Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
Итак представим, что у нас есть онлайн чат с высокой активностью, и заказчик хочет выгружать все сообщения, обогащенные данными о пользователе, за определенную дату в Excel. В день может копиться более 1 миллиона сообщений.
У нас есть 3 таблицы:
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
Message. Хранит данные о сообщении – Имя пользователя, ДатуВремя, Текст сообщения.
Task. Задача на формирование отчета, которую создает заказчик. Хранит ID, Статус задачи (выполнено или нет), и два параметра: Дату сообщения начало, Дату сообщения конец.
Состав колонок будет следующим:

В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.4.5</version>
</dependency>Для тестирования добавим spring-boot-starter-test
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>И еще нам нужен сам драйвер для подключения к БД
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc10</artifactId>
<version>19.10.0.0</version>
</dependency>Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
package com.report.generator.demo.config;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.scheduling.TaskScheduler;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
@Configuration
@EnableScheduling
@EnableAsync
@EnableJpaRepositories(basePackages = "com.report.generator.demo.repository")
@PropertySource({"classpath:application.properties"})
@ConditionalOnProperty(
value = "app.scheduling.enable", havingValue = "true", matchIfMissing = true
)
public class DemoConfig {
private static final int CORE_POOL_SIZE = 2;
@Bean(name = "taskScheduler")
public TaskScheduler getTaskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(CORE_POOL_SIZE);
scheduler.initialize();
return scheduler;
}
}
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
@Async("taskScheduler")
@Scheduled(fixedDelay = 60000)
public void scheduledTask() {
log.info("scheduledTask is started");
Task task = getTask();
if (Objects.isNull(task)) {
log.info("task not found");
return;
}
log.info("task found");
generate(task);
}Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List<Message> с помощью простого метода:
List<Message> findAllByMessageDateBetween(Instant dateFrom, Instant dateTo);А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
create function message_ref(
date_from timestamp,
date_to timestamp
) return sys_refcursor as
ret_cursor sys_refcursor;
begin
open ret_cursor for
select m.id,
u.name,
u.rating,
m.message_date,
m.text
from message m
left join users u on m.user_id = u.id
where m.message_date between date_from and date_to;
return ret_cursor;
end message_ref;Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: "{ ? = call message_ref(?, ?) }", callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
package com.report.generator.demo.repository.entity;
import lombok.Data;
import org.hibernate.annotations.CacheModeType;
import org.hibernate.annotations.NamedNativeQuery;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import java.io.Serializable;
import java.time.Instant;
import static com.report.generator.demo.repository.entity.MessageData.MESSAGE_REF_QUERY_NAME;
@Data
@Entity
@NamedNativeQuery(
name = MESSAGE_REF_QUERY_NAME,
query = "{ ? = call message_ref(?, ?) }",
callable = true,
cacheMode = CacheModeType.IGNORE,
resultClass = MessageData.class
)
public class MessageData implements Serializable {
public static final String MESSAGE_REF_QUERY_NAME = "MessageData.callMessageRef";
private static final long serialVersionUID = -6780765638993961105L;
@Id
private long id;
@Column
private String name;
@Column
private int rating;
@Column(name = "MESSAGE_DATE")
private Instant messageDate;
@Column
private String text;
}Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);В итоге наш метод генерации имеет следующий вид:
@Transactional
void generate(Task task) {
log.info("generating report is started");
try (
StatelessSession statelessSession = sessionFactory.openStatelessSession()
) {
ReportExcelStreamWriter writer = new ReportExcelStreamWriter();
Query<MessageData> query = statelessSession.createNamedQuery(MESSAGE_REF_QUERY_NAME, MessageData.class);
query.setParameter(1, task.getDateFrom());
query.setParameter(2, task.getDateTo());
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);
ScrollableResults results = query.scroll(ScrollMode.FORWARD_ONLY);
int index = 0;
while (results.next()) {
index++;
writer.createRow(index, (MessageData) results.get(0));
if (index % 100000 == 0) {
log.info("progress {} rows", index);
}
}
writer.writeWorkbook();
task.setStatus(DONE.toString());
log.info("task {} complete", task);
} catch (Exception e) {
task.setStatus(FAIL.toString());
e.printStackTrace();
log.error("an error occurred with message {}. While executing the task {}", e.getMessage(), task);
} finally {
taskRepository.save(task);
}
}4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.0.0</version>
</dependency>Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelWriter {
private final XSSFWorkbook wb;
private final XSSFSheet sheet;
public ReportExcelWriter() {
this.wb = new XSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
XSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
XSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(XSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:
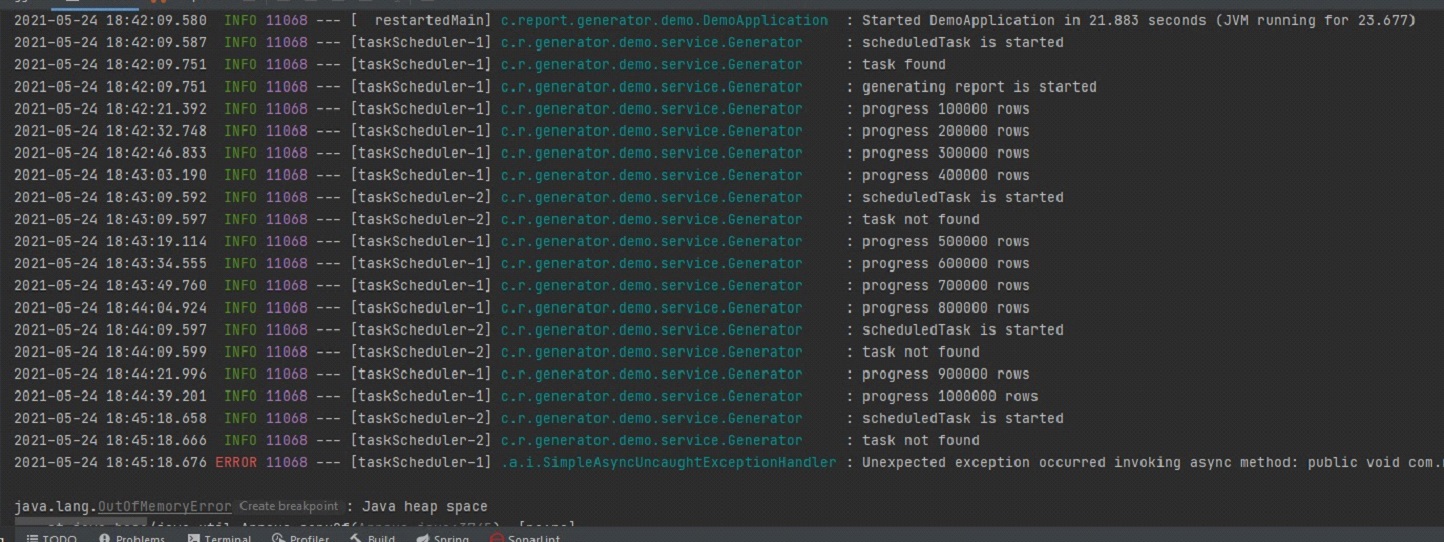
А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.streaming.SXSSFCell;
import org.apache.poi.xssf.streaming.SXSSFRow;
import org.apache.poi.xssf.streaming.SXSSFSheet;
import org.apache.poi.xssf.streaming.SXSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelStreamWriter {
private final SXSSFWorkbook wb;
private final SXSSFSheet sheet;
public ReportExcelStreamWriter() {
this.wb = new SXSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
SXSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
SXSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(SXSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
5. Итог
В результате удалось добиться максимальной производительности за счет использования хранимой функции, StatelessSession, ScrollableResults и использования библиотеки org.apache.poi из пакета streaming. При большом желании можно улучшить производительность еще, если написать все на чистом jdbc, может быть есть еще варианты, как, что и где можно улучшить. Буду рад услышать комментарии от более опытных в этом экспертов. В данном примере не учтено ограничение на 1 млн. строк, т. к. это простая формальность и для примера не очень важна. Для наполнения БД тестовыми данными был добавлен тестовый класс DemoApplicationTests. Весь код можно посмотреть в репозитории на GitHub.












zazar
А как потом открыть эксель с миллионом записей и не упасть в OutOfMemoryError?
sshikov
Я на миллионе не пробовал, но 64 битный офис вполне нормально открывает таблицы с сотнями тысяч записей. До 500 примерно было. От ширины естественно будет зависеть.
alexdenisenko
github.com/monitorjbl/excel-streaming-reader
xakep666
Отчасти ответ: формировать так, чтобы не использовались shared strings. По-умолчанию в экселе строки сохраняются в отдельный файл в архиве, а в файле листа используются указатели на них (последовательный номер). Это хорошо работает, когда файл не очень большой и уникальных строк мало, да и ещё размер экономит. Но совсем иная ситуация, когда там сотни тысяч - миллионы уникальных строк. Их все предварительно надо загрузить в память, ну и как-то уметь адресовать файл с этими строками. Грузит ли в память целиком эксель, не знаю, но многие библиотеки так делают.