Привет.
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
Это самый простой список того, что должен уметь парсер. По-хорошему, он еще должен отправлять информацию об ошибках, если таковые были найдены в исходном документе.
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Для начала, нужно разделить работу парсера на два этапа:
Это что касается непосредственно парсинга документа. Про поиск элементов я буду говорить чуть позже далее в этой главе.
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
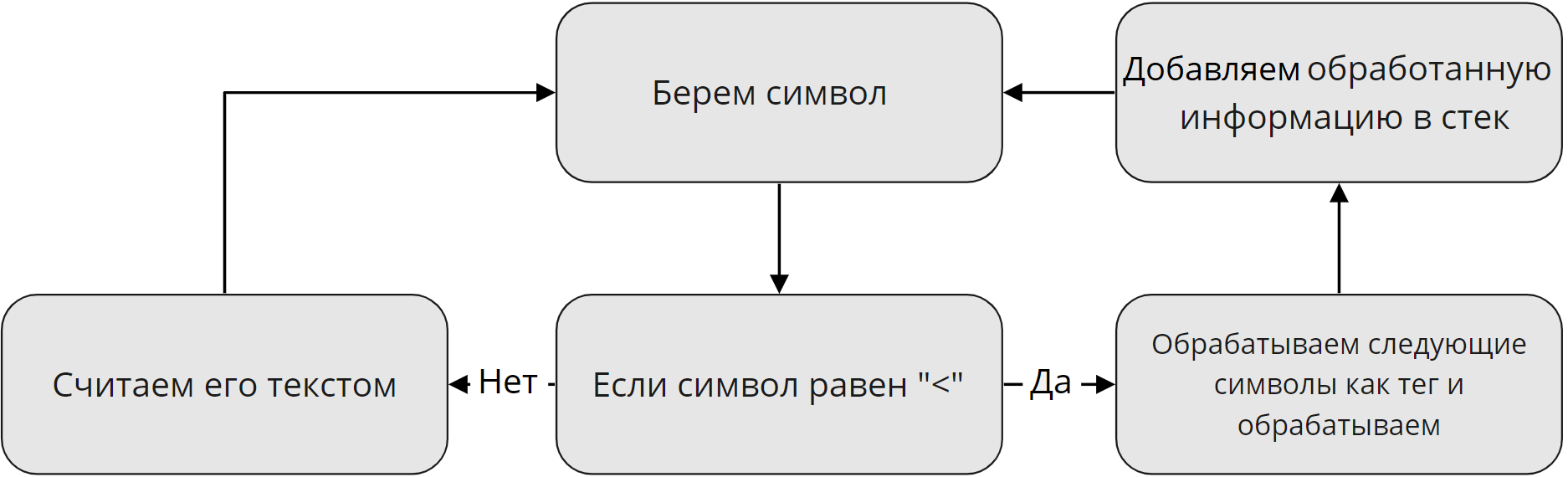
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего "<" идет тег, а не текст? Об этом я расскажу в следующих частях. Пока что этого вполне хватит.
Также тут стоит уточнить. Логично, что в документе помимо тегов есть еще и текст. Говоря простым языком, если парсер найдет открывающий тег и если в нем будет текст, он запишет его после открывающего тега в виде отдельного тега. Такой тег будет считаться как одиночный и не будет участвовать в дальнейшей работе парсера.
Ну и второй этап. Самый сложный с точки зрения проектирования, и самый простой на первый взгляд с точки зрения понимания:
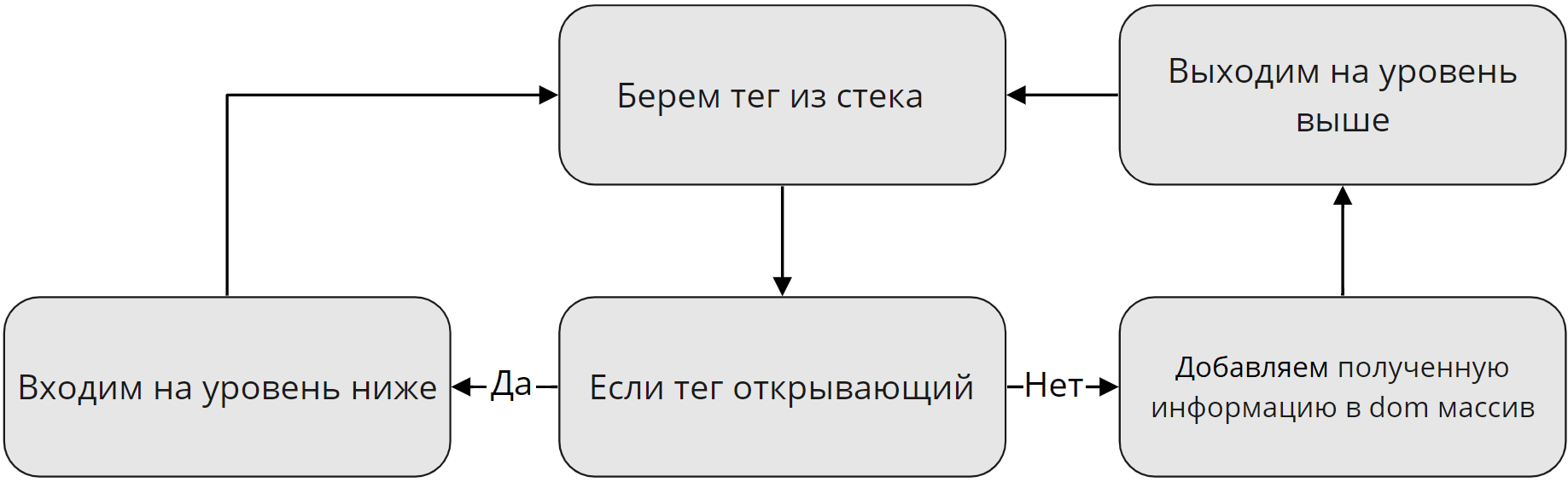
В данном случаи уровень означает уровень рекурсии. То есть если парсер нашел открывающий тег, он вызывает самого себя, «входит на уровень ниже», и так будет продолжаться до тех пор, пока не будет найден закрывающий тег. В этом случаи рекурсия выдает результат, «Выходит на уровень выше». Но, как обстоят дела с одиночными тегами? Такие теги считаются рекурсией ни как открывающие, ни как закрывающие. Они просто переходят в dom «Как есть».
В итоге у нас получится что-то вроде этого:
А теперь давайте поговорим про поиск элементов. Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
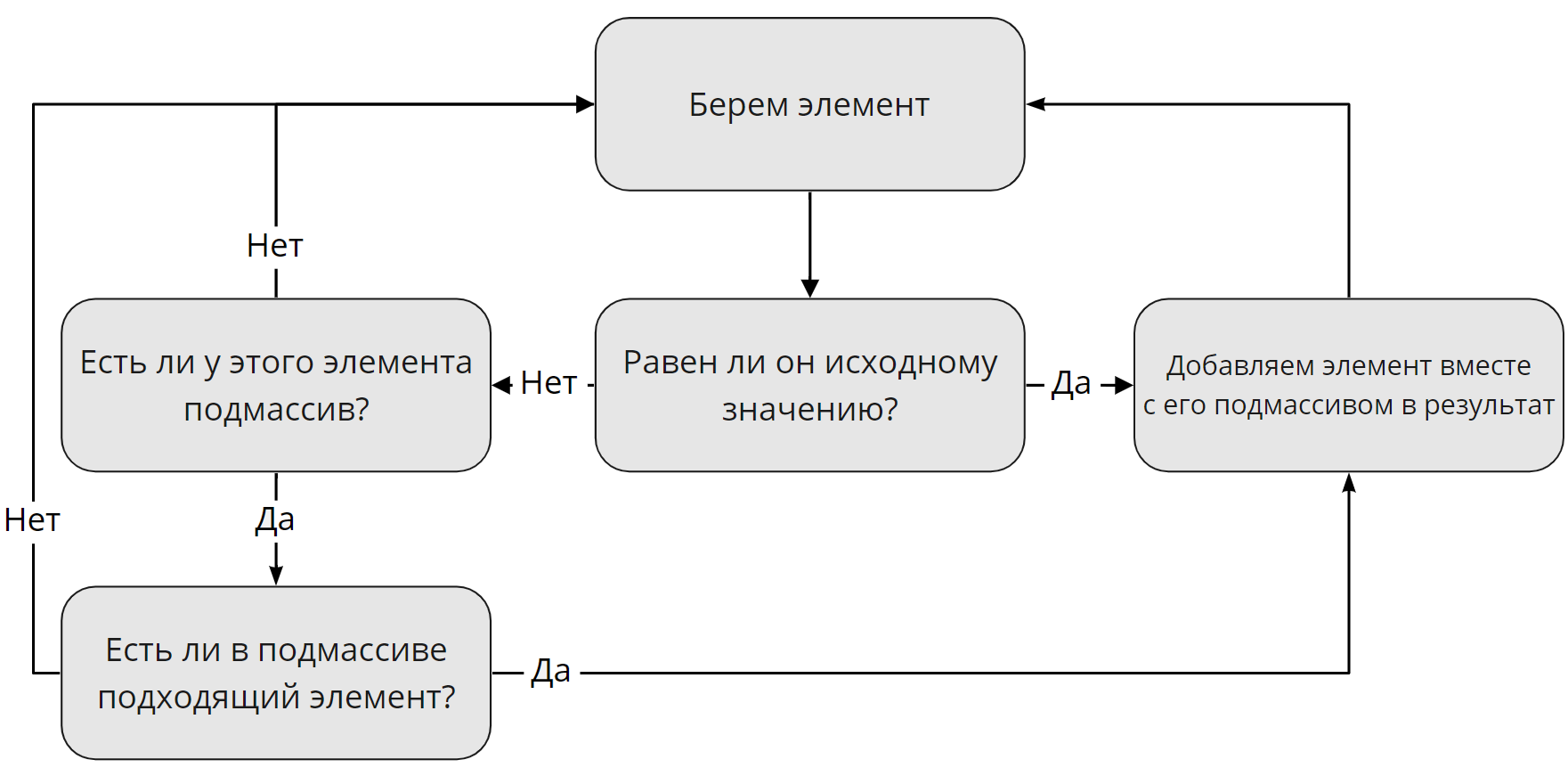
Немного уточнений. Под исходным значением я имел в виду название тега, «div» например. Также, если элемент не равен исходному значению, но у него есть подмассив с подходящим элементом, в результат запишется именно подходящий элемент с его подмассивом, если таковой существует.
Стоит также сказать, что у парсера будет функция, позволяющая искать определенный элемент в документе. Это заметно ускорит производительность парсера, что позволит ему выполняться быстрее. Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Хорошо, с поиском элементов разобрались, а как насчет children элементов? Тут тоже все просто: наш парсер будет брать все вложенные подмассивы найденных до этого элементов, если таковые существуют. Если таковых нет, парсер выведет пустой результат и пойдет дальше:
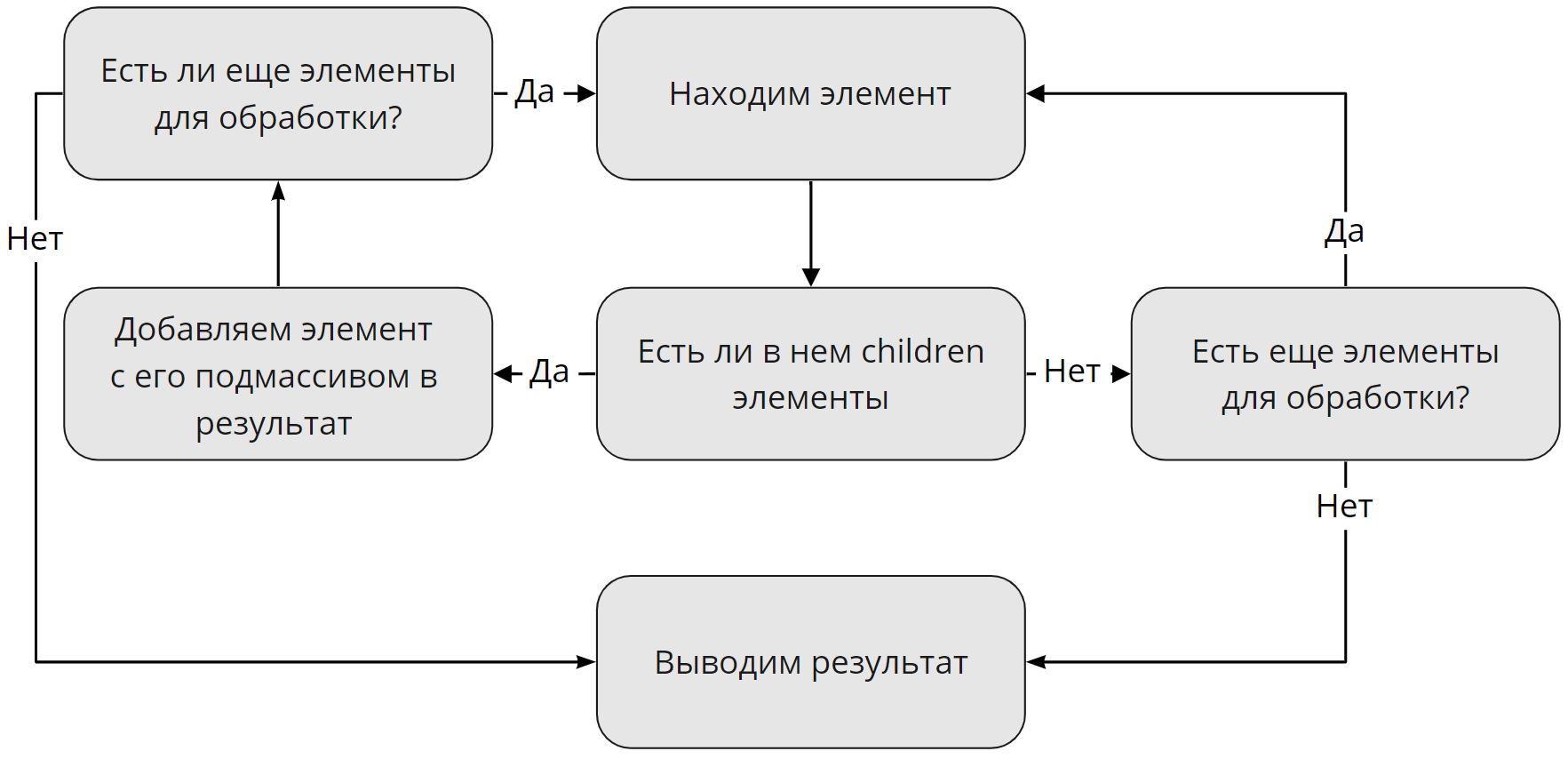
Тут говорить особо не о чем. Парсер просто будет брать весь полученный текст из подмассива и выводить его.
Документ может содержать ошибки, с которыми наш скрипт должен успешно справляться, либо, если ошибка критическая, выводить ее на экран. Тут будет приведен список всех возможных ошибок, о которых, в будущем, мы будем говорить:
В парсере теги script и style будут сразу же пропускаться, поскольку я не вижу смысл их записывать. С комментариями ситуация другая. Если вы захотите из записывать, то вы сможете включить отдельную функцию скрипта, и тогда он будет их записывать. Комментарии будут записываться точно так же как и текст, то есть как отдельный тег.
Эту статью скорее нужно считать небольшим экскурсом в тему парсеров html. Я ее написал для тех, кто задумывается над написанием своего парсера, либо для тех, кому просто интересно. Поверьте, это действительно весело!
Данная статья является первой вводной частью. В следующих частях этого цикла уже будет участвовать непосредственно код, и будет меньше картинок с алгоритмами(что прекрасно, потому что рисовать я их не умею). Stay tuned!
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Введение
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Что должен делать парсер?
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
- Проектировать dom-дерево на основе документа
- Если есть ошибки в документе, то он должен их решать
- Находить элементы в dom-дереве
- Находить children элементы
- Находить текст
Это самый простой список того, что должен уметь парсер. По-хорошему, он еще должен отправлять информацию об ошибках, если таковые были найдены в исходном документе.
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Разделяй и властвуй
Для начала, нужно разделить работу парсера на два этапа:
- Отделение обычного текста от тегов
- Сортировка всех полученных тегов в dom дерево
Это что касается непосредственно парсинга документа. Про поиск элементов я буду говорить чуть позже далее в этой главе.
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего "<" идет тег, а не текст? Об этом я расскажу в следующих частях. Пока что этого вполне хватит.
Также тут стоит уточнить. Логично, что в документе помимо тегов есть еще и текст. Говоря простым языком, если парсер найдет открывающий тег и если в нем будет текст, он запишет его после открывающего тега в виде отдельного тега. Такой тег будет считаться как одиночный и не будет участвовать в дальнейшей работе парсера.
Ну и второй этап. Самый сложный с точки зрения проектирования, и самый простой на первый взгляд с точки зрения понимания:
В данном случаи уровень означает уровень рекурсии. То есть если парсер нашел открывающий тег, он вызывает самого себя, «входит на уровень ниже», и так будет продолжаться до тех пор, пока не будет найден закрывающий тег. В этом случаи рекурсия выдает результат, «Выходит на уровень выше». Но, как обстоят дела с одиночными тегами? Такие теги считаются рекурсией ни как открывающие, ни как закрывающие. Они просто переходят в dom «Как есть».
В итоге у нас получится что-то вроде этого:
[0] => Array
(
[is_closing] =>
[is_singleton] =>
[pointer] => 215
[tag] => div
[0] => Array //открывается подмассив
(
[0] => Array
(
[is_closing] =>
[is_singleton] =>
[pointer] => 238
[tag] => div
[id] => Array
(
[0] => tjojo
)
[0] => Array //открывается подмассив
(
[0] => Array //Текст записывается в виде отдельного тега
(
[tag] => __TEXT
[0] => Привет!
)
[1] => Array
(
[is_closing] => 1
[is_singleton] =>
[pointer] => 268
[tag] => div
)
)
)
)
)
Что там насчет поиска элементов?
А теперь давайте поговорим про поиск элементов. Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
Немного уточнений. Под исходным значением я имел в виду название тега, «div» например. Также, если элемент не равен исходному значению, но у него есть подмассив с подходящим элементом, в результат запишется именно подходящий элемент с его подмассивом, если таковой существует.
Стоит также сказать, что у парсера будет функция, позволяющая искать определенный элемент в документе. Это заметно ускорит производительность парсера, что позволит ему выполняться быстрее. Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Поиск children элементов
Хорошо, с поиском элементов разобрались, а как насчет children элементов? Тут тоже все просто: наш парсер будет брать все вложенные подмассивы найденных до этого элементов, если таковые существуют. Если таковых нет, парсер выведет пустой результат и пойдет дальше:
Поиск текста
Тут говорить особо не о чем. Парсер просто будет брать весь полученный текст из подмассива и выводить его.
Ошибки
Документ может содержать ошибки, с которыми наш скрипт должен успешно справляться, либо, если ошибка критическая, выводить ее на экран. Тут будет приведен список всех возможных ошибок, о которых, в будущем, мы будем говорить:
- Символ ">" не был найден
Такая ошибка будет возникать в том случаи, если парсер дошел до конца документа и не нашел закрывающего символа ">".
- Неизвестное значение атрибута
Данная ошибка сигнализирует о том, что была проведена попытка передачи значения атрибуту когда закрывающий тег был найден.
<tag some =><!--И что там написано? А никто не знает, как и парсер-->
- Ошибка html синтаксиса
Данная ошибка возникает в двух случаях: Либо у атрибута тега в названии есть "<", либо если знак "=" ставится дважды, хотя значение еще не было передано.
<tag some = ='something'><!--Случайная ошибка, с кем не бывает--> <tag <some ='something'><!--И что это? Тег там, где должен быть атрибут? Непорядок-->
- Слишком много открывающих тегов
Данная ошибка часто встречается на сайтах, и говорит она о том, что открывающих тегов больше, чем закрывающих.
<div> <div id = ='wefwe'> Привет! </div> <!--И куда делся </div>?-->
Данная ошибка не является критической и будет решаться парсером.
- Слишком много закрывающих тегов
То же самое, что и прошлая ошибка, только наоборот.
<div id = ='wefwe'> Привет! </div> </div><!--И что ты собрался закрывать?-->
Данная ошибка также не является критической.
- Children элемент не найден
В этом случаи парсер просто будет выводить пустой массив.
Script, style и комментарии
В парсере теги script и style будут сразу же пропускаться, поскольку я не вижу смысл их записывать. С комментариями ситуация другая. Если вы захотите из записывать, то вы сможете включить отдельную функцию скрипта, и тогда он будет их записывать. Комментарии будут записываться точно так же как и текст, то есть как отдельный тег.
Заключение
Эту статью скорее нужно считать небольшим экскурсом в тему парсеров html. Я ее написал для тех, кто задумывается над написанием своего парсера, либо для тех, кому просто интересно. Поверьте, это действительно весело!
Данная статья является первой вводной частью. В следующих частях этого цикла уже будет участвовать непосредственно код, и будет меньше картинок с алгоритмами(что прекрасно, потому что рисовать я их не умею). Stay tuned!







m03r
Вы ведь не забросите публикацию серии? Интересно, что вышло в итоге, и чем оно отличается от встроенного DOMDocument.
P.S. С дебютом :)
ShamanHead Автор
Спасибо за поддержку. Забрасывать не намерен, тема мне кажется интересной, поэтому хочу ее развивать.
michael_vostrikov
Вы зря пишете такие короткие статьи. Кода нет, по теме ничего нет, текста наберется может строк 140. Разбивать текст на статьи надо по теме или функциональности кода, а не по размеру. Довольно редко встречаются такие большие темы, которые надо делить на несколько частей. Судя по названию, вряд ли у вас настолько сложная тема, можно было все описать в одной статье.
ShamanHead Автор
Это вводная часть, она и не должна быть большой. Если бы я тут подробнее углубился бы в детали, тогда моя статья была бы не меньше той, ссылку на которую вы оставили. А это только теоритический материал, без кода. С помощью этой статьи я хотел заинтересовать читателя темой, а не полностью охватить эту тему.
michael_vostrikov
Я говорю о том, что не надо писать вводные статьи) Пишите сразу нормальные. Если тема кому-то интересна, он и так статью прочитает. Более того, если тема кому-то интересна, ему интересны детали, а не описание того, насколько это интересно.
ShamanHead Автор
Справедливо, спасибо за критику.