–X86 – это исторически сложившееся недоразумение,– мэтр и в 80 не утратил полемического задора.
– Вообще-то ей принадлежит 95% серверного рынка, – вяло откликнулся я. Мне не хотелось вступать в спор на сто раз заезженную тему
– А я уже запутался в этих префиксах, — не унимался академик. – 15 байт на инструкцию, это немыслимо!
– Ну, не ice, конечно. Но у кого лучше-то?
– Да у кого угодно, хотя бы у ARM-a.
– Я все же не понимаю. Cложения с умножениями должны быть?
– Должны.
– И сдвиги c логическими операциями?
– Да.
– И загрузки с сохранениями тоже. Какая разница как они называются и кодируются?
Как обычно, правоту учителя я осознал много позже. Когда тоскливым зимним вечером сел писать декодер команд, чтобы как то себя развлечь. Простенький декодер для ARM мне удалось изобразить на VHDL (а знаю я его так себе) за пару дней. Правда, каюсь, у меня была шпаргалка. :)

Для X86 не удалось ни за неделю, ни за две, ни за месяц… Даже для базового набора.
Разница здесь даже не только в RISC (Reduced Instruction Set Computing) для ARM и CISC (Complex Instruction Set) для X86. Разница скорее в пути исторического развития. Больше 40 лет назад, а началось все в 1978 году, X86 ISA (Instruction Set Architecture) была вполне себе компактным набором команд со своей внутренней логикой. Но время шло, росла разрядность шин, расширялись регистры (включая SIMD), перманентно возрастало число команд. Тут один паренёк сделал интересную попытку просто посчитать число инструкций в Х86. То ли ему лень было открывать мануал и считать их, то ли он знал о существовании “безымянных” опкодов (команд, у которых даже названия нет), то ли верил во всемогущество логики. Как легко понять, логика оказалась бессильна. :) Кстати, я пытался найти график роста числа X86 инструкций по годам (или по поколениям). Пока не смог (может, есть у кого?). Зато нашел вот такую картинку.
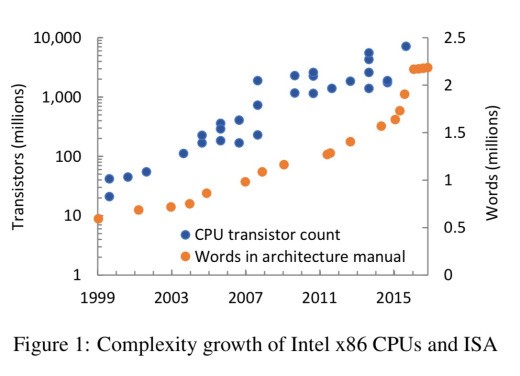
Если честно, я не знаю, сколько сейчас в X86 ISA инструкций. Но хорошо помню все те, в разработку которых сам вкладывался, при этом не отдавая себе отчета в том, что каждый новый бит в ISA снабжается ярлыком “хранить вечно”. А «творцов» вроде меня в Intel было несколько тысяч. И битов для того, чтобы закодировать все их фантазии постоянно не хватало. :) К существующему набору команд добавлялись все новые префиксы: REX, VEX… Последнее четырехбайтовое (EVEX) расширение было введено для AVX-512. К слову, весь набор команд АRM (даже с учетом SVE) убирается в эти самые 4 байта. ARM изначально пошел другим путем, строя свою систему команд на базовых принципах простоты, компактности и расширяемости.
Разницу можно понять, если перейти с точки зрения программиста на точку зрения circuit designer. А она как известно состоит в том, что транзистор – отличная вещь, но переключается медленно, а энергию рассеивает безбожно. И при прочих равных, лучше бы их было поменьше. А теперь взгляните на алгоритм декодирования x86 инструкций(та задача, которую я пытался решить).
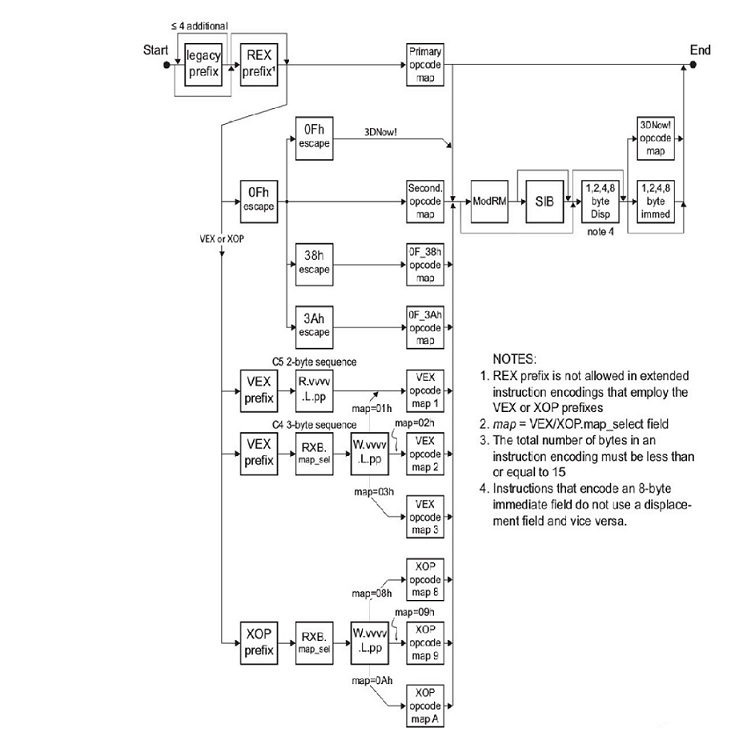
И, как говорится, почувствуйте разницу во входных трактах (front end) для ARM и X86. Тут можно возразить, что front end – это совсем небольшая часть ядра, всего около 10%. Да, но не надо забывать, что вся эта логика умножается ещё на количество ядер на чипе. А это уже серьезно.
Eщё одно соображение, что front end – как раз та часть, которая ответственна за backward compatibility. Вы можете смело перелопатить или даже выкинуть back end. Intel, кстати, воспользовался этим в начале 2000-х, заменив архитектуру NetBurst (P4) на Core-M (P3). А вот front end сильно сократить не удастся. Хотя иногда очень хочется, потому что из существующей X86 ISA сейчас используется около 20%. Остальное – пережитки прошлого.
Другой недостаток огромной длины инструкций – относительно частые промахи в instruction cache. Грубо говоря, при равном размере кэшей, количество промахов будет тем больше, чем больше длина инструкции. Конечно, размер кэшей можно увеличивать. Но опять же, это транзисторы, которых могло бы не быть, будь инструкции покороче. По этой же причне я очень настороженно отношусь к разного рода VLIW (Very Long Instruction World) архитектурам. Впрочем, они обладают еще и тем недостатком, что для них очень сложно разрабатывать компиляторы. Тему компиляторов я до сего момента сознательно избегал, поскольку сам никогда их не разрабатывал. Хотелось бы послушать, что скажут знающие люди о прелестях разработки компиляторов для RISC, CISC и VLIW.
И все же, несмотря на огромный накопленный груз legacy, а может быть и благодаря ему, разработчики X86 оказались правы в главном. Принцип backward compatibility свято соблюдается в архитектуре с самого начала. Весь существующий софт работает на новом железе «из коробки». Именно это позволило построить столь глубокую и развитую экосистему вокруг архитектуры. И остается только снять шапку перед инженерами Intel и AMD, которые вопреки отнюдь не идеальному дизайну ISA, на протяжении многих лет сохраняют лидерство в серверном сегменте. Однако, груз legacy становится все тяжелее.
– Вообще-то ей принадлежит 95% серверного рынка, – вяло откликнулся я. Мне не хотелось вступать в спор на сто раз заезженную тему
– А я уже запутался в этих префиксах, — не унимался академик. – 15 байт на инструкцию, это немыслимо!
– Ну, не ice, конечно. Но у кого лучше-то?
– Да у кого угодно, хотя бы у ARM-a.
– Я все же не понимаю. Cложения с умножениями должны быть?
– Должны.
– И сдвиги c логическими операциями?
– Да.
– И загрузки с сохранениями тоже. Какая разница как они называются и кодируются?
Как обычно, правоту учителя я осознал много позже. Когда тоскливым зимним вечером сел писать декодер команд, чтобы как то себя развлечь. Простенький декодер для ARM мне удалось изобразить на VHDL (а знаю я его так себе) за пару дней. Правда, каюсь, у меня была шпаргалка. :)
Для X86 не удалось ни за неделю, ни за две, ни за месяц… Даже для базового набора.
Разница здесь даже не только в RISC (Reduced Instruction Set Computing) для ARM и CISC (Complex Instruction Set) для X86. Разница скорее в пути исторического развития. Больше 40 лет назад, а началось все в 1978 году, X86 ISA (Instruction Set Architecture) была вполне себе компактным набором команд со своей внутренней логикой. Но время шло, росла разрядность шин, расширялись регистры (включая SIMD), перманентно возрастало число команд. Тут один паренёк сделал интересную попытку просто посчитать число инструкций в Х86. То ли ему лень было открывать мануал и считать их, то ли он знал о существовании “безымянных” опкодов (команд, у которых даже названия нет), то ли верил во всемогущество логики. Как легко понять, логика оказалась бессильна. :) Кстати, я пытался найти график роста числа X86 инструкций по годам (или по поколениям). Пока не смог (может, есть у кого?). Зато нашел вот такую картинку.
Если честно, я не знаю, сколько сейчас в X86 ISA инструкций. Но хорошо помню все те, в разработку которых сам вкладывался, при этом не отдавая себе отчета в том, что каждый новый бит в ISA снабжается ярлыком “хранить вечно”. А «творцов» вроде меня в Intel было несколько тысяч. И битов для того, чтобы закодировать все их фантазии постоянно не хватало. :) К существующему набору команд добавлялись все новые префиксы: REX, VEX… Последнее четырехбайтовое (EVEX) расширение было введено для AVX-512. К слову, весь набор команд АRM (даже с учетом SVE) убирается в эти самые 4 байта. ARM изначально пошел другим путем, строя свою систему команд на базовых принципах простоты, компактности и расширяемости.
Разницу можно понять, если перейти с точки зрения программиста на точку зрения circuit designer. А она как известно состоит в том, что транзистор – отличная вещь, но переключается медленно, а энергию рассеивает безбожно. И при прочих равных, лучше бы их было поменьше. А теперь взгляните на алгоритм декодирования x86 инструкций(та задача, которую я пытался решить).
И, как говорится, почувствуйте разницу во входных трактах (front end) для ARM и X86. Тут можно возразить, что front end – это совсем небольшая часть ядра, всего около 10%. Да, но не надо забывать, что вся эта логика умножается ещё на количество ядер на чипе. А это уже серьезно.
Eщё одно соображение, что front end – как раз та часть, которая ответственна за backward compatibility. Вы можете смело перелопатить или даже выкинуть back end. Intel, кстати, воспользовался этим в начале 2000-х, заменив архитектуру NetBurst (P4) на Core-M (P3). А вот front end сильно сократить не удастся. Хотя иногда очень хочется, потому что из существующей X86 ISA сейчас используется около 20%. Остальное – пережитки прошлого.
Другой недостаток огромной длины инструкций – относительно частые промахи в instruction cache. Грубо говоря, при равном размере кэшей, количество промахов будет тем больше, чем больше длина инструкции. Конечно, размер кэшей можно увеличивать. Но опять же, это транзисторы, которых могло бы не быть, будь инструкции покороче. По этой же причне я очень настороженно отношусь к разного рода VLIW (Very Long Instruction World) архитектурам. Впрочем, они обладают еще и тем недостатком, что для них очень сложно разрабатывать компиляторы. Тему компиляторов я до сего момента сознательно избегал, поскольку сам никогда их не разрабатывал. Хотелось бы послушать, что скажут знающие люди о прелестях разработки компиляторов для RISC, CISC и VLIW.
И все же, несмотря на огромный накопленный груз legacy, а может быть и благодаря ему, разработчики X86 оказались правы в главном. Принцип backward compatibility свято соблюдается в архитектуре с самого начала. Весь существующий софт работает на новом железе «из коробки». Именно это позволило построить столь глубокую и развитую экосистему вокруг архитектуры. И остается только снять шапку перед инженерами Intel и AMD, которые вопреки отнюдь не идеальному дизайну ISA, на протяжении многих лет сохраняют лидерство в серверном сегменте. Однако, груз legacy становится все тяжелее.











mark_ablov
У Intel было много ISA, как минимум с десяток. Ни одна, кроме x86 не выстрелила, увы.
vvvphoenix Автор
Горестная судьба Itaniuma вся прошла перед моими глазами. Поделка, впрочем не была так плоха чтоб с первого дня окрестить ее Itanicом. Однако, это EPIC…
quwy
А глубинная причина, кстати, в тех же словах: «backward compatibility». Которая была заявлена, но на практике не работала. Ну и VLIW опять же, еще ни одна VLIW-архитектура по-настоящему не взлетела.
vvvphoenix Автор
Зато энергию этот backward compatibility блок потреблял за троих :)
tyomitch
Внезапно, как раз Huawei и пытается продвигать собственные VLIW-архитектуры: www.zdnet.com/article/amazon-huawei-efforts-show-move-to-ai-centric-chips-continues
Ankoroid
Для очень специфических задач, а вовсе не для процессоров общего назначения.
Так то есть несколько VLIW архитектур (не Эльбрус), которые вполне живы — например ST2XX встречаются в спутниковых ресиверах.
tyomitch
Qualcomm Hexagon живее всех живых: наверное, в большинстве смартфонов стоит.
Мне просто показалось забавным, что VLIW хоронят в блоге Huawei, которая один из нынешних активистов VLIW-строения.
plus79501445397
ЕМНИП, x86 разрабатывалась «на скорую руку» как временная, а основной должна была стать iAPX 432
vvvphoenix Автор
:) Я тоже слышал эту байку. Не уверен, что правда, оч давно было. Но хорошо коррелирует с мыслью о том, что в истории X86 гораздо большую роль играло стечение обстоятельств, чем изначально заложенная логика :)
beeruser
Это не байка.
«Stephen Morse: Father of the 8086 Processor»
www.pcworld.com/article/146917/article.html
Или вот ещё момент оттуда, про порядок байт, если кому лень читать статью:
mvv-rus
Ну, вообще-то, little endian порядок байт в слове был и в архитектурах весьма распространенных в те времена миникомпьютеров от DEC — PDP-11 и VAX-11. Так что насчет того, что концепции разных порядков байтов не существовали бы — это автор, наверное, всё же погорячился.
PS Правда, у этих концепций тогда был бы шанс не дожить до нашего времени — может, он это имел в виду?
mpa4b
Были архитектуры, где правильно выбранный порядок байт упрощал или ускорял работу процессора. Были — где наоборот, замедлял. И были же — те, где на него пофиг было процессору. примеры:
LDA ADDR,X, где процессор побайтно читает 16-битное число, прибавляет к нему 8-битный индексный регистр и с полученным адресом выходит на шину прочитать аргумент. порядок байт выбран неправильно (почему — см. ниже)ну и соглашусь, что уже в i8086, mc68000 и далее — порядок байт перестал играть какую-либо роль. например архитектура ARMv7A позволяет переключать порядок байт прям в пользовательской программе, инструкциями
SETEND BE/LE.dmitrmax
У PDP-11 не little endian, а PDP endian
vvvphoenix Автор
Подумал о том, что ARM — это консорциум вендоров. А Интел -одна компания, пусть и большая. И решения там принимают люди. Очень умные. Но людям свойственно ошибаться. Поэтому в истории X86 так много было странных решений. Просто эти решения принимались гораздо меньшим числом людей. Иногда вообще одним человеком
tyomitch
Почему это ARM — консорциум? Одна компания, намного меньше Intel.
dmitrmax
Консорциум вендоров. То есть куча компаний, которые применяют ARM в своих чипах.
tyomitch
И в чём отличие от Intel?
dmitrmax
Чипы с архитектурой x86 на настоящий момент производятся только двумя компании в сколь-либо заментном количестве.
dmitrmax
На мой взгляд, little endian гораздо логичнее. Big endian это всего лишь попытка натянуть на АЛУ привычную нам запись чисел слева направо.
tyomitch
Не стоит забывать, что «привычная нам запись чисел слева направо» позаимствована у арабов, которые пишут справа налево, т.е. в естественном порядке от младших разрядов к старшим (little-endian).
dmitrmax
С чего вы взяли, что она позаимствована от арабов? Арабские цифры на самом деле индийский. Арабы используют другие цифры.
vvvphoenix Автор
Вот что подумал — arm — консорциум вендоров. А Интел — одна компания. И решения в ней принимает гораздо меньшее число людей. А людям свойственно ошибаться. И поэтому в x86 гораздо больше странных решений…
mark_ablov
У меня, кстати, лежит плата под iAPX 432. Может дойдут руки пощупать этот процессор в живую.
vvvphoenix Автор
Может не надо оживлять призраков. Мало ли… :)
vvvphoenix Автор
Может все же не стоит оживлять призраков? Мало ли… :)