У компаний, которым необходимо управлять данными и приложениями на более чем одном сервере, во главу угла поставлена инфраструктура.
Для каждой компании значимой частью рабочего процесса является мониторинг инфраструктурных узлов, особенно при отсутствии прямого доступа для решения возникающих проблем. Более того, интенсивное использование некоторых ресурсов может быть индикатором неисправностей и перегрузок инфраструктуры. Однако мониторинг может использоваться не только для профилактики, но и для оценки возможных последствий использования нового ПО в продакшне. Сейчас для отслеживания потребляемых ресурсов на рынке существует несколько готовых к использованию решений, но с ними, тем не менее, возникают две ключевые проблемы: дороговизна установки и настройки и связанные со сторонним ПО вопросы безопасности.
Первая проблема это вопрос цены: стоимость может варьироваться от десяти евро (потребительские расценки) до нескольких тысяч (корпоративные расценки) в месяц, в зависимости от числа подлежащих мониторингу хостов. Для примера, предположим что мне нужен мониторинг трех узлов в течение одного года. При цене в 10 евро в месяц я потрачу 120 евро, тогда как небольшая компания будет вынуждена раскошелиться на десять-двадцать тысяч, что окажется финансово несостоятельным решением и попросту подорвет весь бюджет.
Вторая проблема это стороннее ПО. Учитывая, что для анализа данные пользователя — будь то частное лицо или компания — должны обрабатываться третьей стороной, возникает вопрос: каким образом третья сторона собирает данные и представляет их пользователю? Обычно для этого на узел устанавливают специальное приложение, через которое и ведется мониторинг, но зачастую такие приложения успевают устареть или оказываются несовместимы с операционной системой клиента. Опыт исследователей в области информационной безопасности проливает свет на проблемы в работе с «проприетарным ПО». Стали бы вы доверять такому ПО? Я — нет.
У меня есть свои узлы как для Tor, так и для некоторых криптовалют, поэтому для мониторинга я предпочитаю бесплатные, легко настраиваемые альтернативы с открытыми исходниками. В этом посте мы рассмотрим три таких инструмента: Grafana, InfluxBD и CollectD.

Мониторинг
Для эффективного анализа каждой метрики нашей инфраструктуры нужно приложение, способное подхватывать статистику с интересующих нас устройств. В этом отношении нам на помощь приходит CollectD: этот демон группирует и собирает («collects», потому и такое имя) все параметры, которые можно хранить на диске или передать по сети.
Данные затем будут переданы инстансу InfluxDB: это база данных временных рядов (time series database, TSBD), которая связывает данные со временем (закодированным в UNIX временную метку) в которое их получил сервер. Таким образом, отправленные CollectD данные поступят уже как последовательность событий.
Наконец, мы воспользуемся Grafana: эта программа свяжется с InfluxDB и отобразит данные на удобных для пользователя цветастых приборных панелях. Благодаря всевозможным графикам и гистограммам мы сможем в реальном времени отслеживать данные CPU, оперативной памяти и так далее.

InfluxDB

Давайте начнем с InfluxDB, свободно распространяемой TSBD для хранения данных в виде последовательности событий. Эта разработанная на Go база данных станет сердцем нашей мониторинговой «системы».
Всякий раз при поступлении данных к ним по умолчанию привязывается UNIX метка. Гибкость такого подхода освобождает пользователя от необходимости хранить переменную «time», что в противном случае оказывается довольно сложным. Давайте представим, что у нас есть несколько расположенных на разных материках устройств. Каким образом мы будем обрабатывать переменную «time»? Станем ли мы привязывать все данные ко времени по Гринвичу, или мы зададим каждому узлу свой часовой пояс? Если данные сохраняются в разных часовых поясах, каким образом нам корректно отобразить их на графиках? Как можно видеть, проблемы возникают одна за другой.
Так как InfluxDB отслеживает время и автоматически проставляет метки на каждое поступление данных, она может синхронно записывать данные в конкретную базу данных. Именно поэтому InfluxDB часто представляют в виде таймлайна: запись данных не влияет на производительность базы данных (что порой случается у MySQL), поскольку запись это всего лишь добавление конкретного события в таймлайн. Поэтому название программы происходит от восприятия времени как бесконечного и неограниченного «потока».
Установка и настройка
Еще одно преимущество InfluxDB заключается в простоте установки и предоставляемой сообществом проекта, которое его широко поддерживает, объемной документации. У InfluxDB есть два типа интерфейса: командная строка (удобный инструмент для разработчиков, но плохо подготовлена к работе с большими объемами данных) и HTTP API для прямого взаимодействия с базой данных.
Скачать InfluxDB можно не только с официального сайта, но и через систему управления пакетами (мы продемонстрируем это через Debian). Кроме того, перед установкой рекомендуется проверить пакеты через GPG, поэтому ниже мы импортируем ключи пакета InfluxDB:
root@node#~: curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
root@node#~: source /etc/os-release
root@node#~: echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.listНаконец, мы обновим и установим InfluxDB:
root@node#~: apt-get update
root@node#~: apt-get install influxdbДля запуска мы воспользуемся
systemctl:root@node#~: service start influxdb Чтобы к нам не залогинился кто-нибудь с гнусными намерениями, мы создадим пользователя «administrator». Взаимодействовать с базой данных можно через имеющийся в InfluxDB и похожий на SQL язык запросов «InfluxQL». Для создания нового пользователя мы выполним запрос
create user.root@node#~: influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGESВ том же CLI интерфейсе мы создадим базу данных «metrics», в которой и будем хранить наши метрики.
> CREATE DATABASE metricsЗатем мы настроим конфигурацию InfluxBD (
/etc/influxdb/influxdb.conf) таким образом, чтобы интерфейс открывался через порт 24589 (UDP) с прямым соединением к базе данных «metrics» для поддержки CollectD. Также нам надо будет скачать файл types.db и поместить его по адресу /usr/share/collectd/ (или в любую другую папку) для корректного определения данных, которые CollectD передает в родном формате.root@node#~: nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"Больше про CollectD в конфигурации можно прочесть в документации.
CollectD

CollectD в нашей мониторинговой инфраструктуре будет исполнять роль агрегатора данных, который упрощает передау данных до InfluxDB. По определению CollectD собирает метрики с CPU, оперативной памяти, жестких дисков, сетевых интерфейсов, процессов… Потенциал этой программы безграничен, особенно если учесть широкий выбор как уже доступных плагинов, так и набор запланированных.
Как можно видеть, установка CollectD проста:
root@node#~: apt-get install collectd collectd-utilsДавайте проиллюстрируем работу CollectD упрощенным примером. Допустим, я хочу знать число процессов на моем узле. Для проверки этого CollectD совершит вызов API чтобы узнать число процессов за единицу времени (по определению это 5000 миллисекунд) и ничего более. Как только агрегатор получит данные, он передаст их для настройки в InfluxDB через модуль (под названием «Network»), который нам надо будет настроить.
Откройте нашим редактором файл
/etc/collectd.conf, пролистайте до секции Network и отредактируйте его как указано ниже. Обязательно укажите IP по которому находится интерфейс InfluxDB (INFLUXDB_IP).root@node#~: nano /etc/collectd.conf
...
<Plugin network>
<Server "INFLUXDB_IP" "24589">
</Server>
ReportStats true
</Plugin>
...
Я предлагаю изменить в файле конфигурации имя хоста, который пересылается InfluxDB (в нашей инфраструктуре это «централизованная» база данных, поскольку она расположена на одном узле). Таким образом, к нам не будут поступать лишние данные и исчезнет риск перезаписи данных другими узлами.

Grafana

Один график стоит тысячи изображений
Беря во внимание перефразированную цитату, наблюдение за метриками инфраструктуры в режиме реального времени через графики и таблицы дает нам действовать эффективно и своевременно. Для создания и настройки приборной панели наших графиков и таблиц мы воспользуемся Grafana.
Grafana это совместимый с широким набором баз данных (включая InfluxDB) свободно распространяемый инструмент по графическому отображению метрик, в котором пользователь может создавать оповещения об удовлетворении частью данных конкретного условия. Например, если ваш процессор достигает пиковых значений, оповещение может прийти вам в Slack, Mattermost, на почту и так далее. Более того, свои оповещения я настроил так, чтобы активно отслеживать каждый случай, когда кто-то «заходит» в мою инфраструктуру.
Grafana не требует каких-то особых настроек: как мы уже отметили ранее, InfluxDB «сканирует» переменную «time». Сама же интеграция очень проста: мы начнем с импорта публичного ключа чтобы добавить пакет с официального сайта Grafana (он зависит от вашей операционной системы):
root@node#~: wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
root@node#~: echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
root@node#~: apt-get update && apt-get install grafanaЗатем запустим его через systemctl:
root@node#~: systemctl start grafana-webТеперь, когда мы перейдем в браузере на страницу localhost:3000, мы должны будем увидеть интерфейс входа в Grafana. По определению, зайти можно через логин admin и пароль admin (после первого входа учетные данные рекомендуется сменить).

Давайте перейдем в раздел Sources (Источники) и добавим туда нашу базу данных Influx:


Теперь под надписью New Dashboard виднеется небольшой зеленый прямоугольник. Наведите на него свой курсор и выберите Add Panel (Добавить Панель), а затем Graph (График):

Теперь можно увидеть график с тестовыми данными. Нажмите на заголовок этой диаграммы и нажмите Edit(Изменить). С Grafana можно создавать умные запросы: вам не нужно знать каждое поле в базе, Grafana предложит их вам из списка подходящих для анализа параметров.
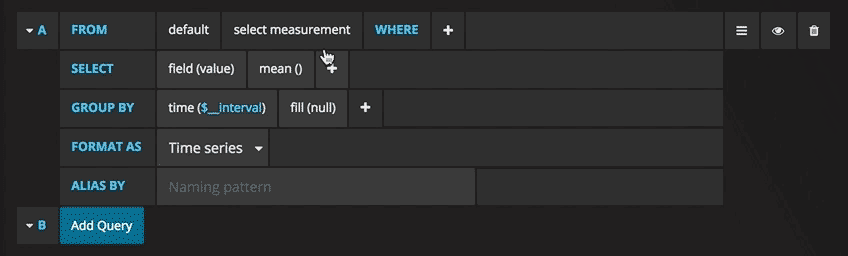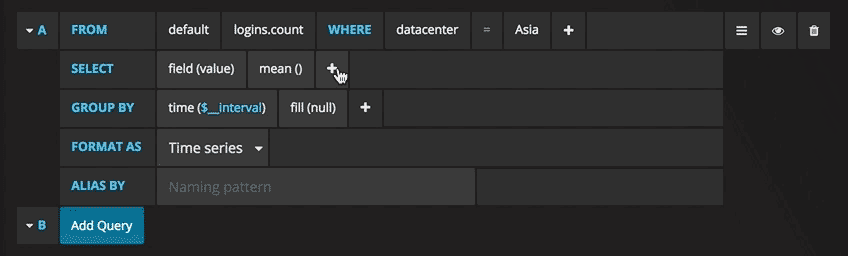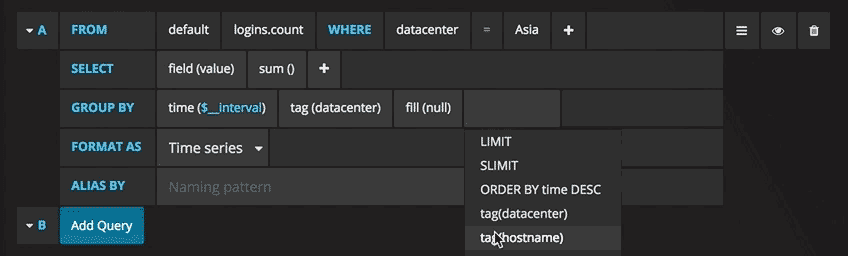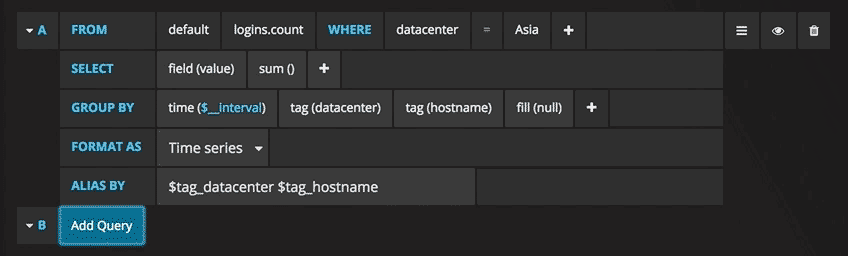
Писать запросы еще никогда не было так легко: просто выберите интересующую вас метрику и нажмите Refresh (Обновить). Еще я рекомендую разделить метрики по хостам, чтобы было проще изолировать проблемы. Если вам интересны другие идеи по созданию контрольных панелей, для вдохновения можно посетить сайт Grafana со всевозможными примерами.
Мы заметили, что Grafana это очень легко расширяемый инструмент, и он позволяет нам сравнивать очень разные по сравнению друг с другом данные. Нет ни одной метрики, которую нельзя было бы заполучить, так что вас ограничивает только ваша же изобретательность. Отслеживайте ваши устройства и получайте самый полный обзор вашей инфраструктуры в реальном времени!




IvanVakhrushev
В продакшене вы тоже используете OSS версию InfluxDB?