
Если вам нравится изучать языки (или вы их преподаете), то вы наверняка сталкивались с таким способом освоения языка как параллельное чтение. Он помогает погрузиться в контекст, увеличивает лексикон и позволяет получить удовольствие от обучения. Читать тексты в оригинале параллельно с русскоязычными, на мой взгляд, стоит, когда уже освоены азы грамматики и фонетики, так что учебники и преподавателей никто не отменял. Но когда дело все же доходит до чтения, то хочется подобрать что-то по своему вкусу, либо что-то уже знакомое или любимое, а это часто невозможно, потому что такого варианта параллельной книги никто не выпускал. А если вы учите не английский язык, а условный японский или венгерский, то трудно найти вообще хоть какой-то интересный материал с параллельным переводом.
Сегодня мы сделаем решительный шаг в сторону исправления этой ситуации.
Из чего делаем
На входе у нас будут два текстовых файла с оригинальным текстом и его переводом. Для примера возьмем книгу "Убить пересмешника" Харпер Ли на русском и английском языках.
Начало документов выглядит так (отрывки приведены в таком виде, в котором они были найдены в сети):
TO KILL A MOCKINGBIRD
by Harper Lee
DEDICATION
for Mr. Lee and Alice
in consideration of Love & Affection
Lawyers, I suppose, were children once.
Charles Lamb
PART ONE
1
When he was nearly thirteen, my brother Jem got his arm badly
broken at the elbow. When it healed, and Jem’s fears of never being
able to play football were assuaged, he was seldom self-conscious about
his injury. His left arm was somewhat shorter than his right; when he
stood or walked, the back of his hand was at right angles to his body,
his thumb parallel to his thigh. He couldn’t have cared less, so long as
he could pass and punt.Харпер Ли
Убить пересмешника
Юристы, наверно, тоже когда-то были детьми.
Чарлз Лэм
ЧАСТЬ ПЕРВАЯ
1
Незадолго до того, как моему брату Джиму исполнилось тринадцать, у него была сломана рука. Когда рука зажила и Джим перестал бояться, что не сможет играть в футбол, он ее почти не стеснялся. Левая рука стала немного короче правой; когда Джим стоял или ходил, ладонь была повернута к боку ребром. Но ему это было все равно - лишь бы не мешало бегать и гонять мяч.Как делаем
Задача объемная, поэтому разобьем ее на три части:
- Подготовка текстов
- Выравнивание двух текстов по предложениям
- Создание книги
Начнем с выравнивания двух текстов, так как эта часть является центральной и крайние пункты опираются на нее.
Получение параллельного корпуса
Строго говоря, нам нужно получить параллельный корпус из двух текстов. Задача не так проста как кажется по ряду причин:
- Переводчики часто переводят текст не как одно предложение к одному. Особенно ярко это заметно при переводе на иероглифические тексты (китайский, японский и т.д.), где сложные предложения как правило будут разбиты на несколько простых. В переводах на другие языки это также встречается довольно часто.
- Некоторые предложения или абзацы могут попросту отсутствовать, а иногда переводчик добавляет что-нибудь от себя.
- При очистке текстов от лишней информации, которая не участвует в выравнивании (автор, название, номера глав и подзаголовки), понадобится сохранить ее местоположение в тексте, чтобы конечная книга получилась полной и красивой.
Для выравнивания воспользуемся библиотекой lingtrain-aligner, над которой я работаю около года и которая родилась из кучи скриптов на python, часть из которых еще ждет своего часа. Проект открытый, буду рад вашим идеям и предложениям. Все ссылки вы найдете в конце статьи.
Под капотом библиотека использует модели машинного обучения, которые переводят предложения в векторное пространство. Это позволяет посчитать между векторами расстояние и проинтерпретировать его как близость предложений по смыслу. Эти модели многоязычные, одна из них поддерживает чуть более 50-ти языков, вторая — более ста. Причем сюда не входят родственные языки, для которых такой подход тоже будет иметь смысл за счет того, что они частично пересекаются по лексикону. Ссылки на статьи и списки языков, опять же, найдете ниже.
При подаче в программу текстов, произойдет следующее:
- Текст сливается в одну строку.
- Строка подчищается в зависимости от языка текста.
- Строка разбивается по предложениям при помощи библиотеки razdel или регулярок.
- Из каждой строки достается метаинформация, на основе специальных меток.
Метки нам понадобятся для того, чтобы при составлении книги из корпуса восстановить деление по частям и главам.
Давайте подготовим тексты для подачи в программу.
Подготовка текстов
Язык разметки
В качестве разметки был придуман простой язык, который совместим с последующим разбиением текста на предложения. Сейчас поддерживаются несколько типов меток, которые ставятся в конце строки. В конце каждой метки должна стоять точка.
| Метка | Значение | Установка |
|---|---|---|
| %%%%%title. | Название произведения | Вручную |
| %%%%%author. | Автор | Вручную |
| %%%%%h1. %%%%%h2. %%%%%h3. %%%%%h4. %%%%%h5. | Заголовки | Вручную |
| %%%%%divider. | Разделитель | Вручную |
| %%%%%. | Новый абзац | Автоматически |
Метки абзацев
Метки абзацев будут проставлены автоматически по следующему правилу: если строка кончается на символ [.,:,!?] и перенос строки, то считаем такую строку концом абзаца.
Правила подготовки текста
- Удалить заведомо лишние строки (информацию об издателе, посвящение, номера страниц, примечания).
- Проставить метки для автора и названия.
- Проставить метки для заголовков (H1 самый большой, H5 самый маленький). Если заголовки не нужны, то просто удалите их.
- Убедиться, что в тексте нет строк, которые кончаются точкой и при этом не являются концом абзаца (иначе целый абзац разобьется в этом месте на два).
Расставьте метки руками в соответствии с правилами, пустые строки в данном случае роли не играют. Должны получиться документы, похожие на такие:
TO KILL A MOCKINGBIRD%%%%%title.
by Harper Lee%%%%%author.
%%%%%divider.
PART ONE%%%%%h1.
1%%%%%h2.
When he was nearly thirteen, my brother Jem got his arm badly
broken at the elbow. When it healed, and Jem’s fears of never being
able to play football were assuaged, he was seldom self-conscious about
his injury. His left arm was somewhat shorter than his right; when he
stood or walked, the back of his hand was at right angles to his body,
his thumb parallel to his thigh. He couldn’t have cared less, so long as
he could pass and punt.
...Харпер Ли%%%%%author.
Убить пересмешника%%%%%title.
%%%%%divider.
ЧАСТЬ ПЕРВАЯ%%%%%h1.
1%%%%%h2.
Незадолго до того, как моему брату Джиму исполнилось тринадцать,
у него была сломана рука. Когда рука зажила и Джим перестал бояться,
что не сможет играть в футбол, он ее почти не стеснялся. Левая рука стала
немного короче правой; когда Джим стоял или ходил, ладонь была повернута к
боку ребром. Но ему это было все равно - лишь бы не мешало бегать и
гонять мяч.
...Здесь и дальше все "главные" заголовки ("ЧАСТЬ ПЕРВАЯ", "ЧАСТЬ ВТОРАЯ" и т.д.) помечены меткой h1, номера глав помечены метками h2. Перед выравниваем все метки будут удалены из текста и будут использованы при создании книги.
Выравнивание
Colab блокнот
Чтобы выровнять свои тексты используйте вот этот Colab блокнот. Это интерактивный блокнот на питоне, в который вы можете вносить изменения и запускать в браузере. В нем есть инструкции и некоторые комментарии к процессу. В конце можно будет скачать получившуюся книгу как html страничку.
Скрипты
Здесь же давайте напишем небольшой скрипт, обсудим сложности и ограничения нашего подхода.
Установим библиотеку следующей командой:
pip install lingtrain-alignerИмпортируем необходимые компоненты:
from lingtrain_aligner import preprocessor, splitter, aligner, resolver, reader, vis_helperОпределим пути до входных файлов и прочитаем все строки в переменные:
text1_input = "harper_lee_ru.txt"
text2_input = "harper_lee_en.txt"
with open(text1_input, "r", encoding="utf8") as input1:
text1 = input1.readlines()
with open(text2_input, "r", encoding="utf8") as input2:
text2 = input2.readlines()Определим также путь до SQLite базы данных (это хранилище со всей необходимой для выравнивания информацией) и параметрами языка lang_from и lang_to. Эти параметры очень важны, так как они влияют на правила разбиения строк на предложения:
db_path = "db/book.db"
lang_from = "ru"
lang_to = "en"
models = ["sentence_transformer_multilingual", "sentence_transformer_multilingual_labse"]
model_name = models[0]Получить список всех доступных языков можно следующей командой:
splitter.get_supported_languages()Если нужного языка в списке пока нет, но он поддерживаются моделями, то используйте код xx, тогда к тексту будут применены стандартные правила фильтрации и разбиения на предложения. Модель sentence_transformer_multilingual работает быстрее и поддерживает 50+ языков, sentence_transformer_multilingual_labse поддерживает 100+ языков.
Добавим к текстам метки абзацев:
text1_prepared = preprocessor.mark_paragraphs(text1)
text2_prepared = preprocessor.mark_paragraphs(text2)Разобьем документы на строки:
splitted_from = splitter.split_by_sentences_wrapper(text1_prepared , lang_from, leave_marks=True)
splitted_to = splitter.split_by_sentences_wrapper(text2_prepared , lang_to, leave_marks=True)Создадим нашу базу данных и наполним ее данными, взятыми из нашей разметки. В базе хранятся строки с координатами абзацев и глав, метаданные, маппинг выровненных строк на их изначальный состав и местоположение. Такая структура позволяет писать для этого хранилища UI, в котором можно проводить различные манипуляции с корпусом. Это отдельный проект, о нем в следующий раз.
aligner.fill_db(db_path, splitted_from, splitted_to)Теперь можно выровнять документы. Процесс выравнивания идет кусками с размером batch_size, вокруг каждого куска берется дополнительное количество строк размера window, чтобы гарантированно захватить необходимые строки. Модель берет заданное количество строк первого текста и подбирает в соответствующем фрагменте второго текста лучшие соответствия, используя векторные представления. На этом основывается первоначальное выравнивание. Для того, чтобы выровнять первые четыреста строк, выполним следующую команду.
batch_ids = [0,1,2,3]
aligner.align_db(db_path, model_name, batch_size=100, window=30, batch_ids=batch_ids, save_pic=False,
embed_batch_size=50, normalize_embeddings=True, show_progress_bar=True
)Результат выравнивания
Теперь можно посмотреть на результат первичного выравнивания! Это возможно благодаря тому, что в базе мы храним изначальные номера строк для выровненного корпуса. Воспользуемся модулем vis_helper. Так как строк у нас 400, то нарисуем все на одной картинке, задав параметр batch_size=400. Если указать, например, batch_size=50, то получим 4 картинки по-меньше.
vis_helper.visualize_alignment_by_db(db_path, output_path="alignment_vis.png", lang_name_from=lang_from, lang_name_to=lang_to, batch_size=400, size=(800,800), plt_show=True)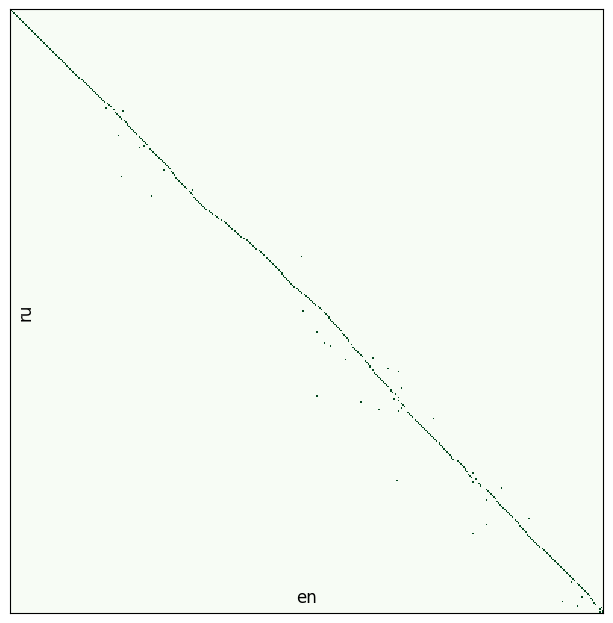
Посмотрим на картинку. Выравнивание предсказуемо идет от начала к концу, но есть конфликты. Основных причин две:
- У модели было слишком много удачных вариантов.
- Так случается, если строка короткая. Например, в тексте идет диалог, фразы в нем односложные, используются одни и те же имена.
- У модели было слишком мало вариантов и правильного среди них нет.
- У текстов разные тенденции к разделению на предложения. Один постепенно "убегает из окна" и мы не ищем правильные варианты там, где надо. Окно можно увеличить, но не слишком сильно, потому что у модели становится больше вариантов для ошибок. Нужен компромисс.
Хорошим решением мне видится регрессия на координаты строк при выравнивании батча и сдвиг окна на конец потока при выравнивании следующего. Минусом тут будет потеря возможности распараллеливания обсчета батчей, так как они станут зависимы друг от друга.
Сейчас окно сдвигается на основе отношения длин текстов. Батчи не зависимы, но есть другая проблема, — если один из текстов это только часть книги, а второй текст полный, то окно быстро убежит от правильного потока выравнивания.
Меня зовут Уинстон Вульф. Я решаю проблемы.
Давайте теперь разбираться с шероховатостями. Глядя на картинку, мы видим, что есть непрерывные цепочки, есть разрывы и есть выбросы. Например, для предложений 10,11,12 модель подобрала предложения 15,16,17 из второго текста. Эта цепочка хорошая. Все, что находится между цепочками назовем конфликтом. При таком определении конфликта можно измерить его размер и подобрать стратегию разрешения. Логика по решению проблем находится в модуле resolver.
Для начала давайте посмотрим на все найденные конфликты:
conflicts_to_solve, rest = resolver.get_all_conflicts(db_path, min_chain_length=2, max_conflicts_len=6)conflicts to solve: 46
total conflicts: 47При этом в переменную conflicts_to_solve попадут конфликты, которые соответствуют заданным параметрам поиска, а в переменную rest остальные.
Выведем на экран статистику:
resolver.get_statistics(conflicts_to_solve)
resolver.get_statistics(rest)('2:3', 11)
('3:2', 10)
('3:3', 8)
('2:1', 5)
('4:3', 3)
('3:5', 2)
('6:4', 2)
('5:4', 1)
('5:3', 1)
('2:4', 1)
('5:6', 1)
('4:5', 1)
('8:7', 1)Видим, что чаще всего попадаются конфликты размера 2:3 и 3:2, это означает, что одно из предложений было переведено как два, либо два предложения были слиты в одно.
Посмотреть на конфликт можно следующей командой:
resolver.show_conflict(db_path, conflicts_to_solve[10])124 Дом Рэдли стоял в том месте, где улица к югу от нас описывает крутую дугу.
125 Если идти в ту сторону, кажется, вот—вот упрешься в их крыльцо.
126 Но тут тротуар поворачивает и огибает их участок.
122 The Radley Place jutted into a sharp curve beyond our house.
123 Walking south, one faced its porch; the sidewalk turned and ran beside the lot.Видим, что строки 125 и 126 нужно бы сложить в одну, тогда правильное сопоставление выглядело бы как [124]-[122] и [125,126]-[123]. Как же научить этому программу? Так как она уже умеет выбирать лучший из предоставленных вариантов, то давайте ей их и предоставим. Конфликты у нас не очень большие, поэтому мы будем брать все возможные варианты разрешения конфликта, считать для них коэффициент похожести, суммировать и брать лучший. В данном случае это будет два варианта:
- [124,125]-[122] // [126]-[123]
- [124]-[122] // [125,126]-[123]
Что до стратегии выравнивания, то на данный момент лучше всего себя проявила такая, — сначала ищем конфликты при минимальной длине хорошей цепочки 2 (при таком параметре конфликтов найдется больше всего) и максимальной длиной конфликта не больше 6. Разрешаем все найденные конфликты, при этом большие конфликты становятся меньше так мы их частично разрешили. Затем увеличиваем оба параметра, ищем и снова разрешаем, добивая остатки.
Выглядит это так:
steps = 3
batch_id = -1 #выровнять все доступные батчи
for i in range(steps):
conflicts, rest = resolver.get_all_conflicts(db_path, min_chain_length=2+i, max_conflicts_len=6*(i+1), batch_id=batch_id)
resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False)
vis_helper.visualize_alignment_by_db(db_path, output_path="img_test1.png", batch_size=400, size=(800,800), plt_show=True)
if len(rest) == 0:
breakРезультат после первого шага:

И после второго:
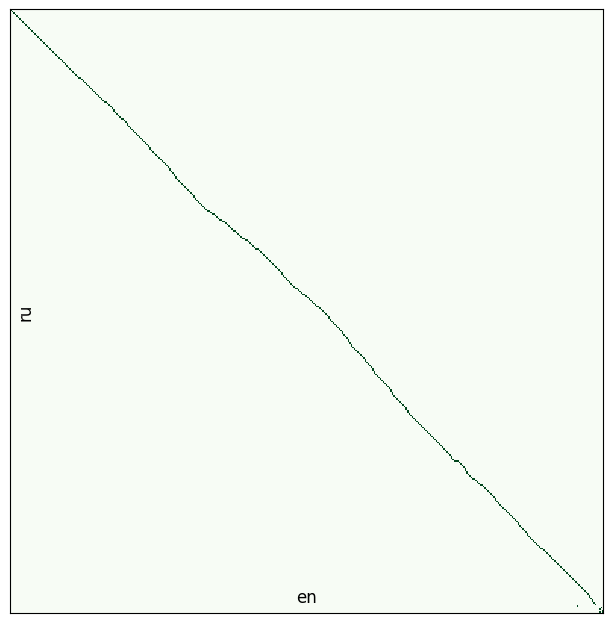
На выходе мы имеем файл book.db. Теперь мы можем перейти к созданию книги.
Конфликты на концах интервала
Отметим, что алгоритм находит конфликты только между цепочками, поэтому разрывы могут остаться на концах интервала. Для разрешения таких конфликтов есть методы:
resolver.fix_start(db_path, model_name, max_conflicts_len=20)и
resolver.fix_end(db_path, model_name, max_conflicts_len=20)Книги и стили
За создание книжки отвечает модуль reader.
from lingtrain_aligner import readerСначала прочитаем из базы тексты, разбитые по абзацам, и данные о главах:
paragraphs_from, paragraphs_to, meta = reader.get_paragraphs(db_path, direction="from")Параметр direction ["from", "to"] показывает на основе какого текста делить выравнивание на абзацы. Это дает нам возможность лучше подредактировать только один текст (например, русский) и на его основе сформировать книгу.
Теперь передадим данные в метод create_book():
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html")Получим вот такую книгу:

Это обыкновенная html страничка со встроенными стилями. В стили я добавил модификаторы, поэтому ее можно распечатать или сохранить как pdf, при этом шрифт с полями станут меньше.
Стилизация
У нас в загашнике осталась информация о соответствии пар предложений. Давайте ее задействуем, дополнительная подсветка поможет при подготовке материалов для обучения. Чтобы это сделать зададим параметр template.
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="pastel_fill")
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="pastel_start")
Шаблонов стилей пока немного, предлагайте свои кастомные стили, добавим их в библиотеку.
Кастомные стили
Зададим параметр template="custom" и передадим объект styles. Этот объект представляет из себя массив CSS стилей, которые будут применены к предложениям каждого абзаца циклически.
Например, подсветим каждое втрое предложение в абзаце желтым цветом начиная со второго:
my_style = [
'{}',
'{"background": "#fafad2"}',
]
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="custom", styles=my_style)
Задавать можно любые применимые к span'ам стили:
my_style = [
'{"background": "linear-gradient(90deg, #FDEB71 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #ABDCFF 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #FEB692 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #CE9FFC 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #81FBB8 0px, #fff 150px)", "border-radius": "15px"}'
]
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="custom", styles=my_style)
Заключение
В голове есть еще много идей по доработкам и дополнительным фишкам. Например, можно сделать мультиязычные книги, можно доставать из текста ключевые предложения и искать по ним картинки (или генерировать нейросетями), можно делать пословное выравнивание и много чего еще. Пока же хочется поделиться промежуточным результатом с сообществом и выслушать ваше мнение.
Поддержать проект можно на Patreon'e.
Ссылки
[1] Код lingtrain-aligner на github.
[2] Выровнять тексты в Google Colab.
[3] Sentence Transformers модели.
[4] Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation













mikhailian
У переводчиков в ЕС есть целый научный отдел. Так вот, ваша работа уже на голову выше той порнографии, которой они занимаются уже 50 лет.
А вы эту статью на английском не писали?
averkij Автор
Пока не писал, но сейчас сотрудничаю с НКРЯ, делаю выравниватель для команды русско-китайского параллельного корпуса.
averkij Автор
А чем конкретно занимается этот научный отдел?
mikhailian
У DG TRAD (или как они называются сейчас DGT) есть отдел New Technologies, но по факту насколько я знаю они рабы Trados. Не уверен, есть ли что-то про их работу в публичном пространстве.
В Европарламенте есть свой отдел, занимающийся translation memory, параллельными корпусами и машинным переводом. Там более осмысленно. Вот этот тендер содержит довольно подробную спеку, там по тексту понятно, сколько у них данных в параллельных корпусах.