fn main() {
println!("Hello, Rust!");
println!("... Goodbye!");
}Синтаксис — это первое, на что обращают внимание разработчики, впервые столкнувшись с кодом на Rust. И сложно найти что-то другое, что вызывало бы больше негодования у новичков, и при этом такое, к чему совершенно спокойно относятся уже "понюхавшие пороха" Rust-программисты. Посмотрите, например, сколько эмоций вызывает синтаксис Rust у комментаторов одной из типичных новостей про Rust на OpenNET:
Язык не для меня, нахожу его немного убогим в плане синтаксиса, но мне нравится много идей тем, взять хотя бы управление памятью.
Вообще никак не зашел. Зашел он хейтерам крестов, может их кресты както в детстве обидели, я не знаю. Но когда даже крестовики говорят, что синтаксис конченый — это очень серьезный повод задуматься, крестов видели конченый синтаксис.
Самое интересное в этой истории то, что примеры на сайте раста типа "привет мир", почему то намного более читабельные чем то, что реально используется и лежит на гитхабе, а там адовый синтаксис с кучей спец символов и какая то ещё жуткая муть.
Сначала хотел указать вам на ошибку, но потом понял, что "синтоксис" в данном контексте, нужно понимать как "токсичный синтаксис". Вот это именно то, чего мне не хватало что бы охарактеризовать раст.
Теперь я точно знаю: Раст — это ЯП с ТОКСИЧНЫМ СИНТАКСИСОМ!
Новый язык должен бить старые по всем параметрам уверенно и с превосходством. Rust это не новая технология, это всё что было раньше только с инфраструктурой и плохо читаемым синтаксисом.
Да вообще не понимаю, чего все ополчились на Rust. Нормальный язык с нормальным синтаксисом, надо просто мозгом думать.
Синтаксис языка, безусловно, имеет значение. Но сама величина его важности условна: для людей, только начинающих знакомство с языком, она больше. А вот для разработчиков, уже привыкших к языку, гораздо важнее выразительность: то есть не синтаксис сам по себе в абстрактном отношении с собой, а то, насколько язык хорошо справляется с выражением требуемых концепций и насколько они легко воспринимаются.
Как ни печально, но встречают язык по голому синтаксису. И синтаксис Rust тут не предлагает чего-то революционного. По сути это обычный C-подобный синтаксис, который имеют и многие другие языки, но с различными современными улучшениями. И они, как ни странно, делают его лучше других, в ряде случаев выразительнее.
Проблема в том, что сразу этого не видно. Чтобы оценить выразительность, нужно уже владеть теми концепциями, языковую запись которых требуется оценить. Более того, нужно также иметь представление о проблемах выражения подобных концепций в других языках и иметь в виду возможное наличие этих проблем при оценке. Поэтому концептуальная сложность самого языка может выглядеть на первый взгляд как переусложнение синтаксиса. На самом деле синтаксис Rust не так плох, как о нем говорят. Он имеет множество замечательных находок, которыми удобно пользоваться, и вопреки расхожему мнению, читаются программы на Rust достаточно хорошо.
Так давайте рассмотрим подробнее, чем именно синтаксис Rust не угодил своим критикам и почему никто из них не может предложить ничего лучше, когда их просят это сделать.
Фигурные скобки
Многие люди, которые критикуют языки программирования за использование фигурных скобок и других спецсимволов, часто хотят, чтобы программа выглядела подобно тексту на естественном языке. Но такой формат совершенно неудобен для записи программного кода, и вот почему: текст на естественном языке — это просто запись последовательного потока речи, тогда как текст программы — это чаще выражение структурных отношений между элементами кода. Очевидно, что графическими обозначениями зачастую можно добиться большей выразительности при записи структур, будь то спецсимволы или отступы.
Выделение блоков кода одними лишь отступами имеет свои преимущества, но чаще всего оно требует серьезной дисциплины от программиста. Особенно при перемещении фрагментов кода из одного места в другое, из одного уровня вложенности — в другой. Читаемость кода улучшается, но возрастает напряжение внимания при работе с кодом, возникает почва для появления досадных ошибок.
Интересно, что одна из главных проблем, которую должно было решить обозначение блоков отступами — это проблема несоответствия между отступами и реальной синтаксической группировкой инструкций. При этом человек прочитывает один порядок, ориентируясь на отступы, а парсер языка — другой порядок, ориентируясь на правило, по которому блок выделяется скобками:
if (test(x))
foo(x);
bar(x);Должен ли bar вызываться только тогда, когда test завершился успешно? По правилам языка — нет, так как отсутствуют фигурные скобки, обозначающие блок. Но такое форматирование кода затрудняет для человека понимание этого. Все потому, что имеется лишняя избыточность в обозначении блоков: скобками — для парсера, отступами — для человека, и они могут не совпадать. Поэтому в Python решили отказаться от этой избыточности:
if test(x):
foo(x)
bar(x)Но ирония в том, что такое единообразное представление, тем не менее, не устраняет возможную ошибку полностью. То есть, ошибкой в первом примере могло быть не отсутствие фигурных скобок, а наличие случайного отступа. Тогда программа в первом случае работает правильно, но выглядит некорректной, тогда как во втором случае она действительно некорректна.
Появление подобных ошибок наталкивает на мысль, что избыточность в обозначении блоков — не так уж и плоха, она позволяет ввести дополнительные способы контроля. Более того, наличие скобок делает возможным автоматическое расставление отступов: зная, что код был отформатирован автоматически (например, по сохранению изменений в файл), программист может визуально убедиться, что никакая инструкция не съехала, все расставлено на своих позициях как надо.
Даже без автоформатирования, Rust решает проблему случайных отступов радикальным образом:
if test(x) {
foo(x);
}
bar(x);В конструкциях if, else, for, while и так далее, блок требуется обязательно! Сокращенная, бесскобочная запись тела у данных операторов в языке просто отсутствует. С одной стороны, это "загрязняет" фигурными скобками простые условия, но отчасти это компенсируется тем, что теперь круглые скобки вокруг условного выражения становятся избыточными и их можно убрать.
Вообще, в Rust блоки очень важны, они являются самостоятельными программными объектами с особыми свойствами.
Во-первых, блоки обозначают область видимости переменных. По достижении конца блока все переменные, введенные внутри блока, уничтожаются и происходит освобождение занятых ими ресурсов:
...
{
let mut data = data.lock().expect("Mutex should be lockable");
data.read();
data.write();
}
...Здесь data вне блока — это мьютекс, содержащий некоторые данные. А data внутри блока — это специальная ссылка на защищенные мьютексом данные, которая формируется при блокировке мьютекса и после удаления которой исходный мьютекс будет разблокирован. То есть блок в данном случае ограничивает область блокировки мьютекса, и встречаться подобные блоки могут в любом месте, где допустимо размещение инструкций.
Во-вторых, блоки сами являются выражениями и они возвращают значения! Значением блока считается значение последнего вычисленного выражения в блоке, если оно не завершается точкой с запятой. Иначе блок будет возвращать пустое значение.
let value = {
let a = 1;
let b = 2;
a + b
};Очень удобно вводить локальные блоки и компоновать их с выражениями вовне. Каким бы ни было простым это свойство блоков, оно кардинально меняет способ работы с потоком выполнения: оно позволяет не только локализовать связанные инструкции, но и приносит в поток вложенную структурность. Благодаря этому, в частности, становится ненужен специальный тернарный условный оператор (что также избавляет от ряда проблем, с ним связанных):
let value = if x < 42 { -1 } else { 1 };А многие функции и замыкания избавляются от лишнего синтаксиса с оператором возврата:
fn add_two(a: isize) -> isize {
a + 2
}вместо
fn add_two(a: isize) -> isize {
return a + 2;
}Для специальных блоков, таких как unsafe и async, появляется возможно оборачивать ими только часть выражения, что в ряде случаев удобно и делает код нагляднее:
let a = 5 + unsafe { an_unsafe_fn() };Сложно представить, как можно обеспечить удобную (и свободную от известных ошибок) поддержку блоков такой же функциональности, не используя скобок для их обозначения.
Точка с запятой
Отдельного рассмотрения заслуживает то, как работает точка с запятой в Rust. Многим не нравятся языки, которые требуют окончания инструкций точкой с запятой: зачем, если и так перевод строки может означать завершение инструкции? Отказ от точки с запятой оправдан, если в языке любая строка по умолчанию является инструкцией, как в Python. Если же язык использует концепцию "все есть выражение", которая расширяет его выразительные возможности, то без специального терминатора, по которому можно отличить строку-инструкцию от строки-выражения, удобным в использовании может быть только язык с динамической типизацией, такой как Ruby. Да и в таком языке в ряде случаев подход "все есть выражение" приводит к неудобствам:
class Foo
def set_x val
@val = val
nil
end
endЗдесь возникает необходимость вставлять nil в конце блока, чтобы set_x возвращал пустое значение, а не результат выражения @val = val, то есть не значение val. Если это еще терпимо, то ситуация становится совершенно неприемлемой в случае статических языков и использования ветвлений:
if x < 42 {
foo(x)
} else {
bar(x)
}Здесь foo возвращает число, но мы его не используем, а bar возвращает "пусто". Какого типа должно быть значение всего условного выражения?
Для динамически типизированных языков подобный код приемлем, потому что они допускают возврат значений разных типов в зависимости от условия, которое проверяется во время выполнения программы. Для статически типизированного языка — все плохо, придется ставить выражения-заглушки в каждой подобной ситуации, даже если результат никто не присваивает.
Rust решает эту проблему элегантным способом, который позволяет оставаться ему статически типизированным языком и при этом использовать преимущества подхода "все есть выражение" без особых хлопот. Способ заключается в том, что точка с запятой используется не как простой разделитель инструкций, а как оператор, превращающий выражение в инструкцию. При этом инструкция тоже интерпретируется как выражение, которое всегда возвращает пустое значение:
if x < 42 {
foo(x);
} else {
bar(x)
}Здесь foo возвращает число, но мы его не используем, и нам не нужно, чтобы оно возвращалось из данной ветки условия, поэтому мы завершаем выражение точкой с запятой. При этом bar возвращает "пусто", а значит мы не обязаны ставить точку с запятой после его вызова (но можем и поставить, для симметрии), ибо типы возврата обеих веток уже совпали.
Интересно, что в совокупности с правилами владения и семантикой перемещения по умолчанию получается, что если объект был перемещен в выражение, которое закончилось точкой с запятой и объект никуда больше перемещен не был, то он удаляется:
let message = "Hello!".to_string();
message;
println!("{}", message); // error[E0382]: borrow of moved value: `message`Так что инструкция a; становится аналогом drop(a). Это нужно помнить, чтобы не удивляться, когда компилятор откажется компилировать инструкцию, в которой производится попытка сохранить ссылку на перемещенное внутрь нее значение.
В итоге подобное концептуальное расширение функций точки с запятой весьма удобно в использовании. В подавляющем большинстве случаев оно ни к каким проблемам не приводит, благодаря контролю соответствия типов и времен жизни со стороны компилятора. Что же касается "загрязнения" кода точками с запятой, то благодаря тому, что теперь она не ставится в ряде распространенных случаев, доля непустых строк в программах на Rust, содержащих точку с запятой, составляет около 20%. Не так уж и много.
Постфиксная запись типа
Иногда простота синтаксиса является кажущейся. Например, частенько задается вопрос: зачем в Rust используется постфиксная запись типа, ведь это усложняет запись, еще и приходится отделять имена от типа с помощью двоеточия, тогда как префиксная запись, принятая в C/C++, этого не требует и выглядит чище. На самом деле префиксная запись чище только в ряде простых случаев использования, но в более сложных случаях она изрядно запутывает и парсер, и человека.
Вообще, какой следует выбрать объективный критерий простоты синтаксиса? Мне видится, что немаловажно для оценки простоты синтаксиса является простота его парсера. Простой парсер может стать важным преимуществом языка программирования, так как он ускоряет время компиляции, разбор исходных файлов в IDE и утилитах анализа и автоматического преобразования кода (статические анализаторы, автоформатеры, авторефакторы и пр.). Кроме того, простота разбора синтаксиса также важна и для человека: во-первых, человеку тоже приходится "парсить" текст программы при ее чтении, а во-вторых, однозначность синтаксиса упрощает поиск нужных строк по кодовой базе, например, среди множества проектов на GitHub.
Рассмотрим пример объявления переменной определенного типа.
В Rust:
let i: u64;В C++:
uint64_t i;Первый вариант — это "паскалевский" способ декларации типа. Хотя он дополнительно "загрязнен" символом двоеточия, однако в общем случае он проще, как для разбора парсером, так и для восприятия человеком.
Прочитав i в i: u64, парсер уже знает, что i — это имя переменной, прочитав : он знает, что дальше идет имя типа, прочитав u64 он знает, что это имя типа, даже не сверяясь со списком имеющихся типов (то есть не заглядывая в семантику). Такой подход избавляет от необходимости декларировать тип до того, как будет объявлена переменная этого типа. В C/C++ из-за этого приходится отдельно делать объявления, отдельно определения, и иногда изменение порядка деклараций может изменить семантику.
Для человеческого восприятия преимущества "паскалевской" записи раскрываются в сложных случаях:
int (*fns[16])(int * const * p);Проблема данного кода в том, что в нем синтаксис типа перемешан с синтаксисом объявляемой переменной. Чтобы в этом разобраться, нужно применять особое правило чтения по спирали.
Синтаксис же, принятый в Rust, отделяет обозначение типа от имени переменной:
let fns: [fn(*const *mut isize) -> isize; 16];Обозначение типа при этом всегда одинаково, вне зависимости от того, указано ли оно в аннотации типа в инструкции let, в вызове size_of или в объявлении функции как тип возвращаемого значения.
Ну и стоит сказать, что "паскалевская" декларация упрощается в случае автовыведения типа:
let a = foo();Тип просто не указывается. Отсутствует также и двоеточие, что улучшает читаемость кода в большинстве случаев использования переменных.
Для человека, читающего код, имя переменной зачастую важнее ее типа, поэтому логично, что оно ставится на первое место. К тому же имена обычно более равномерны по длине, чем типы, и постфиксная запись улучшает выравнивание полей и переменных в группе.
Зачем вообще нужен let?
Иногда let ругают за его избыточность и ненужность. Но обычно это делают те, кто не идет дальше элементарных примеров объявления переменных в Rust. Дело в том, что инструкция let занимается не объявлением переменных, а сопоставлением выражения с образцом (паттерном):
let PATTERN: EXPR_TYPE = EXPR;
let PATTERN = EXPR;В аннотации типа, если она требуется, указывается тип значения выражения справа, а не тип отдельных переменных, которые могут вводиться внутри паттерна (а могут и не вводиться). При этом let также используется в условиях if и while, если вместо истинности логического выражения там необходимо проверить соответствие выражения образцу:
if let PATTERN = EXPR {
...
}
while let PATTERN = EXPR {
...
}Сам синтаксис образца PATTERN общий для всех мест, где он может использоваться: помимо указанных let, if let и while let, это также оператор match, for и аргументы функций и замыканий (там уже нет надобности в отдельном слове let, так как ничего другого, кроме образца, использовать в этих местах нельзя).
struct Foo {
a: i32,
}
let Foo { a: mut b } = Foo { a: 25 };В примере выше производится деструктуризация значения типа Foo и вводится новая переменная с именем b, которая получает свое значение из поля a и в дальнейшем может измениться.
В простых случаях паттерн может состоять только из одного имени новой переменной, но это только частный случай. К тому же Rust не требует, чтобы значения с новыми именами были связаны именно в той же инструкции, где эти имена были объявлены:
let a;
a = 25;Наконец, Rust поддерживает затенение переменных:
let a = 25;
// `a` имеет числовой тип
let a = "hello";
// теперь `a` имеет строковый типВо всех этих случаях нужно явно отличать let a или let a = 25 от просто a или a = 25, и ключевое слово let прекрасно с этим справляется.
Сокращения в ключевых словах
Уж наверное только совсем ленивые критики синтаксиса Rust не "проехались" по сокращениям в ключевых словах. Зачастую дело выставляют таким образом, что Rust форсирует сокращения и сплошняком только из них и состоит. Но на самом деле из 40 ключевых слов языка сокращениями являются только 7:
fn, mut, mod, pub, impl, dyn, refПри этом dyn и ref используются крайне редко. Дополнительно есть еще 5 коротких ключевых слов (в две и три буквы), которые не являются сокращениями:
if, as, let, for, useВсе остальные слова — длиннее. Некоторые из них сделаны длинными намеренно, например continue и return: они используются редко и должны быть хорошо заметны в коде, хотя первоначальные версии языка вместо них использовали слова cont и ret.
Тем не менее, больше всего претензий возникает к ключевому слову fn. Предлагают обычно либо его убрать совсем, либо заменить на function.
На самом деле fn — весьма неплохой выбор для достижения компромисса между двумя крайностями. Наличие длинного слова function особо не помогает при чтении кода, обычно определение функции и так заметно по остальной ее сигнатуре и обязательному блоку с ее телом. Оно только оттягивает на себя внимание от имени и аргументов функции. К тому же оно занимает слишком много места, что плохо сказывается не только на скорости набора, но в ряде случаев и на чтении кода, например, в мессенджерах.
Но и отсутствие ключевого слова — тоже плохо, так как в этом случае возникают ситуации, когда становится невозможно однозначно отличить функциональный тип от других элементов языка:
let a: fn(i32, String); // `a` - указатель на функцию с двумя аргументами
let b: (i32, String); // `b` - кортеж из двух элементовБез специального ключевого слова, предваряющего имя объявляемой функции, становится сложно искать строки объявления по кодовой базе, так как они синтаксически становятся похожи на вызовы.
Хорошо, но почему бы не выбрать сокращение подлиннее, такое как fun или func? Это довольно спорный вопрос даже в Rust-сообществе, но fn выглядит более нейтральным, так как не является другим самостоятельным словом и не имеет никаких посторонних значений по звучанию, так что оно хорошо ассоциируется с function и является минимально возможным его сокращением.
Говоря о коротких ключевых словах и спецсимволах, стоит заметить, что код с ними становится плохо читаемым в том случае, если программист также выбирает короткие имена для объектов программы. В таком случае глаз "спотыкается", становится сложно отличить пользовательские имена от элементов языка. В случае же использования длинных имен, дискомфорта не возникает, наоборот, глазу становится проще отделять имена от синтаксических конструкций, что улучшает восприятие кода. Поэтому такие слова как fn, mut, mod, pub, impl, dyn и ref, после которых идут пользовательские имена, не затрудняют, а улучшают чтение программы, если при этом программист выбирает длинные осмысленные имена для своих объектов, а не увлекается сокращениями.
Стрелка в сигнатуре функций
Другая частая претензия к объявлению функций в Rust, это использование символа "стрелки" для разделения блока параметров от типа возвращаемого функцией результата:
fn foo(x: i32) -> bool {
...
}
Кажется, что последовательнее тут тоже использовать двоеточие:
fn foo(x: i32): bool {
...
}Однако в таком случае создается впечатление, что тип bool относится ко всему выражению слева, то есть ко всей функции, тогда как на самом деле он является только частью функционального типа, указывающей тип возвращаемого значения. Проблему становится заметно еще отчетливее в случае объявления переменной функционального типа:
let foo: fn(x: i32) -> bool;Против
let foo: fn(x: i32): bool;Видно, что двоеточие во втором случае затрудняет для человека восприятие типа, а стрелка подходит на его место лучше других символов, так как это принятое обозначение во многих функциональных языках, куда оно проникло из математики, из просто типизированного лямбда исчисления.
В случае если функция не должна возвращать никакого значения, в Rust считается, что она возвращает значение "пусто" (), и тип возвращаемого значения можно не указывать. То есть
fn foo() -> () {
...
}равнозначно
fn foo() {
...
}Без подобного сахара для такого тривиального случая, от обилия спецсимволов действительно начало бы пестрить в глазах.
Замыкания
В отличие от обычных функций, список аргументов у замыканий выделяется не круглыми скобками, а вертикальными чертами:
foo().map(|x| x + 2)В большинстве случаев у замыкания типы аргументов и тип возвращаемого значения выводятся автоматически и указывать их не нужно. Если все тело замыкания состоит только из одного выражения, то фигурные скобки также можно не ставить.
Текущий синтаксис прошел определенную историю развития, в процессе которого он избавился от всего лишнего и приобрел эту окончательную, легковесную и лаконичную форму. Использование вертикальных черт улучшает читаемость кода: замыкание хорошо выделяется в группе аргументов функций, где оно используется чаще всего, при этом его сложно спутать с кортежем или массивом.
Преимущества подобного синтаксиса достаточно очевидны, остается загадкой, почему он не устраивает многих критиков языка. Пожалуй действительную проблему представляют только некоторые вырожденные случаи, например:
foo().map(|_| ())Конструкция |_| () выглядит некрасиво. Она означает, что мы игнорируем входной аргумент замыкания и возвращаем из замыкания пустое значение. Подобный map полезен, когда нужно преобразовать одно значение типа Result в другое с заменой положительного значения возврата на "пусто". Однако добиться этого можно и более наглядным образом, просто передав функцию drop вместо замыкания:
foo().map(drop)Двоеточия в пути
В Rust используется двойное двоеточие :: в качестве квалификатора пространств имен, который разделяет сегменты в логических путях к элементам (items) языка, при том, что для доступа к полям и методам структур используется точка .. Это часто раздражает людей, привыкших к языкам, где для доступа к полям и методам используется тот же синтаксис, что и для доступа к элементам внутри пространства имен. Им кажется, что синтаксически разделять эти два обращения совершенно избыточно, и Rust использует подобное разделение либо в силу скудоумия своих создателей, либо из-за желания подражать C++.
Однако на самом деле, предоставляемые Rust возможности требуют явного синтаксического разделения статических обращений xx::yy::zz и динамических xx.yy.zz, где результат будет зависеть от значения объектов xx, yy и zz во время выполнения. Возможны ситуации, когда программист должен использовать канонический путь для обращения к методу, когда ему нужно явно указать тип или типаж, на котором будет вызван данный метод:
let foo = Foo;
foo.bar(); // вызов метода `bar` из `Foo`
Bar::bar(&foo); // вызов метода `bar` из реализации типажа `Bar` для `Foo`Такое происходит, когда разные типажи, реализованные для типа, используют одинаковые имена методов, и разрешить конфликт имен необходимо статическим указанием на конкретный типаж или тип, к которому относится метод. Подобная запись вызовов оказывается незаменимой при обобщенном программировании. Если использовать для статического и динамического обращения один и тот же разделитель, то становится невозможно различать подобные вызовы:
Foo::bar(&foo); // вызов метода `bar` из `Foo` у объекта `foo`
Foo.bazz(&foo); // вызов метода `bazz` у созданного на месте объекта `Foo`Программа, написанная на Rust, не имеет информации о типах во время выполнения, так как при компиляции происходит "стирание типов". Поэтому возникает необходимость различать динамические и статические обращения: механизм их работы сильно отличается, как и последствия, к которым они приводят, так что программист должен видеть это в коде явно. Однако в качестве утешения появляется возможность использовать одни и те же идентификаторы для имен переменных и модулей, что очень удобно.
Дженерики
Хотя код с использованием угловых скобок для обозначения параметров обобщенных типов <T> выглядит более "шумно", чем код с использованием квадратных скобок [T], тем не менее в Rust используется вариант с угловыми скобками, потому что он однозначно отделяет тип от контекста его использования, тогда как конструкция [T] — сама является обозначением типа (среза).
fn parse<F: FromStr>(&self) -> Result<F, F::Err> {
// ...
}Обобщенный метод parse на вход принимает тип F, реализующий типаж FromStr, и ссылку на экземпляр объекта &self, для которого реализуется данный метод. Возвращает же он обобщенный тип Result, в который передаются в качестве параметров типа F и ассоциированный с ним тип F::Err.
Угловые скобки используются для работы с обобщенными типами как в контексте объявления обобщенных элементов, так и в контексте выражения при подстановке уже конкретных типов. И с этим связана, пожалуй, самая уродливая конструкция языка — жуткий мутант, внушающий первобытный страх любому, кто случайно заглядывает в глубины "синтОксиса" кода на Rust. Имя этому монстру — Турбофиш:
"2021".parse::<usize>()Вот этот страшный зверь ::<> и есть Турбофиш. К сожалению оказалось, что от него совсем не просто избавиться: конструкция A<B>() выглядела бы логичнее и лаконичнее, но в контексте выражения парсер не может отличить ее начало от операции сравнения A < B. Отсюда и возникает необходимость дополнить угловую скобку разделителем сегментов в пути ::. Турбофиш очень знаменит в сообществе разработчиков на Rust, и если он когда-нибудь все-таки будет устранен (что вряд ли), то этот факт опечалит многих людей. По-своему он прекрасен, и к нему уже все привыкли.
Времена жизни
Имена времен жизни в Rust указываются с префиксом в виде одинарной кавычки: 'name. Не всем это нравится, но данный синтаксис самый лаконичный из всего, что было предложено. До его введения использовался синтаксис /&name и &name/, который гораздо хуже читается. Идея синтаксиса 'name была навеяна тем фактом, что близким аналогом параметра времени жизни является параметр типа, то есть указание времени жизни по-факту делает элемент обобщенным:
struct StringReader<'a> {
value: &'a str,
count: uint
}Идентификаторы с префиксом или суффиксом в виде одинарной кавычки используются в языках семейства ML. В частности, в OCaml запись 'name используется для обозначения переменной типа в обобщенных конструкциях. Rust продолжает эту традицию.
Кроме того, в Rust нашлось еще одно интересное применение подобного синтаксиса — для задания меток:
'outer: loop {
loop {
break 'outer;
}
}Параллели с временами жизни тут не случайны: предполагалось, что в будущем в языке появится возможность аннотировать любые блоки подобными метками, которые будут также служить идентификаторами времен жизни их содержимого:
'a: {
let x: &'a T = ...;
}Сложно сказать, будет ли вообще реализована такая функция в языке, но если потребность в ней возникнет, то она органично впишется в существующий синтаксис.
Макросы
Синтаксис описания декларативных макросов справедливо критикуют за плохую читаемость, хотя сам по себе он довольно простой и понятный. Требование смешения обычного кода с командами макроса налагает серьезные ограничения на синтаксис команд и не в пользу повышения их читаемости. Проблема эта известна, и довольно давно уже ведутся работы по улучшению системы макросов в рамках реализации "macros 2.0". Но пока приходится довольствоваться тем, что есть. Хотя синтаксис макросов действительно часто выглядит токсично, спасает то, что он крайне минималистичен и прост: имеются идентификаторы фрагментов $name и конструкции повторения $(..)+, $(..)* и $(..)?. По сути — это все.
Отдельно стоит упомянуть синтаксис обращения к макросу name!. Он проектировался с целью сделать имена макросов заметнее в потоке кода, чтобы визуально можно было сразу отличить вызов макроса от вызова обычной функции. Это важно, так как макросы расширяют синтаксис языка и принимают в качестве параметра код с пользовательским синтаксисом, то есть синтаксис самого выражения, а не его вычисленное значение. Восклицательный знак хорошо справляется со своей задачей, вызов становится заметным, но не настолько, чтобы перетянуть на себя все внимание (как происходит с другими, широкими символами, вроде @). Интуитивно восклицательный знак можно воспринимать как команду активного действия: макрос разворачивается во время компиляции, тогда как обычная функция остается в этом отношении пассивной. В похожем отношении восклицательный знак также используется в языке D при инстанциации шаблонов.
Собираем все вместе
Хорошо, допустим, каждый из элементов синтаксиса относительно неплох, но как они сочетаются все вместе? Разве их комбинация не превращает Rust-код в нечитаемое месиво из спецсимволов? Например:
fn foo<'a, T: FromStr, I: IntoIterator<Item = T>, F: Fn(T) -> bool>(
self: &'a Self,
first: T,
callable: F,
iter: I,
) -> Result<&'a T, T::Err> {
// ...
}На самом деле это действительно большая проблема. Сигнатуры обобщенных функций с заданными ограничениями, видимо, самые перегруженные синтаксисом элементы языка Rust. И чтобы справиться с ними, Rust предлагает различные синтаксические улучшения и особый сахар, который помогает лучше упорядочить ограничения и скрыть из виду те аспекты, которые и так достаточно очевидны:
fn foo<T, I>(&self, first: T, callable: impl Fn(T) -> bool, iter: I) -> MyResult<T>
where
T: FromStr,
I: IntoIterator<Item = T>,
{
// ...
}Сигнатура метода foo уже не выглядит настолько страшно, как в исходном варианте. Она не идеальна, но сравнивая с тем, что было, все же заметен явный прогресс в улучшении читаемости. Видно, что алиасы, автовывод времен жизни, сахар для указания self, impl Trait в позиции аргумента, блок where и прочее, введены в язык не случайно и они сильно упрощают чтение действительно сложных мест, с непростой семантикой.
Заключение
Как видите, синтаксис Rust не так уж и плох. По крайней мере любой элемент синтаксиса продуман глубже, чем кажется при поверхностном взгляде и выбран именно таким по веским причинам соблюдения баланса простоты, единообразия и выразительности. Отчего же столько негодования и яростных воплей разносится по сети, насчет "токсичности" синтаксиса Rust? Я думаю главной причиной является объективная сложность и непривычность концепций, которые скрываются за этим синтаксисом, а также высокая информативная плотность кода на Rust. Новичку это вселяет ужас, а опытному Rust-программисту облегчает жизнь, так как расширяет его возможности, обеспечивает высокую степень явности и локализованности кода.
Источники
- The Rust Reference
- The Rust-dev Archives
- Niko Matsakis — Syntax matters...?
- Aleksey Kladov — Why is Rust the Most Loved Programming Language?
- Such a Little Thing: The Semicolon in Rust
- Why does Rust bother with “let”?
- Why should a language prefer indentation over explicit markers for blocks?
- Python: Why separate sections by indentation instead of by brackets or 'end'
- Why does rust parser need the fn keyword?
- Please Rust-lang, why, oh why, do you choose to name function 'fn' and module 'mod', dont you expect to read any of the programs you write!?
- What's the origin of -> in Rust function definition return types?
- Why double colon rather that dot
What is the syntax: instance.method::<SomeThing>()?- What is rust's lambda syntax and design rationale?
I now realize why rust uses ::for module namespace seperator and.for accessing fields in a structUnify attributes and macros to use @sigil, redux- ::<>
- Обсуждения синтаксиса из комментариев к новости "Выпуск языка программирования Rust 1.47"
- Анонсировано создание независимой от Mozilla организации Rust Foundation
soymiguel
Cтатья на несколько тысяч знаков о токсичности синтаксиса <чиво-бы-то-ни-было> — это апофеоз развития ИТ-сообщества 21 века, которое мы заслужили.
С нетерпением жду брекинг-новостей о массовых самовыпилах с трансляциями последних истерик в ТикТоке (а кто-нибудь еще помнит снапчат, этот моднючий блидинг-эдж 2хлетней давности?) и привычной уже констатации худшего года в истории человечества из-за необратимого повсеместного распространения моржового оператора в Питоне.
Так же с удовольствием бы почитал о токсичности формы ручек для отверток, например.
Rive
Если бы программы не читались после написания и не писались командой, то вопрос командного взаимодействия не стоял бы вовсе.
Но увы, делать эту работу в коммерческой разработке иногда приходится, а следовательно код становится одним из способов общения команды между собой.
Если исходный код выглядит как стенография лекции по истории гностических ересей в Южной Франции на палимпсесте конспекта курса по топологии, это не будет способствовать популярности такого ЯП на рынке труда: работодатели будут считать найм разработчиков такого кода слишком дорогим, а рабочих мест для работников не будет хватать.
soymiguel
Вы знакомы с, чтобы далеко не ходить, ABAP? Ни разу еще не встречал хронически безработного ABAPера. И ничего, работают, в основном, в командах.
С другой стороны, синтаксис 1С, не то, чтобы ужасен, конечно, нет — он чудовищен… А проблем таких на рынке нет.
freecoder_xx Автор
Почему молодые? Думаю, хейтеры синтаксиса Rust на Opennet вполне себе бородаты.
soymiguel
Молодость и перспективность как субъективное состояние души. Есть наверняка и 15-летки — апологеты Фортрана и Лиспа, и кто их осудит.
И да, само понятие «хейтер синтаксиса» вообще слабо коррелирует с опытом и мудростью, имхо.
MinimumLaw
Ну я бородат. И мне не зашел синтаксис Rust. Правда на OpenNet я ничего не комментирую. Обстановочка не та.
Впрочем, я и не хейтер. Вопрос в том, что любой синтаксис становится привычным при регулярном использовании. Не в синтаксисе дело. Он явно создан сторонниками Pascal'я. Не хорош и не плох. Я поплевался пока пробовал Rust в деле, но явного отторжения не вызвал. Часть на С выглядит лучше, часть на Rust'е. Меня больше python выбешивал. Пока не плюнул и не сказал — не мое. И то ругаться не буду. Просто это не мой инструмент.
Вопросы к Rust они о другом. Впрочем, вот допишу статью потом обсудим… Лежит в черновиках…
bolk
«Раст» создан поклонниками «Паскаля»? Что-то не могу в «Расте» буквально ничего от «Паскаля» вспомнить.
tyomitch
Тип после имени переменной, а не до, как в C++ и Java.
bolk
ОМГ и это всё? А где «begin»/«end»? Присваивание через «:=», указатели через «крышечку»? На Си он в миллион раз больше похож, чем на Паскаль.
PsyHaSTe
А что не как в TypeScript?
F0iL
Ну в Go то же самое, например. При этом он в гораздо большей степени C-like.
То же самое в Kotlin и Scala. Но там уж и говорить нечего :)
barnabyfletcher
Да почему сразу хейтеры Rust'a? Удобный синтаксис, если его изучать, уделяя не меньше времени чем остальным. Просто менее популярный, потому больше людей его хейтят т.к. не пользуются им на постоянной основе.
thatsme
> Думаю, хейтеры синтаксиса Rust на Opennet вполне себе бородаты.
И не только на opennet, a вот я вчера побрился. И кстати как раз сегодня перед тем как спать пойти (после того как релиз залил), размышлял на тему об отсуствии статей на хабре об уродливости синтаксиса раста.
Целая куча замечательных, полезных и интересных идей так заштукатурена отвратительным уродливым синтаксисом, что на код даже смотреть не хочется. Дело не в сложности чтения этого кода, а в отвращении которое он вызывает при одном только взгляде.
Это что-то на уровне животных инстинктов, совершенно не рациональное, но это есть. Есть совершенно неполиткоректный факт, — многим людям сложно смотреть на калек и деформированных людей. Они даже взгляд отводят. Со временем это проходит, какая-то привычка вырабатывается. Так вот rust такое-же «биологически обусловленное» отторжение вызывает…
DarkEld3r
Это скорее узость кругозора. Когда-то и меня сильно волновал вопрос синтаксиса: отступы или скобочки, как эти скобочки расставлять,
int* pилиint *pи прочие "чрезвычайно важные нюансы". С опытом понимаешь, что всё это ерунда. Только опыт желательно иметь разноплановый. Скажем, пощупать лисп с хаскелем, а не только на С десять лет писать.tyomitch
Не забывайте «пробелы или табы», главный философский вопрос ушедшего века!
merhalak
Даже этот вопрос имеет решение в Rust.
https://doc.rust-lang.org/stable/book/ch01-02-hello-world.html
PsyHaSTe
Да ну? hard_tabs = true. Пробелы по дефолту, но и всё. У нас например половина настроек форматирования отлична от дефолтов так-то.
freecoder_xx Автор
А вы можете сформулировать более четкие претензии к синтаксису? Я понимаю ваши чувства, но не зная их подоплеку сложно спорить конструктивно.
thatsme
В том то и дело, что чтобы чёткие претензии к синтаксису раста составить, нужен будет сеанс психоанализа. Я же написал, что это нечто иррацопнальное, не нравится и всё. Причём все идеи заложенные в раст очень нравятся, но смотреть на код неприятно.
Там вон уже и минусов понаставили, и в узости кругозора обвинили, а на самом деле это возможно из разряда фобий, или просто нечто социо-культурное. Вот как пример www.quora.com/Why-do-some-people-dislike-people-with-disabilities попытка объяснения. Но явление довольно массовое.
0xd34df00d
А, ну теперь
Xobotun
Мне кажется, тут где-то уже спрашивали и вы что-то отвечали — но как эти символы вводить? Отдельную раскладку или IDE должна уметь в подстановку "tau" > "?"?
UPD: нашёл, спасибо.
JTG
Для непосвящённых это выглядит как-то так:
freecoder_xx Автор
По вашему синтаксис языка программирования не достоин обсуждения?
soymiguel
По-моему, употребление термина «токсичность», не относящееся к токсикологии и смежным темам — это красный флаг в целом.
А предметное обсуждение особенностей языков программирования — это круто и очень полезно.
freecoder_xx Автор
А красный флаг тогда тут при чем? Мы разве гонки обсуждаем, или мореплавание, или революционную борьбу?
Mat1lda
Красный флаг в том плане, что в прогрессивном 21 веке это слово вызывает аналогию с заменой ключевых слов в ЯП, чтобы чёрные не обижались (привет питон).
cl0ne
А что за ключевые слова в питоне заменили?
tyomitch
bugs.python.org/issue34605
markhor
Так это же про документацию. Никто кейворды не трогал, к счастью.
tyomitch
Mat1lda употребил словосочетание «ключевые слова» не в том значении, которое поняли вы. Определение из википедии: «Ключевые слова — особо важные, общепонятные, ёмкие и показательные для отдельно взятой культуры слова в тексте»
Mat1lda
www.opennet.ru/opennews/art.shtml?num=49256
chapuza
Абсолютно согласен.
Вообще, обсуждение характеристик синтаксиса (даже если называть их уместными словами с соответствующими значениями, типа «читаемость») — мне непонятно в принципе. Совершенно очевидно, что любой язык (да, и кобол, и сиквел — тоже) превращается из нечитаемого в читаемый по мере погружения.
Когда я еду во Францию, я освежаю в голове всякие «сильвупле» и «мерси», а не говорю, мол, «фу, какой нечитаемый язык, я лучше пару дней буду питаться не в кабаках, а в супермаркетах без кассиров».
Какая вообще нахрен разница, каков синтаксис языка, если он не умеет, например, из коробки задействовать все ядра? А если умеет — ну в чужой монастырь не надо со своим синтаксисом лезть, можно потратить пару часиков на привыкание.
tyomitch
Пользователю языка — без разницы.
Разработчикам новых языков — полезно учиться на чужих ошибках, чтобы их не повторять.
chapuza
Это было бы круто, кабы существовала непротиворечивая корректная шкала оценки синтаксиса. А так, как ее нет, то и определить — ошибка ли это, или суперспособность — возможным не представляется. «Демократичным» голосованием это определять? — Увольте.
Вон там внизу предлагают изменять язык до неузнаваемости, развивать и дополнять, пока количество синтаксического сахара не превысит количество символов на клавиатуре (а потом и в юникоде) — я бы лично не хотел, чтобы над языками издевались таким способом, выбранным по результатам голосования у джаваскриптовиков, которые желают, чтобы все мучались так, как они.
Я лучше уж разочек синтаксис (любой) освою, а потом буду языком пользоваться, а не переучивать семантику каждые полгода.
tyomitch
Тем и полезны статьи вроде этой, что каждый может ознакомиться с аргументами всех сторон, и сделать выводы самостоятельно.
SadOcean
Ну почему же не надо.
Синтаксис языка — не что-то, высеченное в камне, его можно и нужно менять, развивать и дополнять. Разумеется, после релиза сложновато депрекейтить, но уж дополнять то, в том числе другой синтаксис для существующих вещей можно.
Ну и да — это может быть полезно для других языков
netch80
Сложный декодинг определений типов C — как раз пример, что погружение помогает привыкнуть к тому, что "тут так принято" и смириться, но не тому, что всё равно придётся тратить каждый раз заметную порцию интеллектуальных усилий на его раскрутку.
С теми же фигурными скобками и фальшивым отступом аналогичный пример.
chapuza
За что я люблю синтетические примеры, так это за всё.
Я готов поспорить, что когнитивные усилия здесь придется тратить на понимание того, как этот тип заполняется, и зачем вообще автору втемяшилось объявлять такую функцию. После того, как это будет понято, тип сам собой нарисуется.
В простом коде все эти фигурные скобки и отступы считываются мгновенно, а в сложном — основные проблемы чтения связаны далеко не с ними.
netch80
И это, и что этот тип из себя представляет. В том и проблема. Пример реальный, а не синтетический.
bolk
А выражение «ядовитый тон» для вас тоже красным флагом является?
tyomitch
Словарь гласит, что «ядовитый тон» означает «презрительный».
Синтаксис ЯП может быть презрительным?
zoonman
Вполне себе синтаксис можно презирать.
beeklz
Речь же явно идёт о оттенке цвета.
tyomitch
Можно хоть один пример текста, где бы «ядовитый тон» означал оттенок цвета?
Noortvel
ну я думаю под «токсичностью» подразумевалась плохая читабельность и автор хотел внести этим какой то литературной красоты, эх какое словцо приловчил к тексту! А вообще код на Расте и правда трудно читать, особенно новичкам, не знаю, возможно просто привык к Си стилю(и терпеть не могу Perl). Но есть люди, которые высказывают мнение о плохо читаемости, и думаю стоит им пояснить почему создатели Раста решили сделать именно так, а не иначе, чтобы переманить часть тех, кого это не устроило в языке.
freecoder_xx Автор
Вы саму статью читали? Хотя бы вводную ее часть?
PsyHaSTe
"Токсичность" можно вольно транслировать как "недружелюбность". И недружелюбность чего-бы-то-ни-было, синтаксиса или ещё чего вполне возможна.
IkaR49
С первого дня изучения раста меня напрягали только лайфтаймы, всё остальное, плюс минус, уже видел в крестах.
Так же считаю ваши аргументы за первые 2 пункта неудачными и протянутыми за уши, но и сами претензии, имхо, крайне глупые.
snuk182
ВЖ пугают с непривычки. Когда приходит понимание, что их синтаксис не просто так аналогичен дженерикам, становится совсем просто.
Sartor
Так проблема как раз в том, что привыкнуть к ним очень тяжело. Я ситуативно пишу на раст и до сих пор, если честно, не всегда понимаю что от меня хочет компилятор, когда требует указания времени жизни.
DarkEld3r
Даже любопытно стало. А примера неочевидности под рукой не сохранилось?
PsyHaSTe
Ну есть более-менее очевидные например асинки. А есть менее очевидные, например:
То есть претензия компилятора понятна, но не очень ясно что в таком случае нужно делать. Намерение вроде понятно: нам приходит на вход ссылка и мы хотим вернуть себя, ограниченным тем лайфтаймом который пришел на вход. Трейт
SomeTraitу нас приходит из библиотеки, и менять его мы не имеем права. Вот как такую ситуацию можно разрешить?Можно было бы попытаться сделать такую сигнатуру:
Но компилятор не разрешит, скажет что оригинальная сигнатура другая:
Хотя в теории мы просто сделали дополнительное ограничение. То есть в нашем случае лайфтаймы оказывается не контравариантные, и если создатель библиотеки не предусмотрел такого вариант то упс.
Mingun
Ну и решение: к сожалению, без изменения типажа решения не выйдет. Решается так:
Еще один пример — стандартный типаж
Index, возвращающий ссылку на свои внутренности. Из-за этого невозможно возвращать только что сконструированные структуры-обертки над частью своих внутренностей и это иногда зарубает интересные идеи API.PsyHaSTe
Ну вот речь о том, что типаж нельзя поменять (в реальной задачи это
actix_web::FromRequest), форкать или патчить либу ради этого как-то не очень хочется.Так что проблемы с лайфтаймами бывают вполне себе. Казалось бы, зачем трейту знать про то что реализация хочет лайфтайм как-то именовать и что-то на основании этого делать? Да вроде незачем. А оказывается, что без этого нифига не работает.
anonymous
Может я что-то упустил, но Rust имеет ML-подобный синтаксис. Очень велико влияние OCaml, на котором он изначально и писался.
neplul
Там от ML рожки да ножки остались. До версии 1.0 можно было говорить про ML-подобный синтаксис, потом началась игра в «поддавки» C-подобному синтаксису.
0xd34df00d
Сравните синтаксис раста с синтаксисом какого-нибудь хаскеля.
Да даже какая-нибудь агда ближе к ML, имхо.
tyomitch
А если не перегружать символы
<и>, и вместо этого писатьA[B]()?Тогда и токсичных рыб нет, и метафора «из множества реализаций
Aберём соответствующуюB» совершенно прозрачная.IkaR49
Квадратные скобки заняты для слайсов и массивов.
tyomitch
И в чём проблема? Имя функции не может быть ни массивом, ни слайсом.
middle
Да, но синтаксически содержимое квадратных скобок в каждом случае разное.
tyomitch
И в чём проблема? У круглых скобок в объявлении функции и у круглых скобок в арифметическом выражении тоже содержимое синтаксически разное.
middle
Эти круглые скобки встречаются только в разных контекстах, в отличии от обсуждаемых квадратных.
А проблемы возникают самые разные. Например, Rust обходится без предварительного объявления рекурсивных типов или функций (просто нет такой возможности, потому что не нужно), а в C++ их сначала нужно декларировать, а потом объявлять (кстати, это куда более глубокие вещи, чем лежащие на поверхности фигурные скобочки, которые тут обсуждают).
warlock13
И именно поэтому есть
fn.Mingun
А в этом случае у парсера уже есть подсказка, что-есть-что в виде ключевого слова
fn. И опять не нужно знать извне, что мы парсим — объявление функции или арифметическое выражение. Эта информация уже закодирована в разбираемом тексте. Если выкинутьfn, как тут выше уже предлагали, то это становится невозможно (не говоря уже о том, что эти люди вообще что ли не пытались никогда ничего искать по коду на GitHub.com?)IkaR49
То есть у вас А::<В>(), то есть турбофиш заменится на A[B](), окей.
А теперь представьте себе массив А, в котором лежат указатели на функции, и вы используете имя счетчика В. Тогда выглядеть это будет: А[В](). Упс…
tyomitch
Так а в чём «Упс...»-то?
Вас ведь не смущает, что для поиска в HashMap по ключу используются те же самые квадратные скобки, но семантика у них совсем другая, чем при индексировании массива?
В верхнем комментарии треда я указал, что оба названных вами случая обобщаются как «из набора функций, обозначенного A, взять одну конкретную, соответствующую B», так что схожесть синтаксиса для этих двух случаев совершенно намеренная.
freecoder_xx Автор
Доступ к элементу массива по индексу и к значению в хэш-таблице по ключу осуществляется во время выполнения и вообще говоря для этого используется один и тот же оператор (собственные реализации типажа
Index). ИменноIndexуправляет возможностью делать доступ[i]в рантайме, это просто сахар для вызоваcontainer.index(i), однако в случае обобщенной функции требуется совершенно другая семантика — выбор функции осуществляется на этапе компиляции.tyomitch
Осталось понять, почему разница между поиском во время выполнения и во время компиляции должна быть отражена в синтаксисе, а разница между сложением указателей и поиском в хеш-таблице — не должна быть отражена в синтаксисе.
Mingun
А почему должна? И то и то специально построено на абстракции типажа
Index— поэтому использование и не должно отличаться.Грубо говоря, что при индексации массива производится прибавление к указателю массива смещения — деталь реализации. Могли бы и массивы реализовать под капотом, как хеш-таблицы (если бы спецификация языка это позволяла).
А способ вызова функции напрямую влияет на то, что будет выполняться — или точно определенный код, или относительно произвольный
tyomitch
Я о том и говорю, что ни та ни другая не должна; что подстановка чего бы то ни было во время компиляции — деталь реализации, неинтересная пользователю языка.
Rust может и значения элементов массива подставлять во время компиляции, несмотря на [].
Я о том и говорю, что
A[B]()— вызов «относительно произвольного» кода, хоть A массив, хоть хеш-таблица, хоть дженерик.freecoder_xx Автор
Ну это все же относится к оптимизации частных случаев использования и не работает в общем случае.
0xd34df00d
Семантика та же самая. Массив вообще можно рассматривать как частный случай хешмапы (которую, кстати, в свою очередь можно было бы рассматривать как частный случай функции, и использовать круглые скобки).
tyomitch
Можно пойти дальше и вообще все скобки, включая {}, заменить на круглые. Получится лисп :-)
northzen
О, привет Матлаб.
На деле же получается не очень удобно.
AnthonyMikh
Можете рассказать, какие с этим возникают проблемы?
northzen
В принципе, никаких.
Но я не люблю синтаксис, завязанный на чуткое понимание контекста. То есть, когда есть миллион использований одних и тех же символов и в зависимости от контекста у них разное значение.
Хочется, чтобы контекст «берем N-ый элемент» вычитывался сразу, а не путался с «вызываем функцию от N».
Поскольку редактор в самом Матлабе не совершенствуется уже кучу лет и подсветка и навигация по коду остаются достаточно примитивными, если хочется прочитать и вникнуть в кусок кода, то такие случаи с круглыми скобочками могут приводить к тому, что придется прыгать по всему скрипту.
А еще проще: мне просто не нравится и неудобно. Я писал на Матлабе большую часть своей программерской жизни, как и на Си. И все еще не нахожу это удобным.
Physmatik
Банальный пример, который часто бесит.
Есть функция
f, принимающая число и возвращающая масив. Вам нужен второй элемент. В нормальном (читай, любом) языке вы напишитеres = f(10)[2](нумерация с единицы), но в Матлабе будетres = f(10)(2). На этом этапе парсер вам скажет "какие нахрен скобки за скобками? Я не понимаю". И приходитсяout = f(10); res = out(2), или[~, res] = f(10). Со вторым, однако, проблема, потому что количество аргументов в таком матчинге может влиять на алгоритм и вывод функции — то есть не всегда применимо, но это уже немножко другая история.И парсер тут не тупой: функция ведь может возвращать функцию, и что тогда делать? В какой байт-код компилить?
Но самое паршивое, это когда читаешь код плохого прогера (а МАТЛАБ — система для инженеров). И пойди тогда разберись, что такое
ar(i, k)— индексация массива или вызов функции.0xd34df00d
Нет, тут тупой либо парсер, либо весь матлаб.
Во-первых, парсер в любом случае не занимается генерацией байт-кода (ну, в норме, по крайней мере). И унифицированный синтаксис облегчает работу парсеру, а не усложняет её (и не усложняет работу последующих стадий при наличии хоть какой-то статической проверки типов — им всё равно нужно эту самую проверку выполнять).
Во-вторых, какая разница, писать
out = f(10); res = out(2);или сразуf(10)(2)? От сохранения в переменную, у которой даже аннотации типа нет, тайпчекеру или кодгену больше информации доступно не станет. Или, иными словами, всё равно ведь надо как-то решать, вернулаfфункцию или массив, чтобы понять, что лежит вout, и в какой байт-код компилироватьout(2).Ну и, в конце концов, в этом нашем хаскеле, например, индексация массива — это просто ещё один оператор (определённый в библиотеке, кстати), который вызывается, как любой другой оператор (которые в хаскеле отличаются от функций только инфиксным синтаксисом против префиксного для, собственно, функций), который можно частично применить, который можно передать в функцию или вернуть из функции, и так далее.
Physmatik
Буквальный код ошибки выглядит так
Indexing with parentheses '()' к тому, что индексирование тут ещё бывает через фигурные скобки для специальных массивов.
Если столько не исправляют, то, скорее всего, что-то фундаментальное. В принципе, я согласен с вами в том, что причина, скорее всего, не в "функция ведь может возвращать функцию, и что тогда делать?".
mayorovp
Скорее всего это фундаментально положенный болт.
Physmatik
Не думаю, хотя не сильно удивлюсь, если и вправду так.
mayorovp
А я уверен, что именно в этом и дело. Это общая беда любых языков программирования, которые идут "в нагрузку" к другому программному продукту.
Расчёт тут простой: если у всего продукта целиком недостаточно фич — язык его не спасёт, а если достаточно — то пользователи никуда не денутся. Поэтому сам язык развивается по остаточному принципу, лишь бы на нём хотя бы в теории можно было писать. Это и есть фундаментально положенный болт.
freecoder_xx Автор
A[B]это еще доступ по индексу.tyomitch
См. выше
Mingun
В статье же объяснялось что синтаксис такой, что вам не нужно знать, что такое
Aи что такоеB, чтобы правильно распарсить исходник (т.е. вы не знаете, что это имя функции, так что ваше знание "Имя функции не может быть ни массивом, ни слайсом." вам ничем не поможет). И это хорошо — это позволяет всегда корректно парсить произвольные куски кода, что очень хорошо для подсветки синтаксиса и извлечения информации из еще недописанного кода, чтобы IDE могла чем-то помочь, а не свешивать лапки.tyomitch
В целом я согласен, но конкретно с
::<>я не вижу:[]?[]мешает подсветке синтаксиса?Проблема, которую я вижу — что если внутри
[]будет тип вместо выражения или наоборот, то это отловится не сразу при парсинге, а на более позднем этапе. Но и здесь ничего нового: сейчас неподходящий индекс вlet hello = [42]; print!("{}", hello["world"]);тоже ловится не сразу при парсинге, а на более позднем этапе.Mingun
IDE уже знает, что это функция или тип и может просматривать свою базу данных о функциях и типах. В вашем варианте она должна еще предлагать и варианты из выражений.
Написав
x::<уже известно, чтоxили имя функции, или имя типа, а дописавx::<T>(уже понятно, что точно имя функции. Основываясь на этом IDE может искатьxв своей базе данных функций или типов и предлагать, что делать дальше. Конечно, если такой функции/типа еще не написано, то она ничем не поможет, но если есть — то уже поможет.Если использовать синтаксис с квадратными скобками, то написав
x[непонятно, что такоеx— имя функции? имя типа? слайс?Написав
x[T](это все еще неясно —xэто слайс или имя функции.А если в области видимости окажется и слайс с именем
xи имя функции или имя типа с именемx? Тут IDE предлагать адекватные варианты уже сложнее — если она сможет понять, что именно ожидается в месте написания кода, то предложит, а если нет — то в лучшем случае будут лишние варианты а в худшем — только неправильные.Есть еще проблема. В Rust можно инстанцировать Unit-структуры просто написав их имя:
Это индексация выражения
xтолько что созданным экземпляром типаUnitили инстанцирование generic с типомUnit?Зависело бы от того, что такое
x.Ведь это те мелочи, от которых любит подгорать у хейтеров C++, когда изменения в одном месте программы внезапно могут сказаться на другом ее месте (в данном случае добавление строчки с определением
xвыше, которое скроет начальное определениеx).По-моему хорошо, что создатели языка постарались учесть эти проблемы и уменьшить их, насколько возможно. То, что код делает, должно быть минимально ясно из взгляда на локальный кусок кода, а не ворошением всего файла/модуля/проекта. Может быть и у Rust это не всегда получается, я не знаю, но это же не повод совсем на это забить
tyomitch
Я о том и говорю, что пока x не определено — IDE не поможет ни при том ни при другом синтаксисе, а как только x определено — IDE известно, что это такое, и при том и при другом синтаксисе.
То это ошибка «E0428: the name is defined multiple times» хоть при том, хоть при другом синтаксисе.
Busla
Как это не поможет?! — x, не определено, но понятно, что это имя функции -> IDE может сама мне сгенерировать «рыбу» определения функции.
nin-jin
А зачем их как-то отдельно ещё и инстанцировать? Вообще сомнительная фича.
freecoder_xx Автор
Затем, что они становятся бесполезными, если не иметь возможности их инстанциировать.
nin-jin
Они сами себе инстансы же.
freecoder_xx Автор
Нет, их нужно инстанциировать, если необходимо получить объект данного типа. Как и другие структурные типы.
PsyHaSTe
Ну например
Result<(), Error>(функции типа записи в файл) требуют в концеOk(())чтобы компилировалось. Без инстанса()типа()тут не обойтисьtyomitch
Вопрос в том, зачем создавать больше одного инстанса каждого такого типа.
PsyHaSTe
А как по-другому? Каждая функция возвращающая
()должна создать свой экземпляр этого типа, иначе не работает. Это же не ГЦ язык где можно просто так ссылку вернуть, в расте ссылка должна была бы явно обозначаться&().А ещё бывают массивы юнитов
nin-jin
Все "инстансы" такого типа будут равны друг другу, так что нет никакого смысла "создавать" инстансы. Достаточно использовать имя типа в качестве алиаса для синглтона инстанса.
PsyHaSTe
Стандартный ничем не отличается от энума
enum MyUnit { Unit }. Наделять его какими-то специальными свойствами "просто шобы було" нет никакого смысла — и так работает, зачем вкоряживать кастомную логику? Так-то кому-то массив юнитов может показаться бесполезным, вещь которую нужно запретить, но в дальнейшем оказывается что всё несколько сложнее.AnthonyMikh
Ну, не совсем, unit-like структуры чаще используются в качестве тИповых маркеров, а не явно в коде.
NeoCode
Интересная тема.
Во-первых, конечно, любому современному сложному языку программирования не хватает спецсимволов. Тех же скобок, например, чтобы не использовать знаки «больше» и «меньше» в качестве скобок. Да, есть целый Unicode, но нужно чтобы эти символы были на всех клавиатурах мира — а значит, мы опять возвращаемся к ASCII. Наверное, неплохим решением было бы, если бы консорциум Unicode выделил 20 наиболее важных символов и предложил бы наносить их на все клавиатуры на буквенные клавиши (возможно потребовался бы еще один Shift). Для полной совместимости с ASCII можно было бы даже
продублировать их в начале ASCII, в кодах 0x01..0x1F (исключая POSIX-символы переносов строки, табуляций и чего-то там еще). Но такое чудо вряд ли случится:)
Фигурные скобки и точка с запятой нужны. Это именно то, что позволяет структурировать код явно, не надеясь на невидимые пробелы и табы, как это принято в Python, а также make-файлах и еще каких-то древних форматах.
Постфиксная запись типа… ну лично мне не нравится. Но наверное авторы правы. Смысл var и let я понимаю, ключевые слова, предваряющие введение новых имен, должны быть обязательно.
Сокращения в ключевых словах это хорошо, особенно fn. Это лучше чем функции в C/C++ без ключевых слов вообще. Значительно упрощает работу парсера. А вот стрелки в сигнаруте функций… в Go вообще обошлись без спецсимволов там. Просто возвращаемый тип после скобок с аргументами.
Замыкания — нет, не нравятся. Я бы вообще не стал делить функции на обычные и замыкания, использовал бы везде fn как универсальное ключевое слово. Кстати, в Rust вроде бы нет явного связывания переменных, как в С++ (в квадратных скобках).
Также не нравится применение символа "|" в паттерн-матчинге. Это же всегда было «Битовое ИЛИ», зачем его мешать сюда? Чем запятая не угодила?
С использованием :: наверное авторы правы, хотя мне не нравится. Опять же — недостаточно спецсимволов!
Использование угловых скобок — с одной стороны наверное это выразительно, но всем известно про то что они путаются с символами «меньше» и «больше», и для парсера это тоже может быть проблемой. Опять же нехватка спецсимволов.
Для «цитирования» кода в макросах тоже не помешали бы особые, уникальные скобки-кавычки. Ну и т.д.
mayorovp
Совместимость с ASCII в век победившего UTF-8 уж точно не нужна. Вот в раскладку клавиатуры новые скобки по-включать — идея по-лучше, жаль только нереализуема.
NeoCode
Ну есть в этом что-то логичное и правильное — «законодательно» разделить все символы на 3 группы: «международные», «национальные» и «дополнительные». И сделать так, чтобы «международные» кодировались 1 байтом даже в utf-8 (и заодно у производителей клавиатур появилась бы мотивация их наносить на клавиши), «национальные» укладывались в два байта utf-16 (кодовую плоскость, если я не ошибаюсь), а всякие эмодзи и древние алфавиты — всё остальное.
А первые 32 байта ASCII как раз не используются, кроме нуля, пробела, переносов строк и табов. Совместимость с древними телетайпами вряд ли кому нужна.
tyomitch
Вы из какого года пишете? Windows API до сих пор не поддерживает строки в UTF-8.
mayorovp
Ну, Windows API вместо этого UTF-16 использует. Невелика разница.
Однако, код программы напрямую в Windows API никто передавать не будет, а все нормальные текстовые редакторы UTF-8 таки поддерживают.
khim
Про год лучше у вас спросить. Потому как в 2021м у большей части населения планеты Windows таки UTF-8 поддерживает. Только суровый Enterprise отстаёт.
mayorovp
Уточнение: поддерживать-то поддерживает, но баг в conhost до сих пор не закрыли. ReadFile из стандартного ввода не может прочитать русские буквы из консоли.
tyomitch
Активная кодировка выбирается для всего процесса целиком, т.е. если в программе используется хоть одна сторонняя либа, то смена активной кодировки для процесса может её поломать. Много вы видели программ под Windows без использования сторонних либ? Т.е. поддержка «для галочки» появилась, но пользоваться ей на практике пока невозможно.
gatoazul
Под APL, где синтаксис состоял чуть менее, чем полностью из загадочных символов, делали специальные клавиатуры.
Если языки программирования массово будут использовать символы Юникода (как это уже делает Raku), то подтянутся и производители клавиатур.
NeoCode
Не, не подтянутся. Программисты это слишком малая часть пользователей клавиатур. Боюсь, уже поздно, а вот предлагаемая мной модификация Unicode, будь она сделана сразу в 1991 году, может и помогла бы.
tyomitch
Ох нет спасибо: я только сегодня возился с кодом на Xtend, в котором как часть синтаксиса используются ёлочки
«». Часть исходников была в UTF-8, часть — в CP-1252, и используемая кодировка в самом файле никак не обозначена — «догадайся мол сама».tyomitch
Что делать тем, у кого на клавишах уже нет места для новых значков, а вокруг них уже нет места для новых Shift?
NeoCode
На большинстве клавиш по 3 символа. Вполне влезет и 4.
Но кстати, какие у них интересные есть символы — полускобочки двух видов, еще одни «панциреобразные» скобочки ? ?
В принципе, такие бы всем непомешали, соответственно этим ребятам свободных клавиш понадобилось бы меньше:)
tyomitch
На всякий случай поясню, что ?...?...?...?— это кавычки (для прямой речи, названий и т.д.): обычные и вложенные; а ?...? используются для вставки авторского пояснения в прямую речь.
NeoCode
Ну в программировании мы бы им обязательно нашли применение!
freecoder_xx Автор
Синтаксис с вертикальной чертой в качестве "или" довольно распространен в функциональных языках, откуда паттерн-матчинг и завезли в Rust.
0xd34df00d
Не нужно. Например, чтобы набрать строку
foo : ? ? SLam ? ? ? ?? ? ?? > ?, я пишу на клавиатуреfoo : `GG `|- SLam `Gt `Ge `:<Down> `Gt`_1 `r= `Gt`_2 `to `bot.С другой стороны, вся эта ерунда на самом деле не нужна в подавляющем большинстве случаев. Когда я писал код на плюсах, уникод бы там не сильно помог. Это только для всякого матана нужно, чтобы текст


был похож на код
Нет, это визуальный мусор. Фигурные скобки и точки с запятой для структурирования не нужны ни в хаскеле, ни в идрисе, ни в агде, и у меня ни разу из-за этого не было проблем (и я ни разу не наблюдал проблемы у других людей). В питоне проблемы были, да, но в питоне вообще своя атмосфера, я его не осилил.
NeoCode
Думаю, что и в хаскеле, и в идрисе, и в агде еще более своя атмосфера:)
0xd34df00d
Ну, суть в том, что скопированная без учёта форматирования строчка (или блок строк) вызовут ошибку компиляции. Придумать пример, когда по-тихому изменится семантика, можно, но надо очень сильно напрячься.
freecoder_xx Автор
Все-таки Rust — это императивный язык, поэтому сравнение с Haskell в этом отношении немного неуместно. Например, в Haskell нет традиционного для императивных языков условия
ifбезelse, а в Rust оно есть. Ну и там, где возникает в Haskell необходимость писать императивно, появляются и фигурные скобки, и точка с запятой. Хоть опционально, но ведь почему-то они в языке присутствуют, не так ли?0xd34df00d
Есть, просто это библиотечная функция, которая называется, скажем,
when.Они возникают не там, где есть необходимость писать императивно, а там, где есть необходимость написать несколько выражений в одну строчку, чтобы эти самые выражения разделить. Смотрите, никакой императивщины, но мусор есть:
В реальном коде я такой стиль, кстати, видел очень редко, потому что проще написать
и скобки — действительно визуальный мусор. Куда чаще его видно в сообщениях в ирке, чтобы на несколько строк и сообщений что-то там не разбивать.
И обратно, когда императивщина нужна, точки с запятой и скобки тоже не нужны:
AnthonyMikh
Мне напомнить, зачем в GHC ввели расширение EmptyCase?
0xd34df00d
Напомните. Очень интересно, как это связано со структурированием кода.
AnthonyMikh
Разбор значения типа-суммы без вариантов. В синтаксис на пробелах оно не впихивается ну вот вообще никак.
0xd34df00d
Ага. Языка, где пишут так:
не существует. И языка, где для указывания пустых случаев используется
impossible, тоже не существует.В любом случае, в хаскеле
{}в этом контексте — это скорее один большой символ, так как между скобками всё равно ничего не может быть (кроме пробелов, конечно). Это не структурирование кода, это маркер. Вместо него могло бы быть с тем же успехом::или ещё какая-нибудь зарезервированная последовательность символов (покуда парсинг остаётся однозначным).DistortNeo
Свободных спецсимволов или комбинаций полно, просто разработчикам языков немного мешает уже накопленный опыт.
Мне в этом плане нравится, как это сделано в D. Зачем пытаться копировать неудачный синтаксис из C++ и усложнять парсинг, когда можно использовать любой другой символ:
!,@,#,$, означающий, что дальше идёт набор шаблонных параметров:Dictionary![TKey, Tuple![Item1, Item2]]илиDictionary!(TKey, Tuple!(Item1, Item2))А вот тут мне нравится, как это сделано в C# — через добавление новых ключевых слов, а не усложнение логики старых:
NeoCode
В D действительно правильно сделано. И в Rust этот подход кстати тоже применен — для атрибутов: символ # изменяет логику квадратных скобок
А в C# сделано неправильно. Там есть оператор switch, его и нужно было расширять — разрешить ему возвращать значения, расширить синтаксис case-образцов и всё остальное, а они вместо этого взяли и ввели альтернативный синтаксис, совершенно ни на что не похожий. В конце концов, можно было бы кроме switch добавить еще match, в котором не требуется break после каждого case; но в остальном и switch и match должны обладать одинаковыми возможностями. Это логично, подобно тому как скажем циклы while и do..while существуют одновременно и отличаются только в одном аспекте.
AikoKirino
В C# есть https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/switch-expression
tyomitch
И что у него общего с оператором switch, кроме ключевого слова?
BigBeaver
l4l
Запятая будет лишним гемором для парсера: https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=84d9b5daaacbb00406e433c389ecb869
mayorovp
Второе обращение явно заслуживает какого-то специального названия, но оно точно не "динамическое".
Не вижу никакого "стирания типов" при компиляции. Автор явно понимает под этим словом что-то иное, не совпадающее со значением этого слова в Java или TypeScript.
Vilaine
Разве в Rust можно получить тип переменной во время исполнения? Завязав логику на этом.
mayorovp
При желании — да, см. трейт Any. При большем желании можно и что-то более хитрое придумать.
Однако, я бы не сводил Type Erasure к возможности получить тип переменной во время исполнения. Ну или, если всё же принять ваше определение, всё равно остаётся непонятной следующая связка:
Нет, я решительно не понимаю как невозможность узнать тип переменной в рантайме влияет на необходимость разделять операторы
::и.. К примеру, в Java используется только точка и ничего (да, первый оператор тоже есть, но он означает иное).Vilaine
Действительно, в такой реализации, как у Rust, можно добавлять к типам метки как общее поведение и обращаться с ними динамически, но ведь можно и не добавлять. =) Data.Typeable в Haskell похожим образом работает, но про него говорится «types erased». В Typescript аналог в принципе что-то вроде function f(s: {typeLabel: string}), если ввести в стандарные библиотеки.
На самом деле мне удалось нагуглить вот какую проблему в параметричности Rust:
Код: play.rust-lang.org/?gist=461340df78e7db710b6e37b592c1ad6e&version=nightly
Тут становится уже сложнее говорить про стирание типов.
Но мне тоже непонятно, причем тут разделение на операторы `::` и `.`.
freecoder_xx Автор
Anyне дает никакой информации о структуре типа, он позволяет лишь получить уникальное число-идентификатор типа. И то только в том случае, если данный трейт используется. Так-то при желании вы можете руками реализовать хранение информации о типе в рантайме, но ведь речь не о том, что можно сделать руками, а о том, как язык работает по умолчанию.В Java насколько я знаю статические методы резолвятся в рантайме, также как и не статические. Статик там означает, что вызов относится к классу, а не то, что вызов будет определен на этапе компиляции, как в Rust.
mayorovp
А где говорилось, что должна быть какая-то информация о структуре типа? :-)
Только если считать промежуточный байт-код "рантаймом". Так-то при генерации машинного кода вызовы статических, приватных и финальных методов превращаются в вызовы по фиксированным адресам (точно не знаю, но я не могу даже представить зачем делать иначе).
Вы так пишете, как будто в Rust те вызовы, которые идут "через точку", не определены на этапе компиляции!
freecoder_xx Автор
Вот здесь говорилось, что этой информации нет во время выполнения: "Программа, написанная на Rust, не имеет информации о типах во время выполнения, так как при компиляции происходит "стирание типов". ". Мне показалось, что вы спорили с этим утверждением.
Java-код компилируется в инструкции виртуальной машины и речь именно об этой компиляции. Во что транслируются уже эти инструкции и транслируются ли вообще, в контексте данного разговора не важно.
Вызов через точку можно рассматривать как вызов, при котором неявно передается указатель на предыдущий сегмент, а значение этого указателя определено в рантайме. Тогда как в вызове через
::сегменты являются именами статических пространств имен и не имеют представления во время выполнения. Поэтому структуры в Rust не могут иметь статических полей, в отличии от классов Java, и статические методы в Rust — это просто функции, расположенные в пространстве имен структуры, ничего более.mayorovp
А сколько информации требуется? Я вот считаю, что TypeId — это уже информация о типах. Вам зачем-то нужна информация о структуре. Кому-то ещё понадобится исходный код типа. В каждом случае получится разное понимание стирания типов. Где будем останавливаться и почему?
Но ведь если выкинуть детали реализации, то в таком случае всё ещё проще же: вызов статического метода приводит к инструкции invokestatic, после которой указывается вызываемый метод. Метод указывается компилятором статически. Где тут резолвинг в рантайме? :-)
Но метод-то связывается не по значению указателя, а по его типу (за исключением ситуации trait object, но эта фича используется относительно редко, а точка пишется всегда).
Не вижу отличия от Java.
freecoder_xx Автор
Где должны храниться значения статических полей в Rust, если после компиляции информация о типе нигде не хранится?
mayorovp
А какое отношение значения полей имеют к метаинформации?
freecoder_xx Автор
Отредактировал свое сообщение.
mayorovp
А какое отношение значения статических полей имеют к информации о типе?
inv2004
Про скобки и отступы:
Из-за древнего примера из си предлагается ещё последующие 100 лет дуть на воду. Опять же не надо забывать, что в современности мало кто программирует в notepad/nano, а отступ в vscode будет виден очень хорошо, за все годы я вспомнил что сделал такую ошибку только один раз, и то всё было найдено и исправлено меньше чем за минуту.
Про блоки: опять же блоки нет никакой нужды обозначать именно скобками, от этого они не перестанут быть блоками в других языках. А вот про область видимости — тут это растёт больше из проблем borrow-checker'а, и в примере с локом, в других языках это выглядит менее вербозно и без борров-чекера, что-то типа:
withLock(mutex): ...
Про;. Опять же нет никаких проблем сделать синтаксис без этого в компилируемом языке, если выражение возвращает (), то не надо ставить;, а если что-то возвращает и находится в конце функции — то это и есть её результат. Просто Раст очень пытался перетянуть на себя си-аудиторию, вот и получилась эдакая микс всего сразу.
Читая про постфиксную запись, я скорее склонен считать, что это попытка выдать желаемое за действительное, можно написать точно такой же текст о том почему это в плюсах удобнее, например auto a = fb() сразу сообщает пользователю об автовыведение типа — удобно как бы. Т.е. не то что это действительно так, но довольно спорный вопрос как удобнее на самом деле.
Опять же let mut избыточен, достаточно mut. Рассуждения о том какой синтаксис чтобы парсеру было удобно — вообще странные.
Не согласен с автором в том, что понимание как работает язык делает синтаксис лучше, скорее просто замыливает глаз, так как описанное в статье скорее из разряда о том как выкручиваются авторы самого раста, а не о горошком синтаксисе. Не смотря что Ява основной язык в моём резюме, но написание на этом вербозном языке, даже спустя десяток лет, не вызывает никаких положительных эмоций, а раст даже Яву переплюнул, правда не только из-за синтаксиса.
PS: всех с Новым Годом!
freecoder_xx Автор
Как насчет code review через веб-интерфейс? Или публикации кусков кода в мессенджерах? Или копи-пасты со stackoverflow? Отступ-то вы увидите, но у вас не будет дополнительного контроля, что вы не сдвинули что-то где-то. На Rust также распространена практика, когда тебе нужно что-то быстро проверить на работоспособность в онлайн-плейграунде и копируешь туда код зачастую с "поехавшими" отступами, но благодаря скобкам об этом не нужно беспокоиться.
Хотя то, что отступы видны хуже, следует также из того факта, что люди с плохим зрением их не видят, в отличии от скобок.
А если нужно лочить не одно значение, а сразу два или три? Городить вложенные блоки? И ведь речь не только о локах мьютекса, а вообще о всем, для чего удобно использовать RAII.
Какого типа должно быть значение
val?Нет никакого
let mut, естьlet PATTERN.let— это не оператор объявления переменных, это оператор сопоставления (в паттерне переменных может и не быть).tyomitch
Пример прямиком из MSDN:
mayorovp
Ужас. Лучше бы в языке этого варианта не было!
inv2004
withLock(mutex1, mutex2)
anonymous
Идея хорошая, но шаг влево и уже не работает:
Через запятую поддерживается определение переменных только одного типа, а в реальной жизни обычно используется что-то вроде
Мне и так нравится, но возможно кому-то это покажется уродливым.
freecoder_xx Автор
Не знаю как в C#, но в Java с
try-with-resourcesответственность за корректное освобождение ресурсов перекладывается на вызывающую сторону. К тому же не всегда использование ресурсов настолько локализовано, что безошибочное использованиеtry-with-resourcesочевидно.Использование
Cleanerулучшает ситуацию и избавляет от необходимости следить за освобождением в тривиальных случаях, но в более сложных — головной боли не избежать. О проблемах освобождения ресурсов в Java подробно рассказывается в докладе Евгения Козлова "Вы все еще используете finalize()? Тогда мы идем к вам".nin-jin
При чтении текста не озвучиваются знаки препинания, а при посимвольном чтении озвучиваются в том числе и пробельные символы. Тут разве что предпочтительнее для отступов использовать табы, а не пробелы, чтобы не пересчитывать в уме число пробелов в число отступов.
Physmatik
Перепечатайте, чай, руки не отвалятся.
В статьях PVS-studio до половины ошибок — это кривой копипаст: где переменную не переименовали, где + на — сменить забыли, где ещё что-то похожее.
А вот этого просто не понял. В чём там проблема?
inv2004
Меня прежде всего интересует как оно в vscode, всё остальное вторично, если очень надо — надо в web-интерфейс запилить что-то типа плагина из vscode. Зачем дополнительно страдать ради тех кто копирует в чатах не могу понять, хотя большинство чатов уже нормально понимают
Не видно отступы, при этом видно {}? странно, ну да ладно, так как я, человек с плохим зрением, не хочу их расставлять для кого-то кроме себя, а расставлять я их не хочу, хотя когда-то в плюсах я считал это обязательным.
это невалидное выражение при данных сигнатурах, валидное должно быть drop(bar(x)), и это гораздо большая проблема если язык вообще позволяет писать такое, раст и не позволяет, но если считать что; это drop, то зачем мне делать drop на каждый вызов того что и так возвращает ()?
я не очень понимаю как mut может относиться к части pattern
AnthonyMikh
Тут возвращаемое значение деконструируется на
aиb, но только одно имя позволяет значение менять.inv2004
Ок. Признаться за всё время с растом ни разу не делал так. Однако всё равно не готов это сходу отнести маркер мутабельности к паттерн матчингу
freecoder_xx Автор
Можно и не делать. Но
;помимо этого превращает выражение в инструкцию, то есть выступает разделителем инструкций.inv2004
… что можно и не делать (разделять инструкции; ), что доказывают много современных языков. Но вы вроде писали о том как важно помогать парсеру… ценой своего удобства
freecoder_xx Автор
Я писал о том, что точка с запятой не просто разделяет инструкции, она превращает выражение в инструкцию. У вас строка кода может быть как инструкцией, так и выражением, и если нужно последнее — просто не ставьте точку с запятой.
inv2004
Осталось понять как то, что вы написали поможет не ставить бесполезный символ в конце каждой строки, никак не поможет
hello_my_name_is_dany
C# же как-то умеет без деклараций определять переменные и их типы, как в сишном стиле
так и в похожем как у rust, javascript и тд
Так в чём проблема была сделать что-то типа такого:
В общем и целом складывается впечатление, что хотели сделать что-то типа околофункционального ЯП, но в итоге сделали просто, на скорую руку и синтаксис в итоге выглядит так, чтобы его просто легче было парсить, хотя другие ЯП с этим вполне себе справляются (начиная от перегрузок операторов, заканчивая контекстным анализом синтаксиса).
Я пробовал кодить на расте и некоторые моменты мне понравились, но пока язык выглядит сыровато по моим ощущениям. Буду следить за развитием этого языка, потому что из него действительно может получиться хороший инструмент для разработки.
Оффтоп: Всех с наступающим!
Vilaine
Хотели сделать более последовательный и безопасный типизированный императивный ЯП без устаревшего багажа и сделали.
dimaaannn
Очевидно, что зависит от использования.
Если мне нужно создать переменную типа int в шарпе — нет никакого смысла писать
потому что гораздо читабельнее будет
Однако если создаётся какой нибудь
гораздо удобнее и читабельнее написать
Vilaine
Не читабельнее, чем если было бы
Зато есть единственный синтаксис объявления переменной. Сейчас в С-подобных ЯП по сути просто развитие старого невыводящего типы анализатора, с сохранением старого синтаксиса. Поддержка int a; не есть сознательный «сахар» для удобства разработчиков, это на 100% легаси. Посмотрите как делается новый ЯП:
1) На базе Java developer.android.com/kotlin/learn#variables
2) После C# то же самое www.tutorialspoint.com/fsharp/fsharp_variables.htm
Разработчики других новых ЯП принимают точно такие же решение, как и Rust. Потому что добавлять новый синтаксис, чтобы писать на 4 символа меньше — это добровольный отстрел ноги для будущего ЯП.
freecoder_xx Автор
Ну в статье же приведен пример, когда это вызывает проблемы:
Что это, функция или кортеж?
hello_my_name_is_dany
Это кортеж
А вот это функция:
И нет неоднозначности, просто взять приоритет у оператора ->, и уже по контексту понятно, что это аргументы функции, а не кортеж.
PsyHaSTe
Насколько я понимаю, язык помимо прочего стараются делать максимально контекстно-свободным, в том плане что по-возможности каждая конструкция имеет уникальный префикс и мы заране знаем что дальше. То есть не надо откатываться назад и начинать разбор повторно. В вашем случае мы в позиции
let myFunc: (i32, i32)не знаем, есть ли дальше->или нет, и в зависимости от этого трактуем или как функцию, или как кортеж. В языке стараются таких ситуаций не допускать, поэтому например по префиксу fn даже дальше парсить не надо: знаем, что там функция.tyomitch
То, что вы описали, называется LL(1); контекстно-свободный парсинг — это намного более широкий класс.
PsyHaSTe
Верно, спасибо за более точную формулировку
nin-jin
Контекстная свобода — это независимость интерпретации от контекста. Пример контекста — число открытых скобочек. То же, о чём вы говорите, к контекстам не имеет отношения. Разные конструкции с общим префиксом — типичная ситуация. Например:
constиcontinue.PsyHaSTe
Это одна и та же конструкция: в одном случае это будет
Keyword("const"), а в другом —Keyword("continue"). Как будто вы никогда компиляторы не писали...nin-jin
С тем же успехом можно утверждать, что
let myFunc: (i32, i32)парсится вПодобный парсер даже для подсветки синтаксиса не годится.
tyomitch
Именно в такой список и лексится :)
Парсеры в ЯП уже полвека как двухуровневые.
nin-jin
Ага, конечно:
warlock13
А указатель на функцию тогда как? Сейчас там тоже
fn, только как часть типа.freecoder_xx Автор
По моему
Выглядит чище, чем
Во втором случае используется много символов для указания того, что функция ничего не возвращает, и пишем мы их только ради того, чтобы обозначить тип как функцию.
PsyHaSTe
В том что у лямбд в расте уникальный тип, который реализует только общий интерфейс "функция с сигнатурой i32 -> bool".
то есть
Так что отдельный синтаксис для фунок нужен в любом случае
Полагаю это ложное ощущение. По крайней мере после шарпа и тайпскрипта раст воспринимается на ура.
tyomitch
И что в этом хорошего?
PsyHaSTe
Компилятор может их лучше соптимизировать, ведь нет индирекции и виртуализации. Для гц языков это может и не сильно важно, а вот для низкоуровневых С/С++/Раста это важно
AnthonyMikh
Тем, что код функции, вызываемой при вызове замыкания, известен на этапе компиляции и его адрес можно подставить по месту, а потому сам экземпляр замыкания занимает ровно столько памяти, сколько занимают захваченные значения (с поправкой на выравнивания). В частности, если замыкание не захватывает вообще ничего, то оно вообще не занимает места в памяти:
Лямбда-функции в C++, если не ошибаюсь, работают похожим образом.
Mingun
Причина не в этом. Лямбды захватывают контекст, который тоже является частью типа. Если контекст не захватывать, то тип одинаковый и все компилируется.
AnthonyMikh
Ваш пример компилируется в силу того, что обе лямбды неявно приводятся к функциональным указателям, что возможно в силу того, что они не захватывают контекст:
Mingun
Не знаю, спорить не буду, но что-то я сомневаюсь, что типы так приводятся. Все же в Rust довольно строгая система типов, автоприведения в большинстве случаев нет.
0xd34df00d
Надо сделать как в
джаваскриптеплюсах, где+[](){}имеет типvoid (*)()(там как раз плюсик делает из лямбды указатель на функцию).AnthonyMikh
А чего сомневаться-то, просто укажем заведомо неверный тип:
И компилятор всё сразу скажет:
Заметьте, никаких
[closure@main.rs:2:12]PsyHaSTe
В данном случае оно есть, и можно видеть что код компилируется. Потому что индивидуальные типы компилируются только для замыканий, которые захватывают переменные, а все функции без замкнутого окружения в пределах одной сигнатуры разделяют один тип.
Как видно, в отличие от замыканий у них один-единственный (и называемый) тип.
AnthonyMikh
… Если их тем или иным способом привести к функциональному указателю, что ты и сделал. Так-то это всё-таки разные типы:
freecoder_xx Автор
Да! Но можно было показать проще:
vanxant
Предлагаю Boomburum ввести с Нового года такое правило, что статья со знаком вопроса в названии должна содержать опрос. Иначе это тухлый кликбейт, как здесь.
Пока что придётся довольствоваться опросом при нажатии на кнопку «минус», но там закрытый список вариантов.
nin-jin
Вы слышали когда-нибудь про риторические вопросы?
tyomitch
Меня всегда забавляло, что заголовки с ! в конце запрещены, но это не помешало мне пять лет назад запостить habr.com/ru/post/388505 поставив ZWNJ после !
0xd34df00d
Я тут подумываю написать статью с рабочим названием «Что в доказательстве?» с описанием вопросов интерпретации формальных доказательств. Какой опрос вы бы хотели там видеть?
AnthonyMikh
Я чувствую рунглиш.
0xd34df00d
Я где-то уже писал, что стилистика начинает страдать, да.
vanxant
qed и не-qed )
AstraVlad
После вот этого:
я сам написал бы про такой язык что-нибудь токсичное…
freecoder_xx Автор
Какую проблему вы видите в этом коде?
adjachenko
Ответ довольно таки однозначен, но также очевидно вы либо не знакомы с с/с++ либо не считаете это проблемой. В с/с++ (а может и в других языках тоже) строка message; гарантированно НИЧЕГО не делает и будет удалена компилятором тогда как в расте это скрытый дроп. Вот разница в ожидаемом поведение и реальностью и есть проблема. Так уж случилось что с/с++ появились существенно раньше раста и сформировали семантику ожидаемого поведения для тех кто знакомиться с растом и имеет сишный опыт. Появись раст раньше си тогда бы сишное поведение вызывало заслуженный вопрос — чё за нах.
phtaran
можете объяснить? Что за скрытый дроп.
ошибка потому что владение ушло к кому-то другому, но к кому?
*картинка с пилотом*
vlad9486
Просто ушло. К кому-то без имени, а значит и без возможности обратиться. В потусторонний мир.
Fenex
Можете думать что это сокращение от:
Владение ресурсом переходит к переменной `_`, и далее обращение к `message` недопустимо (с оговоркой что `message` не реализует Copy).
ZyXI
Это не переменная: попробуйте скомпилировать
Сразу видно, что
_s— переменная, а_— нет.Ещё где-то на Rust’овских форумах где-то было обсуждение по поводу того, что
let _ = fooприводит к немедленному освобождениюfoo, а сохранение в неиспользуемую переменную — к освобождению по выходу из контекста, из-за чего что-то работало неправильно.freecoder_xx Автор
Да,
_— это ключевое слово, а не переменная, которое означает "игнорировать связывание в этом месте".tzlom
Если это плохо- то скажите как получить подобное поведение в С++? В плюсах невозможно отметить переменную убитой на произвольной строке (фигурные скобки не обеспечивают всех инвариантов), так что вот типичный use after free: delete(message); print(messsage); с которым в общем виде не возможно бороться в C++
adjachenko
В с++ это невыразимо. Есть предложение сделать дестрактив мув, но там все сложно и с учётом пандемии я лично считаю что раньше с++3х это не случится. В комитете не считают это проблемой которую целесообразно фиксить в языке и перекладывают это на статические анализаторы.
mayorovp
Независимо от того, делает ли строка
message;хоть что-то или является скрытым дропом — ей не место в нормальном коде.freecoder_xx Автор
message;— просто частный пример для иллюстрации того, что происходит. В реальном коде будетfoo();с дропом в этом месте значения, которое вернулаfoo, который может приводить к побочным эффектом, в случае кастомизацииDrop'а этого значения.mayorovp
Но если там будет
foo(message);с дропом этого значения, то никак не вина языка в том, что компилятор отловил ошибку. Именно поэтому хейтеры и приводят искусственные примеры сmessage;, которые в реальном коде никогда не встретятся...adjachenko
Ну это всего лишь ваше мнение, я прекрасно могу представить что такой код может появиться в раст для оптимизации, например закрыть файл раньше чем завершится скоуп где обьявленна файловая переменная. drop(file); банально сложнее набирать. У меня лично персональная ненависть к скобкам и я бы точно предпочел file;
Mingun
Зато проще читать. А вот у меня бы точно возник бы вопрос, что делает такая сиротливая строчка и не нужно ли ее удалить.
0xd34df00d
Это смотря какой код в C++. Смотрите, компилятор убрал неиспользуемый объект, но эффект от него остался. Я бы
std::stringиспользовал, но там будет в дизасме слишком много мусора.В любом случае, в расте это ошибка компиляции, что делает проблему на порядки более неважной.
adjachenko
Я точно знаю, что вы отлично разбираетесь в с++, но в вашем примере я аналог message; не нашел вместо этого вы иллюстрируете побочный эффект мува что совершенно точно не тоже самое. Я думаю вы просто уже подзабыли из за долгово неиспользования с++ что единственная разумная причина такого кода на с++ это подавление ворнинга о неиспользуемой переменной. Есть 100500 макросов которые генерируют именно такой код — переменная; #define unused(x) x; Смысл в том что семантика раста в этом случае это дестрактив мув которого нет в с++, но это и есть проблема т.к. в с это просто ничего.
0xd34df00d
Речь лишь о том, что выкидываемые оптимизатором сущности всё равно влияют на семантику программы. Собственно, где-то рядом вам тут уже написали, что
message;стоит читать какlet _ = message;.Никогда не считал это разумным способом. Есть неиспользуемая переменная — удалите её (если это локальная переменная) или уберите её имя в определении функции (если это параметр).
adjachenko
есть такой атрибут [[nodiscard]]. И вот какой нибудь очень талантливый человек решил, что он точно знает, что вот ни в коем случае нельзя игнорировать возвращаемое значение, но вы с ним почему то не согласны. Как предлагаете решать такое противоречие в проекте где ворнинги это ошибка? Что насчёт условной компиляции, где для одной платформы переменная используется, а для другой — нет?
tyomitch
adjachenko
а что насчёт MSVC/clang? у меня на работе все три в одном проекте используются. Да, конечно, это решение, но сравните сколько усилий требуется, что бы заглушить варнинг для 3 компиляторов с помощью прагм и просто написав имя переменной с точкой запятой.
PsyHaSTe
Так и пример с точкой запятой немного надуманный, на практике будет
drop(resourse);. Чуть длиннее, зато не надо ломать голову над тем, почему так написано.adjachenko
Я вообще и начал с ответа на вопрос почему это проблема, т.к. в с/с++ всем все понятно почему так написано, и что такой код ничего не делает на с/с++ и НЕ МЕНЯЕТ СЕМАНТИКУ это буквально хак который заставляет компилятор заткнутся и не ругаться, что переменная не используется, т.к. она формально используется.
Тогда как на расте это совсем другой код и смысл претензии в том что, раст заимствует синтаксис из с да ещё и по возможности с той же семантикой, что бы больше людей быстрее научилось понимать раст, а тут такое дело что; и конкретно очень распространённый хак на с имеет совсем другую семантику в расте ставя под сомнение обоснованность заимствования; т.к. это не помогает понять, а наоборот мешает.
Да, я вижу люди утверждают, что такой код на расте плохой/не идиоматичный, другие добавляют, что он и на с/с++ тоже смысла не имеет. Вот с этим спорю уже я — на с/с++ он имеет смысл и встречается довольно часто, т.к. альтернатива синтаксически ещё хуже. На расте я лично тоже вижу в нем смысл и предпочел бы его явному дропу, потому что так короче — это моё персональное предпочтение чем короче тем почти всегда лучше.
Если уж у меня была возможность это поменять я бы смотрел в сторону оператора — destructive move. Ну например как то так
читается как переместить содержимое message в пустую переменную == дропнуть месседж. С таким синтаксисом было бы сложнее сделать ошибку вида
Вместо того что бы втихую игнорить возвращаемое значение компилятор бы ругался, требуя либо объявить переменную
x = foo(message)
либо явно дропнуть ее
= foo(message)
Да, я признаю что это тоже не идеальное решение, т.к. другим людям может быть не важно игнорируется возвращаемое значение или нет, а вот лишний знак равно придётся писать. Но я там на верхнем уровне оставил комментарий, что есть другой путь где и писать = не нужно, но при этом при чтении = будет явно присутствовать. Смотри habr.com/ru/post/532660/?reply_to=22488134#comment_22488090
PsyHaSTe
Думаю раст не ругается на это для случаев вроде такого:
с вашими правилами получается, что компилятор будет требовать
что конечно тоже возможно, но наверное не очень полезно для нас как программистов.
Вот это "не важно игнорируется возвращаемое значение или нет" на самом деле довольно часто именно так и есть, для случаев когда возвращаемое значение игнорировать не стоит есть атрибут, который на подобное использование выдаст варнинг "меня забыли использовать". Но в подавляющем числе случаев если такой пометки нет то "вернулось и дропнулось, а нам пофиг" — самый частый сценарий такой операции.
adjachenko
С моим видением дизайна ЯП/компилятора вам НЕ потребуется писать ничего лишнего если вы игнорите возвращаемое значение и в зависимости от ваших предпочтений вы можете видеть или НЕ видеть этот синтаксис при чтении кода как пожелаете. Т.е. для меня это было бы так:
набираю в IDE: foo(message)
IDE авто заменяет на: = foo(message)
я такой, о точно забыл обработать значение, и дописываю
x = foo(message)
или да все правильно мне пох в этом случае на возврат значения
brom_portret
Странное дело, в начале вы говорите что обязательное использование фигурных скобок это хорошо, так как исключает ошибку. Тут я с вами согласен, лет пять назад пришел к тому же, и с тех пор не пишу конструкции типа
if (foo)
bar()
Но следом вы рассказываете про точку с запятой и приводите следующий пример
if x < 42 {
foo(x);
} else {
bar(x)
}
Помоему это ужасно.
Я представил сиутацию когда мне нужно найти ошибку в чужом коде и я встречаю подобную конструкциию. Как мне понять, что хотел сделать автор? Намеряна ли пропущена; после bar() и намерянно ли она есть поcле foo()? Как мне понять без реверсинга всей относящейся логики что тут нет опечатки?
В общем двойственное ощущение, с одной стороны хотят чтобы кодеры по меньше делали ошибок, а с другой изначально закладывают синтаксис, который способствуют ошибкам.
mayorovp
К счастью, поведение кода от наличия точки с запятой после
bar(x)не меняется (при условии, что оба варианта компилируются). Так что подобный странный код можно просто не писать...freecoder_xx Автор
Если данный код скомпилировался (или прошел
check), то вы точно знаете, чтоbarвозвращает(), так как другая ветка условия возвращает именно это значение благодаря;, а типы значений веток обязательно должны совпадать.Этот пример просто для иллюстрации данного факта, так лучше не писать. Хотя в реальном продакшн-коде я часто замечаю пропущенную точку с запятой в похожих ситуациях, когда поставить забыли или не захотели, но еще ни разу это не привело ни к какой проблеме понимания кода или к какой-то иной ошибке.
PsyHaSTe
Просто
bar(x)возвращает () иbar(x);возвращает его же. Можно писать а можно нет, это не ошибка любом случае: семантика обеих записей совпадает. Я для симметрии всегда пишуphtaran
а есть примеры где это даёт более явный выигрыш? Экономия одного слова это мелочь и не прям супер выигрыш и возможно это вкусовщина. Скажем я бы предпочел увидеть явный оператор возврата, чтобы не угадывать по флоу какое выражение было вычислено последним, подозреваю что это «последнее вычисленное выражение» (по опыту с groovy) может являться источником неясности и потенциалом для выстрела в ногу. В общем эта экономия выглядит как-то сомнительно. Также выходит что в одних местах оправдывается многословие как необходимое, а в других оправдывается срезание синтаксиса «для выразительности»
скажем Python достаточно выразительный язык, но там не стали экономить на return
это цитата не автора статьи, но как же смешны подобные рассуждения про «надо просто мозгом думать». Вот если бы все так и рассуждали, про язык, потом про библиотеки, потом про архитектуры с этой мантрой «надо просто мозгом думать» («я тут наархитектурил, а если ты не понял то ты тупой или ленивый») то немного бы мы так написали полезного софта. Кроме языка и так много о чем надо думать, язык это самый нижний слой, это просто инструмент. Представьте себе если бы человеческие автоматизмы не работали и надо было бы осознанно думать как ходить, как переставлять одну ногу, потом другую, потом как дышать, как делать вдох, потом как выдох и тд. Надеюсь аналогия понятна.
mayorovp
Любые лямбды. В выражении
|x| { return x + 1; }слово return визуально занимает половину пространства (пусть по символам и выходит "всего-то" 6 из 20). А такие выражения приходится писать довольно часто.freecoder_xx Автор
Можете уточнить, в каких ситуациях это составляет проблему? Просто посмотреть на последнюю строчку в теле функции.
returnоправдывается как многословный потому, что он может встретиться в любой строчке внутри функции, вам его придется искать и вы должны хорошо его видеть, ибо он меняет поток выполнения программы. А вот в последней строчке он не нужен, так как явно или неявно присутствует там всегда (в Rust нет процедур) и поток выполнения там он не меняет.Что же касается просто блоков, то там вообще оказывается не применим
return, потому что это именно оператор возврата из функции, а не из текущего блока. Поэтому в блоках можно возвращать только последнее выражение.phtaran
аа, теперь я понял. А если в конце функции в последнем выражении поставить точку с запятой то это уничтожит значение? Я сужу по прошлому обсуждению и выглядит так что точка с запятой вызывает drop
откомменчу тут же и это
эта экономия имеет смысл для коротких и однострочных лямбд. Но в других языках, хотя бы некоторых (даже вербозной джаве) однострочные лямбды не требуют return а многострочные требуют. По-моему вполне нормально.
AnthonyMikh
Да, но у вас так код почти наверняка не скомпилируется.
mayorovp
Да, уничтожит, но в подавляющем большинстве случаев именно это и требуется.
PsyHaSTe
Вопрос единообразия. Ретурн не нужен в лямбдах, однострочных функциях, ифах и так далее. Это просто вопрос консистентности.
freecoder_xx Автор
Уничтожит, но вы получите ошибку компиляции, если типы возврата не совпадут:
AnthonyMikh
Вот явных примеров я не покажу, но по опыту могу сказать, что код на Rust из-за этого читать проще, потому что явный
return— это теперь всегда именно ранний возврат.Получи возможность забыть написать
returnи получитьNoneв качестве возвращаемого значения вместо того, что было вычислено. И да, мне кажется, называть выразительным язык, в котором лямбды в принципе не могу больше одной строчки занимать — это немного смешно.AcckiyGerman
Зато в очень выразительном, например, JS, где лямбда в лямбде и лямбдой погоняет, очень интересно разбирать по десять подряд анонимных функций в стеке исключения.
Да, это проблема в динамически типизируемом языке, но в расте такая ошибка всплыла бы на этапе компиляции.
Mingun
Отсутствие явного
returnдля выхода из функции действительно можно считать за плохой тон, поначалу. Например, задумавшись, как грепать места возврата из функции… Я для себя решил, что всегда буду писатьreturn, ибо нефиг...Но оказалось, что его опускание как-то само-собой получается, дискомфорта не испытываю. Можно сказать, что при отсутствии явного ключевого слова также стараешься делать функции поменьше, чтобы с первого взгляда было видно, где у нас возврат. А фактически, возврат из функции где-то в середине ее тела без явного ключевого слова возможен только при использовании больших
if/match, а иначе в середине естественным образом появляются этиreturn.И я говорю не только за свой код — читая код стандартной библиотеки и других проектов (serde) тоже замечаю, что даже без наличия
returnчитаемость не страдаетphtaran
ну скажем я когда читаю функцию, я читаю логику, и в конце я вижу что она возвращает. Если функция ничего не возвращает то мне надо смотреть или на начало где указано что возвращается, либо смотреть на точку с запятой последнего оператора чтобы понять что скажем эта функция ничего не возвращает?
А если скажем есть блок if… else if… else и в каждом из этих ветвлений есть по 4-5 команд, то мне надо искать глазами последнюю в каждом из блоков чтобы понять что пойдёт в ретурн?
PsyHaSTe
так а блоки из функции сами по себе никогда не возвращаются. Возвращает только последняя строчка. Если же в последней написано:
То вроде и не надо напрягаться, чтобы понять, что пойдет в ретурн.
tyomitch
Это если в каждой ветке по одной строке, а не по два экрана кода.
PsyHaSTe
Даже если там по 2 экрана кода, смотреть надо на последнюю строчку из этих экранов. А вообще — рефакторинг, экстракт метод и вот это все спасут отца русской демократии. На практике (а не при теоретизированнии в комментах) могу сказать, что опускание ретурна очень удобно. Регулярно этим пользуюсь.
Mingun
Вот я и говорю, что как-то само собой получается, что 2 экрана не выходит. Естественно, если будет получатся 2 экрана, то я задумаюсь о выделении в отдельную функцию (почти наверняка) или добавлю ключевое слово (хотя наверняка это будет из-за желания уменьшить количество отступов в первую очередь). Но вот говорю как есть — пока такого в моей практике не встречалось.
freecoder_xx Автор
Соглашусь, что иногда
returnудобно использовать, чтобы сократить количество вложенных блоков и улучшить читаемость. Хотя во многих других случаях лучше без него.swelf
Ну в теории, с return ты ищешь ключевое слово return, а в случае в растом надо весь код читать, смотреть где есть if else, match и и тп. а если там в качестве выражения цепочка filter map find так глаз еще и замылиться может, есть ли там вобще точка с запятой.
AnthonyMikh
Как человек, который пишет на Rust по работе, могу сказать, что это проблема надумана.
phtaran
я пока так из этой ветки не понял как понять что метод что-то НЕ возвращает, мне смотреть на сигнатуру или искать глазами точку с запятой?
тогда получается что опускание ретурнов дополнительно отягощает другие проблемы.
Сейчас мне приходится иметь дело с большими объёмами не очень красивого кода, в том числе с длинными методами и блоками. В моём случае опускание return усугубило бы ситуацию. И исправить положение рефакторингом я не могу т.к. «нельзя просто взять и отрефакторить», как вы сказали, десятки тысяч строк кода. Мне даже никто не даст это сделать, т.к. это время и деньги. Т.е. мне приходится читать то что другие написали «как им было удобно писать» (улавливаете иронию ситуации?)
PsyHaSTe
Метод не может ничего не возвращать, просто иногда он возвращает юнит-тип — тип с единственным значением. По некоторому недоразумению кастрированный юнит в си-лайк языках носит название
void. Кастрированный в том плане, что ни в переменную его не сохранишь, ни аргументом явно не передашь (хотя как раз в ANSI C вроде можно, но в последующих языках уже нет)По-моему опыту функции в 2 экрана возникают не из-за ретурнов, и ретурны никак с ними не помогут.
phtaran
конечно это верно, но я говорю о том что опускание return добрасывает еще одну какашку сверху этого беспорядка. И это часто нельзя решить рефакторингом, т.к. нельзя же рефакторить абсолютно всё что читаешь (именно читаешь, а не пишешь), это могут быть десятки тысяч строк кода. Есть разница между «так удобно писать» и «так удобно читать». Профессионалы тем и отличаются, что пишут код не на любителя, а такой в котором смогут разобраться и читать без боли все или хотя бы большинство.
а для чего это может понадобиться?
PsyHaSTe
Кто сказал что это какашка? У меня вот мнение, что это наоборот шоколадка. Кто прав?
Что во что рефакторить, отсутствие ретурна в его присутствие? Добавление необязательных элементов (вроде скобок там, где их можно опустить) я за рефакторинг бы не стал считать.
Причудливые особенности которые используются в каждом первом ML языке? Ну простите, это скорее не особенности, а синдром утенка у некоторых людей. Которые когда говорят "я знаю много языков" оказывается имеют в виду "Си, Сишарп, Сиплюсплюс, джава, джаваскрипт". В итоге думают, что у них кругозор огого, а на самом деле они просто с разных сторон неплохо знают сишку.
На прошлой неделе мне пришлось разбираться в целой подсистеме, которая написана на… %langname%. «О привет, путник пожаловавший в наш сервис.
Оно работает точно так же как и в любом другом языке. Точка запятой — разделитель, возвращаемое значение — юнит тайп, в сишке это
void. В чем различие с другими сишными языками-то?phtaran
eсли есть крупные блоки ветвлений, неудобно отслеживать возврат в 3-5 пунктах, 1 точку проще. (мне проще, ну может я странный, да)
я говорю о том что невозможно рефакторить весь код который плохо читается. Даже если это минорные изменения, которые вы не считаете за рефакторинг, чтобы поменять это, придётся делать много пулл реквестов и проходить ревью (в крупных проектах это долго)
если вы про предвзятость, то она есть у всех. Этот аргумент работает в обе стороны, старшие часто более консерватины, а молодые слишком падки на всё новое. Если Rust не может убедить программистов с багажом, тогда придётся ему ждать поколение без сишки. Надо только продержаться до этого времени. Убедить программистов с багажом помогло бы отсутствие причудливых специфичных решений. Даже эта статья называется «Так ли токсичен синтаксис Rust?». На воре и шапка горит
tyomitch
Ниже PsyHaSTe процитировал заметку Эрика Липперта, что это очень сложный trade-off: если в языке слишком много причудливых специфичных решений, то на него слишком сложно переходить; если слишком много легаси — то на него нет смысла переходить.
По-моему, в C# очень удачный баланс между легаси и новизной, даже если бы могло быть и лучше. F# и прочие попытки выбросить из языка легаси — переманили в свои ряды совсем небольшую долю программистов. С другого конца спектра можно вспомнить мертворождённую J#.
PsyHaSTe
Покажите пример, а то без примера непонятно. Вот сколько на расте пишу, не помню чтобы с этим были какие-то проблемы.
Так как раз код с ретурнами читается плохо, а без них — лучше.
Просто некоторым нужна более быстрая лошадь, а автомобиль они ругают за то что у них посадка другая и седло не накинешь. Что поделать, некоторым непонтяно, что сделать лошадь которая будет бежать 200км/ч нереально, и "что-то нужно менять" чтобы это стало возможным.
Абсолютно верно
phtaran
чтобы показать пример, мне нужно придумывать полотна кода. Если я вставлю просто троеточия то вы скажете «ну и в чем проблема, я прекрасно вижу точки возврата?». В реале глаз будет более замылен и блоки тоже могут быть больше.
ну пусть.
этот код можно улучшить если завести переменную result и указать её в конце функции. Только мне надо смотреть на то нет стоит ли там точка с запятой чтоб понять возвращает что-то функция или нет — после этого полотна кода я могу уже не помнить сигнатуру функции. Раньше я бы смотрел на return, теперь надо смотреть на менее заметную точку с запятой
ну одно дело когда это стал автомобиль, а другое если у лошади убрали седло и натянули его на копыта, а копыта вставили в хвост
если раньше мне приходилось смотреть на return то теперь надо смотреть не подавляется ли возврат. В чем тут инновация?
мы кажется ходим по кругу. Мы выше уже осуждали это. Я назвал почему это плохо (для меня), вы сказали потом что можно легко отрефакторить. Дальше я сказал что это не так легко, и вы вернулись к началу — что и так хорошо.
я в целом озвучил что хотел, я не смогу убедить вас, а вы меня. С наступившим! :)
mayorovp
Один вопрос, а нахрена писать такой код, как вы показали?
tyomitch
ИРЛ чаще, чем хотелось бы, приходится иметь дело с кодом, вызывающим точно такой же вопрос.
PsyHaSTe
во-первых ретурны этому коду не помогут никак. Он просто плох как есть
во-вторых "подавить точкой с запятой" у вас ничего не выйдет, потому что компилятор пожалуется что не все ветви кода возвразщают значение.
Этот код можно улучшить с помощью рефакторинга "экстракт метода" а также опционально "замена условного ветвления полиморфизмом" (всё по Фаулеру, ага). И тогда будет:
Или даже с ретурнами (раст их не запрещает если что, я все время ими пользуюсь для того чтобы happy path был линеен):
Не надо никуда смотреть, подавить что-то случайно чтобы оно скомпилировалось не выйдет. Это просто короткая запись для
drop(expr), вместо этого можно писать простоexpr;. Дропнуть что не нужно у вас просто не выйдет.phtaran
я говорю о ЧТЕНИИ кода
про рефакторинг это уже 3-й круг, я уже писал об этом.
я как бы не призывал такой код писать. Но вот читать мне подобный код нередко приходится. Когда (и если) Rust станет мейнстримом, выпейте за меня бокальчик когда увидите такой же плохой код на Rust ))
вот-вот, я примерно это и имею в виду
PsyHaSTe
Ну вот нет никаких проблем при чтении
Этот код плох не из-за ретурнов, и что есть ретурны что нет разницы никакой не будет.
сишарп был хорош до +- 5 версии, а стех пор он только сахаром обрастает, а полезных фичей раз-два и обчелся за все последние 5 лет :(
phtaran
меня язык вполне устроил бы, вопрос больше в экосистеме — мне кажется с# заточен на MS экосистему. Net core вроде как постепенно меняет ситуацию, но скажем навскидку Google App Engine саппортит c# хуже чем java. Если в докер запаковать то наверняка получится работать в Kubernetes и тд. Что там ещё с другими тулами, скажем драйверами субд и тд, вот это всё — я глубоко не вникал, если кто-то скажет что сейчас там всё круто то я только за.
а как язык с# меня устроил бы и 3 года назад
0xd34df00d
Для обобщённого программирования. Непосредственно в C это не нужно, а в плюсах бывает полезно написать что-то вроде (очень упрощая)
Сегодня так делать нельзя, для
T = voidнадо писать специализацию.DistortNeo
Да и в switch штука полезная будет.
freecoder_xx Автор
Смотреть на сигнатуру. В любом случае лучше всегда на нее смотреть, зачастую этого уже достаточно.
AnthonyMikh
На сигнатуру, конечно, типы не врут.
FDsagizi
код на Rust оч экономит ресурсы мозга, тк проще парсить.
nin-jin
Нет, отступ случайным быть не может, ибо человек ориентируется именно на него. Бардак с отступами может быть лишь у человека, привыкшего к тому, что отступы можно ставить абы как.
И после этого вы ещё что-то говорите про лаконичность. Писать 3 строки вместо 1 — это верх расточительства. С отступами было бы 2 — разумный компромис между лаконичностью и дебагом/трейсами.
А чего это одни скобочки можно убирать, а другие нет? Почему бы все скобки не сделать опциональными, требуя их лишь для сложных выражений?
О, а тут почему они опциональны вдруг, а скобки вокруг аргументов — нет?
Во многих языках они "очень важны" и используются для задания вложенных скоупов для переменных. Даже в сях.
Думаю лучше явно игнорировать возвращаемое значение, чем делать это неявно, случайно написав точку с запятой как и везде.
Discriminated Union есть и в стат типизированных языках. И они позволяют возвращать значения разных типов, а не только одного пустого.
А может не стоило оставлять WTF в языке? Достаточно было бы предоставить функцию drop, которая бы принимала любое значение и ничего не возвращала. А на бессмысленном коде в духе
a;лучше кидать ошибку.Разработчики Раста настолько суровые, что не хотят, чтобы программирование на их языке вызывало коннотации с весельем?
Язык, полный сокращений, приучает программистов тоже сокращать. Теория разбитых окон, все дела.
Вообще не очень очевидно, почему функции и замыкания имеют совсем разный синтаксис. Особенно глядя на D, где замыкания выглядят как и объявления функций, только без имени:
Опять же, D замечательно всё различает, хоть и использует везде точки.
Так может не надо было лепить угловые скобки? Опять же, в D используются вообще круглые скобки.
amarao
не согласен. Смотрите, питон, который считается образцом readability, тоже использует def вместо define. Почему? Потому что короткое служебное слово лучше длинного.
А вот замену
andна&&иorна||, да ещё и с омонимией объявления closures, я считаю большой эстетической ошибкой в Rust.nin-jin
Когда-то и земля плоской считалась. С читаемостью у него всё довольно плохо на самом деле.
tyomitch
А где хорошо?
0xd34df00d
Где нас нет.
Все языки отстой, на самом деле.
tyomitch
Если всюду плохо, это не значит, что всюду в равной степени плохо.
nin-jin
Место вакантно, дерзайте.
amarao
У Питона очень высокая читаемость на фоне других языков программирования. Вы можете не понимать всех бездн манкипатчинга и интроспекции собственного стека для полифорфизма, но в целом, открыв исходник на python человек с плохим пониманием понимает, что там происходит куда лучше, чем у большинства языков.
Понятно, что в питоне есть свой хитрый мунскпик. Какой-нибудь там
[x(**y) for x, y in foo(*bar)]вызовет боль даже у опытного питониста, но обычные выражения — одни из самых читаемых, которые я видел в индустрии.AnthonyMikh
А я не понимаю. Потому что совершенно непонятно, что за сущности принимаются и возвращаются, и для того, чтобы это понять, приходится изучать контекст.
Vilaine
По отзывам, тайпхинты в Python (e.g.
def run(input: Input) -> bool) начинают проставлять для более простого вхождения в код разработчиков со стороны. То есть типы используются исключительно, чтобы улучшить читаемость, ни о какой корректности пока не ведётся речь (но когда везде проставлены, то нет смысла не включать анализатор).AnthonyMikh
О, то есть мы сначала объявляем типы ненужными и проверяем их в рантайме, а потом таки ставим хинты, которые ни на что не влияют и которые нужно проверять сторонним инструментом! Фантастическая рациональность.
Vilaine
Посмотрите, когда появились все такие ЯП. В 90-х годах была восторженная уверенность, что динамические интерпретируемые языки упростят разработку, т.к. о типах больше не надо будет задумываться. Роберт Мартин с тех и до сих пор на таком настаивает, с юнит-тестами для гарантий контрактов. Но индустрия в этом, по-видимому, уже разочаровалась и двигается в другом направлении.
Хинты появились в питоне в 2010-х, хотя мышление основной массы разработчиков пока инертно. Но, тем не менее, вышеупомянутая мотивация имеет место.
PsyHaSTe
Речь о том, что сначала объявили типы "устаревшими", которые "ограничивают программиста", а потом в течение пары десятков лет наткыкались на детские "внезапно вместо числа пришла строка", которые сначала лечатся какими-нибудь дикими правилами приведения, а потом выработали практики как этого не допустить, и в итоге приходим к тому, что типы-то оказывается не такие уж бесполезные были.
Vilaine
По моему опыту проблемы «внезапно вместо числа пришла строка» в реальной практике не существует. 80% проблем — это плохая работа с Option/Maybe. При этом оно встроено в дизайн некоторых ЯП неисправимым образом (Java, C#). Поэтому с динамическими ЯП, где статанализ навешан сверху и сильно потом, мне было в каком-то роде проще роде работать — основная проблема не была повторена.
Потом идут последствия рефакторинга — IDE практически беспомощны без тайпхинтов, надежда после любого изменения контрактов только на полноту юнит-тестов, которая не может быть формально гарантирована.
Далее следуют ошибки, когда разработчик опирается на интерфейс структуры без каких-либо оснований, например, ошибки динамического/ad-hoc диспатча, недоконвертация внешних данных во внутренние структуры, и т.п.
Про то, что можно словить проблемы при type juggling я знаю только теоретически. Да, практики порешали, но эти практики (в основном hexagonal arch & clean code) имеют смысл и безотносительно типов.
PsyHaSTe
Да-да, именно поэтому если к какой-либо ЖС либе нет документации то воспользоваться ей тупо невозможно. Сидишь по сорцам пытаешься понять, какую форму должен иметь объект. И оказывается, что если вместо 12 передавать "12" то всё чудесным образом начинает работать.
Vilaine
Ну ок, у нас разный опыт и разная статистика. Я, честно говоря, не могу писать код на Javascript, не хватает интеллектуальных способностей и терпения. Поэтому в динамических ЯП существенно опираюсь на PHP, Python и в меньшей степени Javascript.
PsyHaSTe
во-первых && и || привычнее родному сишному глазу
во-вторых все остальные операторы std::ops именно что операторы. Делать исключение для булеанов, да при том что & и | как бинарные операторы на тех же булках никуда не денешь, хотя бы ради сокращенной записи x &= bar; y |= baz, наверное было бы плохой идеей. Тем более что or/and различной длины, а && и || — одинаковой. Важно когда пишешь ёлочку условий, с красивым форматированием оно оказывается выровненным друг с другом.
tyomitch
Вполне возможно иметь и &&/||, и and/or, как в PHP и в Perl.
PsyHaSTe
Так в расте так и работает для всех операторов, кроме именно этих. Комментарий в документации объясняет, почему так:
0xd34df00d
… и в C++.
amarao
Семантически они странные. Что такое "ИИ" "ИЛИИЛИ"? В Си оно имело смысл в рамках локального птичьего языка (++a+++++b--), в Rust осталась только += форма (как более разумная), так что сделать && и || в and и or было бы разумно. Заодно было бы понятно, что это не арифметические выражения, а логические. То же касается и not. Минус омонимия (с макросами и divergence в типах), плюс читаемость, плюс явное указание на то, что "это не оверлоадится".
PsyHaSTe
ИИ\ИЛИИЛИ — это сокращённые формы И/ИЛИ, работающие с short circuit, к которым за время существования С все привыкли
amarao
Все — это кто? Люди, привыкшие, что у них UB на каждой второй строчке? При всём уважении, так себе аргумент. Они же привыкли ++ писать и кастить void* к нужному типу из malloc'а.
and, or и not как указание на логику, а не биты — очень разумно. Замечу, что '!' в расте зачем-то перегружаемый и вызывает wtf, потому что
let x: bool = !true — это false,
а let x: u8 = !1 — это 0xFE
А true! — это макрос.
Визуальная дрожь, которая отсутствовала, если бы у нас был not для логических операций.
PsyHaSTe
С++/C#/Java/JS — Достаточный перечень языков, чтобы выбрать такую запись.
DistortNeo
Так в этих языках разделение как раз имеется:
!— это логическое отрицание,~— побитовое дополнение. Отличие же от Раста в том, что в Расте строгая типизация — нет неявного приведения произвольных выражений к логическому типу, поэтому и нет необходимости в двух разных операторах.nin-jin
Представьте себе кастомный тип в котором необходимо поддержать обе операции: и отрицание, и дополнение. Например — значение четырёхзначной логики. Подход, где на один оператор навешивается несколько разных семантик этому, очевидно, мешает.
ZyXI
Вообще, если рассматривать
boolкакu1, то никаких разных семантик нет. Кроме того, подход, когда операторов слишком много, делает изучение языка и чтение программ ещё сложнее.Если вам очень нужны дополнительные операторы, то для их реализации всегда можно использовать макросы. По крайней мере, так тот, кто будет читать программу, будет знать, что значение дополнительных операторов нужно начинать искать в документации на присутствующий в коде макрос. А вы сами дважды подумаете, нужно ли вам заморачиваться с не слишком лёгкими в реализации макросами, или вам достаточно будет функций.
PsyHaSTe
На самом деле возможность введения произвольных операторов (а точнее возможность использовать функции в инфиксной форме и разрешение им состоять не только из букв и цифр) была бы очень полезна. Но не думаю что в расте это когда-либо сделают.
amarao
Писать полезно, читать уже не очень. Читаемость кода — это важно. Иногда даже важнее, чем удобство писателя.
nin-jin
А если натуральные числа хранить как строку в единичной системе счисления, то вместо оператора сложения можно использовать конкатенацию и никаких разных семантик нет.
ZyXI
boolвообще-то уже хранится какu1, с довеском из семи бит, всегда равных нулю, существующим исключительно по технических причинам. А вот единичную систему счисления для чисел почему-то не используют.0xd34df00d
Вполне себе используют. Вот я прям сейчас в соседнем окне использую.
PsyHaSTe
А где-то бул и как 4(8) байт хранится
tyomitch
На архитектурах, где чтение байта с адреса, не кратного слову, медленнее — это вполне логично.
amarao
Я только что написал в своём пет-проекте контр-пример, который мне очень не понравится.
Вот этот
assert!(!очень шумный.DistortNeo
Если оно выделено разными цветами, то вообще не напрягает.
amarao
Вы не можете иметь подсветку синтакиса всюду. Визуально перегрузка восклицательного знака — шумно. Я вообще не могу понять что имели в виду '!' для макроса. Что оно требует внимания? Почему? Для '!' как неравенства есть хотя бы визуальная аллюзия на ¬, да и! используется не только в языках программирования (вроде бы).
А для макроса-то за что?
PsyHaSTe
Предложите свой символ для макроса, чтобы было видно, что это макрос, а не просто функция
DistortNeo
Ага, вон в C/C++ макросы вообще никак не отличаются от обычных идентификаторов и не имеют ограчений по области видимости. А потом приходится искать причины, почему это проект не компилируется после подключения какой-нибудь библиотеки (и это касается даже стандартной библиотеки).
nin-jin
m@cro
0xd34df00d
Предлагаю ставить доллар в начале имён макросов.
tyomitch
Вот обрадуются-то пехапешники
0xd34df00d
Вы раскусили попытку их привлечь.
amarao
Моё чувство прекрасного говорит, что из всех символов с клавиатуры, в Rust меньше всего заезжен '@' и '%'. % в синтакисе всегда очень некрасивый (привет, постскрипт), так что, видимо, @. В начале или в конце — это вопрос интересный.
Ниже ещё '$' предлагают.
$print(f"{array[2]}")не самый плохой вариант. Или print$. Хотя, в целом, значков на клавиатуре не хватает.print?выглядит красивее всего, imho. Вообще, в японском такой волшебный разгул красивых значков...https://en.wikipedia.org/wiki/List_of_Japanese_typographic_symbols
Mingun
А по мне, так очень оторванно выглядит. Не воспринимается, как единое целое с идентификатором
PsyHaSTe
Доллар уже используется внутри макроса для обозначения метапеременных, будет путаница. @ во-первых не подходит семантически, во-вторых точно так же будете ругаться:
А что делать людям без японской клавиатуры? Разбираться как это набирается?
amarao
Это главная беда современного программирования. Значков мало. Математики себе изобретают, а программисты страдают.
Посмотрите по ссылке на красоту и вариативность скобок...
tyomitch
amarao
Мило, но меня трудно впечатлить греческими буквами (на Кипре это штатная раскладка).
tyomitch
Греческих букв на этой клавиатуре всего четыре.
tyomitch
Ни разу не видел
!для отрицания вне языков программирования: где не ¬, там черта сверху. Меня как раз удивляет, почему K&R выбрали!: визуального сходства с ¬ я не вижу даже близко.nin-jin
Скорее всего эволюция была такой:
=/==!=!=!DistortNeo
Ну не знаю. Во многих старых языках программирования для отрицания равенства использовался оператор
<>, а не!=.nin-jin
Так наденьте глушитель:
warlock13
Можно даже так:
ZyXI
Зачем нужны отдельно
notи побитовое отрицание, если!либо будет делать то же, что иnot, либо его нельзя будет применить к булевым, аnotв любом случае нельзя применить ко не-булевым?&&и||— это особый случай из-за short-circuit и, соответственно, необходимости особого отношения со стороны компилятора.PsyHaSTe
Очевидно, что основная проблема раста: отсуствие поддержки четырёхзначной логики.
nin-jin
Четырёхзначная логика элементарно реализуется на структурах в любом языке.
AnthonyMikh
Мне напомнить про
goto failбаг? В Rust допустить подобную ошибку было бы проблематичнее просто в силу обязательности скобок вокруг тела.А ещё после Rust обязательные круглые скобки вокруг условия в других языках бесят.
Случайно это сделать сложно, у вас иначе просто код не скомпилируется из-за несовпадения типов.
mafia8
А если сделать без let? Что будет хуже?
freecoder_xx Автор
Невозможно будет отличить случай сопоставления от случая присваивания. Тогда придется выбрать иной синтаксис для сопоставления, скажем, такой:
вместо
Вариант c
letвыглядит чище и традиционнее. И он как бы намекает, что перед нами все-таки не присваивание (раз он присутствует). Но многие незнакомые с языком думают, что тут именно присваивание, и что поэтомуletлишний.tyomitch
Зачем их отличать?
PsyHaSTe
чтобы запись
x = 5не была контекстно-зависимой. А ещё вам в любом случае нужен синтаксис для паттерн-матчинга.tyomitch
В JavaScript как-то обошлись. Ну или в чём принципиальное отличие деструктуризации от паттерн-матчинга? Почему для деструктуризации использование знака равенства не вызвало «контекстной зависимости», а для паттерн-матчинга — вызвало бы?
mayorovp
Ага, так "обошлись" что куча проблем из-за этого была, и в итоге в строгом режиме эту "фичу" запретили. Ну и зачем новому языку ходить по старым граблям?
tyomitch
Если у вас аллергия на JavaScript, возьмите Python: там тоже синтаксис деструктуризации и присваивания совпадает.
(Фича JavaScript, которую запретили в строгом режиме — глобальная область видимости по умолчанию у переменных, а вовсе не единство синтаксиса присваивания и деструктуризации.)
mayorovp
Дело не в деструктуризации и присваивании, а в объявлении и присваивании. И нет, не могу назвать их совпадение в Питоне достоинством Питона.
tyomitch
ОК, мотивация «хотим явного объявления переменных» намного яснее, чем названная PsyHaSTe «в любом случае нужен синтаксис для паттерн-матчинга.»
babylon
mayorovp да!
В любом случае мы делаем из undefined context defined context.
Проблема не в этом, а в контексте коли мы его объявили через let единожды!
Даже при динамическом создании класса мы должны как минимум указать хотя бы его имя. Введение let как бы к этому обязывает.
Для одноименных переменных это особенно важно. На одном уровне нельзя продекларировать переменную дважды. Если можно, то это разные уровни. Особенно полезно это знать при рекурсиях. Где не всегда виден уровень.
chapuza
Есть ровно один способ этого добиться: сквозь границу скоупа переменная может просочиться в двух случаях: кложурный захват и макрос с явно объявленной негигиеничной переменной.
Мутабельной переменной, видной отовсюду, чуть ли не
$global— не поможешь синтаксисом, это родовая травма языка. И все эти отмазки про производительность и (хахаха) циклы — это детский сад. Если уж так надо дать возможность стрелять в ногу, нужно неletобсуждать, а сделать способ эксплицитно отменять гигиену скоупа, типаСий макрос должен орать из кода: то, что вы тут наменяете, просочится во внешний мир.
adjachenko
Вот я тоже не понимаю почему люди нуждаются в разделении объявления и присваивания. Если вас не затруднит можете обьяснить почему вы считаете что на концептуальном уровне присваивание не тоже самое что инициализация и одновременное сокрытие переменной с тем же именем объявленной ранее. Я считаю что разницы нет на КОНЦЕПТУАЛЬНОМ уровне, а тот факт что есть разница для ЯП это просто напросто "узаконенная" оптимизация. Эта операция происходит настолько часто что очень важно что бы она работала быстро, поэтому и происходит разделение позволяющее оптимизировать присваивание. Также я считаю, что компилятор мог бы и сам различать когда это оптимизация применима, а когда нет имея единый синтаксис объявления который выглядит как присваивание. Имея два синтаксиса компилятор перекладывает на меня бремя по идентификации мест где эта оптимизация применима. 50 лет назад это решение было рациональным — сейчас нет.
mayorovp
На концептуальном уровне разница появляется когда становится важно в блоке какого уровня переменная объявлена. Хочется читать код, а не разгадывать головоломки...
adjachenko
Я понимаю что не так то просто привести хороший пример, но прошу вас постарайтесь. Я думаю вы знакомы с IIFE идиомой которая на с++ реализуется через лямбду. Т.е. ЛЮБОЙ блок кода заворачиваем в лямбду и тут же ее вызываем. Внутри лямбды скрываем/переопределяем переменную из контекста вызова и вуаля компилятор/программист счастлив — оба не против и не ругаются что в лямбде локальная переменная имеет тоже имя что и в вызывающем коде, но может быть другого типа и/или иметь другое значение.
Опять же я хочу обратить ваше внимание на тот факт, что тот же самый код вместе с IIFE НЕ вызывает проблем (хотя я лично ваше мнение ещё не знаю, может для вас и вызывает).Если убрать трюк с лямбдой то оба компилятор и конвенционный программист на с++ начинают выть что это ОЧЕНЬ плохо когда локальную переменную скрывают/подменяют в этом куске/блоке/скоупе, т.к
Я специально так делаю на работе уже довольно продолжительное время и заметил что это не вызывает РЕАЛЬНЫХ(мне не известны случаи что бы это привело к багу или жалобе что читать такое сложно) проблем с пониманием у моих коллег. Мало того некоторые спустя несколько месяцев начинают делать так же.
PsyHaSTe
Ну вот а в сишарпе шедовинг и переопределение встречаются на каждом шагу. Например, можно посчитать, сколько различных значений path/db есть в примере ниже:
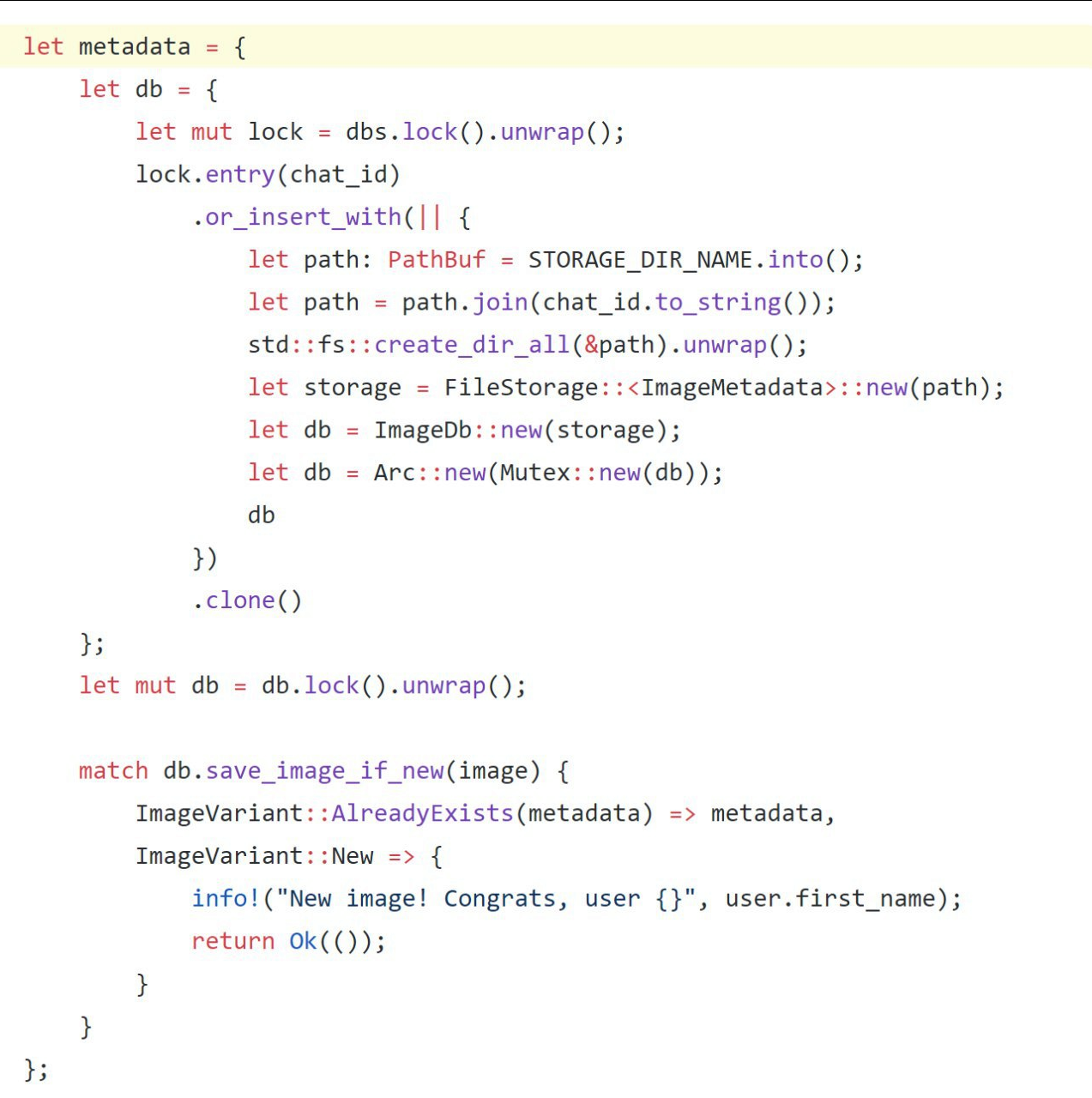
У нас есть по крайней мере три сценария которе нужно различать: объявление неизменяемого биндинга, изменяемого биндинга и мутация существующего значения. И хотелось бы все их легко в коде видеть и отличать одно от другого.
adjachenko
В вашем примере есть два типа объявления (неизменямый и изменяемый биндинг), но нет ни одного присваивания. Есть мутация, но она имеет совсем другой синтаксис — вызов функции.
Т.е. я так и не увидел почему объявление нужно отличать от присваивания. И да я не считаю что шедовинг это проблема, я как раз искренне не понимаю почему это проблема для других людей.
PsyHaSTe
Ну как раз в 99% случаев я и не мутирую ничего, а только объявляю. Но перепутать эти 99% с 1% мутаирования существующей переменной я бы не захотел.
letдает однозначную грамматику, однозначная грамматика дает лучшую работу IDE, лучшие подсказки, лучшие ошибки и так далее. Хотя бы ради этого смысл в нем есть. Разница в том что если я пишу:То я хочу видет ошибку компиляции (нашли, в чем проблема?)
adjachenko
Я понимаю на что вы намекаете и вашу опечатку заметил, но этот пример мимо. Вы не можете объявить переменную оператором &= это просто не имеет смысла. Т.е. этот пример не вызывает никаких проблем с определением ошибки у компилятора (во вселенной где нет разницы между присваиванием и объявлением). Это просто не валидный код в обоих вселенных.
По мотивам вашего примера можно представить такой код
Да в моем мире такой код будет иметь иную семантику т.к. mask
в if скоупе будет локальной перменной и на каждом проходе цикла будет битово эндится с неизмненной mask объявленной до цикла. Т.е. в моей вселенной такой пример будет достигаться следующим кодом на расте
Что бы написать код в моей вселенной с такой же семантикой как у раста придется писать что то типа
Конечно вы можете сказать, что я сошел сума и так писать не удобно/не правильно и т.д., но это всего лишь ваши привычки. Я лишь показываю что нет НИКАКОЙ концептуальной разницы между присваиванием и объявлением, а все гипотетические сложности которые вы здесь приводите это следствие побочных эффектов которые уже давным давно побежденны в фукнциональных языках. И мне кстати в связи с этим очень странно видеть 0xd34df00d на одной стороне с вами по этому вопросу. Мало того в моей вселенной я могу читать любой код вырванный из любого контекста и ТОЧНО понимать что в нем происходит, а в расте(да что уж почти во всех языках) если я вырву кусок кода из контекста (схлопну цикл в IDE) то я понятия не имею что внутри цикла мой mask меняется — это ИМХО затрудняет понимание кода — так называемая локальность кода/семантики нарушается. Мне нужно видеть больше чем минимум что бы адекватно мыслить о том как этот код работает.
PsyHaSTe
Речь о том, что семантика раста максимально контекстно-независима.
В вашем случае если мы видим
mask = 12нужно идти вверх по скопу смотреть "а нет ли там какого-нибудь подходящего mask`? Причем если выше по скоупу есть, но другого типа (например, String), то компилятор что должен выдавать? Мне ни ошибка не нравится, ни отсутствие её в этом случае :)Поэтому леты и ещё раз леты. Тем более, что как выше было замечено это консинстентно работает с паттернами
if let/while let/...Vilaine
Вот рабочий код:
Он компилируется. Чтобы его скомпилировать, мне пришлось добавить let. Если я убираю let, то получаю
Идеология Rust — максимальная безопасность. Принятое решение на 100% соответствует его идеологии. Кроме того, никакие из современных ЯП не разменивали эту существенную толику безопасности на экономию трёх символов, не правда ли? Явное лучше неявного и т.п.
adjachenko
Да нормальный рабочий код, только мне опять не понятно зачем здесь лет. Он НИЧЕМ не помогает ни мне ни компилятору. Уберите его и просто посмотрите на код вы никапли не потеряете в читабельности. Ваш пример имел бы больший вес в этой дискуссии если бы второй лет хайдил первый лет. Но как я уже писал выше это была бы локальная переменная изменение которой не влияет на выше объявленную если вы явно это не укажите в двух местах. Если вы посмотрите на мой пример, то увидите что то о чем я говорю приводит к ещё более явному коду чем то что сейчас в расте — чтобы поменять значение переменной верхнего скоупа нужно явно вернуть значение из вложенного скоупа и переопределить переменную верхнего скоупа, тогда как сейчас в расте и других не функциональных языках достаточно внутри цикла присвоить новое значение не локальной переменной == воспользоваться побочным эффектом. По сути то о чем я говорю технически запрещает часть побочных эффектов связанных с присваиванием. Ещё раз, замена присваивания на переопределение технически устраняет часть побочных эффектов как невыразимую тем самым уменьшая возможность ошибиться, но меняет семантику делая ее не ПРИВЫЧНОЙ для тех кто привык использовать побочные эффекты — почти всех программистов на земле. Да я вижу что в силу привычек вы не можете увидеть сейчас преимущества, но для меня оно совершенно очевидно. Я уверен, что мы с вами застанем новые промышленные языки которые сделают присваивание не выразимым, только (пере)определение.
PsyHaSTe
к ФП отношение имеет чуть более чем никакое. В хаскелле вы в любом ифе можете сделать writeSTRef и получить ровно то же поведение.
То что вы пишете выше — вы предлагает ввести неоднозначную грамматику где
a = bможет иметь разный смысл в зависимости от того, есть ли где-то выше по скоупу такоеaили нет. Это тяжело парсить парсером -> с этим тяжело работать человеку -> не нужно.Могу вернуть вам ту же аргументацию.
tyomitch
Ваши б слова да Гвидо в уши:
Опечатки нет, но &= всё равно истолковалось как объявление.
AnthonyMikh
А как же костыль
nonlocal?adjachenko
Ну судя по синтаксису и моим куцим знаниям это питон. Худо-бедно, но об ошибке рапортует. Лучше хоть как то работающий ЯП чем идеальный в
вакуумеголове дизайнера языка.red75prim
Иногда удобно для уменьшения сползания вправо, ну и код красивее выглядит.
вместо
adjachenko
Очень интересно как вы выдаёте пример раздельного ОБЪЯВЛЕНИЯ за пример присваивания. let x; НЕ является законченным объявлением, но образует объявление вместе с последующим синтаксисом присваивания.
red75prim
А это тогда раздельное объявление, которое становится целым только в рантайме?
adjachenko
нет, оно становится цельным во время компиляции, замените 12 или 13 на строковый литерал или на не целое число и получите ошибку что тип переменной нельзя однозначно вывести.
red75prim
Да. Я уже разобрался, что вы хотели сказать. Это называется static single assignment form.
Можете попытаться развернуть в такую форму код с массивами.
tyomitch
Здесь вы никак не замените присваивание внутри цикла на сокрытие и переинициализацию переменной.
adjachenko
любой цикл может быть заменен на рекурсию (цикл частный случай рекурсии)
Когда то давно я восхищался языком Nemerle в котором циклов не было принципиально — только рекурсия, но при этом были макросы которые выгледели как циклы и заменяли их на рекурсию, и да потом оптимизатор заменял левую рекурсию снова на циклы. И во всем этом жонглировании есть смысл — сайд эффектом было то что любая левая рекурсия в коде сама заменалсь на циклы, т.к. авторы потратили время на оптимизацию рекурсий.
tyomitch
«Без присваивания можно обойтись, если переписать весь код в стиле Nemerle» — не то же самое, что «без присваивания можно обойтись, это просто оптимизация сокрытия с переинициализацией».
adjachenko
Ну, а теперь пожалуйста если не затруднит, покажи мне на КОНЦЕПТУАЛЬНОМ уровне в чем же разница. Если это действительно так, то должен существовать простой, часто используемый шаблонный контр пример, который с лёгкостью демонстрирует разницу.
Я еще раз уточню — присваивание это пере использование ресурсов аллоцированных/ассоциированных с именем для другого «значение» что бы это(значение) не значило.
Объявление это ассоциация/аллокация ресурсов (значения) с именем.
Когда вы присваиваете что то левому операнду, то правый уже существует. Я думаю вы согласитесь что на концептуальном уровне
тоже самое что и
Я не могу представить программу где бы была невозможна замена ВСЕХ присваиваний на объявления и сохранение поведения программы кроме эффективности использования ресурсов.
Да присваивание и/или мув могут иметь побочные эффекты, но нет фундаментальных препятствий разделить суть присваивания и побочный эффект.
tyomitch
Я же выше привёл простой, конкретный пример.
Циклы очень часто используются, хотя код можно было бы писать и без них.
adjachenko
Ну я же уже продемонстрировал, что цикл с побочным эффектом на внешней по отношению к скоупу цикла переменной легко выражается/заменяется на цикл/рекурсию где НЕТ побочных эффектов для нелокальной для цикла переменной.
Я прошу привести пример, где никак невозможно заменить присваивание на переопределение + явное вынесение побочных эффектов (если они есть).
tyomitch
Покажите замену того кода на цикл без присваиваний. Без рекурсии.
chapuza
Во-первых, есть куча языков, в которых циклы в принципе не предусмотрены синтаксисом. Во-вторых, в мультипарадигменных языках как-то все более принято заменять циклы на функциональные аналоги типа
map/reduce, или, на худой конец, comprehensions. В-третьих, даже в языках с «родными» циклами, вышеприведенный фрагмент — смердит, и я лично разворачиваю на ревью код, который так волюнтаристски мутирует весь окружающий мир; это нечитаемо и очень подвержено привнесению ошибок впоследствии.А почему она должна существовать? «Покажите замену кода с
gotoна код безgotoи без циклов» — тоже разновидность некорректного безответного вопроса.tyomitch
Но это же стандартная реализация поиска в дереве: как
processя обозначил выбор ребёнка, как сравнение с 42 — сравнение ключей.Или
своёвstd::collectionsтакое не смердит?Я уже ответил на пять каментов выше в ветке.
chapuza
А ничё, что код, на который вы дали ссылку — уже рекурсивен? Подозреваю, что Rust не сможет вывести тотальность перекрестной рекурсии, поэтому там и появляется хак с псевдобесконечным циклом, переопределением биндинга из внутреннего скоупа и бесчисленными ранними возвратами, превращающими и без того лапшу — в мелкопокрошенное спагетти. Может быть, лучше заняться доведением до ума компилятора, чтобы можно было бы избежать вот таких хаков?
Ну это ответ в духе «все ваши варианты мне не нравятся, поэтому не существуют».
tyomitch
Покажите мне (перекрёстно-)рекурсивный вызов
search_tree, а то я его в упор не вижу.Вы пытаетесь меня убедить в существовании языков без циклов даже после комментария, в котором я явным образом ссылаюсь на Nemerle?
0xd34df00d
Не смердит то, что не нужно ревьювить, и что проревьювили (или доказали) за меня. В стандартной библиотеке ghc тоже пусть хоть ST обмазываются по полной для поиска по деревьям (правда, не знаю, зачем), моё дело — писать код с явной рекурсией (а не циклами и состоянием, о которых больно рассуждать) и благодарить компилятор за TCO.
PsyHaSTe
Обычно наоборот заменяют рекурсию на цикло ибо стаковерфлоу. И если вы не фанат передавать по 10 аргументов чтобы сделать TCO то лучше конечно так не делать.
А так утверждение из разряда "программист на фортране может писать на фортране на любом языке программирования". То что любой цикл можно переписать в рекурсию не означает, что разумно это делать.
Причем в нашем случае можно использовать "трюк с лямбдой" как выше подсказывают:
Только вот лучше я буду let писать чем вот это.
PsyHaSTe
Потому что как различить
a = 50объявляет новую переменную или мутирует существующую? Рефакторинг превращается в боль:Теперь переименование b в a внезапно ломающее изменение. Ну и так далее. Не, не надо такого счастья
0xd34df00d
Нетрудно придумать пример с shadowing'ом, когда подобное переименование всё равно будет ломающим: достаточно внутри
ifпечататьb, а неa.PsyHaSTe
Ну это не сильвербуллет, но часть проблем снимает. А ещё если у нас есть let'ы то компилятор при рефакторинге может нам сказать что семантика принта может поменяться. В случае когда = может означать что угодно провести такой анализ куда сложнее
tyomitch
Компилятору для генерации кода всё равно приходится определять, какие из = — объявления, а какие — присваивания, так что при рефакторинге хоть с let, хоть без let он сможет сказать одно и то же.
PsyHaSTe
Нет, компилятор когда дошел до
=уже знает, присваивание это или биндинг, именно потому что они различаются с помощьюlet.adjachenko
Ну тут выше был приведён контр пример
может полный компилятор и знает разницу здесь, но вот какой нибудь кастрированный интелисенс/человек уже не может так однозначно сказать, что это здесь присваивание или все же
хитромудровыебаннаяраздельная инициализация.PsyHaSTe
Просто присваивание. То что оно единственное и все такое — доп. контекст, который может вам и не нужен. Если он интересен можно тыкнуть в x и посмотреть что это.
Не говоря про то, что в реальности let x; я не встречал ну ни разу. Чаще будет что-то вроде:
Если уж мы экономим горизонтальное место.
adjachenko
Нет, это не присваивание. Это часть раздельного объявления. Скажите мне пожалуйста какого типа переменная let x; и какое в ней значение ДО присваивания и не забудьте про адрес памяти где она лежит?
PsyHaSTe
тип
{unknown}(по аналогии с {integer} для констант), значения очевидно никакого нет. Место в памяти решается так же как и с {integer} — по первому использованию.0xd34df00d
А почему бы, кстати, не вывести тип из последующих контекстов использования, как всегда с Х-М делается? Видим, что где-то присваивается
12— навешиваем одно уравнение. Видим, что в другом месте42.0— навешиваем ещё уравнение (и система пока ещё совместна). В третьем месте"hello from js"— всё, рапортуем об ошибке.PsyHaSTe
Потому что в расте нет индирекции по-умолчанию. Нельзя навесить уравнение
Monadнапример потому что нет такого типа. Есть либо Box либо SomeConreteStruct. Единственный сценарий который я могу придумать — ссылка &dyn Something на стеке, который ну ооочень редко встречается и рассматривать его можно разве что с эстетически-гипотетической точки зрения.Поэтому даже списки в расте это не совсем монады, потому что вместо сигнатуры
(a -> f b) -> f a -> f bу них сигнатура
(g : a -> f b) -> f a -> FlatMap (f a) g0xd34df00d
А, прикольное следствие из отсутствия этого, да. Спасибо за пояснение!
adjachenko
Мой комментарий может показаться вам слишком резким, и я не хочу обидеть лично вас, но то что вы написали — полная чушь.
? Отсутствие значение это НЕ валидное значение это вообще НЕ значение. Этот как NAN не число или null не значение. Нельзя разыменовывать нулл поинтер. И естественно адреса у такой переменной НЕТ и быть не может, т.к. ни тип ни значение ещё не известны.Раст это статически типизированный ЯП, а это значит что присваивание НЕ меняет ТИП переменной, тогда как по вашей версии сначала тип unknown, а потом int или еще что то. Также в расте не существует типа unknown. Еще больше, присваивание семантически это всегда создание КОПИИ объекта (не важно глубокой или неглубокой), что бы создать копию, ваш левый операнд в операции присваивания ДОЛЖЕН быть валиден на момент копирования — какой инвариант имеет значение
Я ещё не достаточно хорошо знаю раст поэтому расскажу на примере с++ — присваивание это такая специальная операция которую можно переопределить — предоставить свою реализацию. Смысл в том что операция может быть вызвана только лишь на уже сконструированном и валидном объекте, но let x; не вызывает НИКАКОГО конструктора не аллоцирует ресурсы и не создаёт валидную переменную, у которой можно было бы вызвать операцию присваивания далее по коду.
Еще разок, объявление это связывание уже сконструированного объекта с именем всегда гарантированно 0 рантайм оверхед.
Присваивание это создание КОПИИ объекта связанного с именем справа от знака равно используя ресурсы объекта связанного с именем слева от оператора =, это либо дефолтная реализация копирование содержимого памяти объекта справа в память объекта слева (предполагаем что они/адреса всегда разные) либо кастомная операция. Надеюсь я смог объяснить почему вы не правы.
PsyHaSTe
Почему-то это именно так и работает для текущих цифровых типов:
Что это за тип такой
{integer}? Сколько байт в "статически компилируемом расте" он занимает, 8 или 16 или 32 или ещё сколько?Конечно не означает, иначе не-копи типы нельзя было бы присваивать, но почему-то можно.
А в расте не как в С++, в нем присваивание нельзя переопределить — и присваивание всегда является мувом значения из одного места в другое. В случае, если тип — копи, и его нельзя переместить, то вставляется неявное копирование, для удобства. В противном случае будет ошибка "тип нельзя переместить в переменную". А чтобы что-то переместить в переменную изначально там не обязательно что-то должно быть.
Если бы это был код на С++ со своими 100500 разных конструкторов, перегрузок базовейших операторов и т.п. то я наверное был бы неправ, только мы не про С++ говорим. Если что-то верно в С++ это не обязательно универсальная правда для всех языков, вот и все
mayorovp
Это именно что "плюсизм", который не имеет никакого отношения к Rust. В Rust о присваиваниях заботится компилятор, и программист не может этого переопределить. Можно только выбрать будет ли тип копируемым или перемещаемым. Как следствие — нет ограничений вроде "операция может быть вызвана только лишь на уже сконструированном и валидном объекте", компилятор знает что делать если "целевой объект" ещё не сконструирован и не валиден.
adjachenko
Здесь ответ обоим @mayorvp и PsyHaSTe на коменты выше
Да признаю, семантика = в расте не такая как в плюсах. Нет, вы все ещё не правы на счёт let; Вы нашли изъян в моих НЕСУЩЕСТВЕННЫХ тезисах. Вы все еще никак не отреагировали на суть:
Если вы все ещё прибываете в заблуждении насчёт что let x; это полное определение (а не часть раздельного), то попытайтесь ответить на такой вопрос — если бы следующий код был бы валидным (а он не компилируется без ошибок), то что по вашему мы бы увидели в консоли?
Ответ смотри здесь. Я так понимаю что {integer} это ВНУТРЕННЕЕ обобщенное(не доконца выведенное) представление типа числовой переменной и является деталью реализации компилятора и НИКОГДА не доступно из программы. Иными словами это как конецпт интегрального типа в с++ — шаблонный тип с определенным интерефейсом. В валидной программе тип любой переменной ВСЕГДА будет выведен до самого конца и в случае числовых констант дефолтный выбор это i32.
Если в моем примере выше вы напишите let x = 1; то на консоль быдет распечатано: i32, 1, 0x7ffe490bef0c
Видите никаких {integer} здесь и не пахнет. i32 это валидный КОНКРЕТНЫЙ заместитель обобщеннго {integer} т.к. полностью удовлетворяет всем тербованиям {integer}.
И ещё раз для закрепления — ошибка компилятора о том что тип {intger} в очередной раз подтверждает мой тезис — в валидной программе все типы выведены до конца, неполное объявление, а затем попытка использования приводит к ошибке компилятора где он сообщает максимум известной информации на момент ошибки. Т.е. если удалость понять что это {integer} уже хорошо давайте скажем прогера хоть что то о типе это лучше чем ничего не сказать ни смотря на то что конкретный тип не был выведен.
PsyHaSTe
{unknown}Ну вот и
{unknown}такой же — ВНУТРЕННЕЕ обобщенное(не доконца выведенное) представление типа любой переменной. Которе является деталью реализации компилятора и НИКОГДА не доступно из программы (как кстати видно в примере выше "если бы это компилировалось"). Один в один.adjachenko
Я не знаю, может у вас свой персональный компилятор раста, но тот который в песочнице говорит error[E0282]: type annotations needed
Я нигде не вижу никаких {unknown}.
Противоречит вашему предыдущему ответу, что на консоль в качестве имени типа будет распечатано {unkown}. Тут либо на консоль пойдёт что то другое либо оно доступно из программы.
А сам факт того что оно не компилируется + текст ошибки говорит о том, что определение переменной x неполное. Я до сих пор не пойму о чем тут можно спорить дальше.
В помощь вам простая модификация моего примера, сделайте то о чем просит компилятор — добавьте аннотацию типа например let x: i32; И тогда следующая ошибка будет borrow of possibly-uninitialized variable: `x`
Видите — тип уже есть (адрес думаю тоже), но вот валидного значения все ещё нет — незаконченное определение. Если вы
пуститесь во все тяжкиеиспользуете unsafe, то тогда требование валидного значения снимается и там же в ансэйфе вам будет доступен адрес. Но даже для ансэйф нужен тип.Да даже если мы представим, что ваш персональный компилятор в котором есть {unknown} существует, то пользы/смысла в этом нет. {integer} очень полезен т.к. имеет предопределённый интерфейс и компилятор даже не зная конечный тип уже может генерить дженерик код для такой переменной используя интерфейс {integer} т.к. любой конечный подходящий тип будет его реализовывать.
Я не могу представить интерфейс {unknown} — он пуст /бесполезен. Даже Void (тип с монозначением) более полезен чем ваш {unknown}. Ваш тип {unknown} не имеет значений — пустой. Из основ ФП я знаю, что нет ни одной функции из пустого типа во что бы то ни было поэтому он бесполезен на практике.
AnthonyMikh
Вообще-то есть, функция идентичности.
0xd34df00d
Вообще-то есть. Собственно, из пустого типа есть ровно одна функция в любой другой тип. Можно думать об этом в терминах множеств (из пустого множества в любое другое множество есть ровно одна функция, которая ничего не делает), можно думать в терминах категорий (пустой тип — начальный объект в некоторой соответствующей категории). Поэтому, собственно, пустым типом удобно представлять ложь: из него «следует» всё, что угодно (а ещё тут есть категориальная интерпретация логики, где некоторая стрелка из нуля и есть ложь…).
Вот в пустой тип функция есть только из пустого типа, и это identity-функция.
adjachenko
Да вы правы, ещё раз перечитал, я ещё довольно таки плаваю в основах ФП и могу нести не то что есть на самом деле, спасибо за поправку. Мой мохзг запомнил
«главное»то что захотел, а не то что есть category-theory-for-programmers 2.6tyomitch
Пардон, мой комментарий выше следует читать «Компилятору
языка без let для генерации кода всё равно приходится определять, какие из = — объявления, а какие — присваивания, так что при рефакторинге хоть на языке с let, хоть на языке без let компилятор сможет сказать одно и то же.» (Я выделил добавленные слова.)
PsyHaSTe
Если мы про раздельное написание лета и присваивание то тут у нас нет никакого разночтения — это просто обычное присваивание, записывание в переменную или как угодно ещё. Компилятору все равно требуется проверить, что в переменную можно писать. А условия записи:
binding.ty == Modifiers.Mut || binding.assignment_count == 0С точки зрения парсера есть только присваивание в данном случае. Энфорсингом единственной инициализации является уже семантическая модель раста, как и какой-нибудь борровчекер.
PsyHaSTe
Ради интереса взял сишарп (просто потому что у него есть удобное компиляторное апи), посмотерть, как он различает "первоначальную инициализацию" и присваивание.
Что оказалось — а никак.
Код
Дерево:
Видно, что в обоих случаях у нас есть просто некий SimpleAssignmentExpression и все. Полагаю, в расте должно работать подобным образом.
adjachenko
Я думаю вы согласитесь что нет никакой разницы (для результата вызова pint(a)) объявление это или присваивание. Теперь что насчет кода который включает этот скоуп? Если это объявление то все хорошо — никаких проблем, а если это присваивание то это побочный эффект по отношению к локальному скоупу if
Я лично предпочел бы явное разделение побочного эффекта что то типа
В этом случае мне не важно была а объявлена до этого момента и это присваивание или это объявление а т.к. любой код который использует а увидит то что я ожидаю — 50 в случае если cond истинна и 10 иначе. Вы даже можете убрать первичное объявление а и заменить его на 10 в else ветке и ничего не поменяется.
PsyHaSTe
В вашем примере я не понимаю, a = 50 должно мутировать a в нижнем принте или нет. Является ли a = 50 ошибкой и должно быть b = 50 или нет? С летом вопрос однозначный, а в этом коде неоднозначность.
Второй вопрос
a = 10— это мутабельный биндинг или нет? Имеем ли мы вообще право его мутировать в первую очередь?вопрос три — а нет ли ещё выше по скоупу (вне нашего примера) ещё какой-нибудь a? Должны ли мы мутировать эту внешнюю а или опять же мы должны её затенить? Вопрос, вопросы...
Странно вообще воспринимать придирки что целых 3 буквы требуют писать, а с другой стороны те же люди говорят что
fnэто слишком коротко.adjachenko
я никогда не утверждал, что fn это плохо, по мне так лучше его вообще выпилить или заменить на хаскелевский синтаксис ->, но тут мне хотя бы понятна где возникает неоднозначность и как fn реально помогает её разрулить.
Да мне понятны ваши вопросы, вопросы… Это просто система привычек которые у нас сформировались — использование побочных эффектов.
Смотрите побочные эффекты на глобальных переменных уже вроде бы как все адекватные люди признали злом, видимо нужно еще ндцать лет что бы все те же адекватные люди поняли, что нет ни какой разницы между мутаций глобальной переменной из функции и мутации переменной из вышестоящего скоупа в ТОЙ же функции — точно такое же зло.
Мне НЕ нужно видеть что происходит внутри любого вложенного блока, я точно могу быть уверенным что внутри НИЧЕГО видимого здесь поменяться не может. Также я вижу что x переопределяется и что с этого момента он имеет другое значение.
Сейчас в расте да и в других языках мне НУЖНО заглянуть внутрь вложенного блока что бы узнать, а не мутирует ли он что либо — это и есть нарушение локальности.
В моей вселенной x = 5 ВСЕГДА локален тому скоупу в котором вы его видите. Т.е. не важно есть там наверху переменная с таким именем или нет ее, x = 5 только здесь и сейчас -до конца скоупа или до следующего ПЕРЕОПРЕДЕЛЕНИЯ x в том же скоупе. Скоуп закончился все нет никакого x. Если выше был объявлен другой x то он НИКАК не поменяется это совершенно ДРУГОЙ не связанный х.
Все бест практисы для всех языков советуют просто давать локальным переменным ДРУГИЕ имена, что бы они ничего не хайдили и тем самым добиваться того поведения о котором я пишу — НЕ МУТИРОВАТЬ переменные из вышестоящего скоупа до тех пор пока это не вредит производительности. Проблема в том что давать другие имена не всегда лучшее решение, часто бывает что имена локальных переменных становятся муторнее/менее понятными. Это простительно для языков спроектированных ДО раста.
если мне нужна мутабильность то я буду писать
mut x = Type{5};
что позволит мне вызывать мутирующие методы класса/структуры Type. для переменной x, без mut только лишь не мутирующие методы.
Присваивание это частный случай мутации который семантически заменяет все содержимое объекта тогда как мутирующий метод может менять только лишь часть объекта. Опять же мутирующие методы это узаконенная оптимизация, вы всегда можете выразить мутирующий метод через код который создаёт копию объекта с изменённым состоянием. Есть целая идиома имутабл классов в шарпах и как самый яркий пример это строки.
+= выглядит как мутирующий оператор, но на самом деле он НЕ мутирующий но создает копию и переопределяет str.
Есть только одна проблема с этим подходом, разработчики C# не осилили сделать оптимизацию которая вместо переопределения в рантайме вызовет специфичный/оптимальный/эффективный код конкатенации. У них была проблема/причина компилятор НЕ знал сколько ссылок есть на этот объект и поэтому они НЕ смогли сделать такую оптимизацию. Раст ЗНАЕТ сколько у него ссылок на это значение и МОЖЕТ реализовать такую оптимизацию когда ссылка ровно одна.
Поэтому для раста это изъян в дизайне, он может (без потери производительности) и должен был бы запретить присваивание как таковое исключая целый ряд потенциальных ошибок как невыразимых.
PsyHaSTe
Да какое это зло. Вот возьмите хачкель (или идрис если хачкель кажется вам слишком старым и накопившим легаси), вот написал я
acc' <- newSTRef accи дальше где-то ниже в каком-то ифчике мутирую. Что, зло? Никто так не делает? Да, мутировать когда можно не мутировать и использовать "expression everything" плохо, только вот не всегда это возможно. Раст это низкоуровневый язык, поэтому там мутирование например позволяет избежать лишних аллокаций, потому что caller может всегда передать свой буфер который функция будет мутировать, вместо принятой в гц-языках практики что функция сама саллоцирует и вернет значение. Типичный пример — чтение с консоли, в расте в стд эта функция требует чтобы ей передали первым аргументом&mut String. Как вы тут будете безmutжить?Вопрос, почему в дофига ФП хачкеле в котором кстати никаких мутаций через
=не существует всё равно есть паттернlet ... in ...?А бест практисы раста где можно шедовить переменные мне нравятся куда больше. Просто потому что вместо того чтобы выдумывать по 3-4 бесполезных названий вида
user_string, user_parsed, user_reference_count_wrapperя могу просто сделатьuserи все. Зачем все эти мусорные переменные "рыбу заворачивали" мне в коде и в автодополнении, и в watch? Они несут чисто техническую нагрузку и облегчение понимания кода только в том месте, где они объявляются. Ниже про них знать не нужно.И как мы отличим присваивание от мутирования в таком случае?
Что конечно же неприемлимо для низкоуровневого высокопроизводительного языка. Рассчитывать что придет магический компилятор и весь наш говнок… простите, "легкочитаемый" код соптимизирует немного наивно. В ГЦ языках другой трейдоф, и там например не надо волноваться, на стеке или в куче у нас объект — в расте перемещение объекта из кучи в стек или наоборот — ломающее изменение, которое видно в типах. Наверное приводить пример "а вот в сишарпе вот так" не стоит, ведь у него совсем другие цели и подходы.
adjachenko
Я не настоящий
сварщикфпшник, но сочувствующий. Мой мозг так же как и мозг многих других разработчиков сильнопострадалподвержен влиянию с++. Спросите лучше 0xd34df00d говорят он успешно прошёл курс ФП терапии и больше не используетнекачественные препаратынебезопасные языки.По этому вопросу я вам не оппонент, мне тоже нравится шэдовинг куда больше чем извращения с именами переменных, но в кругу с++ это считается одним из смертных грехов.
На остальные тезисы попробую ответить скопом т.к. они связаны. Я тут подумал и мне кажется я начинаю понимать в чем сложность донести мою мысль до вас, не уверен что все так и есть но думаю как то так: ваша нейросеть сильно прикипела к ключевому слову let и/или аналогам в других языках. Когда я говорю что оно лишнее ваши нейроны кричат что я сошел сума и кто-то пытается вас лишить очень уютного/удобного ментального костыля. Ну и ладно давайте я уважу вашу нейросеть, да и к тому же это неважная деталь для той мысли что я пытаюсь объяснить. Я переформулирую мою мысль с равенством первоначальной до изоморфии.
Я заявляю, что если вы начиная с этой секунды везде и всегда (на расте конечно) где ставите знак равно будете ещё ставить let, то ваш код станет только лучше и вы ничего не потеряете, другими словами добровольно откажитесь от того 1% случав где вы использовали присваивание и вместо него используйте шэдовинг с явным возвратом значение из вложенного скоупа в том случае если мутировали не локальную переменную.
тоже самое но со вложенным скоупом
Специально проверил оба примера валидный раст код. Обратите внимание на то что отпала необходжимость в mut. Да mut все еще нужен для вызова мутирующих/инплэйс функций, но это опять же несущественные детали не влияющие на суть идеи. Шарпы и другие языки НЕ МОГУТ В ПРИНЦИПЕ реализовать эффективную оптимизацию и заменить переопределение на присваивание, но не потаму что (не)испоьзуется гц, а потаму что раст реализовал уникальную функциональность компилятор раст знает сколько ссылок на объект, это ключевая информация для реализации этой оптимизации. Смотрите одна ссылка значит мутабельный, много значит немутабельный и нельзя оптимизировать — придется делать копии.
Я думаю примеры выше прекрасно демонстрируют, что во первых нет никакой разницы между присваиванием и переопределением, и что еще важнее нам обсалютно до лампочки что из них одно, а что другое, это просто детали оптимизации. Компилятор САМ разберется где можно эффективно заменить переопределение на присваивание, а где нет.
Очень хорошо, что половину пути вы уже прошли:
А теперь пожалуйста покажите пример
когда я не смогу применить свою идею(везде где есть = добаить let) на расте.
Как я уже неоднократно писал, все эти мутации это просто узаконенные оптимизации. Еще раз до эпохи раста это было РАЗУМНО, т.к. не было принципиальной возможности реализовать эти оптимизации на уровне компилятора, не было ключевой информации сколько ссулок на объект. Раст может сделать эту оптимизацию на уровне компилятора и поэтому наличие присваивания (и mut тоже) является ИЗЪЯНОМ дизайна раст. Да я понимаю что разработчики скорее всего не могли этого предвидеть заранее когда делали подсчет ссылок, но никогда не поздно что то улучшить, хотя конечно это то еще ломающее изменение языка и по сути что то типа раст2 или вообще другой язык. Хотя технически вы уже сегодня можете отказаться от многих mut и от всех присваиваний.
Ну а теперь как вишинка на торте, если везде и всегда писать let x = value; и нигде не иметь x = value; то очевидно что нет необходимости в let и можно просто везде писать x = value;
для полноты я проверил еще и мувыбл тип
red75prim
Как вот такое будет выглядеть без присваиваний?
adjachenko
Сначало, я думал что не смогу это написать, но потом немного подумав и немного погуглив выяснил, что раст движется в правильном направлении и все ужо хотова — правда в найтли.
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
red75prim
Нет, этот код делает другое. Результат должен быть [3, 28, 20, 23, 6, 7, 7, 4, 5, 7].
Playground
adjachenko
Да вы конечно правы, мой предыдущий пример не о том. Я начал с упрощённого варианта и у меня были большие сложности, поэтому когда у меня наконец заработал простой вариант, я совершенно позабыл что это только начало. Так или иначе держите то что вы хотели
песочница
Да это опять не 100% то что вы хотите (тип а изменился со статического масива на вектор), но это уже детали (arraymap есть в найтли значит нет фундаментальных проблем реализовать этот трайт для array). В любом случае вы просто заставили меня по упражняться в рэнджи, спасибо было интересно посмотреть как оно в расте — неплохо, мне понравилось.
Ну а по существу такую билиберду конечно никогда в реальном коде не увидешь поэтому меня мало интересует насколько раст хорошо это оптимизирует, вот что на самом деле интересено, так это насколько эффективен код из моего первого примера т.к. это пишется ежедневно тысячами разработчиков.
PsyHaSTe
А терь вы выделили х2 памяти на ту же операцию. Если например мы уже заняли всю память то ваш код вызывает OOM и падение приложения. Отлично.
Ну это же сишная мантра "НАСТОЯЩИЙ ПРОГРАММИСТ НИКОГДА ТАКОГО НЕ НАПИШЕТ", не надо её тут нам. Пишут и не только так.
Вот другой пример, я тут недавно учился дату-время выводить на расте. Покажите, как можно переписать этот код без
mutи дополнительных аллокацийAnthonyMikh
Ай :( Надо было что-то вроде
, чтобы новой аллокации не было
PsyHaSTe
Переписал как
спасибо! Вроде и длина и truncate ожидает длину в байтах, так что должно работать корректно.
adjachenko
Я рад что ваша риторика изменилась, с «без let ну вообще жизни нет никак» на
«дайте мне тоже самое, но с перламутровыми пуговицами»Я изначально сказал, что на КОНЦЕПТУАЛЬНОМ уровне присваивание и (пере)определение это одно и тоже, но присваивание это узаконенная форма оптимизации (которая очень важна). Так же я говорил, что только лишь раст имеет возможность переложить эту оптимизацию с человека на компилятор, а другие языке не могут в принципе, но я нигде не говорил что раст УЖЕ реализовал все необходимые оптимизации. Это раз.
Зная основы ФП, даже не глядя на ваш код я уверен, что он может быть переписан без единого присваивания на расте, но вот ваше требование отсутствия дополнительных аллокаций (за базу для сравнения очевидно берем вашу реализацию) обоснованно примерно чуть более чем никак. Это два.
Ну и самое главное, каникулы закончились времени на дискуссии/упражнения в раст у меня больше нет, так что вам для саморазвития будет полезно самому попытаться переписать ваш собственный пример, для начало запилите все присваивания, а уже потом смотрите сколько там аллокаций может раст уже все сам разрулил, такое часто бывает, иногда бывает даже так что ФП подход приводит даже к БОЛЕЕ эффективному коду чем классика. Я вполне допускаю, что без доп аллокаций сегодня это переписать невозможно, но вы не отчаивайтесь, с каждым релизом раста эффективность будет расти.
я такого не писал, я сказал что пример выше бессмысленная белиберда, полезная разве что только в качестве упражнения в ренджи, и поэтому насколько (не)эффективный код раст сгенерирует для этого примера меня лично вообще не интересует. Ваш пример куда разумней, но времени нет.
tyomitch
Я и в седьмой раз вам напишу, что «оптимизация аллокаций» — второстепенная польза от присваиваний, по сравнению с возможностью использования в программе циклов.
Если нет мутации внешних скопов, то всё, что происходит внутри цикла, остаётся внутри цикла — каждая итерация будет выполняться с теми же данными, как и первая.
adjachenko
Ещё раз, другими словами — ЛЮБОЙ цикл заменяется на рекурсию. ЛЮБАЯ рекурсия заменяется на цикл, хвостовая особый случай и заменяется эффективно. Если вы с этим не согласны, мне больше нечего вам сказать — учите мат. часть. Если вы с этим согласны, тогда вспоминаем мой первоначальный тезис — на КОНЦЕПТУАЛЬНОМ уровне (т.е. игнорируя детали реализации в том числе производительность) присваивание и определение это одно и то же.
mayorovp
Ещё раз, другими словами — структурное и функциональное программирование это разные КОНЦЕПЦИИ, и не следует подменять одну из них другой.
tyomitch
Не вы ли пытаетесь подменить программирование на Rust функциональным, завлекая не соответствующим действительности лозунгом «достаточно всюду писать let и явно вытаскивать изнутри if изменения внешних переменных, максимум что вы потеряете — оптимизацию аллокаций»?
mayorovp
Вы это точно мне пишете?
tyomitch
«На концептуальном уровне (т.е. игнорируя детали реализации в том числе производительность) Rust то же самое что машина Тьюринга, поэтому давайте вместо кода на Rust писать таблицы переходов для машины Тьюринга»
PsyHaSTe
Любой код на С++ заменяется на ассемблер, любой ассемблер можно описать на С++. Если вы с этим не согласны, мне больше нечего вам сказать — учите мат. часть. Если вы с этим согласны, тогда вспоминаем мой первоначальный тезис — на КОНЦЕПТУАЛЬНОМ уровне (т.е. игнорируя детали реализации в том числе производительность) С++ и ассемблер это одно и то же.
adjachenko
Дальше идет псевдо ассемблер:
push state //сохраняем первоначальное состояние цикла в стеке
push condition // сохраяняем счестчик/условие
loop: pop condition
cmp condition 0
jne break
call body
dec condition
push condition
jmp loop
break: ...
body: pop state
work with state localy
push new state
ret
Смотрите здесь почтивсе так же как просиходит в любом языке. Разница в том, что любой язык добавит непосредсвтенно перед безусловным jmp что то типа
pop state
Это будет соответсовать drop, выходу из скоопа/окончанию времени жизни возвращаемого/локального значения из тела цикла. НЕТ никаких технических проблем не делать этот pop state. Да синтаксиса это выразить нет, ну так это не моя беда.
Самое близкое что есть в расте это
let x = loop{
break value;
}
Смотрите опять же циклы в расте НЕ выражения — т.е. что бы что то вернуть из цикла нужно вызвать break со значением. То что я написал на псевдо асме делает цикл выражением таким же как if, но возвращая значение на каждой итерации. Последнее значение может быть присвоенно внешней переменной, а промежуточные значения переходят на следующую итерации. Т.е еще раз это механика фолд через цикл + один уровень стека. Вобщем то он так и реализован в любом языке, только через явное присваивание state на каждой итерации. Таким образом хвоствая рекурсия которая нуждается только в одно уровне стека и никогда не приведет к SO, сама функция не вызавает сама себя, а возвращает результат для следующего вызова на стеке и уже внешний цикл делает этот вызов. Да только хвостовая рекурсия может быть так записана (т.к. в общем случае потребуется более одного уровня стека), но так это именно то во что конвертируются циклы. В любом случае я показал на этом примере как именно низкоуровневая механика ЦИКЛА, а не механика рекурсивного вызова прекрасно сочетается с переопределением вместо присваивания.
Я бы предложил например такой синтаксис:
а без let выглядит еще проще
Думаю можно и получше синтаксис придумать, это не суть. Суть в том, что любой цикл я вам через fold выражу, а этот фолд потом в цикл и преобразую. Синтаксис при этом будет как у родного ванильного цикла. К if выражениям уже все привыкли и оценили их по достоинству, почему циклы не сделали выражениеми — загадка.
anonymous
Проблема с размером аккумулятора для фолда.
Если мы не разрешаем менять внешний (для цикла) контекст, то в аккумуляторе должен быть вся изменяющаяся часть контекст (и возникает проблема с аллокацией, о которой уже упомянали).
А если разрешаем мутации внешнего контекста — то уже не возможна замена на фолд.
adjachenko
Мы все здесь ходим по кругу, по сути, вы от меня требуете предоставить вам работающий компилятор, да ещё и оптимизирующий, что бы алокации на присваивания заменял.
НЕТ его у меня и я пока не знаю/представляю как его сделать.
Все началось с того что без let ну никак нельзя, потом, сошлись что в принципе можно, но дескать надо все переписать на ФП, т.к. видите ли механика цикла не совместима с этим. Теперь уже и циклы не беда, только вот лядские алокации повылезали.
Я не думал глубоко над тем как оптимизировать переопределение и заменить его на присваивание, это не значит, что это уже кем то не придумано. Я почти уверен, что я вообще ничего нового здесь не придумал и уже есть десятки работ по CS где это уже лет как 30 все разобрано до мелочей в том числе как это оптимизировать, просто как это обычно и бывает ещё не пришёл тот человек/команда который все этого воедино соберёт.
Конечно я всего лишь анонимус из интернета, может я вообще gpt-3 бот, и верить на слово мне нельзя. Если вы убеждены, что такая оптимизация не возможна или представляет собой открытую проблему, то я бы послушал ваши аргументы почему вы так думаете — мне реально интересно.
Вот смотрите моё предсказание направления эволюции раста или его наследника — циклы станут выражениями, как я их здесь описал, присваивание уедет в ансайф (для тех случаев где с автоматической оптимизацией будет туго) со своим спец синтаксисом наподобие что был в паскале :=, let и mut исчезнет. За счёт этого аннотация лайфтайма сильно упроститься будет преимущественно автоматической примерно так же как сейчас type inference. Код будет выглядеть как будто написан на динамическом языке (в примере выше как раз демонстрируется смена типа переменной arr cо статического масива на вектор, но это уже и так доступно), но при этом будет полностью статически типизированным как сейчас.
Когда
мы построим коммунизмэто произойдёт я хз. Тут даже переход на раст идёт очень тяжело, всем не нравиться аннотации, а уж отобрать присваивание у рядового программиста это вообще кощунство за это сегоднясразуна хабре карму сольют.на костёр
Вот кстати меня это немного обескураживает, если я дичь говорю так перестаньте мне отвечать и/или заодно карму за минусуйте — это логично, дискуссия увянет сама собой и рот мне прикроет заодно. А тут так получается, одна рука (человек) рот затыкает, а другая (может даже те же самые люди, а может и другие) вступают в диалог и ждут ответа. Вот это вообще смысла не имеет. Не переживайте это не лично к вам, это так дань традиции высказать своё фу на систему кармы.
PsyHaSTe
А ещё на концептуальном уровне и быстрая сортировка и пузырьком — одно и то же, веть в итоге коллекция оказывается отсортирована! Или вот например — цикл и рекурсия одно и то же, зачем в компиляторах TCO завезли? Переписывают пустое в порожнее на ровном месте, нет чтобы оставить эквивалентные вещи в покое.
Вуяд? В расте где половина АПИ (начиная с примитивных вроде "считать с консоли строку") всё спроектированно вокруг "принять буфер от юзера чтобы не аллоцировать" аллокации это "никак не обоснованное требование"? Видимо вы просто не понимаете, зачем низкоуровневые языки используются и какие у них требования. Программа на расте которая слишком дофига аллоцируюет бтв будет медленее аналогичной программе на джавы или там хаскеле. А писать на расте который ещё медленнее ГЦ языка оказывается — грустная история.
tyomitch
Вы намеренно в пятый раз игнорируете циклы?
Там не просто так мутация переменной во внешнем скопе — там каждая итерация должна использовать значение, присвоенное в предыдущей итерации, что невозможно без мутации переменной во внешнем скопе, либо перекраивания структуры программы (из цикла в рекурсию и т.д.)
adjachenko
Я ничего не игнорирую, биг-бадабум абракадбра пышь оригинальный цикл который эквивалентен примру ищи выще по уровню. Это просто хабр имеет не самый удобный интерфейс комментариев да и вас таких много, а
дартаньяня один, тут лето в разгаре и новогодние каникулы уже закончились.Невозможное возможно, если немного почитать основы ФП, я там ничего нового не изобрёл. Как видите никаких рекурсий, хотя наложение ограничения на рекурсию
высосано из пальцаничем не обоснованно.tyomitch
Ну так я в шестой раз обращаю ваше внимание на то, что там не только «где вы использовали присваивание и вместо него используйте шэдовинг с явным возвратом значение из вложенного скоупа в том случае если мутировали не локальную переменную», но и перекраивание структуры программы с отказом от цикла.
PsyHaSTe
Можно вспомнить структурную теорему бома-якопини, где любую программу можно переписать с помощью одного гигантского свитча (для стейтмашины), циклом и ифчиками. Вопрос только, насколько это "теоретически верно" полезно на практике. Анекдот напоминает:
tyomitch
Уточню, что даже без ифчиков: достаточно одного свича и одного цикла. Movfuscator не даст соврать %)
AnthonyMikh
Если я опечатался в имени переменной, я хочу, чтобы это было ошибкой компиляции, а не тихим объявлением новой переменной.
adjachenko
покажите пожалуйста пример где компилятор(во вселенной где нет разницы в синтаксисе присваивания и объявления) не сможет распознать этой ошибки. Ну т.е. просто двух строчек не достаточно, нужно что бы из примера было явно видно как ожидаемое поведение расходится с реальностью и НЕ является артефактом использования побочных эффектов. за разъяснениями что я имею ввиду смотри habr.com/ru/post/532660/?reply_to=22488148#comment_22488470
Vilaine
Выше по-моему реалистичный пример.
amarao
вы главную претензию к эстетике Rust не объяснили.
Почему можно вот так вот:
но
Упор на синтаксис
println!. Им религия запретила завести f-expressions в макрос стандартной библиотеки?humbug
Можете развернуть свой вопрос?
amarao
Почему в rust не используют более краткие и человеколюбивые f-expressions (когда имена переменных in-line со сторокой форматирования) и используют С-подобный выкрутас, когда параметры в интерполируемой строке и значения параметров передаются раздельно?
0xd34df00d
В расте это вроде вопрос библиотеки. А неужто в питоне, со всей его динамичностью,
f-строки сделаны в ядре языка, а не библиотечно?tyomitch
В самом что ни на есть ядре: github.com/python/cpython/blob/master/Python/compile.c#L4150
0xd34df00d
Неожиданно, спасибо.
humbug
Окей. В стандартной библиотеке есть и такое, читайте модуль std::fmt.
amarao
Вы меня заставили ещё раз перечитать. Я так и не нашёл как можно захватывать перменные по имени. Я вижу, что можно по имени печатать аргументы, но это совсем не то же самое, что печатать переменные.
PsyHaSTe
Просто решили что в стандартной библиотеке это не нужно. Если есть желание, качайте любой из 100500 крейтов поддерживающих интерполяцию, например https://docs.rs/fstrings/0.2.3/fstrings/
amarao
Просто решили сделать неудобно. Просто ответ на вопрос который просто ничего не объясняет.
PsyHaSTe
Обычно всегда делают позиционные форматрования, а потом поверх когда-нибудь делают интерполяцию. Например я не уверен, что это будет работать если вместо имети будет произвольный экспрешн. В отличие от других языков где интерполяция это захардкоженный в компилятор синтаксис, в расте это обычный юзерспейс макрос, что накладывает ограничения, потому что макросы не всесильны.
AnthonyMikh
Не, вот конкретно
format_args!, на которыйprintln!в конечном счёте опирается, захардкожен.PsyHaSTe
Это уже да, но формат аргс который бы захватывал окружение был бы слишком магическим
amarao
Я не пробовал писать макросы раста, но я не вижу особой проблемы трансформации одного в другое. Главное же достоинство f-string в том, что можно захватывать имена переменных, что делает отладку кратно удобнее.
Mingun
Похоже, вы пропустили добавление макроса
dbg!. Он не решит вашу проблему с отладкой?amarao
ого, спасибо, не знал. Интересно.
PsyHaSTe
Ну а макросам в расте запрещено захватывать какой-либо контекст, потому что они гигиенические, и все что не передано явно в макрос попасть не может. Поэтому кроме только имени переменной он ничего не знает. А ему подозреваю одного имени мало, чтобы во время компиляции сгенерировать правильную строку.
amarao
на самом деле это тривиальная трансформация: f"{varname}" => "{}", varname.
ShashkovS
Для отладки в расте есть `dbg!` (что для отладки куда удобнее питоновских f-strings).
Mingun
Наверное решили, что незачем предлагать кучу вариантов сделать одно и то же в стандартной библиотеке, достаточно базового. А базовый это строки отдельно, параметры отдельно, потому что это позволяет компоновать макросы:
Если вы начнете засовывать подобные компоновки внутрь форматной строки, то
Amomum
Насколько я вижу, существует RFC, оно даже принято.
amarao
Жду с нетерпением!
freecoder_xx Автор
Как уже написали, под это есть готовый RCF и в редакции Rust 2021 вполне возможно он будет реализован.
PsyHaSTe
Отличная статья, спасибо.
Насчет претензий к синтаксису раста всегда предлагаю альтернативу: как по-вашему стоит изменить синтаксис чтобы стало лучше? И вот на мой вкус ни одна предложенная альтернатива не лучше, а многие просто хуже, особенно в части лайфтаймов. И только некоторые предлагают менять шило на мыло, например угловые скобки на квадратные. Но тут уже вопрос "из двух равноценных альтернатив команда языка должна была выбрать какой-то один". Тем более что угловые используются чаще: Java/C#/Typescript/C++/...
Что до лямбд: то текущий синтаксис позволяет например деконструкцию в аргументах
Другие языки, например сишарп, на таком примере буксуют и не могут отличить деконструкцию пары от лямбды с двумя аргументами. И приходится писать уродцев в стиле
или
tyomitch
В Eiffel, Python и Scala квадратные, в D и VB.NET круглые.
AcckiyGerman
Python2 тоже умел, но в pep-3113 распаковку аргументов выпилили, так что Python3 так не умеет.
AnthonyMikh
Причём выпилили под совершенно, на мой взгляд, притянутым за уши предлогом.
tyomitch
То, что он выглядит притянутым за уши в 2021, не значит, что он выглядел притянутым за уши в 2007.
syrslava
Или о том, как я наконец-то решил поучиться Rust — его синтаксис очень уж нравится)
nivorbud
Имхо, вопрос о синтаксисе слишком субъективно индивидуален. Например, я психологически не переношу знак доллара перед переменными и плитки в винде. Логически я могу понять плюсы плиток, но… по факту у меня глаза становятся врастопырку, всё ералашит и ничего не могу с этим поделать. Смотрю на плиточный интерфейс и ничего не вижу. А кто-то плитками нормально пользуется. А вот к фигурным скобкам я почему то отношусь спокойно. Так что я думаю, проблема неприятия некоторых синтаксисов и интерфейсов индивидуальна и лежит в психологической плоскости.
Что касается вышеприведенных примеров, то некоторые вещи мне явно не по нраву. Например, разное поведение вызова функции с точкой с запятой на конце и без таковой. Как я понял, без точки с запятой подразумевается неявный return. Правильно? Но здесь нарушается принцип: явное лучше неявного. Да и точку с запятой легко пропустить/не заметить.
mayorovp
Точка с запятой влияет не на return, а на результат: без неё что вычислили — то и получилось, с ней получается всегда
()kotlomoy
Надеюсь, для людей, рекомендующих «правило спирали» в аду есть отдельные котлы. Помню, на stackoverflow тоже все рекомендовали, не разобравшись. За десять лет, наверно, уже можно было понять, что это правило неправильное, нет? Как оно разберет эту строку, например?
А никак, потому что это бред.
Вот есть нормальное правило «право-лево»: cseweb.ucsd.edu/~ricko/rt_lt.rule.html
1. Сначала разбираем всё справа.
2. Потом разбираем всё слева.
3. Если есть круглые скобки, то порядок меняется, как в арифметических выражениях.
Всё.
gatoazul
Заметно, что авторы языка Раст вдумчиво изучали синтаксис разных языков. В отличие от хейтеров синтаксиса Раст, которые кроме С-подобного синтаксиса никогда ничего не видали, и объявление типа не в том месте вызывает у них когнитивный диссонанс.
tyomitch
Когнитивный диссонанс вызывает то, что в английском (как и в русском) определение идёт перед определяемым словом, поэтому «int n» читается как текст на родном языке, а «n: int» — как будто по-албански.
AnthonyMikh
b— указатель или просто целое? А если так:?
tyomitch
Уже в Java этих заморочек нет:
int[] a, b;трактуется вполне однозначно.PsyHaSTe
К слову можно вспомнить воспоминания лида команды C#, который пожалел, что в сишарпе выбран "сишный" синтаксис "сначала тип, потом имя" (пятый пункт сожалений).
tbl
в тайпскрипте Андрес Хейлсберг решил не повторять своей предыдущей ошибки и исправился
PsyHaSTe
Да. Тенденции современных языков как раз показывают, что var: type это самый естественный для восприятия способ записи.
Mingun
Да ладно. В толковых словарях наоборот. Полагаю, что в любых языках
tyomitch
Как минимум, в Оксфордском словаре я вижу «Red Army», «Red Cross», «red giant», «Red Sea» именно в таком написании:
archive.org/details/oxfordenglishref0002unse/page/1208/mode/2up
Можете привести пример толкового словаря, где бы было наоборот? На любом языке.
mayorovp
А где в названии "Red Army" определение, и где определяемое слово?
tyomitch
Красная — определение, армия — определяемое слово.
ru.wikipedia.org/wiki/Определение_(синтаксис)
red75prim
Армия, которая когда-то была названа красной, ...
Mingun
Как вам уже намекнули, вы привели только определяемое слово, а самого определения нет. Я же не зря сказал толковый.
А вот нежирный текст по вашей ссылке — как раз определение, и оно после определяемого слова.
tyomitch
Как я уже намекнул, вам бы для начала вспомнить из школьной программы, что такое определение и что такое определяемое слово. Ссылку на википедию я дал.
Mingun
Вот давайте не переходить на личности. Если все же хочется, то не помешало бы также и вспомнить, что значит "толковый" и что там является определениями, а что определяемыми словами (в общем случае, конечно же, предложениями).
tyomitch
Тогда покажите хоть один источник, где бы понятия «определение» и «определяемое слово» использовались не со школьными значениями, а с вашими.
Намекну, что нежирный текст в толковом словаре называется толкованиями — оттого и название словаря.
PsyHaSTe
А можно перестать докапываться "До фонаря" и понять, что имелось в виду под токсичностью — в частности, это можно читать как "Недружелюбность", имея в виду что недружелюбный синтаксис — это вполне понятный для всех присутствующих термин. Если у вас проблемы с тем, что слово "токсичный" стало очень популярным в этих ваших интернетах и его используют направо и налево — ну, держите наверное свои чувства при себе, срач на сотню комментов ради этого разводить наверное не стоит.
А уж просить "определение определения" это уже куда-то совсем глубоко в демагогию, некрасиво так делать.
tyomitch
Я где-то выражал недовольство словом «токсичный» или просил «определение определения»?
Использовать термины из школьной программы, придавая им собственное, никем другим не используемое значение — вот как некрасиво делать.
PsyHaSTe
Ниже я ответил по существу: законы естественного языка и законы формального — различаются. Точно так же в естественном языке мы скажем Московский авиационный институт ордена Ленина и октябрьской Революции имени Серго Орджоникидзе, а на формальном — Московский ордена Ленина и октябрьской Революции имени Серго Орджоникидзе авиационный институт. Хотя казалось бы
ookami_kb
n: intсовершенно естественно читается какn of type int(во всяком случае, у меня).tyomitch
В быту вы тоже говорите «пиво производства Бельгии» вместо «бельгийское пиво», и «двигатель системы Дизеля» вместо «дизельный двигатель»?
ookami_kb
Во-первых, аналогия, на мой взгляд, не совсем корректная. Пусть "пиво производства Бельгии" я не говорю, но с чтением строки "Пиво (Бельгия)" в каком-нибудь интернет-магазине у меня проблем не возникнет. Никто не читает по словам, всегда сканируется больший объем информации (например, предложение/строка).
Во-вторых,
n of type intзвучит вполне себе нормально, как уточнение типа переменной, если это важно в контексте. Особенно в языках с выведением типа, где тип переменной может опускаться. В этом случае даже проще бегло читать, потому что знаешь, что название переменной будет всегда, и оно всегда будет на первом месте, а вот тип – это дополнительная информация и может опускаться.В-третьих, это довольно популярная практика, это же не Rust решил сделать "не как у всех": Typescript, Kotlin, Scala, Python, Swift, Go.
PsyHaSTe
Обычно говорят просто "Пиво", а потом если клиент приподнимает брови уточняют "Бельгийское, Светлое". Вот так и в ЯПе пишут
А если непонятно, то уточняют
tyomitch
Синтаксис моей мечты:
Машиной парсится без проблем, человеком читается как проза, но нигде так делать не стали : С
PsyHaSTe
Мне не нравится. Как раз потому что получается лесенка из имен. с летми я могу с расстояние в 2 метра увидеть все места где происходит инициализация, потому что они задают видный паттерн.
Ну и плюс я процитирую уже линкуемую статью Липперта:
Обратите внимание на «bizarre conventions of predecessor languages». Это оно и есть. Ваш вариант думаю получше, чем то что щас принято в С++/..., но варианту с летом он уступает. И это при том что я сам с сишарпом то уже почти 10 лет знаком, и синдром утенка по идее должен быть силен. Но оказывается, что леты очень удобны. А синтаксис type first, name later — не очень. Особенно когда у вас в реальном коде возникают вещи вроде:
Кмк куда аккуратнее записывать:
Ну и все же я почти уверен что ваш вариант парсить сложнее, потому что с &CustomSettingsMerger непонятно, это мы берем ссылку на переменную с именем CustomSettingsMerger (и дальше будет например присваивание) или это имя типа Ref<CustomSettingsMerger> (что имеет место на самом деле в нашем случае)?
tyomitch
С функциями не всё так однозначно: по-русски «строковая функция» может означать как возвращающую строку, так и принимающую строку, и запись на ЯП, аналогичная «функция, возвращающая строку», безусловно понятнее, чем в сишном порядке. Есть и третий вариант:
fn foo: int (string x, char y)— с типом результата после имени функции, но перед параметрами — с дополнительным преимуществом, что обозначение типа функции сгруппировано компактно, без имени посередине, как в C++.Но претензия Липперта к тому, что синтаксис лямбды резко отличается от синтаксиса обычной функции, применима и к Rust.
В моём варианте (с явными словами val и var) такой проблемы нет.
Не вижу проблемы: syntax tree в обоих случаях одинаковый.
PsyHaSTe
Но ЯПы все же строятся на англоязычной грамматике, поэтому подходит с двусмысленностями русского языка к этому как-то странно
Как раз в расте лямбда описывается как
let x: fn(i32) -> i32, а функция описываестся какfn x(i32) -> i32. Как по мне, один в один, разве что имя функции в одном случае встречается в середине, а в другом случае в начале. Я бы предпочел в ML стиле чтобы всегда объявлялось как лямбда (как кстати в JS щас модно делать), но в целом максимально близко в терминах сишного синтаксиса.Во-первых val и var в целом похожи до смешания, разглядеть в коде разницу очень сложно. Во-вторых насколько я знаю они разделяют по сути только мутабельность, а тип у них один и тот же — "переменная" (не в том смысле что она меняется, а в том что это именованный биндинг чего-либо).
В одном случае это
Reference { lifetime: ImplicitLifetime, value: Expression(Identifier("CustomSettingsMerger")))а в другом
Type(ReferenceType { lifetime: ImplicitLifetime, target: Identifier("CustomSettingsMerger") }) }Что-то не очень одинаковый.
tyomitch
В этом конкретном аспекте между ними разницы нет.
Я про окружение параметров символами, которые во всех остальных контекстах означают «или».
В Kotlin и Scala —
valиvar, в C# и JavaScript —constиvar; мне оба варианта одинаково понятны.Для функций я в том же комментарии предложил
fn. В любом из случаев, в определении явно прописано, переменная это, функция или что-то ещё, — в отличие от C++/Java.Если и так, то один в другой тривиально конвертируется, как только парсер доходит до
var; не нужен backtracking и повторный разбор. Ничего похожего наa*b;в С++, которое то ли умножение, то ли объявление указателя — на этапе парсинга определить невозможно.0xd34df00d
Каков синтаксис дженериков? Опять всякими скобочками обмазываться?
В расте они, конечно, и так есть, но мы ж про идеальный синтаксис говорим.
tyomitch
Мне нравится, как в VB.NET сделали
List(of x): опять же, читается как проза.0xd34df00d
А как для начала выглядит хешмапа из строк в списки x'ов? Дальше можно обсудить читаемость аналога
Lens s t a bили типов позабористее.AnthonyMikh
"Lenses give me a
s t a bto my eyes"0xd34df00d
Видел эту шутку в варианте «I took a s t a b at lenses»
gatoazul
В естественных языках не бывает глубоко вложенных сложных определений. Поэтому они никак не могут тут служить образцом.
А сишная манера даже при небольшой сложности практически нечитаема, да еще и парсинг контекстно-зависимый.
tyomitch
«Тип перед названием» не обязательно означает «сишный синтаксис».
Уже в Java нет сложностей ни с читаемостью, ни с парсингом типов.
symbix
Не думаю, что стоит сколь-либо серьезно относиться к комментариям на опеннете — там такая атмосфера, которая привлекает либо троллей, либо очень, так скажем, странных людей.
Претензии к синтаксису обычно возникают у тех, кто программировал на одном-двух похожих языках, и сводятся к тому, что непривычно.
На самом деле к любому синтаксису привыкаешь через 3-4 недели активного использования языка, и то, что казалось странным, перестаёт таким быть и становится совершенно естественным. А объективные, действительно обоснованные претензии к синтаксису могут быть после минимум полугода опыта активного программирования на языке, но за это время обычно и к объективным недостаткам привыкаешь — ну вот просто тут оно так, в других языках другие недостатки, ну и что :)
adjachenko
Я со своим мнением могу оказаться в обсалютной оппозиции ко всем, но мне все равно интересно мнение некоторых комментаторов. Я думаю что фундаментальная проблема всех (мне известных) языков это аксиома что запись/набор исходного кода должен продуцировать тот же код что мы читаем, т.е. концепция висивиг реализованная на самом примитивном уровне текстового редактора — блокнот.
Моя позиция в том что если не разделить две активности: написание и чтение кода на уровне дизайна языка, то всегда будет получаться и кастрированный(не достаточно выразительный) и не однозначный(одно и тоже может иметь более одного синтаксиса и один и тот же синтаксис может иметь несколько значений) язык одновременно.
Когда я пишу код я хочу бескомпромиссной выразительности, чтобы каждая нажатая клавиша решала для меня кучу технических скушных проблем. Когда я читаю код, я хочу как можно меньше тратить времени что бы привести мою ментальную модель того что я ожидаю этот код делает к реальности — тому что на самом деле делает код — понять что там вообще происходит.
Бескомпромиссная выразительность замедляет понимание кода, а ускорение понимание кода делает его многословным. И невозможно в рамках традиционного дизайна ЯП разрешить это противоречие.
Создатели Раст, как и любого другого языка, заявляют что они якобы нашли наилучший компромис, а на самом деле диктуют свою волю/видение того что лично они считают правильным/удобным/лучшим синтаксисом. Это как спор о том что мои настройки водительского места для моего тела лучше чем все остальные, только речь о мозгах — мой набор привычек лучше вашего.
Мне кажется есть другой путь, другой дизайн ЯП который может дать больше если и не полностью разрешить конфликт чтения/написания моих/чужих предпочтений то значительно сгладить эти противоречия.
PsyHaSTe
Много пафоса, мало конкретики. Покажите язык с "разделением написания и чтения на уровне дизайна", а мы попробуем оценить преимущества.
0xd34df00d
Мне в голову только Coq приходит с его тактиками, когда ты пишешь там какое-нибудь (пардон за заведомо некорректный синтаксис, я Coq ковырял из интереса полтора года назад и забыл его как страшный сон)
и здесь
omega— это тактика, то есть, этакий скрипт, который генерирует здоровенный зависимо типизированный пруфтерм (или говорит, что не может), который и является телом этой функции. Пишешь мало, выражаешь много, и язык внутри себя там что-то раскрывает.Правда, как видно из этого примера, оно работает немного в другую сторону: читать чужой (или сгенерированный по тактикам) код я никому не рекомендую.
nikbond
Мои мысли, учитывая другие комментарии здесь:
1. Обсуждать синтаксис языка — это нормально, «шашечки или ехать» тут не при чем. Дизайн языка связан с его синтаксисом, все вместе влияет на эффективность работы программиста, поэтому это важный параметр, особенно если говорить о более менее объективных вещах, а не о "<> vs [] для дженериков".
2. «Токсичность» здесь — это такой художественный оборот, ничего ужасного в этом слове нет.
3. Никогда не встречал проблем с синтаксисом раста, проблемы были исключительно с семантикой — особенно в вопросе заимствований и лайфтаймов. К синтаксическим особенностям адаптируешься очень быстро, тем более что синтаксис вполне похож на мейнстримные языки, просто с дополнениями. Это ж не МЛ и не лисп, чтоб заново внутренний парсер прокачивать на полностью новом синтаксисе.
playnet
Отойдя от C(++) и rust: часто работаю с амазоном, и там есть такая штука для автоматической выкатки инфраструктуры как CloudFormation. И оно понимает 2 формата, json и yaml. Если кто не знает — json это а-ля С++ стиль, с кучей {}, а yaml — а-ля питон, с отступами пробелами. Когда я пришёл в проект, 2 человека работали в формате json, но для меня это была боль. Перенёс блок кода, всё сломалось. Где-то одна из скобочек потерялась, а ругань валидатора там в стиле «плюс-минус в этом файле потеряли скобку». Да, работаю я обычно в vim или блокноте, поэтому не ощутил мощь IDE которые (обычно без проблем) умеют в перемещение блока.
Потом я открыл для себя cfn-flip, и у меня появился локальный гит уже с yaml версиями, которые перед коммитом в основную репу надо было конвертировать назад. К счастью, появился ещё новый сотрудник, который тоже оценил всю мощь yaml и мы убедили старую команду что пора переходить глобально. Бонусом там ещё ряд плюшек появился, вроде поддержки комментариев и упрощённый синтаксис, но это уже оффтоп.
И огромным бонусом 2 момента:
— Код стал в 2 раза меньше по строкам и короче в длине строк
— стало удобно работать в любых текстовых редакторах, а не только в «специальных IDE»
И пока писал, вспомнил про свой старый опыт общения с программистами того же php — форматирование текста компилятору не важно, поэтому ВЕСЬ код мог быть как в одну строку, так и разными, но без отступов, РАБОТАЕТ ЖЕ. А python-стиль всё-таки ломается без форматирования, так что другим людям с кодом можно работать без применения IDE, которые переформатируют код как нужно (и привет системы контроля версий, для которых это уже новый код).
Такие дела.
nugut
У меня с YAML обратная история: стоит немного ошибиться с отступами и вся конструкция летит к чертям. Такое, кстати, часто случается как раз при копирования со страницы примера в vim.
Когда писал в YAML код с достаточно большой вложенностью (Ansible, Kubernetes, Docker Compose и т.п.) как раз форматирование отступами добавляло боли.
Для того чтобы работать с многочисленными скобками, достаточно вспомнить что у vim есть команды перехода по скобкам и сворачивания блоков. А также подсвечивание скобок.
JSON — это не С++ подобный стиль — это валидный Javascript.
tyomitch
Это и валидный Python тоже.
ZyXI
Кстати, валидный JSON — это ещё и валидный YAML.
PsyHaSTe
Ну отсутпы часть структуры, точно так же если не написать скобки в других форматах будет ошибки. В целом, с отступами кажется что труднее набирать, но по факту не особо. По крайней мере если есть редактор который понимает yaml и умеет например сам отступы создавать для подуровней. Или когда вы пишете "минус" сразу понимает что щас будут перечисления масссивов и автоматически выравнивает текст "на основании текущего уровня вложенности". Хотя для достаточно больших файлов мб и неудобно, больше нескольких сотен строк не было нужды писать.
mayorovp
Ну так в том-то и проблема, что они часть структуры, но при этом не всегда корректно копируются-вставляются.
Кстати, говоря о форматах конфигов, мне как-то последнее время очень TOML нравится...
PsyHaSTe
Даже при копировании-вставке IDE обычно правильно поправляет форматирование: вставляет или убирает нужное количество вложенности.
В общем, в теории проблема есть, на практике не встречал: если в питоне проблемы ещё бывают из-за интерпретации, то с ямл или там хаскеллем уже нет.
Ruslannn
Спасибо за развернутую статью, сохраню себе
edward_gray
Каждый новый язык, когда он появляется на свет — он дитя своего времени
Не думаю, что можно ругать синтаксис Assembler, Forth и Pascal )
tyomitch
Очень большая разница: в отличие от Forth, C, Perl и т.п., созданных инженерами для инженеров, Pascal разрабатывался именно ради читаемости кода — профессором для использования в своём курсе.
alisarin
На мой взгляд такое понимание — это заблуждение программистов, хотя и вполне объяснимое. Более того, существует не просто идея такого языка, но и практическая реализация — язык макрокоманд Access. Конечно, эта реализация «мало чего» дает, но для тех кому само собой программирование просто «без надобности» это очень удобно, если нужно просто порезвиться в рамках такого «мало чего», то — не нужно ничего особо изучать, просто понимать как называются объекты в Access — таблица, форма и т.д.
Или, если перейти к философскому осмыслению, то, наверное, не изучал что такое программирование с семантической точки зрения; как можно предположить, оно вряд ли далеко ушло от обыденной семантики и в любом случае, в рамках решения тривиальных задач, а не «тяжелой» математики может допускать перевод и на язык тривиальной семантики.
strcpy
Я два года назад загорелся идеей языка Раст и выделил месяц, чтобы изучить его. В целом я разочаровался даже не потому, что какой-то непривычный синтаксис, а потому что это все слишком сложно, всё время ругается статический анализатор. Чтобы написать программу, которая на C++ делается за 10 минут, надо час. То есть со всеми этими оунершипами — очень много возни в обмен на гарантию отсутствия NPE — это слишком дорого. Мне кажется более перспективный язык — v-lang, он еще сырой, но концептуально это как раз то что нужно — автоматическая сборка и за счет этого скорость. Для тех объектов, которые не могут зациклиться — подсчет ссылок, для остальных — анализ циклов.
freecoder_xx Автор
В обмен на гарантию отсутствия не только NPE, но и UB на ровном месте. Вообще, после нескольких месяцев интенсивного использования Rust мозг перестраивается и борьба с borrow-checker прекращается. Дело привычки.
strcpy
Несомненно в C++ куча мест где можно на пустом месте схлопотать UB. Если бы только эти дыры заткнули, было бы уже значительно лучше. Мне кажется, что вся эта свистопляска с borrow cheker-ом, она больше проблем создает чем решает в смысле цены разработки софта.
PsyHaSTe
Ну вот вам раст эти дыры заткнул, а вы недовольны что "всё сложно и анализатор постоянно ругается" :shrug:
inv2004
попробуйте Nim, в него уже кстати завезли borrow-checker, но не такой строгий как в Rust
AnthonyMikh
То есть никакой. Нельзя быть немножко unsound, также, как нельзя быть немножко беременной.
inv2004
Это у вас IT-софистика. Но намекну что вы будете делать тоже самое в расте, только руками делая clone или расставляя Rc
Alexei_987
Посмотрите вот эту статью и видео ради интереса — https://habr.com/ru/company/rambler_group/blog/533268/
Тут как раз хорошо иллюстрируется идея что можно взять программу допустим на питоне (или С++) и написать за 10 минут, а на Расте это займет час. Но мало кто в работе пишет программы за 10 минут и выбрасывает...
А вот если взять уже программу которую на Питона надо писать хотя бы 1000 часов…
То внезапно окажется что такую же на Раст можно написать за 700. Потому что экономится куча времени на дебаге и рефакторинге.
PsyHaSTe
Посмотрел статью, описанного вами вывода я там не увидел. Давайте возьмем пример первый из статьи:
Переписали:
Видим, что типы не совпадают — поп из пустого вектора вернет None. И тут у нас есть два варианта: в серьезном аппе мы конечно же вернем опшн, выше где-то уже будем проверять что значение есть и дальше писать какую-то логку.
А можно сказать в стиле питона "да и хрен с ним, падай если значения нет" и написать:
Получим ровно то же поведение что и в питоне, и все успешно собирается. Просто в расте не принято забивать на обработку ошибок как это делается в динамических и даже статических мейнстримных япах, там вы явно контролируете "да, я хочу отстрелить себе ногу". В условных тестах например я так и пишу, там никакой особой чистоты во-первых не надо, во-вторых если прекондишн теста не прошел то упасть — совершенно нормально, я и так практически на самом верхнем уровне принятия решения, выше прокидывать просто некому.
Сколько времени нужно чтобы написать анврап? Ну, у меня это заняло секунды три. Хотите так писать — пожалуйста, никто не запрещает. Так что даже вот эти "10 минут на питоне — час на расте" верно только для сценария "пишем идеоматично". А если "пишем как на питоне" то будет минут 15. С такими же рандомными отваливаниями в рантайме "ой, вместо числа была строчка", но зато быстро.
Alexei_987
Этот вывод дают докладчики в своем видео… Понятно что с простыми примерами эффект не так заметен. Как раз там они и говорят что он начинает заметно проявлятся именно на достаточно большой кодовой базе.
tyomitch
Если писать «как на питоне», то какой смысл делать это на Rust?
Можно забивать гвозди отвёрткой, но молотком будет быстрее, а отвёртка полезна совсем для другого.
PsyHaSTe
Чтобы не разводить 10 языков на проекте, например. Ну или растовик на расте наскриптует быстрее, чем на питоне если он его не знает. Мало ли какие сценарии бывают.
Вообще я лично для скриптов шарп юзаю: он менее заточен на корректность, но ноги отстрелить не дает.
PsyHaSTe
А можете привести пример, что вы пытались сделать и как компилято ругался? Потому что честно говоря мне не очень легко представить ситуацию где на хелловорлдах компилятор будет как-то ругаться. Сложности начинаются только при попытке сделать уже что-то более-менее продвинутое: потоки посоздавать, тип дерева сделать и вот всякое такое.
Alexei_987
Из моего опыта:
При написании даже несложного асинхронного кода можно получить очень странные ошибки которые связаны с попыткой переноса типов не реализующих Send через точку await (например обычный синхронный MutexGuard). ИМХО в этом месте компилятор выдает очень странные и неочевидные сообщения об ошибках до понимания которых я дошел только сильно позже когда разобрался как именно работают Futures.
PsyHaSTe
Ну "несложный асинхронный" в расте это просто оксюморон. Человек который начинает знакомиться с япом вряд ли пойдет сразу в асинки, тут и более подготовленному человеку утонуть можно. Хотя, если так и было, то претензия понятна. Но скорее схожа с попыткой "просто прыгнуть по случайному адресу в Java, ведь в ассемблере это у меня было одной из первых лаб!". некоторые вещи просто не делатся просто в каких-то других языках.
warlock13
Вот не верю я в такое. Я иногда вообще сомневаюсь, что программу на C++ можно написать. Потому что решительно непонятно как это вообще можно сделать. А ещё интереснее — как убедиться в том, что ты и правда это сделал?
0xd34df00d
Эмпирически — можно ощущать себя экспериментальным физиком. Особенно когда оно взрывается потом.
AnthonyMikh
Медведников, перелогиньтесь.
0xd34df00d
Это вы просто не бегали по стандарту, чтобы проверить, есть ли у вас в этой строчке UB или нет.
strcpy
Моя программа good enough, я запустил ее с валгриндом, ничего не падает, мне этого достаточно. Растовая программа с тем же успехом может вылететь по out of bounds или грохнуться в анмэндж/нативном коде.
AnthonyMikh
Вы же понимаете, что тестирование может показать наличие ошибок, но никак не их отсутствие?
… Там, где аналогичная программа на C++ портит память.
Надо же, совсем как C++!
chapuza
В точности, как и все без исключения остальные техники проверки корректности более-менее сложного кода.
Ну да, вам ровно про то и говорят же. В точности, как
c++.ZyXI
А что такое «анмэндж/нативный код» у Rust?
nikbond
Но ведь это только в первый раз. Со временем, в какой-то момент вы поймете что пишете на расте быстрее, чем на С++. И эффективней. И красивее. И выразительней. И безопасней, конечно же. И не только чем С++, но и чем добрая половина разных высокоуровневых языков.
Так что нет, это не «слишком высокая цена», просто у раста кривая обучения не похожа на иные языки. И это известный факт.
inv2004
Даже находясь в верхних 5% на этой кривой, вы будете писать значительно дольше чем программисты на 90% других языков, находящихся в 5% в своих языках.
strcpy
Нет конечно. На js сам язык вытрет за мной мусор. На C/C++ я сам должен вытереть, от этого программы становятся больше и писать их дольше. На Rust я должен доказать компилятору что с памятью будет все ОК. Поэтому на раст программы получаются еще более сложными и написание еще более тяжким. Стоит ли оно того? Если программируешь кодек какой-то, хайлоад вебсайт или космический корабль — наверное да, не исключено. Однако для огромной части задач эта сложность программирования не спасает от других багов, а цена работы растет.
AnthonyMikh
Я что-то пропустил или в программировании все задачи, кроме управления памятью, уже решены?
chapuza
Кому известный? На какие «другие»? Чем именно не похожа?
Раст — всего лишь еще один низкоуровневый язык, появление которого бы вообще никто не заметил, если бы не хайп по типам и не агрессивный маркетинг. Даже Julia извне пузыря — выглядит в разы более продуманной. Через несколько лет спираль сделает очередной изгиб — вот тогда и посмотрим.
Говорить про что-то, в чем сам уже освоился, мол «это сложно,
не всем данокривая обучения особенная» — очень смешно и не очень вежливо. У понимания доказательства гипотезы Римана — кривая действительно крутовата. У очередного говноязыка, каких было и будет сотни — никакой особенной кривой нет, код пописал месяцок — и уже мидл.PsyHaSTe
И да, и нет. Смотря с чем сравнивать. Если посмотреть на континуум используемых языков, то раст в стороне в более сложной области, где-то наверное на полпути от мейнстрима к хачкелю\скалке. Если бы это был инопланетный язык который никто не знает (Как какая-нибудь агда), тогда разговора бы и не было, потому что мы берем не все языки, а только на которых реально работу найти хотя бы если ищешь.
chapuza
Шутите, что ли? Вряд ли существует более дубовый и простой с точки зрения синтаксиса язык, чем хаскель. У него высоченный порог входа из-за дикого хлама в prelude и миллиарда способов чихнуть в любом месте. Так-то только лисп проще. Скала без дикого синтаксического сахара — абсолютно внятный и очень красивый язык с минимальным порогом входа; да гиковский сахарок постепенно превращает ее во write-only сущность, но это никак не повышает порог входа, опять же. Можно легко проработать десять лет на скале и думать, что это котлин, если не лезть в дебри.
Я лично не вижу ничего концептуально сложного в расте потому, что там ничего такого и нет. Даже трансформации данных в
R, или неявные преобразования типа в COBOL требуют куда большего умственного напряжения при попытке их понять, чем весь раст вместе взятый.Так что нет, не убедительно. Синтаксис, как синтаксис — не лучше, и не хуже остальных.
PsyHaSTe
Дело не в синтаксисе, а в концепциях. HRTB например это rank-2 лайфтаймы. Не только лишь всем легко в этом разобраться, разработчики команды C# говорили что значительную часть аудитории составляют люди которым обычные генерики сложно, и от
struct Array<T>у них уже голова болит.Ну а эти концепции в свою очередь рождают необходимость их как-то записывать, отсюда появляются синтаксические записи которых нет в других языках -> раст ругают за то что его синтаксис "сложный".
0xd34df00d
Haskell 98/2010 — да, простой. Haskell as in ghc со 100500 расширениями системы типов, которые больше похожи на костыли, чем на планомерное движение в сторону завтипов — ну так себе. Ну или, скажем так, мне проще писать завтипизированный код на идрисе или агде, чем (достаточно продвинутый, но не завтипизированный) код на хаскеле.
chapuza
Да, я упростил «as in ghc со 100500
расширениямикостылями» до «дикого хлама в prelude и миллиарда способов чихнуть» потому что ноги костылей растут именно оттуда.Разумеется, на идрисе писать проще (для агды мне надо освежить нотацию, но не думаю, что это станет прямо порогом, просто пока соль была). Проще потому, что идрис разрабатывался с учетом родовых ошибок хаскеля, и даже небольшой рефакторинг пакетов 1 > 2 не вызывает ни одного wtf. Ну а еще — [nb непопулярное мнение] — проще потому, что зависимые типы — это очень изящная, внятная, полезная, целостная и непротиворечивая парадигма. А типы, как в хаскеле — это попытка натянуть сову на скелет мамонта.
В хаскеле (и всем остальном независимо типизированном, привет, Куба) — типы это помощь компилятору, которая на каждом шагу вставляет палки в колеса разработчику. А в идрисе/агде — это помощь разработчику, милостиво предоставляемая компилятором.
Модуль один, но какие разные векторы!
0xd34df00d
ИМХО оно вполне себе популярное. По крайней мере, я с ним полностью согласен, и знаю много других людей, которым с ним полностью согласны.
А вот тут уже несогласен. Если не выпендриваться, то типов в хаскеле почти всегда достаточно.
freecoder_xx Автор
Дело не в синтаксисе, а прежде всего в том, что правила владения и заимствования, а также контроля времен жизни ссылок, не имеют аналогов в мейнстримных языках. Не получится войти быстро, переиспользуя свои прошлые навыки, приходится учиться программировать заново, в соответствии с этими концепциями. Это трудно.
inv2004
Не имеют аналога === прямо заимствованы из c++
AnthonyMikh
Покажите мне, пожалуйста, рабочий анализатор времён жизни для C++. Только не надо про
-Wlifetime, он сломан.0xd34df00d
Я работу пока ещё не ищу, но ко мне уже постучались, сначала предлагая писать просто на всякой функциональщине, а потом, увидев упоминание агды и идриса в резюме и чуть более серьёзный, чем доказуемые сортировки, проект на агде, сказали «о, чувак, это круто, такое нам тоже нужно, можем обсуждать работу с формализацией нашей ерунды».
PsyHaSTe
Слушай, я прекрасно понимаю, что у тебя ситуация другая. Но ты не часть рынка, ты "вне" его. Я вот с недавних пор кручусь в около-ФП тусовке, так лица одни и те же везде. Мой коллега из чатика со смехунчиками нашел работу на хачкеле и оказывается что он теперь работает с другим чуваком который админит канал по завтипам (и с которым я заочно тоже давно знаком) и с третьим чуваком, с которым я знаком через третьи руки. Даже не завтиповой, а просто ФПшный мир очень и очень тесен, он на порядки меньше какого-нибудь "жаба ворлд"а. Это мне напоминает статью на хабре, где челик сказал как легко без гринкарты попасть в штаты, достаточно иметь 3-5 публикаций в журнале и тебя по О визе перевезут. Блин, если бы у меня были скиллы публиковаться в журналах я бы наверное на сишарпе бы и не писал.
Такое ощущение, что я просто слишком глупый для этого. У меня нет достаточного уровня ненависти к себе чтобы идти в банк или заниматься HFT на плюсах. При этом у меня недостаточно мозгов чтобы заворачивать топосы в левые сопряженные, я не МГУ заканчивал, а средненький московский ВУЗ с преподами за 70 преподающих GPSS и фортран с паскалем, из которого я вынес разве что умение искать информацию. Чего в целом хватает чтобы иметь ЗП выше среднего во МСК (хотя и существенно если не в разы ниже условных сберов), но базы для роста куда-то в науку не дает, тем более что тратить уйму времени впустоту не получается, мотивация под ноль скошена непонятностью перспективности такого направления.
0xd34df00d
А это, кстати, интересно: для того, чтобы опубликоваться в локальном «вестнике» твоего вуза, особые скиллы не нужны. А он тоже вполне может быть ВАК-аккредитованным или вообще даже быть в Scopus/WoS.
Это даже хорошо. Занятие это почти заведомо бесперспективное (особенно по деньгам), поэтому оно и хорошо, да. Иногда мне кажется, что лучше бы, если бы я не выпендривался и дальше писал код на плюсах (или, хрен с ним, на расте). Ну падает иногда, ну какие-то баги там, ну ерунда в проде — ну и хрен с ним. Компайлер крутится, лавеха мутится.
PsyHaSTe
Не знаю насчет вестника, я в свое время пробовал получить хотя бы универскую почту чтобы всякие джетбрейнсовский и майкрософтсвие софтины по учебной программе бесплатно получить. Года полтора окучивал деканат, в резултьтате не добился ничего.
tyomitch
Хмм, а как узнать? Особенно если я не помню точно его длиннющее название.
0xd34df00d
Системно — не знаю, я у научрука спрашивал :]
Бывает ещё прикольнее, кстати, когда публикуешь статьи в каком-то совсем местном шарагожурнале, а потом он получает аккредитацию, и твои статьи ретроактивно оказываются в списке ВАК. Мы так на кафедре развлекались созданием журналов (моя сокурсница даже там редактором успела поработать, кажется) и публикацией в них статей, а потом к моему шестому курсу он стал ваковским.
lanseg
А у меня так же пригорает от синтаксиса go. Чего стоят только бесконечные if err != nil, мутные тестовые фреймвор и ошибки компиляции при неиспользуемое модуле, или переменной, мешающие экспериментам.
Если бы мне не платили, я бы не стал им пользоваться.
nikbond
Я бы не стал им пользоваться даже если бы платили.
Vilaine
К сожалению, когда заходит речь о командной работе, где у большинства глаза никогда не горели в этом направлении или вообще, Go не имеет альтернатив, если нужно компилируемое standalone приложение. Люди не примут такую кривую изучения Rust, для многих она окажется слишком крутой.
phtaran
так где-то была инфа что большинство любителей Rust не пишут на нём а любят кагбэ «заочно»
источник
было бы круто если бы хабровчане которые пишут на Rust пошарили инфу что они пишут на Rust, какие инструменты используют, какие библиотеки, с какими проблемами сталкивались (я не верю что проблем нет), как их решали и тд.
chapuza
В 2020 году сие звучит даже хуже, чем оригинальная кооперативная многозадачность в Go. Я просто не представляю себе, насколько оторванными от реального мира нужно быть, чтобы с таким подходом браться за создание языка в XXI веке.
PsyHaSTe
Не знаю, как можно было такое сказать, учитывая что раст единственный мейнстрим язык с верифицированными многопоточными примитивами и кучей либ наподобие rayon.
inv2004
Про верифицированные многопоточных примитивы поподробнее plz. А async/await уже нормально работает, или как год назад — match неожиданно (и для самих создателей) захватывает контекст всего "верифицированного" многопотока?
PsyHaSTe
Ну вот список верификаций: https://plv.mpi-sws.org/rustbelt/#publications
В качестве примера вот одна где во время верификации обнаружили баг в реализации атомнного референскаунтера: https://www.ralfj.de/blog/2018/07/13/arc-synchronization.html (ну и сам баг)
inv2004
Я знаю кто такие Rustbelt и чем они занимаются, но я не в курсе что они уже доказали то о чём тут разговор.
PsyHaSTe
А я что-то про растбелт говорил? Была просьба показать "показать поподробее" — я показал поподробнее.
chapuza
В официальной документации написана ерунда? — Охотно верю. Нужно рыться в клоне
npm, чтобы найти работающую с многопоточностью библиотеку? — Верю еще охотнее.«Верифицированные многопоточные примитивы» — звучит обалденно круто, как насчет вот такой простой задачки: я хотел бы в 2020 году иметь возможность запустить по гринтреду на каждую FSM у себя в коде (десятки, сотни тысяч, миллионы) и пойти заниматься своими делами, пока мои миллионы транзакций там обрабатываются (они зависимы друг от друга, разумеется, ивент в одной может триггернуть state change в других, или создать новые). Если надо — то по хэшрингу раскидать выполнение на несколько машин в кластере. В идеале — не с помощью какой-то левой библиотеки, а средствами языка.
mayorovp
То, что вы описали — это не многопоточность, а распределенная система акторов. И нет, даже в 2020м году наличие распределенной системы акторов не является чем-то критически важным для языка программирования общего назначения.
PsyHaSTe
Зачем иметь акторный фреймворк "в языке"? Кому и невеста кобыла, у кого и язык без ХТТП в стд — неюзабельный. В расте есть актикс который делает ровно то что вы сказали, занимает топ место в бенчах и вообще прекрасен. В чем проблема, в том, что раст не проповедует "all batteries included", а вместо этого продает "вот вам пакетник и экосистема отличных либ"? А вы в курсе что например был такой крейт hashbrown который предоставлял хэшмапу, и он настолько хорош был, что его затащили в СТД и стандартная хэшмапа начиная с опредленной версии это просто тонкий адаптер (чтобы обратную совместимость по АПИ сохранить) над этой либой? Или вот регулярки: их нет в языке, для регулярок нужно ставить пакет
regex. То же самое кстати с каналами — те которые в СТД хороши, но потом появился пакет crossbeam который намного круче и по апи, и по функционалу получился, и его щас тоже понемногу стабилизируют и затаскивают в СТД.И это не потому, что кортима говноделы которых каждый Васян со свободным временем на коленке обыграет и напишет либу лучше, а потому что экосистема поощряет написание библиотек. "Не с помощью библиотеки, а в самом языке" — единственный такой язык который я знаю это го, и по состоянию на 2021 год в нем есть ровно 0 (ноль) удобных кастомных коллекций или других подобных базовых вещей. И не потому, что СТД такая прекрасная (вспомнить одно только поведение файловой системы го на винде где нет пермишнов rwxrwx на файлах), а в том числе потому что язык не дает никакой возможности спроектировать удобное апи для достаточно абстрактных вещей вроде "мапа любых типов, умеющих хэшироваться" или "тип который можно безопасно переслать в другой поток".
По апи я актиксом более чем доволен. По перфомансу он стабильно занимает первые места в бенчах. В общем, любо-дорого, а не фреймворк. Но вот без шильдика "в стд" видимо придется забить на все это и есть кактус на го :/
chapuza
Затем, что без него параллельные вычисления толком не построить. Заметьте, я нигде ничего не говорил про модель акторов, я описал повседневную задачу. И тут же мне хором стали говорить про акторов. Хотя это лишь один из вариантов решения. ОК, пусть надо просто обсчитывать входной поток данных и сплевывать промежуточные результаты вовне. Задача повседневная, уши модели акторов из нее уже не так торчат. На современном языке программирования такая задача должна отнять час на подумать и 10 минут на написать 20 строчек.
Я совсем не топлю за «все должно быть в std», наоборот. Просто некоторые основополагающие вещи не должны зависеть от того, что завтра в компилятор добавят оптимизацию и ваша сторонняя библиотека поломается.
Кстати, отвечу заодно и на
я не знаю, что такое O-виза, и письма из-за океана — выбрасываю, не читая, но кроме публикаций в журналах еще бывает OSS, SO, даже заметный блог — уже почти достаточно, чтобы начать получать предложения. Я даже просто в твиттере постоянно вижу проскакивающие вакансии на весьма экзотических языках (и не только, просто в шарпе/джаве сложнее стать заметным; впрочем, в руби мне как-то удалось).
tyomitch
Речь про США; чтобы получить туда рабочую визу, люди уже с оффером от работодателя могут годами ждать благосклонности миграционной службы.
chapuza
Наверное, такое тоже бывает. Опираясь на собственный опыт, могу сказать, что вот моя жена не брезгует летать по работе в Штаты и ни разу проблем ни с визами не было, ни от предложений завтра оформить рабочую — отбоя нет.
tyomitch
Не очень понимаю про «завтра оформить»: H-1B разыгрываются раз в году, в апреле.
chapuza
Понятия не имею, если честно. Может быть, это как-то решается, типа «до апреля по обычной, потом так», может быть имеется в виду «со следующего апреля», может быть компания врет (но это вряд ли, это large cap).
Только кто ж по доброй воле в XXI веке туда поедет-то?
0xd34df00d
Ваша жена, вероятно, летает по B-визе. Которая, действительно, оформляется быстро, но работать по ней нельзя — максимум на митингах сидеть.
Рабочая — это уже сложнее. Там либо H-1B (которая разыгрывается раз в год, и на которую мой вузовский приятель подавался раза четыре, и в которую он не выиграл ни разу), либо L-1 (по которой переезжал ваш покорный слуга, но там надо год работать в зарубежном относительно США офисе). Есть ещё O-виза, но там какая-то наркомания (впрочем, знакомый, переехавший по ней, у меня тоже есть).
Ну а куда?
chapuza
А, во, это оно, наверное. В зарубежном офисе она уже несколько лет как.
Не, ну каждый по себе выбирает, конечно, но есть же места не настолько людоедские, хоть та же Канада, если про «за океан». Я не смог жить в Германии, и почти всем доволен в Испании. Многим Латинская Америка подходит, а иным — Исландия и Новая Зеландия. Люди, слава всему, разные, но как по мне — разницы между Россией и Штатами нет вовсе, просто как страны-близнецы, поэтому странно менять одну на другую.
AnthonyMikh
Эм, можете рассказать, откуда вы сделали такой вывод?
chapuza
Я давно живу, много, где побывал (а в нескольких странах жил не как турист), и всю сознательную жизнь (с середины девяностых) тесно работаю с американцами.
Я по утрам читаю новости на четырех языках из минимум шести разных стран, чтобы составить хоть сколько-нибудь правдоподобгую картину того, что происходит в мире.
Так вот, по моим наблюдениям, поведение людей в массе и подходы к государственной политике и пропаганде у наших стран самые близкие.
Как по иному случаю писал Иосиф Александрович, «если выпало в империи родиться — лучше жить в глухой провинции у моря». Так вот империй (пока Меркель не удалось построить пятый рейх в Европе, и пока Китай не потребовал от США госдолг вчерашним днем — но это вряд ли произойдет в обозримом будущем), сегодня на земле ровно две.
swelf
не хочу вмешиваться, но ты запутался, про твое утро и жизнь в 90х у тебя спросили где-то в другом треде. А здесь был вопрос, «каким образом между РФ и США нет никакой разницы»
PsyHaSTe
Пожалуйста: https://docs.rs/actix/0.10.0/actix/trait.StreamHandler.html
ну где-то так и выйдет, да
Вот статья
chapuza
Наверное, я тупой, но я не очень понимаю, как оно мне поможет из коробки обсчитать ввод в сорока синхронизированных потоках (5 машин, каждая по восемь ядер). Это как бы на сегодняшний день прямо супер-повседневная задача.
PsyHaSTe
Супер-распространенная задача по обсчету на кластере машин чего-либо? Вы требования на ходу выдумываете) Сначала требоавли "возможность запустить по гринтреду на каждую FSM у себя в коде", потом "входной поток данных и сплевывать промежуточные результаты вовне", теперь уже кластер машин. Чуть дальше пойдем — окажется, что у нас миллиарды пользователей, 100миллионов рпц надо выдавать, шесть девяток надежности и вот это все — я правильно понимаю?
Для вашей супер-пупер задачи есть готовые решения вроде мап-редьюса и хадупа, вопрос только при чем тут ЯП?
chapuza
Ложь. Я развиваю оригинальную задачу. Если бы вы не выдумали к ней модель акторов в первом комментарии, и не предложили мне костыль во втором (и вообще попробовали бы понять задачу) — вы бы увидели, что ничего в начальных условиях не поменялось. Входной поток бывает плотным, неожиданно да?
Пятнадцать девяток. А так — да, правильно. Чтобы джейсон перекладывать мне и кобола хватит. Я думал, раст позиционируется не как игрушка для одного тепличного компьютера и разрешением на сбой каждую пятую секунду. Простите, видимо ошибался.
Она уже лет 6 не принадлежит категории особенных. Оглядитесь, что ли.
Все ясно. Спасибо.
PsyHaSTe
"Я не выдумываю требования, а развиваю задачу" — называйте как хотите.
0,000031536 миллисекунд недоступности в году? А вы врунишка оказывается.
Ну по сравнению с вашими 15ю девятками ни один язык в мире не отвечает подобным требованиям. Все кругом игрушки делают видимо.
У гитхаба таких задач нет, у стаковерфлоу таких задач нет,… А это одни из самых популярных и нагруженных публичных проектов.
Пожалуйста
GreedEAP
Если учесть что абзац заканчивается "… weren't willing to commit to for 1.0." то это явно текст не 2020года
DarkEld3r
Тут одним комментарием не обойдёшься, а статью писать лень. Да и не уверен, что тут вообще статья получится. Скажем, я успел над тремя проектами на расте поработать: два блокчейновых и третий о котором пока рассказывать не готов (но не блокчейн). Проекты достаточно разные, сложности больше к предметной области относились, чем к расту. Библиотеки… ну тоже разные. Конечно, serde или tokio сейчас везде, но писать об этом смысла мало.
nikbond
У растовского комьюнити есть ежегодичный большой опрос, там есть ответы на все ваши вопросы. Можете ознакомиться с ним здесь:
blog.rust-lang.org/2020/04/17/Rust-survey-2019.html
Я лично люблю раст очень даже «очно», пишу на нем почти ежедневно, и за деньги, и для души.
Upd:
Пардон, вот актуальная ссылка за этот год blog.rust-lang.org/2020/12/16/rust-survey-2020.html
PsyHaSTe
А в чем смысл компилируемого standalone приложения в эпоху докера? Или вы десктоп софт пишите для клиентов?
phtaran
предположу что имеется в виду бинарь где всё включено (GC тоже) и оно просто выполняется. Хотя я так и не понял окончательно, быстрее ли это. Где-то была статья что GC в Go просто потюнали в другую сторону на меньшую latency, и когда java таки «разгонится» и в ней заработает JIT то GO уже не быстрее.
UPD: быстрый старт актуален для AWS Lambda, возможно для таких случаев Go таки лучше
PsyHaSTe
Да, гц го очень разрекламирован но на самом деле довольно посредственный, если смотреть не через маркетинговые очки, а как профессионалы.
Вот хороший цикл обзора state of the art современных ГЦ и почему гошный ГЦ выдает именно те результаты которые выдает:
https://blog.plan99.net/modern-garbage-collection-911ef4f8bd8e
https://blog.plan99.net/modern-garbage-collection-part-2-1c88847abcfd
Но все же поинт "единого бинаря" не очень понятен. В наше время есть "единый докер образ" который точно так же запускается одной командой и тиражируется как угодно.
phtaran
спасибо за ссылки, почитаю
ну я думаю там суть не в упаковке
это скомпилированный в таргет платформу бинарь vs интерпретация скажем java кода с помощью jvm. Старт становится быстрее. По идее на этом преимущества заканчиваются.
Бэнчмарки как известно это очень холиварное дело, и java может проигрывать не столько из-за языка сколько из-за всякой магии Spring, аспектов, рефлексии, проксирования вызовов и тому подобного. Наверняка чтобы выяснить что лучше надо мерять конкретные продакш приложения написанные на том и на том.
касательно упаковки — ну может ещё где-то нет докера или оркестратора, у нас был такой случай мы запускали у клиента просто исполняемые файлы
вот кстати довольно занятная (не истина, а просто занятная) инфа по перформансу
www.techempower.com/benchmarks/#section=data-r19&hw=ph&test=composite
PsyHaSTe
Ну так если жит тормозит то берете AOT компилируете (как андроид делает) и порядок, граали опять же всякие.
Но вот например asp.netcore на 6 месте, который обходит только раст и С++ фреймворки. Там конечно специфический бенчмаркоориентированный код, не особо идеоматичный, но тем не менее.
В общем, надеюсь кто-нибудь когда-нибудь мне объяснит смысл "единого бинаря" и чем он так прекрасен. Потому что пока что мы нашим девопсам отдаем просто докерфайлы и репозитории, они запускают
docker build .и вообще не знают, сколько там бинарей или не бинарей, и как оно вообще работает. Возможно на всяких лямбдах опыт может быть другой, но мне казалось бы странным что все гошные проекты сидят на авс.phtaran
у GraalVM есть свои некоторые минусы, вот статья навскидку dzone.com/articles/profiling-native-images-in-java
в моей практике не было такого что мы использовали GraalVM
Go берут возможно из-за комбинации качеств, типа быстрого старта + хороших (по сравнению с java) возможностей concurrency в ЯП. Я например остро ощущаю отсутствие в java async/await механизма… очень тяжело писать асинхронный код.
По правде говоря, я сам не очень понимаю нишу Go, мне она кажется очень узкой. Это когда «нужно что-то написать простое но ещё не возникло проблем с библиотеками».
касательно AWS Lambda то она довольно популярна в крупных интерпрайзах, в event-driven пайплайнах, когда есть какая-то очередь (Kinesis, SQS, Kafka etc) и лямбда процессит очередь, в big-data пайплайнах тоже, т.к. нередко вместо Spark/Apache Beam берут ту же очередь + лямбда (т.к. разработчикам так проще чем ETL тулзы). Бывает такое что latency важна, скажем для аналитики realtime типа, и в Lambda солидный кусок времени съедает старт кода. Как-то даже про Rust думали, ага.
UPD: Я не знаю сколько реально пишется Go кода для лямбд или контейнеров, просто предполагаю возможные кейсы использования.
PsyHaSTe
ну минус единственный в том, что там свой гц для неподходящий для маленьких куч, то что рефлекшн просто так не заработает было предсказуемо, но забавно, что с конфигурацией даже он заработает, в Net Native емнип от рефлекшна в любой форме тупо отказались. Про то что JIT лучше скомпилит чем AOT это в теории так, на практике все немного иначе. Дампинги и профилировщики — тут тоже понятно, для профилирования не обязательно делать аот, не так часто делается профилирование, можно и пожертвовать "временем запуска".
Лямбда довольно популярна, но я бы не ожидал что прям куча разрабов пишет под нее, а го разработчиков и правда дофига.
Поэтому я соглсен, что язык в теории весьма нишевый, почему на практике столько хайпа, особенно вокруг "единого бинаря" — непонятно. Чай не в 2000 году живем где софт с диска на рабочий стол нужно копировать, и если он portable в единственном бинаре то это сразу +100500 к популярности
0xd34df00d
У меня на позапрошлой работе не было никакого докера, а было полу-ручное упаковывание артефактов в самописный костыльный формат упаковки, и деплой самописной костыльной же системой. Там да, там чем меньше артефактов, тем проще.
PsyHaSTe
Ну обычно когда докера нет, то самым разумным первым шагом является поставить этот самый докер. Учитывая что он чуть ли не на кофеварке может запускаться, то это самый простой и зачастую эффективный способ. Я даже десктопные софтины у себя вроде постгреса или опенвпн ставлю через докер, просто чтобы не париться с установкой. Установка опенвпн сервера на комп — 20 листов инструкции, как что сделать. Установка опенвпн сервера через докер — запустить docker run с тремя аргументами.
0xd34df00d
А теперь представь себе компанию на 10 тыщ разрабов с сорокалетней историей, и где есть целые отделы по поддержке этого самописного формата упаковки и деплой-системы. Эти отделы никогда не дадут тебе внедрить никакой докер, потому что они тогда станут не нужны.
PsyHaSTe
Никогда не любил логику "давайте не будем автоматизировать бесполезных бумажкоперекладывателей потому что тогда вскроется что они не нужны". Луддизм не должен жить, а в компаниях в которых живет политика подобного рода обычно совершенно неинтересно работать.
0xd34df00d
зато гриночки хорошо делаютPsyHaSTe
Можно и без гриночки. Сбербанки нынче платят по 300-400к на руки, это 4-5к евро в месяц или 50-60 в год. Считая налог в европе порядка 30% получаем что это эквивалентно получению 100к евро в год в какой-нибудь Германии. Вполне себе можно жить безо всяких гринок. А учитывая что рынок услуг везде рассчитан на финансовые возможности людей с зарплатой в 500 евро в месяц можно вполне себе неплохо жить.
Но зачем работать в банках? И тот же вопрос про компании с 40летней историей и бюрократическим параличем? Пусть даже они платят деньги и делают гринки.
0xd34df00d
Вопросы хорошие и правильные. Не факт, что я тогдашний с сегодняшним опытом согласился бы на тот оффер. Просто когда тебе 22-23, ты ещё из вуза не выпустился и не имел опыта работы в крупной компании, то обращаешь внимание не на то, а на то, на что надо — не обращаешь. Ну и потом работаешь первые год-два, некоторые WTF возникают, но до того, как складывается цельная картина, проходит время. А там уже и sunken costs fallacy включается. Или, может, и не fallacy.
PsyHaSTe
В твоем случае по-моему все сложилось очень даже удачно. Мы +- ровесники, при этом ты посмотрел мир, поработал с кучей интересных технологий, за которые тебе ещё и заплатили, да и если я правильно помню твои комменты про матчинг, 601 и прочее то не обидели, и пусть деньги получились нерегулярными и щас возможно есть какие-то проблемы, это однозначно плюс. У кого-то и 30к накопить это уже достижение. А у кого-то месячный чек.
tyomitch
Качество жизни не во всём определяется толщиной бумажника. Когда на несколько суток отключают интернет из-за выборов, как было у ближайших соседей — толщина бумажника не сильно утешит.
PsyHaSTe
Ну я вот знаю что 0xd34df00d 'у никто не отключал интернет из-за выборов, потому что последние N лет он в штатах живет. Не в деньгах счастье, но без них тяжеловато, и очень многие мелочи из которых оно складывается (вроде вкусно поесть и красиво пожить) без них невозможны.
Vilaine
Вы правильно заметили про роль докера, но упор всё же на компилируемость (в общепринятом понимании) + тащить за собой своё окружение всё же не идеал. Вижу по треду пару упоминаний непонимания Go. Представьте себе проект на платформе Ruby, NodeJs, PHP, Python, чаще всего состоящий из нескольких приложений на одной инфраструктуре. С ростом используемости нижележащие части кода стали хуже масштабироваться, появился смысл вычленять отдельные сервисы. Вот один из примеров. Это может случиться раньше, чем нужно, из-за некоторого хайпа вокруг микросервисов. Многое можно делать на основном ЯП, но почему бы не делать сразу с «запасом прочности»? Заодно с более дешевой поддержкой, т.к. например можно дольше держать.
Брать C#, Java только ради быстрой инфраструктуры мало смысла. Основная бизнес-логика, понятно, переводиться на них не будет. Rust тяжело пойдёт команде. Которая ценит наличие типизации, но не особо в курсе глубин гарантий. Go тоже статически типизирован, и из-за этого Go уже тяжело даётся команде, которая в шоке, что нельзя вот так запросто обращаться с JSON. И это могут быть люди, которые уже имеют опыт с MyPy, Typescript, Psalm, но там всегда можно выставить тип «Any» и не париться. =) А команда без опыта статанализа (всю жизнь на динамике) вообще видят типизацию Go в обеспечении надежности как у Idris какого-нибудь.
P.S. Для обычного приложения с бизнес-логикой по мне лучше вообще брать Haskell. В Rust всё же слишком много крутится вокруг низкоуровневых оптимизаций, под которые оптимизирован и синтаксис. Революция тут лишь в том, что мне лично об этом можно не думать.
P.P.S. Для личного кроссплатформенного GUI приложения мне однажды не удалось подобрать ничего лучше, чем Python, из-за хороших биндингов к Qt. =) Выбор был тоже максимально прагматичен.
PsyHaSTe
Не очень понял проблему. Например как у нас: есть полсотни сервисов. Языки: шарп, раст, немного ноджс, пара заброшенных проектов на скале и хаскеле. Каждый сервис идет с докерфайлом. Есть тимсити джоба которая ищет ищет в каждой репозитории свой докерфайл, билдит и деплоит. Ничего про содержимое приложения оно не знает, знает только "если сработал триггера на репозитории вызови докер билд и потом передай вот такие-то аргументы как env'ы приложению при docker run". Список параметров разработчики передают, и в принципе мы пару раз полностью меняли стек (шарп на раст например) так, что девопсам даже джобу не пришлось никак трогать — просто поменяли адрес репозитория потому что под сервис 2.0 сделали свою репу.
Соответственно все ваши Ruby, NodeJs, PHP, Python — совершенно однотипно запускаются и работают. Вот я и не понимаю, в чем ценность этого "единого бинаря". Ведь и без него все работает так же, просто есть "единый образ", который совершенно декларативно описан и just works.
Я тоже считаю что хачкель/скала лучше всего при отсутствии каких-либо априорных ограничений на приложение, дальше уже вступает в силу "что лучше знает команда" и "на что есть бюджет". Как раз-таки раст так же как и го по-умолчанию компилируется в единый бинарь, вопрос выше был скорее про альтернативы как раз в виде хачкеля, сишарпа, джавы и так далее.
Vilaine
Ваш стэк кажется более дорогим, чем мог бы быть. По моему опыту эффективнее всего собрать все шишки на одной платформе, и потом её стараться держаться. Иначе будет оверхед в сколько-то процентов человеко-часов.
Ну вот про все эти C#, Java и Haskell, Rust, Go моё мнение в предыдущем комментарии.Docker образ сложнее, чем бинарь Go. Но, в целом, умозрительно дешевле упаковать в Docker на имеющейся технологии, чем вводить этот Go в стэк, да. Это не основной фактор. Задумываться о Go, по-моему, начинают тогда, когда нужно заткнуть проблемы производительности в некоторых местах, так сказать увеличив окно масштабирования.
Хотя некоторые сразу выбирают Go для всего проекта. Скорее всего из-за уже имеющегося опыта с ним, хотя, по-моему, лучше инвестировать время в накопление опыта на другой платформе.
PsyHaSTe
Да ничего дорогого :shrug: 100% команды — шарписты, но необходимость покодить в раст или там ТС сервис не вызывают каких-то особых проблем.
Ой ли? Докер для дотнета вообще генерируется одой кнопкой в visual studio. Полагаю для многих других языков делается так же. Причем для раста я просто взял докер-образ от дотнет приложения и чутка его подредактировал под свои нужнды. Также сделал для ТС. Там конечно свои нюансы были, но тем не менее. Ну пусть будет "один день чтобы сделать рыбу докер-образа для языка Х". Если у вас в компании не любят на каждый сервис уникальный язык брать, то за 1-2 недели можно наделать шаблонов докер-образов на все проекты в компании. И дальше просто при переводе в докер того или иного сервиса брать рыбу и за полчаса заполнять её нужными данными. Или просто взять язык/иде где докеризация занимает буквально один клик на кнопку "да, сделайте мне хорошо".
По моему представлению ГО выбирают динамисты, которым питон оказался медленным, и они с удивлением узнали что можно собирать с +- тем же успехом приложения, но иметь хотя бы минимальную помощь со стороны компилятора из разряда "строки не передаем вместо интов" и иметь многопоток без GIL. В такой перспективе понятна и любовь к interface{}, и хэшмапы черех хэшмапы, и некоторые другие особенности. Не претендую на истину, просто такое вот впечатление сложилось.
А невеликий это сколько в kloc примерно?
Vilaine
Разумеется, другого равнозначного выбора в любом случае нет, используй Go или нет.
Ну вы примерно повторили мои слова) Хорошо подмечено про интерфейсы, но никак иначе там и не получится. Мне кажется, на своих проектах на динамических ЯП через статанализ на тайпхинтах уже понадёжнее, чем в виденных мной Go программах.
У меня ни в коем случае нет нисколько репрезентативной статистики, но в моём понимании невеликий = <10к. Большинство ведь для всяких микросервисов используют, не так ли? Ну вот тысячи строк наверно можно насчитать. Для меня было недавно открытие, что наш небольшой активно меняющийся проект уже несколько сотен тысяч строк, так что я плохо соображаю в терминах LoC.
phtaran
хороший кейс, спасибо что расписали. Выходит что Go может быть хорошим вариантом когда js/python уже не подходят, а java/c# тяжеловато.
вот тут только хочу спросить что вы имеете в виду под «быстрой инфраструктурой»? Быстрый запуск или быстрый доступ к массе инструментов из коробки в случае java/с#?
Возможно ли скажем такое что сначала микросервис кажется простым, берут Go, а дальше он растёт и оказывается что ему уже надо работать ну пусть там с AWS SQS а sdk нет, ну или там с Okta провайдером, и оказывается что инструменты либо плохи либо их нет, и выходит что изначальное предположение что всё окажется простым, не сработало и надо либо бороться с инструментом либо переписать на java/с#
Vilaine
Вот как раз у Go, как ни посмотрю, в настоящий момент преимущество в поддержке библиотек и сервисов (наверно, не в последнюю очередь из-за Google).
Могу согласиться, что при росте кодовой базы будет быстро падать производительность разработчиков из-за невыразительности и слабой типизации Go. Субъективное мнение, но оно довольно распространено, по-моему. Наверно, учитывая невеликий обычно размер Go кода, лучше переписать на что-то более читаемое, чем продолжать бороться, или как-то изначально не выбирать этот ЯП для кандидатов на вырост.
phtaran
я там выше писал что встречал довольно разные точки зрения на производительность Go. Кто-то говорит что у Go быстрый старт но потом выигрыша по сравнению с java нет. В этом есть некоторая логика, т.к. в java/с# сборщики мусора полируются годами, и была статья и тут на хабре что GC GO это не какой-то принципиально новый GC, а по сути типовый GC просто с другими настройками. Потому мне вполне понятно что в AWS Lambda Go имеет преимущество быстрого старта, но вот насчет постоянно работающего сервиса я не уверен.
Возможно я упускаю какой-то нюанс, конечно.
У вас скажем не бывало возможности сравнить производительность сервиса на java/с# и Go?
года 2 назад я видел что у Go не было никакой возможности применять AOP (аспекты) и у меня сложилось впечатление что Go предоставляет только базовый уровень ввода-вывода в HTTP а дальше делай всё сам. Также я слышал что go-шники не любят фреймворки и говорят «если тебе нужен фреймворк — тебе не нужен Go». Т.е. мне кажется что пока это простая молотилка ивентов с S3 сделанная на AWS Lambda то всё ок, но как только нужно что-то чуть сложнее то на Go становится сложно.
Т.е. мне 2 года назад показалось что дело не столько в самом языке сколько в инструментарии. Может конечно и сам язык сделан так что не поддерживает никаких «премудростей». Сейчас ситуация как-то изменилась?
Vilaine
А в Java/C#? Если совсем с нуля, используя как вспомогательный инструмент.
PsyHaSTe
Да точно так же, мб быстрее потому что уже есть либы которые часть сложностей за вас спрятаны.
phtaran
ну возможно у вас в .net всё получше, но если свитчер с python/nodejs станет переписывать на java + Spring то мне кажется переход будет непростой. Можно сказать что часто программист для интерпрайза на java это «Spring программист». Всё типа готовое, но когда надо кастомизировать то работает оно like a magic )
кстати вот вспомнил: Kubernetes и Docker тоже кажется на Go написаны
tyomitch
Почему такое пренебрежение к десктоп-софту? rustc вы бы тоже завернули в докер? Ну или VS, раз ею тоже пользуетесь на своей локальной машине
PsyHaSTe
Да не пренебрежение, просто десктоп по сути мертв (<1% вакансий на хх на моем языке например), поэтому я по-умолчанию считаю что у человека не он пока тот не сказал обратное.
rustcв докер я не завернул, а вот всякие эзотерики вроде идриса — так и стоят, черед докер. Ну и я выше написал: опенвпн, постгрес, монго — стоят через докер потому что это куда удобнее и быстрее делается.Впрочем и десктопный софт который вы описываете тоже ставится через инсталлятор и сколько там файлов тоже как-то обычно пофиг людям. А конкретно портабельный десктоп софт это что-то либо очень старое и привет из нулевых, либо что-то очень редкое типа руфуса.
tyomitch
Это очень сильно зависит от языка: десктоп-вакансий на PHP будет ноль, на C++ — десятки процентов.
PuTTY, WinRAR, IrfanView, procexp, WinDbg, ImageMagick?
Инсталляторы у них есть, но пользоваться ими не обязательно.
PsyHaSTe
Ни один из них бтв у меня не стоит, вроме виндбг который недавно пришлось поставить чтобы попробовать подебажить дамп (и к слову он не справился). так что да, это все редкие вещи, а windbg к слову через стор ставится, если мы про последние версии: https://www.microsoft.com/en-us/p/windbg-preview/9pgjgd53tn86?activetab=pivot:overviewtab
Винрар сменился севензипом, инфанвью потерял смысл когда браузеры научились все картинки показывать + в качествве редактора у людей всякие фотошопы/paint.net. В общем, не буду спорить, YMMV
ну я не по языкам смотрю, а в целом по вакансиям на любой яп. Исключая игродельство десктоп софта нового никто не пишет, максимум поддерживает старое. Исключения — единичные приложения вроде телеграма. А на один телеграм есть 1000 вакансий на очередной магазин
0xd34df00d
А зачем работать с командой людей, с которыми у вас разные профессиональные ценности?
nikbond
А это для многих совсем не очевидная мысль. Люди могут предпочитать работать там где много денег, а не там где комфортно (тут все же часто присутствует дихотомия). Потом, вероятно, приходит выгорание…
Vilaine
Вовсе не разные, моя главная ценность — приносить максимальную пользу. Измеряется в моём случае коммерческой работы в долларах, прямо и непрямо заработанных компанией (вовсе не мной, кстати, у меня невысокая зарплата). Вот работал у нас как-то один, который всё хотел поскорее перевести на микросервисы, желательно на Go. Говнокодил, кстати, как не в себя, до сих пор легенды ходят. Вроде ушел на техлида куда-то, т.к. у нас ещё и плоская структура. Вот с ним не совпадают ценности, т.к. мне кажется он думал о своих интересах больше, чем об интересах компании. А с остальными наоборот совпадают в целом. Личные интересы (на что горят глаза) только могут не совпадать.
Сменить работу разработчику моего уровня квалификации весьма сложно, судя по опыту пассивного поиска (отвечать рекрутерам в линкедине). Если получится, то только на похожий или скорее даже более низкий технический уровень, судя по моему впечатлению о командах после редких интервью. Поэтому навряд ли что-то изменится, хотя может в активном поиске будет выше уровень интереса со стороны более продвинутых команд.
0xd34df00d
А, ну просто вы личными интересами называете то, что я называю профессиональными. Кто там как проводит выходные, наверное, всё же неважно, но на этом уровне личные интересы таки должны совпадать, ИМХО.
Vilaine
Насколько я вижу, далеко не только для нашей команды характерны эксперименты дома по вечерам в области интересов, а на работе — «скучный энтерпрайз». Хотя удачные эксперименты из дома можно попытаться «продать» коллегам для работы, если это будет полезно для бизнеса. Напротив хорошо, если у всех разные интересы — больше новых идей для развития продукта.
0xd34df00d
Тогда я вообще ничего не понимаю. Если люди дома экспериментируют, то почему у них проблемы с пониманием типизации?
Или, условно, вы вечерами экспериментируете с идрисом, а они там, не знаю, с новым веб-фреймворком или с машинным обучением? Но тогда ведь это, опять же, разные интересы.
Vilaine
Именно так, разные интересы. Поэтому у нас на проекте анализируемые хинты, best practices на веб-фреймворке и в углу какой-то корреляционный анализ. Не только и не столько это, но разные интересы однозначно помогают проекту развиваться внутри. Поэтому не могу согласиться с
hhba
Уже говорил, повторюсь — если про язык периодически возникают обсуждения в духе «как наконец перестать ненавидеть его синтаксис
и все остальное в нем», то значит синтаксис и правда плох, и оправдываться тут нечего (даже если кому-то он зашел). Выше 0xd34df00d упоминал Агду — вротмненоги же, да? Почему же там никто не воет? Да потому что там другая парадигма совершенно, отсюда другая публика, там это нормально. А вот Раст пытается пролезть туда, где люди пишут в основном на С/С++, и он на них критически не похож, несмотря на заверения. Так что этот пост и ему подобные недалеко ушли от анекдота про интимные отношения в семье сотрудника Майкрософт.tyomitch
Си, когда появился, тоже был «критически непохож» на Фортран, Кобол и APL; но это ему не помешало.
forgotten
Лично для меня Rust закончился, когда я осознал, что он не умеет в UTF-8. Совсем. Инженеры просто не подумали, им по традиции наплевать на неанглоязычных пользователей.
Найти подстроку, вставить подстроку, заменить подстроку, разбить по подстроке — пиши всё сам, итератор по символам к твоим услугам.
mayorovp
Это шутка юмора такая или как? Вот, к примеру, поиск подстроки: https://doc.rust-lang.org/std/primitive.str.html#method.find
forgotten
Оперировать UTF-8 строкой как массивом уникодных символов невозможно в Rust. Ты можешь оперировать ей как набором указателей на место в буфере, где начинается какой символ.
В реальной жизни же уметь работать с UTF-8 строкой как с набором байтов не нужно вообще никогда.
mayorovp
Напомню, что в utf-8 строках номер символа бесполезен, потому что найти его в строке по номеру можно только последовательным сканированием строки. А вот номер первого байта как раз полезен.
red75prim
Учитывая, что символ (grapheme cluster) в юникоде может состоять из нескольких codepoint'ов (в расте это char), работать с юникодной строкой как с массивом char'ов будет тоже неудобно.
forgotten
… поэтому будем массив байтов давать, ага.
Если разбить уникодную строку по графеме, получатся хотя бы две валидные уникодные строки, в отличие от.
mayorovp
Если разбить utf-8 строку по валидному byte index — то тоже получатся две валидные utf-8 строки.
forgotten
Остаётся только один вопрос — зачем?
В мире нет ни одной реальной задачи, в которой доступ к уникодной строке требуется побайтно. В Расте банально вычислить количество уникодных символов между двумя байтовыми позициями — интересное такое занятие с неопределённым результатом.
mayorovp
Ну да, очень интересное:
str[i..j].chars().count()Чтобы работать с utf-8 строками без лишних конвертаций, используя заложенные в utf-8 возможности. Очевидно же.
forgotten
thread 'main' panicked at 'byte index 1 is not a char boundary
Прекрасный способ отстрелить себе ногу.
Да каких конвертаций? Что станет хуже, если str[i] указывает на char, а не byte?
mayorovp
Ну так передавайте туды валидные индексы, а не взятые с пололка числа!
Оно и сейчас на char указывает, просто не любое значение i является валидным.
PsyHaSTe
Если бы раст был завтиповой язык то он мог бы требовать:
Но увы, раст — это как раз мейнстримный язык "Без зауми", так что валидность индексов контролируйте сами, через, например, index_of и другие средства
shikhalev
Хуже станет то, что для обращения по str[i] каждый раз придется сканировать всю строку с начала.
tyomitch
Python решил эту проблему элегантно:
shikhalev
Для скриптового языка может оно и элегантно. Но для системного слишком далеко от zero-cost. Да еще и непрозрачна структура хранения для программиста.
DistortNeo
В реальных задачах вообще крайне редко нужен произвольный доступ к элементам строки. И если он вам зачем-то понадобился, значит, вы делаете что-то не так.
Можете назвать сценарий, где такое может вообще понадобиться?
Вот знать, сколько байт занимает байтовое представление в строке — вещь нужная и полезная. А вот знать, сколько там кодпоинтов, символов или графем в подавляющем большинстве задач до лампочки.
AnthonyMikh
Поправил
0xd34df00d
Ровно так и работал в одном связанном с NLP проекте, полёт нормальный. Да, кое-где там нужно было бить на символы, но далеко не везде.
chapuza
В расте действительно есть какая-никакая поддержка юникода, но он иногда бывает слишком самонадеянным, пытаясь быть умнее там, где его не просили. Это приводит к вот такому:
Сейчас мне, разумеется, скажут, что в реальной жизни так не бывает, а я отвечу, что я лично чинил такой баг (который, понятно, очень спорадический) в ситуации, когда название компании приклеивалось через дефис к неким метаданным для создания уникального идентификатора, а компания называлась — ну да, претенциозненько «???????».
Потому что пытаться быть умным — языку программирования не положено, а casing нужно осуществлять не хардкодингом, а парсингом спецификации консорциума, как это делают адекватные люди.
mayorovp
Извините, а что изменилось бы если бы они вместо хардкода парсили спецификацию юникода, если хардкод этой самой спецификации соответствует?
AnthonyMikh
И чем бы тут помог Эликсир? Да, операции перевода в нижний регистр и конкатенация не коммутируют, но это именно что логическая ошибка, язык бы тут не помог.
chapuza
Эликсир-то тут вообще при чем?
В адекватных языках операции перевода в нижний регистр и конкатенация коммутируют. Спецификация консорциума напрямую говорит:
Язык общего назначения не должен был проигнорировать слово «conditional», но имеем мы ровно то, что имеем.
Ах, да, если вас вдруг интересует, чем бы помог эликсир: там конвертация концевой
?в?— вы не поверите, опциональна. Разработчик должен эксплицитно сказать: «используй тут правило для греческого». Да, так можно было.? Не соответствует, см. выше.
? Работало бы и завтра, когда выйдет новая версия спецификации, хардкор же, как обычно, поломается.
mayorovp
Вы так пишете, как будто новая версия спецификации какой-то магией подтянется во все реализации, чтобы они смогли её парсить. А потом такой же магией обновятся все тулчейны и все созданные ими программы...
Выйдет новая версия спецификации — программисты напишут новый код для её поддержки, только и всего. Более того, в общем случае код всё равно придйтся писать всем, даже тем кто спеку парсит — ведь формат спеки может и поменяться.
chapuza
Могу научить при компиляции скачивать актульную версию в каталог
external_data, недорого. Ну, или посмотрите, как всеCldrимплементации это делают.Конечно, ведь им надо за что-то платить зарплату — а тут, о ужас, — можно один раз написать нормальный код, и потом заниматься полезными делами. Я начинаю понимать, как даже при открытом сваггере какого-нибудь API, техотделы умудряются закладывать в план «переход на следующую версию».
mayorovp
Для этого нужно компиляцию, как минимум, запустить, иначе магии не произойдёт.
Ну вот и продемонстрируйте нормальный код, который корректно обрабатывает любые Conditional Mappings, включая потенциальные будущие, а мы посмеемся.
tyomitch
Проверил: в Java, в JS и в Python "??" в нижний регистр переводится как "??".
А где иначе? Только в эликсире?
chapuza
В спецификации иначе. Этого недостаточно?
mayorovp
Ага, все вокруг неправильно спецификацию прочитали, один вы её прочитали правильно...
chapuza
О, моё любимое «миллионы леммингов не могут ошибаться».
Можете. Чего вы не можете, так это сложить два и два, да подумать своей головой, вместо ссылок на авторитеты.
DistortNeo
Поясните. В Rust же всё это есть.
warlock13
Вообще, если учитывать нормализацию, то это не столько в самом Rust, сколько в библиотеках — но оно там и должно быть.
DistortNeo
Полноценная работа с юникодом — вещь нереально сложная и, как мне кажется, должна быть реализована на уровне системных библиотек, а не на уровне языка и стандартной библиотеки.
А для остальных же действий, типа распарсить Json знание о юникоде и не нужно — мы просто оставляем строковые значения в их неизменном виде.
tyomitch
Мне не понравится, если результат to_lowercase будет зависеть от системы, на которой запущена программа. Именно потому, что работа с юникодом — вещь нереально сложная, вероятность того, что в разных системах она будет реализована одинаково, ничтожна.
DistortNeo
То есть вы считаете неправильным, что результат работы функций зависит от текущей локали?
tyomitch
Применительно к строковым функциям — багов из-за этого я вспомню больше, чем случаев, когда это было востребовано.