
Привет, Хабр! Я ведущий разработчик системы локализации в Badoo. Мы работаем с несколькими большими проектами: Badoo, Bumble, Lumen и Chappy. Сейчас в системе локализации у нас находятся 150 000 фраз и текстов, переведённых на 52 языка. При этом каждое из наших приложений имеет свою аудиторию, свои рынки, свой стиль общения с пользователями, версии для веба и для мобильных платформ.
В этой статье я расскажу, как мы выстроили процесс локализации, как подходим к контролю качества, как релизим переводы в зависимости от платформы, и главное — как мы добились того, что разработчики хорошо отзываются о нашей системе переводов. Это очень важный момент: над проектами трудятся более 300 разработчиков, работа которых должна быть комфортной. Разработчики не переводчики и не должны думать о переводах.
Статья написана по мотивам моего доклада на конференции Highload++ в ноябре.
Содержание:
Техническое задание всему голова!
Особенности процесса перевода
Просим пользователей помочь
Организация разработки
Контроль качества локализации
Релизы, версии
Главное. Итоги
Дополнительные материалы
Для начала давайте посмотрим, как в целом выглядит процесс локализации у нас в компании.

На этой схеме я не стал отражать все нюансы — для общего понимания они не нужны. Суть в том, что мы начинаем с технического задания (ТЗ). Дальше идут клиентская и серверная разработка, а параллельно им — процесс перевода.
ТЗ и финальный этап релиза не зря выделены одним цветом. Это намёк на то, что релиз должен соответствовать ТЗ. Никак иначе. Если ТЗ недостаточно полное, то разработчикам будет непонятно, кто за что отвечает, кто из них должен интегрировать текст: «мобильщики» должны «зашить» его в мобильное приложение или серверные разработчики отдавать с сервера в ответ на запрос.
Давайте со всем этим разбираться. Но сначала я хочу ввести и объяснить один термин.
Лексема — любой неделимый текст, который надо переводить. Это может быть надпись на кнопке, заголовок или целый параграф.
Вот теперь мы готовы переходить к основному материалу!
Техническое задание
Первый этап нашего процесса — это составление правильного технического задания. Главным элементом, относящимся к локализации, в нём является таблица лексем. По сути, это список текстов, которые должны быть использованы в приложении или на сайте.

В таблице лексем указано, отдаётся текст сервером или интегрируется в приложение. Обязательно указывается ключ: если текст раньше использовался, то ключ будет присутствовать в этой таблице; если же текст нигде не использовался, то будет указан порядковый номер текста, а разработчик сможет задать удобный ключ.
Переиспользование текста — очень коварный момент. С одной стороны, процесс локализации при этом ускоряется, а с другой — вы можете попасть в курьёзную ситуацию.
Объясню на примере. Однажды у нас был вопрос “Do you smoke?” c вариантами ответа “Yes” и “No”. Здесь мы видим три лексемы: две для ответов и одну — для вопроса. Вопрос на русский язык перевели как «Вы курите?», варианты ответов — «Курю» и «Не курю». Потом мы решили провести другой опрос и переиспользовать варианты ответа. На английском языке всё выглядело корректно: “Fancy visiting a party?” — “Yes”/“No”. На русском языке из-за переиспользования лексем получился следующий «диалог»: «Пойдёте на вечеринку?» — «Курю»/«Не курю».
Теперь, когда мы составляем ТЗ и решаем вопрос о повторном использовании текста, мы учитываем, в каких контекстах он раньше использовался. Мы также указываем, отдаётся лексема сервером или интегрируется в клиент и доставляется клиентам через App Store или Google Play.
Эти приёмы помогают экономить время, потому что исключают обсуждение на дальнейших этапах.
Переводы
Следующий этап — перевод. И главное здесь — не потерять изначально заложенную мысль. А это часто случается, потому что все языки разные, со своими оттенками и оборотами. Иногда самый точный перевод просто не умещается на экране и переводчикам приходится искать компромисс.
Расскажу по пунктам, с чего мы начинаем переводить, как доносим до переводчиков контекст, поддерживаем единый стиль и проверяем результат.
Порядок перевода
Порядок есть там, где есть правила (и все им следуют). Поэтому у нас существует регламент очерёдности перевода.
Для начала выбираем язык, который понятен большинству переводчиков. Именно на нём мы будем готовить исходные тексты, чтобы потом они без проблем были переведены на остальные языки. Все языки, на которые мы переводим (а их у нас 52), разделены на основные (родительские) и диалекты. Языком, на котором готовятся тексты, у нас является английский (мы его называем Master). Далее с английского мы переводим на остальные языки: испанский, французский, русский и другие. Иногда перевод требуется уточнить для одного из диалектов — тогда мы переводим на мексиканский испанский или на австралийский английский. Но если нам это не нужно, мы будем использовать перевод на родительский язык: основной испанский или основной английский.
Пример. Допустим, нам нужно приветствие сделать более формальным. Изначально на английском было “Hey”, на испанском — “Hola”, на французском — “Salut”, на русском — «Привет», на австралийском — “G’day mate”, на мексиканском — “Que onda” («Как волна?»; мексиканцы крутые!). Если мы хотим изменить текст, сделав его более официальным, то придётся менять исходный текст на английском. В этот момент переводы на остальные языки становятся некорректными: их необходимо проверить и уточнить. Мы обращаем внимание переводчиков на это.
Влияние контекста
Важный момент — контекст, в котором существует перевод.
Объясню на примерах.
Сразу отмечу, что некоторые примеры — скриншоты известных ресурсов, но их имена не имеют для нас значения, мы просто рассмотрим наиболее распространённые типы ошибок в локализации.

Это табличка с АЗС: «Перед началом движения убедитесь в отсутствии пистолета в баке». На английский слово «пистолет» перевели дословно: “gun”. Но “gun” для американца — это оружие. В этом контексте просьба «Вытащи пистолет из бака» звучит довольно странно.
В следующем примере создатели приложения решили сделать универсальный вариант текста для мужчин и женщин — видимо, для них есть какая-то выгода в этом. Ощущение такое, что тексты и картинки просто собраны на одном экране: о чём идет речь, непонятно.
Следующий пример — о том, как в результате перевода потерялась изначальная мысль текста. Посмотрите на русский вариант справа: нам предлагают начать общение с самим собой. Хотя подразумевалось, что нам дают возможность привязать к аккаунту свой Instagram.
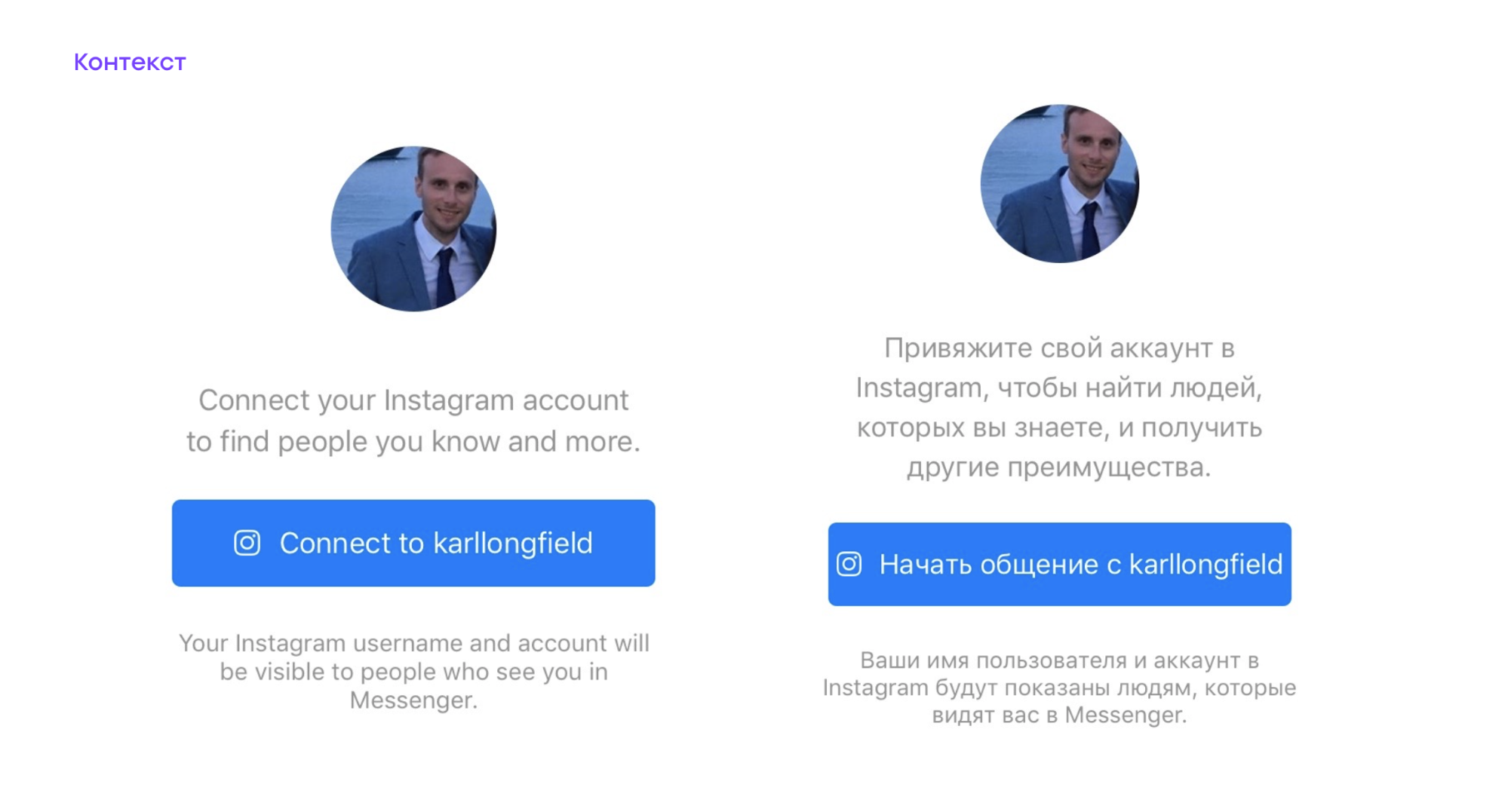
Такие ошибки случаются, когда перевод происходит в отрыве от контекста. Поэтому для каждой лексемы в нашей системе локализации указывается следующее:
- текстовое описание;
- картинка, на которой видно, какие элементы находятся рядом с текстом на экране;
- отметка о том, мужчинам или женщинам будет показан текст, — чтобы переводчики могли определить, необходимы два разных перевода или достаточно одного;
- типы переменных (это очень важный пункт, и я расскажу о нём подробнее, когда мы будем разбирать процесс разработки);
- максимальная длина текста: она очень важна для пуш-уведомлений, потому что ширина экрана мобильного устройства не безгранична.
Также мы обязательно разбиваем большой текст на части. Это удобно, если потом нужно искать или вносить изменения.
Давайте разберём этот момент более детально. Когда мы разбили текст, мы потеряли связь между отдельными фразами и предложениями. Поэтому мы должны обязательно показать переводчикам, что было до и после этого текста. Это актуально, например, в случае с юридическими документами — чтобы они были переведены корректно.
Также мы обязательно подсвечиваем в лексемах локальные термины, жаргонные слова. Например, в случае с предложением “Unlock your Likes List to see everyone who’s interested at once” переводчику нужно знать, что Likes в данном случае — специальная директория приложения, в которой собраны контакты пользователей, которым понравился профиль. Ещё один аналогичный пример — это термин “Stories” («сторис»). Десять лет назад никто при слове «сторис» не представлял себе Instagram. Сейчас же оно ассоциируется в первую очередь с ним.
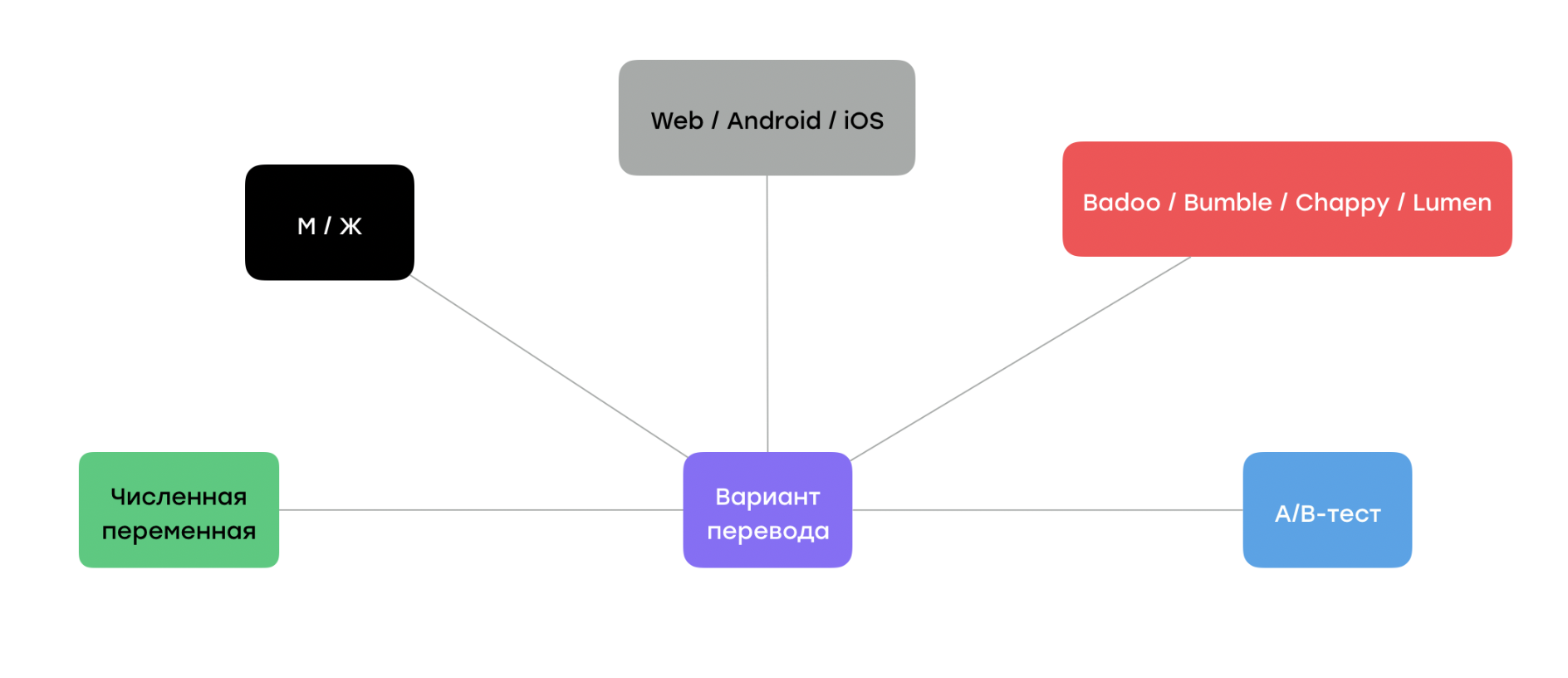
Итак, мы убедились, что вариант перевода сильно зависит от контекста, а именно от следующих факторов:
- пола пользователя;
- численной переменной, которая встречается в тексте: «У вас всего лишь один друг» и «У вас уже десять друзей»;
- платформы: Web, Android, iOS;
- проекта, для которого выполняется перевод.
Остановимся подробнее на последнем пункте — зависимости перевода от проекта. Это важно, потому что каждый проект имеет свой стиль.

Это заголовки писем, которые отправляются пользователю, если его аккаунт был заблокирован.
Для Badoo: «Ваш аккаунт заблокирован».
Для Lumen: «Ваш аккаунт заблокирован».
Для Bumble: «Вы были заблокированы».
А для Chappy — «А-оу!».
Чтобы сохранять единый стиль в рамках каждого проекта, нужно дать переводчикам доступ к истории переводов. У нас есть инструмент, который называется «Память переводов» (Translation memory, TM). Переводчику всегда доступна информация о совпадениях и проценте схожести: он может либо использовать старый перевод, либо ввести новый. Мы показываем переводчикам не только 100%-ные совпадения, но и менее схожие варианты, и обязательно подсвечиваем различия.

Помимо того, что «Память переводов» позволяет сохранять стиль в рамках проекта, она ещё и помогает ускорить процесс, потому что переводчику не нужно вводить два раза одно и то же.
Падежи и числительные
У нас есть инструмент, который называется «Матрица падежных форм». Это как таблица умножения, только для падежей и форм числительных.
Переводчики по мере необходимости заполняют эту матрицу для разных слов в каждом языке. Заполнить её в один приём нереально, поэтому это происходит постепенно: понадобилось слово — внесли.
В результате матрица помогает избежать вот таких ошибок:

Преимущество инструмента в том, что нужная форма выбирается непосредственно перед отрисовкой, перед показом пользователю. Вот как это происходит:

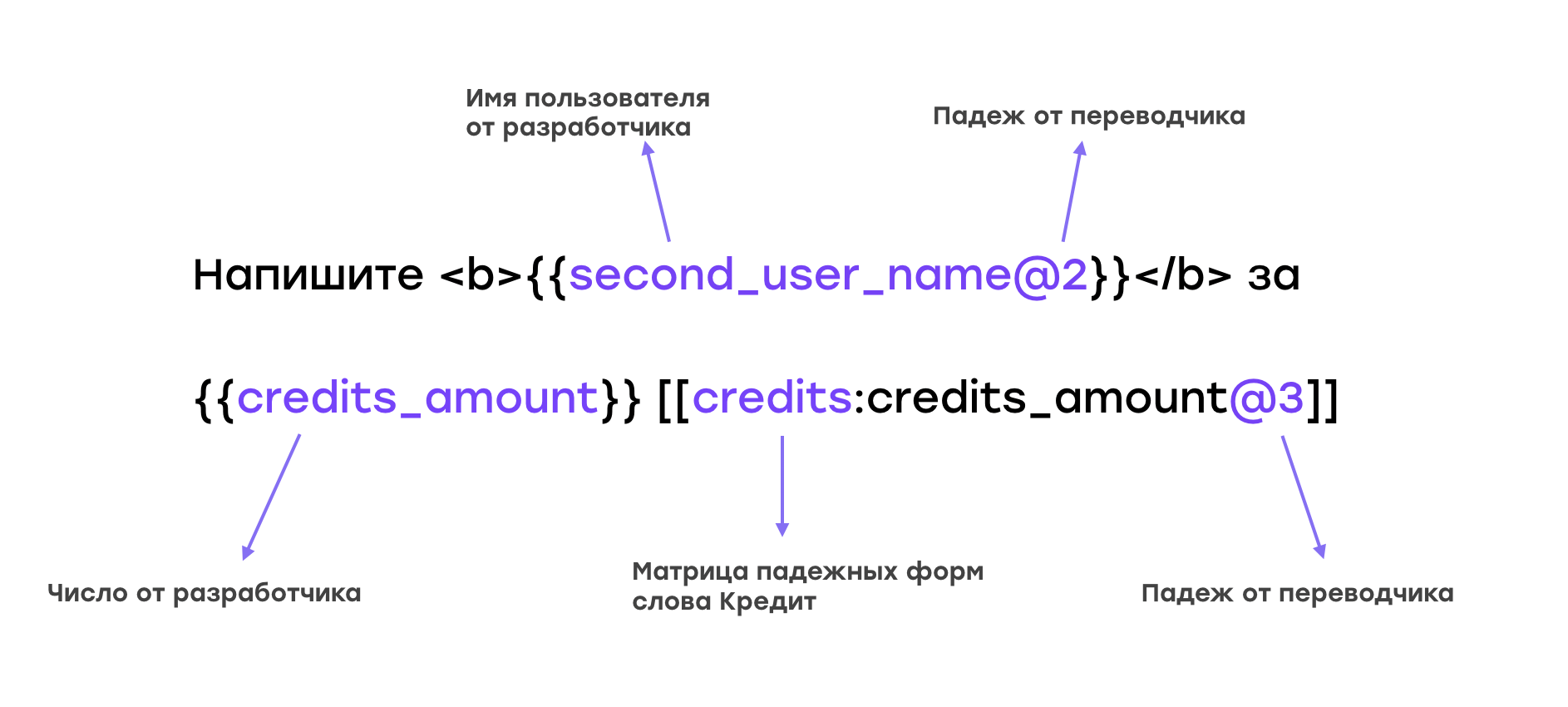
Например, у нас есть перевод на русский язык. “Credits” в центре — это идентификатор, ссылка на матрицу падежных форм. “Credits amount” слева — это число, которое придёт от разработчика. А @3 — это падеж, который указал переводчик (в данном случае винительный).
«Вам нужно 10 кредитов»: словосочетание «10 кредитов» будет подставлено автоматически.
Проверка переводов
Если умножить 150 000 фраз и текстов на 52 языка, мы получим число в районе 7,5 млн. Конечно, проверить всё это вручную нереально. Поэтому мы сделали автоматическую проверку переводов в момент сохранения.
Мы автоматически проверяем такие особенности, как пропущенные эмоджи или переменные. Если переводчик случайно удалил переменную, фраза теряет структуру и смысл. Сравните: «Вам нужно 10 кредитов» и «Вам нужно кредитов» — вторая фраза испорчена, мысль потеряна.
Также мы проверяем пропущенный HTML, иначе поедет вёрстка.
И мы обязательно предупреждаем переводчика о том, что его перевод длиннее оригинала. В этот момент он должен проверить, подойдёт ли он, уместится ли на экране текст.
Выделим основные моменты:
- переводчикам необходимо понимание контекста;
- система переводов должна быть настолько гибкой, чтобы на каждый язык можно было сделать уместный перевод, чтобы переводчик не выбирал универсальные формулировки; необходимо обеспечить поддержку склонений и падежей;
- обязательно нужно автоматически проверять переводы.
Помощь пользователей
Кроме труда профессиональных переводчиков, мы используем помощь пользователей. Здесь есть два метода: A/B-тестирование и совместный перевод.
A/B-тестирование
Итак, вам нужен перевод, например, на русский язык. Переводчик перевёл одну фразу двумя разными способами, и вы не знаете, какой вариант выбрать. В этом случае можно провести A/B-тест: показать пользователям разные варианты и выбрать один в зависимости от их реакции.
У нас был выбор между двумя вариантами: «Готовы к новым знакомствам? Присоединяйтесь!» и «Ещё пара шагов… и вы станете частью Badoo». В результате тестирования мы выяснили, что больше пользователей завершили регистрацию, когда увидели второй вариант пуш-уведомления. Его мы и оставили.
Ниже — полная схема факторов, от которых зависит вариант перевода. Пятый элемент — это как раз A/B тест: если пользователь попадает в какую-то группу, значит, ему будет показан соответствующий вариант текста.
Совместный перевод
Однажды мы разослали пользователям из Мексики уведомление с просьбой перевести некоторые тексты на их язык за небольшое вознаграждение в виде кредитов — внутренней валюты приложения. И они согласились: всего за два дня перевели для нас 5000 лексем. Это огромная помощь, а мексиканцы — отличные ребята!
Чем интересен и почему важен такой подход? Если у вас нет переводчика на локальный диалект, разрешите пользователям делать эту работу. Как выяснилось, они действительно готовы участвовать в развитии проекта, который им нравится.
У нас есть платформа для совместных переводов. В систему можно войти с помощью аккаунта Badoo. И проголосовать за лучший перевод.
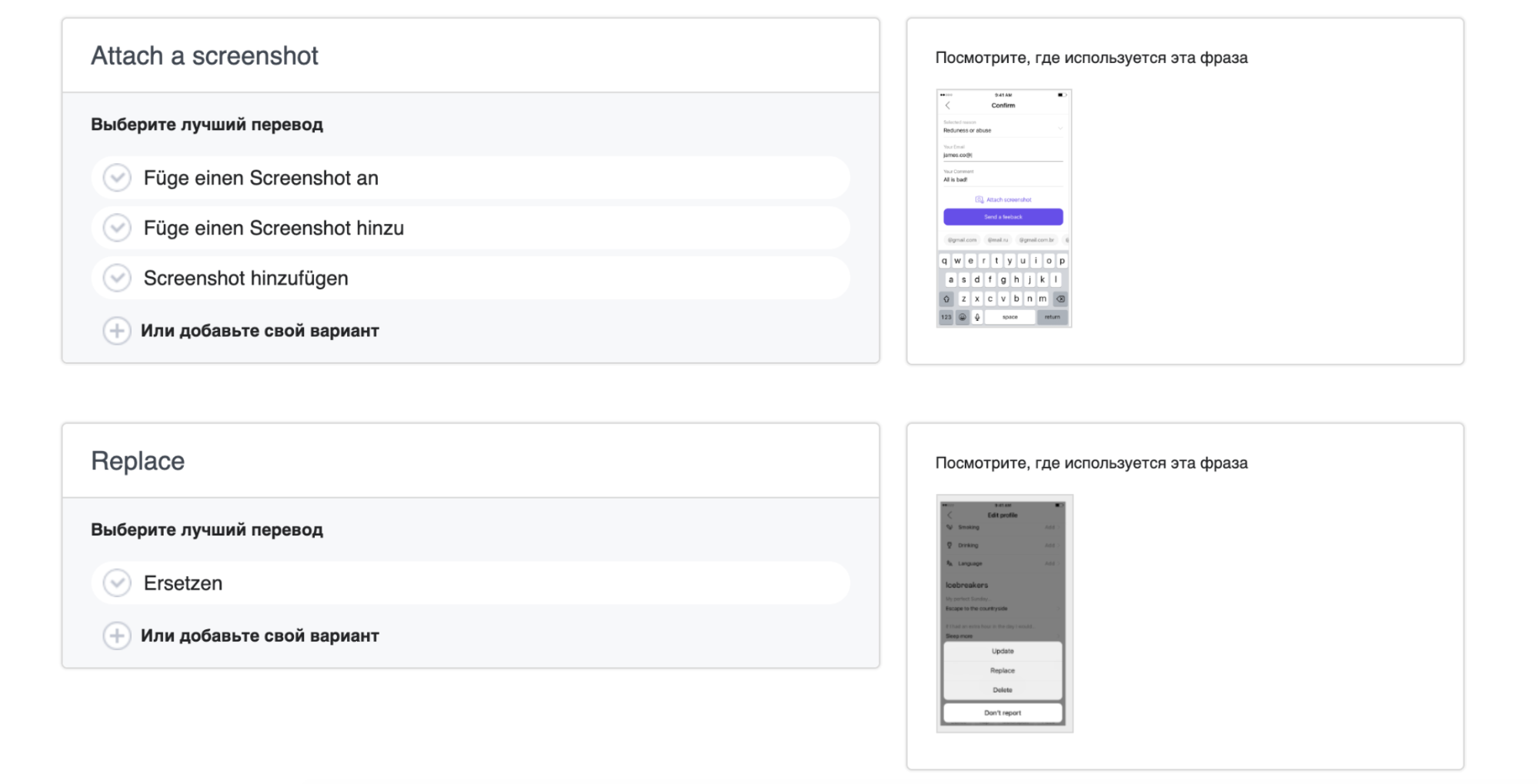
Это скриншот окна перевода на немецкий язык. Пользователь может добавить свой вариант. Когда один из вариантов набирает пороговое количество голосов, мы показываем его нашему штатному переводчику, и он может быть использован как основной (при условии, что он соответствует стилистике, правилам проекта, никого не оскорбляет и так далее).
Не бойтесь просить пользователей о помощи. Они подскажут и помогут.
Разработка
Переходим к самому интересному — к процессу разработки. Я специально сначала рассказал о процессе перевода, описал распространённые проблемы, чтобы потом показать, как эти проблемы решают разработчики.
Основных сложностей здесь две: как организовать параллельную разработку и как отслеживать ошибки при использовании лексем, чтобы правильные переводы показывались в правильное время.
Параллельная разработка
Начну с истории. Раньше схема разработки у нас выглядела иначе. Исходные тексты хранились в файле, в репозитории. Два разработчика могли что-то параллельно менять, и потом возникала необходимость объединять эти изменения. Проблема небольшая, но неудобно.

Старая схема, в которой приходилось объединять изменения
Теперь мы изменяем и вносим лексемы централизованно в системе локализации. Разработчикам нужно только скачать набор лексем перед началом работы над задачей и использовать их. Ключ указан, написал код, используешь — всё, ни о чём больше не думаешь.
Ошибки при использовании лексем
В переводах много переменных.
Если вы спешите, то легко можете спутать “credit_amount” и “credit”. Чтобы избежать этого, мы ввели контроль — текстовый контейнер, некую абстракцию над переводом, которая знает, переменные какого типа используются в этом переводе. Она производит подстановку и контролирует, что переданные типы значений для подстановки соответствуют ожидаемым. Если все подстановки сделаны, то она возвращает строчку, которую уже можно показывать пользователю. Если нет, то возвращается такой же контейнер. Если мы попытаемся показать пользователю перевод раньше, чем успели произвести все подстановки, то в логах мы увидим предупреждение и будем знать, куда идти и как исправлять ситуацию.
Основные моменты в разработке:
- разработчики должны заниматься только своей работой — они не должны думать о локализации, изменении текстов и прочем;
- нужно проверять то, что сделали разработчики, и эту проверку тоже лучше автоматизировать — это сохранит нервные клетки всех участников процесса.
Контроль качества
Итак, у нас уже есть разработанный продукт, который мы перевели. Осталось проверить, насколько хорошо мы это сделали.
Начнём с примеров. Сколько косяков на данном скриншоте?

Я выделил два. Сверху — переводчик, видимо, не знал, что перед его фразой будет показываться дистанция. Снизу — не учтена ширина экрана, на котором показывается перевод.
Второй пример тоже касается слишком длинных переводов, не соответствующих ширине экрана, — здесь просто всё обрезано, надпись не умещается на кнопке.

В следующем примере помимо того, что нам показывают текст на разных языках, нам ещё и предлагают узнать боль.
Чтобы подобных ошибок не возникало на проде, контроль качества просто необходим.
Варианты контроля
Давайте разберёмся, какие варианты контроля существуют.
Первый, который приходит в голову, — это проверить перевод на тестовой версии сайта или приложения. То есть просто запустить и посмотреть, соответствует ли то, что получилось, дизайну, задумке, ТЗ и так далее. С помощью этого способа мы поймали вот такую ошибку в пуш-уведомлении:
Скриншоты приложения
Следующий способ контроля качества — по скриншотам приложения.
Мы разработали специальный инструмент, который в тестовом окружении делает скриншоты всех экранов мобильных приложений на всех языках. Посмотреть, как они выглядят, можно через браузер. Также там есть специальный режим, переключившись на который, мы можем видеть идентификаторы текста, который нам показывают. Это очень помогает при отладке: можно быстро узнать, какая это лексема и почему она попала туда, куда попала (может быть, мы унаследовали код, в котором эта лексема подставляется).
Если у вас есть веб-версия и вам нужно лишь получить откуда-то картинки, можно интегрировать маркеры лексем в исходный текст, написать плагин для Google Chrome — и с машин тестировщиков, из их браузеров, этот плагин будет присылать вам в систему локализации скриншоты страниц, на которых он обнаружил лексемы.
<ul>
<li>...</li>
<li>
<!--lexeme_12345-->
Знакомства
<!--lexeme_12345_end-->
</li>
<li>...</li>
</ul>Мы пользовались этим способом довольно долго. Он позволил собрать огромное количество картинок буквально за две недели. Но мы от него отказались, потому что с его помощью можно получать изображения только уже выпущенной версии, а мы научились получать картинки и дизайн на этапе формирования ТЗ.
Контроль во время перевода
Как я сказал выше, нам показалось мало делать картинки, когда уже есть готовое приложение. Мы решили делать скриншоты, когда приложение ещё не готово, когда ещё ничего нет и необходимо как-то контролировать качество, понимать, всё ли идёт как надо.
Так у нас появился инструмент контроля во время перевода.

Объясню принцип его работы. Наши дизайнеры используют Sketch — приложение, в котором они создают интерфейсы, в том числе и интерфейсы мобильных приложений. Мы научились заменять тексты в Sketch-файлах и с помощью программного интерфейса Sketch генерировать скриншоты нужного нам экрана. Теперь, в процессе работы переводчика, мы можем ему сразу показывать скриншоты экранов на его языке. И делать это даже до того, как разработчики начали создавать первую версию нового функционала.
Позже мы оформили это решение как open-source (статья, код).
Аудит перевода
Если нет возможности проверить перевод на каком-то конкретном языке, например на японском, то можно заказать выборочный аудит, то есть сторонней фирме показать перевод каждой сотой лексемы с картинкой и спросить, всё ли корректно.
Основные моменты в контроле качества:
визуальная оценка качества перевода необходима;
в процессе тестирования важно понять, какими устройствами пользуется ваша аудитория, и тестировать приложение на всех этих устройствах.
Релиз
Итак, у нас есть протестированная круто написанная функциональность. Осталось доставить её пользователям.
Версионирование лексем
У нас в приложении Badoo была услуга «Суперсила». В какой-то момент нам потребовалось изменить её название на “Badoo Premium”, причём сразу во всех версиях атомарно, чтобы пользователь не видел на одном экране «Суперсила», а на другом — “Badoo Premium”.
Для этого к каждой ветке задачи в Jira у нас прикреплена версия лексем. Когда мы включаем в новую версию проекта изменения из какой-либо ветки, то сразу подтягивается и новая версия лексем. Если надо что-то откатить, мы изымаем ветку задачи из новой версии и вместе с ней изымаем версию лексем с переводами на все языки.
Когда лексема попала на тестирование или когда её уже видят пользователи, нужно быть очень осторожными: лучше ничего не менять в ней, а создать новую версию, прикрепить её к тикету и с новым релизом задеплоить новую версию лексемы с новыми переводами.
Версионирование переводов
Однако при переводе можно допустить ошибки. В примере ниже их две.
Неверно: “It's a remath”.
Верно: “It’s a rematch”.
В английском языке нельзя использовать прямой апостроф. Также пропущена буква “с”.
Версионирование лексем и версионирование переводов — это разные вещи. Перевод можно исправить в любой момент: когда задача находится в разработке, когда она на стадии тестирования или даже когда функциональность уже доведена до пользователя (ничего страшного не произойдёт, если в новой версии приложения пользователи увидят исправленный перевод).
Сервер != смартфон
Доставка обновлений на разные платформы происходит по-разному. Если вы разрабатываете мобильное приложение, то наверняка у вас есть серверная и клиентская части.
То, что вы показываете пользователю, или частично приходит с сервера, или находится у него на смартфоне (например, интегрированный перевод).
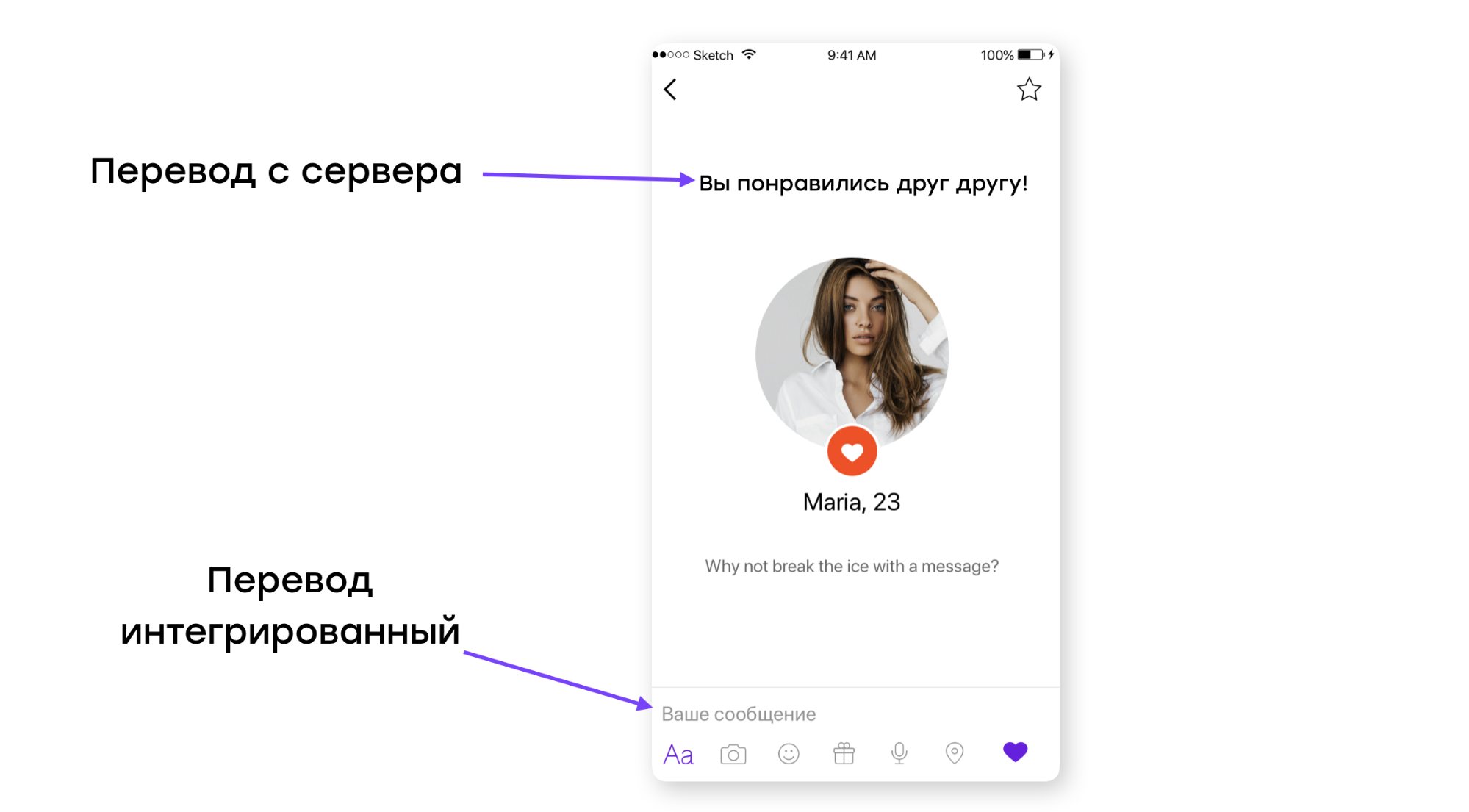
Путь, который проходит перевод с сервера до пользователя, лежит через наш продакшен-сервер, куда можно запросто доставить обновлённые версии файлов с переводами.
А вот путь интегрированного перевода длинный: он лежит через App Store или Google Play. Пользователь скачивает обновление и только после этого видит исправления. Нам этот процесс показался слишком медленным, и мы придумали свой механизм обновления “Hot Update”. Он позволяет по нажатию кнопки сгенерировать новую версию переводов и дать понять всем клиентам в мире, что есть что-то новое, что нужно скачать и использовать.

Когда на мобильном устройстве запускают приложение, оно отправляет на сервер уведомление о запуске и сообщает текущую версию переводов. Если у системы локализации есть готовое обновление, то она выдаёт в ответ уведомление об этом. Клиент скачивает обновление, применяет его.
Новые переводы пользователь увидит, когда переключится на следующий экран. Реализации данного решения посвящены две наши статьи: раз и два.
Релиз: основные моменты
В процессе релиза нужно обязательно учесть, какой путь проходит приложение от вас до ваших клиентов. Вероятно, разные части вашего приложения обновляются по-разному.
Финальные выводы
Давайте вернёмся к схеме, которую я приводил в начале статьи.
На что стоит обратить внимание, если вы разрабатываете систему переводов:
- писать подробное ТЗ;
- учитывать контекст и предоставить переводчикам доступ к нему;
- вести историю переводов, чтобы поддерживать единый стиль в рамках проекта;
- автоматизировать контроль (иначе любой случайный переводчик, который находится в нескольких часовых поясах от вас, сможет сделать всё по-своему);
- освободить разработчиков от решения непрофильных задач. Именно они создают новые версии вашего продукта, это доставляет радость вашим пользователям и дает удовлетворение от проекта, который вы создаёте.
Материалы, которыми я бы хотел с вами поделиться
Обновление строк на лету в мобильных приложениях: часть 1
Обновление строк на лету в мобильных приложениях: часть 2
Как научить веб-приложение говорить на 100 языках: особенности локализации
Переводим интерфейсы на полсотни языков. Sketch


youROCK
То есть совсем отказались от автоматического присвоения номеров лексемам? Или всё-таки используете и то и другое?
aatimin Автор
Эта автоматика работает, но, как ты помнишь (а другие не знают) она только для шаблонов. Этот подход не очень гибкий, он есть, но мы его никак не развиваем, а всё больше и больше пользуемся вызовом переводов лексем по ключам.
youROCK
Ну, я согласен, что когда нужен перевод для мобилок на клиенте, мобилок на сервере, веба и т.д. параллельно, то перевод лексем по ключам будет лучше работать, чем автоматический в HTML-шаблонах :).