В этой статье я продемонстрирую, как использовать мощные возможности гибридного облака на базе Cloudera Data Platform (CDP). Вы узнаете, как подключить локальный CDP Private Cloud Base кластер к CDP в публичном облаке и настроить репликацию данных, провести их профилирование и настроить политику маскировки полей с приватными данными.
Напоминание: видение CDP
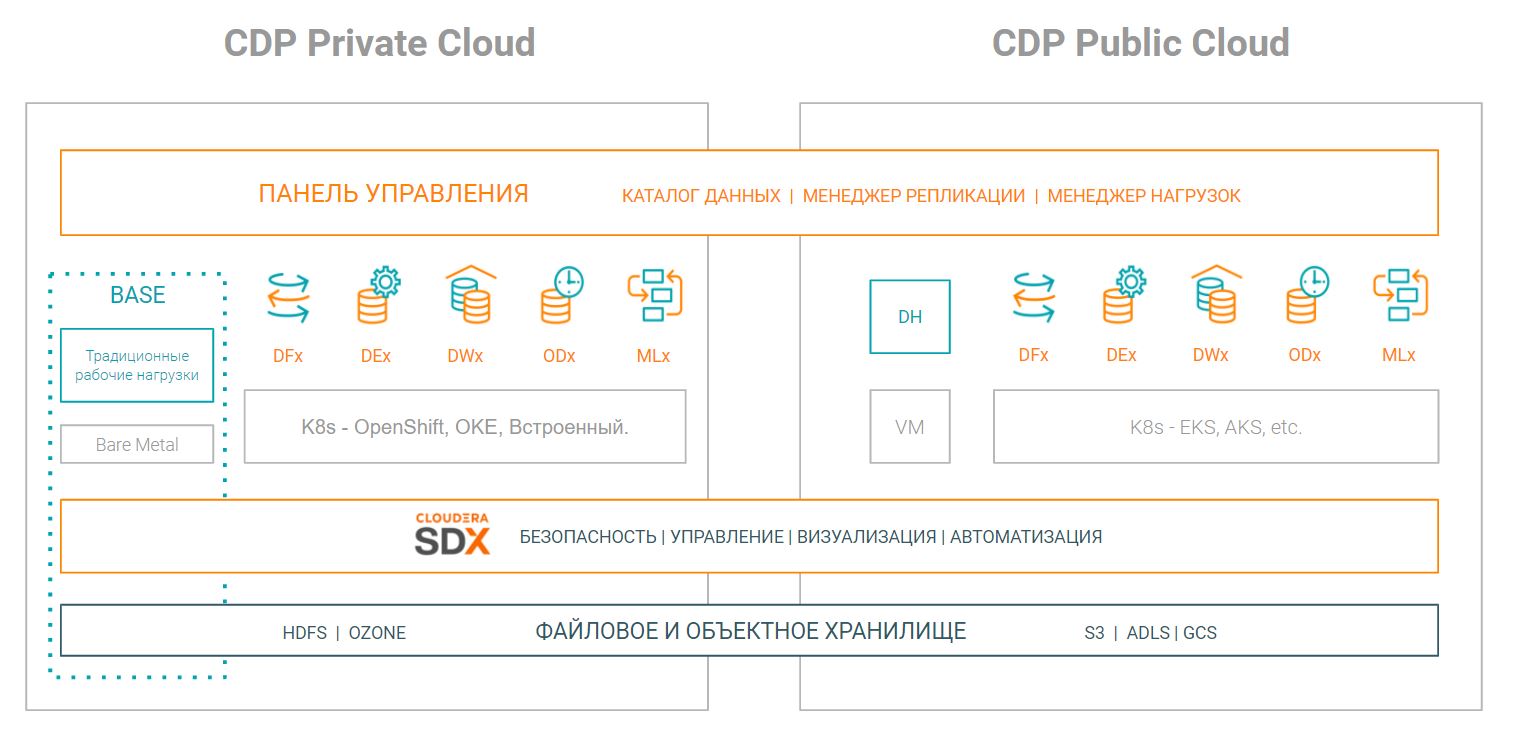
Платформа CDP разработана для беспрепятственного развертывания любых рабочих нагрузок, а также для операций с данными (таких как сбор данных, потоковая передача, обогащение, проектирование, обслуживание и задачи AI/ML) в любой инфраструктуре с использованием новейших инструментов при сохранении единого уровня безопасности и управления (SDX).
Пример использования: Worldwide Bank
В этой статье я буду использовать гипотетический пример банка (Worldwide Bank).
Предположим, что Worldwide Bank - крупный международный банк, который использует традиционную локальную архитектуру платформу больших данных (CDP PvC Base) для проектирования и хранения нескольких петабайт данных.
Поскольку пандемия COVID-19 перенесла мир в беспрецедентные времена, конкуренция достигла своего пика, ускоряя организацию данных за счет внедрения новейших технологий и архитектур, особенно облачных инфраструктур.
Первым вариантом использования новой технологической платформы является создание визуального отчета с оценкой для каждого из рисков, связанных с распространением коронавируса.
Реализация этого первого сценария предполагает возможность учета следующих факторов:
Скорость внедрения, включая развертывание облака.
Поддержание высоких стандартов конфиденциальности и безопасности данных.
Повторное использование текущего набора навыков специалистов (например, переносимость ПО).
Архитектура реализации
После тщательного рассмотрения и анализа вариантов банк выбрал в качестве основы гибридной архитектуры платформу CDP, поскольку она удовлетворяет всем его потребностям. В частности, вот схема реализации:

Предварительные требования
CDP Base кластер (с доступом уровня администратора и пользователем из HDFS supergroup)
CDP Public Cloud среда (с доступом уровня администратора)
Виртуальное хранилище CDW, работающее в среде Public Cloud
Все материалы данной статьи можно найти по этой ссылке.
Шаг 1: Регистрация CDP Base в качестве классического кластера
Начало регистрации
1. В консоли управления CDP Public Cloud перейдите в Классические кластеры > Добавить кластер > CDP Private Cloud Base и введите информацию о кластере CDP:
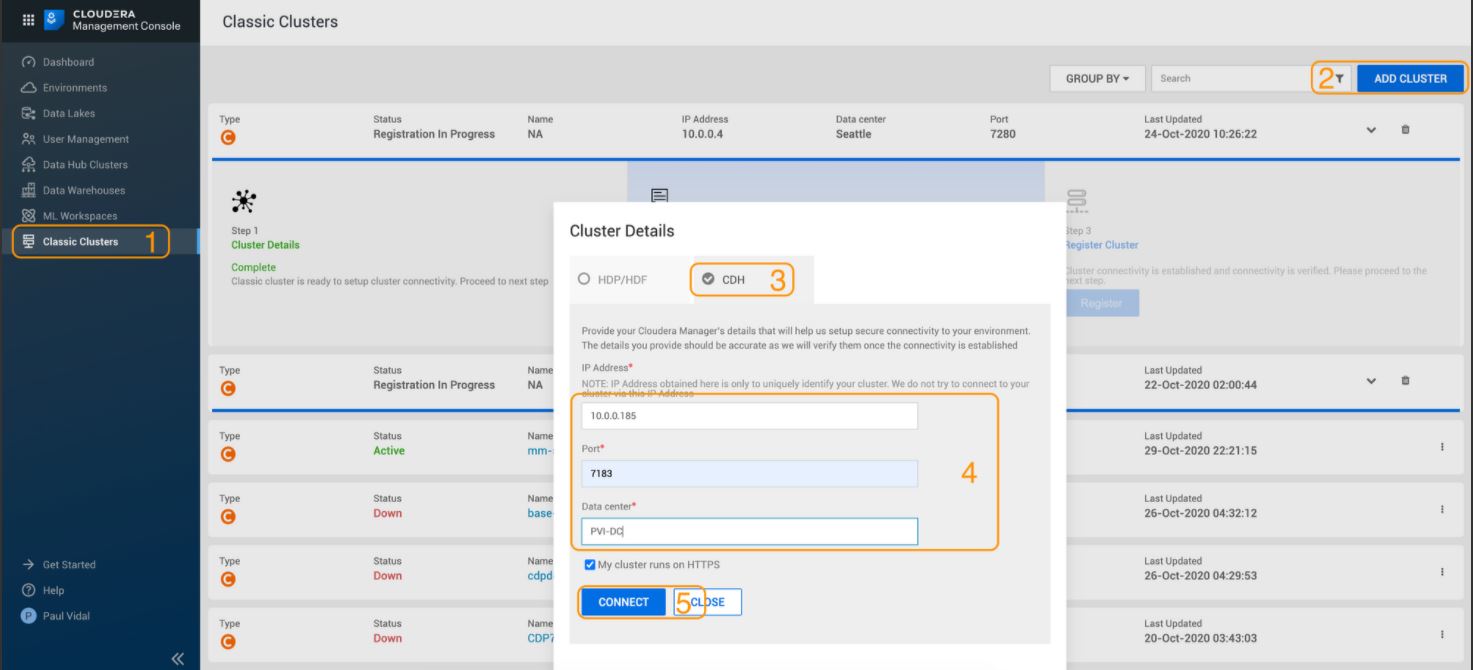
2. После этого вы увидите, что происходит регистрация вашего кластера:

Установка защищенного туннеля связи
1. Нажмите кнопку Files (Файлы) в разделе Install files (Установка файлов) и следуйте инструкциям:
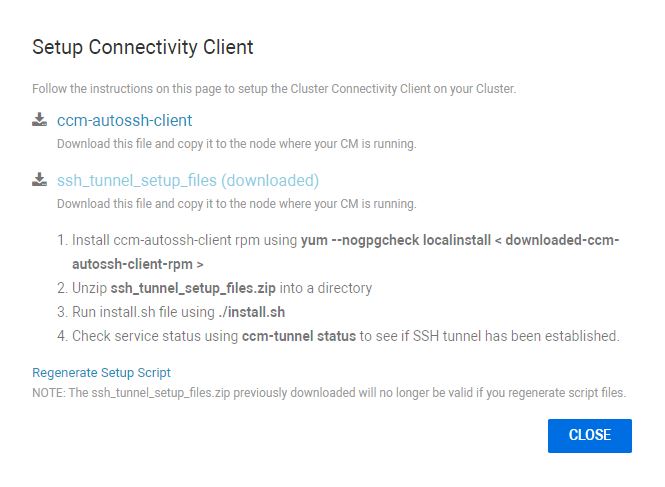
2. Ниже приведены некоторые примеры инструкций для настройки этого на вашем узле CM.
Скачайте из консоли управления архив ssh_tunnel_setup_files.zip.
Скопируйте его на ваш CM узел:
$ scp -i [your_key_location] ssh_tunnel_setup_files.zip
[your_user_with_sudo_privileges]@[your_host]:/home/[your_user_with_sudo_privileges]SSH в узел CM и установите ccm autossh:
$ ssh -i [your_key_location] [your_user_with_sudo_privileges]@[your_host]
$ sudo su $ wget https://archive.cloudera.com/ccm/0.1/ccm-autossh-client-0.1-20191023211905gitd03880c.x86_64.rpm
$ yum -y --nogpgcheck localinstall ccm-autossh-client-0.1-20191023211905gitd03880c.x86_64.rpmУстановите тоннель:
$ unzip ssh_tunnel_setup_files.zip
$ ./install.shПосле установки вы должны увидеть сообщение, подобное этому:
==========================================================================================
SSH tunnel for CM established successfully. Run 'ccm-tunnel status' for status
Run 'journalctl -f -u ccm-tunnel@CM.service' or 'journalctl -xe' for logs.
==========================================================================================
Окончание регистрации
В консоли управления нажмите кнопку Тестовое подключение
После успешного подключения вы можете нажать на Зарегистрировать, добавить пользователя/пароль для CM и подключиться:

3. Наконец, введите расположение вашего базового кластера (для отображения на карте в панели управления):

4. Теперь вы успешно создали защищенный туннель между CDP Base и CDP Public Cloud:

Шаг 2: Создание политики репликации
1. Перейдите к Менеджеру репликации > Классические кластеры > 3 точки напротив вашего кластера > Добавить политику:

2. В нашем случае мы реплицируем 2 набора данных с HDFS:
- Данные о сотрудниках
- Данные о местонахождении банка
На Шаге 1 дайте имя политике и выберите HDFS:

На втором шаге добавьте расположение вашего набора данных и имя вашего суперпользователя:

На шаге 3 выберите s3 и добавьте свои учетные данные в AWS.
3. После проверки укажите целевую корзину (ваше облачное хранилище озера данных) и проверьте его:

4. Для следующих двух шагов используйте настройки по умолчанию.
5. После того, как вы нажмете кнопку "Создать", вы увидите прогресс репликации.
6. Дождитесь его успешного завершения, а затем переходите к следующему шагу:

Шаг 3: Создание внешних и управляемых таблиц в CDW
1. Перейдите в CDW > 3 точки напротив выбранного виртуального хранилища > Открыть Hue:
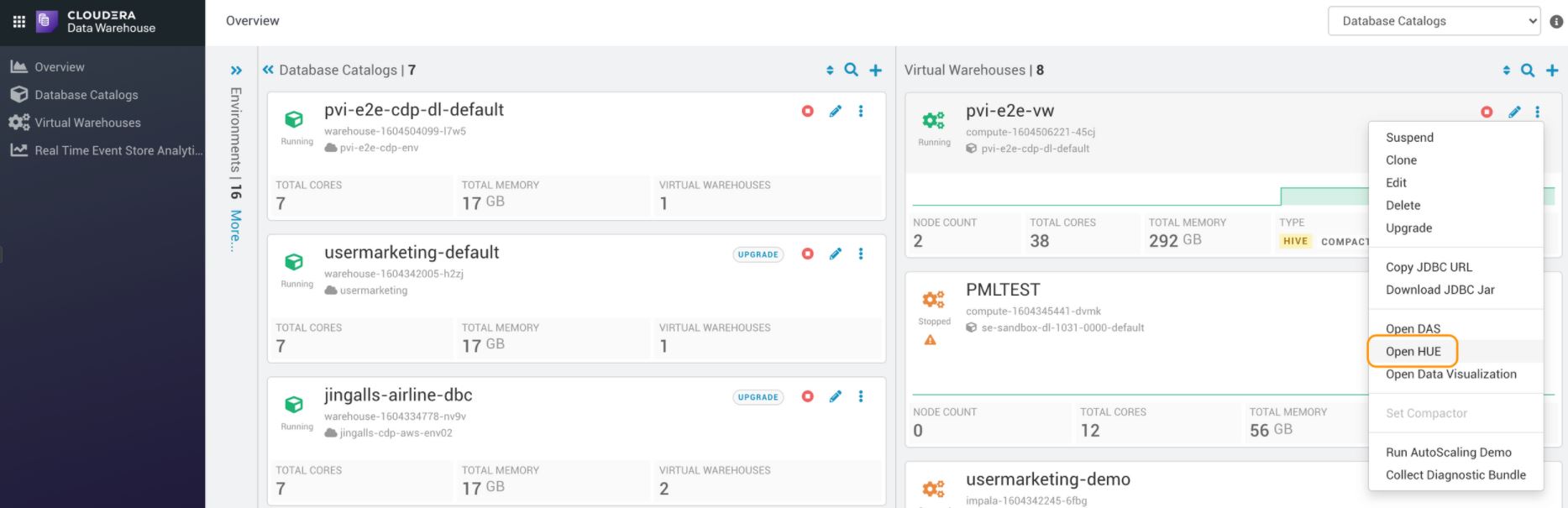
2. В редакторе запросов выполните следующие запросы (разумеется, адаптируя их к вашему облачному хранилищу):
create database if not exists worldwidebank;
use worldwidebank;
CREATE EXTERNAL TABLE if not exists worldwidebank.employees_ext(
number int,
location int,
gender string,
title string,
givenname string,
middleinitial string,
surname string,
streetaddress string,
city string,
state string,
statefull string,
zipcode string,
country string,
countryfull string,
emailaddress string,
username string,
password string,
telephonenumber string,
telephonecountrycode string,
mothersmaiden string,
birthday string,
age int,
tropicalzodiac string,
cctype string,
ccnumber string,
cvv2 string,
ccexpires string,
ssn string,
insuranceid string,
salary string,
bloodtype string,
weight double,
height int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3a://pvi-e2e-cdp-bucket/vizbank/raw/employees/'
tblproperties("skip.header.line.count"="1");
CREATE EXTERNAL TABLE if not exists worldwidebank.locations_ext(
LOCATION_ID int,
ADDRESS string,
BKCLASS string,
CBSA string,
CBSA_DIV string,
CBSA_DIV_FLG string,
CBSA_DIV_NO string,
CBSA_METRO string,
CBSA_METRO_FLG string,
CBSA_METRO_NAME string,
CBSA_MICRO_FLG string,
CBSA_NO string,
CERT string,
CITY string,
COUNTY string,
CSA string,
CSA_FLG string,
CSA_NO string,
ESTYMD string,
FI_UNINUM string,
MAINOFF string,
NAME string,
OFFNAME string,
OFFNUM string,
RUNDATE string,
SERVTYPE string,
STALP string,
STCNTY string,
STNAME string,
UNINUM string,
ZIP int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3a://pvi-e2e-cdp-bucket/vizbank/raw/locations/'
tblproperties("skip.header.line.count"="1");
create table worldwidebank.employees as select * from worldwidebank.employees_ext;
create table worldwidebank.locations as select * from worldwidebank.locations_ext;
CREATE MATERIALIZED VIEW worldwidebank.employees_per_state as select locations.stname, count(*) as num_employees from employees, locations where employees.location=locations.location_id GROUP BY locations.stname;И это все, теперь вы реплицировали данные с вашего локального кластера в облако:

Шаг 4: Запуск профилирования данных
CDP Data Catalog поставляется с профилировщиками данных из коробки. Вы, конечно, можете их настроить, но в наших наборах данных мы будем использовать стандартные профилировщики данных. Также в нём содержится информация о данных классического кластера, который мы подключили ранее.
Запуск профилирования данных
1. Перейдите в консоль управления CDP> Каталог данных > Выберите Вашу среду> Запустить профилировщики:

2. Это запустит кластер DataHub для выполнения заданий профилирования данных. Подождите, пока кластер не будет построен, как на следующем скриншоте:

Проверка профилировщика
1. Вернитесь в Каталог данных > Профилировщики > Выберите среду > Профилировщик чувствительных данных кластера и убедитесь, что профилировщики успешно работают:

2. Перейдите на страницу "Поиск" и найдите Hive таблицу Employees, откройте её схему и проверьте созданные автоматические теги :

Шаг 5: Создание политики доступа, основанной на тегах
1. В каталоге данных перейдите на вкладку Политики и перейдите к политике, чтобы открыть ее в Ranger:

2. В Ranger перейдите к созданию новой политики, основанной на тегах. Настройте правило маскировки так, как показано на следующем скриншоте.

Назовите ее (например, mask_creditcard).
Выберите тег dp_credicard (префикс dp профилировщика данных).
Выберите группу или пользователя, к которому должна применяться эта политика (здесь pvidal).
Выберите Тип доступа: Hive, Select
Выберите опцию маскирования: Redact
Шаг 6: Проверка правила безопасности
1. Вернитесь в консоль управления -> Хранилище данных и откройте Hue для своего виртуального хранилища:

2. Выполните запрос select ccnumber from worldwidebank.employeesи наблюдайте за результатами:

Далее мы можем использовать все те же инструменты, что и в локальной среде для аналитики наших данных. Только при этом под капотом они будут запускаться на нативных сервисах облачного провайдера, т.к. CDP в публичном облаке работает как PaaS.
9CaraTT
Это аналог Cloudflare?
Kiryl_Halozhyn
Не совсем, CDP Public Cloud — это Big Data PaaS для AWS/Azure/GCP со стеком для аналитики больших данных.