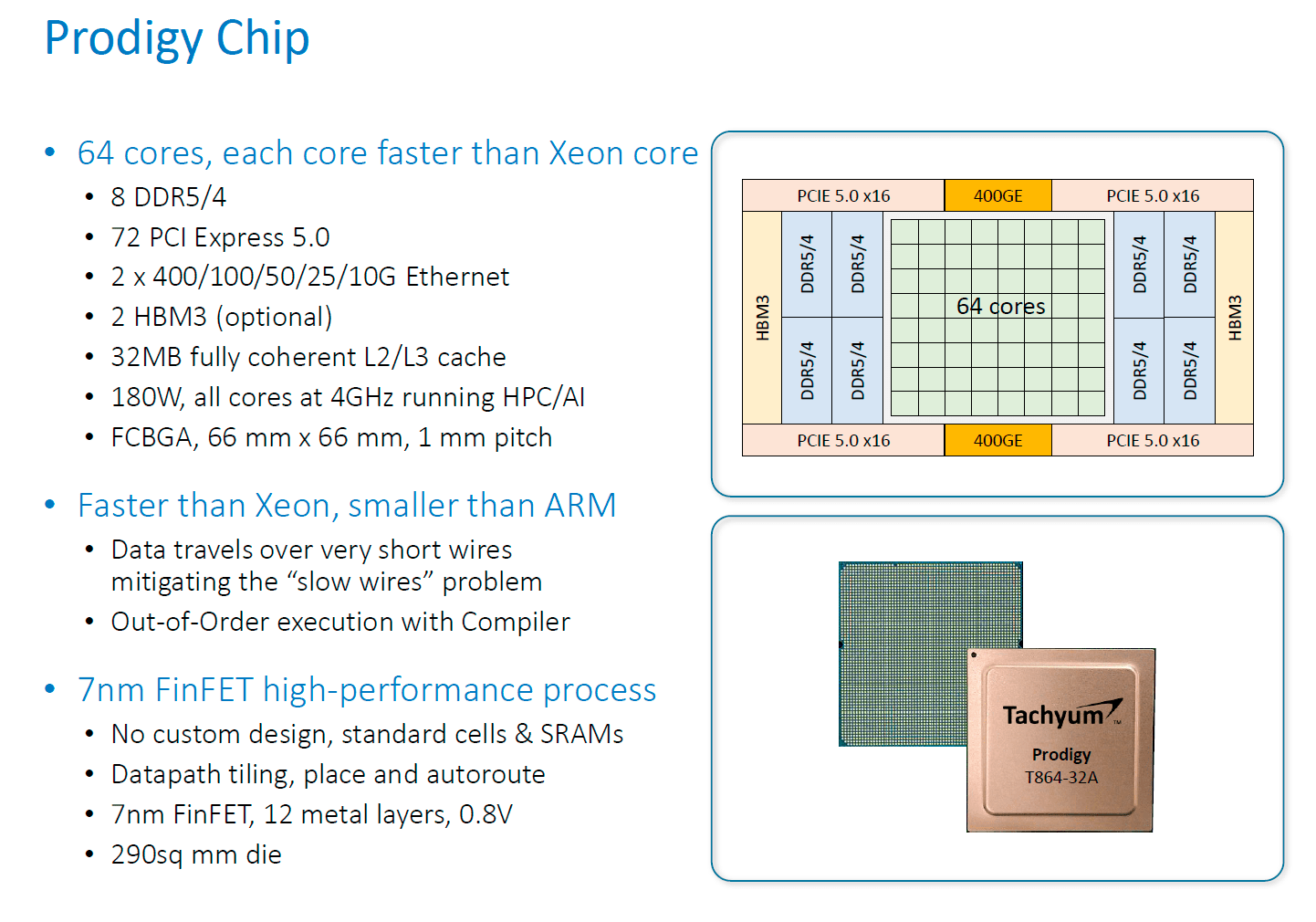
Мы живем в интересные времена. Мне кажется, следующие 2-3 года определят, куда пойдет развитие архитектуры на ближайшее десятилетие. Сейчас на рынке серверных процессоров есть несколько игроков, представляющих совершенно разные подходы к технологии. И это очень здорово (я даже затрудняюсь сказать, на какой слог падает ударение в последнем слове :))
.
А ведь еще лет 5-6 назад казалось, что время застыло и развитие остановилось. Упершись в разного рода ограничения (power wall, scalability wall и т.п.). Я немного рассказывал об этом вот здесь. Закон Мура был поставлен под сомнение и особо горячие теоретики предлагали ввести в него логарифмические поправки :) Доминация Intel на рынке серверных процессоров представлялась тогда незыблемой. AMD не оказывал серьезной конкуренции, GPGPU от NVidia выглядели сугубо нишевым продуктом, а попытки ARM пробиться на серверный рынок не имели успеха.
Все изменилось с развитием таких сегментов как Machine Learning и Artificial intelligence. GPGPU оказались куда лучше “приспособлены” к операциям свертки и перемножения матриц (особенно с небольшой точностью), чем CPU. Кроме того, NVidia сумела продемонстрировать рост числа транзисторов, даже опережающий закон Мура. Это привело к тому, что мир серверных архитектур стал биполярным. На одном конце – x86 СPU, latency-engine, приспособленная к скрывания латентностей out of order машина. Ee неоспоримым достоинством является отличная производительность на однопоточных приложениях (single- thread performance). Недостатком – огромная площадь и число транзисторов. На другом конце GPGPU – Throughput engine, большое количество несложных вычислительных элементов(EU). Здесь все наоборот – размер одного элемента невелик, что позволяет разместить на одном чипе большое их количество. С другой стороны – производительность однопоточных приложений оставляет желать…
Увы, попытки совместить СPU и GPU большой мощности в одном корпусе успеха пока не имели. Хотя бы по той причине, что подобный чип будет потреблять и рассеивать слишком много энергии. Поэтому сейчас в тренде дискретные решения. Я в них не особо верю по двум причинам. Во- первых архитектура становится более сложной и в ней появляются дополнительные затычки в виде шины, связывающей СPU и GPU, и неоднородной структуры памяти. Вторая сложность отчасти связана с первой, и состоит в том, что такие решения гораздо сложнее программировать. Каждая из существующих моделей программирования акселераторов (CUDA от NVidia, DPC++ от Intel, OpenCL или OpenMP) имеет свои достоинства и недостатки. В то же время ни одна из них не является ни универсальной, ни доминирующей.
Мне кажется, что с точки зрения развития архитектуры верный шаг был сделан компанией AMD, представившей процессор Rome. За счет компактности ядра (по сравнению с Intel) в одном корпусе удалось разместить больше ядер. Впрочем, одного этого мало – для того чтобы такое решение масштабировалось по производительности необходимо позаботиться о правильной коммуникации между ядрами (uncore) и качестве параллельных рантаймов. Инженерам AMD удалось решить обе задачи и получить очень конкурентные результаты на одном из важнейших индустриальных бенчмарков – SPEC CPU. Решение от AMD находится между полюсами, представленными Nvidia и Intel. Но оно куда ближе к последнему. Это все еще то же самое “большое ядро”. “Золотая середина” между полярными подходами, как мне кажется, требует большего количества более компактных ядер. И из ныне существующих архитектур ARM имеет наилучшие шансы занять эту нишу.

Так почему же ARM именно от Huawei? Я для себя нашел такой ответ: с возрастанием числа ядер на чипе, значимость производительности одного ядра снижается (но до определенного предела), а важность коммуникаций между ядрами и с памятью возрастает. А коммуникации –это та область, где Huawei является мировым лидером. Именно дизайн uncore (а не только и даже не столько ядра) будет определять производительность системы. И здесь, как мне думается, у нас неплохие шансы.
Однако идеальные архитектуры существуют только в вакууме. В реальности нужно всегда соотноситься с количеством и структурой существующего на серверном рынке программного обеспечения. А оно годами писалось и оптимизировалось под X86. Потребуется много времени и усилий, чтобы сделать его более “дружественным” к архитектуре ARM. Предстоит гигантская работа как в области программных инструментов (компиляторы, библиотеки, рантаймы) так и в области адаптации приложений (аpplication engineering). Но я верю, что дорогу осилит идущий.
.
А ведь еще лет 5-6 назад казалось, что время застыло и развитие остановилось. Упершись в разного рода ограничения (power wall, scalability wall и т.п.). Я немного рассказывал об этом вот здесь. Закон Мура был поставлен под сомнение и особо горячие теоретики предлагали ввести в него логарифмические поправки :) Доминация Intel на рынке серверных процессоров представлялась тогда незыблемой. AMD не оказывал серьезной конкуренции, GPGPU от NVidia выглядели сугубо нишевым продуктом, а попытки ARM пробиться на серверный рынок не имели успеха.
Все изменилось с развитием таких сегментов как Machine Learning и Artificial intelligence. GPGPU оказались куда лучше “приспособлены” к операциям свертки и перемножения матриц (особенно с небольшой точностью), чем CPU. Кроме того, NVidia сумела продемонстрировать рост числа транзисторов, даже опережающий закон Мура. Это привело к тому, что мир серверных архитектур стал биполярным. На одном конце – x86 СPU, latency-engine, приспособленная к скрывания латентностей out of order машина. Ee неоспоримым достоинством является отличная производительность на однопоточных приложениях (single- thread performance). Недостатком – огромная площадь и число транзисторов. На другом конце GPGPU – Throughput engine, большое количество несложных вычислительных элементов(EU). Здесь все наоборот – размер одного элемента невелик, что позволяет разместить на одном чипе большое их количество. С другой стороны – производительность однопоточных приложений оставляет желать…
Увы, попытки совместить СPU и GPU большой мощности в одном корпусе успеха пока не имели. Хотя бы по той причине, что подобный чип будет потреблять и рассеивать слишком много энергии. Поэтому сейчас в тренде дискретные решения. Я в них не особо верю по двум причинам. Во- первых архитектура становится более сложной и в ней появляются дополнительные затычки в виде шины, связывающей СPU и GPU, и неоднородной структуры памяти. Вторая сложность отчасти связана с первой, и состоит в том, что такие решения гораздо сложнее программировать. Каждая из существующих моделей программирования акселераторов (CUDA от NVidia, DPC++ от Intel, OpenCL или OpenMP) имеет свои достоинства и недостатки. В то же время ни одна из них не является ни универсальной, ни доминирующей.
Мне кажется, что с точки зрения развития архитектуры верный шаг был сделан компанией AMD, представившей процессор Rome. За счет компактности ядра (по сравнению с Intel) в одном корпусе удалось разместить больше ядер. Впрочем, одного этого мало – для того чтобы такое решение масштабировалось по производительности необходимо позаботиться о правильной коммуникации между ядрами (uncore) и качестве параллельных рантаймов. Инженерам AMD удалось решить обе задачи и получить очень конкурентные результаты на одном из важнейших индустриальных бенчмарков – SPEC CPU. Решение от AMD находится между полюсами, представленными Nvidia и Intel. Но оно куда ближе к последнему. Это все еще то же самое “большое ядро”. “Золотая середина” между полярными подходами, как мне кажется, требует большего количества более компактных ядер. И из ныне существующих архитектур ARM имеет наилучшие шансы занять эту нишу.
Так почему же ARM именно от Huawei? Я для себя нашел такой ответ: с возрастанием числа ядер на чипе, значимость производительности одного ядра снижается (но до определенного предела), а важность коммуникаций между ядрами и с памятью возрастает. А коммуникации –это та область, где Huawei является мировым лидером. Именно дизайн uncore (а не только и даже не столько ядра) будет определять производительность системы. И здесь, как мне думается, у нас неплохие шансы.
Однако идеальные архитектуры существуют только в вакууме. В реальности нужно всегда соотноситься с количеством и структурой существующего на серверном рынке программного обеспечения. А оно годами писалось и оптимизировалось под X86. Потребуется много времени и усилий, чтобы сделать его более “дружественным” к архитектуре ARM. Предстоит гигантская работа как в области программных инструментов (компиляторы, библиотеки, рантаймы) так и в области адаптации приложений (аpplication engineering). Но я верю, что дорогу осилит идущий.




easyman
Вроде как, да.
Я бы изменил заголовок, это Linux (Android и серверные применения) надо готовиться
www.ixbt.com/news/2020/05/02/windows-huawei-harmonyos-2-0.html
Можете пролить свет на эту ОС?
vvvphoenix Автор
Я все таки больше серверный человек. А серверный мир все же очень консервативен. Harmony — безусловно хорошее начинание. Но думаю, что оно скорее увидит свет в мире ПК. Серверные люди вряд ли скоро уйдут с Linux…