Продолжение цикла публикаций статей про прогнозирование временных рядов. На повестке – перевод статьи How to Develop Multi-Step LSTM Time Series Forecasting Models for Power Usage.
Данную работу можно отнести к сильным в плане объёма предоставляемой информации. К тому же, как предупреждает её автор, она рассчитана на исследователя данных, имеющего багаж определённых знаний о временных рядах и прогнозировании в целом. Однако для облегчения понимания тех или иных деталей в статье будут представлены ссылки на связанные публикации. Со своей стороны я бы порекомендовал прочесть книгу Ф. Шолле «Глубокое обучение на Python», фрагментами из которой я сопроводил некоторые моменты переводимой статьи в виде примечания переводчика. В качестве беглого введения в прогнозирование временных желательно ознакомиться с публикацией «Прогнозирование временных рядов с помощью рекуррентных нейронных сетей», чтобы иметь представление о так называемых одномерных и многомерных моделях, а также о точечном и интервальном прогнозировании и их выполнении.
Опираясь на эти работы можно смело переделать некоторые вещи из переводимой статьи, – а вернее, адаптировать, как говорится, под себя – и расщёлкать ту или иную проблему, связанную с временными рядами.
Перевод сопровождается моими комментариями, которые нацелены помочь в быстром усвоении некоторых деталей.

Обновлено 05.08.2019
С ростом использования интеллектуальных счётчиков электроэнергии и широкого внедрения различных технологий её производства, таких как солнечные батареи и др., появляется множество данных о потреблении электроэнергии.
Эти данные могут быть представлены как многомерный временной ряд и использоваться не только для моделирования, но и прогнозирования будущего потребления электроэнергии.
В отличие от других алгоритмов машинного обучения, рекуррентные нейронные сети с долгой кратковременной памятью (в англоязычной терминологии LSTM. – Прим. пер.) способны автоматически выявлять признаки из временных последовательностей, обрабатывать многомерные данные, а также выводить последовательности переменной длины, благодаря чему их можно использовать для интервального прогнозирования.
В этом руководстве вы узнаете, как подготовить рекуррентные нейронные сети с долгой кратковременной памятью (далее по тексту статьи будет использоваться сокращение – ДКП. – Прим. пер.), чтобы выполнить интервальное прогнозирование временных рядов домового потребления электроэнергии.
После завершения данного руководства вы узнаете:
Узнайте как подготовить модели на основе многомерных входных данных для выполнения интервального прогнозирования временных рядов с помощью ДКП, а также многое другое в моей новой книге с 25-ю пошаговыми руководствами и полным исходным кодом.
Поехали!
Примечание. В целом это руководство ориентировано на продвинутого пользователя, и если вы только начинаете знакомится с прогнозированием временных рядов на Python, то сначала загляните сюда. Если вы только начинаете своё знакомство с методами глубокого обучения с использованием временных рядов, то начните с этой страницы. Если вы действительно нацелены начать работу с ДКП с временными рядами, начните отсюда.
Руководство состоит из девяти частей:
Для выполнения примеров руководства предполагается, что у вас установлены следующие Python-библиотеки: SciPy с версией Python 3, нейросетевая библиотека Keras (версия 2.2 или выше) с низкоуровневой библиотекой TensorFlow или Theano, а также Scikit-Learn, Pandas, NumPy и Matplotlib.
Если вам нужна помощь в настройке среды Python, то ознакомьтесь со следующей публикацией:
Для выполнения примеров руководства графическая карта не требуется. Тем не менее, за невысокую цену вы можете получить доступ к графическим процессорам на Amazon Web Services. В следующей публикации рассказано как это сделать:
Итак, переходим к погружению.
Набор данных «Домовое потребление электроэнергии» представляет собой многомерный временной ряд, отображающий потребление электроэнергии одной семьи в течение четырех лет.
Более полная информация об этом наборе данных представлена в следующей публикации:
Эти данные были собраны в период с декабря 2006 года по ноябрь 2010; замеры потребления электроэнергии выполнялись каждую минуту.
Помимо даты и времени набор данных состоит из семи переменных:
Активная и реактивная энергия относятся к техническим деталям переменного тока (активная мощность это и есть потребляемая мощность, за которую мы, собственно, платим по счётчику. – Прим. пер.).
Переменная sub_metering может быть создана путём вычитания суммы трёх определённых sub_metering-переменных от общей потребляемой энергии следующим образом:
Набор данных можно загрузить из архива UCI Machine Learning в виде сжатого файла формата .zip, размер которого составляет 20 мегабайт:
Загрузите набор данных и разархивируйте его в свой текущий рабочий каталог. После этого у вас появится файл «household_power_consumption.txt» в исходном виде, размер которого составляет примерно 127 мегабайт.
С помощью функции read_csv() мы можем загрузить данные и объединить первые два столбца в один столбец, объединяющий дату и время, — и использовать его в качестве индекса.
Далее мы можем заменить все пропущенные значения, обозначенные символом "?", на значение NaN, являющимся числом с плавающей точкой.
Это позволит нам работать с данными как с одним сплошным массивом значений с плавающей запятой, а не с различными смешанными типами (что было бы не так эффективно).
Далее нужно заполнить пропущенные значения NaN.
Простое решение состоит в том, чтобы скопировать наблюдение с того же времени, но днём ранее. Мы можем реализовать это с помощью функции fill_missing(), принимающей массив данных NumPy и возвращающей скопированные значения ровно 24 часа назад.
Мы можем применить эту функцию непосредственно к данным внутри DataFrame.
Теперь с помощью расчётов из предыдущего раздела создадим новый столбец, содержащий остаток sub-metering.
Далее сохраним подготовленную версию набора данных в отдельный файл: для этого мы просто изменим расширение файла на .csv и сохраним его как «household_power_consumption.csv».
Полный код загрузки, обработки и сохранения набора данных приведён ниже.
При выполнении кода создаётся новый файл «household_power_consumption.csv», который мы будем использовать в качестве отправной точки для нашего проекта моделирования.
В данном разделе мы рассмотрим, как подготовить и оценить модели, прогнозирующие домовое потребление электроэнергии.
Раздел состоит из четырёх частей:
Рассматриваемый в руководстве набор данных можно использовать для разных целей. В нашем случае мы будем использовать его для ответа на конкретный вопрос, а именно:
Чтобы ответить на этот вопрос, необходимо обучить модель прогнозировать ежедневную общую потребляемую мощность на следующие семь дней вперёд.
Примечание:
Общая потребляемая мощность (признак под индексом 0) будет использоваться для формирования целевых данных (y) применительно ко всем примерам данного руководства.
Технически, поставленная задача относится к задаче интервального прогнозирования временных рядов. При этом модель, на вход которой подаётся более одного признака, называется моделью на основе многомерных входных данных (или многомерная модель); она может использоваться для выполнения интервального прогнозирования.
Модель данного типа может быть полезна при планировании расходов домового потребления электроэнергии. Также модель может быть практичной с точки зрения оптимизации спроса на электроэнергию для конкретного дома/семьи.
Предполагается, что с учётом поставленной задачи было бы полезным уменьшить выборку с поминутных замеров потребления электроэнергии до ежедневных значений. Это не относится к обязательным шагам, однако, учитывая, что нас интересует дневная потребляемая мощность, в этом есть смысл.
Мы можем выполнить это с помощью pandas-функции resample(), применяемой к DataFrame. Применение этой функции с аргументом «D» позволяет группировать по дням загруженные данные, проиндексированные по дате и времени. Затем для каждой из восьми переменных мы можем рассчитать сумму всех наблюдений за каждый день и создать новый набор данных с ежедневным потреблением энергии.
Полный код обработки данных приведён ниже.
При его выполнении создается новый набор данных с ежедневным потреблением электроэнергии, который затем сохраняется в отдельном файле «household_power_consumption_days.csv».
Созданный набор данных мы будем использовать для выполнения поставленной задачи с подбором и оценкой прогностических моделей.
Прогноз будет состоять из семи значений — по одному на каждый день предстоящей недели.
Как правило, при выполнении интервального прогнозирования каждый прогнозируемый временной шаг оценивается отдельно. Это полезно по нескольким причинам:
Так как единицами общей мощности являются киловатты, было бы полезным иметь метрику погрешности в тех же единицах (в том же масштабе). При этом и квадратный корень из среднеквадратической ошибки (RMSE), и средняя абсолютная ошибка (MAE) соответствуют этому масштабу, однако в руководстве будет использоваться именно квадратный корень из среднеквадратичной ошибки, поскольку эта метрика используется чаще. К тому же, в отличие от средней абсолютной ошибки, она больше штрафует модель за ошибки прогноза. Таким образом, метрикой для рассматриваемой проблемы в данном руководстве будет RMSE, рассчитываемая для каждого прогнозного временного шага (с 1-го по 7-мой день).
Эта же метрика будет использоваться в качестве результирующей оценки по всем прогнозируемым дням, учитывающей итоги работы модели. Это поможет в выборе лучшей модели.
Функция evaluate_forecasts(), представленная ниже, реализует вышеописанное решение.
При выполнении функции сначала возвращается общее значение RMSE по всему прогнозу, а затем массив из значений RMSE по каждому дню.
Первые три года данных мы будем использовать для обучения моделей, последний год – для их валидации (проверки).
Данные будут разделены на стандартные недели, которые начинаются в воскресенье, а заканчиваются в субботу.
Примечание: В США, Англии и других странах неделя начинается с воскресенья.
Это реалистичный и полезный способ подготовки данных для рассматриваемой проблемы прогнозирования энергопотребления на неделю вперёд. Это также практично с точки зрения использования моделей для прогнозирования конкретного дня (например, среды) или всей последовательности.
При этом разделение будет выполнено в обратном направлении – от валидационной части набора данных.
В ней последним годом является 2010 год, первое воскресение в котором было 3-го января. Заканчиваются данные в середине ноября 2010 года, ближайшая последняя суббота была 20 ноября. С учётом этого на валидацию отводится 46 недель.
Для подтверждения ниже приведены первая и последняя строки суточных данных валидационной части набора данных.
Обучающая часть набора данных формируется согласно следующему. Замеры начинаются в конце 2006 года. Первое воскресенье было 17 декабря, что соответствует второй строке данных. С учётом этого организация данных в стандартные недели даёт 159 полных недель для обучения модели.
Представленная ниже функция split_dataset() разбивает суточные данные на обучающие и валидационные части и организует их в еженедельные данные с помощью NumPy-функции split().
Протестируйте вышеописанную функцию, загрузив суточный набор данных и распечатав первую и последнюю строки обучающих и валидационных данных, чтобы убедиться в соответствии расчётам.
Полный код разбиения данных приведён ниже.
Его выполнение показывает, что обучающая часть действительно содержит 159 недель данных, тогда как на валидационную отводится 46 недель. При этом и первая и последняя строки обеих частей соответствуют тем, которые мы определили в качестве границ с учётом стандартных недель.
Модели будут оцениваться с использованием схемы называемой «валидацией с нарастающим размером блока» (Walk-Forward Validation).
С учётом того, что целью моделирования является прогноз потребления мощности на неделю вперёд, то подаваемые на вход модели фактические еженедельные данные можно использовать в качестве основы для прогнозирования будущих еженедельных значений. Данный подход находит широкое применение на практике.
Принцип вышеописанного подхода продемонстрирован ниже.
Примечание:
Небольшое дополнение к демонстрации подхода. Поскольку набор данных разбит на две части, то с учётом валидации с нарастающим размером блока фактическими данными для прогнозирования первой недели из валидационной части данных (160-я неделя) будут первые 159 недель, т.е. вся обучающая часть данных. В свою очередь, для прогнозирования второй недели валидационной части данных (161-я неделя) фактическими данными будут 159 обучающих недель плюс предыдущая неделя из валидационной части данных (160 неделя) и т.д.:

Код функции evaluate_model(), в которой реализован данный подход к оценке моделей на основе рассматриваемого набора данных, представлен ниже.
Аргументами функции являются обучающая и валидационная части набора данных в формате еженедельных данных, а также дополнительный аргумент n_input, определяющий количество предыдущих наблюдений, которые модель будет использовать в качестве входных данных (параметр n_input лучше всего представить как историю. – Прим. пер.) каждого временного интервала для прогнозирования.
Наряду с этим в данной функции вызываются две новые подфункции: build_model(), используемая для конструирования и обучения модели на обучающих данных, и forecast(), применяемая для выполнения прогнозов при поступлении новых еженедельных данных. Эти функции будут рассмотрены в следующих разделах.
В данном руководстве мы будем работать с искусственными нейронными сетями. Сами по себе они обычно долго обучаются, однако быстро выдают оценку. В связи с этим предпочтительное использование моделей состоит в том, чтобы сконструировать и обучить их один раз на исторических данных, и далее использовать для прогнозирования каждого шага валидации с нарастающим размером блока. Модели являются статическими, то есть не обновляются во время их оценивания.
В этом заключается отличие от других моделей, которые быстрее обучаются, когда модель может быть переоснащена или обновлена на каждом шаге валидации с нарастающим размером блока при поступлении новых данных. Необходимо отметить, что при наличии достаточных ресурсов таким же образом можно использовать и искусственные нейронные сети, однако в этом руководстве это не будет рассматриваться.
Полный код функции evaluate_model() приведён ниже.
После того как модель оценена, можно вывести итоги её выполнения.
Функция summarize_scores() отображает эффективность модели в виде строки со значениями для простого и наглядного сравнения с другими моделями.
Теперь у нас есть все элементы, чтобы начать выполнение оценки моделей на рассматриваемом наборе данных.
Рекуррентные нейронные сети (РНС) (в англоязычной терминологии Recurrent Neural Network, RNN. – Прим. пер.) предназначены для работы с данными в виде последовательностей.
Примечание:
Временные ряды или последовательности – трёхмерные тензоры с формой:
[образцы, метки времени, признаки]
Источник: Глубокое обучение на Python, Франсуа Шолле.
РНС – это разновидность искусственной нейронной сети, в которой выходные данные одного временного интервала предоставляются в качестве входных данных для следующего временного интервала. Данное обстоятельство позволяет РНС принимать решения об объекте прогноза, основываясь как на входных данных для текущего временного интервала, так и на выходных данных предыдущих шагов.
Возможно, наиболее успешным и оттого массово используемым типом (архитектурой) РНС является «Долгая краткосрочная память». Это объясняется тем, что данный тип преодолевает трудности, присущие обычной РНС*. В дополнении к особенности устанавливать связи между выходом предыдущего временного интервала и входом текущего, ДКП также имеет внутреннюю память, работающую как локальная переменная, что позволяет ДКП накапливать состояние поверх входной последовательности.
Примечание:
* Имеется в виду проблема затухания градиента, «напоминающего эффект, который наблюдается в нерекуррентных сетях (сетях прямого распространения) с большим количеством слоёв: по мере увеличения количества слоёв сеть в конечном итоге становится необучаемой… Слои LSTM и GRU создавались специально для решения этой проблемы».
Источник: Глубокое обучение на Python, Франсуа Шолле.
Для получения дополнительной информации о РНС смотрите следующую публикацию:
Для получения дополнительной информации о ДКП смотрите следующую публикацию:
При интервальном прогнозировании временных рядов у ДКП есть ряд преимуществ перед другими методами:
Кроме того, разработаны специализированные архитектуры РНС для интервального прогнозирования последовательностей, называемые прогнозированием «последовательность в последовательность» (в англоязычной терминологии sequence-to-sequence, или seq2seq для краткости. – Прим. пер.).
Примером данной архитектуры является ДКП типа «кодировщик-декодировщик».
ДКП типа «кодировщик-декодировщик» – это модель, состоящая из двух субмоделей – кодировщика, считывающего и сжимающего входные последовательности во внутреннее представление фиксированной длины, и декодировщика, интерпретирующего внутреннее представление для прогнозирования выходной последовательности.
Данный подход к прогнозированию последовательностей показывает себя гораздо эффективнее, чем прямой вывод вектора, что делает его предпочтительным подходом к прогнозированию данных в виде последовательностей.
В целом было обнаружено, что ДКП не так эффективны при проблемах типа авторегрессии, когда прогнозирования следующего временного интервала является функцией предыдущих временных интервалов.
Подробнее об этой проблеме смотрите в следующей публикации:
Одномерные свёрточные нейронные сети (СНС) (в англоязычной терминологии Convolutional Neural Networks, CNN. – Прим. пер.) доказали свою эффективность в автоматическом изучении признаков из входных последовательностей.
Наиболее известный подход состоит в том, чтобы объединить СНС с ДКП в общую модель, в которой СНС выступает в качестве кодировщика для изучения признаков входных последовательных данных, передающихся ДКП как временные интервалы. Эта архитектура называется «СНС-ДКП» (в англоязычной терминологии CNN-LSTM. – Прим. пер.).
Для получения дополнительной информации об этой архитектуре смотрите следующую публикацию:
Изменение уровня мощности в архитектуре «СНС-ДКП» представлено в свёрточной ДКП (в англоязычной терминологии Convolutional LSTM, или ConvLSTM для краткости. – Прим. пер.), которая использует свёрточное считывание входных последовательностей в ячейках ДКП. Этот подход оказался очень эффективным для классификации временных рядов и может быть адаптирован для выполнения их интервального прогнозирования.
В этом руководстве мы рассмотрим набор различных архитектур ДКП для выполнения интервального прогнозирования временных рядов. В частности, мы рассмотрим, как выполнить следующие модели:
Если вы новичок в использовании ДКП для прогнозирования временных рядов, то я настоятельно рекомендую следующую публикацию:
Модели будут разработаны и продемонстрированы на примере решения проблемы прогнозирования домового энергопотребления. Модель будет считаться годной, если её оценка будет лучше, чем у наивной (упрощённой) модели, среднее значение оценки которой с учётом метрики RMSE составляет 465 киловатт (общая оценка за неделю).
Мы не будем фокусироваться на подборе оптимальных параметров моделей, чтобы улучшить их эффективность; вместо этого мы просто продемонстрируем модели, прогнозы которых лучше, чем наивный прогноз. Выбор представленных в примерах конфигураций и гиперпараметров ИНС объясняется методом проб и ошибок. Поэтому итоговые оценки следует рассматривать только в качестве примера, а не как исследование оптимальных параметров и конфигураций моделей для рассматриваемой проблемы.
Учитывая стохастический характер моделей, наиболее эффективно оценивать модель n-ое количество раз и затем вывести среднюю оценку эффективности. Однако вместо этого в целях сохранения простоты кода мы предоставим результаты одиночно оценённых моделей.
Мы не можем знать, какой подход будет наиболее эффективным для данной задачи интервального прогнозирования. Желательно изучить набор разных методов, чтобы выяснить, какие из них лучше всего работают на вашем наборе данных.
Мы начнём с выполнения простой (или ванильной) модели ДКП, которая трансформирует общее еженедельное энергопотребление в дневные последовательности и выполняет прогноз энергопотребления на следующую неделю в виде выходного вектора.
Данное начало послужит основой для выполнения более сложных моделей, которые будут разработаны и описаны в последующих разделах.
Количество предыдущих дней, используемых в качестве входных данных, определяет одномерную последовательность данных, которая будет подаваться на вход ДКП для изучения и выделения признаков. Ниже представлены некоторые идеи об их возможном размере и характере.
Нет однозначного ответа на вопрос, какой размер использовать. Лучшим решением будет протестировать каждый из них вместе с другими подходами, а по результатам выполнения выбрать тот, который показал наилучшие результаты.
При этом выбор должен быть обусловлен следующими факторами:
Хорошим началом будет использование семи предыдущих дней.
Модель ДКП ожидает, что входные данные будут иметь следующую (трёхмерную. – Прим. пер.) форму:
С учётом семи дней ежедневной потребляемой мощности каждая выборка имеет временной интервал, длительность которого равна семи, и один признак.
Примечание:
Временной интервал это и есть «история» (параметр n_input), которая для нижеследующего примера принята за семь предыдущих дней.
Так как обучающая часть данных содержит 159 недель, то её форма будет иметь следующий вид:
С этой формой данных модель будет использовать предыдущую неделю для прогнозирования следующей. Проблема в том, что 159 образцов – это очень маленькое количество данных для обучения модели.
Один из способов создания бoльшего количества данных состоит в том, чтобы изменить подход – выполнять прогнозирование потребления электроэнергии на следующие семь дней с учётом предыдущих несмотря на неделю (данное обстоятельство делает бессмысленным начальное преобразование обучающих и валидационных данных в еженедельную форму. – Прим. пер.).
Данное изменение относится только к обучающей части данных, предназначение валидационной части остаётся неизменным: с учётом данных предыдущей недели прогнозировать ежедневное энергопотребление на следующую неделю.
Для этого потребуется внести небольшие корректировки в подготовку обучающих данных.
Сначала обучающие данные на основе восьми признаков преобразовываются в недельные данные: в связи с этим их форма примет вид [159, 7, 8]. Следующим шагом является сглаживание данных. Делается это для того, чтобы получить восемь временных последовательностей (фактически выполняется обратное преобразование формы данных из 3Д в 2Д (см. примечание выше). – Прим. пер.).
Затем выполняется разделение данных на так называемые перекрывающиеся окна с учётом установленного временного интервала.
К примеру:
Это можно сделать путём отслеживания начальных и конечных индексов для входов и выходов при выполнении итераций по всей длине сглаженных данных с учётом установленного временного интервала.
При этом количество входов и выходов (n_input и n_out соответственно) будет выделено и представлено в качестве аргументов рассматриваемой далее функции. Это делается с той целью, чтобы вы могли поэкспериментировать с их различными значениями применительно к вашей собственной задаче.
Примечание:
Аргумент n_input – это, как уже было сказано, история, то есть на какой прошедший временной интервал «опереться» модели, чтобы выполнить прогноз (n_out), а n_out – это аргумент, определяющий насколько далеко в будущее модель должна научиться прогнозировать (устанавливает длительность прогнозируемого временного интервала).
Ниже приведена функция с именем to_supervised(), которая принимает обучающие данные, историю (количество предыдущих наблюдений, которые модель будет использовать в качестве входных данных) и длительность прогнозируемого временного интервала, а возвращает массивы в формате перекрывающихся скользящих окон.
При выполнении функции осуществляется преобразование 159 выборок в 1100; в связи с этим формы преобразованных данных примут следующий вид: X=[1100, 7, 1] и y=[1100, 7].
Далее определяется конфигурация модели и проводится её обучение.
По сути, данная проблема интервального прогнозирования временных рядов относится к авторегрессии. Это означает, что хороший результат может быть получен в том случае, когда следующие семь дней являются некоторой функцией наблюдений предыдущих. Данное обстоятельство наряду с относительно небольшим объёмом данных обуславливает применение «небольшой», простой по конфигурации, модели.
С учётом этого мы сконструируем модель с несколькими слоями. В роли первого скрытого слоя выступит слой ДКП с 200 нейронами (количество нейронов в скрытом слое не связано с длительностью временного интервала во входных последовательностях). За слоем ДКП следует полносвязный слой с 200 нейронами, назначение которого интерпретировать выявленные слоем ДКП признаки. Наконец, выходной слой будет напрямую выводить вектор с семью прогнозными элементами – по одному на каждый день в выходной последовательности.
За функцию потерь принята среднеквадратичная ошибка (MSE), поскольку она соответствует масштабу принятой ранее метрике (корень из среднеквадратической ошибки, RMSE). В качестве оптимизатора принят алгоритм Adam (вариант стохастического градиентного спуска), обучение модели будет длиться 70 эпох, размер пакета состоит из 16-ти образцов.
Небольшой размер пакета и стохастическая природа алгоритма означают, что одна и та же модель будет по-разному отображать входные и выходные данные при повторном обучении. Это приведёт к тому, что после выполнения оценки моделей, их результаты могу отличаться друг от друга. Вы можете попробовать выполнить обучение модели несколько раз и в подсчётах итоговых результатов использовать среднее значение.
Представленная ниже функция build_model() подготавливает обучающую часть данных, определяет конфигурацию модели, выполняет её обучение и возвращает обученную модель, которую затем можно использовать для выполнения прогнозов.
Теперь, когда модель обучена, мы можем проверить как она будет выполнять прогнозы.
Как правило, модель ожидает, что данные будут иметь одинаковую трёхмерную форму.
В нашем случае ожидаемая форма входного образца с учётом ежедневной потребляемой мощности следующая: «одна выборка – временной интервал длительностью 7 дней – один признак»:
Данную форму должны иметь не только данные валидационной части набора данных, но и «новые», поступающие данные, которые будут использоваться обученной моделью для прогнозирования в будущем. При изменении параметра n-input на 14 дней длительность временного интервала будет также составлять 14 дней, поэтому форма обучающих данных и новых выборок для выполнения прогнозирования должны быть изменены соответствующим образом. При этом о длительности временного интервала необходимо позаботиться в самом начале.
В данном руководстве используется валидация с нарастающим размером блока, описанная в предыдущем разделе. В соответствии с принятыми решениями прогнозирование энергопотребления на предстоящую неделю выполняется на основе наблюдений предыдущей недели. Предыдущие недели собраны в массив, называемый history.
Чтобы предсказать следующую неделю, нужно возвратить последние дни наблюдений. Как и в случае с обучающими данными, сначала необходимо сгладить данные history, удалив недельную структуру, чтобы получить восемь параллельных временных последовательностей.
Затем нужно получить ежедневные значения общей потребляемой мощности (признак под индексом 0) за последние семь дней.
Как и в случае с подготовкой обучающих данных, мы будем использовать для этого выделенный ранее параметр n_input, чтобы число предыдущих дней, используемых в качестве входных данных для модели, могло быть изменено в будущем.
Затем изменим форму входных данных в ожидаемую моделью трёхмерную структуру.
Далее на основе обученной модели и входных данных выполняется прогноз с извлечением выходного вектора, состоящего из семи дней.
Представленная ниже функция forecast() реализует вышеописанные решения, принимая в качестве аргументов обученную модель, список данных предыдущих недель, наблюдаемых до настоящего времени (параметр history, сформированный по результатам валидации с нарастающим размером блока) и временной интервал.
Вот и всё. Теперь у нас есть всё необходимое для выполнения интервального прогнозирования временных рядов с помощью модели ДКП на основе одномерных входных данных ежедневной общей потребляемой мощности.
Полный пример кода представлен ниже.
Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю (по всему прогнозу) и значением RMSE по каждому дню прогнозируемой недели.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
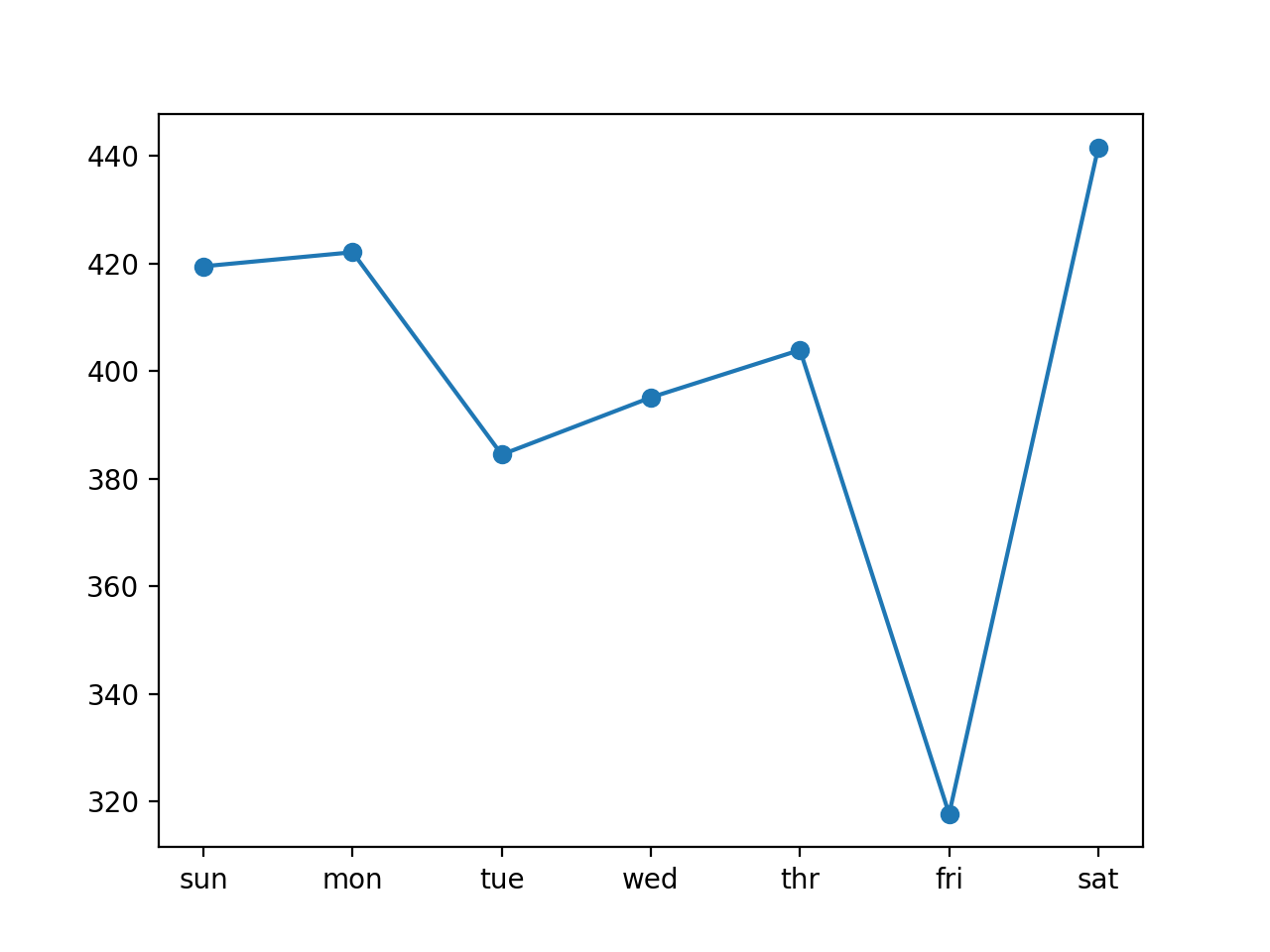
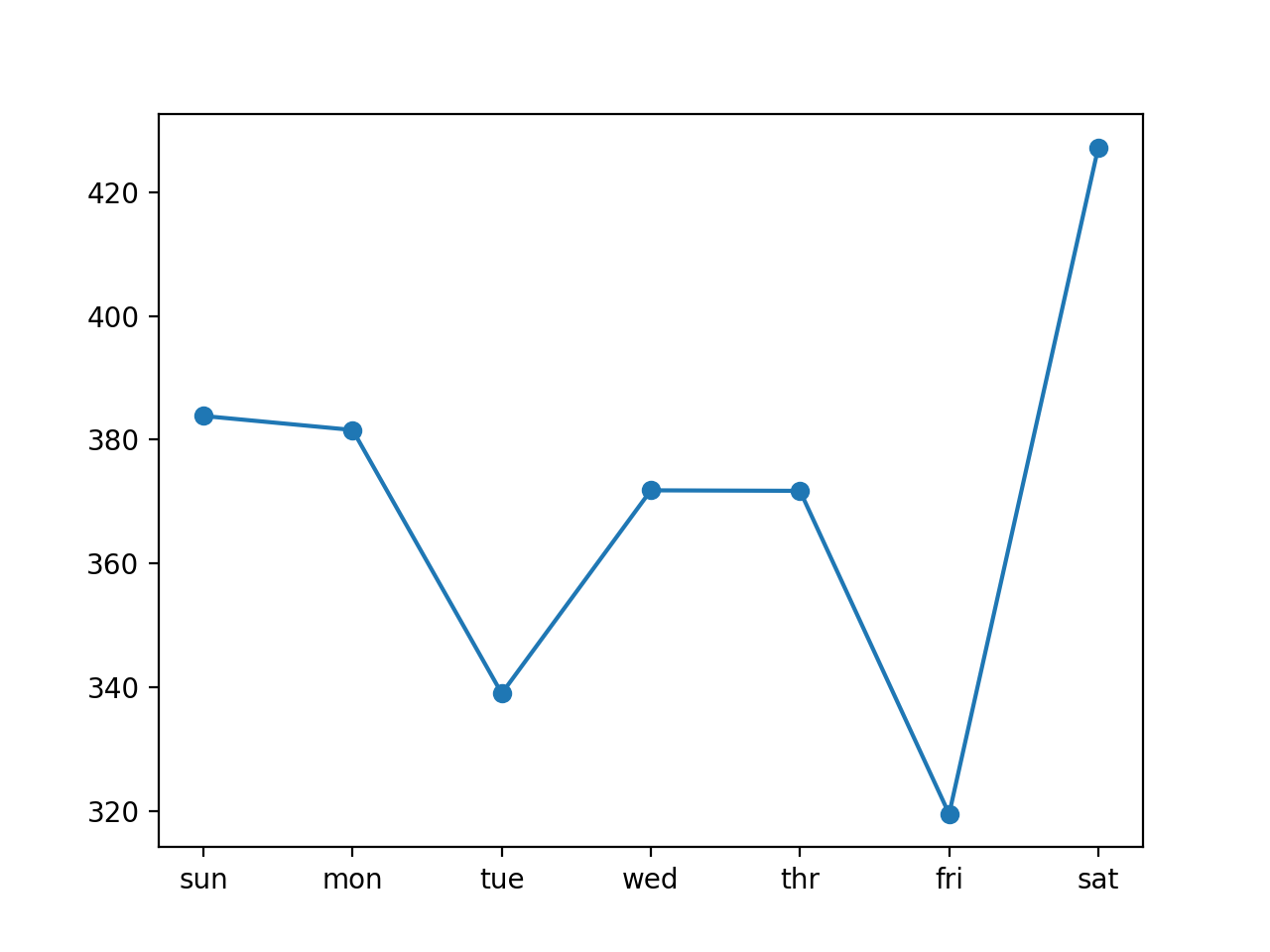
В данном случае по сравнению с наивным прогнозом модель справилась лучше: общее значение RMSE около 399 киловатт, что меньше значения 485 киловатт, достигнутого наивной моделью.
График со значениями ошибки по каждому дню прогнозируемой недели представлен ниже.
Из графика видно, что вторники и пятницы являются более лёгкими для прогнозирования днями, чем остальные, а суббота является самым трудным днём для прогнозирования.
Примечание:
В примеры данного руководства было бы полезно включить графики, визуализирующие результаты выполнения прогнозирования. Графики можно выполнить по-разному. В виду того, что интервал прогноза энергопотребления составляет 7 дней в будущее (параметр n_out), что не так много и не вызывает затруднений в плане задействованных ресурсов и времени выполнения кода, то выведем отдельный график RMSE по каждому дню прогнозируемой недели. Для этого добавим новую функцию show_plot():
Также дополним функцию evaluate_forecasts() следующими строками:
Наконец, построение графика со значениями ошибки по каждому дню прогнозируемой недели дополняется следующей строкой:
Давайте увеличим количество предыдущих дней, используемых в качестве входных данных, с 7 до 14 дней, изменив значение параметра n_input:
Перезапуск примера с учётом выполненного изменения выведет сводную информацию о качестве модели.
Ваши результаты могут отличаться от представленных ниже. Попробуйте выполнить пример несколько раз.
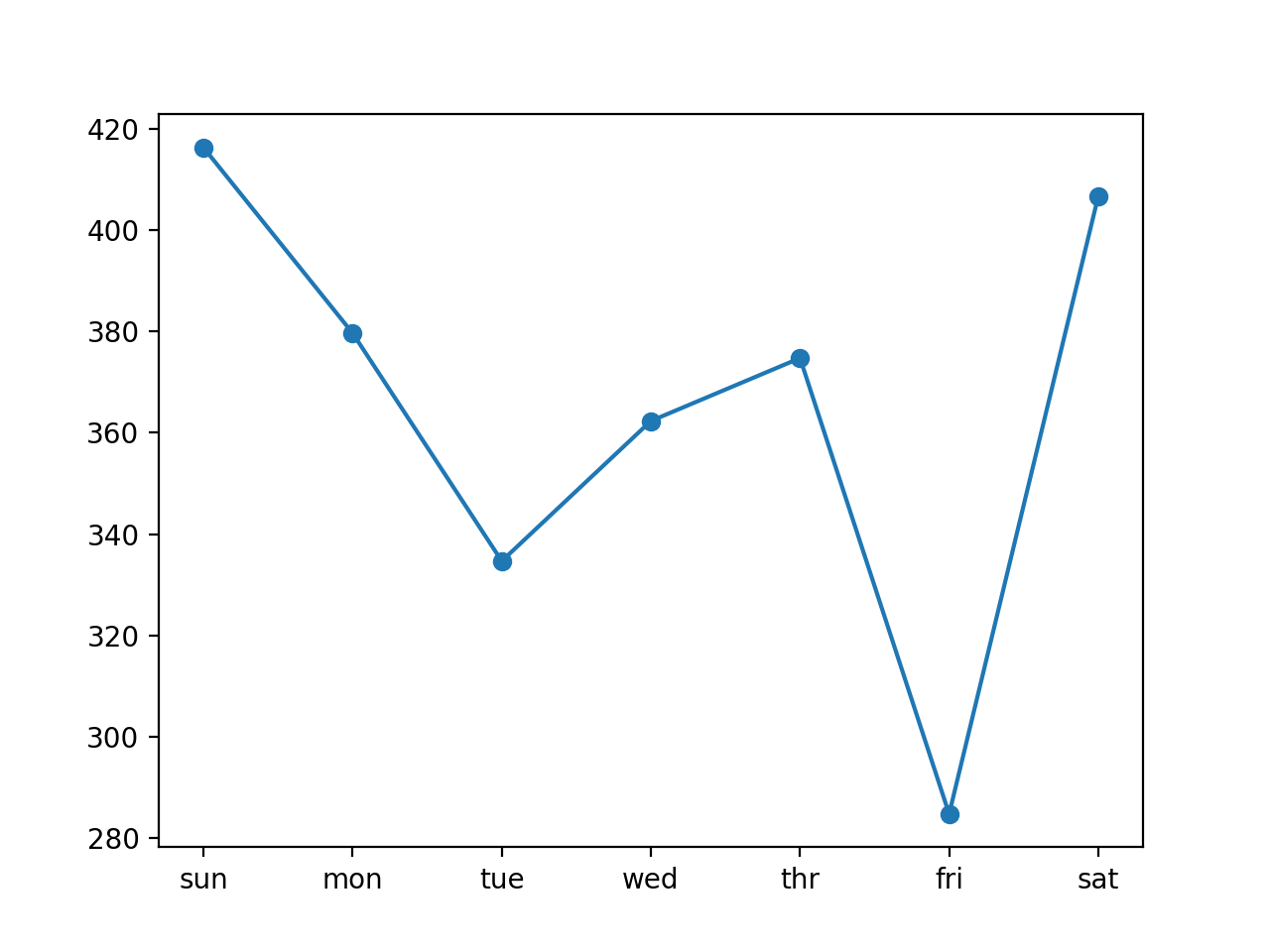
По результатам видно, что значение общей ошибки RMSE снизилось до 370 киловатт. Поэтому можно предположить, что дальнейшая настройка размера n_input и, возможно, количества узлов модели может увеличить её эффективность.
При сравнении значений RMSE по каждому дню друг с другом видно, что некоторые дни хуже, а другие лучше справляются с прогнозом по сравнению с использованием семидневных входных данных.
Можно предположить, что совместное использование двух входов с разными размерами – например, с помощью ансамбля, объединяющего два данных подхода, или единой модели («многоголовая» модель), считывающей обучающие данных разными способами, – способно принести пользу.
В этом разделе рассказывается о том, как обновить ванильную модель до модели ДКП типа «кодировщик-декодировщик» (в англоязычной терминологии Encoder-Decoder LSTM. – Прим. пер.).
Модель не будет выводить векторную последовательность напрямую; она будет состоять из двух субмоделей – кодировщика, считывающего и кодирующего входную последовательность, и декодировщика, интерпретирующего кодированную входную последовательность и выполняющего точечное прогнозирование для каждого элемента в выходной последовательности.
Разница между моделями невелика: на практике они обе выводят прогноз в виде последовательности.
Особенность рассматриваемой в данном разделе модели в том, что ДКП используется в качестве декодировщика: слой с ДКП собирает информацию о выполнении прогнозирования в предыдущие дни в последовательности, а также накапливает внутреннее состояние при выводе каждой последовательности.
Рассмотрим подробнее, как определяется эта модель.
Как и прежде, определяется скрытый слой ДКП с 200 нейронами. Только этот слой будет выступать в роли декодировщика, который будет считывать входную последовательность и выводить вектор из 200 элементов (один выход на единицу) согласно выявленным из входной последовательности признакам. В качестве входных данных будут использованы 14 дней общего энергопотребления.
В примере будет использована простая архитектура «кодировщик-декодировщик», которую легко реализовать с помощью Keras. Данная архитектура имеет много сходств с архитектурой ДКП типа «автокодировщик» (в англоязычной терминологии LSTM Autoencoder. – Прим. пер.).
Примечание:
ДКП типа «автокодировщик» – это одна из реализаций автокодировщика – разновидности ИНС, целью которой является кодирование входного малоразмерного скрытого пространства и последующего его декодирования – применительно к данным в виде последовательностей.
Сначала внутреннее представление входной последовательности повторяется несколько раз – по одному разу для каждого временного шага в выходной последовательности. Эта последовательность векторов будет представлена декодировщику ДКП.
Затем определяется декодировщик в виде скрытого слоя ДКП с 200 нейронами.
Важно отметить, что декодировщик будет выводить всю последовательность, а не только вывод в конце последовательности, как было с кодировщиком. Это означает, что каждый из 200 нейронов будет связан с каждым днём прогнозируемой недели, что позволит определиться с тем, что именно нужно прогнозировать для каждого дня выходной последовательности.
Далее следует полносвязный слой для интерпретации каждого временного шага в выходной последовательности перед окончательным выходным слоем. Важно отметить, что выходной слой прогнозирует один шаг в выходной последовательности, а не все семь дней сразу.
Это означает, что к каждому элементу в выходной последовательности будут применяться одинаковые слои: один и тот же полносвязный и выходной слои будут применены для обработки каждого временного шага, предоставляемого декодировщиком. Для этого слой интерпретации и выходной слой будут помещены в оболочку TimeDistributed, которая позволяет использовать обёрнутые слои для каждого временного шага.
Это позволит ДКП-декодировщику установить связь между временными шагами в выходной последовательности и обёрнутыми полносвязными слоями, чтобы интерпретировать каждый из временных шагов по отдельности с использованием одних и тех же весовых коэффициентов. Альтернативным решением может быть сглаживание всей структуры, созданной декодировщиком, и прямой вывод вектора. Вы можете попробовать выполнить его в качестве расширения примера и посмотреть на результаты сравнения.
Таким образом, выход сети представляется в виде трёхмерного тензора с той же структурой, что и у входной последовательности: [образцы, временной интервал, признаки].
Имеется один признак – общая потребляемая мощность (в ежедневной форме) – и его семь лагированных наблюдений. Следовательно, один еженедельный прогноз будет иметь форму: [1, 7, 1].
Примечание:
Напоминание: в данном разделе рассматривается одномерная модель, то есть модель, в которой и набор входных признаков (X), и набор целевых данных (y) формируется на основе одного-единственного признака – общей потребляемой мощности.
Поэтому перед обучением модели необходимо преобразовать целевые данные (y) из двухмерной формы [образцы, признаки], использованной в предыдущем разделе, в трёхмерную форму.
Обновлённая функция build_model() с учётом данных изменений представлена ниже.
Полный пример кода одномерной модели ДКП типа «кодировщик-декодировщик» представлен ниже.
Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогнозируемой недели на валидационной части набора данных.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
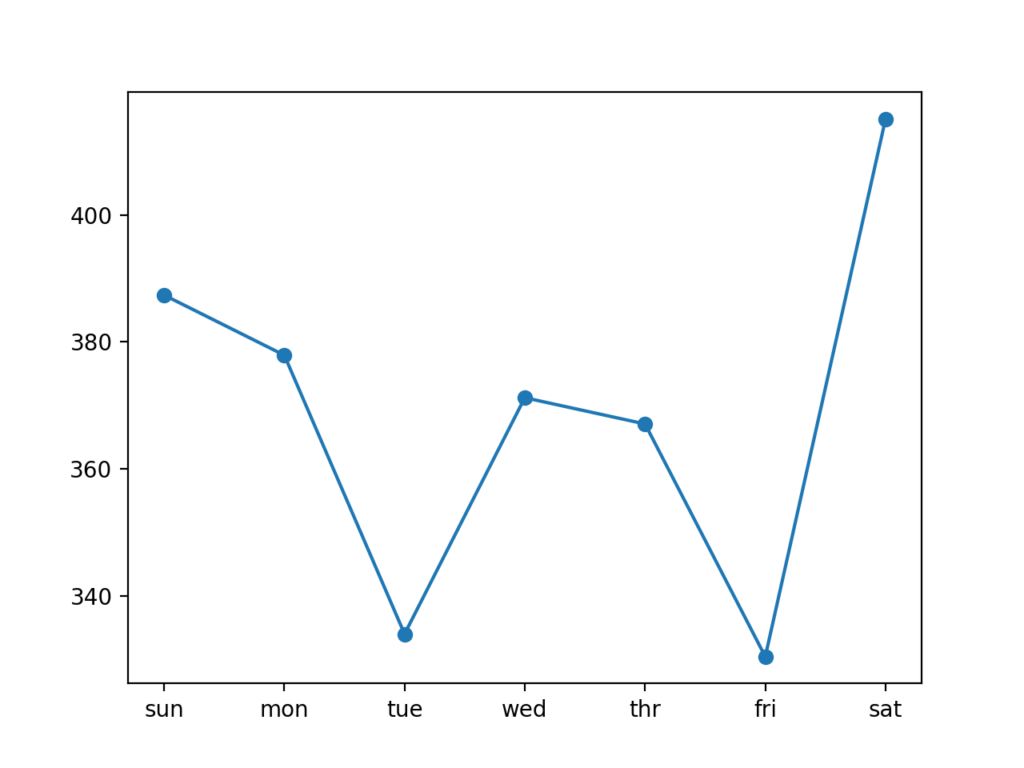
В данном случае модель тоже справилась с прогнозом лучше, чем наивная модель: общее значение RMSE около 372 киловатт
График со значением ошибки RMSE по каждому дню прогнозируемой недели выполняется аналогично предыдущему разделу.
Примечание:
В этом разделе будет рассмотрено обновление разработанной в предыдущем разделе модели ДКП типа «кодировщик-декодировщик», состоящее в том, чтобы для прогнозирования электроэнергии на следующую неделю использовать каждый из восьми признаков в виде одномерного временного ряда.
Для этого каждый из них будет представлен модели в виде отдельной входной последовательности.
В свою очередь ДКП создаст внутреннее представление для каждой входной последовательности, которые будут затем совместно использоваться для интерпретирования декодировщиком.
Использование многомерных входных данных полезно при решении проблем, когда выходная последовательность является некоторой функцией от наблюдений предыдущих временных интервалов множества различных признаков, а не только от прогнозируемого признака. Пока непонятно, подойдёт ли этот подход для решения проблемы прогнозирования потребления электроэнергии, поэтому необходимо исследовать этот вопрос.
Сначала выполним обновление подготовки обучающих данных, включив в неё все восемь признаков, а не только ежедневную общую потребляемую мощность, откорректировав одну строку:
Обновлённая функция to_supervised() с учётом данного изменения представлена ниже.
Также необходимо обновить функцию, используемую для выполнения прогнозов на основе обученной модели, чтобы использовать все восемь признаков на предыдущих временных интервалах.
Для этого внесём в неё небольшие изменения:
Обновлённая функция forecast() с учётом данного изменения представлена ниже.
Используется та же архитектура и конфигурация модели, что и ранее, однако в виду восьмикратного увеличения количества входных данных количество тренировочных эпох увеличится с 20 до 50.
Полный пример кода многомерной модели ДКП типа «кодировщик-декодировщик» представлен ниже.
Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогноза на валидационной части набора данных.
Эксперимент показал, что модель ДКП типа «кодировщик-декодировщик» на основе многомерных входных данных выглядит менее стабильной, чем одномерная модель. Это может быть связано с различным масштабом данных входных признаков.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
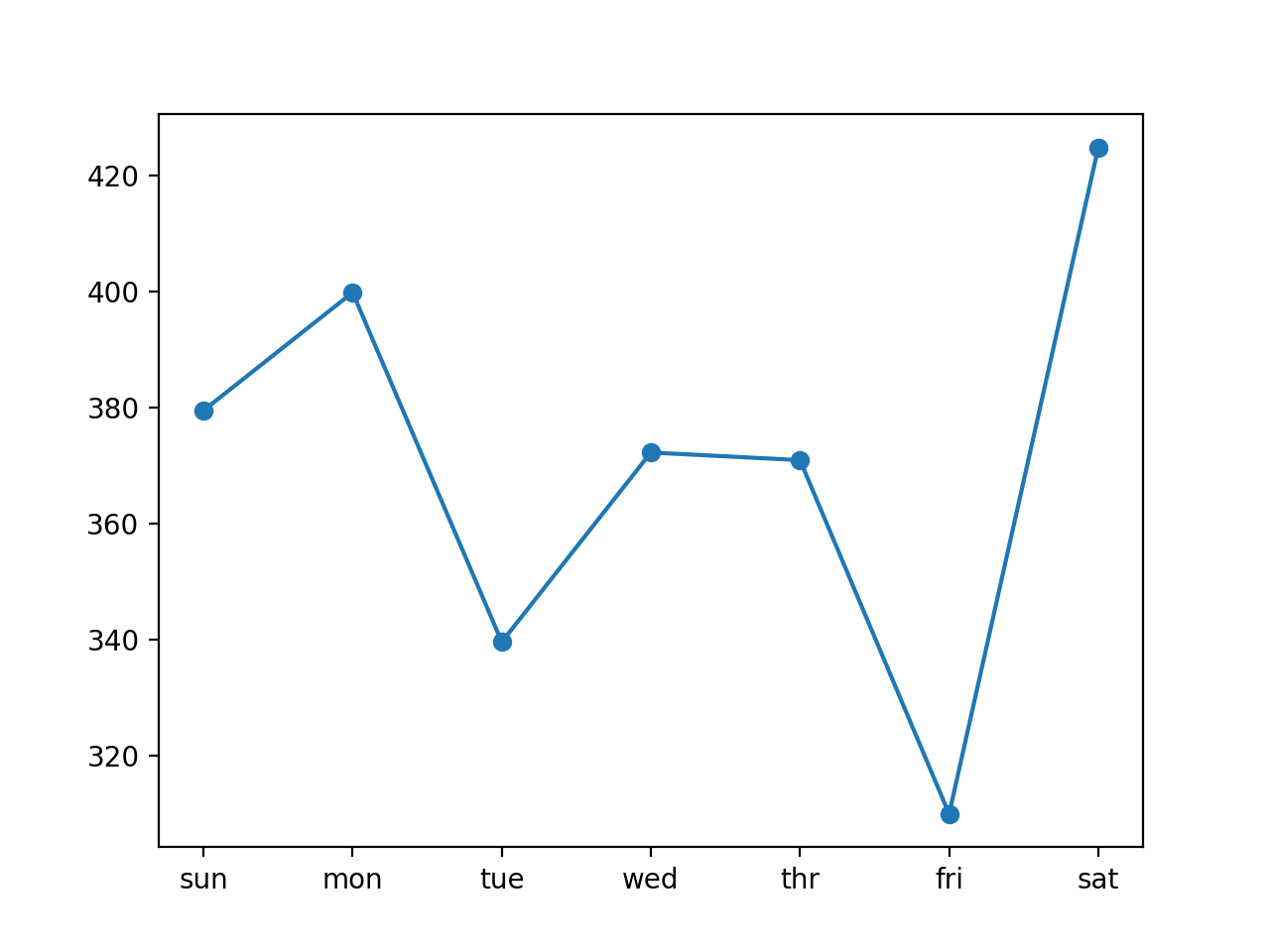
Видно, что и в этом случае модель справилась с прогнозом лучше, чем наивная модель: общее значение RMSE около 376 киловатт.
Ниже представлен график RMSE на каждый день прогнозируемой недели.
Свёрточная нейронная сеть (СНС) может быть использована в качестве кодировщика в архитектуре ДКП типа «кодировщик-декодировщик».
При этом СНС не поддерживает ввод данных в виде последовательностей напрямую; вместо этого одномерная СНС способна последовательно считывать элементы входной последовательности и автоматически изучать характерные признаки (по сути свёртка работает методом перекрывающегося скользящего окна, которое перемещается не по тензору с изображением, а по входной последовательности. – Прим. пер.). Затем они могут быть интерпретированы декодировщиком ДКП как обычно. Совместное использование СНС и ДКП относится к гибридным моделям (СНС-ДКП).
Как и модель ДКП, СНС принимает на входе трёхмерные тензоры, только каждый из признаков считывается как отдельный канал, что в конечном итоге имеет тот же эффект.
Мы упростим пример, сосредоточившись на одномерной модели СНС-ДКП. Однако модель можно легко обновить, чтобы использовать все признаки (оставлено в качестве упражнения).
Примечание:
В Keras одномерные свёрточные сети создаются с помощью слоя Conv1D.
Окно свёртки — это одномерное окно на оси времени: оси с индексом 1 во входном тензоре.
Источник: Глубокое обучение на Python, Франсуа Шолле.
Как и прежде, в качестве входных данных будут использованы 14 дней общего энергопотребления.
Мы определим простую и в то же время эффективную архитектуру СНС в качестве кодировщика, состоящую из двух свёрточных уровней, за которым следует слой объединения по максимуму (MaxPooling1D), результаты которого далее сглаживаются.
Примечание:
Max-pooling – это операция выбора максимального значения из соседних. Её предназначение заключается «в агрессивном уменьшении разрешения карты признаков, во многом подобное свёртке с пробелами». Подробнее в книге Ф. Шолле.
Первый свёрточный слой последовательно считывает элементы входной последовательности и проецирует результаты на карты признаков. Второй свёрточный слой выполняет ту же операцию с той лишь разницей, что считывание выполняется уже на картах признаков, созданных первым слоем, пытаясь тем самым усилить любые существенные характеристики. Каждый свёрточный слой будет использовать 64 фильтра и считывать входные последовательности с размером ядра в три временных шага.
Слой объединения по максимуму выполняет упрощающие преобразования карты признаков, сохраняя ? значений с наибольшим (максимальным) сигналом. После слоя объединения по максимуму извлечённые карты признаков преобразуются в один длинный вектор, которым затем будет использован в качестве входных данных для процесса декодирования.
Определение декодировщика аналогично предыдущему разделу.
Единственное дополнительное изменение – установить количество эпох обучения равным 20.
Обновлённая функция build_model() с учётом данных изменений представлена ниже.
Теперь всё готово, чтобы испытать архитектуру «кодировщик-декодировщик» со свёрточным слоем в качестве кодировщика.
Полный пример кода одномерной модели ДКП типа «кодировщик-декодировщик» с добавлением свёрточного слоя в качестве кодировщика представлен ниже.
Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогноза на валидационной части набора данных.
Небольшой эксперимент показал, что использование двух свёрточных слоёв делает модель более стабильной, чем при использовании только одного слоя.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
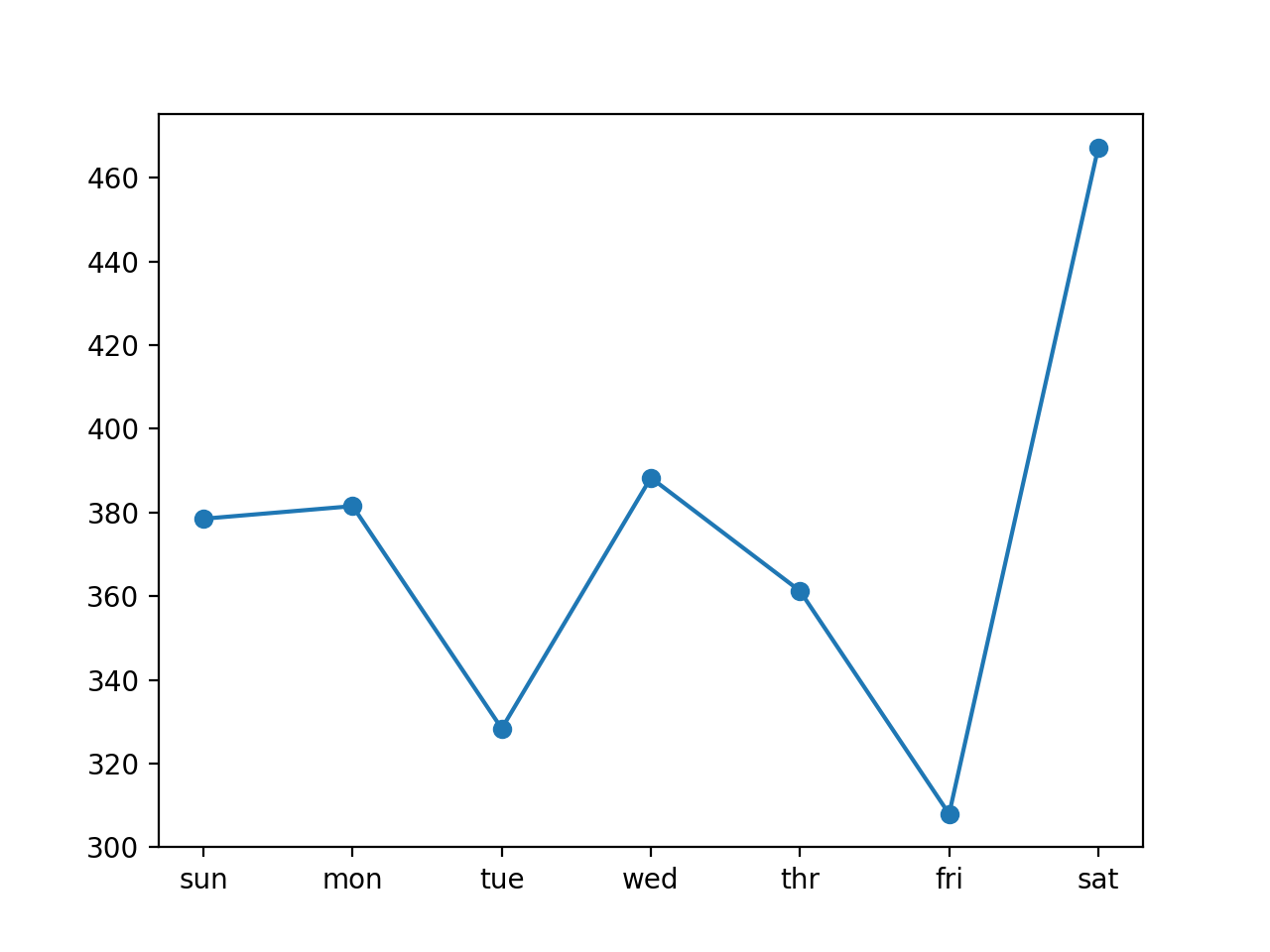
Видно, что и в этом случае модель справилась с прогнозом лучше, чем наивная модель: общее значение RMSE около 372 киловатт.
Ниже представлен график RMSE на каждый день прогнозируемой недели.
Расширением подхода СНС-ДКП является выполнение свёрток СНС (например, как СНС считывает данные входной последовательности) как часть ДКП для каждого временного интервала.
Эта комбинация называется «свёрточная ДКП» (в англоязычной терминологии Convolutional LSTM, или ConvLSTM для краткости. – Прим. пер.). Как и СНС-ДКП она также используется для пространственно-временных данных.
В отличие от модели ДКП, считывающей данные напрямую для вычисления внутреннего состояния и переходов состояний, и модели СНС-ДКП, интерпретирующей выходные данные моделей СНС, свёрточная ДКП использует свёртки непосредственно как часть чтения входных данных в ячейках LSTM (имеется в виду, что не только входные, но и рекуррентные преобразования подвергаются свёртке; другими словами, внутренние матрицы заменяются операциями свёртки, в результате чего данные, проходящие через ячейки свёрточной ДКП сохраняют входное измерение вместо того, чтобы быть просто одномерным вектором. – Прим. пер.).
Более полная информация о том, как выводятся уравнения для свёрточной ДКП, представлена в следующей статье:
Библиотека Keras предоставляет класс под названием ConvLSTM2D для работы со свёрточной ДКП на основе двухмерных данных (имеются в виду двухмерные изображения (ширина и высота). – Прим. пер.). Он также может быть настроен для выполнения прогнозирования одномерных временных рядов (1Д).
По умолчанию класс ConvLSTM2D ожидает, что входные данные будут иметь следующую (пятимерную. – Прим. пер.) форму:
Где каждый из временных интервалов определяется как изображение (строки * столбцы) в виде точек (пикселей).
Предположим, что в качестве входных данных мы используем ежедневные данные за предыдущие две недели. В виду того, что мы работает с одномерной последовательностью общего потребления электроэнергии, то её можно интерпретировать как одну строку с 14 столбцами.
В этом случае свёрточная ДКП выполнит однократное чтение: ДКП будет считывать один временной интервал продолжительностью 14 дней и выполнять на них свёрточную операцию.
Это не идеально.
Вместо этого мы может разделить последовательность продолжительностью 14 дней на две подпоследовательности продолжительностью по 7 дней каждая. Затем свёрточная ДКП будет последовательно считывать элементы двух временных интервалов протяжённостью 7 дней с выполнением операции свёртки на каждом из них.
Таким образом, с учётом поставленной задачи вход для слоя ConvLSTM2D будет:
Или:
Вы можете исследовать и другие возможные конфигурации: например, передачу на вход модели данных за 21 день в виде 3-х подпоследовательностей по 7 дней каждая и/или предоставление данных 8-ми признаков (каналов).
Теперь подготовим данные для модели ConvLSTM2D.
Сначала мы должны изменить форму обучающей части набора данных в ожидаемую моделью пятимерную структуру [выборки, временной интервал, строки, столбцы, каналы].
Затем определим в качестве кодировщика свёрточную ДКП (первый скрытый слой), за которым следует слой сглаживания данных для их подготовки к декодированию.
При этом количество подпоследовательностей (n_steps) и длина каждой подпоследовательности (n_length) будут выделены и представлены в качестве аргументов функции.
В остальном конфигурация модели и её обучение аналогичны предыдущему разделу. Функция build_model() с учётом данных изменений представлена ниже.
Эта модель ожидает пятимерные данные в качестве входных данных. Поэтому также необходимо обновить подготовку образцов в функции forecast() для последующего выполнения прогнозирования.
Обновлённая функция forecast() с учётом данного изменения и выделения параметров n_steps и n_length в качестве её аргументов представлена ниже.
Теперь у нас есть все элементы, чтобы начать выполнение оценки архитектуры «кодировщик-декодировщик» для интервального прогнозирования временных рядов, в которой в роли кодировщика используется свёрточная ДКП.
Полный пример кода одномерной свёрточной модели ДКП типа «кодировщик-декодировщик» представлен ниже.
Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогноза на валидационной части набора данных.
Небольшой эксперимент показал, что использование двух свёрточных слоёв делает модель более стабильной, чем при использовании только одного слоя.
Видно, что и в этом случае модель справилась с прогнозом лучше: общее значение RMSE около 367 киловатт.
Ниже представлен график RMSE на каждый день прогнозируемой недели.
В этом разделе перечислено несколько проектов, выходящих за рамки данного руководства, которые наверняка вас заинтересуют.
Если вы всё-таки дойдёте до этих заданий, дайте мне знать (видимо, автор в курсе, что редкая птица долетит до середины Днепра :). – Прим. пер.).
Для тех, кто хочет узнать больше по этой теме. Здесь указаны важные источники.
Итак, теперь вы знаете как подготовить рекуррентные нейронные сети с долгой кратковременной памятью, чтобы выполнить интервальное прогнозирование временных рядов домового потребления электроэнергии.
В частности:
Есть вопросы?
Задавайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить (это не примечание. – Прим. пер.).
Заметьте, что это была часть главы из моей книги «Глубокое обучение: прогнозирование временных рядов», в которой вы найдёте ещё больше пошаговых руководств для изучения методов глубокого обучения применительно к прогнозированию временных рядов.
Данную работу можно отнести к сильным в плане объёма предоставляемой информации. К тому же, как предупреждает её автор, она рассчитана на исследователя данных, имеющего багаж определённых знаний о временных рядах и прогнозировании в целом. Однако для облегчения понимания тех или иных деталей в статье будут представлены ссылки на связанные публикации. Со своей стороны я бы порекомендовал прочесть книгу Ф. Шолле «Глубокое обучение на Python», фрагментами из которой я сопроводил некоторые моменты переводимой статьи в виде примечания переводчика. В качестве беглого введения в прогнозирование временных желательно ознакомиться с публикацией «Прогнозирование временных рядов с помощью рекуррентных нейронных сетей», чтобы иметь представление о так называемых одномерных и многомерных моделях, а также о точечном и интервальном прогнозировании и их выполнении.
Опираясь на эти работы можно смело переделать некоторые вещи из переводимой статьи, – а вернее, адаптировать, как говорится, под себя – и расщёлкать ту или иную проблему, связанную с временными рядами.
Перевод сопровождается моими комментариями, которые нацелены помочь в быстром усвоении некоторых деталей.
Интервальное прогнозирование временных рядов с помощью рекуррентных нейронных сетей с долгой краткосрочной памятью: прогноз потребления электроэнергии
Обновлено 05.08.2019
С ростом использования интеллектуальных счётчиков электроэнергии и широкого внедрения различных технологий её производства, таких как солнечные батареи и др., появляется множество данных о потреблении электроэнергии.
Эти данные могут быть представлены как многомерный временной ряд и использоваться не только для моделирования, но и прогнозирования будущего потребления электроэнергии.
В отличие от других алгоритмов машинного обучения, рекуррентные нейронные сети с долгой кратковременной памятью (в англоязычной терминологии LSTM. – Прим. пер.) способны автоматически выявлять признаки из временных последовательностей, обрабатывать многомерные данные, а также выводить последовательности переменной длины, благодаря чему их можно использовать для интервального прогнозирования.
В этом руководстве вы узнаете, как подготовить рекуррентные нейронные сети с долгой кратковременной памятью (далее по тексту статьи будет использоваться сокращение – ДКП. – Прим. пер.), чтобы выполнить интервальное прогнозирование временных рядов домового потребления электроэнергии.
После завершения данного руководства вы узнаете:
- Как подготовить и оценить ДКП типа «кодировщик-декодировщик» для интервального прогнозирования временных рядов на основе как одномерных, так и многомерных входных данных.
- Как подготовить и оценить ДКП типа «кодировщик-декодировщик» с добавлением свёрточного слоя в качестве кодировщика для интервального прогнозирования временных рядов.
- Как подготовить и оценить свёрточную ДКП типа «кодировщик-декодировщик» для интервального прогнозирования временных рядов.
Узнайте как подготовить модели на основе многомерных входных данных для выполнения интервального прогнозирования временных рядов с помощью ДКП, а также многое другое в моей новой книге с 25-ю пошаговыми руководствами и полным исходным кодом.
Поехали!
Примечание. В целом это руководство ориентировано на продвинутого пользователя, и если вы только начинаете знакомится с прогнозированием временных рядов на Python, то сначала загляните сюда. Если вы только начинаете своё знакомство с методами глубокого обучения с использованием временных рядов, то начните с этой страницы. Если вы действительно нацелены начать работу с ДКП с временными рядами, начните отсюда.
- Обновление (июнь, 2019): исправлена ошибка в функции to_supervised(), которая отбрасывала данные за последнюю неделю набора данных (спасибо Маркусу).
Обзор руководства
Руководство состоит из девяти частей:
- Описание проблемы.
- Загрузка и подготовка набора данных.
- Оценка модели.
- ДКП для интервального прогнозирования временных рядов.
- ДКП на основе одномерных входных данных и выходного вектора.
- ДКП типа «кодировщик-декодировщик» на основе одномерных входных данных.
- ДКП типа «кодировщик-декодировщик» на основе многомерных входных данных.
- ДКП типа «кодировщик-декодировщик» с добавлением свёрточного слоя в качестве кодировщика на основе одномерных входных данных.
- Свёрточная ДКП типа «кодировщик-декодировщик» на основе одномерных входных данных.
Параметры среды Python
Для выполнения примеров руководства предполагается, что у вас установлены следующие Python-библиотеки: SciPy с версией Python 3, нейросетевая библиотека Keras (версия 2.2 или выше) с низкоуровневой библиотекой TensorFlow или Theano, а также Scikit-Learn, Pandas, NumPy и Matplotlib.
Если вам нужна помощь в настройке среды Python, то ознакомьтесь со следующей публикацией:
Для выполнения примеров руководства графическая карта не требуется. Тем не менее, за невысокую цену вы можете получить доступ к графическим процессорам на Amazon Web Services. В следующей публикации рассказано как это сделать:
Итак, переходим к погружению.
Описание проблемы
Набор данных «Домовое потребление электроэнергии» представляет собой многомерный временной ряд, отображающий потребление электроэнергии одной семьи в течение четырех лет.
Более полная информация об этом наборе данных представлена в следующей публикации:
Эти данные были собраны в период с декабря 2006 года по ноябрь 2010; замеры потребления электроэнергии выполнялись каждую минуту.
Помимо даты и времени набор данных состоит из семи переменных:
- global_active_power: общая активная мощность, потребляемая жилым домом (измеряется в киловаттах).
- global_reactive_power: общая реактивная мощность, потребляемая жилым домом (измеряется в киловаттах).
- voltage: среднее напряжение (измеряется в вольтах).
- global_intensity: среднее значение силы тока (измеряется в амперах).
- sub_metering_1: активная энергия потребления кухонной комнаты (измеряется в ватт-часах активной энергии).
- sub_metering_2: активная энергия потребления прачечной (измеряется в ватт-часах активной энергии).
- sub_metering_3: активная энергия потребления систем климат-контроля (измеряется в ватт-часах активной энергии).
Активная и реактивная энергия относятся к техническим деталям переменного тока (активная мощность это и есть потребляемая мощность, за которую мы, собственно, платим по счётчику. – Прим. пер.).
Переменная sub_metering может быть создана путём вычитания суммы трёх определённых sub_metering-переменных от общей потребляемой энергии следующим образом:
sub_metering_remainder = (global_active_power * 1000 / 60) - (sub_metering_1 + sub_metering_2 + sub_metering_3)
Загрузка и подготовка набора данных
Набор данных можно загрузить из архива UCI Machine Learning в виде сжатого файла формата .zip, размер которого составляет 20 мегабайт:
Загрузите набор данных и разархивируйте его в свой текущий рабочий каталог. После этого у вас появится файл «household_power_consumption.txt» в исходном виде, размер которого составляет примерно 127 мегабайт.
С помощью функции read_csv() мы можем загрузить данные и объединить первые два столбца в один столбец, объединяющий дату и время, — и использовать его в качестве индекса.
# load all data
dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime'])Далее мы можем заменить все пропущенные значения, обозначенные символом "?", на значение NaN, являющимся числом с плавающей точкой.
Это позволит нам работать с данными как с одним сплошным массивом значений с плавающей запятой, а не с различными смешанными типами (что было бы не так эффективно).
# mark all missing values
dataset.replace('?', nan, inplace=True)
# make dataset numeric
dataset = dataset.astype('float32')Далее нужно заполнить пропущенные значения NaN.
Простое решение состоит в том, чтобы скопировать наблюдение с того же времени, но днём ранее. Мы можем реализовать это с помощью функции fill_missing(), принимающей массив данных NumPy и возвращающей скопированные значения ровно 24 часа назад.
# fill missing values with a value at the same time one day ago
def fill_missing(values):
one_day = 60 * 24
for row in range(values.shape[0]):
for col in range(values.shape[1]):
if isnan(values[row, col]):
values[row, col] = values[row - one_day, col]Мы можем применить эту функцию непосредственно к данным внутри DataFrame.
# fill missing
fill_missing(dataset.values)Теперь с помощью расчётов из предыдущего раздела создадим новый столбец, содержащий остаток sub-metering.
# add a column for for the remainder of sub metering
values = dataset.values
dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6])Далее сохраним подготовленную версию набора данных в отдельный файл: для этого мы просто изменим расширение файла на .csv и сохраним его как «household_power_consumption.csv».
# save updated dataset
dataset.to_csv('household_power_consumption.csv')Полный код загрузки, обработки и сохранения набора данных приведён ниже.
# load and clean-up data
from numpy import nan
from numpy import isnan
from pandas import read_csv
from pandas import to_numeric
# fill missing values with a value at the same time one day ago
def fill_missing(values):
one_day = 60 * 24
for row in range(values.shape[0]):
for col in range(values.shape[1]):
if isnan(values[row, col]):
values[row, col] = values[row - one_day, col]
# load all data
dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime'])
# mark all missing values
dataset.replace('?', nan, inplace=True)
# make dataset numeric
dataset = dataset.astype('float32')
# fill missing
fill_missing(dataset.values)
# add a column for for the remainder of sub metering
values = dataset.values
dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6])
# save updated dataset
dataset.to_csv('household_power_consumption.csv')При выполнении кода создаётся новый файл «household_power_consumption.csv», который мы будем использовать в качестве отправной точки для нашего проекта моделирования.
Оценка модели
В данном разделе мы рассмотрим, как подготовить и оценить модели, прогнозирующие домовое потребление электроэнергии.
Раздел состоит из четырёх частей:
- Постановка проблемы
- Метрика оценки
- Разделение набора данных на тренировочную и тестовую части
- Валидация с нарастающим размером блока
Постановка проблемы
Рассматриваемый в руководстве набор данных можно использовать для разных целей. В нашем случае мы будем использовать его для ответа на конкретный вопрос, а именно:
Учитывая текущий уровень потребления, какой расход электроэнергии будет на неделю вперед?
Чтобы ответить на этот вопрос, необходимо обучить модель прогнозировать ежедневную общую потребляемую мощность на следующие семь дней вперёд.
Примечание:
Общая потребляемая мощность (признак под индексом 0) будет использоваться для формирования целевых данных (y) применительно ко всем примерам данного руководства.
Технически, поставленная задача относится к задаче интервального прогнозирования временных рядов. При этом модель, на вход которой подаётся более одного признака, называется моделью на основе многомерных входных данных (или многомерная модель); она может использоваться для выполнения интервального прогнозирования.
Модель данного типа может быть полезна при планировании расходов домового потребления электроэнергии. Также модель может быть практичной с точки зрения оптимизации спроса на электроэнергию для конкретного дома/семьи.
Предполагается, что с учётом поставленной задачи было бы полезным уменьшить выборку с поминутных замеров потребления электроэнергии до ежедневных значений. Это не относится к обязательным шагам, однако, учитывая, что нас интересует дневная потребляемая мощность, в этом есть смысл.
Мы можем выполнить это с помощью pandas-функции resample(), применяемой к DataFrame. Применение этой функции с аргументом «D» позволяет группировать по дням загруженные данные, проиндексированные по дате и времени. Затем для каждой из восьми переменных мы можем рассчитать сумму всех наблюдений за каждый день и создать новый набор данных с ежедневным потреблением энергии.
Полный код обработки данных приведён ниже.
# resample minute data to total for each day
from pandas import read_csv
# load the new file
dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# resample data to daily
daily_groups = dataset.resample('D')
daily_data = daily_groups.sum()
# summarize
print(daily_data.shape)
print(daily_data.head())
# save
daily_data.to_csv('household_power_consumption_days.csv')При его выполнении создается новый набор данных с ежедневным потреблением электроэнергии, который затем сохраняется в отдельном файле «household_power_consumption_days.csv».
Созданный набор данных мы будем использовать для выполнения поставленной задачи с подбором и оценкой прогностических моделей.
Метрика оценки
Прогноз будет состоять из семи значений — по одному на каждый день предстоящей недели.
Как правило, при выполнении интервального прогнозирования каждый прогнозируемый временной шаг оценивается отдельно. Это полезно по нескольким причинам:
- Чтобы отметить уровень каждого временного шага (например, день «+1» против дня «+3»).
- Для сравнения качества моделей с разным временным шагом (например, модели с высокой оценкой прогноза на «день +1» и модели с высокой оценкой прогноза на «день +5»).
Так как единицами общей мощности являются киловатты, было бы полезным иметь метрику погрешности в тех же единицах (в том же масштабе). При этом и квадратный корень из среднеквадратической ошибки (RMSE), и средняя абсолютная ошибка (MAE) соответствуют этому масштабу, однако в руководстве будет использоваться именно квадратный корень из среднеквадратичной ошибки, поскольку эта метрика используется чаще. К тому же, в отличие от средней абсолютной ошибки, она больше штрафует модель за ошибки прогноза. Таким образом, метрикой для рассматриваемой проблемы в данном руководстве будет RMSE, рассчитываемая для каждого прогнозного временного шага (с 1-го по 7-мой день).
Эта же метрика будет использоваться в качестве результирующей оценки по всем прогнозируемым дням, учитывающей итоги работы модели. Это поможет в выборе лучшей модели.
Функция evaluate_forecasts(), представленная ниже, реализует вышеописанное решение.
# evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scoresПри выполнении функции сначала возвращается общее значение RMSE по всему прогнозу, а затем массив из значений RMSE по каждому дню.
Разделение набора данных на тренировочную и тестовую части
Первые три года данных мы будем использовать для обучения моделей, последний год – для их валидации (проверки).
Данные будут разделены на стандартные недели, которые начинаются в воскресенье, а заканчиваются в субботу.
Примечание: В США, Англии и других странах неделя начинается с воскресенья.
Это реалистичный и полезный способ подготовки данных для рассматриваемой проблемы прогнозирования энергопотребления на неделю вперёд. Это также практично с точки зрения использования моделей для прогнозирования конкретного дня (например, среды) или всей последовательности.
При этом разделение будет выполнено в обратном направлении – от валидационной части набора данных.
В ней последним годом является 2010 год, первое воскресение в котором было 3-го января. Заканчиваются данные в середине ноября 2010 года, ближайшая последняя суббота была 20 ноября. С учётом этого на валидацию отводится 46 недель.
Для подтверждения ниже приведены первая и последняя строки суточных данных валидационной части набора данных.
2010-01-03,2083.4539999999984,191.61000000000055,350992.12000000034,8703.600000000033,3842.0,4920.0,10074.0,15888.233355799992
...
2010-11-20,2197.006000000004,153.76800000000028,346475.9999999998,9320.20000000002,4367.0,2947.0,11433.0,17869.76663959999Обучающая часть набора данных формируется согласно следующему. Замеры начинаются в конце 2006 года. Первое воскресенье было 17 декабря, что соответствует второй строке данных. С учётом этого организация данных в стандартные недели даёт 159 полных недель для обучения модели.
2006-12-17,3390.46,226.0059999999994,345725.32000000024,14398.59999999998,2033.0,4187.0,13341.0,36946.66673200004
...
2010-01-02,1309.2679999999998,199.54600000000016,352332.8399999997,5489.7999999999865,801.0,298.0,6425.0,14297.133406600002Представленная ниже функция split_dataset() разбивает суточные данные на обучающие и валидационные части и организует их в еженедельные данные с помощью NumPy-функции split().
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, testПротестируйте вышеописанную функцию, загрузив суточный набор данных и распечатав первую и последнюю строки обучающих и валидационных данных, чтобы убедиться в соответствии расчётам.
Полный код разбиения данных приведён ниже.
# split into standard weeks
from numpy import split
from numpy import array
from pandas import read_csv
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
train, test = split_dataset(dataset.values)
# validate train data
print(train.shape)
print(train[0, 0, 0], train[-1, -1, 0])
# validate test
print(test.shape)
print(test[0, 0, 0], test[-1, -1, 0])Его выполнение показывает, что обучающая часть действительно содержит 159 недель данных, тогда как на валидационную отводится 46 недель. При этом и первая и последняя строки обеих частей соответствуют тем, которые мы определили в качестве границ с учётом стандартных недель.
(159, 7, 8)
3390.46 1309.2679999999998
(46, 7, 8)
2083.4539999999984 2197.006000000004Валидация с нарастающим размером блока
Модели будут оцениваться с использованием схемы называемой «валидацией с нарастающим размером блока» (Walk-Forward Validation).
С учётом того, что целью моделирования является прогноз потребления мощности на неделю вперёд, то подаваемые на вход модели фактические еженедельные данные можно использовать в качестве основы для прогнозирования будущих еженедельных значений. Данный подход находит широкое применение на практике.
Принцип вышеописанного подхода продемонстрирован ниже.
Вход Прогноз
[Неделя1] Неделя2
[Неделя1 + Неделя2] Неделя3
[Неделя1 + Неделя2 + Неделя3] Неделя4
...Примечание:
Небольшое дополнение к демонстрации подхода. Поскольку набор данных разбит на две части, то с учётом валидации с нарастающим размером блока фактическими данными для прогнозирования первой недели из валидационной части данных (160-я неделя) будут первые 159 недель, т.е. вся обучающая часть данных. В свою очередь, для прогнозирования второй недели валидационной части данных (161-я неделя) фактическими данными будут 159 обучающих недель плюс предыдущая неделя из валидационной части данных (160 неделя) и т.д.:
Код функции evaluate_model(), в которой реализован данный подход к оценке моделей на основе рассматриваемого набора данных, представлен ниже.
Аргументами функции являются обучающая и валидационная части набора данных в формате еженедельных данных, а также дополнительный аргумент n_input, определяющий количество предыдущих наблюдений, которые модель будет использовать в качестве входных данных (параметр n_input лучше всего представить как историю. – Прим. пер.) каждого временного интервала для прогнозирования.
Наряду с этим в данной функции вызываются две новые подфункции: build_model(), используемая для конструирования и обучения модели на обучающих данных, и forecast(), применяемая для выполнения прогнозов при поступлении новых еженедельных данных. Эти функции будут рассмотрены в следующих разделах.
В данном руководстве мы будем работать с искусственными нейронными сетями. Сами по себе они обычно долго обучаются, однако быстро выдают оценку. В связи с этим предпочтительное использование моделей состоит в том, чтобы сконструировать и обучить их один раз на исторических данных, и далее использовать для прогнозирования каждого шага валидации с нарастающим размером блока. Модели являются статическими, то есть не обновляются во время их оценивания.
В этом заключается отличие от других моделей, которые быстрее обучаются, когда модель может быть переоснащена или обновлена на каждом шаге валидации с нарастающим размером блока при поступлении новых данных. Необходимо отметить, что при наличии достаточных ресурсов таким же образом можно использовать и искусственные нейронные сети, однако в этом руководстве это не будет рассматриваться.
Полный код функции evaluate_model() приведён ниже.
# evaluate a single model
def evaluate_model(train, test, n_input):
# fit model
model = build_model(train, n_input)
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = forecast(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
# evaluate predictions days for each week
predictions = array(predictions)
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scoresПосле того как модель оценена, можно вывести итоги её выполнения.
Функция summarize_scores() отображает эффективность модели в виде строки со значениями для простого и наглядного сравнения с другими моделями.
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))Теперь у нас есть все элементы, чтобы начать выполнение оценки моделей на рассматриваемом наборе данных.
ДКП для интервального прогнозирования временных рядов
Рекуррентные нейронные сети (РНС) (в англоязычной терминологии Recurrent Neural Network, RNN. – Прим. пер.) предназначены для работы с данными в виде последовательностей.
Примечание:
Временные ряды или последовательности – трёхмерные тензоры с формой:
[образцы, метки времени, признаки]
Источник: Глубокое обучение на Python, Франсуа Шолле.
РНС – это разновидность искусственной нейронной сети, в которой выходные данные одного временного интервала предоставляются в качестве входных данных для следующего временного интервала. Данное обстоятельство позволяет РНС принимать решения об объекте прогноза, основываясь как на входных данных для текущего временного интервала, так и на выходных данных предыдущих шагов.
Возможно, наиболее успешным и оттого массово используемым типом (архитектурой) РНС является «Долгая краткосрочная память». Это объясняется тем, что данный тип преодолевает трудности, присущие обычной РНС*. В дополнении к особенности устанавливать связи между выходом предыдущего временного интервала и входом текущего, ДКП также имеет внутреннюю память, работающую как локальная переменная, что позволяет ДКП накапливать состояние поверх входной последовательности.
Примечание:
* Имеется в виду проблема затухания градиента, «напоминающего эффект, который наблюдается в нерекуррентных сетях (сетях прямого распространения) с большим количеством слоёв: по мере увеличения количества слоёв сеть в конечном итоге становится необучаемой… Слои LSTM и GRU создавались специально для решения этой проблемы».
Источник: Глубокое обучение на Python, Франсуа Шолле.
Для получения дополнительной информации о РНС смотрите следующую публикацию:
Для получения дополнительной информации о ДКП смотрите следующую публикацию:
При интервальном прогнозировании временных рядов у ДКП есть ряд преимуществ перед другими методами:
- Встроенная поддержка последовательностей. ДКП – это тип РНС, предназначенный для работы с последовательностями в качестве входных данных, что отличает их от других моделей, в которых лагированные (взятые в предыдущий момент времени. – Прим. пер.) данные будут представлены как входные признаки.
- Многомерные входы. ДКП напрямую поддерживают множественные параллельные входные последовательности в виде многомерных входных данных, что отличает их от других моделей, в которых многомерные входные данные представляются в виде плоской (2Д) структуры.
- Векторный вывод. Как и другие искусственные нейронные сети, ДКП могут отображать входные последовательности напрямую в выходной вектор, который может предоставлять множественные выходные временные интервалы.
Кроме того, разработаны специализированные архитектуры РНС для интервального прогнозирования последовательностей, называемые прогнозированием «последовательность в последовательность» (в англоязычной терминологии sequence-to-sequence, или seq2seq для краткости. – Прим. пер.).
Примером данной архитектуры является ДКП типа «кодировщик-декодировщик».
ДКП типа «кодировщик-декодировщик» – это модель, состоящая из двух субмоделей – кодировщика, считывающего и сжимающего входные последовательности во внутреннее представление фиксированной длины, и декодировщика, интерпретирующего внутреннее представление для прогнозирования выходной последовательности.
Данный подход к прогнозированию последовательностей показывает себя гораздо эффективнее, чем прямой вывод вектора, что делает его предпочтительным подходом к прогнозированию данных в виде последовательностей.
В целом было обнаружено, что ДКП не так эффективны при проблемах типа авторегрессии, когда прогнозирования следующего временного интервала является функцией предыдущих временных интервалов.
Подробнее об этой проблеме смотрите в следующей публикации:
Одномерные свёрточные нейронные сети (СНС) (в англоязычной терминологии Convolutional Neural Networks, CNN. – Прим. пер.) доказали свою эффективность в автоматическом изучении признаков из входных последовательностей.
Наиболее известный подход состоит в том, чтобы объединить СНС с ДКП в общую модель, в которой СНС выступает в качестве кодировщика для изучения признаков входных последовательных данных, передающихся ДКП как временные интервалы. Эта архитектура называется «СНС-ДКП» (в англоязычной терминологии CNN-LSTM. – Прим. пер.).
Для получения дополнительной информации об этой архитектуре смотрите следующую публикацию:
Изменение уровня мощности в архитектуре «СНС-ДКП» представлено в свёрточной ДКП (в англоязычной терминологии Convolutional LSTM, или ConvLSTM для краткости. – Прим. пер.), которая использует свёрточное считывание входных последовательностей в ячейках ДКП. Этот подход оказался очень эффективным для классификации временных рядов и может быть адаптирован для выполнения их интервального прогнозирования.
В этом руководстве мы рассмотрим набор различных архитектур ДКП для выполнения интервального прогнозирования временных рядов. В частности, мы рассмотрим, как выполнить следующие модели:
- Модель ДКП на основе одномерных входных данных с векторным выходом
- Модель ДКП типа «кодировщик-декодировщик» на основе одномерных входных данных
- Модель ДКП типа «кодировщик-декодировщик» на основе многомерных входных данных
- Модель ДКП типа «кодировщик-декодировщик» с добавлением свёрточного слоя в качестве кодировщика на основе одномерных входных данных
- Свёрточная модель ДКП типа «кодировщик-декодировщик» на основе одномерных входных данных
Если вы новичок в использовании ДКП для прогнозирования временных рядов, то я настоятельно рекомендую следующую публикацию:
Модели будут разработаны и продемонстрированы на примере решения проблемы прогнозирования домового энергопотребления. Модель будет считаться годной, если её оценка будет лучше, чем у наивной (упрощённой) модели, среднее значение оценки которой с учётом метрики RMSE составляет 465 киловатт (общая оценка за неделю).
Мы не будем фокусироваться на подборе оптимальных параметров моделей, чтобы улучшить их эффективность; вместо этого мы просто продемонстрируем модели, прогнозы которых лучше, чем наивный прогноз. Выбор представленных в примерах конфигураций и гиперпараметров ИНС объясняется методом проб и ошибок. Поэтому итоговые оценки следует рассматривать только в качестве примера, а не как исследование оптимальных параметров и конфигураций моделей для рассматриваемой проблемы.
Учитывая стохастический характер моделей, наиболее эффективно оценивать модель n-ое количество раз и затем вывести среднюю оценку эффективности. Однако вместо этого в целях сохранения простоты кода мы предоставим результаты одиночно оценённых моделей.
Мы не можем знать, какой подход будет наиболее эффективным для данной задачи интервального прогнозирования. Желательно изучить набор разных методов, чтобы выяснить, какие из них лучше всего работают на вашем наборе данных.
ДКП на основе одномерных входных данных и выходного вектора
Мы начнём с выполнения простой (или ванильной) модели ДКП, которая трансформирует общее еженедельное энергопотребление в дневные последовательности и выполняет прогноз энергопотребления на следующую неделю в виде выходного вектора.
Данное начало послужит основой для выполнения более сложных моделей, которые будут разработаны и описаны в последующих разделах.
Количество предыдущих дней, используемых в качестве входных данных, определяет одномерную последовательность данных, которая будет подаваться на вход ДКП для изучения и выделения признаков. Ниже представлены некоторые идеи об их возможном размере и характере.
- Все предыдущие дни за несколько лет.
- Предыдущие семь дней (одна неделя).
- Предыдущие две недели.
- Предыдущий месяц.
- Предыдущий год.
- Предыдущая неделя вместе с прошлогодней неделей.
Нет однозначного ответа на вопрос, какой размер использовать. Лучшим решением будет протестировать каждый из них вместе с другими подходами, а по результатам выполнения выбрать тот, который показал наилучшие результаты.
При этом выбор должен быть обусловлен следующими факторами:
- Каким образом должна быть подготовлена обучающая часть данных для обучения модели.
- Каким образом должна быть подготовлена валидационная часть данных для её оценки.
- Каким образом использовать законченную модель для выполнения прогнозов в будущем.
Хорошим началом будет использование семи предыдущих дней.
Модель ДКП ожидает, что входные данные будут иметь следующую (трёхмерную. – Прим. пер.) форму:
[образцы, временной интервал, признаки]С учётом семи дней ежедневной потребляемой мощности каждая выборка имеет временной интервал, длительность которого равна семи, и один признак.
Примечание:
Временной интервал это и есть «история» (параметр n_input), которая для нижеследующего примера принята за семь предыдущих дней.
Так как обучающая часть данных содержит 159 недель, то её форма будет иметь следующий вид:
[159, 7, 1]С этой формой данных модель будет использовать предыдущую неделю для прогнозирования следующей. Проблема в том, что 159 образцов – это очень маленькое количество данных для обучения модели.
Один из способов создания бoльшего количества данных состоит в том, чтобы изменить подход – выполнять прогнозирование потребления электроэнергии на следующие семь дней с учётом предыдущих несмотря на неделю (данное обстоятельство делает бессмысленным начальное преобразование обучающих и валидационных данных в еженедельную форму. – Прим. пер.).
Данное изменение относится только к обучающей части данных, предназначение валидационной части остаётся неизменным: с учётом данных предыдущей недели прогнозировать ежедневное энергопотребление на следующую неделю.
Для этого потребуется внести небольшие корректировки в подготовку обучающих данных.
Сначала обучающие данные на основе восьми признаков преобразовываются в недельные данные: в связи с этим их форма примет вид [159, 7, 8]. Следующим шагом является сглаживание данных. Делается это для того, чтобы получить восемь временных последовательностей (фактически выполняется обратное преобразование формы данных из 3Д в 2Д (см. примечание выше). – Прим. пер.).
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))Затем выполняется разделение данных на так называемые перекрывающиеся окна с учётом установленного временного интервала.
К примеру:
Вход, Выход
[d01, d02, d03, d04, d05, d06, d07], [d08, d09, d10, d11, d12, d13, d14]
[d02, d03, d04, d05, d06, d07, d08], [d09, d10, d11, d12, d13, d14, d15]
...Это можно сделать путём отслеживания начальных и конечных индексов для входов и выходов при выполнении итераций по всей длине сглаженных данных с учётом установленного временного интервала.
При этом количество входов и выходов (n_input и n_out соответственно) будет выделено и представлено в качестве аргументов рассматриваемой далее функции. Это делается с той целью, чтобы вы могли поэкспериментировать с их различными значениями применительно к вашей собственной задаче.
Примечание:
Аргумент n_input – это, как уже было сказано, история, то есть на какой прошедший временной интервал «опереться» модели, чтобы выполнить прогноз (n_out), а n_out – это аргумент, определяющий насколько далеко в будущее модель должна научиться прогнозировать (устанавливает длительность прогнозируемого временного интервала).
Ниже приведена функция с именем to_supervised(), которая принимает обучающие данные, историю (количество предыдущих наблюдений, которые модель будет использовать в качестве входных данных) и длительность прогнозируемого временного интервала, а возвращает массивы в формате перекрывающихся скользящих окон.
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
x_input = data[in_start:in_end, 0]
x_input = x_input.reshape((len(x_input), 1))
X.append(x_input)
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)При выполнении функции осуществляется преобразование 159 выборок в 1100; в связи с этим формы преобразованных данных примут следующий вид: X=[1100, 7, 1] и y=[1100, 7].
Далее определяется конфигурация модели и проводится её обучение.
По сути, данная проблема интервального прогнозирования временных рядов относится к авторегрессии. Это означает, что хороший результат может быть получен в том случае, когда следующие семь дней являются некоторой функцией наблюдений предыдущих. Данное обстоятельство наряду с относительно небольшим объёмом данных обуславливает применение «небольшой», простой по конфигурации, модели.
С учётом этого мы сконструируем модель с несколькими слоями. В роли первого скрытого слоя выступит слой ДКП с 200 нейронами (количество нейронов в скрытом слое не связано с длительностью временного интервала во входных последовательностях). За слоем ДКП следует полносвязный слой с 200 нейронами, назначение которого интерпретировать выявленные слоем ДКП признаки. Наконец, выходной слой будет напрямую выводить вектор с семью прогнозными элементами – по одному на каждый день в выходной последовательности.
За функцию потерь принята среднеквадратичная ошибка (MSE), поскольку она соответствует масштабу принятой ранее метрике (корень из среднеквадратической ошибки, RMSE). В качестве оптимизатора принят алгоритм Adam (вариант стохастического градиентного спуска), обучение модели будет длиться 70 эпох, размер пакета состоит из 16-ти образцов.
Небольшой размер пакета и стохастическая природа алгоритма означают, что одна и та же модель будет по-разному отображать входные и выходные данные при повторном обучении. Это приведёт к тому, что после выполнения оценки моделей, их результаты могу отличаться друг от друга. Вы можете попробовать выполнить обучение модели несколько раз и в подсчётах итоговых результатов использовать среднее значение.
Представленная ниже функция build_model() подготавливает обучающую часть данных, определяет конфигурацию модели, выполняет её обучение и возвращает обученную модель, которую затем можно использовать для выполнения прогнозов.
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 70, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# define model
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(Dense(100, activation='relu'))
model.add(Dense(n_outputs))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return modelТеперь, когда модель обучена, мы можем проверить как она будет выполнять прогнозы.
Как правило, модель ожидает, что данные будут иметь одинаковую трёхмерную форму.
В нашем случае ожидаемая форма входного образца с учётом ежедневной потребляемой мощности следующая: «одна выборка – временной интервал длительностью 7 дней – один признак»:
[1, 7, 1]Данную форму должны иметь не только данные валидационной части набора данных, но и «новые», поступающие данные, которые будут использоваться обученной моделью для прогнозирования в будущем. При изменении параметра n-input на 14 дней длительность временного интервала будет также составлять 14 дней, поэтому форма обучающих данных и новых выборок для выполнения прогнозирования должны быть изменены соответствующим образом. При этом о длительности временного интервала необходимо позаботиться в самом начале.
В данном руководстве используется валидация с нарастающим размером блока, описанная в предыдущем разделе. В соответствии с принятыми решениями прогнозирование энергопотребления на предстоящую неделю выполняется на основе наблюдений предыдущей недели. Предыдущие недели собраны в массив, называемый history.
Чтобы предсказать следующую неделю, нужно возвратить последние дни наблюдений. Как и в случае с обучающими данными, сначала необходимо сгладить данные history, удалив недельную структуру, чтобы получить восемь параллельных временных последовательностей.
# flatten data
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))Затем нужно получить ежедневные значения общей потребляемой мощности (признак под индексом 0) за последние семь дней.
Как и в случае с подготовкой обучающих данных, мы будем использовать для этого выделенный ранее параметр n_input, чтобы число предыдущих дней, используемых в качестве входных данных для модели, могло быть изменено в будущем.
# retrieve last observations for input data
input_x = data[-n_input:, 0]Затем изменим форму входных данных в ожидаемую моделью трёхмерную структуру.
# reshape into [1, n_input, 1]
input_x = input_x.reshape((1, len(input_x), 1))Далее на основе обученной модели и входных данных выполняется прогноз с извлечением выходного вектора, состоящего из семи дней.
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]Представленная ниже функция forecast() реализует вышеописанные решения, принимая в качестве аргументов обученную модель, список данных предыдущих недель, наблюдаемых до настоящего времени (параметр history, сформированный по результатам валидации с нарастающим размером блока) и временной интервал.
# make a forecast
def forecast(model, history, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, 0]
# reshape into [1, n_input, 1]
input_x = input_x.reshape((1, len(input_x), 1))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhatВот и всё. Теперь у нас есть всё необходимое для выполнения интервального прогнозирования временных рядов с помощью модели ДКП на основе одномерных входных данных ежедневной общей потребляемой мощности.
Полный пример кода представлен ниже.
# univariate multi-step lstm
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import LSTM
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scores
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
x_input = data[in_start:in_end, 0]
x_input = x_input.reshape((len(x_input), 1))
X.append(x_input)
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 70, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# define model
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(Dense(100, activation='relu'))
model.add(Dense(n_outputs))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return model
# make a forecast
def forecast(model, history, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, 0]
# reshape into [1, n_input, 1]
input_x = input_x.reshape((1, len(input_x), 1))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhat
# evaluate a single model
def evaluate_model(train, test, n_input):
# fit model
model = build_model(train, n_input)
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = forecast(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
# evaluate predictions days for each week
predictions = array(predictions)
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# evaluate model and get scores
n_input = 7
score, scores = evaluate_model(train, test, n_input)
# summarize scores
summarize_scores('lstm', score, scores)
# plot scores
days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat']
pyplot.plot(days, scores, marker='o', label='lstm')
pyplot.show()Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю (по всему прогнозу) и значением RMSE по каждому дню прогнозируемой недели.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
В данном случае по сравнению с наивным прогнозом модель справилась лучше: общее значение RMSE около 399 киловатт, что меньше значения 485 киловатт, достигнутого наивной моделью.
lstm: [399.456] 419.4, 422.1, 384.5, 395.1, 403.9, 317.7, 441.5График со значениями ошибки по каждому дню прогнозируемой недели представлен ниже.
Из графика видно, что вторники и пятницы являются более лёгкими для прогнозирования днями, чем остальные, а суббота является самым трудным днём для прогнозирования.
Примечание:
В примеры данного руководства было бы полезно включить графики, визуализирующие результаты выполнения прогнозирования. Графики можно выполнить по-разному. В виду того, что интервал прогноза энергопотребления составляет 7 дней в будущее (параметр n_out), что не так много и не вызывает затруднений в плане задействованных ресурсов и времени выполнения кода, то выведем отдельный график RMSE по каждому дню прогнозируемой недели. Для этого добавим новую функцию show_plot():
def show_plot(true, pred, title):
fig = pyplot.subplots()
pyplot.plot(true, label='Y_original')
pyplot.plot(pred, dashes=[4, 3], label='Y_predicted')
pyplot.xlabel('N_samples', fontsize=12)
pyplot.ylabel('Instance_value', fontsize=12)
pyplot.title(title, fontsize=12)
pyplot.grid(True)
pyplot.legend(loc='upper right')
pyplot.show()
Также дополним функцию evaluate_forecasts() следующими строками:
for j in range(predicted.shape[1]):
show_plot(actual[:, j], predicted[:, j], j + 1)
Наконец, построение графика со значениями ошибки по каждому дню прогнозируемой недели дополняется следующей строкой:
fig = pyplot.subplots()
Полный код с учётом данных изменений находится здесь
# univariate multi-step lstm
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import LSTM
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
def show_plot(true, pred, title):
fig = pyplot.subplots()
pyplot.plot(true, label='Y_original')
pyplot.plot(pred, dashes=[4, 3], label='Y_predicted')
pyplot.xlabel('N_samples', fontsize=12)
pyplot.ylabel('Instance_value', fontsize=12)
pyplot.title(title, fontsize=12)
pyplot.grid(True)
pyplot.legend(loc='upper right')
pyplot.show()
# # evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
# plot forecasts vs observations
for j in range(predicted.shape[1]):
show_plot(actual[:, j], predicted[:, j], j + 1)
return score, scores
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
x_input = data[in_start:in_end, 0]
x_input = x_input.reshape((len(x_input), 1))
X.append(x_input)
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 70, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# define model
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(Dense(100, activation='relu'))
model.add(Dense(n_outputs))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return model
# make a forecast
def forecast(model, history, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, 0]
# reshape into [1, n_input, 1]
input_x = input_x.reshape((1, len(input_x), 1))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhat
# evaluate a single model
def evaluate_model(train, test, n_input):
# fit model
model = build_model(train, n_input)
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = forecast(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
# evaluate predictions days for each week
predictions = array(predictions)
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0,
infer_datetime_format=True, parse_dates=['datetime'],
index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# evaluate model and get scores
n_input = 7
score, scores = evaluate_model(train, test, n_input)
# summarize scores
summarize_scores('lstm', score, scores)
# plot scores
days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat']
fig = pyplot.subplots()
pyplot.plot(days, scores, marker='o', label='lstm')
pyplot.show()
При его выполнении у меня отобразились следующие результаты



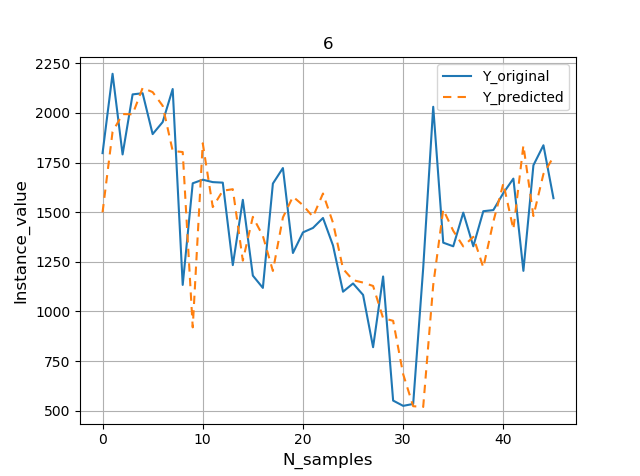
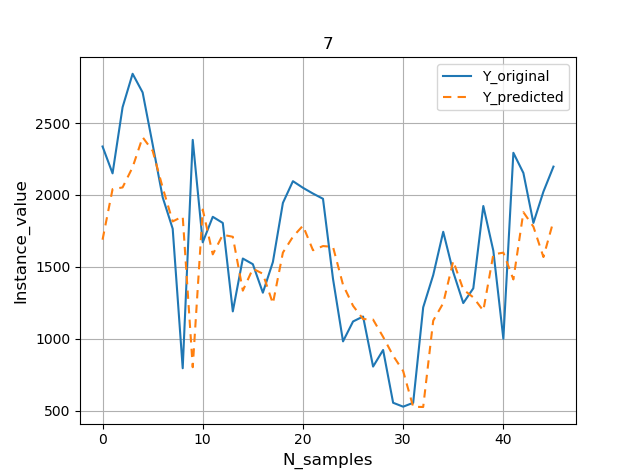
На основании этих графиков и значений ошибок можно сделать вывод, что модель лучше всего справилась с пятничными данными, в то время как с субботними данными прогноз плох.
lstm: [401.716] 418.6, 413.2, 408.7, 393.8, 395.6, 315.0, 453.8На основании этих графиков и значений ошибок можно сделать вывод, что модель лучше всего справилась с пятничными данными, в то время как с субботними данными прогноз плох.
Давайте увеличим количество предыдущих дней, используемых в качестве входных данных, с 7 до 14 дней, изменив значение параметра n_input:
# evaluate model and get scores
n_input = 14Перезапуск примера с учётом выполненного изменения выведет сводную информацию о качестве модели.
Ваши результаты могут отличаться от представленных ниже. Попробуйте выполнить пример несколько раз.
По результатам видно, что значение общей ошибки RMSE снизилось до 370 киловатт. Поэтому можно предположить, что дальнейшая настройка размера n_input и, возможно, количества узлов модели может увеличить её эффективность.
lstm: [370.028] 387.4, 377.9, 334.0, 371.2, 367.1, 330.4, 415.1При сравнении значений RMSE по каждому дню друг с другом видно, что некоторые дни хуже, а другие лучше справляются с прогнозом по сравнению с использованием семидневных входных данных.
Можно предположить, что совместное использование двух входов с разными размерами – например, с помощью ансамбля, объединяющего два данных подхода, или единой модели («многоголовая» модель), считывающей обучающие данных разными способами, – способно принести пользу.
ДКП типа «кодировщик-декодировщик» на основе одномерных входных данных
В этом разделе рассказывается о том, как обновить ванильную модель до модели ДКП типа «кодировщик-декодировщик» (в англоязычной терминологии Encoder-Decoder LSTM. – Прим. пер.).
Модель не будет выводить векторную последовательность напрямую; она будет состоять из двух субмоделей – кодировщика, считывающего и кодирующего входную последовательность, и декодировщика, интерпретирующего кодированную входную последовательность и выполняющего точечное прогнозирование для каждого элемента в выходной последовательности.
Разница между моделями невелика: на практике они обе выводят прогноз в виде последовательности.
Особенность рассматриваемой в данном разделе модели в том, что ДКП используется в качестве декодировщика: слой с ДКП собирает информацию о выполнении прогнозирования в предыдущие дни в последовательности, а также накапливает внутреннее состояние при выводе каждой последовательности.
Рассмотрим подробнее, как определяется эта модель.
Как и прежде, определяется скрытый слой ДКП с 200 нейронами. Только этот слой будет выступать в роли декодировщика, который будет считывать входную последовательность и выводить вектор из 200 элементов (один выход на единицу) согласно выявленным из входной последовательности признакам. В качестве входных данных будут использованы 14 дней общего энергопотребления.
# define model
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_timesteps, n_features)))В примере будет использована простая архитектура «кодировщик-декодировщик», которую легко реализовать с помощью Keras. Данная архитектура имеет много сходств с архитектурой ДКП типа «автокодировщик» (в англоязычной терминологии LSTM Autoencoder. – Прим. пер.).
Примечание:
ДКП типа «автокодировщик» – это одна из реализаций автокодировщика – разновидности ИНС, целью которой является кодирование входного малоразмерного скрытого пространства и последующего его декодирования – применительно к данным в виде последовательностей.
Сначала внутреннее представление входной последовательности повторяется несколько раз – по одному разу для каждого временного шага в выходной последовательности. Эта последовательность векторов будет представлена декодировщику ДКП.
model.add(RepeatVector(7))Затем определяется декодировщик в виде скрытого слоя ДКП с 200 нейронами.
Важно отметить, что декодировщик будет выводить всю последовательность, а не только вывод в конце последовательности, как было с кодировщиком. Это означает, что каждый из 200 нейронов будет связан с каждым днём прогнозируемой недели, что позволит определиться с тем, что именно нужно прогнозировать для каждого дня выходной последовательности.
model.add(LSTM(200, activation='relu', return_sequences=True))Далее следует полносвязный слой для интерпретации каждого временного шага в выходной последовательности перед окончательным выходным слоем. Важно отметить, что выходной слой прогнозирует один шаг в выходной последовательности, а не все семь дней сразу.
Это означает, что к каждому элементу в выходной последовательности будут применяться одинаковые слои: один и тот же полносвязный и выходной слои будут применены для обработки каждого временного шага, предоставляемого декодировщиком. Для этого слой интерпретации и выходной слой будут помещены в оболочку TimeDistributed, которая позволяет использовать обёрнутые слои для каждого временного шага.
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))Это позволит ДКП-декодировщику установить связь между временными шагами в выходной последовательности и обёрнутыми полносвязными слоями, чтобы интерпретировать каждый из временных шагов по отдельности с использованием одних и тех же весовых коэффициентов. Альтернативным решением может быть сглаживание всей структуры, созданной декодировщиком, и прямой вывод вектора. Вы можете попробовать выполнить его в качестве расширения примера и посмотреть на результаты сравнения.
Таким образом, выход сети представляется в виде трёхмерного тензора с той же структурой, что и у входной последовательности: [образцы, временной интервал, признаки].
Имеется один признак – общая потребляемая мощность (в ежедневной форме) – и его семь лагированных наблюдений. Следовательно, один еженедельный прогноз будет иметь форму: [1, 7, 1].
Примечание:
Напоминание: в данном разделе рассматривается одномерная модель, то есть модель, в которой и набор входных признаков (X), и набор целевых данных (y) формируется на основе одного-единственного признака – общей потребляемой мощности.
Поэтому перед обучением модели необходимо преобразовать целевые данные (y) из двухмерной формы [образцы, признаки], использованной в предыдущем разделе, в трёхмерную форму.
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))Обновлённая функция build_model() с учётом данных изменений представлена ниже.
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 20, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))
# define model
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(RepeatVector(n_outputs))
model.add(LSTM(200, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return modelПолный пример кода одномерной модели ДКП типа «кодировщик-декодировщик» представлен ниже.
# univariate multi-step encoder-decoder lstm
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import LSTM
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scores
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
x_input = data[in_start:in_end, 0]
x_input = x_input.reshape((len(x_input), 1))
X.append(x_input)
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 20, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))
# define model
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(RepeatVector(n_outputs))
model.add(LSTM(200, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return model
# make a forecast
def forecast(model, history, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, 0]
# reshape into [1, n_input, 1]
input_x = input_x.reshape((1, len(input_x), 1))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhat
# evaluate a single model
def evaluate_model(train, test, n_input):
# fit model
model = build_model(train, n_input)
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = forecast(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
# evaluate predictions days for each week
predictions = array(predictions)
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# evaluate model and get scores
n_input = 14
score, scores = evaluate_model(train, test, n_input)
# summarize scores
summarize_scores('lstm', score, scores)
# plot scores
days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat']
pyplot.plot(days, scores, marker='o', label='lstm')
pyplot.show()Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогнозируемой недели на валидационной части набора данных.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
В данном случае модель тоже справилась с прогнозом лучше, чем наивная модель: общее значение RMSE около 372 киловатт
lstm: [372.595] 379.5, 399.8, 339.6, 372.2, 370.9, 309.9, 424.8График со значением ошибки RMSE по каждому дню прогнозируемой недели выполняется аналогично предыдущему разделу.
Примечание:
Для общего представления выведем совокупный график по всем временным интервалам
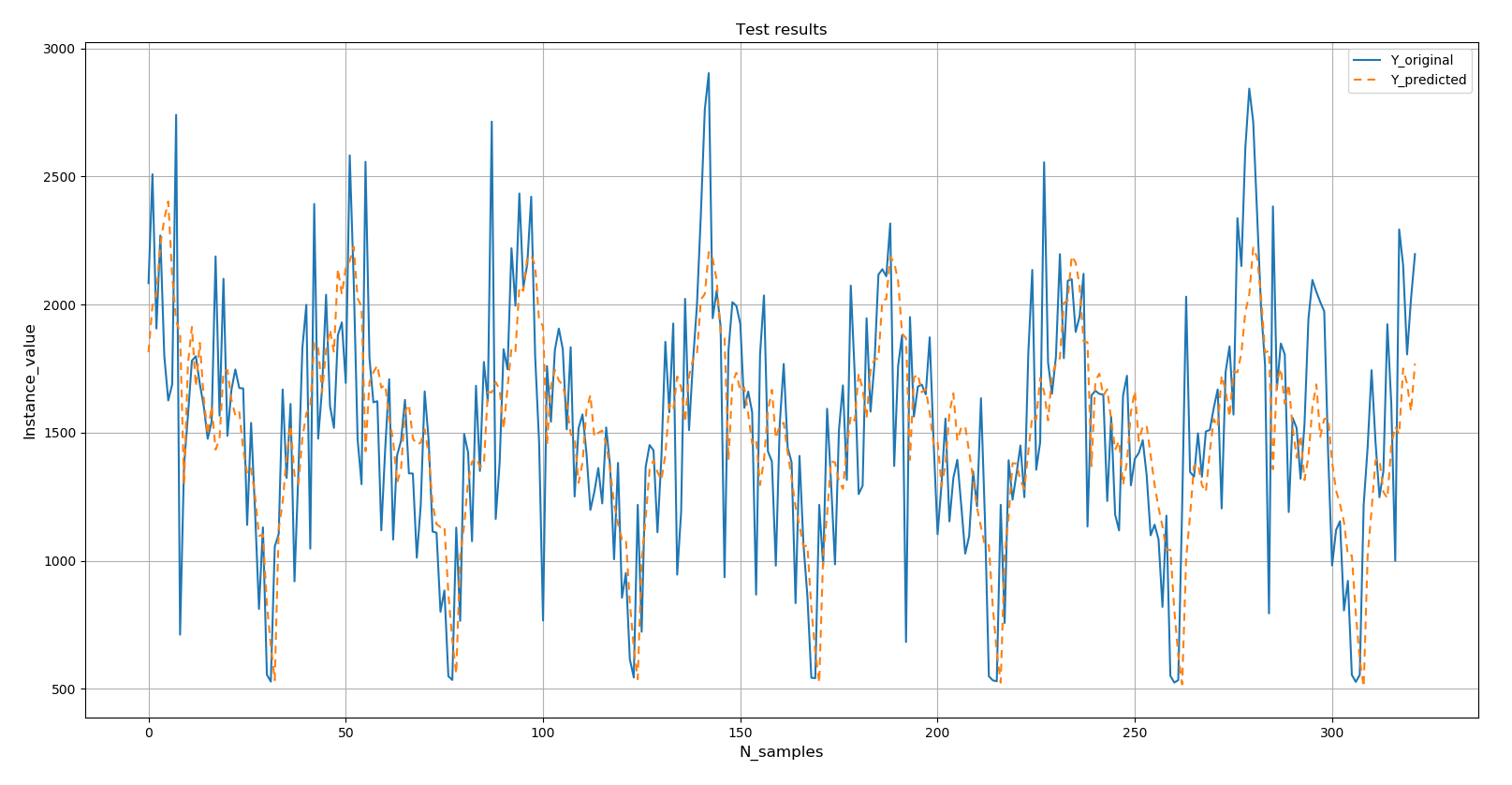
Видно, что волнообразная форма более-менее воспроизведена, однако большинство пик так и остались непокорёнными. Тут не то чтобы есть куда расти, а предстоит большая работа по дополнению кода. О некоторых техниках и методах, которые должны улучшить результаты моделирования, будет рассказано в конце статьи.
lstm: [369.602]Видно, что волнообразная форма более-менее воспроизведена, однако большинство пик так и остались непокорёнными. Тут не то чтобы есть куда расти, а предстоит большая работа по дополнению кода. О некоторых техниках и методах, которые должны улучшить результаты моделирования, будет рассказано в конце статьи.
ДКП типа «кодировщик-декодировщик» на основе многомерных входных данных
В этом разделе будет рассмотрено обновление разработанной в предыдущем разделе модели ДКП типа «кодировщик-декодировщик», состоящее в том, чтобы для прогнозирования электроэнергии на следующую неделю использовать каждый из восьми признаков в виде одномерного временного ряда.
Для этого каждый из них будет представлен модели в виде отдельной входной последовательности.
В свою очередь ДКП создаст внутреннее представление для каждой входной последовательности, которые будут затем совместно использоваться для интерпретирования декодировщиком.
Использование многомерных входных данных полезно при решении проблем, когда выходная последовательность является некоторой функцией от наблюдений предыдущих временных интервалов множества различных признаков, а не только от прогнозируемого признака. Пока непонятно, подойдёт ли этот подход для решения проблемы прогнозирования потребления электроэнергии, поэтому необходимо исследовать этот вопрос.
Сначала выполним обновление подготовки обучающих данных, включив в неё все восемь признаков, а не только ежедневную общую потребляемую мощность, откорректировав одну строку:
X.append(data[in_start:in_end, :])Обновлённая функция to_supervised() с учётом данного изменения представлена ниже.
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
X.append(data[in_start:in_end, :])
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)Также необходимо обновить функцию, используемую для выполнения прогнозов на основе обученной модели, чтобы использовать все восемь признаков на предыдущих временных интервалах.
Для этого внесём в неё небольшие изменения:
# retrieve last observations for input data
input_x = data[-n_input:, :]
# reshape into [1, n_input, n]
input_x = input_x.reshape((1, input_x.shape[0], input_x.shape[1]))Обновлённая функция forecast() с учётом данного изменения представлена ниже.
# make a forecast
def forecast(model, history, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, :]
# reshape into [1, n_input, n]
input_x = input_x.reshape((1, input_x.shape[0], input_x.shape[1]))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhatИспользуется та же архитектура и конфигурация модели, что и ранее, однако в виду восьмикратного увеличения количества входных данных количество тренировочных эпох увеличится с 20 до 50.
Полный пример кода многомерной модели ДКП типа «кодировщик-декодировщик» представлен ниже.
# multivariate multi-step encoder-decoder lstm
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import LSTM
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scores
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
X.append(data[in_start:in_end, :])
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 50, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))
# define model
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(RepeatVector(n_outputs))
model.add(LSTM(200, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return model
# make a forecast
def forecast(model, history, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, :]
# reshape into [1, n_input, n]
input_x = input_x.reshape((1, input_x.shape[0], input_x.shape[1]))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhat
# evaluate a single model
def evaluate_model(train, test, n_input):
# fit model
model = build_model(train, n_input)
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = forecast(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
# evaluate predictions days for each week
predictions = array(predictions)
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# evaluate model and get scores
n_input = 14
score, scores = evaluate_model(train, test, n_input)
# summarize scores
summarize_scores('lstm', score, scores)
# plot scores
days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat']
pyplot.plot(days, scores, marker='o', label='lstm')
pyplot.show()Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогноза на валидационной части набора данных.
Эксперимент показал, что модель ДКП типа «кодировщик-декодировщик» на основе многомерных входных данных выглядит менее стабильной, чем одномерная модель. Это может быть связано с различным масштабом данных входных признаков.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
Видно, что и в этом случае модель справилась с прогнозом лучше, чем наивная модель: общее значение RMSE около 376 киловатт.
lstm: [376.273] 378.5, 381.5, 328.4, 388.3, 361.2, 308.0, 467.2Ниже представлен график RMSE на каждый день прогнозируемой недели.
ДКП типа «кодировщик-декодировщик» с добавлением свёрточного слоя в качестве кодировщика на основе одномерных входных данных
Свёрточная нейронная сеть (СНС) может быть использована в качестве кодировщика в архитектуре ДКП типа «кодировщик-декодировщик».
При этом СНС не поддерживает ввод данных в виде последовательностей напрямую; вместо этого одномерная СНС способна последовательно считывать элементы входной последовательности и автоматически изучать характерные признаки (по сути свёртка работает методом перекрывающегося скользящего окна, которое перемещается не по тензору с изображением, а по входной последовательности. – Прим. пер.). Затем они могут быть интерпретированы декодировщиком ДКП как обычно. Совместное использование СНС и ДКП относится к гибридным моделям (СНС-ДКП).
Как и модель ДКП, СНС принимает на входе трёхмерные тензоры, только каждый из признаков считывается как отдельный канал, что в конечном итоге имеет тот же эффект.
Мы упростим пример, сосредоточившись на одномерной модели СНС-ДКП. Однако модель можно легко обновить, чтобы использовать все признаки (оставлено в качестве упражнения).
Примечание:
В Keras одномерные свёрточные сети создаются с помощью слоя Conv1D.
Окно свёртки — это одномерное окно на оси времени: оси с индексом 1 во входном тензоре.
Источник: Глубокое обучение на Python, Франсуа Шолле.
Как и прежде, в качестве входных данных будут использованы 14 дней общего энергопотребления.
Мы определим простую и в то же время эффективную архитектуру СНС в качестве кодировщика, состоящую из двух свёрточных уровней, за которым следует слой объединения по максимуму (MaxPooling1D), результаты которого далее сглаживаются.
Примечание:
Max-pooling – это операция выбора максимального значения из соседних. Её предназначение заключается «в агрессивном уменьшении разрешения карты признаков, во многом подобное свёртке с пробелами». Подробнее в книге Ф. Шолле.
Первый свёрточный слой последовательно считывает элементы входной последовательности и проецирует результаты на карты признаков. Второй свёрточный слой выполняет ту же операцию с той лишь разницей, что считывание выполняется уже на картах признаков, созданных первым слоем, пытаясь тем самым усилить любые существенные характеристики. Каждый свёрточный слой будет использовать 64 фильтра и считывать входные последовательности с размером ядра в три временных шага.
Слой объединения по максимуму выполняет упрощающие преобразования карты признаков, сохраняя ? значений с наибольшим (максимальным) сигналом. После слоя объединения по максимуму извлечённые карты признаков преобразуются в один длинный вектор, которым затем будет использован в качестве входных данных для процесса декодирования.
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features)))
model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())Определение декодировщика аналогично предыдущему разделу.
Единственное дополнительное изменение – установить количество эпох обучения равным 20.
Обновлённая функция build_model() с учётом данных изменений представлена ниже.
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 20, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))
# define model
model = Sequential()
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features)))
model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(RepeatVector(n_outputs))
model.add(LSTM(200, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return modelТеперь всё готово, чтобы испытать архитектуру «кодировщик-декодировщик» со свёрточным слоем в качестве кодировщика.
Полный пример кода одномерной модели ДКП типа «кодировщик-декодировщик» с добавлением свёрточного слоя в качестве кодировщика представлен ниже.
# univariate multi-step encoder-decoder cnn-lstm
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import LSTM
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scores
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
x_input = data[in_start:in_end, 0]
x_input = x_input.reshape((len(x_input), 1))
X.append(x_input)
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)
# train the model
def build_model(train, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 20, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))
# define model
model = Sequential()
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features)))
model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(RepeatVector(n_outputs))
model.add(LSTM(200, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return model
# make a forecast
def forecast(model, history, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, 0]
# reshape into [1, n_input, 1]
input_x = input_x.reshape((1, len(input_x), 1))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhat
# evaluate a single model
def evaluate_model(train, test, n_input):
# fit model
model = build_model(train, n_input)
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = forecast(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
# evaluate predictions days for each week
predictions = array(predictions)
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# evaluate model and get scores
n_input = 14
score, scores = evaluate_model(train, test, n_input)
# summarize scores
summarize_scores('lstm', score, scores)
# plot scores
days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat']
pyplot.plot(days, scores, marker='o', label='lstm')
pyplot.show()Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогноза на валидационной части набора данных.
Небольшой эксперимент показал, что использование двух свёрточных слоёв делает модель более стабильной, чем при использовании только одного слоя.
В виду стохастической природы алгоритма ваши результаты могут отличаться от представленных далее. Вы можете попробовать выполнить код несколько раз.
Видно, что и в этом случае модель справилась с прогнозом лучше, чем наивная модель: общее значение RMSE около 372 киловатт.
lstm: [372.055] 383.8, 381.6, 339.1, 371.8, 371.8, 319.6, 427.2Ниже представлен график RMSE на каждый день прогнозируемой недели.
Свёрточная ДКП типа «кодировщик-декодировщик» на основе одномерных входных данных
Расширением подхода СНС-ДКП является выполнение свёрток СНС (например, как СНС считывает данные входной последовательности) как часть ДКП для каждого временного интервала.
Эта комбинация называется «свёрточная ДКП» (в англоязычной терминологии Convolutional LSTM, или ConvLSTM для краткости. – Прим. пер.). Как и СНС-ДКП она также используется для пространственно-временных данных.
В отличие от модели ДКП, считывающей данные напрямую для вычисления внутреннего состояния и переходов состояний, и модели СНС-ДКП, интерпретирующей выходные данные моделей СНС, свёрточная ДКП использует свёртки непосредственно как часть чтения входных данных в ячейках LSTM (имеется в виду, что не только входные, но и рекуррентные преобразования подвергаются свёртке; другими словами, внутренние матрицы заменяются операциями свёртки, в результате чего данные, проходящие через ячейки свёрточной ДКП сохраняют входное измерение вместо того, чтобы быть просто одномерным вектором. – Прим. пер.).
Более полная информация о том, как выводятся уравнения для свёрточной ДКП, представлена в следующей статье:
Библиотека Keras предоставляет класс под названием ConvLSTM2D для работы со свёрточной ДКП на основе двухмерных данных (имеются в виду двухмерные изображения (ширина и высота). – Прим. пер.). Он также может быть настроен для выполнения прогнозирования одномерных временных рядов (1Д).
По умолчанию класс ConvLSTM2D ожидает, что входные данные будут иметь следующую (пятимерную. – Прим. пер.) форму:
[выборки, временной интервал, строки, столбцы, каналы]Где каждый из временных интервалов определяется как изображение (строки * столбцы) в виде точек (пикселей).
Предположим, что в качестве входных данных мы используем ежедневные данные за предыдущие две недели. В виду того, что мы работает с одномерной последовательностью общего потребления электроэнергии, то её можно интерпретировать как одну строку с 14 столбцами.
В этом случае свёрточная ДКП выполнит однократное чтение: ДКП будет считывать один временной интервал продолжительностью 14 дней и выполнять на них свёрточную операцию.
Это не идеально.
Вместо этого мы может разделить последовательность продолжительностью 14 дней на две подпоследовательности продолжительностью по 7 дней каждая. Затем свёрточная ДКП будет последовательно считывать элементы двух временных интервалов протяжённостью 7 дней с выполнением операции свёртки на каждом из них.
Таким образом, с учётом поставленной задачи вход для слоя ConvLSTM2D будет:
[n, 2, 1, 7, 1]Или:
- Образцы: n, количество примеров в обучающей части набора данных.
- Время: 2, для двух подпоследовательностей, на которые мы разбили последовательность в 14 дней.
- Строки: 1, для одномерной формы каждой подпоследовательности.
- Столбцы: 7, по семь дней в каждой подпоследовательности.
- Каналы: 1, для единственного признака, который используется в качестве входных данных.
Вы можете исследовать и другие возможные конфигурации: например, передачу на вход модели данных за 21 день в виде 3-х подпоследовательностей по 7 дней каждая и/или предоставление данных 8-ми признаков (каналов).
Теперь подготовим данные для модели ConvLSTM2D.
Сначала мы должны изменить форму обучающей части набора данных в ожидаемую моделью пятимерную структуру [выборки, временной интервал, строки, столбцы, каналы].
# reshape into subsequences [samples, time steps, rows, cols, channels]
train_x = train_x.reshape((train_x.shape[0], n_steps, 1, n_length, n_features))Затем определим в качестве кодировщика свёрточную ДКП (первый скрытый слой), за которым следует слой сглаживания данных для их подготовки к декодированию.
model.add(ConvLSTM2D(filters=64, kernel_size=(1,3), activation='relu', input_shape=(n_steps, 1, n_length, n_features)))
model.add(Flatten())При этом количество подпоследовательностей (n_steps) и длина каждой подпоследовательности (n_length) будут выделены и представлены в качестве аргументов функции.
В остальном конфигурация модели и её обучение аналогичны предыдущему разделу. Функция build_model() с учётом данных изменений представлена ниже.
# train the model
def build_model(train, n_steps, n_length, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 20, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# reshape into subsequences [samples, time steps, rows, cols, channels]
train_x = train_x.reshape((train_x.shape[0], n_steps, 1, n_length, n_features))
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))
# define model
model = Sequential()
model.add(ConvLSTM2D(filters=64, kernel_size=(1,3), activation='relu', input_shape=(n_steps, 1, n_length, n_features)))
model.add(Flatten())
model.add(RepeatVector(n_outputs))
model.add(LSTM(200, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return modelЭта модель ожидает пятимерные данные в качестве входных данных. Поэтому также необходимо обновить подготовку образцов в функции forecast() для последующего выполнения прогнозирования.
# reshape into [samples, time steps, rows, cols, channels]
input_x = input_x.reshape((1, n_steps, 1, n_length, 1))Обновлённая функция forecast() с учётом данного изменения и выделения параметров n_steps и n_length в качестве её аргументов представлена ниже.
# make a forecast
def forecast(model, history, n_steps, n_length, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, 0]
# reshape into [samples, time steps, rows, cols, channels]
input_x = input_x.reshape((1, n_steps, 1, n_length, 1))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhatТеперь у нас есть все элементы, чтобы начать выполнение оценки архитектуры «кодировщик-декодировщик» для интервального прогнозирования временных рядов, в которой в роли кодировщика используется свёрточная ДКП.
Полный пример кода одномерной свёрточной модели ДКП типа «кодировщик-декодировщик» представлен ниже.
# univariate multi-step encoder-decoder convlstm
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import LSTM
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
from keras.layers import ConvLSTM2D
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
# evaluate one or more weekly forecasts against expected values
def evaluate_forecasts(actual, predicted):
scores = list()
# calculate an RMSE score for each day
for i in range(actual.shape[1]):
# calculate mse
mse = mean_squared_error(actual[:, i], predicted[:, i])
# calculate rmse
rmse = sqrt(mse)
# store
scores.append(rmse)
# calculate overall RMSE
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] - predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
return score, scores
# summarize scores
def summarize_scores(name, score, scores):
s_scores = ', '.join(['%.1f' % s for s in scores])
print('%s: [%.3f] %s' % (name, score, s_scores))
# convert history into inputs and outputs
def to_supervised(train, n_input, n_out=7):
# flatten data
data = train.reshape((train.shape[0]*train.shape[1], train.shape[2]))
X, y = list(), list()
in_start = 0
# step over the entire history one time step at a time
for _ in range(len(data)):
# define the end of the input sequence
in_end = in_start + n_input
out_end = in_end + n_out
# ensure we have enough data for this instance
if out_end <= len(data):
x_input = data[in_start:in_end, 0]
x_input = x_input.reshape((len(x_input), 1))
X.append(x_input)
y.append(data[in_end:out_end, 0])
# move along one time step
in_start += 1
return array(X), array(y)
# train the model
def build_model(train, n_steps, n_length, n_input):
# prepare data
train_x, train_y = to_supervised(train, n_input)
# define parameters
verbose, epochs, batch_size = 0, 20, 16
n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1]
# reshape into subsequences [samples, time steps, rows, cols, channels]
train_x = train_x.reshape((train_x.shape[0], n_steps, 1, n_length, n_features))
# reshape output into [samples, timesteps, features]
train_y = train_y.reshape((train_y.shape[0], train_y.shape[1], 1))
# define model
model = Sequential()
model.add(ConvLSTM2D(filters=64, kernel_size=(1,3), activation='relu', input_shape=(n_steps, 1, n_length, n_features)))
model.add(Flatten())
model.add(RepeatVector(n_outputs))
model.add(LSTM(200, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(100, activation='relu')))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mse', optimizer='adam')
# fit network
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose)
return model
# make a forecast
def forecast(model, history, n_steps, n_length, n_input):
# flatten data
data = array(history)
data = data.reshape((data.shape[0]*data.shape[1], data.shape[2]))
# retrieve last observations for input data
input_x = data[-n_input:, 0]
# reshape into [samples, time steps, rows, cols, channels]
input_x = input_x.reshape((1, n_steps, 1, n_length, 1))
# forecast the next week
yhat = model.predict(input_x, verbose=0)
# we only want the vector forecast
yhat = yhat[0]
return yhat
# evaluate a single model
def evaluate_model(train, test, n_steps, n_length, n_input):
# fit model
model = build_model(train, n_steps, n_length, n_input)
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = forecast(model, history, n_steps, n_length, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
# evaluate predictions days for each week
predictions = array(predictions)
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# load the new file
dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# split into train and test
train, test = split_dataset(dataset.values)
# define the number of subsequences and the length of subsequences
n_steps, n_length = 2, 7
# define the total days to use as input
n_input = n_length * n_steps
score, scores = evaluate_model(train, test, n_steps, n_length, n_input)
# summarize scores
summarize_scores('lstm', score, scores)
# plot scores
days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat']
pyplot.plot(days, scores, marker='o', label='lstm')
pyplot.show()Выполнение кода осуществляет обучение модели и её оценку в виде отображения строки с общим значением RMSE за всю неделю и значением RMSE по каждому дню прогноза на валидационной части набора данных.
Небольшой эксперимент показал, что использование двух свёрточных слоёв делает модель более стабильной, чем при использовании только одного слоя.
Видно, что и в этом случае модель справилась с прогнозом лучше: общее значение RMSE около 367 киловатт.
lstm: [367.929] 416.3, 379.7, 334.7, 362.3, 374.7, 284.8, 406.7Ниже представлен график RMSE на каждый день прогнозируемой недели.
Дополнительные задания
В этом разделе перечислено несколько проектов, выходящих за рамки данного руководства, которые наверняка вас заинтересуют.
- Величина входа. Экспериментируйте с большим или меньшим количество дней в качестве входных данных для модели – например: 3 дня, 21 день, 30 дней и более.
- Отладка модели. Настройте структуру и гиперпараметры модели, чтобы повысить качество прогнозов модели в среднем.
- Масштабирование данных. Посмотрите как масштабирование данных, например, стандартизация или нормализация, коррелирует с улучшением качества прогнозов любой из представленных моделей ДКП.
- Мониторинг в процессе обучения и проверки. Контролируйте качество работы модели с помощью кривых обучения на этапах обучения и проверки, а также среднеквадратичной ошибки, чтобы настроить оптимальную структуру и гиперпараметры модели ДКП.
Если вы всё-таки дойдёте до этих заданий, дайте мне знать (видимо, автор в курсе, что редкая птица долетит до середины Днепра :). – Прим. пер.).
Рекомендуемая литература
Для тех, кто хочет узнать больше по этой теме. Здесь указаны важные источники.
Публикации
- 4 стратегии выполнения интервального прогнозирования временных рядов
- Глубокое обучение с рекуррентными нейронными сетями: ускоренный курс
- Введение в рекуррентные нейронные сети с долгой кратковременной памятью: круглый стол с экспертами
- О пригодности ДКП для прогнозирования временных рядов
- Свёрточные нейронные сети с долгой краткосрочной памятью
- Как с помощью Keras подготовить модель типа «кодировщик-декодировщик» для выполнения прогнозирования «последовательность в последовательность»
API
- pandas.read_csv API
- pandas.DataFrame.resample API
- Resample Offset Aliases
- sklearn.metrics.mean_squared_error API
- numpy.split API
Статьи
- Набор данных «Домовое потребление электроэнергии», архив UCI Machine Learning
- Питание переменного тока, Wikipedia
- Свёрточная сеть ДКП: новый подход на основе машинного обучения для прогнозирования текущей погоды, 2015
Заключение
Итак, теперь вы знаете как подготовить рекуррентные нейронные сети с долгой кратковременной памятью, чтобы выполнить интервальное прогнозирование временных рядов домового потребления электроэнергии.
В частности:
- Как подготовить и оценить ДКП типа «кодировщик-декодировщик» для интервального прогнозирования временных рядов на основе как одномерных, так и многомерных входных данных.
- Как подготовить и оценить ДКП типа «кодировщик-декодировщик» с добавлением свёрточного слоя в качестве кодировщика для интервального прогнозирования временных рядов.
- Как подготовить и оценить свёрточную ДКП типа «кодировщик-декодировщик» для интервального прогнозирования временных рядов.
Есть вопросы?
Задавайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить (это не примечание. – Прим. пер.).
Заметьте, что это была часть главы из моей книги «Глубокое обучение: прогнозирование временных рядов», в которой вы найдёте ещё больше пошаговых руководств для изучения методов глубокого обучения применительно к прогнозированию временных рядов.