Введение
Знакомый многим интерфейс PCI Express или PCIe был доступен разработчикам систем на ПЛИС уже тогда, когда он только начинал распространяться в цифровой технике. В это время существовало решение, в котором программное ядро подключалось ко внешней микросхеме физического уровня [5]. Это позволяло создавать одноканальную линию PCIe со скоростью 2,5 гигатранзакций в секунду. В дальнейшем, благодаря развитию технологий, физический уровень интерфейса перекочевал в аппаратные блоки PCIe внутри самих ПЛИС; количество возможных каналов увеличилось до 8, а в ряде новых микросхем — и до 16; вслед за современными стандартами выросли возможные скорости передачи данных.
В то же время, в русскоязычных источниках по-прежнему затруднительно найти вспомогательные материалы по работе с аппаратными ядрами современных ПЛИС, не так и много информации доступно по самому интерфейсу PCIe. Руководство к аппаратным ядрам PCI Express подразумевает, что разработчик уже ознакомился со стандартом и понимает основы передачи данных между устройством и персональным компьютером (ПК). Однако обилие информации в самом стандарте PCIe не дает сразу же разобраться в том, какие шаги необходимо предпринять, чтобы успешно передать данные от устройства в память ПК или обратно. Чтобы получить более полную картину, немалую часть сведений приходится собирать по крупицам из разных источников. Для разработчиков систем на ПЛИС фирмы Intel сложность также заключается в том, что большинство доступных материалов и статей описывают работу с аппаратными ядрами ПЛИС фирмы Xilinx.
В данной статье автор постарается рассказать о том, что необходимо знать разработчику систем на ПЛИС для работы с интерфейсом PCI Express; рассмотрит особенности работы с аппаратными ядрами PCI Express ПЛИС V-й серии фирмы Intel в варианте Avalon-ST.
Уровни PCIe и виды пакетов
Несмотря на то, что PCI Express часто называют шиной, фактически данный интерфейс представляет собой сеть из устройств, связанных группами последовательных дуплексных каналов. Сама сеть PCI Express состоит из нескольких основных узлов: корень (Root), оконечная точка (Endpoint) и маршрутизатор (Switch) (рисунок 1). Для передачи данных только между двумя устройствами достаточно иметь корень и оконечную точку. В случае с современными ПК корень сети располагается на одной подложке вместе с ядрами центрального процессора. Вне зависимости от того, где находится корень PCIe, он связан с системной памятью.
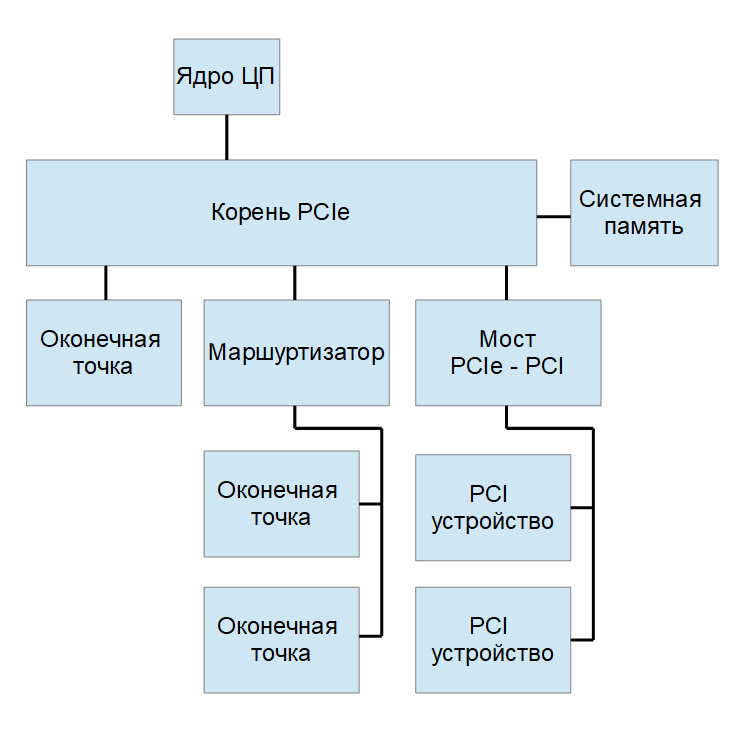
Рисунок 1 — Сеть PCIe
Протокол передачи данных PCIe разделяется на три уровня: уровень транзакций (Transaction Layer), канальный уровень (Data Link Layer) и физический уровень (Physical Layer). Данные по интерфейсу передаются в виде пакетов. Обобщенный вид пакетов представлен на рисунке 2.

Рисунок 2 — Обобщенный вид пакетов PCIe
На уровне транзакций любой пакет (TLP) состоит как минимум из заголовка. В зависимости от типа пакета за заголовком могут следовать данные — полезное содержимое пакета. Также в конце пакета может быть добавлена дополнительная контрольная сумма. Существуют следующие основные виды пакетов уровня транзакций (таблица 1):
Таблица 1 — Виды пакетов уровня транзакций
| № п. | Вид пакета | Наименование типа пакета по спецификации |
|---|---|---|
| 1 | Запрос на чтение памяти | Memory Read Request |
| 2 | Запрос на запись в память | Memory Write Request |
| 3 | Запрос на чтение пространства I/O | I/O Read Request |
| 4 | Запрос на запись в пространство I/O | I/O Write Request |
| 5 | Конфигурационный запрос на чтение | Configuration Read Request |
| 6 | Конфигурационный запрос на запись | Configuration Write Request |
| 7 | Ответ на чтение | Completion |
| 8 | Сообщение | Message |
На канальном уровне к каждому пакету уровня транзакций добавляются порядковый номер пакета и канальная контрольная сумма. Канальный уровень также формирует собственные виды пакетов (DLLP), к которым относятся (таблица 2):
Таблица 2 — Виды пакетов канального уровня
| № п. | Вид пакета | Наименование типа пакета по спецификации |
|---|---|---|
| 1 | Подтверждение пакета уровня транзакций | TLP Ack |
| 2 | Отклонение пакета уровня транзакций | TLP Nack |
| 3 | Управление питанием | Power Management |
| 4 | Управление потоком данных | Flow Control |
Наконец, физический уровень дополняет пакеты символами начала и конца пакетов, которые заимствованы из стандарта IEEE 802.3. Для пакетов уровня транзакций используются символы K27.7 и K29.7 соответственно; для пакетов канального уровня — символы K28.2 и K29.7.
При работе с аппаратными ядрами ПЛИС разработчику необходимо формировать только пакеты уровня транзакций; пакеты канального и физического уровней формируются блоками ядра.
Маршрутизация пакетов уровня транзакций
В общей сложности разные типы пакетов могут попадать от отправителя к получателю тремя способами:
- маршрутизация по адресу;
- маршрутизация по идентификатору;
- косвенная маршрутизация.
Связь между способом маршрутизации и типом пакета уровня транзакций представлена в таблице 3.
Таблица 3 — Соответствие способа маршрутизации и типа пакета
| №п | Способ маршрутизации | Тип пакета |
|---|---|---|
| 1 | Маршрутизация по адресу | Запросы на чтение памяти и запись в память. Запросы на чтение пространства I/O и запись в пространство I/O |
| 2 | Маршрутизация по идентификатору | Конфигурационные запросы на чтение и запись. Сообщения с маршрутизацией по ID. Ответы на чтение |
| 3 | Косвенная маршрутизация | Сообщения с маршрутизацией без ID |
Обращение к оконечной точке. Передача данных между оконечной точкой и системной памятью
Каждая оконечная точка обладает собственным Конфигурационным пространством (Configuration Space), где располагаются различные регистры команд и состояния. В их числе — регистры базового адреса (Base Address Register) или BAR. При инициализации оконечных точек BIOS или операционная система просматривает BAR оконечных точек, чтобы определить, какой размер памяти и под какое пространство требуется для каждой оконечной точки. Затем в каждый активный BAR записывается начальный адрес выделенного участка системной памяти. В результате, оконечная точка приобретает адрес, по которому можно отправлять соответствующие запросы. Обыкновенно, в оконечной точке формируют карту регистров, которую привязывают к выделенным участкам памяти.
Также каждая оконечная точка, а точнее — логическое устройство внутри, получает свой уникальный идентификатор, который состоит из трех частей: номер шины, номер устройства, номер логического устройства (функции).
Таким образом система располагает информацией, достаточной для того, чтобы обмениваться данными с оконечной точкой. Тем не менее, передача данных с помощью запросов в BAR имеет низкое быстродействие. Во-первых, для BAR с шириной в 32 бита полезная длина запросов ограничена одним двойным словом (DWORD); для BAR с шириной 64 бита — двумя двойными словами. Во-вторых, каждый запрос происходит при участии центрального процессора. Чтобы снизить нагрузку на центральный процессор, а также увеличить размер каждой посылки, необходимо, чтобы оконечная точка самостоятельно перемещала данные в системную память или обратно. Для этого оконечная точка должна знать, по каким адресам системной памяти она может записывать или читать данные.
С учетом перечисленного, общую схему передачи данных между оконечной точкой и системной памятью можно представить в следующем виде:
- драйвер оконечной точки выделяет в системной памяти буферы для записи данных;
- драйвер формирует в системной памяти набор адресов и размеров буферов — дескрипторов буферов для записи данных;
- драйвер оконечной точки записывает адрес набора дескрипторов в регистры устройства, привязанные к областям BAR;
- драйвер оконечной точки программирует регистры контроля передачи данных, привязанные к областям BAR;
- оконечная точка посылает запрос на чтение системной памяти, чтобы получить набор дескрипторов для записи в системную память;
- оконечная точка посылает запросы на запись в системную память и наполняет буферы хранения данных;
- оконечная точка информирует центральный процессор и/или драйвер о том, что передача данных закончена, с помощью прерывания или записи в область памяти, определенную драйвером;
- на протяжении всего времени работы оконечная точка отвечает на входящие запросы на чтение и реагирует на сообщения от корня PCIe.
Содержимое пакетов уровня транзакций
На этапе, когда драйвер конфигурирует регистры оконечной точки, в зависимости от типа адресного пространства, связанного с BAR, оконечная точка получат запрос на запись в память (рисунок 3) или запрос на запись в пространство I/O. Если во время конфигурации регистров драйвер читает какой-либо регистр, оконечная точка также получает соответствующие запросы на чтение (рисунок 4).

Рисунок 3 — Пример запроса на запись в память длиной в 1 DW
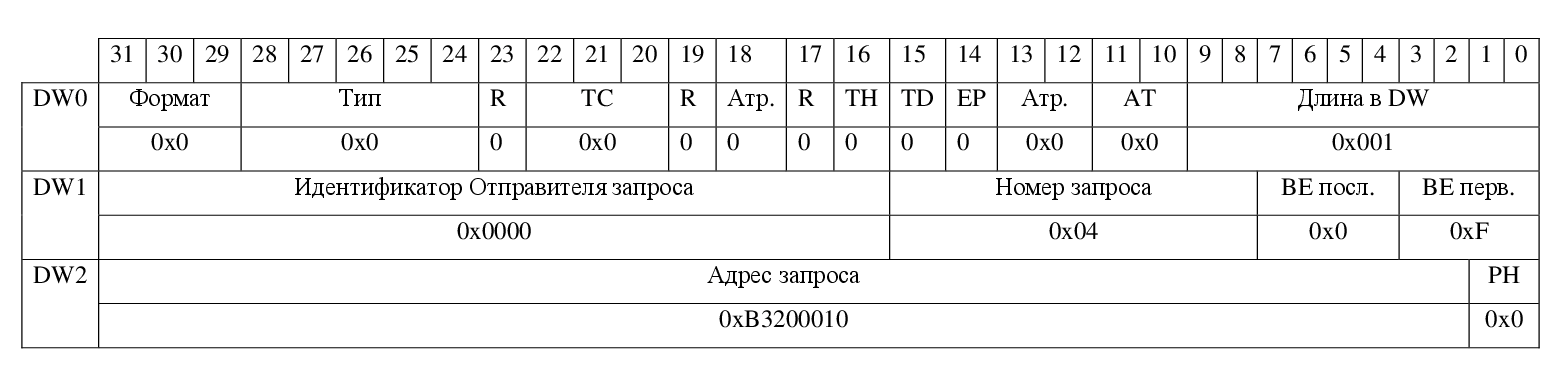
Рисунок 4 — Пример запроса на чтение из памяти длиной в 1 DW
В отличие от запросов на запись или чтение памяти, запросы в пространство I/O обладают рядом ограничений. Во-первых, как запросы на запись, так и чтение, требуют ответа от получателя. Это ведет к тому, что скорость передачи данных с помощью запросов в пространство I/O становится много ниже, чем допускает теоретическая пропускная способность PCIe. Во-вторых, адрес запросов пространства I/O ограничен разрядностью в 32 бита, что не позволяет обращаться к фрагментам системной памяти за пределами 4 ГБ. В-третьих, запросы пространства I/O не могут превышать одно двойное слово и не могут использовать несколько виртуальных каналов для транспортировки. По этим причинам запросы на запись и чтение в пространство I/O в дальнейшем рассматриваться не будут. Тем не менее, содержимое заголовков запросов на запись/чтение памяти и пространства I/O отличается только рядом полей, поэтому структуры пакетов, показанные на рисунках 3, 4, применимы и к запросам в пространство I/O.
Когда оконечная точка или корень PCIe получает запрос на чтение памяти или пространства I/O, устройство обязано отправить ответ. Если отправитель запроса не получит ответ в течение определенного времени, это приведет к ошибке ожидания ответа. Если устройство по каким-то причинам не может отправить запрошенные данные, оно должно сформировать ответ с ошибкой. Возможными причинами могут быть: получатель не поддерживает данный запрос (Unsupported Request); получатель не готов принять конфигурационный запрос и просит повторить его позднее (Configuration Request Retry Status), произошла внутренняя ошибка, из-за которой получатель не может ответить и отклоняет запрос (Completer Abort).
Форматы успешного ответа на запрос чтения и ответа с ошибкой о неподдерживаемом запросе представлены на рисунках 5, 6.

Рисунок 5 — Пример успешного ответа на чтение
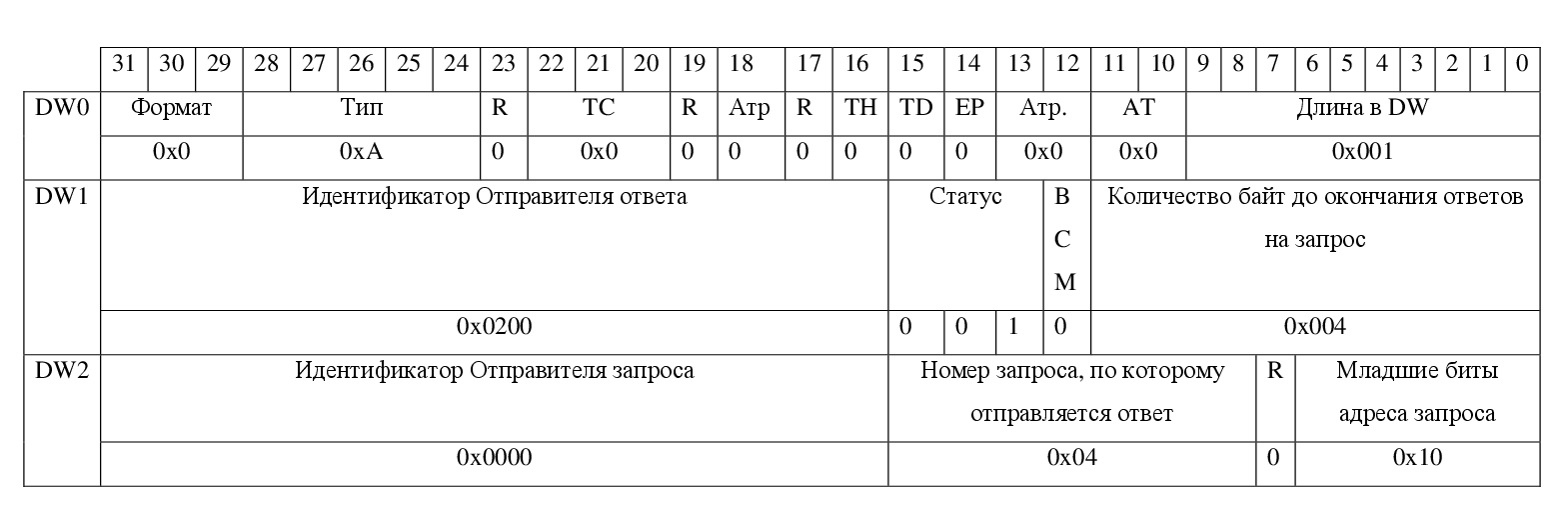
Рисунок 6— Пример ответа о неподдерживаемом запросе
В то время, когда оконечная точка обращается в область памяти в пределах 4 ГБ, формат заголовков пакетов не отличается от заголовков, показанных на рисунках 3, 4. Для запросов записи или чтении памяти за пределами 4 ГБ в заголовке используется дополнительное двойное слово со старшими разрядами целевого адреса (рисунок 7).
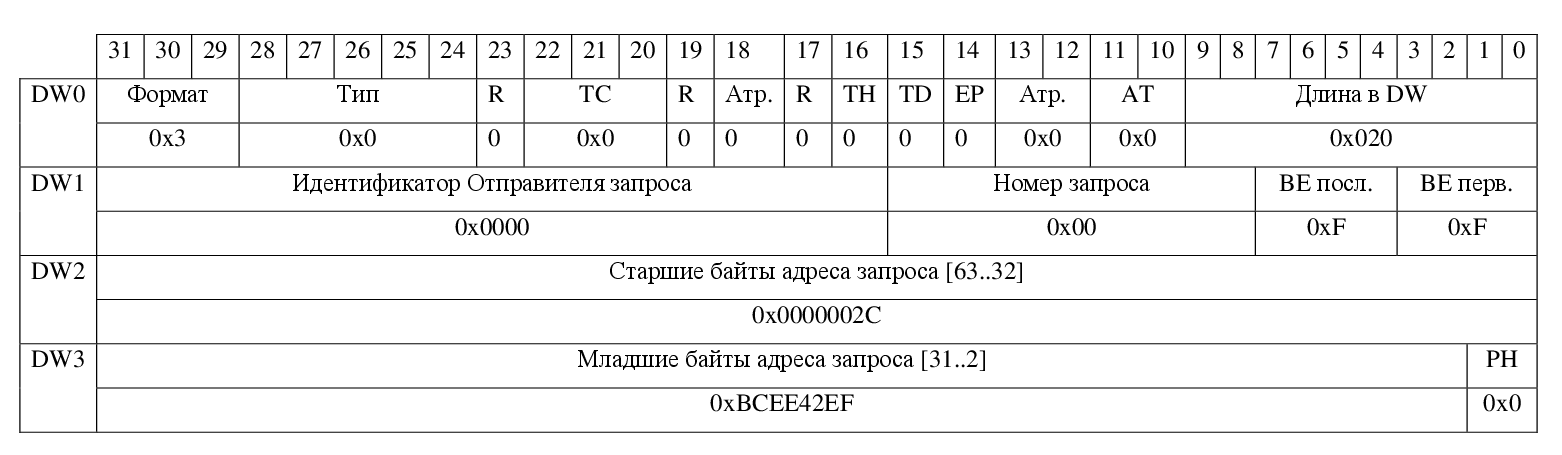
Рисунок 7 — Пример заголовка запроса на запись 128 байт
Пояснения к сокращенным названиям полей заголовков пакетов представлены в таблице 4.
Таблица 4 — Перечень сокращений для полей заголовков
| № п. | Обозначение поля | Название поля | Назначение |
|---|---|---|---|
| 1 | TC | Категория трафика ? Traffic Class | Определяет принадлежность к виртуальному каналу |
| 2 | Атр. | Атрибуты | Устанавливают порядок очередности пакетов: строгий, нестрогий, очередность только по ID, нестрогая очередность вместе с адресацией по ID. |
| 3 | TH | Наличие подсказки обработки пакетов ? TLP Processing Hint | Показывает, есть ли подсказка по обработке пакета в битах [1..0] двойного слова с младшими байтами адреса. |
| 4 | TD | Наличие на уровне транзакций контрольной суммы пакета ? TLP Digest | Показывает, является последнее двойное слово в пакете контрольной суммой или нет. |
| 5 | EP | Наличие ошибки целостности данных пакета | Показывает, нарушена целостность данных пакета или нет. |
| 6 | AT | Трансляция адреса ? Address Translation | Определяет, должен ли адрес быть транслирован: адрес не транслирован, запрос трансляции, адрес транслирован |
| 7 | BE | Активные байты в первом и последнем двойных словах ? Byte Enable | Определяет положение активных байт внутри первого и последнего двойных слов |
| 8 | PH | Подсказка по обработке пакета ? Processing Hint | Подсказывает получателю пакета, как должен использоваться пакет, а также ? структуру данных |
| 9 | BCM | Наличие изменения числа байт | Показывает, было ли изменено количество байт в пакете. Флаг может устанавливать только отправитель в лице PCI-X устройства |
В случае, если оконечная точка, чтобы сообщить о каком-либо событии, использует прерывания, она также должна сформировать соответствующий пакет. Всего в PCIe может использоваться три вида прерываний:
- унаследованные прерывания (Legacy Interrupts или INT);
- прерывания в виде сообщений (Message Signaled Interrupts или MSI);
- расширенные прерывания в виде сообщения (Message Signaled Interrupts Extended или MSI-X).
Унаследованные прерывания INT используются для совместимости с теми системами, которые не поддерживают прерывания в виде сообщений. Фактически данный вид прерываний представляет собой сообщение (пакет типа Message), которое имитирует работу физической линии прерывания. По заданному событию, оконечная точка посылает сообщение корню PCIe о том, что прерывание INT было активировано, а затем ожидает действий от обработчика прерываний. До тех пор, пока обработчик прерываний не выполнит заданное действие, прерывание INT находится в активированном состоянии. Унаследованные прерывания не позволяют определить источник события, что вынуждает обработчика прерываний последовательно просматривать все оконечные точки в дереве PCIe, чтобы обслужить это прерывание. Когда прерывание обслужено, оконечная точка посылает сообщение о том, что прерывание INT более неактивно. Аппаратные ядра ПЛИС по сигналу от логики пользователя самостоятельно формируют необходимые сообщения для прерываний INT, поэтому структура пакетов рассматриваться не будет.
Прерывания в виде сообщений вместе с их расширенным вариантом являются основным и обязательным видом прерываний в PCIe. Оба вида прерываний, по сути, представляют собой запрос на запись в системную память с длиной в одно двойное слово. Отличие от обычного запроса заключается в том, что адрес записи и содержимое пакета выделяются для каждого устройства на этапе конфигурации системы. При этом адресатом становится локальный контроллер прерываний (Local Advanced Programmable Interrupt Controller — LAPIC) внутри центрального процессора. При использовании данного вида прерываний не требуется последовательно опрашивать все устройства в дереве PCIe. Более того, если система разрешает устройству использовать несколько векторов прерываний, каждому вектору можно сопоставить своё событие. В совокупности это позволяет сократить время процессора на обработку прерываний и увеличить общее быстродействие системы.
Прерывания MSI позволяют формировать до 32 отдельных векторов. Конкретное количество зависит от возможностей оконечной точки. При этом, система может разрешить использовать только часть векторов. На этапе конфигурации система записывает адрес прерывания и начальные данные для записи в специальные регистры Конфигурационного пространства оконечной точки. Все активные прерывания используют один и тот же адрес. Но для каждого вектора оконечная точка изменяет биты начальных данных. Для примера, пусть оконечная точка поддерживает максимум 4 вектора прерываний, в системе разрешено использовать все 4 вектора, а начальные данные для записи — 0x4970. Тогда чтобы сформировать первый вектор, оконечная точка передает начальные данные неизменными. Для второго вектора устройство изменяет первый бит и передает число 0x4971. Для третьего и четвертого векторов устройство будет передавать числа 0x4972 и 0x4973 соответственно.
Аппаратные ядра ПЛИС самостоятельно формируют пакет с прерыванием MSI по сигналу от логики пользователя. Однако перед тем, как скомандовать ядру отправить прерывание, логика пользователя также должна предоставить содержимое пакета для требуемого вектора на специальный интерфейс ядра.
Прерывания MSI-X позволяют формировать до 2048 отдельных векторов. В соответствующих регистрах Конфигурационного пространства оконечная точка указывает, в каком из адресных пространств BAR и с каким смещением от базового адреса находятся таблица прерываний (рисунок 8) и таблица флагов ожидающих прерываний (Pending Bit Array ? PBA, рисунок 9), а также — размеры обеих таблиц. Система записывает в каждую строчку таблицы прерываний отдельный адрес и данные для записи, а также разрешает или запрещает использовать конкретный вектор через первый бит поля Vector Control. По заданному событию оконечная точка выставляет флаг в таблице флагов ожидающих прерываний. Если в поле Vector Control для данного прерывания не выставлена маска, оконечная точка отправляет прерывание по адресу из таблицы прерываний с заданным содержимым пакета.

Рисунок 8 — Таблица векторов прерываний MSI-X

Рисунок 9 — Таблица флагов ожидающих прерываний
Аппаратные ядра ПЛИС не имеют специализированного интерфейса для прерываний MSI-X. Разработчик самостоятельно должен сформировать в пользовательской логике таблицу прерываний и таблицу флагов ожидающих прерываний. Пакет с прерыванием также полностью формируется пользователем и передается через общий интерфейс ядра вместе с другими видами пакетов. Формат пакета при этом, как уже было сказано выше, соответствует запросу на запись в системную память с длиной в одно двойное слово.
Особенности аппаратных ядер PCI Express ПЛИС V-й серии фирмы Intel в варианте Avalon-ST
Несмотря на то, что аппаратные ядра PCI Express ПЛИС разных производителей реализует схожий функционал, отдельные интерфейсы ядер или порядок их работы могут отличаться.
Аппаратные ядра PCI Express ПЛИС V-й серии фирмы Intel представлены в двух вариантах исполнения: с интерфейсом Avalon-MM и интерфейсом Avalon-ST. Последний, хотя и требует от разработчика больше усилий, позволяет получить наибольшую пропускную способность. По этой причине ядро с интерфейсом Avalon-MM рассматриваться не будет.
Документация на ядро PCI Express с интерфейсом Avalon-ST достаточно подробно описывает параметры ядра, входные и выходные сигналы. Тем не менее, ядро имеет ряд особенностей, на которые разработчику следует обратить внимание.
Первая группа особенностей связана со способами, которые позволяют сконфигурировать ПЛИС в течение 100 мс по требованиям PCIe. Помимо параллельной загрузки типа FPP, разработчику предлагаются такие способы как конфигурация через протокол (Configuration via Protocol — CvP) и автономный режим работы ядра (autonomous mode). Разработчик обязательно должен убедиться в том, что конфигурация через протокол или автономный режим ядра поддерживается для выбранной скорости PCIe (параметр «Lane Rate»). Для конфигурации через протокол соответствующую информацию можно найти в документации на ядро. В случае с автономным режимом такой информации нет, поэтому необходимо скомпилировать проект. Если автономный режим ядра не поддерживается для текущей скорости ядра, Quartus выдаст соответствующую ошибку (рисунок 10).

Рисунок 10 — Ошибка компиляции ядра PCIe под автономный режим
Если разработчик планирует задействовать конфигурацию через протокол, он также должен обратить внимание на то, к какому ядру ПЛИС подключен соединитель PCIe. Это особенно актуально, если разработчик использует не готовую плату, а собственное устройство. В ПЛИС с несколькими аппаратными ядрами PCIe только одно ядро позволяет задействовать CvP. Местоположение ядра с поддержкой CvP указано в документации серии ПЛИС.
Вторая группа особенностей относится к собственно интерфейсу передачи данных Avalon-ST. Именно этот интерфейс используется, для передачи пакетов уровня транзакций между логикой пользователя и ядром.
На приемной стороне ядро имеет два сигнала, которые позволяют пользователю приостанавливать выдачу принятых пакетов: сигнал «rx_st_mask» и сигнал «rx_st_ready».
С помощью сигнала «rx_st_ready» разработчик может приостанавливать выдачу всех типов пакетов. Однако если активировать этот сигнал, ядро остановит выдачу пакетов только через два такта рабочей частоты. Следовательно, во время активации сигнала логика пользователя должна быть готова принять дополнительный объем данных. Если, к примеру, разработчик использует буфер в виде FIFO, он должен избегать переполнения буфера. В противном случае, часть содержимого пакета будет потеряна.
С помощью сигнала «rx_st_mask» разработчик приостанавливает выдачу запросов, на которые необходимо отправлять ответы. Этот сигнал также не сразу останавливает выдачу пакетов. Согласно документации, после активации сигнала ядро может выдать вплоть до 10 запросов. Если логика пользователя активирует «rx_st_mask», а в буфере для обработки принятых пакетов будет недостаточно места, это может активировать и сигнал «rx_st_ready». В этой ситуации логика пользователя перестает считывать какие-либо пакеты из внутреннего буфера аппаратного ядра. Это не только переполняет буферы аппаратного ядра, но и нарушает требования очередности пакетов. Устройство обязано пропускать вперед запросы, не требующие ответа, и ответы на чтение. В противном случае канал передачи данных будет намертво заблокирован. По этой причине разработчику следует задействовать дополнительный буфер для обработки запросов с ответами и не позволять логике блокировать более приоритетные пакеты.
На передающей стороне проблемы могут вызвать сигналы «tx_st_valid» и «tx_st_ready». Если сигнал «tx_st_ready» активен, логике пользователя запрещается обнулять «tx_st_valid» в середине исходящего пакета. Это означает, что во время передачи разработчик обязан целиком предоставить содержимое пакета. Если источник данных работает медленнее, чем интерфейс ядра, логика пользователя должна накопить необходимый объем данных до начала пакета.
Как на приемной, так и на передающей стороне разработчику следует обратить внимание на порядок байт в заголовке и содержимом пакета, а также — выравнивание данных.
В пакете Avalon-ST аппаратного ядра, в пределах каждого двойного слова внутри заголовка пакета PCIe байты следуют от младшего к старшему; внутри содержимого пакета — от старшего к младшему. Разработчик должен использовать аналогичный порядок в исходящих пакетах для успешной передачи данных от оконечной точки к корню.
Интерфейс Avalon-ST аппаратного ядра выравнивает данные кратно 64 битам. В зависимости от ширины интерфейса Avalon-ST, длины заголовка пакета уровня транзакций и адреса пакета, ядро может добавлять пустое двойное слово между заголовком пакета и его содержимым. В свою очередь, при передаче данных логика пользователя должна заранее добавлять пустое двойное слово по аналогии с ядром. Это пустое двойное слово не учитывается в длине пакета и нужно лишь для правильной работы аппаратного ядра.
Следующая особенность связана со входящими ответами на чтение. В описании ядра сказано, что оно не пропускает входящие ответы, идентификатор которых не совпадает с исходящим запросом. В то же время, за временем ожидания ответов должна следить логика пользователя. Если время ожидания будет превышено, логика пользователя должна поднять флаг «cpl_err[0]» или «cpl_err[1]». Из документации неясно, как будет работать фильтрация в случае, когда оконечная точка посылает несколько запросов на чтение. Логика пользователя лишь сообщает ядру, что время ожидания истекло для одного из запросов, но не может передать ядру идентификатор этого запроса. Возникает вероятность того, что ядро может передать на сторону пользователя ответы для запроса с истекшим временем ожидания. Следовательно, разработчик должен сформировать собственный фильтр входящих ответов.
Напоследок, разработчикам настоятельно рекомендуется использовать информацию о доступных кредитах для исходящих пакетов. Документация на ядро говорит о том, что это необязательно, так как ядро проверяет кредиты и блокирует пакеты, когда кредитов становится недостаточно. Тем не менее, все типы пакетов поступают на ядро по единственному интерфейсу. Если буфер пакетов ядра переполнится, ядро опускает сигнал «tx_st_ready» в ноль. До тех пор, пока сигнал «tx_st_ready» не установится в единицу, логика пользователя в принципе не может отправлять какие-либо пакеты. Количество доступных кредитов обновляется через пакеты от устройства-партнера. Если логика пользователя не только часто пишет, но и читает, то падает скорость, с которой ядро обновляет счетчики лимитов. В конце концов страдает общая производительность системы.
Заключение
В статье были описаны общие принципы передачи данных по интерфейсу PCI Express, приведены форматы основных пакетов данных. Тем не менее, автор опустил такие составляющие интерфейса, как виртуальные каналы, контроль объема входящих ответов на чтение, нестрогая очередность пакетов. Данные темы подробно рассмотрены в ряде зарубежных источников [4, 6].
В статью также включены особенности аппаратных ядер PCI Express ПЛИС V-й серии фирмы Intel, с которыми автор столкнулся во время работы над контроллером интерфейса. Данный опыт может быть полезен другим разработчикам.
Список использованных источников
- A PCIe DMA Architecture for Multi-Gigabyte Per Second Data Transmission / L. Rota, M. Caselle, et. al. // IEEE TRANSACTIONS ON NUCLEAR SCIENCE, VOL. 62, NO. 3, JUNE 2015.
- An Efficient and Flexible Host-FPGA PCIe Communication Library / Jian Gong, Tao Wang, Jiahua Chen et. al. // 2014 24th International Conference on Field Programmable Logic and Applications.
- Design and Implementation of a High-Speed Data Acquisition Card Based on PCIe Bus / Li Mu-guo, Huang Ying, Liu Yu-zhi // ??????2013??32??7??
- Down to the TLP: How PCI express devices talk (Part I) / Eli Billauer
- Low-Cost FPGA Solution for PCI Express Implementation / Intel Corporation.
- Managing Receive-Buffer Space for Inbound Completions / Xilinx // Virtex-7 FPGA Gen3 Integrated Block for PCI Express v4.3, Appendix B
- PCIe Completion Timeout / Altera Forum
- PCIe packet in cyclone VI GX / Altera Forum
- PCIe simple transaction / Altera Forum
- PCIe w/ Avalon ST: Equivalent of ko_cpl_spc_vc0? / Altera Forum
- Point me in the right Direction – PCIe / Altera Forum
- Request timeouts in PCIE / Altera Forum
- The High-speed Interface Design Based on PCIe of the Non-cooperative Receiver Verification Platform / Li Xiao-ning, Yao Yuan-cheng and Qin Ming-wei // 2016 International Conference on Mechanical, Control, Electric, Mechatronics, Information and Computer
- PCI Express Base Specification Revision 3.0 / PCI-SIG
- Stratix V Avalon-ST Interface for PCIe Solutions / Intel Corporation
- Cyclone V Avalon-ST Interface for PCIe Solutions / Intel Corporation

lelik363
Первоисточник, наверное, забыли указать?
Как вы проверяете вашу «прошиву» на соответствие стандарту?
neerps Автор
Статья стала попыткой совместить ту информацию, что я встретил в разных источниках, и полного, добуквенного эквивалента, как мне показалось, у неё нет. Конечно, сейчас всё достаточно быстро меняется, и я мог что-то пропустить.
Я не стану отрицать, что в немалой степени опирался на формат материалов от Eli Billauer, например, в части примеров пакетов. В списке использованных источников есть ссылка на его статью. В своё время он проделал неплохую работу. Однако когда я впервые разбирался, а как вообще передавать данные, только лишь этих материалов мне не хватило. К примеру, Eli толком не рассматривает, как быть, если векторов прерываний несколько; не рассматривает случаи с большими потками данных, где прерывания могут съесть приличную порцию процессорного времени. На мой взгляд, общую картину того, что должно быть сделано, какой алгоритм обмена с драйвером в целом, намного лучше обрисовывают здесь и здесь. Но, опять же, это лишь кусочки всей мозаики, которые дополняют друг друга. Источника, в котором было бы собрано всё и сразу, я пока не видел.
Верификацию в статье я не затрагивал. Часть вопросов по соответствию решает канальный уровень ядра внутри ПЛИС. Тем не менее, для проверки своей логики без BFM не обойтись. Когда я писал контроллер, мне не удалось найти BFM от Altera под мою версию Quartus. Из условно-бесплатных нашел такой вариант. Какие-то косяки логики всё равно пришлось долавливать через экспорт воздействий из SignalTap в файл для тестбенча.
lelik363
В качестве первоисточника я подразумевал непосредственно спецификации от PCI-SIG.
На самом деле тестировать нужно на всех уровнях начиная с физики и выше.
neerps Автор
Да, действительно, конкретный стандарт я не указал. Исправлю.
В целом, получается так, что physical layer, data link layer и даже часть transcation layer предоставляются как есть, от изготовителя ПЛИС. Они берут на себя отладку того, что предоставляют. На стороне разработчика остаётся только дополнить это логикой под конкретное приложение. Все потенциальные проблемы будут именно здесь.