

We have already presented Tarantool Cartridge that allows you to develop and pack distributed applications. Now let's learn how to deploy and control these applications. No panic, it's all under control! We have brought together all the best practices of working with Tarantool Cartridge and wrote an Ansible role, which will deploy the package to servers, start and join instances into replica sets, configure authorization, bootstrap vshard, enable automatic failover and patch cluster configuration.
Interesting, huh? Dive in, check details under the cut.
Starting off with a sample
Let us walk you through only some of the role's functions. You can always find a full description of all its features and input parameters in the documentation. However, trying once is better than seeing it a hundred times, so let us deploy a small application.
Tarantool Cartridge has a tutorial for creating a small Cartridge application that stores information about bank customers and their accounts, as well as provides an API for data management via HTTP. For this purpose, the application describes two possible roles that can be assigned to the instances:
api and storage.Cartridge itself does not say anything about how to start processes — it only provides an opportunity to configure the running instances. So, the rest of it is up to the user: distributing configuration files, running services, and configuring topology. But we're not going to do all of that — Ansible will do it for us.
Getting down to action
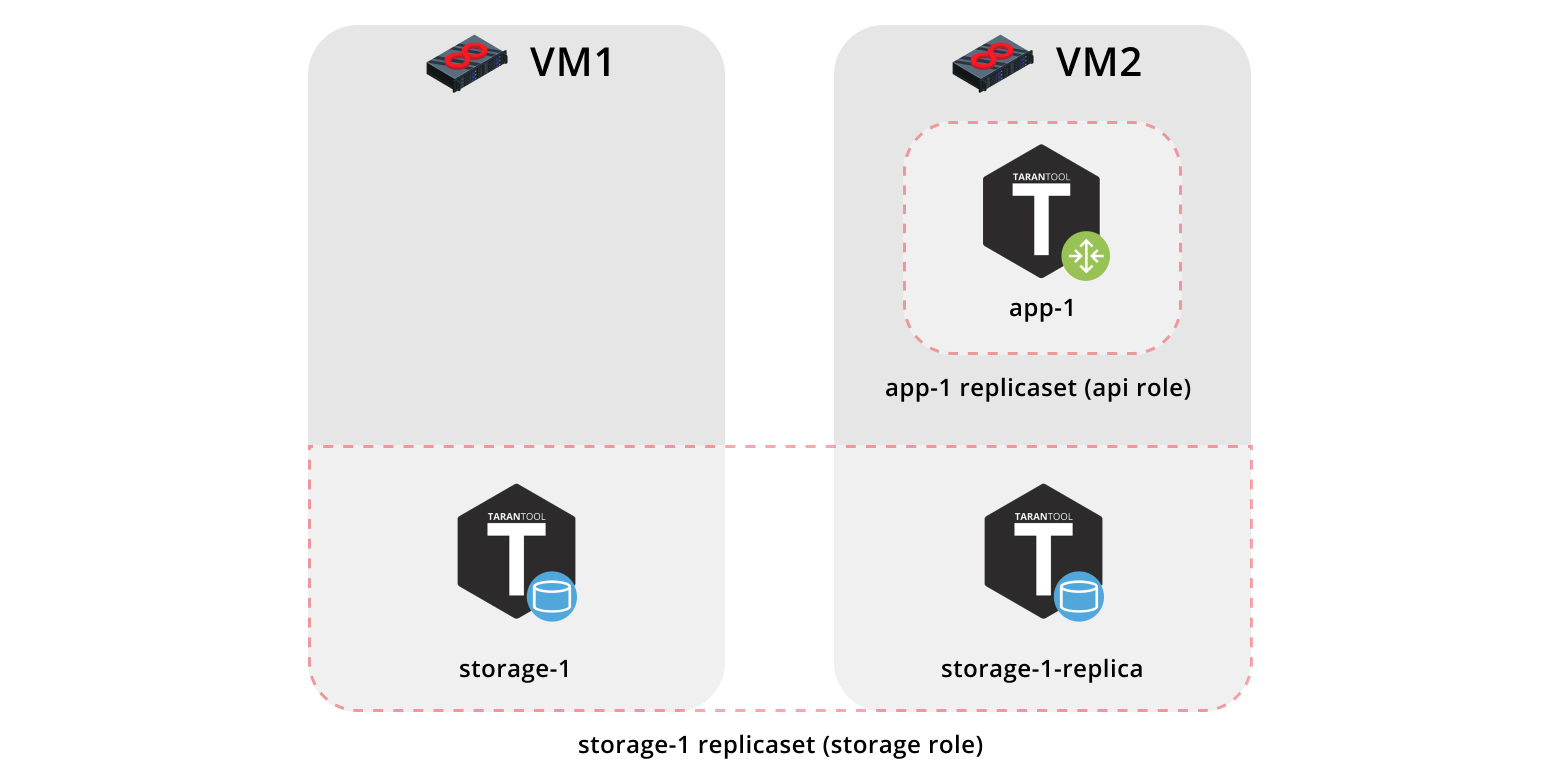
First, let us deploy our application onto two virtual machines and set up a simple topology:
- The
app-1replica set will represent theapirole that contains thevshard-routerrole. There will be just one instance. - The
storage-1replica set will represent thestoragerole (including thevshard-storagerole) — here we will add two instances from different machines.
To run the sample, we will need Vagrant and Ansible (version 2.8 or higher).
The role itself is stored in Ansible Galaxy — a repository that allows you to share your work and use the ready-made roles.
Now clone the sample repository:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git
$ cd deploy-tarantool-cartridge-app && git checkout 1.0.0Then deploy the virtual machines:
$ vagrant upAfter that, install the Tarantool Cartridge Ansible role:
$ ansible-galaxy install tarantool.cartridge,1.0.1And start the installed role:
$ ansible-playbook -i hosts.yml playbook.ymlNow wait until the playbook process is finished, go to http://localhost:8181/admin/cluster/dashboard and enjoy the results:
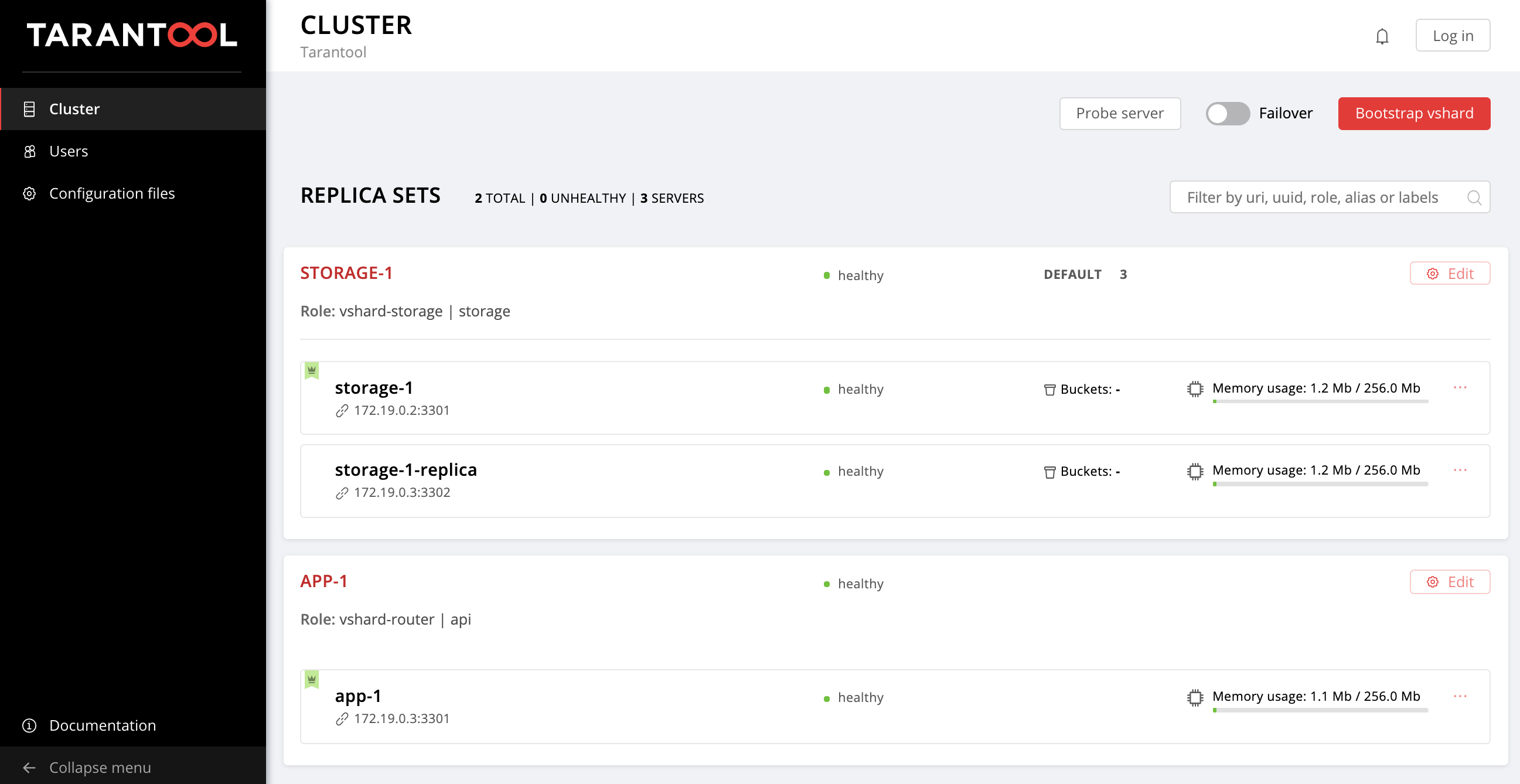
You can upload the data now. Awesome, isn't it?
Now let us figure out how to work with it, and we may as well add another replica set to the topology.
Getting deeper into details
So, what happened?
We got two virtual machines up and running and launched the Ansible playbook that configured our cluster. Now let's look inside the
playbook.yml file:---
- name: Deploy my Tarantool Cartridge app
hosts: all
become: true
become_user: root
tasks:
- name: Import Tarantool Cartridge role
import_role:
name: tarantool.cartridgeNothing interesting happens here; let's launch the Ansible role called
tarantool.cartridge.The most important things (namely, the cluster configuration) is in the
hosts.yml inventory file:---
all:
vars:
# common cluster variables
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package
cartridge_cluster_cookie: app-default-cookie # cluster cookie
# common ssh options
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
# GROUP INSTANCES BY REPLICA SETS
replicaset_app_1:
vars: # replica set configuration
replicaset_alias: app-1
failover_priority:
- app-1 # leader
roles:
- 'api'
hosts: # replica set instances
app-1:
replicaset_storage_1:
vars: # replica set configuration
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # leader
- storage-1-replica
roles:
- 'storage'
hosts: # replica set instances
storage-1:
storage-1-replica:All we need to do is learn how to manage instances and replica sets by modifying this file. Later on, we will add new sections to it. In order to avoid confusion while adding the sections, look at the final version of this file, or
hosts.updated.yml, which is located in the sample repository.Managing the instances
In Ansible terms, each instance is a host (not to be confused with a physical server), i.e. the infrastructure node that Ansible will manage. For each host, we can specify connection parameters (such as
ansible_host and ansible_user) and instance configuration. The instance description is in the hosts section.Let's look into the configuration of the
storage-1 instance:all:
vars:
...
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
...In the
config variable, we specified the instance parameters: advertise URI and HTTP port.Below are the parameters of the
app-1 and storage-1-replica instances.We should provide Ansible with connection parameters for each instance. It seems reasonable to group the instances by virtual machines. For this purpose, the instances are grouped together under
host1 and host2, and each group in the vars section contains the ansible_host and ansible_user parameter values for a single virtual machine. And the hosts section contains hosts (or instances) included in this group:all:
vars:
...
hosts:
...
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:Let's start editing
hosts.yml. Now we add two more instances: storage-2-replica on the first virtual machine and storage-2 on the second one:all:
vars:
...
# INSTANCES
hosts:
...
storage-2: # <==
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica: # <==
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
...
hosts: # instances to be started on the first machine
storage-1:
storage-2-replica: # <==
host2:
vars:
...
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
storage-2: # <==
...Start the Ansible playbook:
$ ansible-playbook -i hosts.yml \
--limit storage-2,storage-2-replica \
playbook.ymlNote the
--limit option. Since each cluster instance is a host in terms of Ansible, we can explicitly specify which instances should be configured when running the playbook.So we go back to the web UI at http://localhost:8181/admin/cluster/dashboard and look at our new instances:
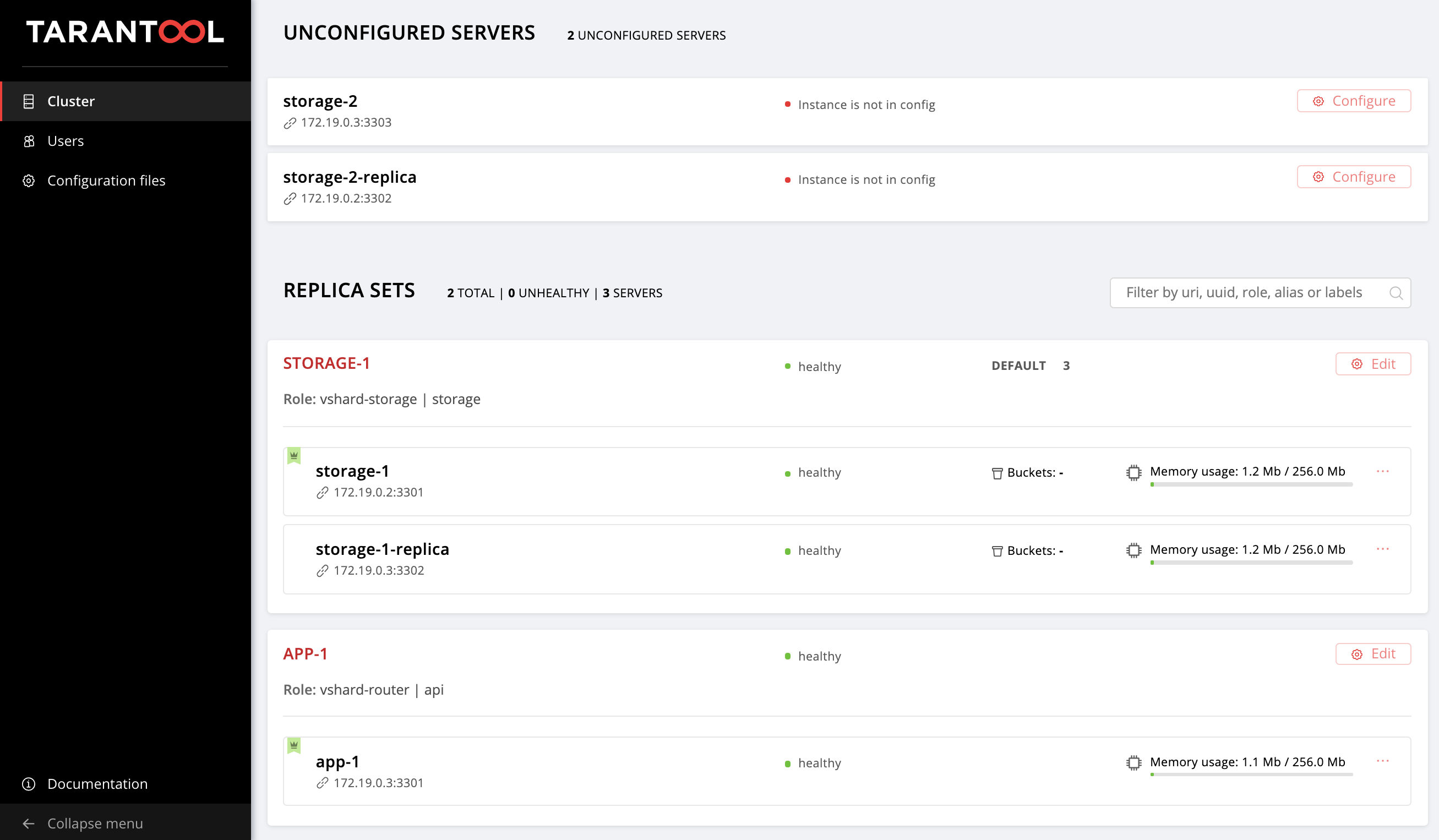
Next, let's master topology management.
Managing the topology
Let us group our new instances into the
storage-2 replica set, add a new group of replicaset_storage_2, and describe the replica set parameters in the variables as we did for replicaset_storage_1. In the hosts section, we specify which instances should be included in this group (i.e. our replica set):---
all:
vars:
...
hosts:
...
children:
...
# GROUP INSTANCES BY REPLICA SETS
...
replicaset_storage_2: # <==
vars: # replicaset configuration
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # replicaset instances
storage-2:
storage-2-replica:Then we run the playbook again:
$ ansible-playbook -i hosts.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasets \
playbook.ymlThis time we pass the name of the group corresponding to our replica set in the
--limit parameter.Let's look at the
tags option.Our role successively executes various tasks marked with the following tags:
-
cartridge-instances: instance management (configuration, membership); -
cartridge-replicasets: topology management (replica set management and permanent removal (expel) of instances from the cluster); -
cartridge-config: control of other cluster parameters (vshard bootstrapping, automatic failover, authorization parameters, and application configuration).
We can explicitly specify what part of the work we want to be done — and the role will skip the rest of the tasks. In this case, we only want to work with topology, so we specify
cartridge-replicasets.Let us evaluate the result of our efforts. Find the new replica set at http://localhost:8181/admin/cluster/dashboard.
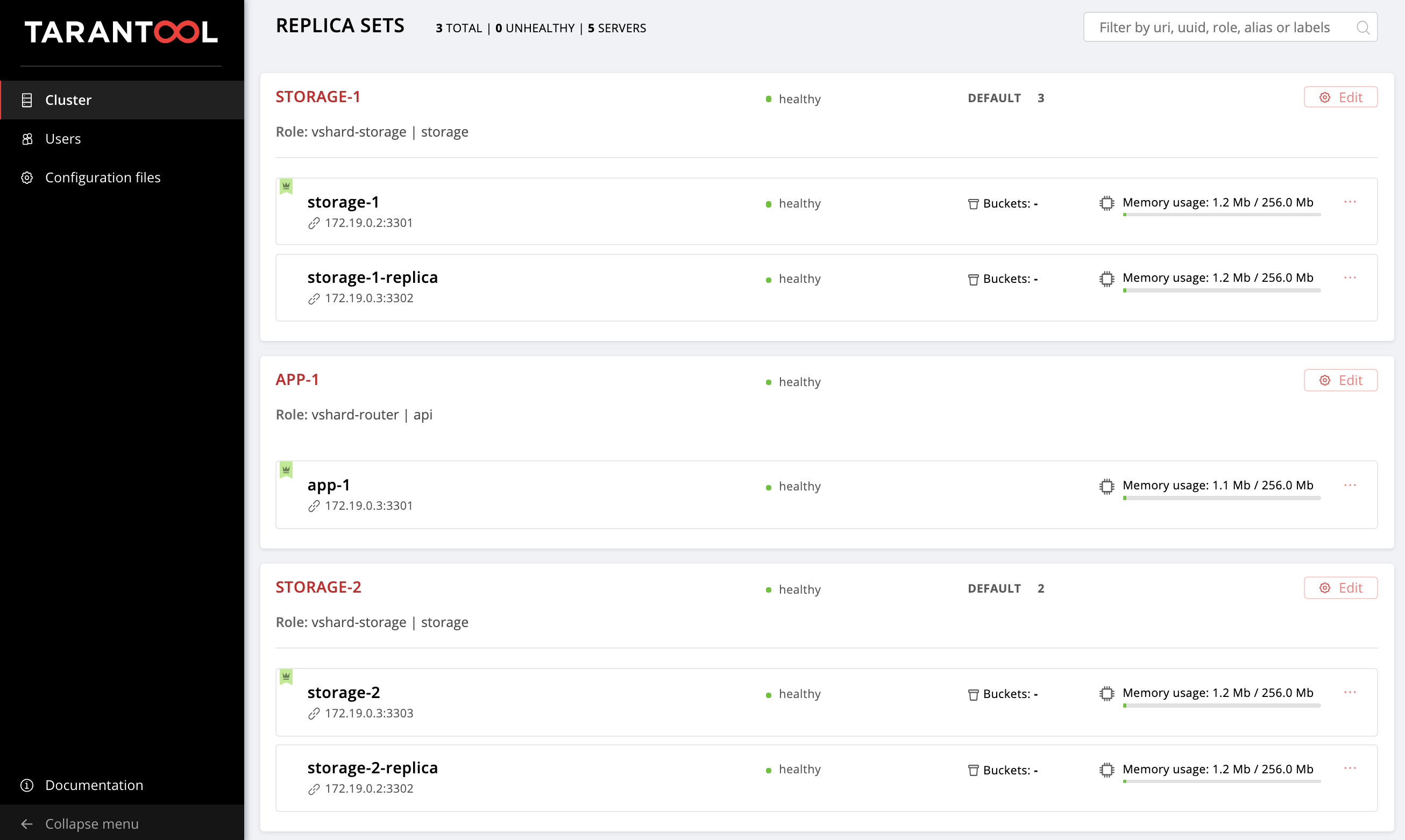
Yay!
Try changing the configuration of the instances and replica sets and see how the topology of the cluster changes. You can try different use cases, such as rolling update or
memtx_memory increase. The role would try to do this without restarting the instance to reduce the possible downtime of your application.Don't forget to run
vagrant halt to stop the virtual machines when you're done with them.What's inside?
Here I will tell you more about what happened under the hood of the Ansible role during our tests.
Let's consider the steps of deploying a Cartridge application.
Installing the package and starting the instances
The first thing to do is to deliver the package to the server and install it. Now the role can work with RPM-packages and DEB-packages.
Next, we launch the instances. It is very simple: every instance is a separate
systemd service. For example:$ systemctl start myapp@storage-1This command launches the
storage-1 instance of the myapp application. The running instance looks for its configuration in
/etc/tarantool/conf.d/. You can view the instance logs using journald.The Unit file
/etc/systemd/systemd/myapp@.sevice for the systemd service is delivered with the package.Ansible has built-in modules for installing packages and managing systemd services, so we did not invent anything new here.
Configuring the cluster topology
The most exciting things happen here. I am sure you would agree that it is strange to bother with a special Ansible role for installing packages and running
systemd services.You can configure the cluster manually:
- The first option is to open the Web UI and click on the buttons. It is quite suitable for a one-time start of several instances.
- The second option is to use GraphQL API. Here you can already automate something, for example, write a script in Python.
- The third option is for the courageous: go to the server, connect to one of the instances with the help of
tarantoolctl connectand perform all the necessary actions with thecartridgeLua module.
The main task of our invention is to do this most difficult part of the work for you.
Ansible allows you to write your own module and use it in your role. Our role uses these modules to manage the various cluster components.
How does it work? You describe the desired state of the cluster in a declarative configuration, and the role gives each module its own configuration section as input. The module receives the current state of the cluster and compares it with the input. Then the code for the necessary cluster state is launched using the socket of one of the instances.
Results
Today we have shown you how to deploy your Tarantool Cartridge application and configure a simple topology. To do this, we used Ansible, a powerful tool that is easy to use and allows you to configure multiple infrastructure nodes at the same time (in our case, the cluster instances).
Above we went over one of the many ways to describe the cluster configuration by means of Ansible. Once you feel that you are ready for more, learn the best practices for writing playbooks. You may find it easier to manage the topology with
group_vars and host_vars.Very soon, we will tell you how to remove (expel) instances from the topology permanently, bootstrap vshard, manage automatic failover, configure authorization, and patch cluster configuration. In the meantime, you can review the documentation yourself and try changing cluster settings.
If something goes wrong, make sure to let us know about the problem. We will do our best to resolve any issue!