 Привет, Хаброжители! Генеративное моделирование — одна из самых обсуждаемых тем в области искусственного интеллекта. Машины можно научить рисовать, писать и сочинять музыку. Вы сами можете посадить искусственный интеллект за парту или мольберт, для этого достаточно познакомиться с самыми актуальными примерами генеративных моделей глубокого обучения: вариационные автокодировщики, генеративно-состязательные сети, модели типа кодер-декодер и многое другое.
Привет, Хаброжители! Генеративное моделирование — одна из самых обсуждаемых тем в области искусственного интеллекта. Машины можно научить рисовать, писать и сочинять музыку. Вы сами можете посадить искусственный интеллект за парту или мольберт, для этого достаточно познакомиться с самыми актуальными примерами генеративных моделей глубокого обучения: вариационные автокодировщики, генеративно-состязательные сети, модели типа кодер-декодер и многое другое.Дэвид Фостер делает понятными и доступными архитектуру и методы генеративного моделирования, его советы и подсказки сделают ваши модели более творческими и эффективными в обучении. Вы начнете с основ глубокого обучения на базе Keras, а затем перейдете к самым передовым алгоритмам.
- Разберитесь с тем, как вариационные автокодировщики меняют эмоции на фотографиях.
- Создайте сеть GAN с нуля.
- Освойте работу с генеративными моделями генерации текста.
- Узнайте, как генеративные модели помогают агентам выполнять задачи в рамках обучения с подкреплением.
- Изучите BERT, GPT-2, ProGAN, StyleGAN и многое другое.
Цели и подходы
В этой книге рассматриваются ключевые методы, доминировавшие в ландшафте генеративного моделирования в последние годы и позволившие добиться впечатляющего прогресса в творческих задачах. Кроме знакомства с базовой теорией генеративного моделирования, в этой книге мы будем создавать действующие примеры некоторых ключевых моделей, заимствованных из литературы, и шаг за шагом рассмотрим реализацию каждой из них.
На протяжении всей книги вам будут встречаться короткие поучительные истории, объясняющие механику некоторых моделей. Пожалуй, один из лучших способов изучения новой абстрактной теории — сначала преобразовать ее во что-то менее абстрактное, например в рассказ, и только потом погружаться в техническое описание. Отдельные разделы теории будут более понятны в контексте, включающем людей, действия и эмоции, а не в контексте таких довольно абстрактных понятий, как, допустим, нейронные сети, обратное распространение или функции потерь.
Рассказ и описание модели — это обычный прием объяснения одного и того же с двух точек зрения. Поэтому, изучая какую-то модель, иногда будет полезно вернуться к соответствующему рассказу. Если же вы уже знакомы с конкретным приемом, то просто получайте удовольствие, обнаруживая в рассказах параллели с каждым элементом модели!
В первой части книги представлены ключевые методы построения генеративных моделей, включая обзор глубокого обучения, вариационных автокодировщиков и генеративно-состязательных сетей. Во второй части эти методы применяются для решения нескольких творческих задач (рисование, сочинение рассказов и музыки) с помощью таких моделей, как CycleGAN, моделей типа кодер-декодер и MuseGAN. Мы увидим, как генеративное моделирование можно использовать для оптимизации выигрышной стратегии игры (World Models), рассмотрим самые передовые генеративные архитектуры, доступные сегодня: StyleGAN, BigGAN, BERT, GPT-2 и MuseNet.
Наивная байесовская параметрическая модель
Наивная байесовская параметрическая модель использует простое предположение, чтобы резко уменьшить количество параметров для оценки. Мы наивно предполагаем, что каждый признак xjне зависит от любого другого признака
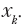 В отношении набора данных, полученных на Ирме, это означает, например, что выбор цвета волос не влияет на выбор типа одежды, а выбор типа очков не влияет на выбор прически. Более формально, для всех признаков
В отношении набора данных, полученных на Ирме, это означает, например, что выбор цвета волос не влияет на выбор типа одежды, а выбор типа очков не влияет на выбор прически. Более формально, для всех признаков 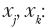
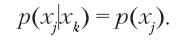
Это известно как наивное байесовское предположение. Чтобы применить его, сначала используется цепное правило вероятности для записи функции плотности в виде произведения условных вероятностей:
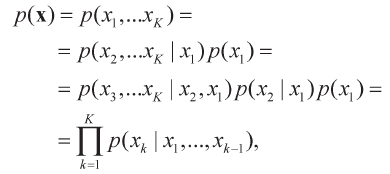
где K — общее число признаков (то есть пять в примере с планетой Ирм).
Теперь применим наивное байесовское предположение, чтобы упростить последнюю строку:
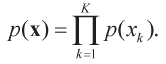
Это — наивная байесовская модель. Задача сводится к оценке параметров
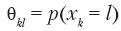 для каждого признака в отдельности и их перемножению для определения вероятности любой возможной комбинации.
для каждого признака в отдельности и их перемножению для определения вероятности любой возможной комбинации.Сколько параметров нужно оценить в нашей задаче? Для каждого признака нужно оценить параметр для каждого значения, которое может принять этот признак. Следовательно, в примере с планетой Ирм эта модель определяется всего 7 + 6 + 3 + 4 + 8 – 5 = 23 параметрами.
Оценка максимального правдоподобия
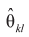 вычисляется как
вычисляется как
где
— число раз, когда признак k принимает значение l в наборе данных, а N = 50 — общее число наблюдений.В табл. 1.2 показаны вычисленные параметры для набора данных с планеты Ирм. Чтобы найти вероятность, с которой модель сгенерирует некоторое наблюдение x, достаточно перемножить вероятности отдельных признаков. Например:

Обратите внимание: эта комбинация отсутствует в исходном наборе данных, но наша модель определяет для нее ненулевую вероятность, а значит, вполне может сгенерировать ее. Кроме того, вероятность этой комбинации выше, чем, например, (длинная стрижка, прямые волосы; рыжий; круглые очки; футболка с круглым вырезом; синий01), потому что белый цвет одежды появляется в наборе наблюдений чаще, чем синий.
То есть наивная байесовская модель способна выявить некоторую структуру данных и использовать ее для создания новых образцов, отсутствующих в исходном наборе. Модель оценила вероятность встретить каждое значение признака независимо от других, поэтому при использовании наивного байесовского предположения можно перемножить эти вероятности, чтобы построить полную функцию плотности,
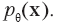

На рис. 1.8 показаны 10 наблюдений, выбранных моделью.
Для этой простой задачи наивное байесовское предположение о независимости признаков является разумным и, следовательно, дает хорошую генеративную модель.
Теперь посмотрим, что получится, если это предположение оказывается ошибочным.

Привет, Ирм! Продолжение
Вы испытываете определенное чувство гордости, глядя на десять новых творений, созданных вашей наивной байесовской моделью. Воодушевленные своим успехом, вы обращаете внимание на другую сторону задачи, и на этот раз она не выглядит такой же простой.
Набор данных с незамысловатым названием Planet Pixel, который был вам предоставлен, не содержит пяти высокоуровневых признаков, которые вы видели выше (цвет волос, тип аксессуара и т. д.), а только значения 32 ? 32 пикселов, составляющих каждое изображение. То есть каждое наблюдение теперь имеет 32 ? 32 = 1024 признака и каждый признак может принимать любое из 256 значений (отдельные цвета в палитре).
Изображения из нового набора данных показаны на рис. 1.9, а выборка значений пикселов для первых десяти наблюдений показана в табл. 1.3.
Вы решаете попробовать наивную байесовскую модель еще раз, на этот раз обученную на наборе данных пикселов. Модель оценит параметры максимального правдоподобия, определяющие распределение цвета каждого пиксела, чтобы на основе этого распределения сгенерировать новые наблюдения. Однако, закончив модель, вы понимаете, что что-то пошло не так. Вместо новых образцов моды модель вывела десять похожих друг на друга изображений, на которых нельзя различить ни аксессуары, ни четкие признаки прически или одежды (рис. 1.10). Почему так случилось?


Об авторе
Дэвид Фостер — соучредитель Applied Data Science, консалтинговой компании в области данных, разрабатывающей индивидуальные решения для клиентов. Получил степень магистра по математике в Тринити-колледже, Кембридж, Великобритания, и степень магистра по операционным исследованиям в Уорвикском университете.
Выиграл несколько международных конкурсов по машинному обучению, в том числе конкурс на приобретение продуктов InnoCentive Predicting Product Purchase. Был удостоен первой награды за визуализацию, позволившую фармацевтической компании в США оптимизировать выбор места для клинических испытаний.
Активный участник онлайн-сообществ, интересующихся data science, и автор нескольких успешных статей в блоге, посвященных глубокому обучению, включая «How To Build Your Own AlphaZero AI Using Python and Keras».
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Глубокое обучение
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.