Регулярно сталкиваюсь с ситуацией, когда многие разработчики искренне полагают, что индекс в PostgreSQL — это такой швейцарский нож, который универсально помогает с любой проблемой производительности запроса. Достаточно добавить какой-нибудь новый индекс на таблицу или включить поле куда-нибудь в уже существующий, а дальше (магия-магия!) все запросы будут эффективно таким индексом пользоваться.

Во-первых, конечно, или не будут, или не эффективно, или не все. Во-вторых, лишние индексы только добавят проблем с производительностью при записи.
Чаще всего такие ситуации происходят при «долгоиграющей» разработке, когда делается не заказной продукт по модели «написал разово, отдал, забыл», а, как в нашем случае, создается сервис с длинным жизненным циклом.
Доработки происходят итеративно силами множества распределенных команд, которые бывают разнесены не только в пространстве, но и во времени. И тогда, не зная всей истории развития проекта или особенностей прикладного распределения данных в его БД, можно легко «напортачить» с индексами. Но соображения и проверочные запросы под катом позволяют заранее предсказывать и обнаруживать часть проблем:
Самое простое — найти индексы, по которым вообще не было проходов. Только надо предварительно убедиться, что сброс статистики (
Но даже если индекс используется и не попал в эту выборку, это вовсе не значит, что он хорошо подходит для ваших запросов.
Чтобы понять, почему какие-то запросы «плохо ходят по индексу», задумаемся о структуре обычного btree-индекса — наиболее частого в природе экземпляра. Индексы из единственного поля обычно никаких проблем не создают, поэтому рассмотрим возникающие проблемы на составном из пары полей.
Предельно упрощенный способ, как его можно представить — это «слоеный пирог», где в каждом слое — упорядоченные деревья по значениям соответствующего по порядку поля.
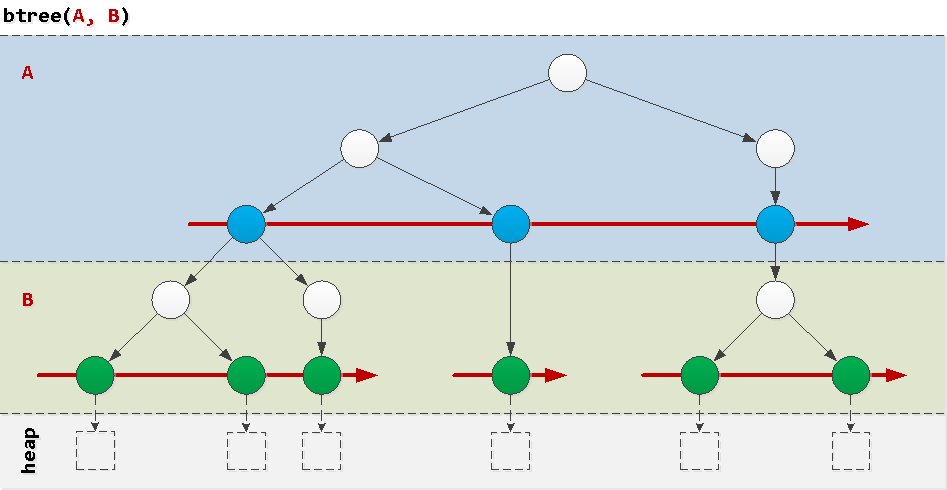
Сразу становится понятно, что поле A упорядочено глобально, а B — только в рамках конкретного значения A. Давайте рассмотрим примеры условий, которые встречаются в реальных запросах, и как они будут «ходить» по индексу.
Заметим, что индекс
То есть если вы создаете более сложный индекс, чем в нашем примере, что-то типа
А это означает, что «физическое» присутствие префикс-индекса в базе — избыточно в большинстве случаев. Ведь чем больше индексов приходится на запись таблицы — тем хуже для PostgreSQL, поскольку вызывает Write Amplification — на это еще Uber жаловался (а тут можно ознакомиться с анализом их претензий).
А если что-то мешает базе жить хорошо, стоит это найти и устранить. Посмотрим на примере:
В идеале, вы должны получить пустую выборку, но смотрим — вот наши подозрительные группы индексов:
Дальше уже сами решаете по каждой группе — стоит ли удалить более короткий индекс или более длинный вообще не нужен был.
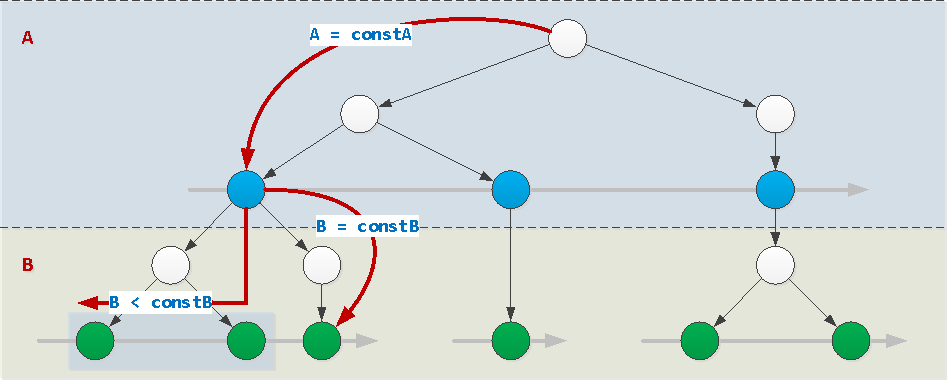
Если значения всех полей индекса, кроме последнего, заданы константами (в нашем примере это поле A) — индекс сможет использоваться нормально. При этом значение последнего поля может быть задано произвольным образом: константой, неравенством, интервалом, набором через
Исходя из описанного выше про префиксные индексов, хорошо будет работать и это:
При части запросов единственной схемой движения по индексу становится полный перебор всех значений в каком-то из «слоев». Повезет, если таких значений единицы — а если тысячи?..
Обычно такая проблема возникает, если в запросе использовано неравенство, в условии не определены предыдущие по порядку индекса поля или этот порядок нарушен при сортировке.
Как следствие из предыдущего — если на каком-то промежуточном «слое» надо найти несколько значений или их диапазон, а потом отфильтровать или отсортировать по лежащим «глубже» в индексе полям, — будут проблемы, если количество уникальных значений «в середине» индекса окажется большим.
Иногда разработчик неосознанно превращает в запросе столбец во что-то другое — в некоторое выражение, индекса для которого нет. Это можно исправить, создав индекс от нужного выражения, или произведя обратное преобразование:
Предположим, вам нужен индекс
В общем, вы выбрали btree. Так как же лучше расположить в нем столбцы —
Давайте представим, что
Фактически, каждый узел дерева, которое мы нарисовали, — страница в индексе. И чем их больше — тем больший дисковый объем будет занимать индекс, тем дольше будет чтение из него.
В нашем примере вариант
Ровно по этой причине всегда выглядит подозрительно, если в вашем индексе поле с заведомо большой вариативностью типа timestamp[tz] стоит не последним. Как правило, значения timestamp-поля монотонно возрастают, а следующие поля индекса имеют только одно значение в каждой временной точке.

Тут мы анализируем сразу и типы самих входящих полей, и применяемые к ним классы операторов — поскольку полем индекса может оказаться какая-то timestamptz-функция вроде date_trunc.
Обратной стороной этой же медали становится ситуация, когда в индексе оказывается boolean-поле, которое может принимать всего 3 значения:
Но, в большинстве случаев, это оказывается не так, и запросы ходят с каким-то конкретным значением boolean-поля. И тогда становится возможным заменить индекс с таким полем на его условную версию:
Отдельным пунктом идут попытки «проиндексировать массив» с помощью btree-индекса. Это вполне возможно, поскольку к ним применимы соответствующие операторы:
Научимся находить и такие:
Последняя достаточно часто встречающаяся проблема — «замусоривание» индекса полностью NULL'овыми записями. То есть записями, где индексируемое выражение в каждом из столбцов принимает значение NULL. Никакой практической пользы такие записи не несут, но вреда при каждой вставке добавляют.
Обычно они появляются, когда вы создаете в таблице FK-поле или связь по значению с опциональным заполнением. Потом накатываете индекс, чтобы FK отрабатывал быстро… и вот они. Чем реже связь будет заполнена, тем больше «мусора» попадет в индекс. Смоделируем:
В большинстве случаев, такой индекс может быть преобразован к условному, который еще и занимает меньше:
Чтобы найти такие индексы, нам необходимо знать реальное распределение данных — то есть все-таки прочитать весь контент таблиц и наложить его на соответствие WHERE-условиям входимости (сделаем это с помощью dblink), что может занять весьма продолжительное время.
Надеюсь, какие-то из приведенных в этой статье запросов помогут и вам.
Во-первых, конечно, или не будут, или не эффективно, или не все. Во-вторых, лишние индексы только добавят проблем с производительностью при записи.
Чаще всего такие ситуации происходят при «долгоиграющей» разработке, когда делается не заказной продукт по модели «написал разово, отдал, забыл», а, как в нашем случае, создается сервис с длинным жизненным циклом.
Доработки происходят итеративно силами множества распределенных команд, которые бывают разнесены не только в пространстве, но и во времени. И тогда, не зная всей истории развития проекта или особенностей прикладного распределения данных в его БД, можно легко «напортачить» с индексами. Но соображения и проверочные запросы под катом позволяют заранее предсказывать и обнаруживать часть проблем:
- неиспользуемые индексы
- префиксные «клоны»
- timestamp «в середине»
- индексируемый boolean
- массивы в индексе
- NULL-мусор
Самое простое — найти индексы, по которым вообще не было проходов. Только надо предварительно убедиться, что сброс статистики (
pg_stat_reset()) происходил достаточно давно, и вы не захотите удалить используемый «редко, но метко». Воспользуемся системным представлением pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;Но даже если индекс используется и не попал в эту выборку, это вовсе не значит, что он хорошо подходит для ваших запросов.
Для чего [не] подходят индексы
Чтобы понять, почему какие-то запросы «плохо ходят по индексу», задумаемся о структуре обычного btree-индекса — наиболее частого в природе экземпляра. Индексы из единственного поля обычно никаких проблем не создают, поэтому рассмотрим возникающие проблемы на составном из пары полей.
Предельно упрощенный способ, как его можно представить — это «слоеный пирог», где в каждом слое — упорядоченные деревья по значениям соответствующего по порядку поля.
Сразу становится понятно, что поле A упорядочено глобально, а B — только в рамках конкретного значения A. Давайте рассмотрим примеры условий, которые встречаются в реальных запросах, и как они будут «ходить» по индексу.
Хорошо: префикс-условие
Заметим, что индекс
btree(A, B) включает в себя «подиндекс» btree(A). Это значит, что все описанные ниже правила будут работать для любого префиксного индекса.То есть если вы создаете более сложный индекс, чем в нашем примере, что-то типа
btree(A, B, C) — можно считать, что у вас в базе автоматически «появляются»:btree(A, B, C)btree(A, B)btree(A)
А это означает, что «физическое» присутствие префикс-индекса в базе — избыточно в большинстве случаев. Ведь чем больше индексов приходится на запись таблицы — тем хуже для PostgreSQL, поскольку вызывает Write Amplification — на это еще Uber жаловался (а тут можно ознакомиться с анализом их претензий).
А если что-то мешает базе жить хорошо, стоит это найти и устранить. Посмотрим на примере:
CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A) -- префиксный #1
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A); -- префиксный #2Запрос поиска префиксных индексов
WITH sch AS (
SELECT
'public'::text sch -- schema
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
В идеале, вы должны получить пустую выборку, но смотрим — вот наши подозрительные группы индексов:
nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
Дальше уже сами решаете по каждой группе — стоит ли удалить более короткий индекс или более длинный вообще не нужен был.
Хорошо: все константы, кроме последнего поля
Если значения всех полей индекса, кроме последнего, заданы константами (в нашем примере это поле A) — индекс сможет использоваться нормально. При этом значение последнего поля может быть задано произвольным образом: константой, неравенством, интервалом, набором через
IN (...) или = ANY(...). А так же по нему можно сортировать.WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
Исходя из описанного выше про префиксные индексов, хорошо будет работать и это:
WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
Плохо: полный перебор «слоя»
При части запросов единственной схемой движения по индексу становится полный перебор всех значений в каком-то из «слоев». Повезет, если таких значений единицы — а если тысячи?..
Обычно такая проблема возникает, если в запросе использовано неравенство, в условии не определены предыдущие по порядку индекса поля или этот порядок нарушен при сортировке.
WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
Плохо: интервал или набор не в последнем поле
Как следствие из предыдущего — если на каком-то промежуточном «слое» надо найти несколько значений или их диапазон, а потом отфильтровать или отсортировать по лежащим «глубже» в индексе полям, — будут проблемы, если количество уникальных значений «в середине» индекса окажется большим.
WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
Плохо: выражение вместо поля
Иногда разработчик неосознанно превращает в запросе столбец во что-то другое — в некоторое выражение, индекса для которого нет. Это можно исправить, создав индекс от нужного выражения, или произведя обратное преобразование:
WHERE A - const1 [op] const2
исправляем:WHERE A [op] const1 + const2WHERE A::typeOfConst = const
исправляем:WHERE A = const::typeOfA
Учитываем кардинальность полей
Предположим, вам нужен индекс
(A, B), причем вы планируете выбирать только по равенству: (A, B) = (constA, constB). Идеальным было бы использование hash-индекса, но… Помимо нежурналирования (wal logging) таких индексов вплоть до версии 10, они еще и не могут существовать на нескольких полях:CREATE INDEX ON tbl USING hash(A, B);
-- ERROR: access method "hash" does not support multicolumn indexesВ общем, вы выбрали btree. Так как же лучше расположить в нем столбцы —
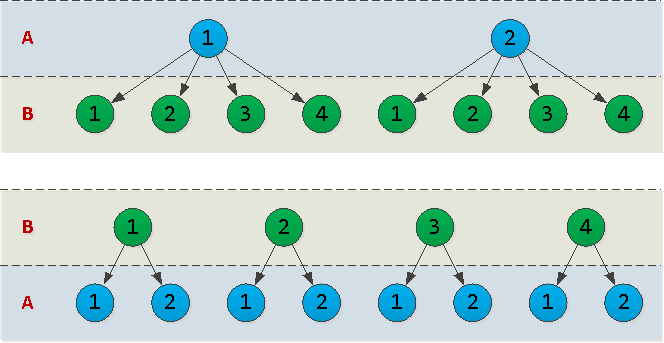
(A, B) или (B, A)? Чтобы ответить на этот вопрос, надо учесть такой параметр как кардинальность данных в соответствующем столбце — то есть как много уникальных значений в нем содержится.Давайте представим, что
A = {1,2}, B = {1,2,3,4}, и нарисуем схему дерева индекса для обоих вариантов:Фактически, каждый узел дерева, которое мы нарисовали, — страница в индексе. И чем их больше — тем больший дисковый объем будет занимать индекс, тем дольше будет чтение из него.
В нашем примере вариант
(A, B) имеет 10 узлов, а (B, A) — 12. То есть выгоднее ставить «первыми» поля, имеющие как можно меньше уникальных значений.Плохо: много и не к месту (timestamp «в середине»)
Ровно по этой причине всегда выглядит подозрительно, если в вашем индексе поле с заведомо большой вариативностью типа timestamp[tz] стоит не последним. Как правило, значения timestamp-поля монотонно возрастают, а следующие поля индекса имеют только одно значение в каждой временной точке.
CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A); -- что-то подозрительноеЗапрос поиска не-финальных timestamp[tz] в индексах
WITH sch AS (
SELECT
'public'::text sch -- schema
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
Тут мы анализируем сразу и типы самих входящих полей, и применяемые к ним классы операторов — поскольку полем индекса может оказаться какая-то timestamptz-функция вроде date_trunc.
nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
Плохо: слишком мало (boolean)
Обратной стороной этой же медали становится ситуация, когда в индексе оказывается boolean-поле, которое может принимать всего 3 значения:
NULL, FALSE, TRUE. Конечно, его присутствие имеет смысл, если вы хотите использовать его для прикладной сортировки — например, обозначив им тип узла в иерархии дерева — папка это или конечный лист («сначала папки»).CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type); -- индекс по иерархии
CREATE INDEX ON tbl(public, id); -- что-то подозрительное
Но, в большинстве случаев, это оказывается не так, и запросы ходят с каким-то конкретным значением boolean-поля. И тогда становится возможным заменить индекс с таким полем на его условную версию:
CREATE INDEX ON tbl(id) WHERE public;Запрос поиска boolean в индексах
WITH sch AS (
SELECT
'public'::text sch -- schema
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[ -- добавить пары-исключения по вкусу
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
Массивы в btree
Отдельным пунктом идут попытки «проиндексировать массив» с помощью btree-индекса. Это вполне возможно, поскольку к ним применимы соответствующие операторы:
Операторы упорядочивания массивов (<, >, = и т. д.) сравнивают содержимое массивов по элементам, используя при этом функцию сравнения для B-дерева, определённую для типа данного элемента по умолчанию, и сортируют их по первому различию. В многомерных массивах элементы просматриваются по строкам (индекс последней размерности меняется в первую очередь). Если содержимое двух массивов совпадает, а размерности различаются, результат их сравнения будет определяться первым отличием в размерностях.Но беда в том, что использовать-то его хотят с операторами включения и пересечения: <@, @>, &&. Конечно, так не работает — потому что для них нужны другие типы индексов. Как не работает такой btree и для функции доступа к конкретному элементу arr[i].Научимся находить и такие:
CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list); -- что-то подозрительное
Запрос поиска массивов в btree
WITH sch AS (
SELECT
'public'::text sch -- schema
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
NULL-записи в индексе
Последняя достаточно часто встречающаяся проблема — «замусоривание» индекса полностью NULL'овыми записями. То есть записями, где индексируемое выражение в каждом из столбцов принимает значение NULL. Никакой практической пользы такие записи не несут, но вреда при каждой вставке добавляют.
Обычно они появляются, когда вы создаете в таблице FK-поле или связь по значению с опциональным заполнением. Потом накатываете индекс, чтобы FK отрабатывал быстро… и вот они. Чем реже связь будет заполнена, тем больше «мусора» попадет в индекс. Смоделируем:
CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;В большинстве случаев, такой индекс может быть преобразован к условному, который еще и занимает меньше:
CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
Чтобы найти такие индексы, нам необходимо знать реальное распределение данных — то есть все-таки прочитать весь контент таблиц и наложить его на соответствие WHERE-условиям входимости (сделаем это с помощью dblink), что может занять весьма продолжительное время.
Запрос поиска NULL-записей в индексах
WITH sch AS (
SELECT
'public'::text sch -- schema
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20 -- меньше 1MB нас не интересуют
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$-- $q$ || quote_ident(nmt) || $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count -- минимум четверть NULL-записей
ORDER BY
1, 2;-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100% покрытие всех записей таблицы
index_null_prc | 90.00 -- из них 90% NULL-"мусора"
Надеюсь, какие-то из приведенных в этой статье запросов помогут и вам.
IvanVakhrushev
Спасибо! Позаимствую парочку идей для своей Java-библиотеки
pg-index-health