Мы периодически тестируем новое оборудование и ПО для использования в наших сервисах. Всегда хочется больше возможностей за разумные деньги. Сегодня расскажу, как мы разбирались в устройстве Western Digital ActiveScale P100 и пытались примерить его под наше S3-хранилище.
Сразу небольшой дисклеймер: мы тестировали продукт с точки зрения его использования в публичном сервисе. Возможно, какие-то функции, интересные и важные для приватного использования, остались за кадром.

Это ActiveScale P100 в апреле 2019 перед установкой в дата-центре OST.
Сейчас наш S3 работает на Cloudian HyperStore 7.1.5. Эта версия обеспечивает 98% совместимости с API Amazon. В нынешнем решении есть все необходимое для нас как сервис-провайдера и наших клиентов, поэтому в альтернативах мы искали никак не меньше.
На этот раз к нам в руки попало программно-аппаратное решение Western Digital ActiveScale. Вендор позиционирует его как решение для организации S3-кластера.
Вот так оно выглядит:

ActiveScale P100, установленный в одном из залов дата-центра OST.
Три верхних юнита – это управляющие ноды. Шесть следующих юнитов – ноды для хранения данных. В каждой из шести нод размещается 12 дисков по 10 Тб каждый. Итого 720 Тб «сырой» емкости. В комплекс также входит 2 сетевых устройства. На каждую ноду – 2 линка по 10G. Итого данное решение занимает в стойке 11 юнитов.
Мы прогнали ActiveScale через нагрузочные тесты: скриптом генерировали разное количество файлов разного размера, пробовали заливать их в однопоточном и многопоточном режиме и фиксировали время выполнения команд на заливку и удаление файлов. Этот тест был искусственным: проводился с компьютера с SSD-диском, большим объемом памяти и процессором с частотой 3,2 ГГц, с ограниченной шириной канала в 100 Мб/сек. Тем не менее, у нас есть результаты аналогичного теста для текущего решения, и полученные показатели были более чем в пределах наших ожиданий.
Результаты нагрузочного теста.
*При удалении объект только помечается на удаление. Само удаление происходит один раз в сутки. Когда кластер будет почти заполнен, это может усложнить capacity management, так как нет актуальной информации о занятых ресурсах.
Совместимость с Amazon S3 тестировали стандартными способами. Вот один из тестов, который я использовал.
На момент тестирования у нас была самая базовая документация, поэтому с устройством этого “черного ящика” мы разбирались самостоятельно – через админский веб-интерфейс, API и физический доступ.
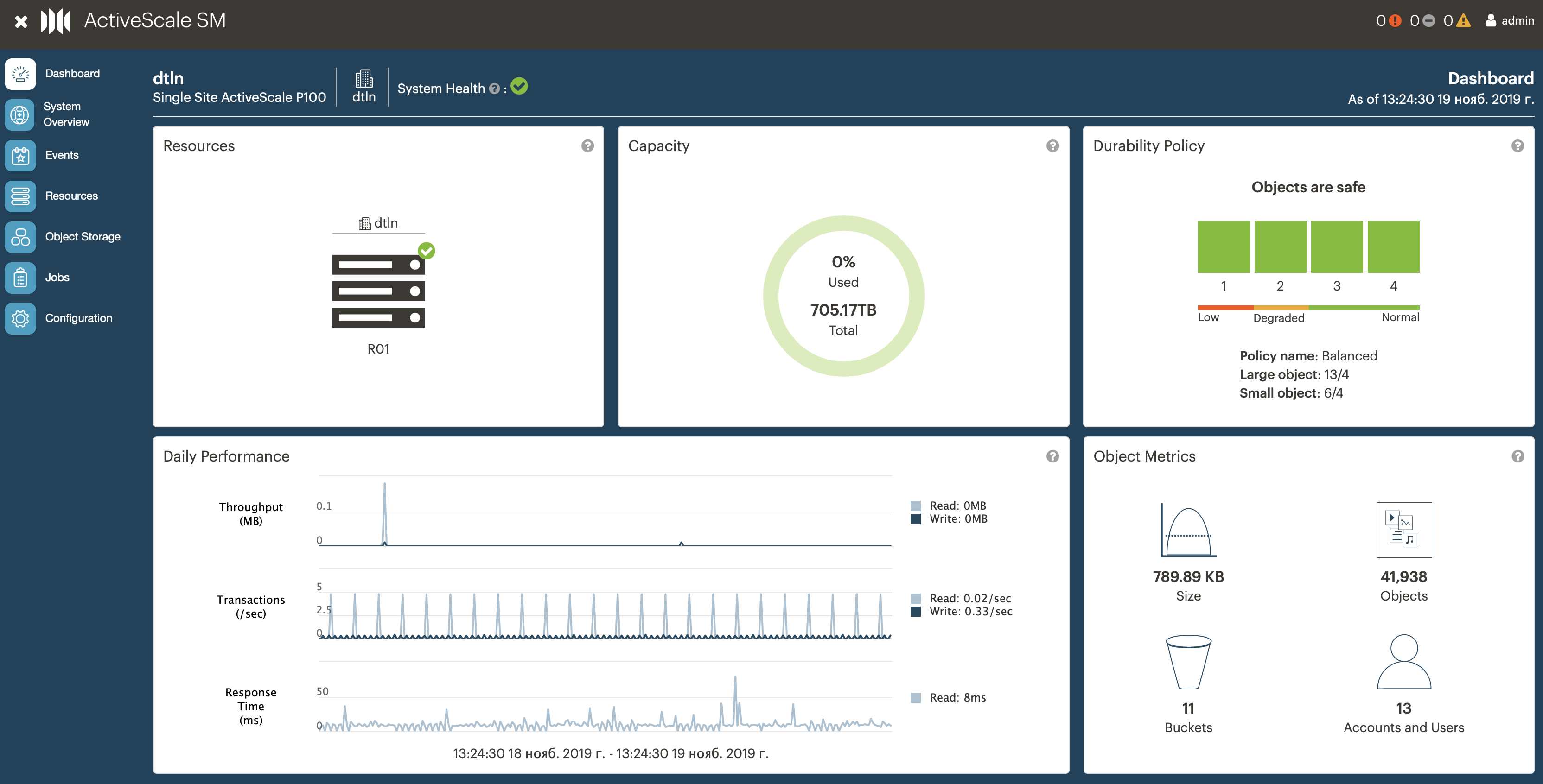
Админский интерфейс. На главной странице сводная информация по размерам и рабочим метрикам кластера, статистика по объектам, пользователям, бакетам, политикам хранения.
Пользовательский интерфейс. В сервисе S3 он нужен, чтобы администратор на стороне клиента мог добавлять/удалять пользователей, генерировать для них ключи доступа, квотировать пользователей и пр. У P100 его нет, но после нашего фидбэка вендор планирует это внедрить.
Управление пользователями/ролями. Для организации публичного сервиса нам нужна возможность создавать пользователей с различными правами доступа. У P100 в этом плане существенные ограничения:
Биллинг. В P100 из коробки его нет, и это самый большой недостаток для нас как сервис-провайдера. У нас коммерческий продукт, и нам нужно как-то выставлять счета клиентам. В P100 есть логи статистики, которые можно снимать каждый час через админскую панель. Теоретически их можно распарсить, вытащить необходимые данные и сделать расчет по ним. Но эти логи хранятся всего 30 суток. Что делать в ситуациях, когда в месяце 31 день или клиент просит перепроверить счет за предыдущие месяцы, непонятно.
Настройка собственных правил хранения объектов. К нам P100 уже приехал со следующими настройками: файлы меньше чанка (20 Кб) хранятся в режиме erasure code (EC) 6+2. Файлы больше чанка хранятся в режиме EC 13+4. P100 сам определяет размер файла и выбирает подходящий режим.
С одной стороны, у P100 больше возможностей в настройках. С другой, все настройки по правилам хранения для фактора репликации и erasure code возможны только на этапе развертывания кластера. Позднее, во время эксплуатации, добавить новые правила хранения данных или изменить существующие уже нельзя. При расширении кластера это нужно сделать, чтобы эффективность и надежность хранения была оптимальной.
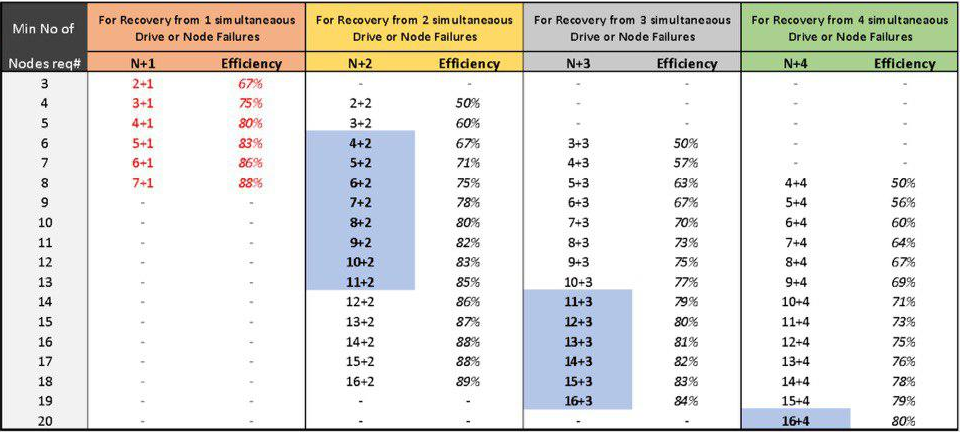
Таблица эффективности хранения в режиме Erasure Code.
Собственный CLI\AdminAPI. Для управления кластером у P100 есть CLI, но написан и протестирован он только для Ubuntu (мы используем Red Hat). Существенных преимуществ перед взаимодействием через curl-запросы (put, get, post) не дает, но есть некоторые особенности по управлению кластером.
Поддержка базового AWS S3 API и AWS CLI. Это как раз показатель про совместимость с Amazon API. Проще говоря, можно ли использовать команды для S3 Amazon в данном решении. По опыту, в среднем этот показатель варьируется где-то в пределах 50–70%.
У P100 по результатам теста получилось 58%. Не получилось сделать тесты на совместимость по назначению прав доступа на отдельные объекты, так как в решении P100 можно назначить общий доступ только на бакет, а не на отдельный объект. Также нет IAM (Identity and Access Management). В итоге совместимость скорее ближе к 50%.

Из результатов теста.
Управление ОС. По спецификации значится ActiveScale OS 5.x По логам и папкам, доступным через веб-интерфейс, выяснил, что в ее основе скорее всего Debian-дистрибутив. При тестировании не удалось найти способы для самостоятельного управления обновлениями, как устанавливать критические обновления безопасности, своих агентов мониторинга и прочее. Однозначно надо обращаться в техподдержку P100 с выездом специально обученного человека.
Количество бакетов на пользователя. В подобных сервисах обычно пользователь может создавать до 100 бакетов, своего рода “папок” для хранения файлов. В общем случае этого достаточно, но практика показывает, что бакетов много не бывает. В P100 100 бакетов – это максимум. В нынешнем нашем решении пользователь может создать 1000 бакетов.
Настройка прав доступа к бакетам и объектам. В P100 можно давать доступы на конкретный бакет, а вот на конкретный объект нет. Последнее часто используется пользователями, поскольку позволяет установить на объект ограничения по количеству скачиваний и времени, когда его можно скачать.
Статистика по кластеру/пользователям/бакетам. Эта информация нужна нам, чтобы отслеживать заполняемость кластера и не пропустить момент, когда мы подберемся к потолку по ресурсам.
В интерфейсе можно посмотреть почти real-time статистику по пользователям и бакетам (информация обновляется раз в час).
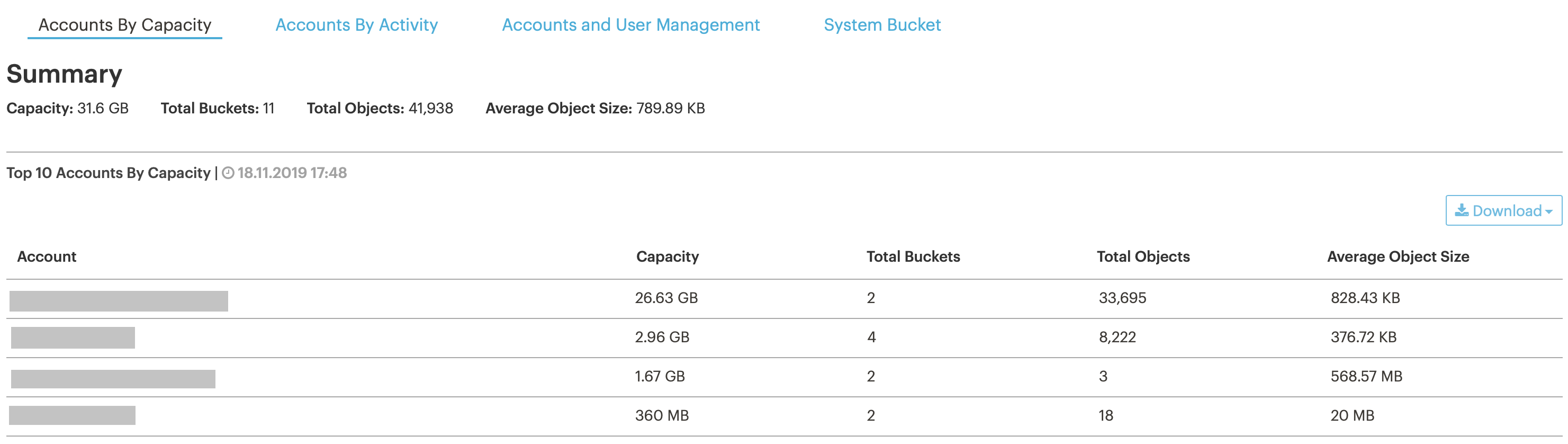
Его можно скачать через специальный системный бакет, но в скачанном виде вместо email или имен пользователей будет UUID, так что нужно как-то еще сопоставить, что за пользователь скрывается за конкретными UUID. Это не проблема, если пользователей 10, а если больше?
Самодиагностика. P100 умеет опрашивать по SNMP всю железную часть, входящую в кластер, и выводить ее на дашборд. Например, можно посмотреть заполненность и температуру дисков, использование памяти и пр.
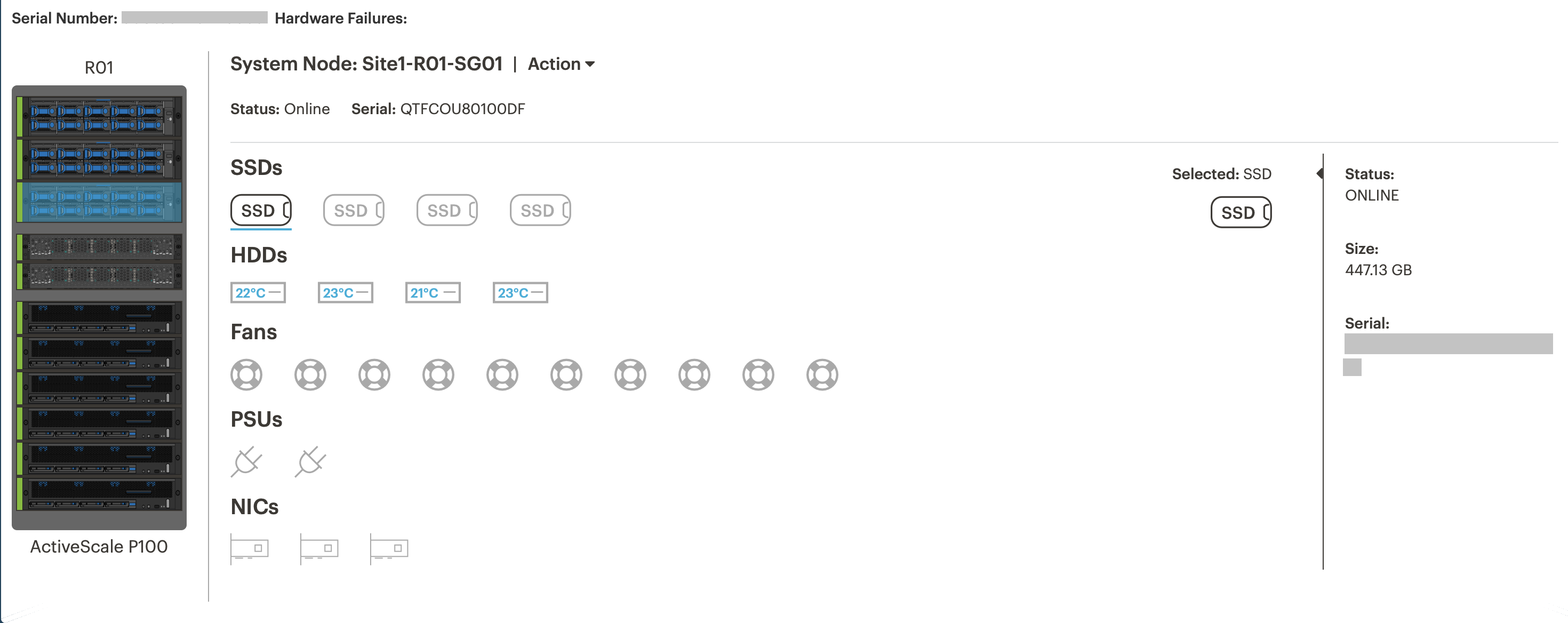
Информация о состоянии системной ноды.
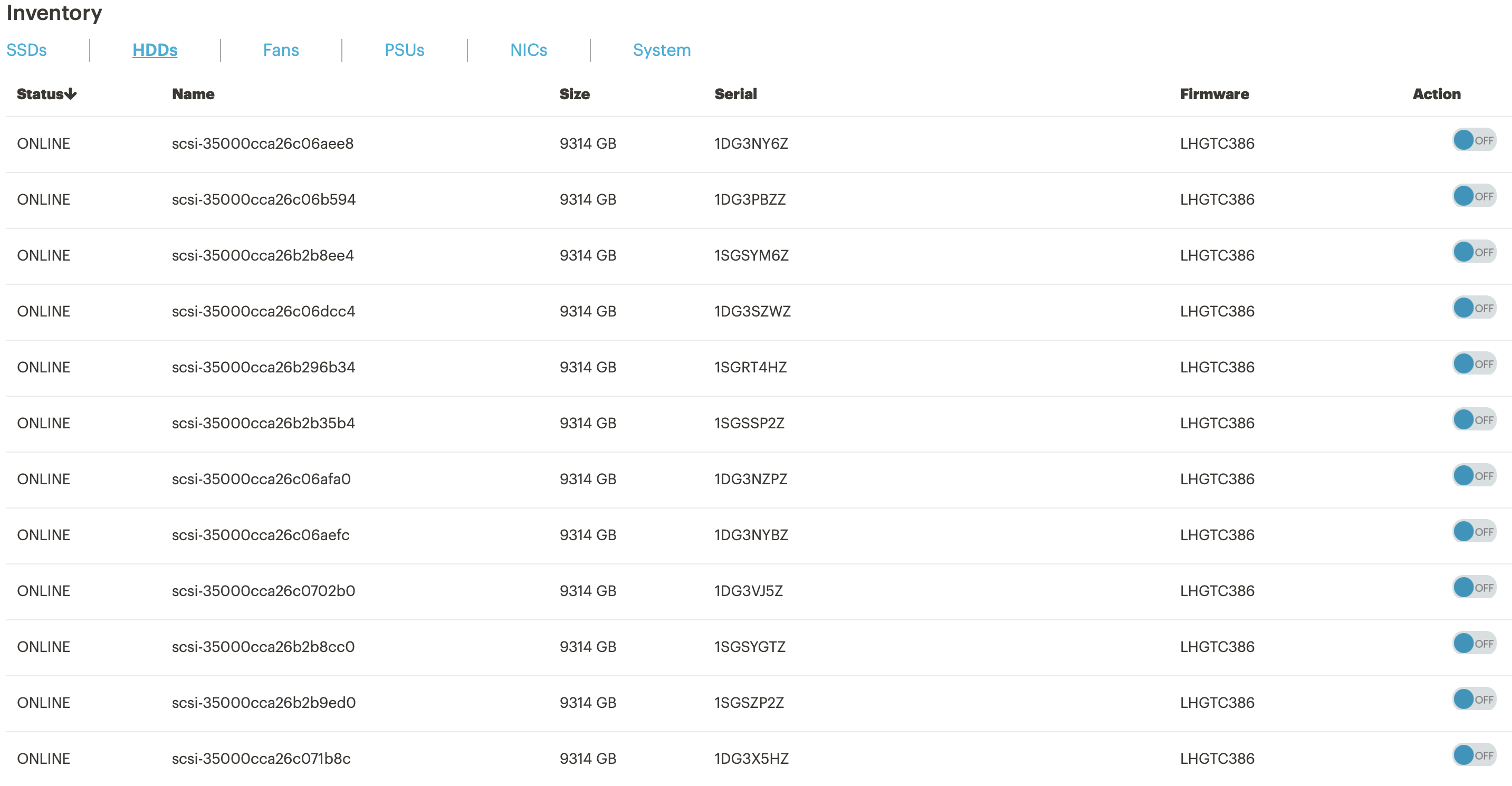
Информация о состоянии дисков. При выходе диска из строя можно включить подсветку, чтобы быстро найти и заменить.
Параметры по загрузке CPU и памяти в кластере.
Логирование действий пользователя. Его нет, а значит разбираться в ситуациях “кто удалил файл и удалил ли” будет непросто.
Поддержка SSE/SSE-C. P100 поддерживает шифрование, но с ограничениями: необходимо запрашивать отдельный лицензионный ключ, а это дополнительные деньги.
Балансировщик нагрузки. Он встроенный, предположительно стоит HAProxy. Настраивать нужно по минимуму: просто указываем входящий и исходящий IP-адреса.
Автоматизация процессов ввода/вывода нод или дисков на нодах. Помогает, когда в кластере ломается нода и ее нужно вывести из эксплуатации. Сейчас для таких ситуаций у нас есть готовое решение. В P100 такого механизма я не нашел, можно только отключить отдельную ноду через админский веб-интерфейс. Скорее всего, придется приглашать инженера от вендора.
S3 Gate Appliance. Это программное решение позволяет развернуть на стороне клиента ftp/nfs/samba-gate и скидывать туда файлы, которые должны попасть в S3. Удобная вещь, если конечный пользователь не умеет пользоваться S3. Такого, к сожалению, на борту у P100 нет.
Рабочие порты приложений. В P100 доступны только стандартные для S3 порты – 80, 443.
Пользовательская документация. Есть только документация по API.
Административная документация. Предоставляется вендором по запросу.
Множественные endpoint’ы. У нас приехала готовая инсталляция, где уже был настроен только один endpoint на кластер. Поменять не получилось.
Георезервирование. Эта опция дает возможность реплицировать данные на трех площадках и переключать клиентов на резервные площадки. У нас был только один кластер, поэтому протестировать не было возможности.
Интеграция с AD. Заявлена, но мы не используем AD применительно к S3, поэтому не тестили.
В целом WD ActiveScale P100 оставил положительные впечатления: работает “из коробки”, быстро и стоит при этом очень даже приемлемо. И тем не менее, это частное решение, которое пока нельзя использовать для построения публичного сервиса S3. Вот главное, чего нам не хватило:
Все пожелания по итогам тестирования вендор принял. Возможно в ближайшее время что-то из них будет реализовано.
Сразу небольшой дисклеймер: мы тестировали продукт с точки зрения его использования в публичном сервисе. Возможно, какие-то функции, интересные и важные для приватного использования, остались за кадром.
Это ActiveScale P100 в апреле 2019 перед установкой в дата-центре OST.
Сейчас наш S3 работает на Cloudian HyperStore 7.1.5. Эта версия обеспечивает 98% совместимости с API Amazon. В нынешнем решении есть все необходимое для нас как сервис-провайдера и наших клиентов, поэтому в альтернативах мы искали никак не меньше.
На этот раз к нам в руки попало программно-аппаратное решение Western Digital ActiveScale. Вендор позиционирует его как решение для организации S3-кластера.
Вот так оно выглядит:
ActiveScale P100, установленный в одном из залов дата-центра OST.
Три верхних юнита – это управляющие ноды. Шесть следующих юнитов – ноды для хранения данных. В каждой из шести нод размещается 12 дисков по 10 Тб каждый. Итого 720 Тб «сырой» емкости. В комплекс также входит 2 сетевых устройства. На каждую ноду – 2 линка по 10G. Итого данное решение занимает в стойке 11 юнитов.
Мы прогнали ActiveScale через нагрузочные тесты: скриптом генерировали разное количество файлов разного размера, пробовали заливать их в однопоточном и многопоточном режиме и фиксировали время выполнения команд на заливку и удаление файлов. Этот тест был искусственным: проводился с компьютера с SSD-диском, большим объемом памяти и процессором с частотой 3,2 ГГц, с ограниченной шириной канала в 100 Мб/сек. Тем не менее, у нас есть результаты аналогичного теста для текущего решения, и полученные показатели были более чем в пределах наших ожиданий.
| Тест |
Размер объекта |
Кол-во объектов |
Кол-во потоков |
Средняя скорость |
Время загрузки |
Время удаления* |
| 1 |
10 Кб |
100 000 |
1 |
104 Кбайт/с |
2 ч 40 м |
6 м 58 с |
| 2 |
10 Кб |
100 000 |
20 |
11 Мбайт/с |
35 м 4 с |
11 м 38 с |
| 3 |
1 Мб |
100 000 |
1 |
5 Мбайт/с |
5 ч 55 м |
7 м 16 с |
| 4 |
1 Мб |
100 000 |
20 |
11 Мбайт/с |
2 ч 31 мин |
7 м 26 с |
| 5 |
10 Гб |
1 |
1 |
10 Мбайт/с |
16 м 5 с |
3 с |
| 6 |
10 Гб |
1 |
20 |
10 Мбайт/с |
16 м 2 с |
3 с |
*При удалении объект только помечается на удаление. Само удаление происходит один раз в сутки. Когда кластер будет почти заполнен, это может усложнить capacity management, так как нет актуальной информации о занятых ресурсах.
Совместимость с Amazon S3 тестировали стандартными способами. Вот один из тестов, который я использовал.
На момент тестирования у нас была самая базовая документация, поэтому с устройством этого “черного ящика” мы разбирались самостоятельно – через админский веб-интерфейс, API и физический доступ.
Что нашли внутри
Админский интерфейс. На главной странице сводная информация по размерам и рабочим метрикам кластера, статистика по объектам, пользователям, бакетам, политикам хранения.
Пользовательский интерфейс. В сервисе S3 он нужен, чтобы администратор на стороне клиента мог добавлять/удалять пользователей, генерировать для них ключи доступа, квотировать пользователей и пр. У P100 его нет, но после нашего фидбэка вендор планирует это внедрить.
Управление пользователями/ролями. Для организации публичного сервиса нам нужна возможность создавать пользователей с различными правами доступа. У P100 в этом плане существенные ограничения:
- можно создать только одного системного пользователя, т. е. администратора кластера. Больше – только через интеграцию с Active Directory.
- пользователей нельзя объединить в группы и назначить им администратора. Собственно, это делает для нас невозможным предоставлять публичный сервис.
- пользователя нельзя удалить окончательно, поэтому если новый пользователь будет с таким же логином, то придется проявить изобретательность.
- настройка квот для пользователей (объем, количество транзакций и пр.) возможна только через CLI.
Биллинг. В P100 из коробки его нет, и это самый большой недостаток для нас как сервис-провайдера. У нас коммерческий продукт, и нам нужно как-то выставлять счета клиентам. В P100 есть логи статистики, которые можно снимать каждый час через админскую панель. Теоретически их можно распарсить, вытащить необходимые данные и сделать расчет по ним. Но эти логи хранятся всего 30 суток. Что делать в ситуациях, когда в месяце 31 день или клиент просит перепроверить счет за предыдущие месяцы, непонятно.
Настройка собственных правил хранения объектов. К нам P100 уже приехал со следующими настройками: файлы меньше чанка (20 Кб) хранятся в режиме erasure code (EC) 6+2. Файлы больше чанка хранятся в режиме EC 13+4. P100 сам определяет размер файла и выбирает подходящий режим.
С одной стороны, у P100 больше возможностей в настройках. С другой, все настройки по правилам хранения для фактора репликации и erasure code возможны только на этапе развертывания кластера. Позднее, во время эксплуатации, добавить новые правила хранения данных или изменить существующие уже нельзя. При расширении кластера это нужно сделать, чтобы эффективность и надежность хранения была оптимальной.
Таблица эффективности хранения в режиме Erasure Code.
Собственный CLI\AdminAPI. Для управления кластером у P100 есть CLI, но написан и протестирован он только для Ubuntu (мы используем Red Hat). Существенных преимуществ перед взаимодействием через curl-запросы (put, get, post) не дает, но есть некоторые особенности по управлению кластером.
Поддержка базового AWS S3 API и AWS CLI. Это как раз показатель про совместимость с Amazon API. Проще говоря, можно ли использовать команды для S3 Amazon в данном решении. По опыту, в среднем этот показатель варьируется где-то в пределах 50–70%.
У P100 по результатам теста получилось 58%. Не получилось сделать тесты на совместимость по назначению прав доступа на отдельные объекты, так как в решении P100 можно назначить общий доступ только на бакет, а не на отдельный объект. Также нет IAM (Identity and Access Management). В итоге совместимость скорее ближе к 50%.
Из результатов теста.
Управление ОС. По спецификации значится ActiveScale OS 5.x По логам и папкам, доступным через веб-интерфейс, выяснил, что в ее основе скорее всего Debian-дистрибутив. При тестировании не удалось найти способы для самостоятельного управления обновлениями, как устанавливать критические обновления безопасности, своих агентов мониторинга и прочее. Однозначно надо обращаться в техподдержку P100 с выездом специально обученного человека.
Количество бакетов на пользователя. В подобных сервисах обычно пользователь может создавать до 100 бакетов, своего рода “папок” для хранения файлов. В общем случае этого достаточно, но практика показывает, что бакетов много не бывает. В P100 100 бакетов – это максимум. В нынешнем нашем решении пользователь может создать 1000 бакетов.
Настройка прав доступа к бакетам и объектам. В P100 можно давать доступы на конкретный бакет, а вот на конкретный объект нет. Последнее часто используется пользователями, поскольку позволяет установить на объект ограничения по количеству скачиваний и времени, когда его можно скачать.
Статистика по кластеру/пользователям/бакетам. Эта информация нужна нам, чтобы отслеживать заполняемость кластера и не пропустить момент, когда мы подберемся к потолку по ресурсам.
В интерфейсе можно посмотреть почти real-time статистику по пользователям и бакетам (информация обновляется раз в час).
Его можно скачать через специальный системный бакет, но в скачанном виде вместо email или имен пользователей будет UUID, так что нужно как-то еще сопоставить, что за пользователь скрывается за конкретными UUID. Это не проблема, если пользователей 10, а если больше?
Самодиагностика. P100 умеет опрашивать по SNMP всю железную часть, входящую в кластер, и выводить ее на дашборд. Например, можно посмотреть заполненность и температуру дисков, использование памяти и пр.
Информация о состоянии системной ноды.
Информация о состоянии дисков. При выходе диска из строя можно включить подсветку, чтобы быстро найти и заменить.
Параметры по загрузке CPU и памяти в кластере.
Логирование действий пользователя. Его нет, а значит разбираться в ситуациях “кто удалил файл и удалил ли” будет непросто.
Поддержка SSE/SSE-C. P100 поддерживает шифрование, но с ограничениями: необходимо запрашивать отдельный лицензионный ключ, а это дополнительные деньги.
Балансировщик нагрузки. Он встроенный, предположительно стоит HAProxy. Настраивать нужно по минимуму: просто указываем входящий и исходящий IP-адреса.
Автоматизация процессов ввода/вывода нод или дисков на нодах. Помогает, когда в кластере ломается нода и ее нужно вывести из эксплуатации. Сейчас для таких ситуаций у нас есть готовое решение. В P100 такого механизма я не нашел, можно только отключить отдельную ноду через админский веб-интерфейс. Скорее всего, придется приглашать инженера от вендора.
S3 Gate Appliance. Это программное решение позволяет развернуть на стороне клиента ftp/nfs/samba-gate и скидывать туда файлы, которые должны попасть в S3. Удобная вещь, если конечный пользователь не умеет пользоваться S3. Такого, к сожалению, на борту у P100 нет.
Рабочие порты приложений. В P100 доступны только стандартные для S3 порты – 80, 443.
Пользовательская документация. Есть только документация по API.
Административная документация. Предоставляется вендором по запросу.
Не тестили, но заявлено вендором
Множественные endpoint’ы. У нас приехала готовая инсталляция, где уже был настроен только один endpoint на кластер. Поменять не получилось.
Георезервирование. Эта опция дает возможность реплицировать данные на трех площадках и переключать клиентов на резервные площадки. У нас был только один кластер, поэтому протестировать не было возможности.
Интеграция с AD. Заявлена, но мы не используем AD применительно к S3, поэтому не тестили.
Выводы
В целом WD ActiveScale P100 оставил положительные впечатления: работает “из коробки”, быстро и стоит при этом очень даже приемлемо. И тем не менее, это частное решение, которое пока нельзя использовать для построения публичного сервиса S3. Вот главное, чего нам не хватило:
- нет возможности создавать группы пользователей и задавать для них администратора;
- нет графического пользовательского интерфейса;
- нет биллинга;
- включение дополнительных функций только через обращение к вендору;
- невозможность в рамках одного кластера держать разные политики хранения и назначать их для разных групп пользователей в зависимости от текущих задач.
Все пожелания по итогам тестирования вендор принял. Возможно в ближайшее время что-то из них будет реализовано.