Пару лет назад, в разговоре с кем-то промелькнула примерно такая фраза: "Мы используем In-Memory OLTP - это очень быстро, зачастую даже вместо временных таблиц создаём In-Memory и всем советуем". Спустя какое-то время, мне задали вопрос как можно держать одну таблицу в памяти, чтобы работать с ней максимально быстро. Выяснив подробности - небольшая таблица, данные должны храниться только за последние несколько минут, суммарно не больше 10000 записей "приемлемых" (не LOB) типов данных, потеря данных при перезагрузке/файловере не страшна и даже приветствуется. In-Memory OLTP, без тени сомнения ответил я.
Перед запуском в продакшн я излазил всю документацию, проводил свои тесты - просто огонь. Работает реально быстро, таблица SCHEMA_ONLY и IO не генерирует вообще (я же умный, смотрю sys.dm_io_virtual_file_stats до и после). С обращениями через natively compiled stored procedures - не просто быстро работает, летает. Одним словом мечта.
Правда, оказалось, что у моей мечты есть тёмная сторона.
Сочиняем мечту
Про In-Memory написано уже очень много всего, в т.ч. и на Хабре (1, 2). И во всех материалах, которые я встречал, написано:
SCHEMA_ONLY
This option ensures durability of the table schema. When SQL Server is restarted or a reconfiguration occurs in an Azure SQL Database, the table schema persists, but data in the table is lost. (This is unlike a table in tempdb, where both the table and its data are lost upon restart.) A typical scenario for creating a non-durable table is to store transient data, such as a staging table for an ETL process. A SCHEMA_ONLY durability avoids both transaction logging and checkpoint, which can significantly reduce I/O operations.
Жирненьким текст в цитате выделил я, потому что во всех источниках видел эту фразу в том или ином виде. Если мы создаём таблицу как SCHEMA_ONLY, её содержимое никоим образом не попадает на диск - данные не пишутся ни в журнал транзакций, ни при чекпоинтах.
Но так ли это на самом деле?
Воплощаем мечту
Я делаю всё на SQL Server 2017, но всё описанное будет одинаковым для любой версии SQL Server 2014-2019 (правда, на 2016 не проверял).
Итак, чтобы насладиться быстродействием In-Memory OLTP нам нужна база данных, в этой БД нужно создать файловую группу, которая CONTAINS MEMORY_OPTIMIZED_DATA и в этой файловой группе нужно создать файл (на самом деле каталог). Поехали
CREATE DATABASE hekaton;
GO
ALTER DATABASE hekaton
ADD FILEGROUP hekaton CONTAINS MEMORY_OPTIMIZED_DATA;
GO
ALTER DATABASE hekaton
ADD FILE (
NAME=hekaton_hekaton,
FILENAME='D:\SQLServer\DEFAULT\hekaton_hekaton'
)
TO FILEGROUP hekaton;
GO
ALTER DATABASE hekaton
SET RECOVERY FULL;
GO
BACKUP DATABASE hekaton TO DISK = 'NUL';
GO
USE hekaton
GO
SELECT name, type_desc, size * 8 / 1024 AS sizeMB
FROM sys.database_files;Я перевожу БД в полную модель восстановления, потому что то, о чём я буду говорить дальше, наиболее очевидно проявляется в ней. Последний запрос выводит список файлов и их размеры:
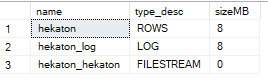
Да, каюсь, я никогда не работал с FILESTREAM. Да, везде написано, что In-Memory файловая группа, по сути, FILESTREAM. Если вы работали, то, наверное, уже понимаете, от чего у меня полыхает. Если нет - давайте я покажу.
Убиваем мечту
Теперь переходим к тому, из-за чего всё затевалось, я создаю чудесную, молниеносную, волшебную In-Memory таблицу с DURABILITY = SCHEMA_ONLY и даже вставляю в неё одну запись:
CREATE TABLE hekaton (
id int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1500000)
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY);
GO
INSERT INTO hekaton (id)
VALUES (1);
GOНу и посмотрим, что у нас вставилось и сколько теперь файлы занимают на диске:
SELECT *
FROM hekaton;
SELECT name, type_desc, size * 8 / 1024 AS sizeMB
FROM sys.database_files;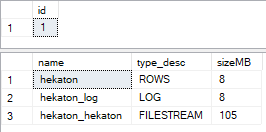
Воу, 105 мегабайт на диске для хранения 1 записи? Ну, ладно, я, в общем, готов с этим смириться - ведь больше расти не будет, правильно? Нет, не правильно. Для демонстрации я запущу вот это:
CHECKPOINT;
GO 10
SELECT name, type_desc, size * 8 / 1024 AS sizeMB
FROM sys.database_files;Господа, делайте ваши ставки! Что произойдёт с размером файлов после выполнения десяти чекпоинтов? Я бы зуб поставил, что ничего (и хорошо, что не поставил):
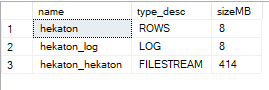
Но ведь это же не может быть правдой? У меня SCHEMA_ONLY-таблица с одной записью! Так, ладно. Насколько же глубока кроличья нора? В документации сказано, что нужно планировать место в размере размер in-memory таблицы * 4, где-то я видел, что нужно обеспечить свободное место в объём ОЗУ, доступного SQL Server, * 4. Давайте попробуем.
EXEC sp_configure 'show advanced options', 1
RECONFIGURE
GO
EXEC sp_configure 'max server memory (MB)', 512
RECONFIGURE
GO
EXEC sp_configure 'max server memory (MB)'
CHECKPOINT;
GO 100
SELECT name, type_desc, size * 8 / 1024 AS sizeMB
FROM sys.database_files;Ваши ставки?

Такие дела. In-Memory таблица с одной записью (которая даже не изменяется), оказывается может занимать на диске столько места, сколько доступно на этом диске.
Срываем покровы
Вам, наверняка интересно почему так получается. На самом деле, мне тоже интересно, почему так получается со SCHEMA_ONLY-таблицей. В целом, на msdn есть отличная статья про Durability Memory-Optimized таблиц (а если вам нужно детально разобраться с тем как устроен In-Memory OLTP, есть отличный whitepapper от Kalen Delaney). И, справедливости ради, нигде не написано, что для SCHEMA_ONLY таблиц поведение будет отличаться.
Суть в том, что для обеспечения Durability, SQL Server создаёт и хранит Data и Delta файлы для одной или нескольких таблиц. Оба файла append-only и есть специальный background-процесс, который отвечает за запись в них. Периодически эти файлы мёржатся, а "старые", "ненужные" уже Data и Delta файлы удаляются специальным сборщиком мусора. Исходя из цитаты в начале (ну и если наблюдать за sys.dm_db_xtp_checkpoint_files) - SQL Server ничего не пишет в журнал транзакций и при чекпоинтах, но всё равно создаёт эти файлы при каждом CHECKPOINT'е! Причём, если у вас больше 16 ГБ ОЗУ - файлы будут по 128 МБ, если меньше (как у меня сейчас) - по 16 МБ. Ну а в каких-то случаях, начиная с SQL Server 2016, могут использоваться "large checkpoint" по 1 ГБ!
Ключевая, для меня, фраза в статье (хотя, на мой взгляд, она не передаёт все нюансы):
CFPs transition through several states before they can be deallocated. Database checkpoints and log backups need to happen to transition the files through the phases, and ultimately clean up files that are no longer needed.
Исходя из написанного здесь (там про FILESTREAM) и собственного горького опыта, речь не столько о самих бэкапах и чекпоинтах (ВАЖНО! Не делайте чекпоинты без бэкапа журнала транзакций в полной модели восстановления, чтобы вызвать сборщик мусора - ситуация будет становиться только хуже), сколько о том, что для того, чтобы файлы могли совершить "transition through the phases" нужно чтобы тот VLF, в котором они были созданы, был помечен как неактивный.
Ну ладно, скажете вы, это же ерунда - бэкапы журнала транзакций в полной модели восстановления у вас снимаются регулярно, а в простой модели восстановления и волноваться не о чем. И я скажу вам да, но нет.
Давайте посмотрим как это выглядит:
ALTER DATABASE hekaton
SET RECOVERY SIMPLE;
GO
BACKUP DATABASE hekaton TO DISK = 'NUL';
GO
CHECKPOINT;
GO
SELECT name, type_desc, size * 8 / 1024 AS sizeMB
FROM sys.database_files;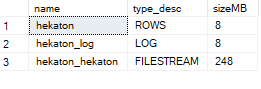
Повторим эксперимент. В одной сессии откроем транзакцию:
CREATE TABLE foo (bar int);
GO
BEGIN TRAN
INSERT INTO foo (bar)
VALUES (1);А во второй выполним:
CHECKPOINT;
GO 30
SELECT name, type_desc, size * 8 / 1024 AS sizeMB
FROM sys.database_files;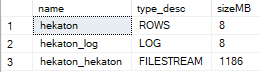
Ой, в простой модели восстановления файловая группа для In-Memory продолжает расти, если что-то мешает "переводу" нужного VLF в статус "неактивный". Это может быть незакрытая транзакция, репликация, какой-нибудь REBUILD индексов - да много можно чего придумать.
В полной модели восстановления у вас, помимо перечисленного, может быть настроена Availability Group.
DANGER! Availability Group
А что не так с Availability Group? С ней всё так, не считая того, что она использует специальный механизм, который не отмечает забэкапленные VLF как неактивные. Почему? Потому что Microsoft заботится о нас. Потому что у нас может отвалиться реплика, а что же ей потом делать, если пока она была офлайн, прошёл бэкап журнала транзакций? Вот на этот случай, SQL Server и не отмечает неактивными VLF даже после бэкапа журнала транзакций (предполагаю, что тоже самое может касаться Database Mirroring). При этом для процесса, пишущего в журнал транзакций, нет проблемы понять какие "активные" VLF можно переиспользовать, а какие нет. Более подробно про Availability Group и FILESTREAM.
Честно говоря, даже удивительно, что какие-то механизмы могут понимать, что VLF, отмеченный как активный, на самом деле неактивный, а In-Memory OLTP не может. Но благодаря этому, моя чудесная SCHEMA_ONLY-таблица из 10 тысяч строк, о которой я говорил в начале, в нормальной жизни занимает порядка 2 МБ в памяти и 4 ГБ на диске, а во время "окна для обслуживания" может занимать на диске в десятки раз больше.
А это правда проблема?
It depends.
С одной стороны - проблема не самая большая. По сути, без Availability Group, проблема возникает только в том случае, когда за промежуток между бэкапами журнала транзакций, выполняется столько чекпоинтов, что файловая группа вырастает настолько, что это становится проблемой. В каких ситуациях это возможно? Наиболее вероятный вариант, кмк - это "обслуживание индексов". Документация говорит:
For memory-optimized tables, an automatic checkpoint is taken when transaction log file becomes bigger than 1.5 GB since the last checkpoint. This 1.5 GB size includes transaction log records for both disk-based and memory-optimized tables.
Плюс, у нас есть recovery interval и target recovery time, которые тоже влияют на частоту чекпоинтов. Будет ли это проблемой для вас - я не знаю. В любом случае - заводя memory-optimized table (даже с DURABILITY = SCHEMA_ONLY) в большой БД, стоит начать обращать на это внимание и отслеживать чекпоинты. Availability Group значительно усугубляет ситуацию.
Нужно понимать, что в полной мере проблема с ростом in-memory файловой группы проявится (ну или наконец-таки станет проблемой) именно тогда, когда у вас и без того будет куча проблем. Вырастает журнал транзакций - железно вместе с ним вырастает In-memory файловая группа и если места на диске впритык - вас ждут незабываемые моменты. И нужно помнить, что эту файловую группу нельзя ограничить в размере, потому что если она уткнётся в этот лимит, БД перейдёт в состояние SUSPECT.

Решение?
У меня нет работающего "production-ready" решения.
В любой версии SQL Server Memory-Optimized таблицы могут занимать на диске на порядки больше места, чем в памяти, и могут занять всё свободное место вне зависимости от модели восстановления БД.
Единственное решение, которое помогает, в случае, когда место на диске приближается к концу - подрезать журнал транзакций, физически убирая, тем самым, часть VLF, чтобы сборщик мусора мог удалить лишние файлы.
Принимая решение об использовании In-Memory OLTP в промышленном окружении нужно обязательно учитывать, что:
Файловую группу In-Memory нельзя удалить из БД, она останется с вами навсегда.
Файловая группа In-Memory, при совпадении ряда условий, может быстро и значительно расти.
Таблицы, объявленные как SCHEMA_ONLY, не генерируют IO и не используют Data и Delta файлы на диске, но эти файлы для них создаются при каждом CHECKPOINT'е.
При использовании Availability Group, файловая группа In-Memory будет гораздо больше, чем в точно такой же БД, не входящей в Availability Group.




Tzimie
Ого. Весьма нетривиально.