
Сфера Data Science настолько обширна и настолько быстро развивается, что изучить «вообще всё» в ней попросту невозможно. Но вас не должно это демотивировать, ведь выход один — развиваться и не дать себя захватить страху «как же мало я знаю».
Под катом проект, задействующий мощь современных облачных платформ машинного обучения в классической задаче распознания кошек и собак. Проект написан так, чтобы вы могли адаптировать его под свои задачи.
Я просто пришел сказать это. Я ошеломлен и несколько напуган растущим размахом и глубиной машинного обучения сегодня.
- Вам нужно создать высокопроизводительный дата-пайплайн? Изучите Apache Beam или Spark и буферы протоколов.
- Нужно масштабировать обучение модели? Изучите AllReduce и многоузловые распределенные архитектуры.
- Нужно развернуть свои модели? Изучите Kubernetes, TFServing, квантование и управление API.
- Вам нужно отслеживать пайплайны? Настройте базу данных для метаданных, изучите Docker и станьте инженером DevOps.
И здесь даже нет алгоритма моделирования и пространства моделирования, что заставляет меня чувствовать себя самозванцем без исследовательской подготовки. Должен быть способ проще!
Я провел последние несколько недель, размышляя об этой дилемме и о том, что я порекомендовал бы дата-сайентисту с таким же мышлением, как у меня. Многие упомянутые выше темы важно изучить, особенно если вы хотите сосредоточиться на новой области MLOps, но есть ли инструменты и технологии, позволяющие «встать на плечи гигантов»? Ниже я перечислил 4 инструмента, которые абстрагируют большую часть сложности и позволяют эффективнее разрабатывать, отслеживать и масштабировать процессы машинного обучения.
- TFRecorder (через Dataflow) : с легкостью превращайте данные внутри TFRecords в файл CSV. Для изображений предоставьте JPEG URI и метки в CSV. Масштабирование до распределенных серверов с помощью Dataflow без кода Apache Beam.
- TensorFlow Cloud(через AI Platform Training): масштабируйте обучение модели TensorFlow для одно- и многоузловых кластеров графических процессоров на AI Platform Training с помощью простого вызова API.
- AI Platform Predictions. Разверните свою модель в качестве конечной точки API для сервиса автомасштабирования (финансово поддерживаемого Kubernetes) с графическими процессорами, той самой, что используется Waze! О том, что это за компания можно почитать тут.
- Weights & Biases. Логируйте наборы данных и модели, чтобы отслеживать версии и происхождение в пайплайне разработки. Дерево взаимосвязей между вашими экспериментами и артефактами создается автоматически.

Обзор рабочего процесса
Я использую типичную задачу компьютерного зрения «кошки против собак», чтобы пройтись по каждому из этих инструментов. Рабочий процесс состоит из этих этапов:
- Сохраните необработанные изображения JPEG в хранилище объектов, при этом каждое изображение находится в подпапке с указанием его метки.
- Создайте файл CSV с URI изображений и метками в необходимом формате.
- Преобразуйте изображения и метки в TFRecords
- Создайте набор данных из TFRecords и обучите модель CNN с помощью Keras.
- Сохраните модель как SavedModel и разверните как конечную точку API.
- Изображения JPEG, TFRecords и SavedModels будут храниться в хранилище объектов.
- Эксперименты и происхождение артефактов будут отслеживаться с помощью Weights & Biases.
Блокноты Jupyter Notebook и применяемые скрипты находятся в этом репозитории GitHub. Теперь давайте углубимся в каждый инструмент.
TFRecorder
TFRecords до сих пор запутывает меня. Я понимаю преимущество и обеспечиваемую производительность, но мне всегда было трудно с ними работать, когда я начинал работу с новым набором данных. Видимо, я не единственный, и, к счастью, проект TFRecorder недавно был выпущен. Работать c TFRecords еще никогда не было так просто, для этого требуется только (1) организация ваших изображений в виде логического каталога и (2) работа с фреймами Pandas и CSV. Вот предпринятые мной шаги:
- Создание файла CSV с тремя столбцами, включая URI изображения, указывающий на расположение каталога каждого изображения.

- Чтение CSV во фрейм данных pandas с вызовом функции TFRecorder для преобразования файлов в Dataflow с указанием выходного каталога.
dfgcs = pd.read_csv(FILENAME)dfgcs.tensorflow.to_tfr(
output_dir=TFRECORD_OUTPUT,
runner='DataFlowRunner',
project=PROJECT,
region=REGION,
tfrecorder_wheel=TFRECORDER_WHEEL)Вот оно! Менее 10 строк кода, которые масштабируются для преобразования миллионов изображений в формат TFRecord. Как Data Scientist, вы только что заложили основу для высокопроизводительного обучения. Взгляните на график и показатели задачи Dataflow в консоли Dataflow, если интересно узнать о волшебстве, происходящем в фоновом режиме.
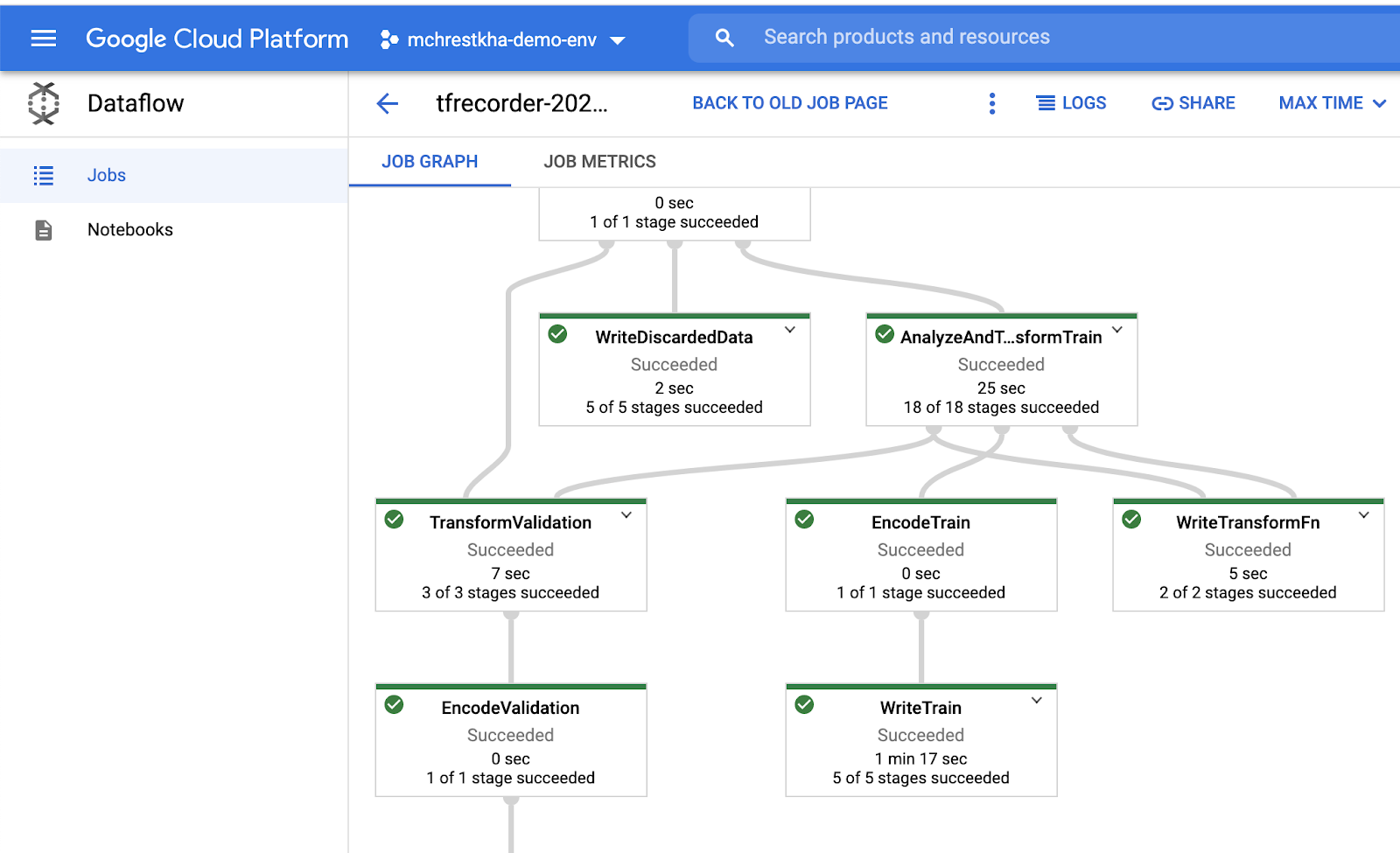
Немного посмотрев код на GitHub, я выяснил схему tfrecorder:
tfr_format = {
"image": tf.io.FixedLenFeature([], tf.string),
"image_channels": tf.io.FixedLenFeature([], tf.int64),
"image_height": tf.io.FixedLenFeature([], tf.int64),
"image_name": tf.io.FixedLenFeature([], tf.string),
"image_width": tf.io.FixedLenFeature([], tf.int64),
"label": tf.io.FixedLenFeature([], tf.int64),
"split": tf.io.FixedLenFeature([], tf.string),
}Затем вы можете прочитать TFRecords в TFRecordDataset для пайплайна обучения модели Keras с помощью такого кода:
IMAGE_SIZE=[150,150]
BATCH_SIZE = 5
def read_tfrecord(example):
image_features= tf.io.parse_single_example(example, tfr_format)
image_channels=image_features['image_channels']
image_width=image_features['image_width']
image_height=image_features['image_height']
label=image_features['label']
image_b64_bytes=image_features['image']
image_decoded=tf.io.decode_base64(image_b64_bytes)
image_raw = tf.io.decode_raw(image_decoded, out_type=tf.uint8)
image = tf.reshape(image_raw, tf.stack([image_height, image_width, image_channels]))
image_resized = tf.cast(tf.image.resize(image, size=[*IMAGE_SIZE]),tf.uint8)
return image_resized, label
def get_dataset(filenames):
dataset = tf.data.TFRecordDataset(filenames=filenames, compression_type='GZIP')
dataset = dataset.map(read_tfrecord)
dataset = dataset.shuffle(2048)
dataset = dataset.batch(BATCH_SIZE)
return dataset
train_dataset = get_dataset(TRAINING_FILENAMES)
valid_dataset = get_dataset(VALID_FILENAMES)TensorFlow Cloud (AI Platform Training)
Теперь, когда у нас есть tf.data.Dataset, передаем его в вызов обучения модели. Ниже приведен простой пример модели CNN, использующей Keras Sequential API.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])model.summary()
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=1e-4),
metrics=['accuracy'])
model.fit(
train_dataset,
epochs=10,
validation_data=valid_dataset,
verbose=2
)Сначала я запустил этот код в своей среде разработки на подмножестве изображений (в моем случае — в блокноте Jupyter Notebook), но хотел масштабировать его для всех изображений и сделать это быстрее. TensorFlow Cloud позволяет мне использовать одну команду API, которая отправляет код в контейнер и на запуск в качестве распределенного задания GPU.
import tensorflow_cloud as tfctfc.run(entry_point='model_training.ipynb',
chief_config=tfc.COMMON_MACHINE_CONFIGS['T4_4X'],
requirements_txt='requirements.txt')Это не первоапрельская шутка. Три строки кода — это полноценный скрипт на Python, который нужно поместить в тот же каталог, что и ваш блокнот Jupyter. Самая сложная часть — инструкция настройки, проверка того, что вы правильно аутентифицированы в своем проекте Google Cloud Platform. Углубимся в происходящее. Сначала создается контейнер Docker со всеми необходимыми библиотеками и блокнотом, который сохраняется в сервисе реестра контейнеров Google Cloud.

Затем этот контейнер передается в полностью управляемую бессерверную службу обучения AI Platform Training. Без необходимости настраивать инфраструктуру и устанавливать какие-либо библиотеки графических процессоров, я смог обучить эту модель на машине с 16 виртуальными ЦП и 60 ГБ оперативной памяти и 4 графическими процессорами Nvidia T4. Я использовал эти ресурсы только тогда, когда они мне были нужны (~15 минут), и могу вернуться к разработке в своей локальной среде с помощью IDE или Jupyter Notebook.
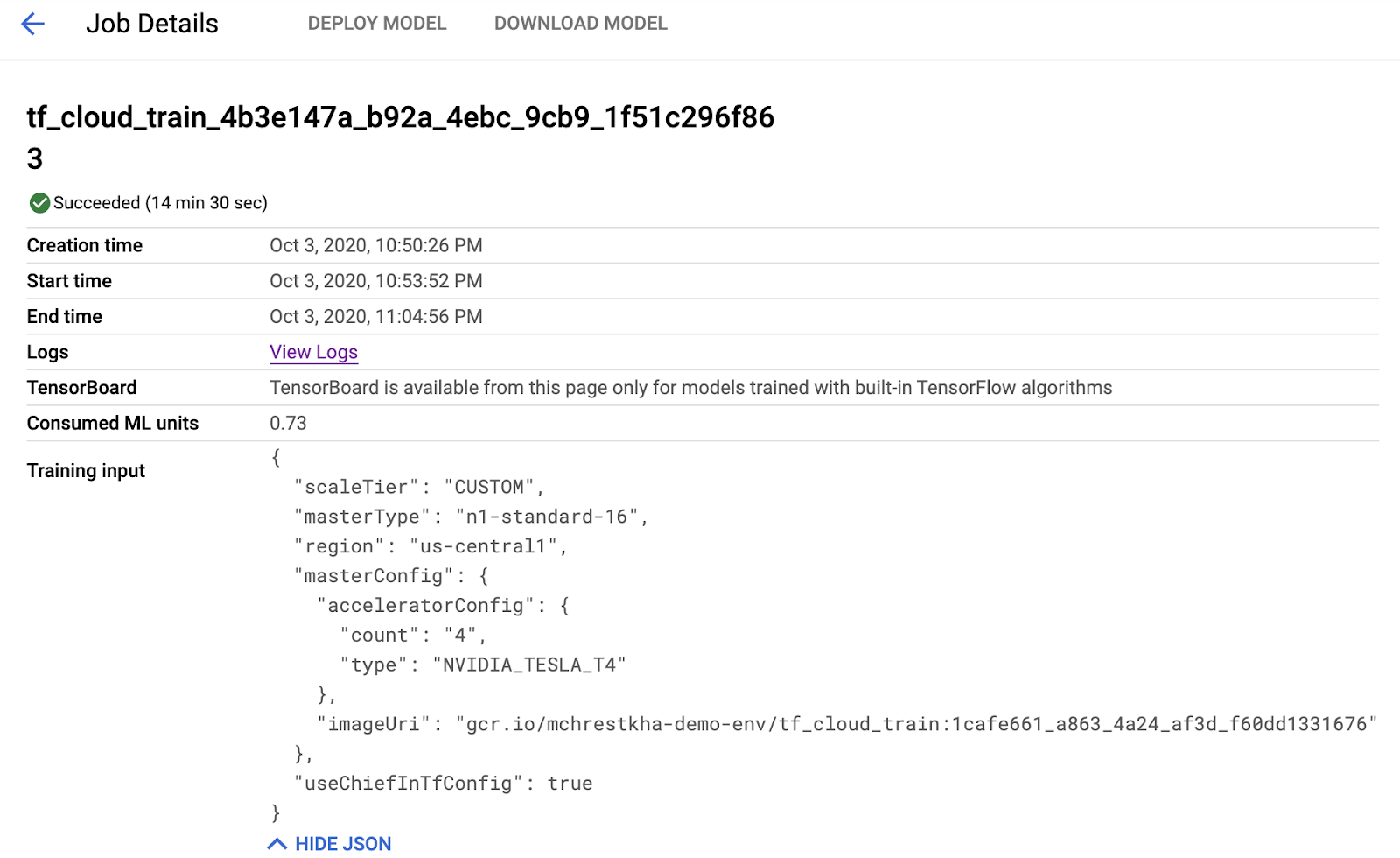
SavedModel, наконец, сохраняется в хранилище объектов, как указано в самом конце скрипта обучения.
MODEL_PATH=time.strftime(«gs://mchrestkha-demo-env-ml-examples/catsdogs/models/model_%Y%m%d_%H%M%S»)
model.save(MODEL_PATH)AI Platform Predictions
Имея свою модель SavedModel в хранилище объектов, я могу загрузить ее в свою среду разработки и выполнить несколько примерных прогнозов. Но что, если я хочу позволить другим работать с моделью без необходимости настраивать среду Python и изучать TensorFlow. Здесь на сцену выходит AI Platform Predictions. Он позволяет развертывать двоичные файлы модели в качестве конечных точек API, которые вызываются с помощью REST, простого Google Cloud SDK (gcloud) или других клиентских библиотек. Пользователи должны знать, что это требуемые входные данные (в нашем случае файл изображения JPEG, преобразованный в массив JSON [150,150,3]), а также знать, могут ли они встроить модель в свой рабочий процесс. Когда вы вносите изменения (заново обучите модель на новом наборе данных, новой архитектуре модели, возможно, даже используете новый фреймворк), то можете опубликовать новую версию. Приведенный ниже простой пример скрипта с SDK gcloud крайне полезен для развертывания моделей в этом сервисе автоматического масштабирования, поддерживаемом Kubernetes.
MODEL_VERSION="v1"
MODEL_NAME="cats_dogs_classifier"
REGION="us-central1"
gcloud ai-platform models create $MODEL_NAME --regions $REGION
gcloud ai-platform versions create $MODEL_VERSION --model $MODEL_NAME --runtime-version 2.2 --python-version 3.7 --framework tensorflow --origin $MODEL_PATHAI Platform Predictions — это сервис, который меня волнует особенно, поскольку он устраняет многие сложности, связанные с распространением вашей модели (внутри организации и вовне) таким образом, чтобы начать извлекать из модели пользу. Хотя цель поста — показать экспериментальный рабочий процесс такие компании, как Waze, используют AI Platform Predictions для развертывания и обслуживания своих моделей в промышленных масштабах.
Weights & Biases
Я завершил эксперимент. Но как насчет будущих экспериментов? Мне может понадобиться:
- Провести много экспериментов на этой неделе и отслеживать работу.
- Вернуться через месяц и попытаться вспомнить все входные и выходные данные каждого эксперимента.
- Поделиться работой с коллегами, которые, надеюсь, смогут собрать детали рабочего процесса воедино.
Много работы делается на просторе ML пайплайнов. Это захватывающая, но только зарождающаяся область с лучшими практиками и отраслевыми стандартами, которые еще предстоит разработать. Некоторые замечательные проекты включают MLFlow, пайплайны Kubeflow, TFX и другие. Comet.ML для нужд моего рабочего процесса MLOps и непрерывная доставка находились вне поля зрения, и я хотел что-то простое. Я выбрал Weights & Biases (WandB) из-за простоты применения и легкой интеграции для отслеживания экспериментов и артефактов.
Начнем с экспериментов. WandB предлагает множество вариантов настройки, но если вы работаете с любым из популярных фреймворков, нужно сделать не много. В случае TensorFlow Keras API я просто (1) импортировал библиотеку python wandb (2) инициализировал запуск эксперимента и (3) добавил функцию обратного вызова в рамках шага обучения модели.
model.fit(
train_dataset,
epochs=10,
validation_data=valid_dataset,
verbose=2,
callbacks=[WandbCallback()]
)Код передает нестандартные метрики в централизованный сервис отслеживания экспериментов. Взгляните на то, как вообще люди работают с WandB здесь.
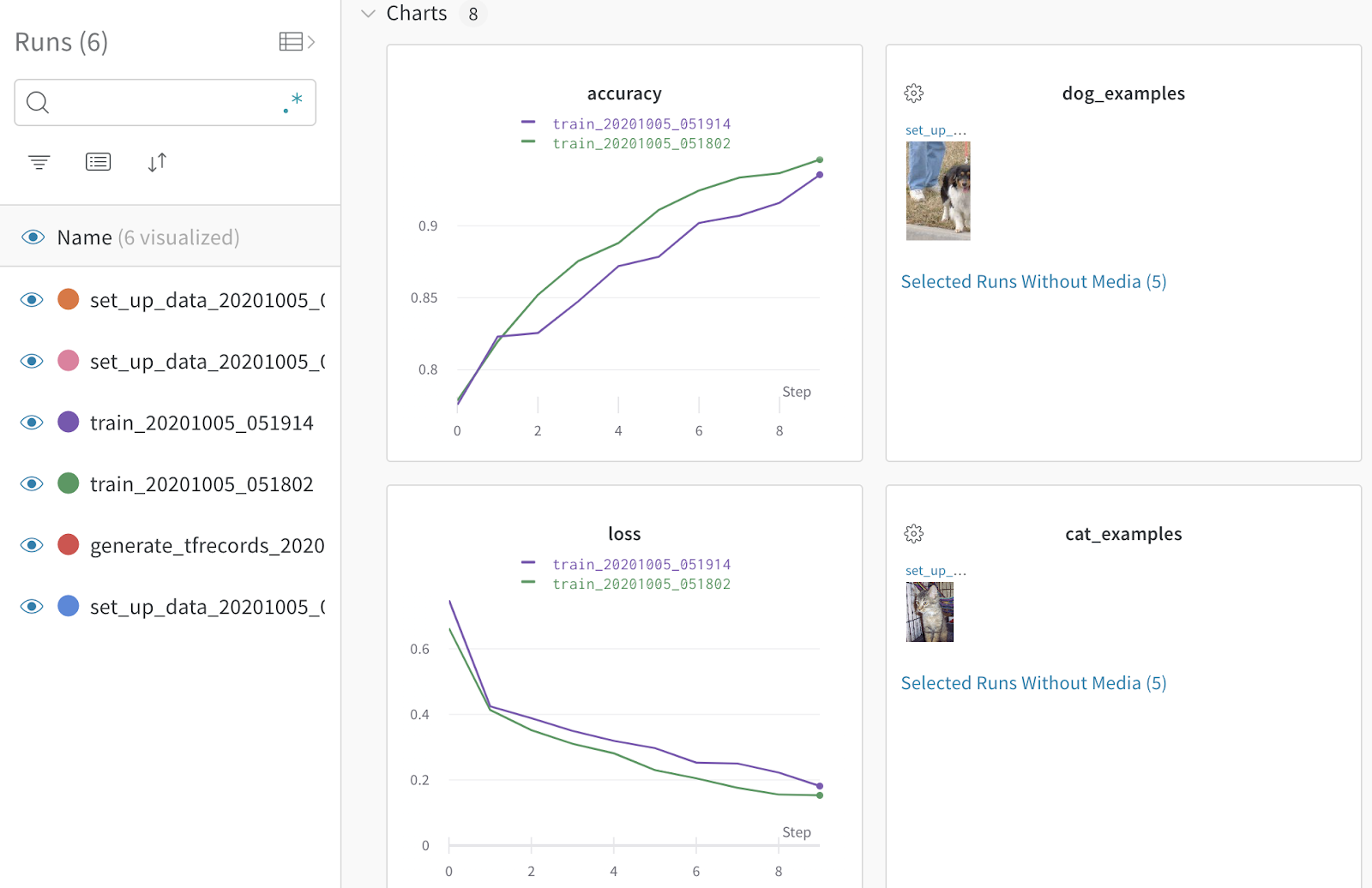
WandB также предоставляет API артефактов, который соответствует моим потребностям намного больше, чем некоторые из тяжелых инструментов, существующих сегодня. Я добавил короткие фрагменты кода по всему конвейеру, чтобы определить 4 ключевых элемента:
- Инициализация шага в моем пайплайне
- Использование существующего артефакта (когда он есть) в рамках этого шага
- Логирование артефакта, созданного на этом шаге
- Указание на завершение шага
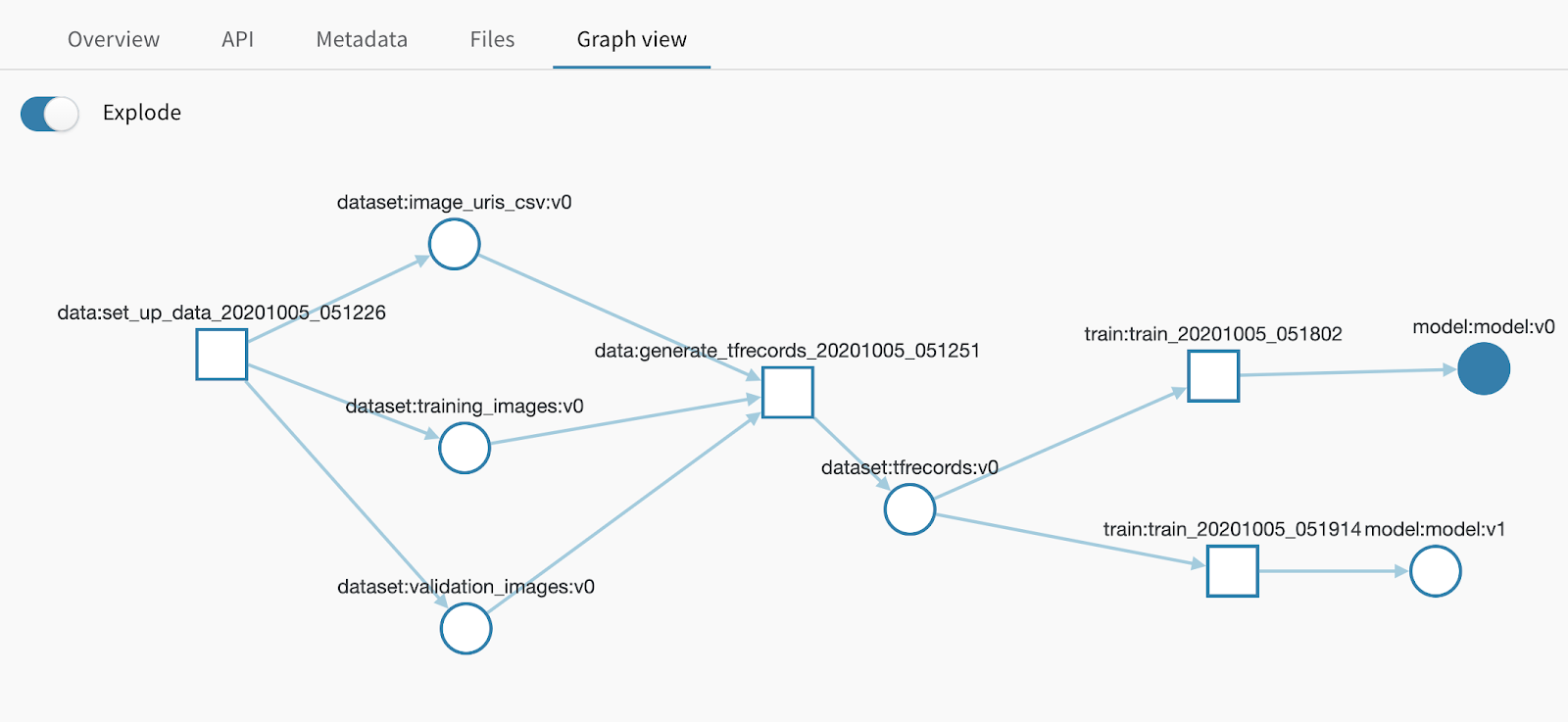
run = wandb.init(project='cats-dogs-keras', job_type='data', name='01_set_up_data')
<Code to set up initial JPEGs in the appropriate directory structure>
artifact = wandb.Artifact(name='training_images',job_type='data', type='dataset')
artifact.add_reference('gs://mchrestkha-demo-env-ml-examples/catsdogs/train/')
run.log_artifact(artifact)
run.finish()
run = wandb.init(project='cats-dogs-keras',job_type='data', name='02_generate_tfrecords')
artifact = run.use_artifact('training_images:latest')
<TFRecorder Code>
artifact = wandb.Artifact(name='tfrecords', type='dataset')
artifact.add_reference('gs://mchrestkha-demo-env-ml-examples/catsdogs/tfrecords/')
run.log_artifact(artifact)
run.finish()
run = wandb.init(project='cats-dogs-keras',job_type='train', name='03_train')
artifact = run.use_artifact('tfrecords:latest')
<TensorFlow Cloud Code>
artifact = wandb.Artifact(name='model', type='model')
artifact.add_reference(MODEL_PATH)
run.log_artifact(artifact)Этот простой API артефактов хранит метаданные и данные о происхождении каждого запуска и артефакта, так что в рабочем процессе у вас есть полная ясность. Пользовательский интерфейс также имеет приятную древовидную диаграмму для просмотра истории запусков и артефактов.
Заключение
Если вас пугают бесконечные темы машинного обучения, инструменты и технологии, вы не одиноки. Я чувствую синдром самозванца каждый день, разговаривая с коллегами, партнерами и клиентами о различных аспектах науки о данных, MLOps, аппаратных ускорителях, конвейерах данных, AutoML и т.д. Просто помните, что это очень важно.
- Будьте практичны: нереально всем нам быть фулстек-инженерами в DevOps, Data и Machine Learning. Выберите одну или две области, которые вас интересуют, и работайте с другими для решения общесистемных проблем.
- Сосредоточьтесь на своей проблеме: все мы увлекаемся новым фреймворком, новой исследовательской работой, новым инструментом. Начните с вашей бизнес-задачи, вашего набора данных, ваших требований к конечному пользователю. Не всем нужны 100 моделей ML в производстве, которые ежедневно переобучаются и обслуживаются миллионами пользователей (по крайней мере, пока).
- Определитесь с инструментами найдите основной набор инструментов, действительно умножают эффективность, обеспечивают масштабируемость и устраняет сложность. Я прошелся по своему набору инструментов для Tensorflow (TFRecorder + TensorFlow Cloud + AI Platform Predictions + Weights & Biases), но нашел правильный инструментарий, который соответствует вашей проблеме и рабочему процессу.
Примеры Jupyter Notebook из этого поста можно найти на моем GitHub.
А прокачать себя по-максимуму в Data Science, аналитике или машинном обучении можно под чутким руководством наших менторов.

- Обучение профессии Data Science с нуля
- Онлайн-буткемп по Data Science
- Обучение профессии Data Analyst с нуля
- Онлайн-буткемп по Data Analytics
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
Eще курсы