мы-то думаем, что это retransmit, а туда кто-то другой засовывает свои пакеты и, в общем, портит нам картинку. Естественно, мы стали разбираться, нашли очень много мест, где мы думали, что оно работает, но оно, на самом деле, работает не так, как мы думаем. Например, входящий в сеть трафик, казалось бы, должен был перекрашиваться, трафик с классом CS6 и CS7 на бордерах не должен попадать в нашу сеть. Но в некоторых местах были, скажем, огрехи, и мы их успешно полечили.
Некоторые производители преподносили сюрпризы в виде того, что вот вы считаете счетчики на исходящем направлении таких пакетов, а чип работает таким образом, что он, на самом деле, для обработки исходящего access listа заворачивает трафик еще раз через себя, откусывая половинку от пропускной способности чипа. Было 900 гигабит на чип, стало в два раза меньше.
И мы сделали некоторое улучшение, связанное с тем, что настройки на хосте могут быть разные. То есть какой-то хост может чаще отправлять retransmits, какой-то хост может реже, какой-то два, какой-то пять, и все это алертит наш мониторинг, все это false positive.
Во-первых, мы отказались от идеи красить каждый TCP retransmit. Мы поняли, что в принципе, не нужен нам каждый retransmit для того, чтобы понять, где проблема. Мы стали красить только SYN-retransmit. SYN — это первый пакет в сессии, нам этого достаточно, для получения сигнала. SYN-ACL мы тоже красим.
Все равно это давало некоторое количество false positive. Мы пошли еще чуть-чуть дальше. Мы стали красить только первые TCP SYN-retransmit в сессии. То есть их отправляется, на самом деле, несколько, мы красили каждый, — стали красить только один. Так мы пришли к тому, что имеем сейчас.
Итого есть Netmon, есть агенты на хостах, которые красят первый SYN-retransmit в сессии, и эти retransmits мы считаем на каждом устройстве, практически на каждом линке в нашей сети.
Но смотреть глазами на картинку, которую я раньше показывал, не очень удобно. То есть дежурным это не продашь, потому что в каждом срезе вам придется это все оценивать глазами. И мы пришли к тому, что хочется иметь alert. Хочется, чтобы зажигалась лампочка: устройство такое-то — проблема; другое устройство — проблема.
Давайте вспомним немного математической статистики. Идея с alert такова, что каждое устройство, по сути, — корзинка. У нас есть вероятность успеха и вероятность неуспеха для четырех устройств. Вероятность попадания retransmit в корзинку, то бишь успех, это ¼. Получается биномиальное распределение.
В чем сложность сделать здесь alert? В том, что мы не можем сделать пороги статическими, не можем сказать: если на одно устройство прилетает десять retransmits, а на другое девять, то проблемы нет. А если десять и пять, то проблема есть. Потому что если мы это масштабируем до тысячи PPS, то такие данные будут уже не актуальными. 1000 PPS и 800 PPS между разными устройствами — это точно проблема.
Мы не можем задать статические пороги в PPS или байтах, не можем их задать в процентах — с ними та же проблема. Поэтому нам нужно решение, которое этот порог сделает более-менее динамическим, в зависимости от числа пакетов.
А прелесть биноминального распределения в том, что на приросте PPS оно стремится к нормальному, и для нормального распределения мы можем уже посчитать матожидание, дисперсию и вычислить доверительный интервал, что мы и сделали. Доверительный интервал у нас 3NPQ, то есть он зависит от числа пакетов через устройство. В итоге у нас получился динамический сдвигающийся порог.
Вот так выглядит на картинке наш сигнал. Если какое-то устройство выбивается из распределения, то мы поднимаем на нем флажочек — с ним что-то не так.
Куда мы хотим развиваться дальше, что мы хотим здесь улучшить, помимо, конечно, борьбы с false positive? В первую очередь, нам было бы интересно посмотреть, а что там в момент проблемы? Для этого у нас в агенте есть такая опция — Debug. Мы можем выгрузить то, что именно ретрансмитнулось, то есть 5-tuple пакета, например, в отдельный коллектор, и потом на него посмотреть. Но это дает некоторую нагрузку на хосты, поэтому нам иногда запрещают так делать. Мы хотим прикрутить ERSPAN и выгружать такие пакеты на коллектор с самих железок, потому что на железке нам никто не запрещает это делать.
Дима Афанасьев рассказывал, как мы будем развивать наши фабрики, и одним из пунктов был переход от MPLS-фабрики к IPv6 only. Что это нам дает? В MPLS три бита для QoS-маркировки. В IPv6 — как минимум шесть. В нашей сети сейчас реально используется только три бита. То есть у нас остается еще три бита, в которые мы можем заложить, по сути, любую информацию с хоста.
Например, сейчас мы красим только первый SYN-retransmit в сессии. А второй бит можем покрасить, например, если пакет уходит во внешнюю сеть. И мы можем ретрансмититься, то есть выделить еще один сигнал, который мы потом будем рассматривать отдельно.
Кроме того, переход к дизайну с edge pod, когда у нас DCI выполнен в каком-то отдельном месте, грозит нам тем, что в этом месте мы можем более точно контролировать наш diffserv-домен. То есть перекрашивать и делать что-то с красками, чтобы отсечь false positive.
Как итог — делать все перечисленное оказалось достаточно больно, но интересно. Ничего страшного не было. Мы, по сути, разработали решение, которое может использовать каждый. Оно проверено фактически на каждом вендоре, это работает, это не сложно. И оно действительно показывает, с каким устройством в сети возникла проблема. Поэтому мой посыл — не бойтесь делать так же, и пусть мониторинги у вас остаются зелеными. Спасибо, что послушали.