В предыдущей статье мы научились подавать Vendor команды в устройство USB3.0 на базе контроллера FX3 и реализовали программную шину SPI. Сегодня мы продолжим начатое и сделаем компонент SPI to Avalon_MM. Может возникнуть вопрос: мы же уже умеем работать с шиной Avalon_MM через JTAG средствами TCL-скриптов, зачем нам что-то ещё?
Дело в том, что когда мы работаем на чистом TCL, как делали это здесь и здесь, всё замечательно. Но для задач, гоняющих десятки или даже сотни мегабайт, этот вариант слишком медленный. Поэтому мы вынуждены добавить программу на С++, работающую через USB 3.0.
Вариант с TCL-сервером, к которому обращается плюсовая программа, рассмотренный в этой статье, требует сложной ручной подготовки при каждом запуске. Надо обязательно запустить среду исполнения (для Windows и Linux они разные), запустить серверный скрипт, а затем – в программе синхронизировать работу с данными по USB и с командами через TCP. Не люблю такие сложности. Оставим те варианты под случаи, когда они не создают трудностей. Здесь же у нас есть USB-устройство, мы всё равно с ним работаем, вот и будем обращаться к шине AVALON_MM через него. Приступаем.

Предыдущие статьи цикла:
Перед тем как заняться разработкой своего блока, я попытался найти что-то готовое. Да, работа с TCL как напрямую, так и через сеть – создаёт ряд неудобств для пользователя. Но нельзя ли достучаться до JTAG-адаптера напрямую? Ну, или хотя бы подключиться к JTAG-серверу, как это делают штатные компоненты системы? Я мучил Гугля всё более и более мудрёными запросами. Увы. Есть вариант, когда сервер реализуется на самой плате (только в нашем варианте с платы выкинут процессор, не на чем его там запустить), но нет примеров, как подключиться к JTAG-серверу, запущенному на PC. Были статьи про существующий сервер для проекта «Марсоход», запускаемый на «Малине», но насколько я понял, там надо подменять DLL. Было ещё несколько статей с явно нужными ключевыми словами, но все они были удалены, а в кэше Гугля лежало что-то, совершенно нечитаемое.
Я даже выдвинул гипотезу, что дело в ядрах с ограниченными правами использования. Тех, которые работают только тогда, когда подключены к PC с запущенным сервером. Возможно, кто поймёт принцип управления JTAG-сервером, тот сможет их всколоть, а правообладатели этого не хотят, поэтому тщательно скрывают протоколы. У нас нет задачи что-то всколоть, а у меня нет желания писать статью, которую быстро удалят. Поэтому я решил просто сделать свой блок. Какой? Решение выплывает из моей текущей рабочей загрузки. Я играю в среду Litex. Там используется шина AXI-Lite или Wishbone. Я работаю со второй из них и вижу в системе массу переходников. Там есть и SPI to Wishbone, и UART to Wishbone и всё, что угодно to Wishbone. Поэтому я и решил сделать переходник SPI to Avalon-MM.
Если вбить Гуглю запрос Avalon Memory-Mapped Master Templates, то мы попадём вот сюда:
Avalon Memory-Mapped Master Templates (intel.com)
Скачиваем имеющийся на этой странице zip-файл, там есть примеры мастеров для шины AVALON-MM практически на все случаи жизни. В документе приводятся примеры, как просто взять и положить файлы из этого архива, после чего начать работать с ними. Приведу пример рисунка для одного из направлений
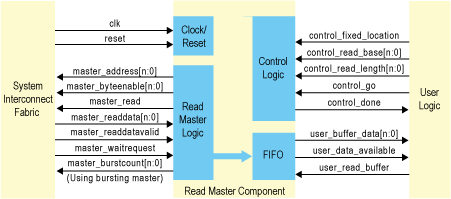
Мы должны реализовать участок Control Logic и FIFO, после чего всё заработает само. Сначала я гипнотизировал эти примеры, мечтая пойти именно по этому пути. Первое, что не давало покоя: мастер чтения и мастер записи – разные блоки, каждый из которых подключается к шине AVALON. Соединить их не так просто. Затем, начав практические опыты, я понял, что иерархия там тоже получается не самая лучшая. Мне бы пришлось сделать очень много транзитных верёвок. Система становилась слишком сложной, а выше я уже писал, что не люблю сложных систем.
Тогда я внимательно посмотрел на исходные тексты и понял, что на самом деле там реализуются действия, сложность которых не выше, чем у блоков AVALON_MM Slave, которые мы уже делаем, как семечки щёлкаем. Там нет ничего страшного. Нет никаких линий GNT, характерных для некоторых «взрослых» шин. Вообще ничего нет. Знай себе, ставь стробы и удерживай их, пока не получил подтверждения, что данные прокачались. Всё! Остальное за нас сделает логика, являющаяся внешней по отношению к нашему блоку (она спрятана от нас где-то внутри System Interconnect Fabric).
Некоторые небольшие трудности возникли бы при отладке пакетных передач, но я же не собираюсь их гонять! У меня очень медленная шина SPI (в прошлой статье мы видели, что на ней частота тактовых сигналов не превышает 4 МГц, а данных по ней пробегает 8 + 32 + 32 = 72 бита, итого предельная частота следования данных 55,(5) КГц). Так что получили запрос – прогнали одно слово по Avalon, отпустили шину. Ждём следующий запрос. Не нужны тут пакеты!
Итого. Пишем свой модуль с нуля, но всё равно, черпая вдохновение в исходных кодах, скачанных с вышеуказанной странички. Собственно, если кому-то больше нравится работать не по примерам (пусть и фирменным), а по документам — ссылка на спецификацию Avalon на той страничке тоже есть.
В основу работы модуля положим конечный автомат. Причём сигналом сброса для него я выбрал положительный уровень линии SS. Давайте я покажу типичную посылку по шине SPI, взяв первую попавшуюся времянку с просторов сети:

На этом рисунке линия называется не SS (Slave Select), а CS (Chip Select). Но мы видим, что её высокий уровень можно трактовать как сброс шины. Это очень удобно. Не надо бояться, что произойдёт рассинхронизация. Мы почти уверены, что перед первым битом этот сигнал перейдёт из единицы в ноль. В своём коде для FX3 я сделаю так, чтобы быть уверенным не почти, а стопроцентно.
Как я уже начерно говорил в предыдущей статье, сначала будет идти восьмибитная команда, дальше – тридцатидвухбитный адрес. Поэтому вполне можно завести сорокабитный регистр команды-адреса и завести состояние автомата, в котором в этом регистре копится входная посылка.

Когда значение bit_cnt достигло сорока (из-за особенностей языков Verilog, да и VHDL тоже, в коде используется константа 39), мы выходим на рабочий участок. Команд может быть две: чтение и запись. За это отвечает нулевой бит команды (из-за той же особенности языка – в коде проверяется первый). Вот так выглядит обработчик этого состояния на SystemVerilog:
Чтобы хоть как-то оправдать восьмибитный регистр команды, я использую старшие 4 бита как BYTE_ENABLE для шины AVALON_MM, чтобы дать возможность писать не только по 32 бита. Для этого в конце текста есть такая строка:
Вторая строка в этой паре подключает наш регистр адреса к линиям адреса шины AVALON_MM.
Теперь пройдёмся по ветви чтения. Сначала надо считать данные из шины. Я исхожу из предположения, что шина SPI крайне медленная, поэтому не ввожу на неё никакого сигнала готовности. Считаем, что данные из AVALON_MM придут так быстро, что в SPI не успеет убежать ни одного лишнего бита. Нам потребуется два состояния. В первом мы взведём строб чтения и будем удерживать его, пока нам не придёт подтверждения, что данные пришли. Тогда мы защёлкнем эти данные и будем выдавать их в SPI на протяжении тридцати двух тактов. Собственно, всё. Потом мы на всякий случай сбросим счётчик битов (а вдруг начнётся передача новой команды без снятия SS?) и вновь перейдём в состояние idle, где будем копить новую команду. Состояние read1 выделено особым цветом, так как оно не зависит от положительного перепада на линии SCK шины SPI. Оно привязано только к тактовому сигналу шины AVALON_MM.

Вот так реализованы эти состояния в автомате.
И вот так привязан выход регистра сдвига к сигналу MOSI шины SPI:
Ветка записи – с точностью до наоборот. Сначала в состоянии write1 мы принимаем 32 бита данных, затем – выставляем строб записи и висим в состоянии write2 (также не привязанным к SCK, поэтому имеющем особый цвет), пока нам не сообщат, что наши данные ушли.

Получаем такой код для реализации состояний.
и такую строку для статического проецирования регистра данных на линии данных AVALON_MM:
Остальной текст модуля – необходимая технологическая мишура. Нам надо продискретизировать линии SPI по тактовой частоте шины AVALON_MM, кроме того, надо получить задержанный на один авалоновский такт сигнал SCK шины SPI, чтобы иметь возможность ловить его перепад. Все эти действия мы имеем право выполнять только если уверены, что шина SPI достаточно медленная относительно AVALON_MM. Именно поэтому в прошлой статье я занимался оптимизацией, но не гнался за бешеными показателями.
Cобственно, всё. Модуль готов. Вот его полный текст для справки.
Можно внедрять его в проект. Как это делается – мы детально рассматривали тут и потом постоянно занимались этим в цикле статей про Redd. Но сегодня править придётся намного больше вещей, чем обычно.
Обычно я детально рассказываю про процесс внедрения модуля. Но сегодня потребуется такое количество мелких правок, что мне кажется, рассказ не будет иметь никакого эффекта. Все дочитают до третьего абзаца, затем – зевнут и перейдут к следующему разделу. Поэтому сегодня я дам TCL-скрипт, внедряющий новый модуль в систему, и расскажу, как его применить. Будет не так скучно, а главное – это будет давать какие-то новые знания. Вот такой скрипт сделал Квартус после всех моих действий:
Итак. У меня в проекте традиционно имеется каталог MyCores. Туда я кладу СистемВерилоговский файл spitoAvalon_mm.sv.

А теперь на уровень проекта кладу файл SpiToAvalonMM_hw.tcl.
Прекрасно. Открываем Platform Designer и… видим, что наш компонент сам запрыгнул в перечень доступных!

Собственно, внедрение завершено, но давайте чисто для справки я пробегусь по основным его свойствам. Вот так я раскидал всё по шинам:

Обратите внимание, что всем линиям шины SPI пришлось дать осмысленные имена.
Теперь посмотрим настройки шины AVALON_MM
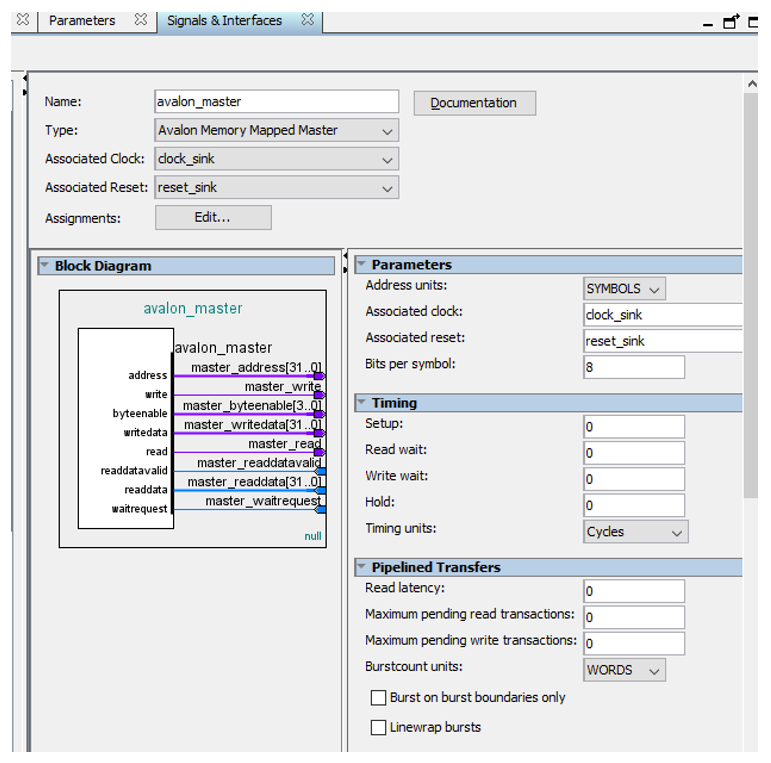
Я выставил адресацию с точностью до байта. Можно было бы переключить точность до слова, но раз у меня есть линии BYTE_ENABLE, то можно же сделать работу с байтами и WORDами. Так что до байта. И какая-то из латентностей, уже не помню какая, была установлена в единицу. Я заменил на ноль. Собственно, на рисунке выше все задержки и латентности равны нулю, так что не перепутаете. Единицу будет хорошо видно.
Собственно, как проверить шину? А давайте через неё подключим небольшую ОЗУшку и попробуем писать и читать данные. Добавляем в систему, доставшуюся нам в наследство от прошлых статей, два элемента: мост SpiToAvalonMM и On Chip Memory. Но ОЗУ мы настроим чуть более сложно, чем обычно. Дело в том, что при отладке зеркальных систем можно получить, что запись и чтение работают. Но если допущена идеологическая ошибка в обоих направлениях, оно неверно запишется, так же неверно считается, но считанные данные совпадут с записанными, и мы увидим ложную работу. Поэтому желательно, чтобы в ОЗУ были заранее известные данные. Сначала мы убедимся, что они читаются верно, а уже затем начнём проводить пару запись-чтение, чтобы проверить уже работу записи при заведомо работающем чтении. Для этого мы взводим флажок Enable non-default initialization file и начинаем разбираться, куда положить и как сделать файл onchip_mem.hex.

Кладём его на тот же уровень, где живут файлы *.qpf и *.qsf. А вот с содержимым придётся немного повеселиться. Генератор такого файла входит в состав NIOS II EDS, то есть, в состав Квартуса. Но увы, это elf2hex. А нам бы bin2hex. Я нашёл замечательный проект SRecord 1.64 (sourceforge.net), который умеет преобразовывать любые файлы в любые. Замечательный проект! Он стоит того, чтобы попасть в записные книжки разработчиков железа… Но в классическом HEXе адресация идёт байтами, а Квартус хочет, чтобы шла DWORD-ами, поэтому пришлось писать генератор hex файла самому. Учитывая, что надо было экономить время на разработку, он получился таким.
Просто для справки: вот так выглядят вновь добавленные блоки в процессорной системе:

Conduit выход spi экспортирован наружу, единственная шина AVALON_MM соединяет наш мастер со slave-входом ОЗУ. А больше я даже не знаю, что сказать. Обычно у нас системы были позабористей. Тут – всё просто.
Не забываем, что у нас появились новые выводы (SPI). Дело в том, что когда я повторял свои подвиги при написании этого текста, я реально забыл это сделать, и очень удивлялся, что постоянно читается FFFFFF, хотя система уже была проверена при черновой подготовке и не должна была дурить. Так что не забываем! Для моей аппаратуры получилось так:

В прошлый раз в «прошивке» FX3 мы сделали только запись в SPI. В этот раз надо добавить чтение. Для начала – чтение бита данных. Если при записи было очень полезно работать с конкретными битами, так как вместо чтения-модификации-записи, можно было только писать, то при чтении такой режим не даёт никакого выигрыша. Всё равно надо принять данные и как-то выделить требуемый бит. Поэтому для чтения данных я сделал такой макрос:
Из оптимизации там только то, что я заранее знаю, что нужные нам биты находятся в диапазоне 32-63, поэтому сразу обращаюсь к регистру GPIO->lpp_gpio_invalue1, не тратя такты процессора на проверку.
Само чтение – тоже особо ничем не приметно. Но кто будет вглядываться в текст, тот заметит, что последовательность действий отличается от той, которая напрашивается сама собой. Я просто постарался раскидать работу, чтобы и в положительном, и в отрицательном полупериоде сигнала SCK задержку вносили какие-то полезные команды. Было бы обидно всё полезное расположить в одной половинке, а в другую добавлять бесполезную задержку при помощи NOPов. И так всё медленно работает!
И, наконец, обработчик Vendor-команды в итоге стал таким:
Как и в прошлый раз, начерно всё проверяем через какую-нибудь подавалку USB-команд. Лично я предпочитаю BusHound. Как через него выполнять подобные проверки, было рассказано в предыдущей статье. Вот я читаю адрес 0. Длину всегда задаю равную четырём. Читается 12345678, как раз то, что было записано в файле onchip_mem.hex.

С адреса 4 читается 11111111

Ну, и так далее. Теперь пробуем записать. Скажем, по адресу 0x40 значение 0x87654321.

Контрольное чтение даст то же самое. Для экономии места я не буду показывать, как сначала писал несколько слов по разным адресам, а затем – читал их и убеждался, что значение осталось прежним. Вы можете поверить мне на слово, либо сделать аналогичную систему и проверить это самостоятельно.
Убедившись, что всё работает верно, я добавил в класс, общающийся с библиотекой LibUSB, две функции. Если быть совсем точным, то я создал класс CAvalonViaFX3, унаследовав его от уже известного по одной из прошлых статей CUsbTester, а уже в него добавил эти две функции. Но это уже детали реализации, для нас сейчас важен сам код. Вот он:
Ну, и код, тестирующий память, размером 4 килобайта, выглядит так:
Внутренний буфер data пришлось завести для того, чтобы можно было выводить при ошибках ожидаемые значения. Правда, это не понадобилось, всё работает и так. Но если бы понадобилось – это бы сильно помогло выяснить наиболее вероятную причину ошибки (сбой адреса, сбой данных, прочие сбои). Если делать на века, то, разумеется, можно было бы обойтись без буфера, пользуясь только генератором псевдослучайных чисел, порождённым от той же базовой константы, от которой был порождён генератор чисел, использованные при записи. Но это бы сделало текст менее читаемым, а для статей читаемость важнее, чем доведение эффективности из области «и так неплохо» в область идеала.
Мы освоили методику разработки мастеров, читающих и пишущих в шину AVALON_MM. Набивая руку, мы сделали переходник SPI в AVALON_MM и проверили его работоспособность. При работе с контроллером FX3 это позволит обращаться (с не очень высокой производительностью) к шине без использования каких-либо сторонних средств, так как раньше пришлось бы работать с TCL-командами или скриптами.
Материалы, получившиеся при написании статьи, можно скачать тут.
Дело в том, что когда мы работаем на чистом TCL, как делали это здесь и здесь, всё замечательно. Но для задач, гоняющих десятки или даже сотни мегабайт, этот вариант слишком медленный. Поэтому мы вынуждены добавить программу на С++, работающую через USB 3.0.
Вариант с TCL-сервером, к которому обращается плюсовая программа, рассмотренный в этой статье, требует сложной ручной подготовки при каждом запуске. Надо обязательно запустить среду исполнения (для Windows и Linux они разные), запустить серверный скрипт, а затем – в программе синхронизировать работу с данными по USB и с командами через TCP. Не люблю такие сложности. Оставим те варианты под случаи, когда они не создают трудностей. Здесь же у нас есть USB-устройство, мы всё равно с ним работаем, вот и будем обращаться к шине AVALON_MM через него. Приступаем.
Предыдущие статьи цикла:
- Начинаем опыты с интерфейсом USB 3.0 через контроллер семейства FX3 фирмы Cypress
- Дорабатываем прошивку USB 3.0, используя анализатор SignalTap, встроенный в среду разработки Quartus
- Учимся работать с USB-устройством и испытываем систему, сделанную на базе контроллера FX3
- Боремся с таймаутами при использовании USB 3.0 через контроллер FX3, возникающими при определенных условиях
- Добавляем поддержку Vendor-команд к USB3.0 устройству на базе FX3
Введение
Перед тем как заняться разработкой своего блока, я попытался найти что-то готовое. Да, работа с TCL как напрямую, так и через сеть – создаёт ряд неудобств для пользователя. Но нельзя ли достучаться до JTAG-адаптера напрямую? Ну, или хотя бы подключиться к JTAG-серверу, как это делают штатные компоненты системы? Я мучил Гугля всё более и более мудрёными запросами. Увы. Есть вариант, когда сервер реализуется на самой плате (только в нашем варианте с платы выкинут процессор, не на чем его там запустить), но нет примеров, как подключиться к JTAG-серверу, запущенному на PC. Были статьи про существующий сервер для проекта «Марсоход», запускаемый на «Малине», но насколько я понял, там надо подменять DLL. Было ещё несколько статей с явно нужными ключевыми словами, но все они были удалены, а в кэше Гугля лежало что-то, совершенно нечитаемое.
Я даже выдвинул гипотезу, что дело в ядрах с ограниченными правами использования. Тех, которые работают только тогда, когда подключены к PC с запущенным сервером. Возможно, кто поймёт принцип управления JTAG-сервером, тот сможет их всколоть, а правообладатели этого не хотят, поэтому тщательно скрывают протоколы. У нас нет задачи что-то всколоть, а у меня нет желания писать статью, которую быстро удалят. Поэтому я решил просто сделать свой блок. Какой? Решение выплывает из моей текущей рабочей загрузки. Я играю в среду Litex. Там используется шина AXI-Lite или Wishbone. Я работаю со второй из них и вижу в системе массу переходников. Там есть и SPI to Wishbone, и UART to Wishbone и всё, что угодно to Wishbone. Поэтому я и решил сделать переходник SPI to Avalon-MM.
Где черпаем вдохновение
Если вбить Гуглю запрос Avalon Memory-Mapped Master Templates, то мы попадём вот сюда:
Avalon Memory-Mapped Master Templates (intel.com)
Скачиваем имеющийся на этой странице zip-файл, там есть примеры мастеров для шины AVALON-MM практически на все случаи жизни. В документе приводятся примеры, как просто взять и положить файлы из этого архива, после чего начать работать с ними. Приведу пример рисунка для одного из направлений
Мы должны реализовать участок Control Logic и FIFO, после чего всё заработает само. Сначала я гипнотизировал эти примеры, мечтая пойти именно по этому пути. Первое, что не давало покоя: мастер чтения и мастер записи – разные блоки, каждый из которых подключается к шине AVALON. Соединить их не так просто. Затем, начав практические опыты, я понял, что иерархия там тоже получается не самая лучшая. Мне бы пришлось сделать очень много транзитных верёвок. Система становилась слишком сложной, а выше я уже писал, что не люблю сложных систем.
Тогда я внимательно посмотрел на исходные тексты и понял, что на самом деле там реализуются действия, сложность которых не выше, чем у блоков AVALON_MM Slave, которые мы уже делаем, как семечки щёлкаем. Там нет ничего страшного. Нет никаких линий GNT, характерных для некоторых «взрослых» шин. Вообще ничего нет. Знай себе, ставь стробы и удерживай их, пока не получил подтверждения, что данные прокачались. Всё! Остальное за нас сделает логика, являющаяся внешней по отношению к нашему блоку (она спрятана от нас где-то внутри System Interconnect Fabric).
Некоторые небольшие трудности возникли бы при отладке пакетных передач, но я же не собираюсь их гонять! У меня очень медленная шина SPI (в прошлой статье мы видели, что на ней частота тактовых сигналов не превышает 4 МГц, а данных по ней пробегает 8 + 32 + 32 = 72 бита, итого предельная частота следования данных 55,(5) КГц). Так что получили запрос – прогнали одно слово по Avalon, отпустили шину. Ждём следующий запрос. Не нужны тут пакеты!
Итого. Пишем свой модуль с нуля, но всё равно, черпая вдохновение в исходных кодах, скачанных с вышеуказанной странички. Собственно, если кому-то больше нравится работать не по примерам (пусть и фирменным), а по документам — ссылка на спецификацию Avalon на той страничке тоже есть.
Главный автомат
В основу работы модуля положим конечный автомат. Причём сигналом сброса для него я выбрал положительный уровень линии SS. Давайте я покажу типичную посылку по шине SPI, взяв первую попавшуюся времянку с просторов сети:
На этом рисунке линия называется не SS (Slave Select), а CS (Chip Select). Но мы видим, что её высокий уровень можно трактовать как сброс шины. Это очень удобно. Не надо бояться, что произойдёт рассинхронизация. Мы почти уверены, что перед первым битом этот сигнал перейдёт из единицы в ноль. В своём коде для FX3 я сделаю так, чтобы быть уверенным не почти, а стопроцентно.
Как я уже начерно говорил в предыдущей статье, сначала будет идти восьмибитная команда, дальше – тридцатидвухбитный адрес. Поэтому вполне можно завести сорокабитный регистр команды-адреса и завести состояние автомата, в котором в этом регистре копится входная посылка.
Когда значение bit_cnt достигло сорока (из-за особенностей языков Verilog, да и VHDL тоже, в коде используется константа 39), мы выходим на рабочий участок. Команд может быть две: чтение и запись. За это отвечает нулевой бит команды (из-за той же особенности языка – в коде проверяется первый). Вот так выглядит обработчик этого состояния на SystemVerilog:
Смотерть текст.
always_ff @(posedge master_clk, posedge spi_ss)
begin
// Это эквивалентно сбросу со стороны SPI
if (spi_ss == 1)
begin
bit_cnt <= 0;
state <= idle;
end else
begin
master_write <= 0;
master_read <= 0;
case (state)
idle: begin
// Ура! У нас очередной перепад SCK!
if ((spi_sck_d == 0) && (spi_sck_reg == 1))
begin
regCmdAndAddr <= {spi_mosi_reg,regCmdAndAddr[39:1]};
bit_cnt <= bit_cnt + 1;
// Особенность машинного языка - анализируем не новое,
// а предыдущее значение
if (bit_cnt == 39)
begin
// Пишем
if (regCmdAndAddr[1])
begin
state <= write1;
end else
// Читаем
begin
state <= read1;
end
end
end
end
Чтобы хоть как-то оправдать восьмибитный регистр команды, я использую старшие 4 бита как BYTE_ENABLE для шины AVALON_MM, чтобы дать возможность писать не только по 32 бита. Для этого в конце текста есть такая строка:
assign master_byteenable = regCmdAndAddr [7:4];
assign master_address = regCmdAndAddr [39:8];
Вторая строка в этой паре подключает наш регистр адреса к линиям адреса шины AVALON_MM.
Теперь пройдёмся по ветви чтения. Сначала надо считать данные из шины. Я исхожу из предположения, что шина SPI крайне медленная, поэтому не ввожу на неё никакого сигнала готовности. Считаем, что данные из AVALON_MM придут так быстро, что в SPI не успеет убежать ни одного лишнего бита. Нам потребуется два состояния. В первом мы взведём строб чтения и будем удерживать его, пока нам не придёт подтверждения, что данные пришли. Тогда мы защёлкнем эти данные и будем выдавать их в SPI на протяжении тридцати двух тактов. Собственно, всё. Потом мы на всякий случай сбросим счётчик битов (а вдруг начнётся передача новой команды без снятия SS?) и вновь перейдём в состояние idle, где будем копить новую команду. Состояние read1 выделено особым цветом, так как оно не зависит от положительного перепада на линии SCK шины SPI. Оно привязано только к тактовому сигналу шины AVALON_MM.
Вот так реализованы эти состояния в автомате.
Cмотреть текст.
read1: begin
master_read <= 1;
if (master_readdatavalid)
begin
state <= read2;
regData <= master_readdata;
end
end
read2: begin
if ((spi_sck_d == 0) && (spi_sck_reg == 1))
begin
regData <= {1'b0,regData[31:1]};
bit_cnt <= bit_cnt + 1;
// Особенность машинного языка - анализируем не новое,
// а предыдущее значение
if (bit_cnt == 71)
begin
bit_cnt <= 0;
state <= idle;
end
end
end
И вот так привязан выход регистра сдвига к сигналу MOSI шины SPI:
assign spi_miso = regData [0];
Ветка записи – с точностью до наоборот. Сначала в состоянии write1 мы принимаем 32 бита данных, затем – выставляем строб записи и висим в состоянии write2 (также не привязанным к SCK, поэтому имеющем особый цвет), пока нам не сообщат, что наши данные ушли.
Получаем такой код для реализации состояний.
Смотреть текст.
// При записи, надо сначала допринимать данные из SPI
write1: begin
// Ура! У нас очередной перепад SCK!
if ((spi_sck_d == 0) && (spi_sck_reg == 1))
begin
regData <= {spi_mosi_reg,regData[31:1]};
bit_cnt <= bit_cnt + 1;
// Особенность машинного языка - анализируем не новое,
// а предыдущее значение
if (bit_cnt == 71)
begin
state <= write2;
end
end
end
// Всё заполнено. Держим строб записи.
write2: begin
master_write <= 1;
// Если шина нас услышала - ну и прекрасно. Вышли
if (master_waitrequest == 0)
begin
bit_cnt <= 0;
state <= idle;
end
end
и такую строку для статического проецирования регистра данных на линии данных AVALON_MM:
assign master_writedata = regData;
Остальной текст модуля – необходимая технологическая мишура. Нам надо продискретизировать линии SPI по тактовой частоте шины AVALON_MM, кроме того, надо получить задержанный на один авалоновский такт сигнал SCK шины SPI, чтобы иметь возможность ловить его перепад. Все эти действия мы имеем право выполнять только если уверены, что шина SPI достаточно медленная относительно AVALON_MM. Именно поэтому в прошлой статье я занимался оптимизацией, но не гнался за бешеными показателями.
reg spi_sck_reg, spi_sck_d;
reg spi_mosi_reg;
always @ (posedge master_clk)
begin
spi_sck_reg <= spi_sck;
spi_mosi_reg <= spi_mosi;
spi_sck_d <= spi_sck_reg;
end
Cобственно, всё. Модуль готов. Вот его полный текст для справки.
Смотреть полный текст модуля.
module spitoAvalon_mm (
input master_clk,
input master_reset,
output [31:0] master_address,
output reg master_write=0,
output [3:0] master_byteenable,
output [31:0] master_writedata,
output reg master_read,
input master_readdatavalid,
input [31:0] master_readdata,
input master_waitrequest,
input spi_sck,
input spi_mosi,
output spi_miso,
input spi_ss
);
// Чтобы не заводить SPI_SCK на линию GCK,
// мы ориентируемся на то, что шина - медленная, поэтому
// просто ловим перепады по основной тактовой частоте
// Да и вообще, отдискретизируем SPI по тактовой. Во избежание...
reg spi_sck_reg, spi_sck_d;
reg spi_mosi_reg;
always @ (posedge master_clk)
begin
spi_sck_reg <= spi_sck;
spi_mosi_reg <= spi_mosi;
spi_sck_d <= spi_sck_reg;
end
// Число битов, принятых из SPI
reg [7:0] bit_cnt;
// Регистр команд/адреса. Итого 8 + 32 = 40 бит
reg [39:0] regCmdAndAddr = 0;
reg [31:0] regData = 0;
enum {idle,
read1, read2,
write1,write2
} state = idle;
always_ff @(posedge master_clk, posedge spi_ss)
begin
// Это эквивалентно сбросу со стороны SPI
if (spi_ss == 1)
begin
bit_cnt <= 0;
state <= idle;
end else
begin
master_write <= 0;
master_read <= 0;
case (state)
idle: begin
// Ура! У нас очередной перепад SCK!
if ((spi_sck_d == 0) && (spi_sck_reg == 1))
begin
regCmdAndAddr <= {spi_mosi_reg,regCmdAndAddr[39:1]};
bit_cnt <= bit_cnt + 1;
// Особенность машинного языка - анализируем не новое,
// а предыдущее значение
if (bit_cnt == 39)
begin
// Пишем
if (regCmdAndAddr[1])
begin
state <= write1;
end else
// Читаем
begin
state <= read1;
end
end
end
end
// При записи, надо сначала допринимать данные из SPI
write1: begin
// Ура! У нас очередной перепад SCK!
if ((spi_sck_d == 0) && (spi_sck_reg == 1))
begin
regData <= {spi_mosi_reg,regData[31:1]};
bit_cnt <= bit_cnt + 1;
// Особенность машинного языка - анализируем не новое,
// а предыдущее значение
if (bit_cnt == 71)
begin
state <= write2;
end
end
end
// Всё заполнено. Держим строб записи.
write2: begin
master_write <= 1;
// Если шина нас услышала - ну и прекрасно. Вышли
if (master_waitrequest == 0)
begin
bit_cnt <= 0;
state <= idle;
end
end
// При чтении - наоборот, сначала считали данные
// Для медленной шины, надо бы ещё готовность SPI добавить
// но в этом примере, мы ею пренебрежём
read1: begin
master_read <= 1;
if (master_readdatavalid)
begin
state <= read2;
regData <= master_readdata;
end
end
read2: begin
if ((spi_sck_d == 0) && (spi_sck_reg == 1))
begin
regData <= {1'b0,regData[31:1]};
bit_cnt <= bit_cnt + 1;
// Особенность машинного языка - анализируем не новое,
// а предыдущее значение
if (bit_cnt == 71)
begin
bit_cnt <= 0;
state <= idle;
end
end
end
default: begin
state <= idle;
end
endcase
end
end
assign master_byteenable = regCmdAndAddr [7:4];
assign master_address = regCmdAndAddr [39:8];
assign master_writedata = regData;
assign spi_miso = regData [0];
endmodule
Можно внедрять его в проект. Как это делается – мы детально рассматривали тут и потом постоянно занимались этим в цикле статей про Redd. Но сегодня править придётся намного больше вещей, чем обычно.
Внедряем модуль в проект
Обычно я детально рассказываю про процесс внедрения модуля. Но сегодня потребуется такое количество мелких правок, что мне кажется, рассказ не будет иметь никакого эффекта. Все дочитают до третьего абзаца, затем – зевнут и перейдут к следующему разделу. Поэтому сегодня я дам TCL-скрипт, внедряющий новый модуль в систему, и расскажу, как его применить. Будет не так скучно, а главное – это будет давать какие-то новые знания. Вот такой скрипт сделал Квартус после всех моих действий:
Смотреть текст Квартуса.
# TCL File Generated by Component Editor 17.1
# Wed Dec 30 02:23:32 MSK 2020
# DO NOT MODIFY
#
# SpiToAvalonMM "SpiToAvalonMM" v1.0
# 2020.12.30.02:23:32
#
#
#
# request TCL package from ACDS 16.1
#
package require -exact qsys 16.1
#
# module SpiToAvalonMM
#
set_module_property DESCRIPTION ""
set_module_property NAME SpiToAvalonMM
set_module_property VERSION 1.0
set_module_property INTERNAL false
set_module_property OPAQUE_ADDRESS_MAP true
set_module_property AUTHOR ""
set_module_property DISPLAY_NAME SpiToAvalonMM
set_module_property INSTANTIATE_IN_SYSTEM_MODULE true
set_module_property EDITABLE true
set_module_property REPORT_TO_TALKBACK false
set_module_property ALLOW_GREYBOX_GENERATION false
set_module_property REPORT_HIERARCHY false
#
# file sets
#
add_fileset QUARTUS_SYNTH QUARTUS_SYNTH "" ""
set_fileset_property QUARTUS_SYNTH TOP_LEVEL spitoAvalon_mm
set_fileset_property QUARTUS_SYNTH ENABLE_RELATIVE_INCLUDE_PATHS false
set_fileset_property QUARTUS_SYNTH ENABLE_FILE_OVERWRITE_MODE false
add_fileset_file spitoAvalon_mm.sv SYSTEM_VERILOG PATH MyCores/spitoAvalon_mm.sv TOP_LEVEL_FILE
#
# parameters
#
#
# display items
#
#
# connection point conduit_end
#
add_interface conduit_end conduit end
set_interface_property conduit_end associatedClock ""
set_interface_property conduit_end associatedReset ""
set_interface_property conduit_end ENABLED true
set_interface_property conduit_end EXPORT_OF ""
set_interface_property conduit_end PORT_NAME_MAP ""
set_interface_property conduit_end CMSIS_SVD_VARIABLES ""
set_interface_property conduit_end SVD_ADDRESS_GROUP ""
add_interface_port conduit_end spi_ss spi_ss Input 1
add_interface_port conduit_end spi_sck spi_sck Input 1
add_interface_port conduit_end spi_mosi spi_mosi Input 1
add_interface_port conduit_end spi_miso spi_miso Output 1
#
# connection point avalon_master
#
add_interface avalon_master avalon start
set_interface_property avalon_master addressUnits SYMBOLS
set_interface_property avalon_master associatedClock clock_sink
set_interface_property avalon_master associatedReset reset_sink
set_interface_property avalon_master bitsPerSymbol 8
set_interface_property avalon_master burstOnBurstBoundariesOnly false
set_interface_property avalon_master burstcountUnits WORDS
set_interface_property avalon_master doStreamReads false
set_interface_property avalon_master doStreamWrites false
set_interface_property avalon_master holdTime 0
set_interface_property avalon_master linewrapBursts false
set_interface_property avalon_master maximumPendingReadTransactions 0
set_interface_property avalon_master maximumPendingWriteTransactions 0
set_interface_property avalon_master readLatency 0
set_interface_property avalon_master readWaitTime 0
set_interface_property avalon_master setupTime 0
set_interface_property avalon_master timingUnits Cycles
set_interface_property avalon_master writeWaitTime 0
set_interface_property avalon_master ENABLED true
set_interface_property avalon_master EXPORT_OF ""
set_interface_property avalon_master PORT_NAME_MAP ""
set_interface_property avalon_master CMSIS_SVD_VARIABLES ""
set_interface_property avalon_master SVD_ADDRESS_GROUP ""
add_interface_port avalon_master master_address address Output 32
add_interface_port avalon_master master_write write Output 1
add_interface_port avalon_master master_byteenable byteenable Output 4
add_interface_port avalon_master master_writedata writedata Output 32
add_interface_port avalon_master master_read read Output 1
add_interface_port avalon_master master_readdatavalid readdatavalid Input 1
add_interface_port avalon_master master_readdata readdata Input 32
add_interface_port avalon_master master_waitrequest waitrequest Input 1
#
# connection point clock_sink
#
add_interface clock_sink clock end
set_interface_property clock_sink clockRate 0
set_interface_property clock_sink ENABLED true
set_interface_property clock_sink EXPORT_OF ""
set_interface_property clock_sink PORT_NAME_MAP ""
set_interface_property clock_sink CMSIS_SVD_VARIABLES ""
set_interface_property clock_sink SVD_ADDRESS_GROUP ""
add_interface_port clock_sink master_clk clk Input 1
#
# connection point reset_sink
#
add_interface reset_sink reset end
set_interface_property reset_sink associatedClock clock_sink
set_interface_property reset_sink synchronousEdges DEASSERT
set_interface_property reset_sink ENABLED true
set_interface_property reset_sink EXPORT_OF ""
set_interface_property reset_sink PORT_NAME_MAP ""
set_interface_property reset_sink CMSIS_SVD_VARIABLES ""
set_interface_property reset_sink SVD_ADDRESS_GROUP ""
add_interface_port reset_sink master_reset reset Input 1
Итак. У меня в проекте традиционно имеется каталог MyCores. Туда я кладу СистемВерилоговский файл spitoAvalon_mm.sv.
А теперь на уровень проекта кладу файл SpiToAvalonMM_hw.tcl.
Прекрасно. Открываем Platform Designer и… видим, что наш компонент сам запрыгнул в перечень доступных!
Собственно, внедрение завершено, но давайте чисто для справки я пробегусь по основным его свойствам. Вот так я раскидал всё по шинам:
Обратите внимание, что всем линиям шины SPI пришлось дать осмысленные имена.
Теперь посмотрим настройки шины AVALON_MM
Я выставил адресацию с точностью до байта. Можно было бы переключить точность до слова, но раз у меня есть линии BYTE_ENABLE, то можно же сделать работу с байтами и WORDами. Так что до байта. И какая-то из латентностей, уже не помню какая, была установлена в единицу. Я заменил на ноль. Собственно, на рисунке выше все задержки и латентности равны нулю, так что не перепутаете. Единицу будет хорошо видно.
Добавляем тестовую систему
Собственно, как проверить шину? А давайте через неё подключим небольшую ОЗУшку и попробуем писать и читать данные. Добавляем в систему, доставшуюся нам в наследство от прошлых статей, два элемента: мост SpiToAvalonMM и On Chip Memory. Но ОЗУ мы настроим чуть более сложно, чем обычно. Дело в том, что при отладке зеркальных систем можно получить, что запись и чтение работают. Но если допущена идеологическая ошибка в обоих направлениях, оно неверно запишется, так же неверно считается, но считанные данные совпадут с записанными, и мы увидим ложную работу. Поэтому желательно, чтобы в ОЗУ были заранее известные данные. Сначала мы убедимся, что они читаются верно, а уже затем начнём проводить пару запись-чтение, чтобы проверить уже работу записи при заведомо работающем чтении. Для этого мы взводим флажок Enable non-default initialization file и начинаем разбираться, куда положить и как сделать файл onchip_mem.hex.
Кладём его на тот же уровень, где живут файлы *.qpf и *.qsf. А вот с содержимым придётся немного повеселиться. Генератор такого файла входит в состав NIOS II EDS, то есть, в состав Квартуса. Но увы, это elf2hex. А нам бы bin2hex. Я нашёл замечательный проект SRecord 1.64 (sourceforge.net), который умеет преобразовывать любые файлы в любые. Замечательный проект! Он стоит того, чтобы попасть в записные книжки разработчиков железа… Но в классическом HEXе адресация идёт байтами, а Квартус хочет, чтобы шла DWORD-ами, поэтому пришлось писать генератор hex файла самому. Учитывая, что надо было экономить время на разработку, он получился таким.
Смотреть текст.
void SpiToAvalonDemo::on_m_btnCreateMemInitFile_clicked()
{
// Create an output stream
QFile file ("onchip_mem.hex");
if (!file.open(QIODevice::WriteOnly))
{
return;
}
QTextStream out (&file);
uint32_t initData [4096/sizeof(uint32_t)];
memset (initData,0,sizeof(initData));
initData [0x00] = 0x12345678;
initData [0x01] = 0x11111111;
initData [0x02] = 0x22222222;
initData [0x03] = 0x33333333;
initData [0x04] = 0x44444444;
initData [0x05] = 0x55555555;
initData [0x06] = 0x66666666;
initData [0x07] = 0x77777777;
initData [0x08] = 0xffffffff;
// Адрес всегда нулевой
out << ":020000020000FC\r\n";
for (size_t i=0;i<sizeof(initData)/sizeof(initData[0]);i+=8)
{
uint8_t cs = 0x20;
out <<":20";
cs += (uint8_t) (i/0x100);
cs += (uint8_t) (i/0x1);
out << QString ("%1").arg(i,4,16,QChar('0'));
out << "00";
uint8_t* ptr = (uint8_t*)(initData+i);
for (int j=0;j<32;j++)
{
cs += ptr[j];
out << QString ("%1").arg(ptr[j],2,16,QChar('0'));
}
cs = -1 * cs;
out << QString ("%1\r\n").arg(cs,2,16,QChar('0'));
}
// EOF
out << ":00000001FF\r\n";
// out.writeRawData((const char*)initData,sizeof(initData));
file.close();
}
Просто для справки: вот так выглядят вновь добавленные блоки в процессорной системе:
Conduit выход spi экспортирован наружу, единственная шина AVALON_MM соединяет наш мастер со slave-входом ОЗУ. А больше я даже не знаю, что сказать. Обычно у нас системы были позабористей. Тут – всё просто.
Не забываем назначить новые выводы
Не забываем, что у нас появились новые выводы (SPI). Дело в том, что когда я повторял свои подвиги при написании этого текста, я реально забыл это сделать, и очень удивлялся, что постоянно читается FFFFFF, хотя система уже была проверена при черновой подготовке и не должна была дурить. Так что не забываем! Для моей аппаратуры получилось так:
Дорабатываем код FX3
В прошлый раз в «прошивке» FX3 мы сделали только запись в SPI. В этот раз надо добавить чтение. Для начала – чтение бита данных. Если при записи было очень полезно работать с конкретными битами, так как вместо чтения-модификации-записи, можно было только писать, то при чтении такой режим не даёт никакого выигрыша. Всё равно надо принять данные и как-то выделить требуемый бит. Поэтому для чтения данных я сделал такой макрос:
#define GET_IO_BIT(nBit) ((GPIO->lpp_gpio_invalue1 >> (nBit-32))&1)
Из оптимизации там только то, что я заранее знаю, что нужные нам биты находятся в диапазоне 32-63, поэтому сразу обращаюсь к регистру GPIO->lpp_gpio_invalue1, не тратя такты процессора на проверку.
Само чтение – тоже особо ничем не приметно. Но кто будет вглядываться в текст, тот заметит, что последовательность действий отличается от той, которая напрашивается сама собой. Я просто постарался раскидать работу, чтобы и в положительном, и в отрицательном полупериоде сигнала SCK задержку вносили какие-то полезные команды. Было бы обидно всё полезное расположить в одной половинке, а в другую добавлять бесполезную задержку при помощи NOPов. И так всё медленно работает!
Смотреть текст.
unsigned int SPI_Read (int nBits)
{
unsigned int data = 0;
SET_IO_BIT (MY_BIT_MOSI);
while (nBits)
{
data >>= 1;
nBits -= 1;
CLR_IO_BIT (MY_BIT_CLK);
data |= (GET_IO_BIT (MY_BIT_MISO) << 31);
SET_IO_BIT (MY_BIT_CLK);
}
CLR_IO_BIT (MY_BIT_CLK);
return data;
}
И, наконец, обработчик Vendor-команды в итоге стал таким:
Смотреть текст.
if (bType == CY_U3P_USB_VENDOR_RQT)
{
// Cut size if need
if (wLength > sizeof(ep0_buffer))
{
wLength = sizeof (ep0_buffer);
}
// Need send data to PC
if (bReqType & 0x80)
{
CLR_IO_BIT(MY_BIT_SS);
SPI_Write(bRequest,8);
SPI_Write(wValue,16);
SPI_Write(wIndex,16);
ep0_buffer [0] = SPI_Read (32);
SET_IO_BIT(MY_BIT_SS);
CyU3PUsbSendEP0Data (wLength, (uint8_t*)ep0_buffer);
isHandled = CyTrue;
} else
{
CyU3PUsbGetEP0Data (wLength, (uint8_t*)ep0_buffer, NULL);
ep0_buffer [wLength] = 0; // Null terminated String
CyU3PDebugPrint (4, (char*)ep0_buffer);
CLR_IO_BIT(MY_BIT_SS);
SPI_Write(bRequest,8);
SPI_Write(wValue,16);
SPI_Write(wIndex,16);
SPI_Write(ep0_buffer[0],32);
SET_IO_BIT(MY_BIT_SS);
CyU3PUsbAckSetup();
isHandled = CyTrue;
}
}
Черновая проверка
Как и в прошлый раз, начерно всё проверяем через какую-нибудь подавалку USB-команд. Лично я предпочитаю BusHound. Как через него выполнять подобные проверки, было рассказано в предыдущей статье. Вот я читаю адрес 0. Длину всегда задаю равную четырём. Читается 12345678, как раз то, что было записано в файле onchip_mem.hex.
С адреса 4 читается 11111111
Ну, и так далее. Теперь пробуем записать. Скажем, по адресу 0x40 значение 0x87654321.
Контрольное чтение даст то же самое. Для экономии места я не буду показывать, как сначала писал несколько слов по разным адресам, а затем – читал их и убеждался, что значение осталось прежним. Вы можете поверить мне на слово, либо сделать аналогичную систему и проверить это самостоятельно.
Добавляем код для программной работы
Убедившись, что всё работает верно, я добавил в класс, общающийся с библиотекой LibUSB, две функции. Если быть совсем точным, то я создал класс CAvalonViaFX3, унаследовав его от уже известного по одной из прошлых статей CUsbTester, а уже в него добавил эти две функции. Но это уже детали реализации, для нас сейчас важен сам код. Вот он:
bool CAvalonViaFX3::WriteDword(uint32_t addr, uint32_t data)
{
int res = libusb_control_transfer(m_hUsb,
0x40,0xf1,
(uint16_t)addr,(uint16_t)(addr>>16),
(unsigned char*)&data,4,100);
return (res == 4);
}
bool CAvalonViaFX3::ReadDword(uint32_t addr, uint32_t& data)
{
int res = libusb_control_transfer(m_hUsb,
0xc0,0xf0,
(uint16_t)addr,(uint16_t)(addr>>16),
(unsigned char*)&data,4,100);
return (res == 4);
}
Ну, и код, тестирующий память, размером 4 килобайта, выглядит так:
static const int memSize = 4096;
void SpiToAvalonDemo::on_m_btnMemoryTest_clicked()
{
QRandomGenerator genWrite (1234);
uint32_t data [memSize/sizeof(uint32_t)];
for (size_t i=0;i<memSize/sizeof(uint32_t);i++)
{
data[i] = genWrite.generate();
}
for (int i=0;i<memSize;i+=sizeof(uint32_t))
{
if (!m_tester.WriteDword(i,data[i/sizeof(uint32_t)]))
{
QString msg = QString ("Write Error at Addr: 0x%1\n").arg(i,8,16,QChar('0'));
qDebug() << msg;
return;
}
}
for (int i=0;i<memSize;i+=sizeof(uint32_t))
{
uint32_t rd;
if (!m_tester.ReadDword(i,rd))
{
QString msg = QString ("Read Error at Addr: 0x%1\n").arg(i,8,16,QChar('0'));
qDebug() << msg;
return;
}
if (rd!=data[i/sizeof(uint32_t)])
{
QString msg = QString ("Miscompare at Addr: 0x%1 Written: %2 Read: %3\n").arg(i,8,16,QChar('0')).
arg(data[i],8,16,QChar('0')).arg(rd,8,16,QChar('0'));
qDebug() << msg;
return;
}
}
qDebug()<<"Test Finished\n";
}
Внутренний буфер data пришлось завести для того, чтобы можно было выводить при ошибках ожидаемые значения. Правда, это не понадобилось, всё работает и так. Но если бы понадобилось – это бы сильно помогло выяснить наиболее вероятную причину ошибки (сбой адреса, сбой данных, прочие сбои). Если делать на века, то, разумеется, можно было бы обойтись без буфера, пользуясь только генератором псевдослучайных чисел, порождённым от той же базовой константы, от которой был порождён генератор чисел, использованные при записи. Но это бы сделало текст менее читаемым, а для статей читаемость важнее, чем доведение эффективности из области «и так неплохо» в область идеала.
Заключение
Мы освоили методику разработки мастеров, читающих и пишущих в шину AVALON_MM. Набивая руку, мы сделали переходник SPI в AVALON_MM и проверили его работоспособность. При работе с контроллером FX3 это позволит обращаться (с не очень высокой производительностью) к шине без использования каких-либо сторонних средств, так как раньше пришлось бы работать с TCL-командами или скриптами.
Материалы, получившиеся при написании статьи, можно скачать тут.



VBKesha
Спасибо за статью!
EasyLy Автор
На здоровье!
В цикле остались две штуки. Они уже сделаны, просто ещё на Хабр не выложены (теги вписывать — не в WORDе форматирование делать). И что дальше — пока не придумал. Но в анализатор уже по проекту реально играю. Проект как ждал, чтобы вовремя свалиться.
VBKesha
Я глядя на ваши статьи, достал свой старый проект и начал более менее в порядок приводить. И по ходу дела успел уже помучатся с SPI альтеровским, с его мерзкой длинной по чтению данных. А теперь вот SGDMA который судя по даташиту если он начал работать то не остановить.
В общем веселье со всех сторон, но проект более менее приобретает цивильный вид, а не набор подпорок.