Пару лет назад я написал очень простую реализацию фрактального сжатия изображений для студенческой работы и выложил код на github.
К моему удивлению, репозиторий оказался довольно популярным, поэтому я решил обновить код и написать статью, объясняющую его и теорию.
Теория
Эта часть довольно теоретическая, и если вас интересует только документация к коду, можете её пропустить.
Сжимающие отображения
Пусть — полное метрическое пространство, а — отображение из на .
Мы говорим, что является сжимающим отображением, если существует , такое, что:
Исходя из этого, будет обозначать сжимающее отображение с коэффициентом сжимания .
О сжимающих отображениях существует две важные теоремы: теорема Банаха о неподвижной точке и теорема коллажа.
Теорема о неподвижной точке: имеет уникальную неподвижную точку .
Показать доказательство
Сначала докажем, что последовательность , заданная как является сходящейся для всех .
Для всех :
Следовательно, является последовательностью Коши, и является полным пространством, а значит, является сходящейся. Пусть её пределом будет .
Более того, поскольку сжимающее отображение является непрерывным как липшицево отображение, оно также является непрерывным, то есть . Следовательно, если стремится к бесконечности в , мы получаем . То есть является неподвижной точкой .
Мы показали, что имеет неподвижную точку. Давайте при помощи противоречия покажем, что она уникальна. Пусть — ещё одна неподвижная точка. Тогда:
Возникло противоречие.
Для всех :
Следовательно, является последовательностью Коши, и является полным пространством, а значит, является сходящейся. Пусть её пределом будет .
Более того, поскольку сжимающее отображение является непрерывным как липшицево отображение, оно также является непрерывным, то есть . Следовательно, если стремится к бесконечности в , мы получаем . То есть является неподвижной точкой .
Мы показали, что имеет неподвижную точку. Давайте при помощи противоречия покажем, что она уникальна. Пусть — ещё одна неподвижная точка. Тогда:
Возникло противоречие.
Далее мы будем обозначать как неподвижную точку .
Теорема коллажа: если , то .
Показать доказательство
В предыдущем доказательстве мы показали, что .
Если мы зафиксируем в , то получим .
При стремлении к бесконечности мы получим требуемый результат.
Если мы зафиксируем в , то получим .
При стремлении к бесконечности мы получим требуемый результат.
Вторая теорема говорит нам, что если мы найдём сжимающее отображение , такое, что близко к , то можем быть уверенными, что неподвижная точка тоже находится близко к .
Этот результат будет фундаментом для нашей дальнейшей работы. И в самом деле, вместо сохранения изображения нам достаточно сохранить сжимающее отображение, неподвижная точка которого близка к изображению.
Сжимающие отображения для изображений
В этой части я покажу, как создавать такие сжимающие отображения, чтобы неподвижная точка находилась близко к изображению.
Сначала давайте зададим множество изображения и расстояние. Мы выберем . — это множество матриц с строками, столбцами и с коэффициентами в интервале . Затем мы возьмём . — это расстояние, полученное из нормы Фробениуса.
Пусть — это изображение, которое мы хотим сжать.
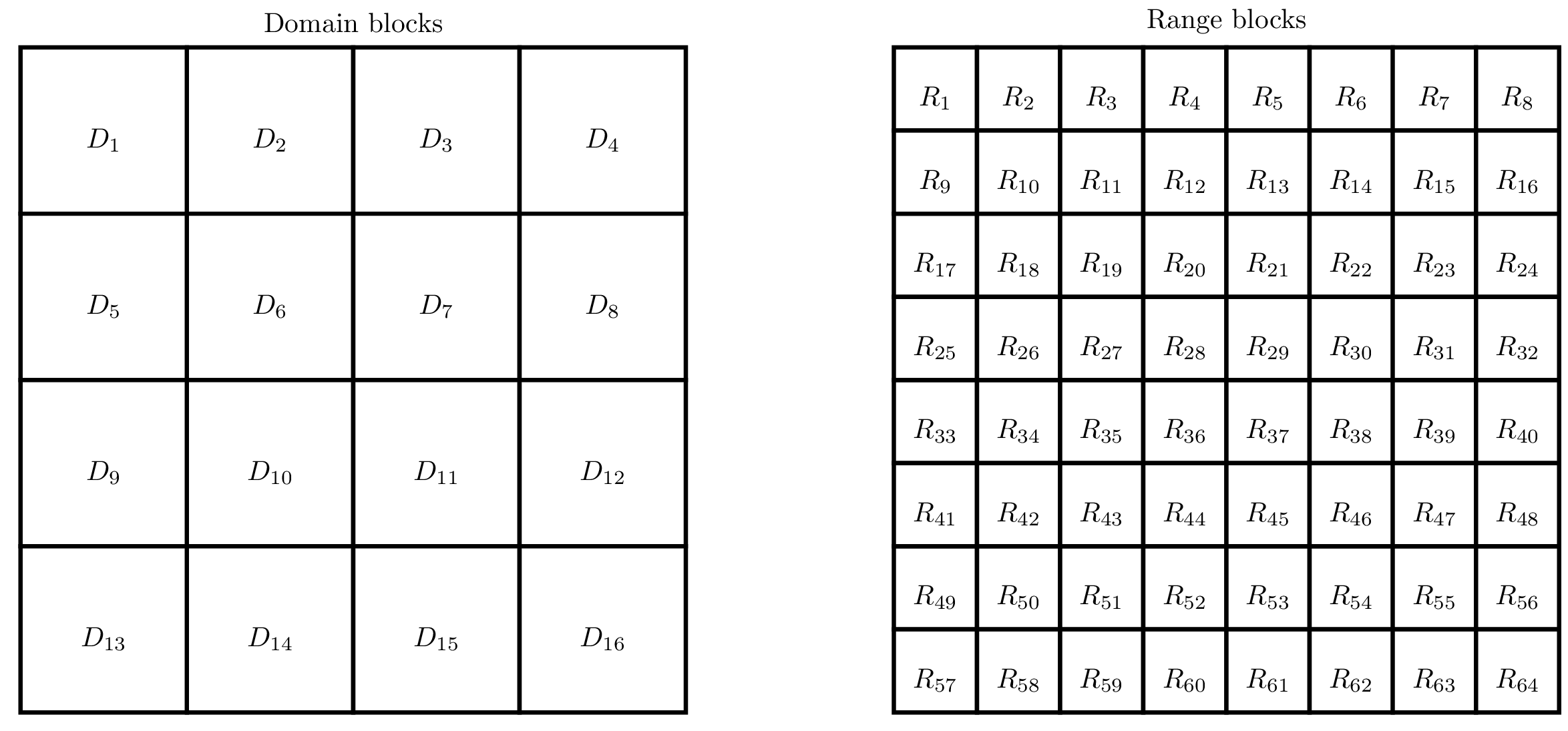
Мы дважды разделим изображение на блоки:
- Сначала мы разделим изображение на конечные или интервальные блоки . Эти блоки разделены и покрывают изображение целиком.
- Затем мы разделяем изображение на блоки источников или доменов . Эти блоки необязательно разделены и необязательно покрывают всё изображение.
Например, мы можем сегментировать изображение следующим образом:
Затем для каждого блока интервала мы выбираем блок домена и отображение .
Далее мы можем определить функцию как:
Утверждение: если являются сжимающими отображениями, то и тоже сжимающее отображение.
Показать доказательство
Пусть и предположим, что все являются сжимающими отображениями с коэффициентом сжимания . Тогда получаем следующее:
Остаётся один вопрос, на который нужно ответить: как выбрать и ?
Теорема коллажа предлагает способ их выбора: если находится близко к для всех , то находится близко к и по теореме коллажа и тоже находятся близко.
Таким образом мы независимо для каждого можем построить множество сжимающих отображений из каждого на и выбрать наилучшее. В следующем разделе мы покажем все подробности этой операции.
Реализация
В каждый раздел я буду копировать интересные фрагменты кода, а весь скрипт можно найти здесь.
Разбиения
Я выбрал очень простой подход. Блоки источников и конечные блоки сегментируют изображение по сетке, как показано на изображении выше.
Размер блоков равен степеням двойки и это очень упрощает работу. Блоки источников имеют размер 8 на 8, а конечные блоки — 4 на 4.
Существуют и более сложные схемы разбиения. Например, мы можем использовать дерево квадрантов (quadtree), чтобы сильнее разбивать области с большим количеством деталей.
Преобразования
В этом разделе я покажу, как создавать сжимающие отображения из на .
Помните, что мы хотим сгенерировать такое отображение , чтобы было близко к . То есть чем больше отображений мы сгенерируем, тем больше вероятность найти хорошее.
Однако качество сжатия зависит от количества битов, необходимых для сохранения . То есть если множество функций будет слишком большим, то сжатие окажется плохим. Здесь нужно искать компромисс.
Я решил, что будет иметь следующий вид:
где — это функция для перехода от блоков 8 на 8 к блокам 4 на 4, и — аффинные преобразования, изменяет контрастность, а — яркость.
Функция
reduce снижает размер изображения, усредняя окрестности:def reduce(img, factor):
result = np.zeros((img.shape[0] // factor, img.shape[1] // factor))
for i in range(result.shape[0]):
for j in range(result.shape[1]):
result[i,j] = np.mean(img[i*factor:(i+1)*factor,j*factor:(j+1)*factor])
return resultФункция
rotate поворачивает изображение на заданный угол:def rotate(img, angle):
return ndimage.rotate(img, angle, reshape=False)Для сохранения формы изображения угол может принимать только значения .
Функция
flip отражает изображение зеркально, если direction равно -1 и не отражает, если значение равно 1:def flip(img, direction):
return img[::direction,:]Полное преобразование выполняется функцией
apply_transformation:def apply_transformation(img, direction, angle, contrast=1.0, brightness=0.0):
return contrast*rotate(flip(img, direction), angle) + brightnessНам нужен 1 бит, чтобы запомнить, требуется ли зеркальное отражение, и 2 бита для угла поворота. Более того, если мы сохраним и , использовав по 8 бит на каждую величину, то для сохранения преобразования нам в целом понадобится всего 11 битов.
Кроме того, нам следует проверять, являются ли эти функции сжимающими отображениями. Доказательство этого немного скучно, и не особо нам нужно. Возможно, позже я добавлю его как приложение к статье.
Сжатие
Алгоритм сжатия прост. Сначала мы генерируем все возможные аффинные преобразования всех блоков источников при помощи функции
generate_all_transformed_blocks:def generate_all_transformed_blocks(img, source_size, destination_size, step):
factor = source_size // destination_size
transformed_blocks = []
for k in range((img.shape[0] - source_size) // step + 1):
for l in range((img.shape[1] - source_size) // step + 1):
# Extract the source block and reduce it to the shape of a destination block
S = reduce(img[k*step:k*step+source_size,l*step:l*step+source_size], factor)
# Generate all possible transformed blocks
for direction, angle in candidates:
transformed_blocks.append((k, l, direction, angle, apply_transform(S, direction, angle)))
return transformed_blocksЗатем для каждого конечного блока мы проверяем все ранее сгенерированные преобразованные блоки источников. Для каждого мы оптимизируем контрастность и яркость с помощью метода
find_contrast_and_brightness2, и если протестированное преобразование наилучшее из всех пока найденных, то сохраняем его:def compress(img, source_size, destination_size, step):
transformations = []
transformed_blocks = generate_all_transformed_blocks(img, source_size, destination_size, step)
for i in range(img.shape[0] // destination_size):
transformations.append([])
for j in range(img.shape[1] // destination_size):
print(i, j)
transformations[i].append(None)
min_d = float('inf')
# Extract the destination block
D = img[i*destination_size:(i+1)*destination_size,j*destination_size:(j+1)*destination_size]
# Test all possible transformations and take the best one
for k, l, direction, angle, S in transformed_blocks:
contrast, brightness = find_contrast_and_brightness2(D, S)
S = contrast*S + brightness
d = np.sum(np.square(D - S))
if d < min_d:
min_d = d
transformations[i][j] = (k, l, direction, angle, contrast, brightness)
return transformationsДля нахождения наилучшей контрастности и яркости метод
find_contrast_and_brightness2 просто решает задачу наименьших квадратов:def find_contrast_and_brightness2(D, S):
# Fit the contrast and the brightness
A = np.concatenate((np.ones((S.size, 1)), np.reshape(S, (S.size, 1))), axis=1)
b = np.reshape(D, (D.size,))
x, _, _, _ = np.linalg.lstsq(A, b)
return x[1], x[0]Распаковка
Алгоритм распаковки ещё проще. Мы начинаем с полностью случайного изображения, а затем несколько раз применяем сжимающее отображение :
def decompress(transformations, source_size, destination_size, step, nb_iter=8):
factor = source_size // destination_size
height = len(transformations) * destination_size
width = len(transformations[0]) * destination_size
iterations = [np.random.randint(0, 256, (height, width))]
cur_img = np.zeros((height, width))
for i_iter in range(nb_iter):
print(i_iter)
for i in range(len(transformations)):
for j in range(len(transformations[i])):
# Apply transform
k, l, flip, angle, contrast, brightness = transformations[i][j]
S = reduce(iterations[-1][k*step:k*step+source_size,l*step:l*step+source_size], factor)
D = apply_transformation(S, flip, angle, contrast, brightness)
cur_img[i*destination_size:(i+1)*destination_size,j*destination_size:(j+1)*destination_size] = D
iterations.append(cur_img)
cur_img = np.zeros((height, width))
return iterationsЭтот алгоритм срабатывает, потому что сжимающее отображение имеет уникальную неподвижную точку, и какое бы исходное изображение мы ни выбрали, мы будем стремиться к нему.
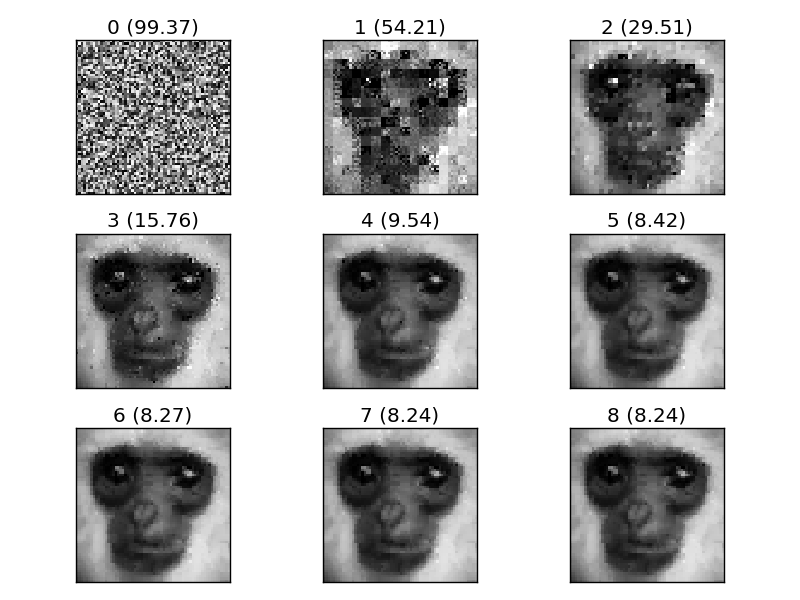
Думаю, настало время для небольшого примера. Я попробую сжать и распаковать изображение обезьяны:

Функция
test_greyscale загружает изображение, сжимает его, распаковывает и показывает каждую итерацию распаковки:Совсем неплохо для такой простой реализации!
RGB-изображения
Очень наивный подход к сжатию RGB-изображений заключается в сжатии всех трёх каналов по отдельности:
def compress_rgb(img, source_size, destination_size, step):
img_r, img_g, img_b = extract_rgb(img)
return [compress(img_r, source_size, destination_size, step), compress(img_g, source_size, destination_size, step), compress(img_b, source_size, destination_size, step)]А для распаковки мы просто распаковываем по отдельности данные трёх каналов и собираем их в три канала изображения:
def decompress_rgb(transformations, source_size, destination_size, step, nb_iter=8):
img_r = decompress(transformations[0], source_size, destination_size, step, nb_iter)[-1]
img_g = decompress(transformations[1], source_size, destination_size, step, nb_iter)[-1]
img_b = decompress(transformations[2], source_size, destination_size, step, nb_iter)[-1]
return assemble_rbg(img_r, img_g, img_b)Ещё одно очень простое решение заключается в использовании для всех трёх каналов одинакового сжимающего отображения, потому что часто они очень похожи.
Если хотите проверить, как это работает, то запустите функцию
test_rgb: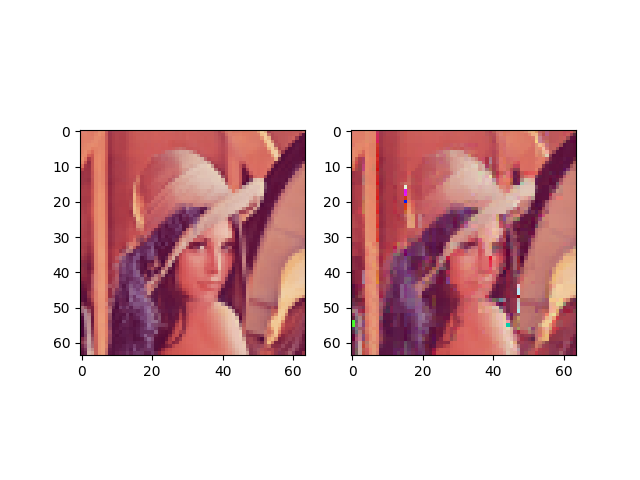
Появились артефакты. Вероятно, этот метод слишком наивен для создания хороших результатов.
Куда двигаться дальше
Если вы хотите больше узнать о фрактальном сжатии изображений, то могу порекомендовать вам прочитать статью Fractal and Wavelet Image Compression Techniques Стивена Уэлстеда. Её легко читать и в ней объяснены более сложные техники.
Комментарии (5)


PrinceKorwin
11.12.2019 12:25В своё студенческое время тоже делал похожий архиватор, но упёрся в то, что всё это закопирайчено и огорождено. Хотя было очень интересно и познавательно, да.
Интересно. Сейчас архивация на основе фрактального сжатия всё также закрыта патентами или можно таки что-то OpenSource соорудить?

Cerberuser
11.12.2019 14:38В тред призывается 3DVideo, ибо соответствующий раздел курса по сжатию медиаданных я помню, даже несмотря на то, что сам тогда всё провалил к чертям :)
Gryphon88
11.12.2019 15:42Почему традиционно считается, что мы можем сделать функцию преобразования изображения f(x,y) в f(x)*f(y)? Это ж во всех случаях не так, а для ряда преобразований ошибка будет очень большая.
AndreyDmitriev
С цветовыми артефактами можно попытаться побороться в цветовой модели HSI. Кроме того там можно подкрутить алгоритм для разных каналов. Надо будет попробовать на досуге.