
Больно только в первый раз!
Всем привет! Дорогие друзья, в этой статье я хочу поделиться своим опытом использования TensorRT, RetinaNet на базе репозитория github.com/aidonchuk/retinanet-examples (это форк официальной репы от nvidia, который позволит начать использовать в продакшен оптимизированные модели в кратчайшие сроки). Пролистывая сообщения в каналах сообщества ods.ai, я сталкиваюсь с вопросами по использованию TensorRT, и в основном вопросы повторяются, поэтому я решил написать как можно более полное руководство по использованию быстрого инференса на основе TensorRT, RetinaNet, Unet и docker.
Описание задачи
Предлагаю поставить задачу таким образом: нам необходимо разметить датасет, обучить на нём сеть RetinaNet/Unet на Pytorch1.3+, преобразовать полученные веса в ONNX, далее сконвертировать их в engine TensorRT и всё это дело запустить в docker, желательно на Ubuntu 18 и крайне желательно на ARM(Jetson)* архитектуре, тем самым минимизируя ручное развертывание окружения. В итоге мы получим контейнер готовый не только к экспорту и обучению RetinaNet/Unet, но и к полноценной разработке и обучению классификации, сегментации со всей необходимой обвязкой.
Этап 1. Подготовка окружения
Здесь важно заметить, что в последнее время я полностью ушёл от использования и развертывания хоть каких-то библиотек на desktop машине, как впрочем и на devbox. Единственное, что приходится создавать и устанавливать — это python virtual environment и cuda 10.2 (можно ограничиться одним драйвером nvidia) из deb.
Предположим, что у вас свежеустановленная Ubuntu 18. Установим cuda 10.2(deb), подробно на процессе установки я останавливаться не буду, официальной документации вполне достаточно.
Теперь установим docker, руководство по установке докера можно легко найти, вот пример www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-ru, уже доступна 19+ версия — ставим её. Ну и не забудьте сделать возможным использования docker без sudo, так будет удобнее. После того как всё получилось, делаем вот так:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
И можно даже не заглядывать в официальный репозиторий github.com/NVIDIA/nvidia-docker.
Теперь делаем git clone github.com/aidonchuk/retinanet-examples.
Осталось совсем чуть-чуть, для того чтобы начать пользоваться docker с nvidia-образом, нам потребуется зарегистрировать в NGC Cloud и залогиниться. Идём сюда ngc.nvidia.com, регистрируемся и после того как попадаем внутрь NGC Cloud, жмём SETUP в левом верхнем углу экрана или преходим по этой ссылке ngc.nvidia.com/setup/api-key. Жмём «сгенерить ключ». Его рекомендую сохранить, иначе при следующем посещении его придётся генерить заново и, соответственно, разворачивая на новой тачке, повторно производить эту операцию.
Выполним:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Username просто копируем. Ну вот, считай, среда развернута!
Этап 2. Сборка контейнера docker
На втором этапе нашей работы мы соберем docker и познакомимся с его внутренностями.
Перейдём в корневую папку по отношению к проекту retina-examples и выполним
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Мы собираем docker пробрасывая в него текущего юзера — это очень полезно если вы будете что-то писать на смонтированный VOLUME с правами текущего юзера, иначе будет root и боль.
Пока собирается docker, давайте изучим Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Как видно из текста, мы берем все наши любимые либы, компилируем retinanet, накидываем базовых инструментов для удобства работы с Ubuntu и настраиваем сервер openssh. Первой строкой идет как раз наследование образа nvidia, для которого мы делали логин в NGC Cloud и который содержит Pytorch1.3, TensorRT6.x.x.x и еще кучу либ, позволяющих скомпилировать cpp исходники нашего детектора.
Этап 3. Запуск и отладка контейнера docker
Перейдем к основному кейсу использования контейнера и среды разработки, для начала запустим nvidia docker. Выполним:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestТеперь контейнер доступен по ssh <curr_user_name>@localhost. После успешного запуска, открываем проект в PyCharm. Далее открываем
Settings->Project Interpreter->Add->Ssh InterpreterШаг 1
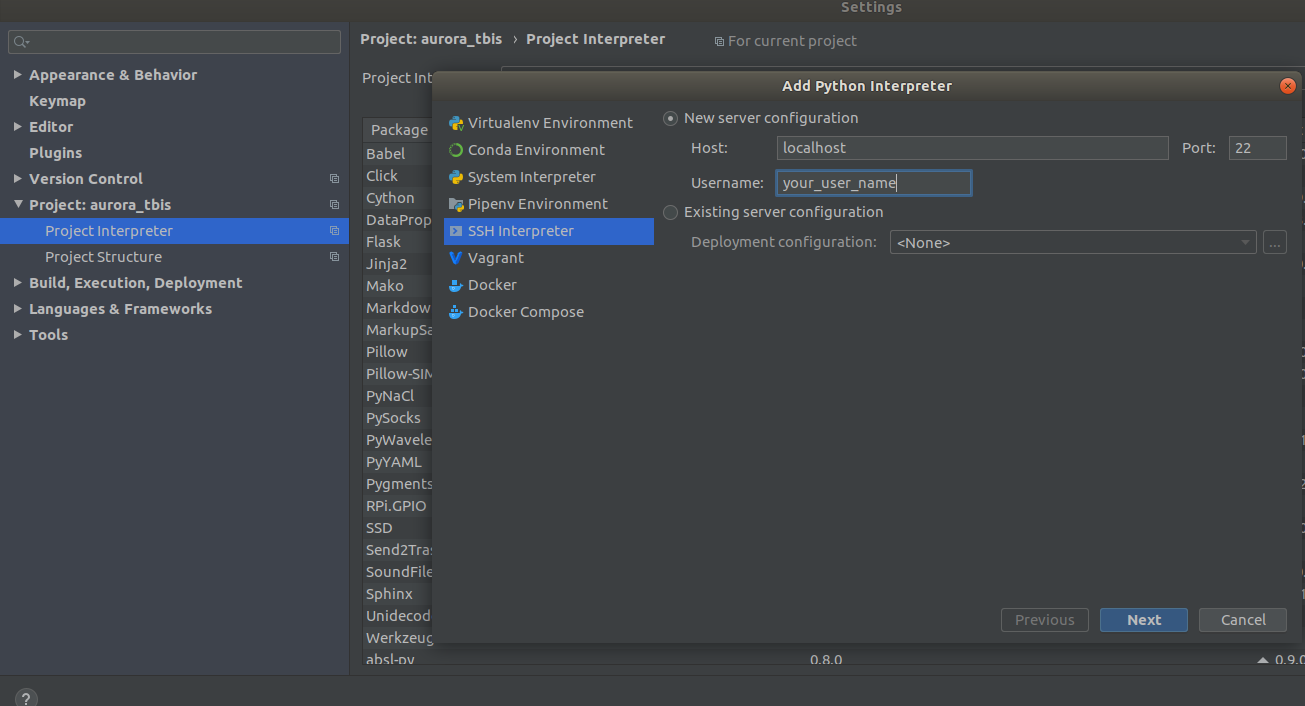
Шаг 2
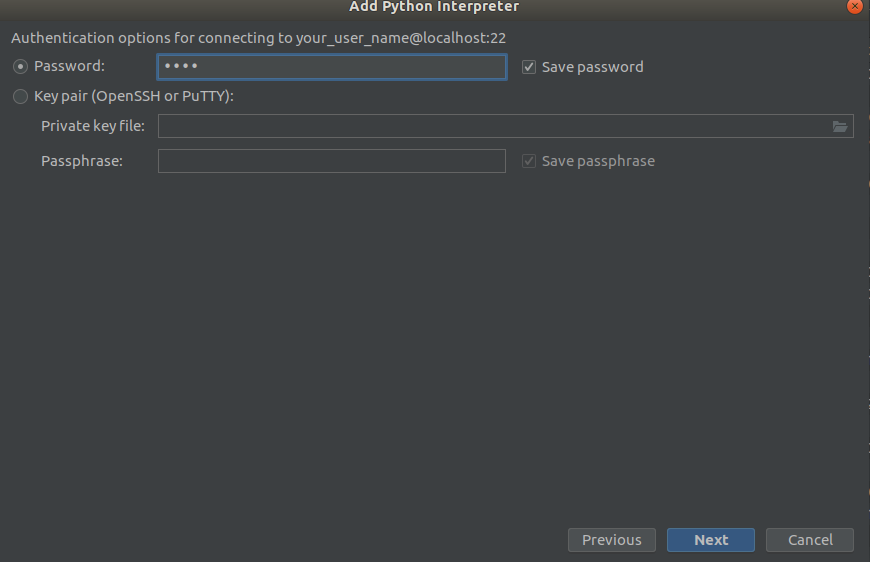
Шаг 3
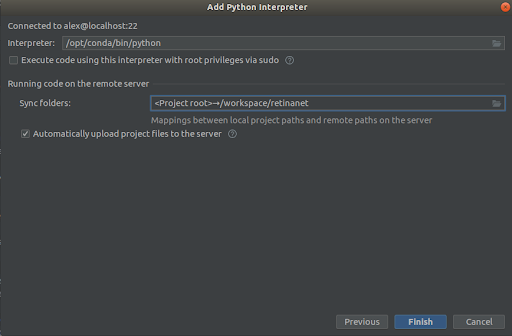
Выбираем всё как на скриншотах,
Interpreter -> /opt/conda/bin/python— это будет ln на Python3.6 и
Sync folder -> /workspace/retinanetЖмём финиш, ожидаем индексирование, и всё, среда готова к использованию!
ВАЖНО!!! Сразу после индексирования вытянуть из docker скомпилированные файлы для Retinanet. В контектсном меню в корне проекта выберем пункт
Deployment->DownloadПоявятся один файл и две папки build, retinanet.egg-info и _С.so
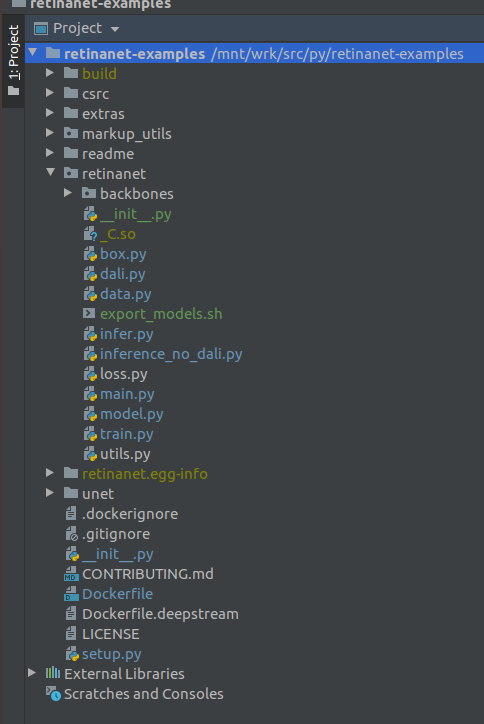
Если ваш проект выглядит так, то среда видит все необходимые файлы и мы готовы, к обучению RetinaNet.
Этап 4. Размечаем данные и обучаем детектор
Для разметки я, в основном, использую supervise.ly — приятная и удобная тулза, в последнее време кучу косяков пофиксили и она стала существенно лучше себя вести.
Предположим что вы разметили датасет и скачали его, но сразу засунуть его в наш RetinaNet не выйдет, так как он в собственном формате и для этого нам необходимо сконвертировать его в COCO. Тулза для конвертации находится в:
markup_utils/supervisly_to_coco.pyОбратите внимание, что Category в скрипте это пример и вам необходимо вставить свои (категорию background добавлять не надо)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Авторы оригинального репозитория почему-то решили, что ничего кроме COCO/VOC вы обучать для детекции не будете, поэтому пришлось немного подредактировать исходный файл
retinanet/dataset.pyДобавив тутда любимые аугментации albumentations.readthedocs.io/en/latest и выпилить жёстко вшитые категории из COCO. Также есть возможность кропнуть большие области детекции, если вы на больших картинках ищите маленькие объекты, у вас маленький датасет =), и ничего не работает, но об этом в другой раз.
В общем train loop тоже слабенький, изначально он не сохранял чекпоинты, юзал какой-то ужасный scheduler и т.д. Но теперь вам осталось только выбрать backbone и выполнить
/opt/conda/bin/python retinanet/main.pyc параметрами:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
В консоле увидите:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Что бы изучить весь набор параметров посмотрите
retinanet/main.pyВ общем они стандартные для детекции, и у них есть описание. Запустите обучение и дождитесь результатов. Пример инференса можно посмотреть в:
retinanet/infer_example.pyили выполнить команду:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
В репозитории уже встроен Focal Loss и несколько backbone, а так же легко впиливаются свои
retinanet/backbones/*.pyВ табличке авторы приводят некоторые характеристики:
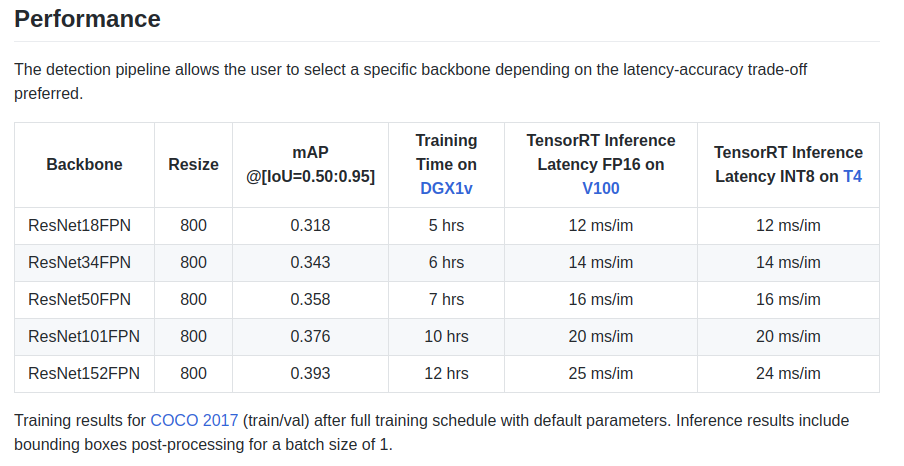
Также есть backbone ResNeXt50_32x4dFPN и ResNeXt101_32x8dFPN, взятый из torchvision.
Надеюсь с детекцией немного разобрались, но стоит обязательно прочитать официальную документацию, чтобы понять режимы экспорта и логирования.
Этап 5. Экспорт и инференс моделей Unet c энкодером Resnet
Как вы, наверное, обратили внимание, в Dockerfile были установлены библиотеки для сегментации и в частности замечательная либа github.com/qubvel/segmentation_models.pytorch. В пакете юнет можно найти примеры инференса и экспорта pytorch чекпоинтов в engine TensorRT.
Основная проблема при экспорте Unet-like моделей из ONNX в TensoRT — это необходимость задавать фиксированный размер Upsample или пользоваться ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
С помощью этого преобразования можно сделать это автоматически при экспорте в ONNX, но уже в 7 версии TensorRT эту проблему решили, и нам осталось ждать совсем немного.
Заключение
Когда я начал использовать docker у меня были сомнения на счёт его производительности для моих задач. В одном из моих агрегатов сейчас довольно большой сетевой трафик создаваемый несколькими камерами.
Разные тесты на просторах интернета говорили об относительно большом overhead на сетевое взаимодействие и запись на VOLUME, плюс ко всему неведомый и страшный GIL, а так как съемка кадра, работа драйвера и передача по сети кадра являются атомарной операцией в режиме hard real-time, задержки в сети для меня очень критичны.
Но всё обошлось =)
P.S. Остаётся добавить ваш любимый трейн луп для сегментации и в продакшен!
Благодраности
Спасибо сообществу ods.ai, без него невозможно развиваться! Огромное спасибо n01z3, надоумевшему меня заняться DL, за его бесценные советы и чрезвычайный профессионализм!
Используйте в production оптимизированные модели!
 Aurorai, llc
Aurorai, llc

NEWANDY
Спасибо за статью.
Я как потом в продакшн?
Весь докер переносим на сервер (Jetson) и делаем во flask АПИ интерфейс к модельке?
Alex_Donchuk Автор
Спасибо, что прочли. К сожалению, данный докер не переносим, а базовый докер для Jetson, еще с багами. Как разработчики всё поправят, напишу статью о сборке под Jetson. Сейчас я просто сделал образ/дамп для Jetson, где развернул всё руками, можете поступить так же. Интерфейс — flask, asyncio и т.д., ваш любимый короче.
NEWANDY
ок. спасибо.
akaAzazello
Зачем вообще докер, что на джетсоне, что тут — для лишнего overhead?
Alex_Donchuk Автор
Докер очень удобен для быстрого развертывания и точного воспроизведения окружения.
akaAzazello
Шаги для развёртывания и точного вопроизведения все одинаковые + развёртывание докера + overhead(который в случае встраиваемых систем может быть очень критичен).
Вы же не будете на рабочей станции разворачивать докер всякий раз для перетренировки модели, а на встраиваемую систему jetson тащить Ubuntu Unity(которую NVidia поставляет с образом) — вам всё-равно надо делать свой образ(image) скриптами и записывать его на SD/встроенную память Jetson — ими же и воссоздаётся всё окружение и работают они минимум не медленнее.
Есть места, где докер уместен, но в данном контексте его использование выглядит делом привычки, а не оправданным техническими причинами.
upd: возможно, именно поэтому докер на jetson и отсуствует спустя годы после появления arm64 сборок(с мая 2016го, L4T 24.1)
Alex_Donchuk Автор
github.com/NVIDIA/nvidia-docker/wiki/NVIDIA-Container-Runtime-on-Jetson