Привет! Меня зовут Владимир Олохтонов, я старший разработчик в команде автоматической модерации Авито. Осенью 2019 мы запустили сервис поиска похожих изображений на основе библиотеки faiss. Он помогает нам понимать, что фотографии уже встречались в другом объявлении, даже если они достаточно серьёзно искажены: размыты, обрезаны и тому подобное. Так мы определяем потенциально фейковые публикации.
Мне бы хотелось рассказать о тех проблемах, с которыми мы столкнулись в процессе создания этого сервиса, и наших подходах к их решению.

Статья предполагает, что читатель хотя бы немного знаком с темой поиска по многомерным пространствам, поскольку дальше речь пойдёт в основном о технических деталях. Если это не так, я рекомендую сначала прочитать базовую статью в блоге Mail.ru.
Постановка задачи и описание нашей системы
Первое, о чём я задумался, когда мне поставили задачу сделать систему поиска по картинкам — это требования и ограничения:
- Число записей. У нас было около 150 миллионов векторов на старте, сейчас уже больше 240 миллионов.
- Ограничения на время поиска. В нашем случае — порядка 300 ms для 95 перцентили.
- Ограничение по памяти. Нужно, чтобы индекс помещался на обычные сервера с учётом роста на ближайшие 2 года.
- Удобство эксплуатации. Поскольку все наши сервисы живут на Kubernetes, делать систему, нуждающуюся в запуске на железе, очень не хотелось.
- Картинки могут добавляться, но они не удаляются и не модифицируются.
Из требований вытекают основные свойства будущей системы:
Поскольку нам нужно искать по сотням миллионов векторов достаточно быстро, то полный перебор не подходит — нам нужен индекс, который будет жить в оперативной памяти. Чтобы векторы туда поместились, их надо сжимать.
Раз индекс висит в памяти, то для страховки от его потери мы будем время от времени снимать бэкапы и складывать их во внешнее хранилище. Бэкапы не должны требовать удвоения затрат памяти, даже временно, поскольку речь идёт о десятках гигабайт.
Остаётся только обеспечить горизонтальное масштабирование. Самый простой способ в наших условиях — это одинаковые eventually consistent индексы. Тогда инстансы сервиса смогут не знать про существование друг друга, а единственной точкой синхронизации станет база данных.
Наш сервис написан на Python3.7, в качестве базы для хранения векторов используется PostgreSQL, хранилище — MinIO. В главной роли библиотеки для индексации выступает faiss.

Для взаимодействия с внешним миром используется http-фреймворк avio, это наша внутренняя обёртка вокруг aiohttp.
Поскольку asyncio плохо сочетается с вызовами fork, которые нужны нам для бэкапов, да и вызов долгих блокирующих операций в асинхронном сервисе — моветон, то вся работа с индексом вынесена в отдельный процесс, взаимодействие с которым реализовано через multiprocessing.Pipe.
Выбор структуры индекса
Для сжатия мы решили использовать Product Quantization. Этот подход позволяет сжать исходный вектор до 64 байт.

Product Quantization позволяет разбить векторы на части и построить независимые кластеризации. Схемы взяты из статьи Криса МакКормика
Для ускорения поиска мы выбрали смешанный подход на основе Inverted File и HNSW.
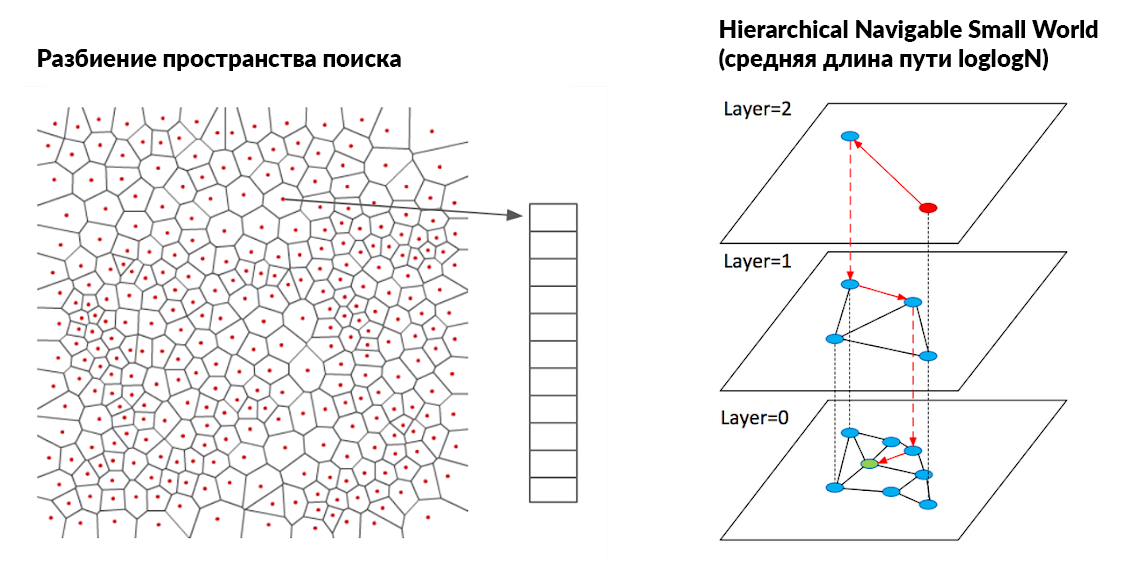
В итоге мы получили структуру индекса, которая в терминах faiss описывается вот такой загадочной строкой: IVF262144_HNSW32,PQ64. Это означает, что мы делаем Inverted File на 262144 кластера, отбирать ближайшие из которых мы будем с помощью HNSW с 32 соседями, а все векторы сжимаются до 64 байт методом Product Quantization.
Вот ссылки на гайдлайн по выбору индекса от авторов faiss и бенчмарк.
На что стоит обратить внимание, глядя на результаты бенчмарка:
- В индекс делается один запрос на поиск 10 000 векторов, а тайминги приведены в пересчёте на 1 вектор.
- Время указано для 16 OpenMP-потоков. Если искать на одном ядре, то время будет примерно в 16 раз выше, поскольку параллелизм обеспечивается с помощью #pragma omp parallel for.
Расчёт памяти
Корректнее всего оценивать затраты памяти в относительных величинах — в байтах на вектор. Это позволяет замечать утечки памяти, если они появляются, и легко отличать их от органического роста из-за вставок.
Память тратится в первую очередь на хранение векторов, в случае IVF262144_HNSW32,PQ64 это 80 байт на вектор:
- 64 байта на хранение кодов, описывающих вектор;
- 8 байт на хранение id (они хранятся в int64);
- 8 байт на хранение указателя на вектор внутри кластера.
Относительные затраты памяти можно посчитать по формуле:
int(faiss.get_mem_usage_kb() * 1024 / index.ntotal)Также память может уходить на предвычисленную таблицу расстояний, но она перестаёт автоматически вычисляться при превышении рассчётного размера в 2Gb. Её размер считается как nlist ? pq.M ? pq.ksub ? float. То есть в нашем случае 262144 ? 64 ? 256 ? 4 ? 17G, где pq.M — это число компонент Product Quantization, а pq.ksub — 256, поскольку именно столько кластеров можно описать одним байтом.
На что стоит обратить внимание при расчёте памяти. Данные выше приведены только для статического индекса: если вы добавляете и удаляете элементы, то потребление памяти стоит умножить минимум на 2. У меня есть предположение, что это связано с динамической аллокацией памяти для векторов в Inverted File, но конкретного подтверждения я пока не нашёл. Если у вас есть ответ — расскажите в комментариях к статье.
Схождение bytes per vector после выкатки сервиса:
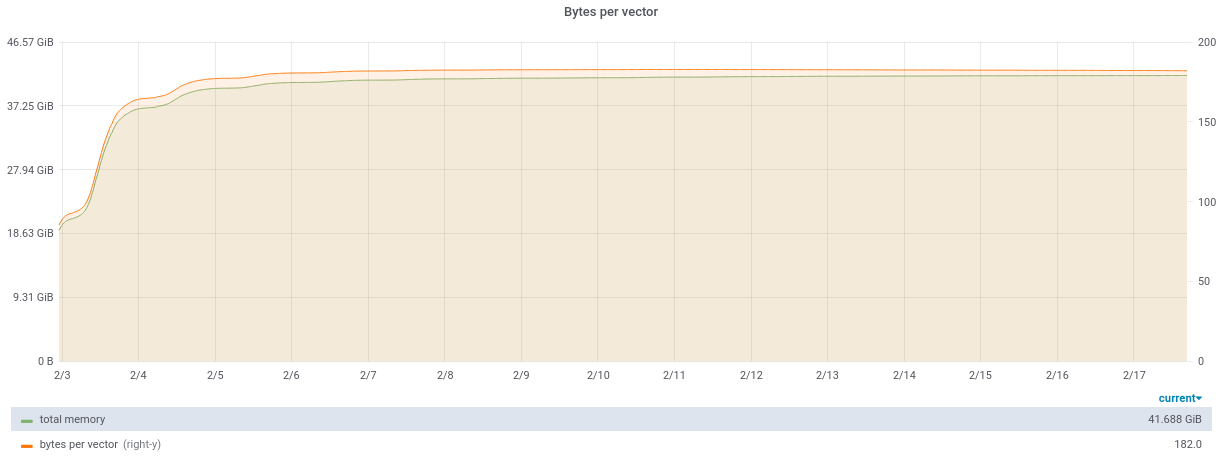
Если задача, которую вы решаете, не подразумевает удаления и модификации векторов, то можно выделить большую их часть в статичный индекс-архив и вставлять новые векторы только в маленький индекс, время от времени вливая его в большой, а запросы на поиск делать в оба индекса. В общем, всё по классике инфопоиска.
Распараллеливание запросов
Несмотря на использование OpenMP внутри faiss, любой долгий запрос, попавший в большие кластеры, может на существенное время заблокировать индекс. Чтобы это не мешало системе корректно работать, мы используем ThreadPoolExecutor (faiss дружелюбный и отпускает GIL).
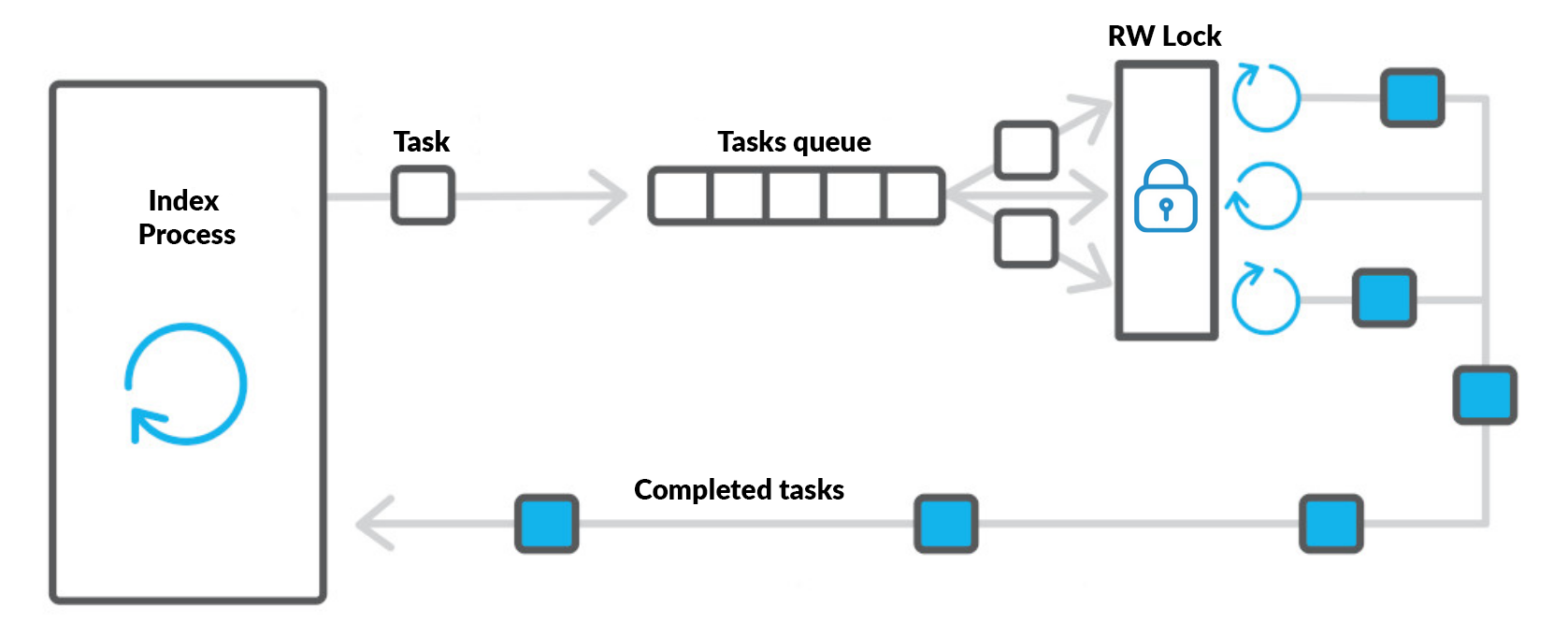
Для того, чтобы faiss корректно работал в многопоточной среде, нужно сделать две вещи. Во-первых, не допускать параллельного выполнения модифицирующих операций (add, remove) с какими-либо другими. Во-вторых, лимитировать число OpenMP-тредов во время выполнения читающих запросов таким образом, чтобы общее число тредов не превышало заданное ограничение на ядра, иначе неизбежна потеря производительности.
Для отделения пишущей нагрузки от читающей удобнее всего использовать RWLock, который позволяет заходить в критическую секцию множеству читателей, но только одному писателю. Для Python я рекомендую этот пакет. Число запущенных OpenMP-тредов можно регулировать с помощью функции faiss.omp_set_num_threads.
Для получения оптимальной производительности имеет смысл подбирать размер батча на один тред таким образом, чтобы максимизировать query-per-second. У нас размер батча равен 5.
Стоит обратить внимание, что при использовании многопоточности несколько возрастает потребление памяти. Похоже, что это баг, вот соответствующий issue.
Больше информации о поддержке многопоточности можно найти в статье на вики faiss.
Пропускная способность и тайминги операций
Вставка новых векторов происходит в базу, из которой они раз в 5 секунд вычитываются каждым инстансом независимо и вставляются в индекс батчами по 10 000 штук (ну или сколько накопилось с последнего апдейта). Скорость вставки в индекс достаточная для того, чтобы бутылочным горлышком стала база: порядка 800 тысяч векторов в минуту.
Один инстанс на 20 ядрах способен обработать до 150 rps поисков 20 ближайших соседей для одной картинки. Масштабирование по нагрузке очень простое: достаточно просто сделать больше инстансов, поскольку они ничего не знают друг про друга.
Бэкапы индекса
Поскольку индекс висит в оперативной памяти, то в случае смерти машинки возможна его потеря. Для того, чтобы избежать проблем, стоит его регулярно дампить в хранилище. Мы используем для этих целей MinIO.
Самый удобный способ — сделать fork и с помощью Copy-on-Write получить почти бесплатную в плане потребления памяти и влияния на время операций копию индекса. Затем этот индекс нужно сохранить на диск и перекинуть в хранилище. Здесь стоит исходить из объёма статического индекса — в нашем случае порядка 80 байт на вектор.
Соответственно, при старте приложения нужно только загрузить последнюю копию из хранилища и вставить туда недостающие данные из базы.
Использование GPU
Мы пока не используем поиск на GPU в проде, но я провёл замеры для понимания соотношения времён операций.
Данные: SIFT1M, размерность 128.
Запрос: ищем 100 ближайших соседей для 10 000 векторов с разными значениями nprobe.
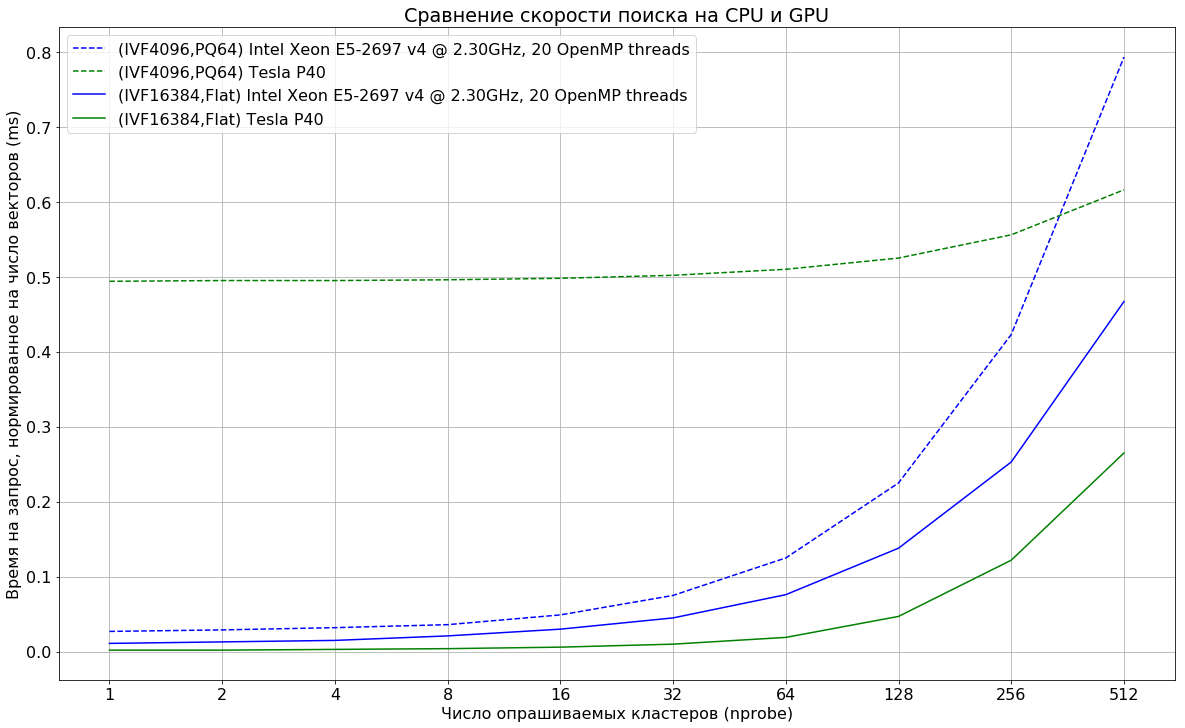
На что стоит обратить внимание:
- Индекс должен целиком помещаться в память GPU. Хотя способы использовать несколько GPU для поиска и существуют, однако, на мой взгляд, подход несёт с собой минусы, связанные со сложностью эксплуатации такого решения.
- Flat-индексы заметно быстрее работают на GPU, однако они применимы только при относительно небольшом количестве данных (максимум десятки миллионов векторов при размерности 128).
- При использовании PQ64-индекса преимущество GPU проявляется только при опросе очень большого числа кластеров.
Напоследок
Faiss — это наверное лучший на сегодня open source инструмент для приближённого поиска, но как и любой сложный инструмент он требует привыкания к своим особенностям.
Лучше всего его осваивать, периодически поглядывая в код, хотя и документация у faiss вполне приличная. Также можно задавать вопросы разработчикам в issues, обычно они достаточно оперативно отвечают.
Если вы собираетесь разворачивать такого рода систему на заранее определённом множестве машин, то могу порекомендовать посмотреть на систему vearch от JD.com. Они сделали большую часть грязной работы и выложили своё решение в open source, хотя с документацией всё пока довольно печально.







Vladpe
Не знаю стал ли я жертвой этой функции, или чего-то еще…
но когда продавал два разных велоколеса, то одно из объявлений было забанено как дублирующее, хотя там в описании параметры товара указывал и они разные, да и фото конкретно так были НЕ похожи друг на друга.
sgjurano Автор
Вопрос конечно совсем не по теме статьи :)
Скорее всего ваше объявление было забанено по какой-то другой причине, раз вы говорите, что фотки разные.
Vladpe
Я написал в поддержку тогда и его в итоге разбанили, извинившись.
а статья мощная, но оооочень технически ориентированная. Реально я думаю понятна будет ничтожному проценту людей, тем кто конкретно такую же штуку запиливал. И то вопросы останутся. А остальным только впечатлиться «до чего техника дошла» :)
sgjurano Автор
Можно спрашивать детали, я постараюсь ответить :)