Недавно поучаствовал в дискуссии на тему влияния на производительность указания длины в столбцах с типом nvarchar. Доводы были разумны у обеих сторон и поскольку у меня было свободное время, решил немного потестировать. Результатом стал этот пост.
Спойлер – не всё так однозначно.
Все тесты проводились на SQL Server 2014 Developer Edition, примерно такие же результаты были получены и на SQL Server 2016 (с небольшими отличиями). Описанное ниже должно быть актуально для SQL Server 2005-2016 (а в 2017/2019 требуется тестирование, поскольку там появились Adaptive Memory Grants, которые могут несколько исправить положение).
Нам понадобятся – хранимая процедура от Erik Darling sp_pressure_detector, которая позволяет получить множество информации о текущем состоянии системы и SQL Query Stress – очень крутая open-source утилита Adam Machanic/Erik Ejlskov Jensen для нагрузочного тестирования MS SQL Server.
Вопрос, на который я стараюсь ответить – влияет ли на производительность выбор длины поля (n)varchar (далее везде просто varchar, хотя всё актуально и для nvarchar), или можно использовать varchar(max) и не париться, поскольку если длина строки < 8000 (4000 для nvarchar) символов, то varchar(max) и varchar(N) хранятся IN-ROW.
Создаём 3 таблицы из трёх полей, разница только в длине varchar: 10/100/max. И заполним их одинаковыми данными:
В итоге каждая таблица будет содержать 262144 строк. Столбец I (integer) содержит неповторяющиеся числа от 1 до 262145; d (datetime) уникальные даты и v (varchar) – cast (I as varchar(10)). Чтобы это было чуть больше похоже на реальную жизнь, создаём уникальный кластерный индекс по i:
Сначала посмотрим планы выполнения разных запросов.
Во-первых, проверим, что отбор по полю varchar не зависит от его длины (если там хранится < 8000 символов). Включаем действительный план выполнения и смотрим:

Как ни странно, разница, хоть и небольшая, но есть. План запроса с varchar(max) сначала выбирает все строки, а потом их отфильтровывает, а varchar(10) и varchar(100) проверяют совпадения при сканировании кластерного индекса. Из-за этого, сканирование занимает практически в 3 раза больше времени – 0,068 секунд против 0.022 у varchar(10).
Теперь посмотрим, что будет, если просто выводить varchar-колонку, а отбирать данные по ключу кластерного индекса:

Тут всё понятно – для таких запросов никакой разницы нет.
Теперь интересная часть. Предыдущим запросом мы получили всего-то 1001 строку, а теперь хотим отсортировать их по неиндексированной колонке. Пробуем:
Ой, а что там такое жёлтенькое?
Забавно, т.е. запрос запросил и получил 6,5 мегабайт оперативной памяти для сортировки, а использовал только 96 килобайт. А насколько будет хуже, если строк будет побольше. Ну, пусть будет не 1000, а 100000:
А вот тут уже посерьёзнее. Причём первый запрос, который работает с самым маленьким varchar(10) тоже чем-то недоволен:
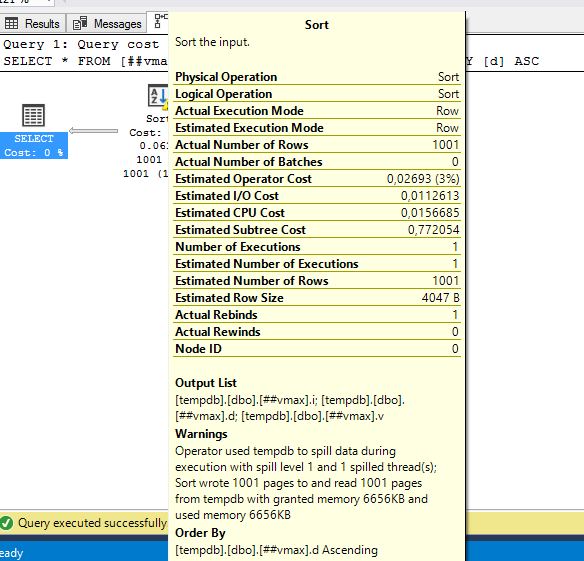
Слева тут предупреждение последнего запроса: запрошено 500 мегабайт, а использовано всего 9,5 мегабайт. А справа – предупреждение сортировки: запрошено было 8840 килобайт, но их не хватило и ещё 360 страниц (по 8 кб) было записано и прочитано из tempdb.
И тут напрашивается вопрос: WTF?
Ответ – так работает оптимизатор запросов SQL Server. Чтобы что-то отсортировать, это что-то нужно сначала поместить в память. Как понять сколько памяти нужно? Вообще, нам известно сколько какой тип данных занимает места. А что же со строками переменной длины? А вот с ними интереснее. При выделении памяти для сортировок/hash join, SQL Server считает, что в среднем они заполнены наполовину. И выделяет под них память как (размер / 2) * ожидаемое количество строк. Но varchar(max) может хранить аж 2Гб – сколько же выделять? SQL Server считает, что там будет половина от varchar(8000) – т.е. примерно 4 кб на строку.
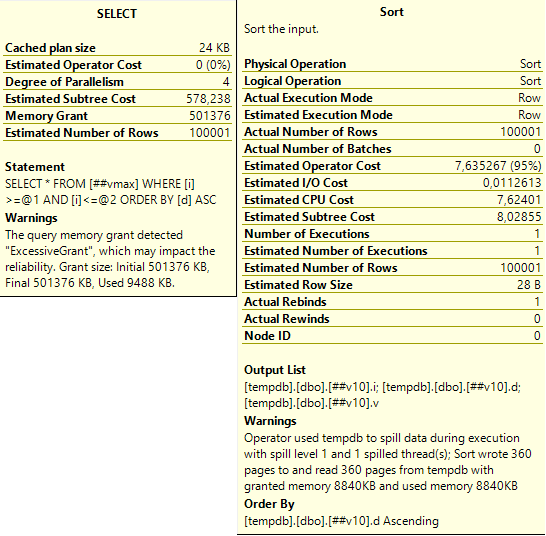
Что интересно – такое выделение памяти приводит к проблемам не только с varchar(max) – если размер ваших varchar’ов любовно подобран так, что большая часть из них заполнена наполовину и больше – это тоже ведёт к проблемам. Проблемам иного плана, но не менее серьёзным. На рисунке выше есть описание – SQL Server не смог корректно выделить память для сортировки маленького varchar’а и использовал tempdb для хранения промежуточных результатов. Если tempdb лежит на медленных дисках, или активно используется другими запросами – это может стать очень узким местом.
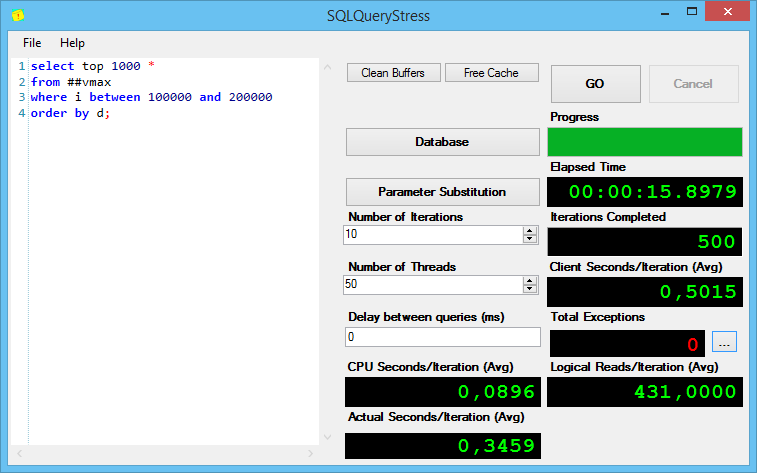
Теперь посмотрим, что происходит при массовом выполнении запросов. Запустим SQL Query Stress, подключим его к нашему серверу, и скажем выполнить все эти запросы по 10 раз в 50 потоках.
Результаты выполнения первого запроса:
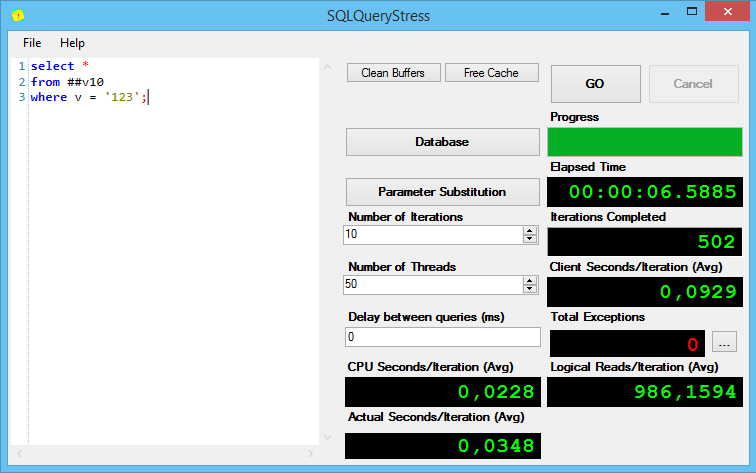
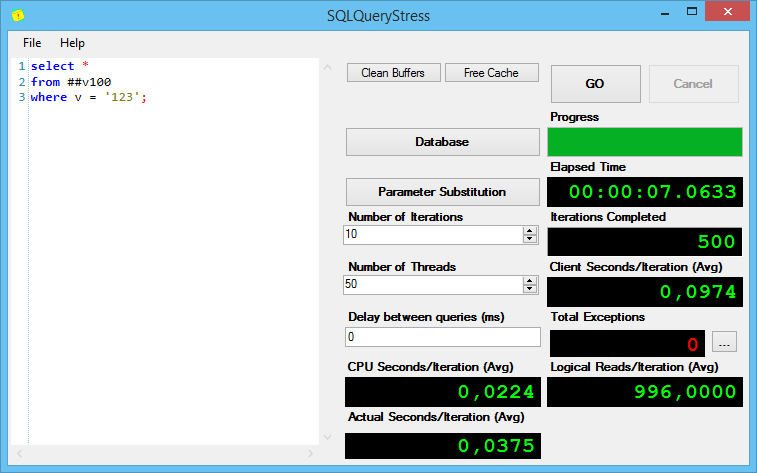
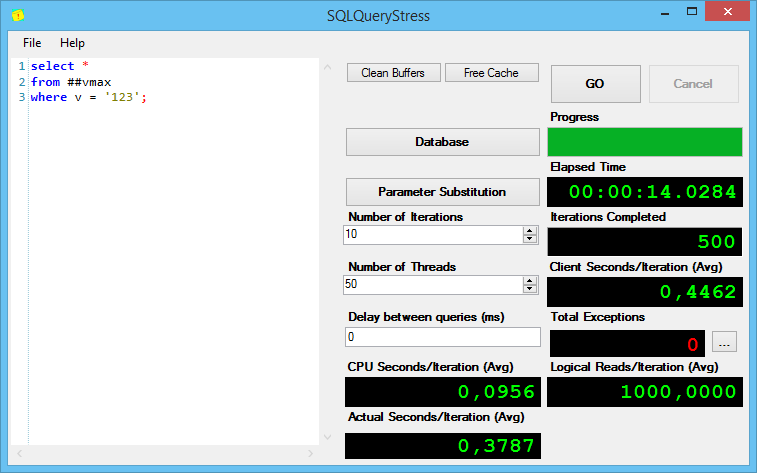
Интересно, но без индексов, при поиске varchar(max) показывает себя хуже всех, причём солидно так хуже по процессорному времени на итерацию и общему времени выполнения.
sp_pressure_detector не показывает тут ничего интересного, поэтому её вывод не привожу.
Результаты выполнения второго запроса:
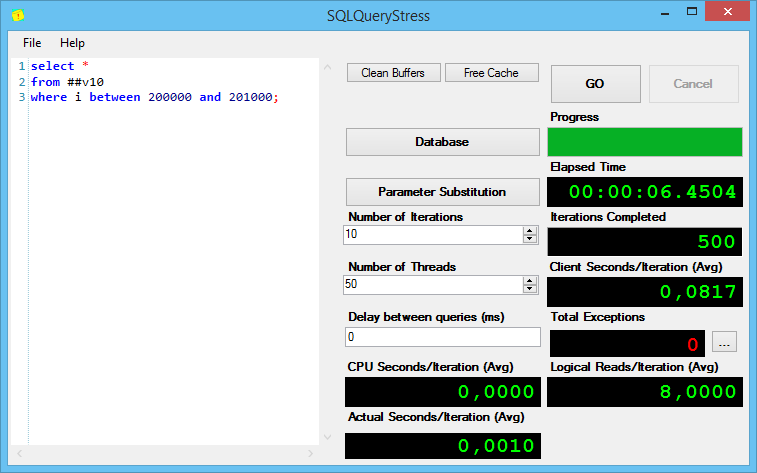
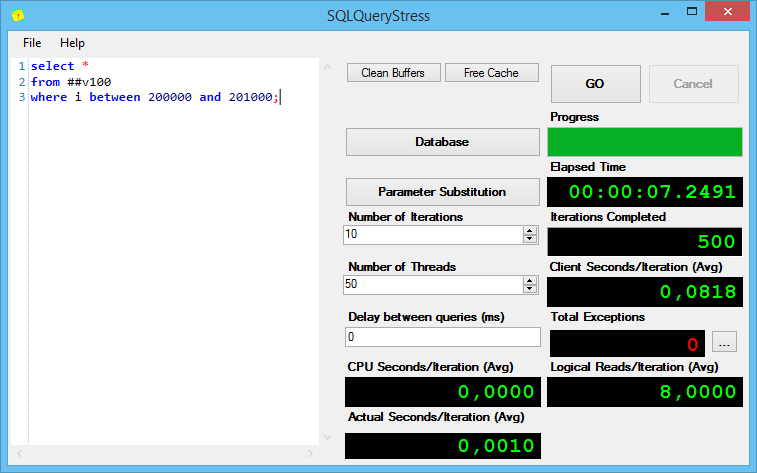

Тут всё ожидаемо – одинаково хорошо.
Теперь интересная часть. Запрос с сортировкой полученной тысячи строк:

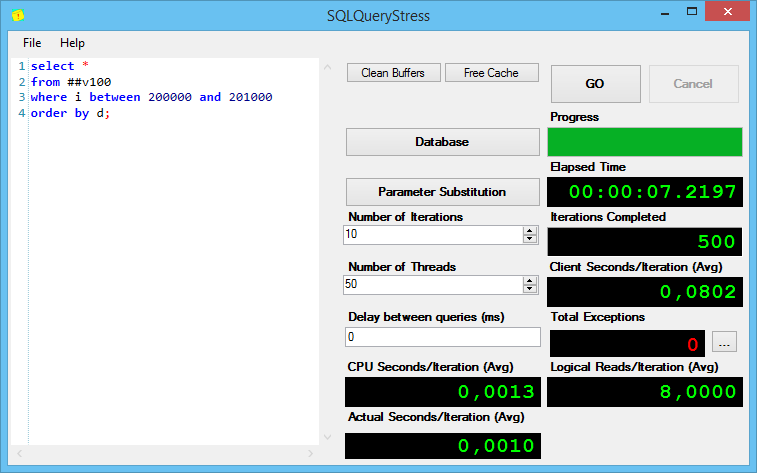
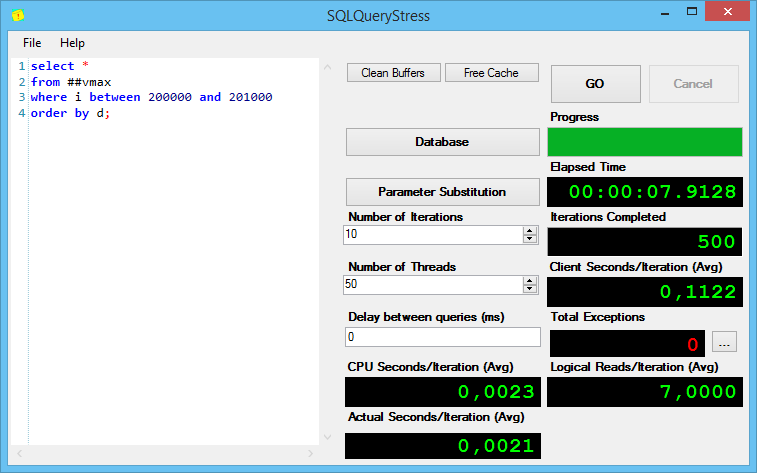
Тут всё оказалось точно также, как и с предыдущим запросом – строк не много, сортировка проблем не вызывает.
Теперь последний запрос, который сортирует неоправданно много строк (я добавил в него top 1000, чтобы не тянуть весь сортированный список):

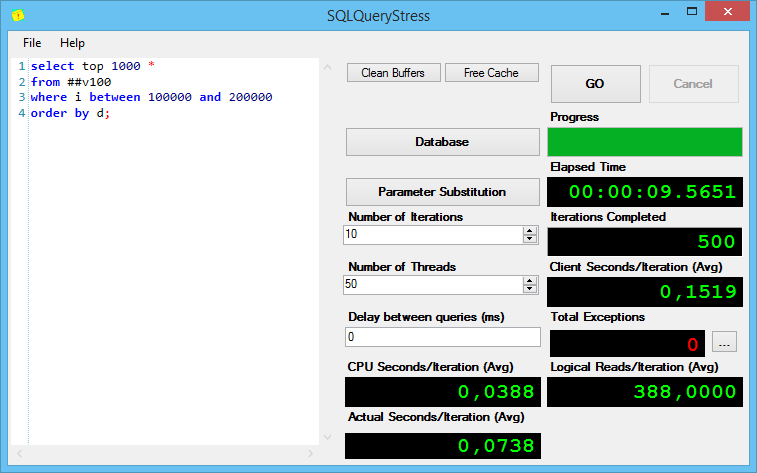
И вот тут привожу вывод sp_pressure_detector:

Что он нам говорит? Все сессии запрашивают по 489 МБ (на сортировку), но только на 22 из них SQL Server’у хватило памяти, даже учитывая, что используют все эти 22 сессии всего по 9 МБ!
Всего доступно 11 Гб памяти, 22 сессиям было выделено по 489.625 и у SQL Server’a осталось всего-то 258 доступных мегабайт, а новые сессии тоже хотят получить по 489. Что делать? Ждать, пока освободится память – они и ждут, даже не начиная выполняться. Что будут делать пользователи, если в их сессиях выполняются такие запросы? Тоже ждать.
Кстати, обратите внимание на рисунок с varchar(10) – запросы с varchar(10) выполнялись дольше, чем запросы с varchar(100) – и это при том, что у меня tempdb на очень быстром диске. Чем хуже диск под tempdb – тем медленнее будет выполняться запрос.
С осторожностью используйте сортировку в своих запросах, там где у вас есть колонки (n)varchar. Если сортировка всё же нужна, крайне желательно, чтобы по колонке сортировки был индекс.
Учтите, что чтобы получить сортировку совсем необязательно явно использовать order by – её появление возможно и при merge join’ах, например. Та же проблема с выделением памяти возможна и при hash join’ах, например, вот с varchar(max):
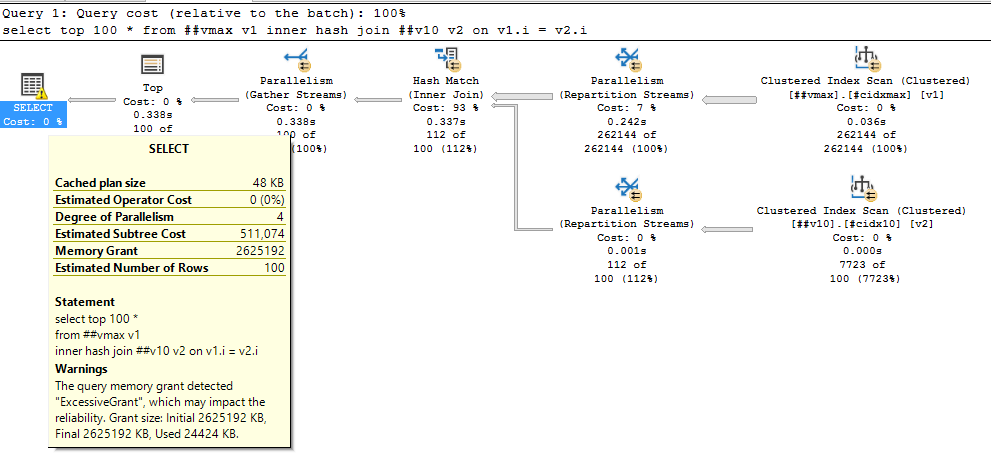
Выделено 2.5 ГИГАБАЙТА памяти, используется 25 мегабайт!
Главный для меня вывод: размер колонки (n)varchar – ВАЖЕН! Если размер слишком маленький – возможны spill’ы в tempdb, если слишком большой – возможны слишком большие запросы памяти. При наличии сортировок разумным будет объявлять длину varchar как средняя длина записи * 2, а в случае SQL Server 2012/2014 — даже больше.
Неожиданный для меня вывод: varchar(max), содержащий меньше 8000 символов, реально работает медленнее, при фильтрах по нему. Пока не знаю как это объяснить — буду копать ещё.
Бонусный вывод для меня: уже почти нажав «опубликовать» я подумал, что ведь и с varchar(max) можно испытать проблему «маленького varchar'a». И правда, при хранении в varchar(max) больше чем 4000 символов (2000 для nvarchar) — сортировки могут стать проблемой.
Почему в самом начале я написал, что не всё так однозначно? Потому что, например, на моём домашнем ноуте с полумёртвым диском, spill'ы в tempdb при сортировке «маленьких» varchar приводили к тому, что такие запросы выполнялись на ПОРЯДКИ медленнее, чем аналогичные запросы с varchar(max). Если у вас хорошее железо, возможно, они не станут такой проблемой, но забывать о них не стоит.
Что было бы ещё интересно — посмотреть есть ли какие-то проблемы из-за слишком больших/маленьких размеров varchar'ов в других СУБД. Если у вас есть возможность проверить — буду рад, если поделитесь.
Отловить такие проблемы с помощью кэша планов запросов, к сожалению, не получится. Вот примеры планов из кэша: никаких предупреждений в них, увы, нет.

Спойлер – не всё так однозначно.
Все тесты проводились на SQL Server 2014 Developer Edition, примерно такие же результаты были получены и на SQL Server 2016 (с небольшими отличиями). Описанное ниже должно быть актуально для SQL Server 2005-2016 (а в 2017/2019 требуется тестирование, поскольку там появились Adaptive Memory Grants, которые могут несколько исправить положение).
Нам понадобятся – хранимая процедура от Erik Darling sp_pressure_detector, которая позволяет получить множество информации о текущем состоянии системы и SQL Query Stress – очень крутая open-source утилита Adam Machanic/Erik Ejlskov Jensen для нагрузочного тестирования MS SQL Server.
О чём вообще речь
Вопрос, на который я стараюсь ответить – влияет ли на производительность выбор длины поля (n)varchar (далее везде просто varchar, хотя всё актуально и для nvarchar), или можно использовать varchar(max) и не париться, поскольку если длина строки < 8000 (4000 для nvarchar) символов, то varchar(max) и varchar(N) хранятся IN-ROW.
Готовим стенд
create table ##v10 (i int, d datetime, v varchar(10));
create table ##v100 (i int, d datetime, v varchar(100));
create table ##vmax (i int, d datetime, v varchar(max));Создаём 3 таблицы из трёх полей, разница только в длине varchar: 10/100/max. И заполним их одинаковыми данными:
;with x as (select 1 x union all select 1)
, xx as (select 1 x from x x1, x x2)
, xxx as (select 1 x from xx x1, xx x2, xx x3)
, xxxx as (
select row_number() over(order by (select null)) i
, dateadd(second, row_number() over(order by (select null)), '20200101') d
, cast (row_number() over(order by (select null)) as varchar(10)) v
from xxx x1, xxx x2, xxx x3
) --262144 строк
insert into ##v10 --varchar(10)
select i, d, v from xxxx;
insert into ##v100 --varchar(100)
select i, d, v from ##v10;
insert into ##vmax --varchar(max)
select i, d, v from ##v10;
В итоге каждая таблица будет содержать 262144 строк. Столбец I (integer) содержит неповторяющиеся числа от 1 до 262145; d (datetime) уникальные даты и v (varchar) – cast (I as varchar(10)). Чтобы это было чуть больше похоже на реальную жизнь, создаём уникальный кластерный индекс по i:
create unique clustered index #cidx10 on ##v10(i);
create unique clustered index #cidx100 on ##v100(i);
create unique clustered index #cidxmax on ##vmax(i);Поехали
Сначала посмотрим планы выполнения разных запросов.
Во-первых, проверим, что отбор по полю varchar не зависит от его длины (если там хранится < 8000 символов). Включаем действительный план выполнения и смотрим:
select * from ##v10 where v = '123';
select * from ##v100 where v = '123';
select * from ##vmax where v = '123';Как ни странно, разница, хоть и небольшая, но есть. План запроса с varchar(max) сначала выбирает все строки, а потом их отфильтровывает, а varchar(10) и varchar(100) проверяют совпадения при сканировании кластерного индекса. Из-за этого, сканирование занимает практически в 3 раза больше времени – 0,068 секунд против 0.022 у varchar(10).
Теперь посмотрим, что будет, если просто выводить varchar-колонку, а отбирать данные по ключу кластерного индекса:
select * from ##v10 where i between 200000 and 201000;
select * from ##v100 where i between 200000 and 201000;
select * from ##vmax where i between 200000 and 201000; Тут всё понятно – для таких запросов никакой разницы нет.
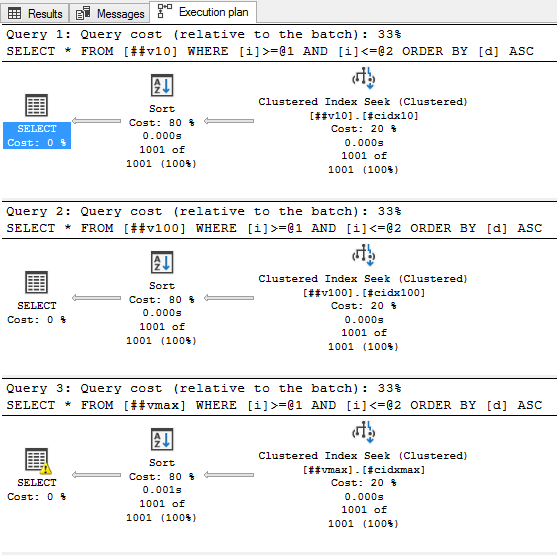
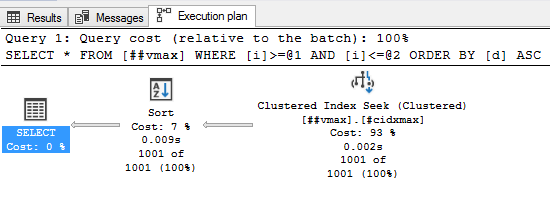
Теперь интересная часть. Предыдущим запросом мы получили всего-то 1001 строку, а теперь хотим отсортировать их по неиндексированной колонке. Пробуем:
select * from ##v10 where i between 200000 and 201000 order by d;
select * from ##v100 where i between 200000 and 201000 order by d;
select * from ##vmax where i between 200000 and 201000 order by d;Ой, а что там такое жёлтенькое?
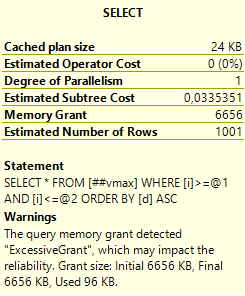
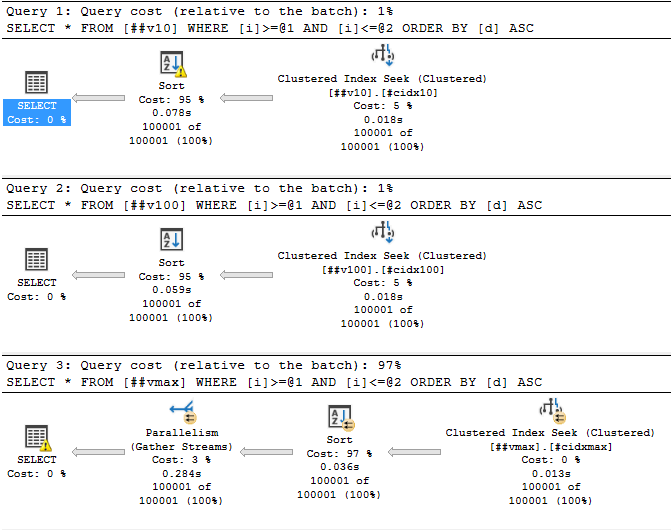
Забавно, т.е. запрос запросил и получил 6,5 мегабайт оперативной памяти для сортировки, а использовал только 96 килобайт. А насколько будет хуже, если строк будет побольше. Ну, пусть будет не 1000, а 100000:
А вот тут уже посерьёзнее. Причём первый запрос, который работает с самым маленьким varchar(10) тоже чем-то недоволен:
Слева тут предупреждение последнего запроса: запрошено 500 мегабайт, а использовано всего 9,5 мегабайт. А справа – предупреждение сортировки: запрошено было 8840 килобайт, но их не хватило и ещё 360 страниц (по 8 кб) было записано и прочитано из tempdb.
И тут напрашивается вопрос: WTF?
Ответ – так работает оптимизатор запросов SQL Server. Чтобы что-то отсортировать, это что-то нужно сначала поместить в память. Как понять сколько памяти нужно? Вообще, нам известно сколько какой тип данных занимает места. А что же со строками переменной длины? А вот с ними интереснее. При выделении памяти для сортировок/hash join, SQL Server считает, что в среднем они заполнены наполовину. И выделяет под них память как (размер / 2) * ожидаемое количество строк. Но varchar(max) может хранить аж 2Гб – сколько же выделять? SQL Server считает, что там будет половина от varchar(8000) – т.е. примерно 4 кб на строку.
Что интересно – такое выделение памяти приводит к проблемам не только с varchar(max) – если размер ваших varchar’ов любовно подобран так, что большая часть из них заполнена наполовину и больше – это тоже ведёт к проблемам. Проблемам иного плана, но не менее серьёзным. На рисунке выше есть описание – SQL Server не смог корректно выделить память для сортировки маленького varchar’а и использовал tempdb для хранения промежуточных результатов. Если tempdb лежит на медленных дисках, или активно используется другими запросами – это может стать очень узким местом.
SQL Query Stress
Теперь посмотрим, что происходит при массовом выполнении запросов. Запустим SQL Query Stress, подключим его к нашему серверу, и скажем выполнить все эти запросы по 10 раз в 50 потоках.
Результаты выполнения первого запроса:
Интересно, но без индексов, при поиске varchar(max) показывает себя хуже всех, причём солидно так хуже по процессорному времени на итерацию и общему времени выполнения.
sp_pressure_detector не показывает тут ничего интересного, поэтому её вывод не привожу.
Результаты выполнения второго запроса:
Тут всё ожидаемо – одинаково хорошо.
Теперь интересная часть. Запрос с сортировкой полученной тысячи строк:
Тут всё оказалось точно также, как и с предыдущим запросом – строк не много, сортировка проблем не вызывает.
Теперь последний запрос, который сортирует неоправданно много строк (я добавил в него top 1000, чтобы не тянуть весь сортированный список):
И вот тут привожу вывод sp_pressure_detector:
Что он нам говорит? Все сессии запрашивают по 489 МБ (на сортировку), но только на 22 из них SQL Server’у хватило памяти, даже учитывая, что используют все эти 22 сессии всего по 9 МБ!
Всего доступно 11 Гб памяти, 22 сессиям было выделено по 489.625 и у SQL Server’a осталось всего-то 258 доступных мегабайт, а новые сессии тоже хотят получить по 489. Что делать? Ждать, пока освободится память – они и ждут, даже не начиная выполняться. Что будут делать пользователи, если в их сессиях выполняются такие запросы? Тоже ждать.
Кстати, обратите внимание на рисунок с varchar(10) – запросы с varchar(10) выполнялись дольше, чем запросы с varchar(100) – и это при том, что у меня tempdb на очень быстром диске. Чем хуже диск под tempdb – тем медленнее будет выполняться запрос.
Отдельное примечание для SQL Server 2012/2014
В SQL Server 2012/2014 есть ещё одна забавная шутка с sort spills. Даже если вы используете тип char/nchar – это не гарантирует отсутствие spill’ов в tempdb. MS признала проблему в оптимизаторе, когда он выделял слишком мало памяти для сортировки, даже если количество строк было оценено верно.
Маленькое демо:

Включаем документированный флаг трассировки (НЕ ДЕЛАЙТЕ ЭТОГО НА ПРОДЕ БЕЗ НЕОБХОДИМОСТИ):
Восклицательный знак у сортировки пропал, spill’а больше нет.
Маленькое демо:
create table ##c6 (i int, d datetime, v char(6));
insert into ##c6 (i, d, v)
select i, d, v
from ##v10
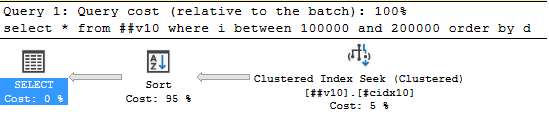
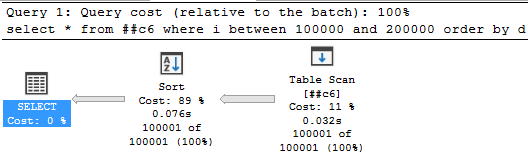
select * from ##c6 where i between 100000 and 200000 order by d;Включаем документированный флаг трассировки (НЕ ДЕЛАЙТЕ ЭТОГО НА ПРОДЕ БЕЗ НЕОБХОДИМОСТИ):
DBCC TRACEON (7470, -1);Восклицательный знак у сортировки пропал, spill’а больше нет.
Выводы
С осторожностью используйте сортировку в своих запросах, там где у вас есть колонки (n)varchar. Если сортировка всё же нужна, крайне желательно, чтобы по колонке сортировки был индекс.
Учтите, что чтобы получить сортировку совсем необязательно явно использовать order by – её появление возможно и при merge join’ах, например. Та же проблема с выделением памяти возможна и при hash join’ах, например, вот с varchar(max):
select top 100 *
from ##vmax v1
inner hash join ##v10 v2 on v1.i = v2.iВыделено 2.5 ГИГАБАЙТА памяти, используется 25 мегабайт!
Главный для меня вывод: размер колонки (n)varchar – ВАЖЕН! Если размер слишком маленький – возможны spill’ы в tempdb, если слишком большой – возможны слишком большие запросы памяти. При наличии сортировок разумным будет объявлять длину varchar как средняя длина записи * 2, а в случае SQL Server 2012/2014 — даже больше.
Неожиданный для меня вывод: varchar(max), содержащий меньше 8000 символов, реально работает медленнее, при фильтрах по нему. Пока не знаю как это объяснить — буду копать ещё.
Бонусный вывод для меня: уже почти нажав «опубликовать» я подумал, что ведь и с varchar(max) можно испытать проблему «маленького varchar'a». И правда, при хранении в varchar(max) больше чем 4000 символов (2000 для nvarchar) — сортировки могут стать проблемой.
insert into ##vmax(i, d, v)
select i, d, replicate('a', 4000) v
from ##v10;
select * from ##vmax where i between 200000 and 201000 order by d;
truncate table ##vmax;
insert into ##vmax(i, d, v)
select i, d, replicate('a', 4100) v
from ##v10;
select * from ##vmax where i between 200000 and 201000 order by d;Почему в самом начале я написал, что не всё так однозначно? Потому что, например, на моём домашнем ноуте с полумёртвым диском, spill'ы в tempdb при сортировке «маленьких» varchar приводили к тому, что такие запросы выполнялись на ПОРЯДКИ медленнее, чем аналогичные запросы с varchar(max). Если у вас хорошее железо, возможно, они не станут такой проблемой, но забывать о них не стоит.
Что было бы ещё интересно — посмотреть есть ли какие-то проблемы из-за слишком больших/маленьких размеров varchar'ов в других СУБД. Если у вас есть возможность проверить — буду рад, если поделитесь.
Маленький бонус
Отловить такие проблемы с помощью кэша планов запросов, к сожалению, не получится. Вот примеры планов из кэша: никаких предупреждений в них, увы, нет.

XelaVopelk
«Sort Warnings» в sql trace и «sort_waring» в XE ловит такие вещи.
unfilled Автор
Всё верно, но ни в default trace, ни в system_health сессии XE этих событий нет. Поймать можно, но ловить нужно специально.