Введение
Данная статья является продолжением серии статей описывающей алгоритмы лежащие в основе
Synet — фреймворка для запуска предварительно обученных нейронных сетей на CPU.
Если смотреть на распределение процессорного времени, которое тратится на прямое распространение сигнала в нейронных сетях, то окажется что зачастую более 90% всего времени тратится в сверточных слоях. Поэтому если мы хотим получить быстрый алгоритм для нейронной сети – нам нужен, прежде всего, быстрый алгоритм для сверточного слоя. В настоящей статье я хочу описать методы оптимизации прямого распространения сигнала в сверточном слое. Причем начать хочется с наиболее широко распространенных методов, основанных на матричном умножении. Изложение я буду стараться вести в максимально доступной форме, чтобы статья была интересна не только специалистам (они и так про это все знают), но и более широкому кругу читателей. Я не претендую на полноту обзора, так что любые замечания и дополнения только приветствуются.
Параметры сверточного слоя
Начать описание хотелось бы с описания параметров, которые есть в сверточном слое. Специалисты могут смело пропустить этот раздел.
Размеры входного и выходного изображения
Прежде всего, сверточный слой характеризуется входным и выходным изображением, которые характеризуются следующими параметрами:

- srcC / dstC — число каналов во входном и выходном изображении. Альтернативные обозначения: C / D.
- srcH / dstH — высота входного и выходного изображения. Альтернативное обозначение: H.
- srcW / dstW — ширина входного и выходного изображения. Альтернативное обозначение: W.
- batch — число входных (выходных) изображений — слой за раз может обработать целую партию изображений. Альтернативное обозначение: N.
Размеры ядра свертки
Операция свертки по своей сути — это взвешенная сумма некой окрестности данной точки изображения. Размер ядра свертки — характеризует величину этой окрестности и описывается двумя параметрами:

- kernelY — высота ядра свертки. Альтернативное обозначение: Y.
- kernelX — ширина ядра свертки. Альтернативное обозначение: X.
Наиболее часто встречаются свертки с размером ядра 1x1 и 3x3. Размеры 5x5 и 7x7 встречаются значительно реже. Большие размеры свертки, а также свертки с ядром отличным от квадратного тоже иногда встречаются, но это больше экзотика.
Шаг свертки
Еще один важный параметр — шаг свертки:

- strideY — вертикальный шаг свертки.
- strideX — горизонтальный шаг свертки.
Если шаг отличен от 1x1, например — 2x2, то выходное изображение будет в два раза меньше (свертка будет рассчитана только в окрестности четных точек).
Растяжение свертки
Ядро свертки можно растянуть (увеличить эффективный размер окна, при сохранени количества операций) при помощи следующих параметров:
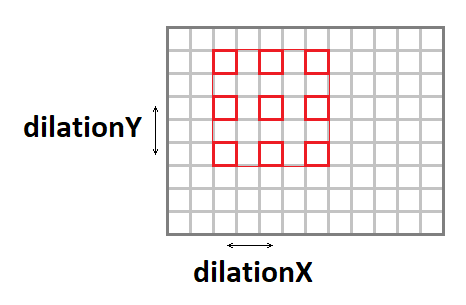
- dilationY — вертикальное растяжение свертки.
- dilationX — горизонтальное растяжение свертки.
Стоит отметить, что случаи с растяжением, отличным от 1x1 достаточно редкое явление (так я за свою карьеру с таким ни разу не встретился).
Паддинг входного изображения
Если применить свертку с окном, отличным от единичного к изображению, то выходное изображение будет меньше на величину kernel — 1. Свертка как бы «съедает» края. Чтобы сохранить размер изображения, входное изображение часто дополняют по краям нулями. За это отвечают еще четыре параметра:

- padY / padX — передние вертикальный и горизонтальный отступы.
- padH / padW — задние вертикальный и горизонтальный отступы.
Группы каналов
Обычно каждый выходной канал представляет собой сумму сверток по всем входным каналам. Однако, это не всегда так. Есть возможность разбить входные и выходные каналы на группы, суммирование осуществляется только внутри групп:

- group — число групп.
На практике чаще всего встречаются ситуации с group = 1 и group = srcC = dstC — так называемое depthwise convolution.
Смещение и активационная функция
Хотя формально смещение и активационная функция не входят в свертку, но очень часто эти две операции следуют за сверточным слоем, почему их обычно тоже включают в него. В виду разнообразия возможных активационных функций и их параметров, я не буду здесь их подробно описывать.
Базовая реализация алгоритма
Для начала хотелось бы привести базовую реализацию алгоритма:
float relu(float value)
{
return value > 0 ? return value : 0;
}
void convolution(const float * src, int batch, int srcC, int srcH, int srcW,
int kernelY, int kernelX, int dilationY, int dilationX,
int strideY, int strideX, int padY, int padX, int padH, int padW, int group,
const float * weight, const float * bias, float * dst, int dstC)
{
int dstH = (srcH + padY + padH - (dilationY * (kernelY - 1) + 1)) / strideY + 1;
int dstW = (srcW + padX + padW - (dilationX * (kernelX - 1) + 1)) / strideX + 1;
for (int b = 0; b < batch; ++b)
{
for (int g = 0; g < group; ++g)
{
for (int dc = 0; dc < dstC / group; ++dc)
{
for (int dy = 0; dy < dstH; ++dy)
{
for (int dx = 0; dx < dstW; ++dx)
{
float sum = 0;
for (int sc = 0; sc < srcC / group; ++sc)
{
for (int ky = 0; ky < kernelY; ky++)
{
for (int kx = 0; kx < kernelX; kx++)
{
int sy = dy * strideY + ky * dilationY - padY;
int sx = dx * strideX + kx * dilationX - padX;
if (sy >= 0 && sy < srcH && sx >= 0 && sx < srcW)
sum +=
src[((b * srcC + sc)*srcH + sy)*srcW + sx] *
weight[((dc * srcC / group + sc)*kernelY + ky)*kernelX + kx];
}
}
}
dst[((b * dstC + dc)*dstH + dy)*dstW + dx] = relu(sum + bias[dc]);
}
}
}
}
}
}
В этой реализации я предполагал, что входное и выходное изображение имеет формат NCHW:
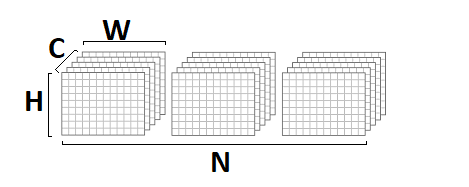
веса свертки хранятся в формате DCYX, а активационная функция у нас это ReLU. В общем случае это не так, но для базовой реализации такие предположения вполне уместны — надо же от чего-то отталкиваться.
Мы имеем 8 вложенных циклов и общее количество операций:
batch * kernelY * kernelX * srcC * dstH * dstW * dstC / group * 2,
при этом количество данных во входном:
batch * srcC * srcH * srcW,
и выходном изображении:
batch * dstC * dstH * dstW,
а количество весовых коэффициентов:
kernelY * kernelX * srcC * dstC / group.
Если group << srcC (число групп значительно меньше числа каналов), а также при достаточно больших параметрах srcC, srcH, srcW и dstC у нас получается классическая вычислительная задача, когда количество вычислений значительно превышает объем входных и выходных данных. Т.е. операция свертки при грамотной реализации должна упираться в вычислительные ресурсы процессора, а не в пропускную способность памяти. Осталось только эту реализацию найти.
Сведение задачи к матричному умножению
Основная операция в свертке — это получение взвешенной суммы, причем веса одинаковы для всех точек выходного изображения. Если переупорядочить входное изображение следующим образом:
void im2col(const float * src, int srcC, int srcH, int srcW,
int kernelY, int kernelX, int dilationY, int dilationX,
int strideY, int strideX, int padY, int padX, int padH, int padW, float * buf)
{
int dstH = (srcH + padY + padH - (dilationY * (kernelY - 1) + 1)) / strideY + 1;
int dstW = (srcW + padX + padW - (dilationX * (kernelX - 1) + 1)) / strideX + 1;
for (int sc = 0; sc < srcC; ++sc)
{
for (int ky = 0; ky < kernelY; ky++)
{
for (int kx = 0; kx < kernelX; kx++)
{
for (int dy = 0; dy < dstH; ++dy)
{
for (int dx = 0; dx < dstW; ++dx)
{
int sy = dy * strideY + ky * dilationY - padY;
int sx = dx * strideX + kx * dilationX - padX;
if (sy >= 0 && sy < srcH && sx >= 0 && sx < srcW)
*buf++ = src[((b * srcC + sc)*srcH + sy)*srcW + sx];
else
*buf++ = 0;
}
}
}
}
}
}
То мы перейдем от формата srcC — srcH — srcW мы перейдем к формату srcC — kernelY — kernelX — dstH — dstW. Ниже на рисунке показано, как происходит преобразование изображения с паддингом 1 и ядром 3x3:
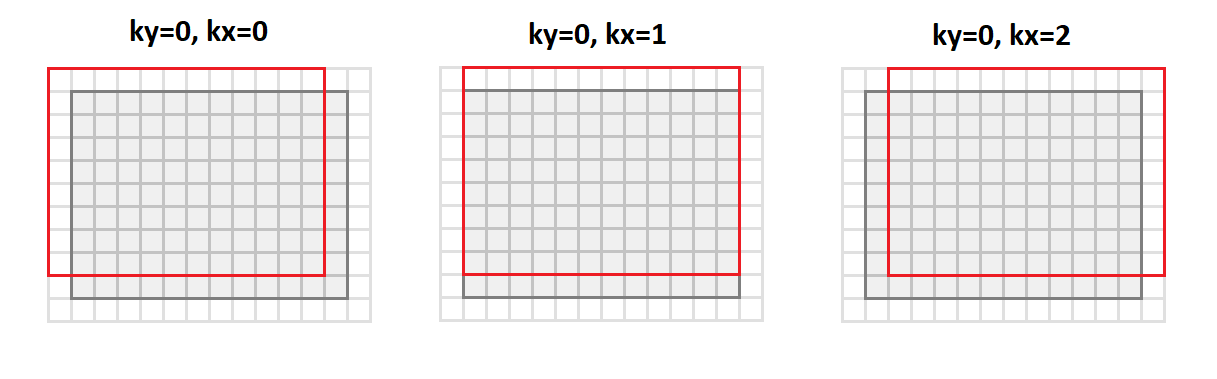
При этом все точки окрестности изображения, которые требуются для операции свертки выстраиваются вдоль столбцов результирующей матрицы (отсюда и ее название — image to columns).
Новое представление входного изображения интересно тем, что теперь операция свертки у нас сводится к матричному умножению:
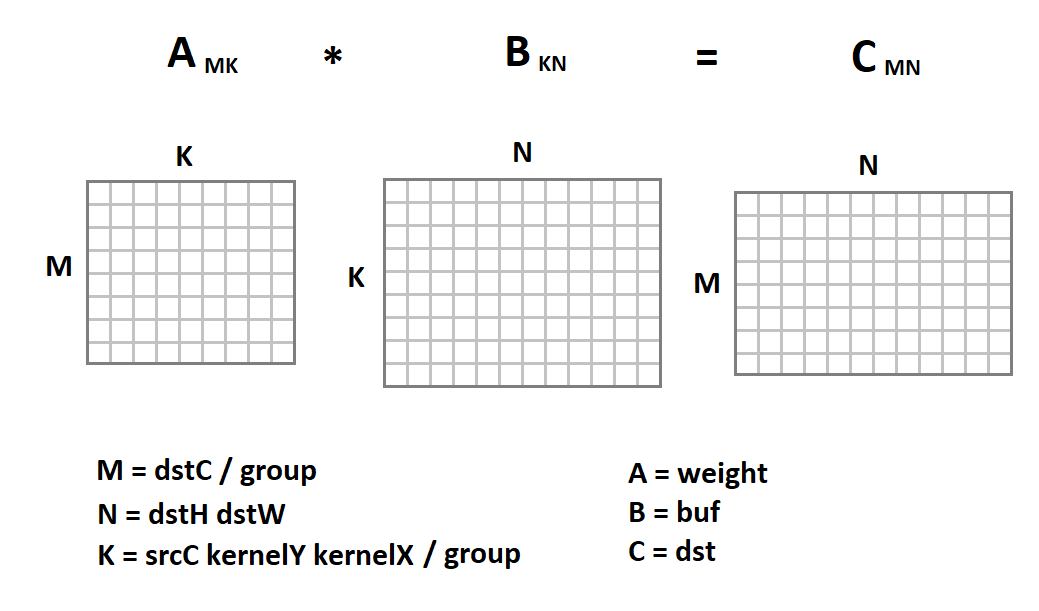
Теперь код свертки будет выглядеть следующим образом:
void gemm_nn(int M, int N, int K, float alpha, const float * A, int lda,
float beta, const float * B, int ldb, float * C, int ldc)
{
for (int i = 0; i < M; ++i)
{
for (int j = 0; j < N; ++j)
{
C[i*ldc + j] = beta;
for (int k = 0; k < K; ++k)
C[i*ldc + j] += alpha * A[i*lda + k] * B[k*ldb + j];
}
}
}
void convolution(const float * src, int batch, int srcC, int srcH, int srcW,
int kernelY, int kernelX, int dilationY, int dilationX,
int strideY, int strideX, int padY, int padX, int padH, int padW, int group,
const float * weight, const float * bias, float * dst, int dstC, float * buf)
{
int dstH = (srcH + padY + padH - (dilationY * (kernelY - 1) + 1)) / strideY + 1;
int dstW = (srcW + padX + padW - (dilationX * (kernelX - 1) + 1)) / strideX + 1;
int M = dstC / group;
int N = dstH * dstW;
int K = srcC * kernelY * kernelX / group;
for (int b = 0; b < batch; ++b)
{
im2col(src, srcC, srcH, srcW, kernelY, kernelX, dilationY, dilationY,
strideY, strideX, padY, padX, padH, padW, buf);
for (int g = 0; g < group; ++g)
gemm_nn(M, N, K, 1, weight + M * K * g, K, 0,
buf + N * K * g, N, dst + M * N * g, N));
for (int i = 0; i < M; ++i)
for (int j = 0; j < N; ++j)
dst[i*N+ j] = relu(dst[i*N + j] + bias[i]);
src += srcC*srcH*srcW;
dst += dstC*dstH*dstW;
}
}
Здесь тривиальная реализация матричного умножения приведена только в качестве примера. Мы можем заменить ее на любую другую реализацию. Благо, что матричное умножение — это давно отработанная операция, которая уже реализована во множестве библиотек с очень высокой эффективностью (до 90% от теоретически возможной производительности CPU). На тему как достигается эта эффективность у меня даже есть отдельная статья.
Использование матричного умножения для формата NHWC
Наряду с форматом NCHW, в машинном обучении часто используют формат NHWC :

Для примера отметим, что NHWC — это родной формат Tensorflow.
Примечательно, что и для этого формата операцию свертки можно также привести к матричному умножению. Для этого из формата srcH — srcW — srcC переведем исходное изображение в формат dstH — dstW — kernelY — kernelX — srcC при помощи функции im2row:
void im2row(const float * src, int srcC, int srcH, int srcW,
int kernelY, int kernelX, int dilationY, int dilationX, int strideY, int strideX,
int padY, int padX, int padH, int padW, int group, float * buf)
{
int dstH = (srcH + padY + padH - (dilationY * (kernelY - 1) + 1)) / strideY + 1;
int dstW = (srcW + padX + padW - (dilationX * (kernelX - 1) + 1)) / strideX + 1;
for (int g = 0; g < group; ++g)
{
for (int dy = 0; dy < dstH; ++dy)
{
for (int dx = 0; dx < dstW; ++dx)
{
for (int ky = 0; ky < kernelY; ky++)
{
for (int kx = 0; kx < kernelX; kx++)
{
int sy = dy * strideY + ky * dilationY - padY;
int sx = dx * strideX + kx * dilationX - padX;
for (int sc = 0; sc < srcC; ++sc)
{
if (sy >= 0 && sy < srcH && sx >= 0 && sx < srcW)
*buf++ = src[(sy * srcW + sx)*srcC + sc];
else
*buf++ = 0;
}
}
}
}
}
src += srcC / group;
}
}
При этом все точки окрестности изображения, которые требуются для операции свертки выстраиваются вдоль строк результирующей матрицы (отсюда и ее название — image to rows). Также нам следует изменить формат хранения весов свертки из формата DCYX в формат YXCD. Теперь мы можем применять матричное умножение:

В отличие от формата NCHW, мы умножаем матрицу изображения на матрицу весов, а не наоборот. Ниже приведен код функции свертки:
void convolution(const float * src, int batch, int srcC, int srcH, int srcW,
int kernelY, int kernelX, int dilationY, int dilationX,
int strideY, int strideX, int padY, int padX, int padH, int padW, int group,
const float * weight, const float * bias, float * dst, int dstC, float * buf)
{
int dstH = (srcH + padY + padH - (dilationY * (kernelY - 1) + 1)) / strideY + 1;
int dstW = (srcW + padX + padW - (dilationX * (kernelX - 1) + 1)) / strideX + 1;
int M = dstH * dstW;
int N = dstC / group;
int K = srcC * kernelY * kernelX / group;
for (int b = 0; b < batch; ++b)
{
im2row(src, srcC, srcH, srcW, kernelY, kernelX, dilationY, dilationY,
strideY, strideX, padY, padX, padH, padW, group, buf);
for (int g = 0; g < group; ++g)
gemm_nn(M, N, K, 1, buf + M * K * g, K * group, 0,
weight + N * g, dstC, dst + N * g, dstC));
for (int i = 0; i < M; ++i)
for (int j = 0; j < N; ++j)
dst[i*N+ j] = relu(dst[i*N + j] + bias[i]);
src += srcC*srcH*srcW;
dst += dstC*dstH*dstW;
}
}
Достоинства и недостатки метода
С начала хотелось бы перечислить достоинства этого подхода:
- Данный метод имеет очень простую реализацию. Не даром он применяется практически во всех известных мне библиотеках.
- Эффективность метода для многих случаев очень велика: от единиц процентов в базовой версии мы достигаем более 80% от теоретического максимума.
- Подход универсальный — у нас один код для всех возможных параметров сверточного слоя (а их не мало!). Поэтому данный метод часто работает в случаях, когда более эффективные (и потому более специализированные) подходы имеют ограничения.
- Подход работает для основных форматов тензоров изображений — NCHW и NHWC .
Теперь о недостатках:
- К сожалению стандартное матричное умножение эффективно при условии, что значениях параметров M, N, K достаточно велики и кроме того это величины приблизительно одного порядка (эффективность базируется на том обстоятельстве, что требуемое число вычислений ~O(N^3), при этом требуемая пропускная способность памяти ~O(N^2)). Поэтому, если какой-то из параметров M, N, K мал, эффективность метода резко падает.
- Метод требует преобразования входных данных. А это далеко не бесплатная операция. Ей можно принебречь только при условии достаточно большого K. А если еще учесть, что внутри стандартного матричного умножения существует еще внутренне преобразование входных данных, то ситуация становится еще печальней.
- Исходя из того, что K = srcC * kernelY * kernelX / group, эффективность метода особенно низка для входных сверточных слоев. А для depthwise convolution матричный метод вообще проигрывает тривиальной реализации.
- Метод требует дополнительной обработки выходных данных для операции сдвига и вычисления активационной функции.
- Существуют более эффективные математические методы вычисления свертки, которые требую меньшего числа операций.
Выводы
Метод вычисления свертки, основанный на матричном умножении прост в реализации, и имеет высокую эффективность. К сожалению, он не универсален. Для ряда частных случаев существуют более быстрые подходы, описание которых мне хотелось бы отложить для следующих статей данной серии. Жду отзывов и замечаний от читателей. Надеюсь, вам было интересно!
P.S. Этот и другие подходы реализованы мной в Convolution Framework в рамках библиотеки Simd.
Данный фреймворк лежит в основе лежащие в основе Synet — фреймворка для запуска предварительно обученных нейронных сетей на CPU.
DustCn
Поздравляю, вы написали как работает intel-tensorflow, а именно проводя на лету конверсию формата, используя оптимизированный кернел из MKL для перемножения и делая фьюз следущей операции relu. Все это возможно при встраивании в TF на уровне оптимизации графа операций.
ErmIg Автор
Я видел много реализаций сверточного слоя в разных библиотеках. Во многом они совпадают. Может потому, что код у всех открытый, а может люди независимо приходят к похожим вещам. Это в принципе не так важно. Я лишь хотел раскрыть для заинтересованного читателя, как это все устроено.