
Ресурс Videocardz под видом «утечки» опубликовал характеристики готовящихся к продаже в конце этого года процессоров Intel Alder Lake. Хотя, вероятнее всего, это предварительный вброс от маркетологов компании, чтобы отследить реакцию публики на новинку, так как подобные «утечки» не просто за несколько дней — за несколько месяцев до релиза — уже давно стали привычной нормой.
Наибольший интерес в публикации Videocardz представляет информация о компоновке ядер новых флагманов Intel 12-го поколения.
Согласно опубликованной информации новые процессоры Intel будут изготавливаться по уже знакомому нам техпроцессу 10 нм и оснащаться 16 ядрами, но с подвохом: только восемь из них будут «полноценными». Маркетологи компании даже ввели специальную терминологию: P-core и E-core, что расшифровывается как Prerfomance-core и Eco-core, или просто «big core» и «small core». Вот об этом решении стоит поговорить подробнее.
Когда от инженера требуют 5,0 ГГц, получается вот это
Сами маркетологи компании загнали себя в яму, постоянно козыряя частотой 5,0-5,3 ГГц на флагманских моделях. На кого-то это до сих пор действует, хотя большинство опытных потребителей в курсе, что на подобном уровне способно работать одновременно только одно ядро, обычно — CPU-0, если мы говорим о пользовательском сегменте.
Это утверждение легко проверяется, если сходить на ресурс wikichip, который собирает информацию и спецификации процессоров. Вот, для примера характеристики топовых моделей Intel разных поколений на официальном ark.intel для i9-9900K:
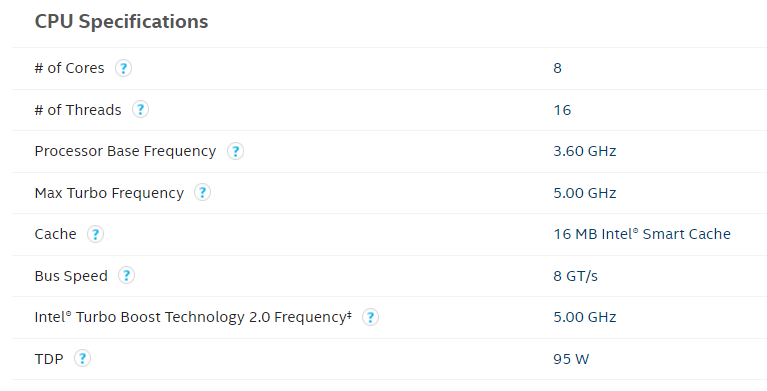
Turbo-частота — 5,0 ГГц, что активно пиарилось отделом продаж Intel. Базовая частота намного скромнее — 3,6 ГГц. И нигде не указана реальная максимальная производительность всех ядер этого процессора одновременно.
А вот таблица того же процессора с Wikichip:

Как видим, правда оказалась где-то посередине; реально i9-9900K выдает весьма солидные 4,7 ГГц на все ядра, что по факту является стабильными 4,6 ГГц на ядро без троттлинга и прочих проблем с избыточным разгоном одного из ядер.
Вот только цифра в 4,7 ГГц нигде толком не упоминается. Потому что не так солидно, как в случае с 5,0 ГГц. Хотя именно одновременная максимальная чистота на всех ядрах — важнейшая характеристика, если процессор будет использоваться в многопоточных задачах, например, в игровом ПК или при рендере. Ситуация с умолчиванием реальных рабочих частот процессоров Intel тянется как минимум со времен 8-го поколения Intel Core, то есть с процессоров линейки 8700 и его младших моделей.
Процессоры Alder Lake — для кого и почему
Так как новую литографию Intel так и не освоили, а опять размещать заказ у более успешных TSMC — это обвалить акции компании, было принято решение сыграть на «энергоэффективности».
В итоге, согласно утечке, флагманы Alder Lake 12-го поколения будут оснащены 8 полноценными, и 8 энергоэффективными ядрами. В маркетинговом буклете получается потребительский 16-ядерный процессор, но по факту — выглядит это не очень хорошо.
Вот так выглядят предварительные характеристики флагманов:

Первое, что бросается глаза — огромный разрыв между базовыми и турбо-частотами «взрослых» и «эффективных» ядер между собой. Фактически, это два процессора в одной коробке: обычный i9 и повешенный ему на шею процессор уровня i3 или i5. По задумке
Опытный пользователь знает, что наибольшая стабильность в производительности приложения достигается равной частотой на всех ядрах. И в случае с новыми Alder Lake таковая будет на уровне самого медленного комплекта ядер, то есть по планке 3,7 ГГц, если спецификации указаны верно. Вполне возможно, реальная стабильная производительность всех E-core разместится где-то на отметке в 3,4-3,5 ГГц, в зависимости от «удачности» процессора при производстве.
При этом в распоряжении пользователя будет только 24 потока вместо ожидаемых 32 потоков при работе с 16-ядерным процессором.
Похожим по характеристикам процессором является другой продукт компании — i9-9980XE, который вышел в 4 квартале 2018 года и был оснащен 18 ядрами/36 потоками:
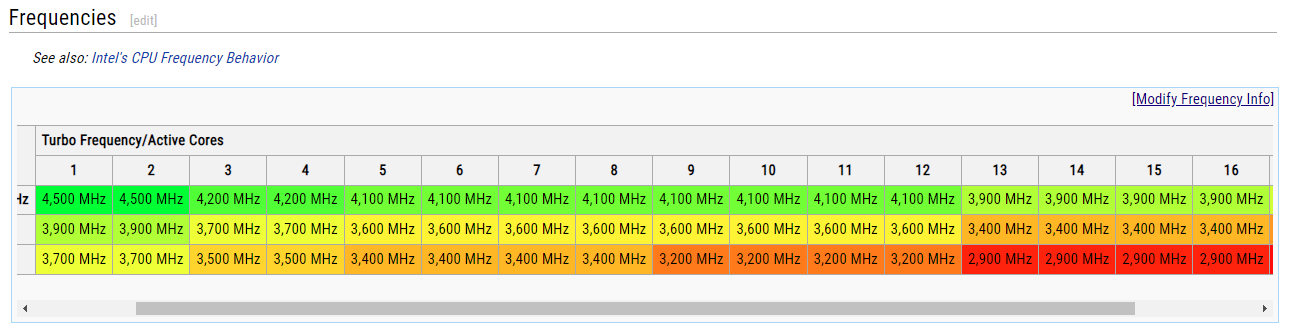
Вторая и третья строка — частота ядер в режимах AVX2 и AVX512
Как видим, уже тогда Intel выпускали процессоры по техпроцессу 14 нм с достаточным числом производительных ядер. Вот только рекомендованная розничная цена такого процессора — около 1999$ согласно странице на ark.intel, а более новая модель, Intel-10980XE, который вышел годом позже — 1000$.
Как мы видим, тенденция с 2018 года сохранилась даже с переходом от 14 нм на 10 нм: при увеличении числа основных ядер серьезно проседает как турбо-частота, так и частота всех работающих ядер одновременно. Максимум, что смогли выжать инженеры Intel из текущей технологии, они уже показали в i9-10900X, который имеет 10 ядер/20 потоков, но всего 4,5 ГГц турбо-частоты на CPU-0, при сохранении конкурентной на фоне AMD цены.
Массовый же i9-11900K оснащался скромными 8 ядрами/16 потоками, но показывал так нужные маркетологам 5,3 ГГц в соло-режиме.

Как видим, физику обмануть невозможно: новые Alder Lake будут оснащаться теми же 10 нм ядрами, что и 10-11 поколение процессоров intel, флагман будет иметь на борту все те же 8 ядер/16 потоков и не ядром больше. Потому что иначе падают частоты. Вот только для 12 поколения процессоров Intel придумали «довесок» в виде еще одного восьмиядерного процессора из бюджетного сегмента.
Единственным достижением Intel можно считать то, что «основная» часть процессора, скорее всего, сможет работать на частоте в 5,0 ГГц на все P-ядра. Правда, для этого можно купить просто i9-11900K и получить примерно ту же производительность за, вероятно, меньшие деньги и на уже существующем сокете.

Фантастический TDP
Но чехарда с ядрами и частотами и топтание на месте — не единственная проблема новых процессоров. Внимательный читатель заметил, что в списке характеристики новых флагманов Intel фигурирует и параметр TDP новых процессоров. А это, простите, минимум 125 Вт в стоке и до 228 Вт под нагрузкой, когда работают все ядра:

В целом, это согласуется с законами физики этой части вселенной: если ты просто упаковываешь два процессора в один контейнер, то и выделять тепла они будут столько же, сколько и раньше. Для справки: системы охлаждения, способные по паспорту рассеять 220 Вт тепла в российской рознице стартуют от 9 тысяч рублей или от 100$ на Amazon. Если брать систему с запасом — на 250+ Вт — то получится уже 12 тысяч рублей и более.
Зачем вообще нужны эти E-core
Такой странной компоновкой процессоров Intel пытается попасть в тренд энергосберегающих технологий, которые активно развиваются в мобильном или ноутбучном сегменте. Вот только не совсем понятно, зачем покупателю флагманского процессора компании, который, ожидаемо, хочет получить максимальную производительность, нужны эти «экологичные» технологии.
У Intel давно реализована система интеллектуального управления множителями, когда материнская плата в автоматическом режиме занижает множитель процессора и его частоту, если в данный момент на камень нет соответствующей мощности нагрузке. И даже в таком виде система была не всегда удобна: в задачах с переменной сложностью, например, в современных играх, эти скачки множителя CPU приводили к потере производительности в самом приложении, так что одним из популярных способов фикса этой «фичи» процессоров Intel стала банальная ручная блокировка множителей в BIOS на желаемом уровне. Хотя бы на уровне базовой производительности, заявленной по паспорту.
Как же в многопоточных и сложных приложениях будет происходить переключение между двумя разными процессорами, которые логически пусть и объединены в один блок, остается только догадываться. Вполне возможно, для достижения максимальной производительности пользователи новых флагманских процессоров Intel будут вообще отключать блок с «младшими» ядрами за банальной ненадобностью. Иначе вся суть покупки «флагмана» просто теряется за маркетинговой мишурой.

Комментарии (140)

tmin10
15.07.2021 17:19+6системы охлаждения, способные по паспорту рассеять 220 Вт тепла в российской рознице стартуют от 9 тысяч рублей или от 100$ на Amazon. Если брать систему с запасом — на 250+ Вт — то получится уже 12 тысяч рублей и более.
А откуда цены? Посмотрел на Be quiet Dark Rock Pro 4 c 250 TDP, цена 7-8 тысяч (https://www.e-katalog.ru/BE-QUIET-DARK-ROCK-PRO-4.htm). Но цены Be quiet считают завышенными и поиск по каталогу выдаёт варианты от 3.2к рублей (https://www.e-katalog.ru/ek-list.php?katalog_=303&presets_=22173&order_=price). Так что в статье в ~4 раза завысили цены.

dartraiden
15.07.2021 17:32+5Базовая частота намного скромнее — 3,6 ГГц.
А кого волнует базовая частота? Процессор на ней почти никогда не работает. Интерес представляет турбо-частота для конкретного числа ядер.
Например, у моего процессора базовая частота 2.6 ГГц, под нагрузкой на все ядра он работает на 4.2 ГГц, а в простое сбрасывает до 800 МГц.
Вот только не совсем понятно, зачем покупателю флагманского процессора компании, который, ожидаемо, хочет получить максимальную производительность, нужны эти «экологичные» технологии.
Странная логика, то есть такой покупатель бы предпочёл 8 сильных ядер, чем 8 сильных + 8 слабых? Intel пока не может предложить 16 сильных ядер, это случится лишь в следующем поколении после Alder Lake. Если кому-то не нужны дополнительные ядра, добро пожаловать в биос, отключите их.

creker
15.07.2021 18:37+3Покупатель предпочел бы 12 быстрых или сколько там получится разместить. На эти медленные ядра тратится драгоценная площадь кристалла. Подобный продукт это нормальное решение для ноутов, но не для настольного сегмента. Пусть еще в серверные и HEDT продукты засунут эти ядра.
dartraiden
15.07.2021 18:38Скорее всего, там не получается разместить больше 8 быстрых. Может, из-за энергопотребления (200-ватные печки не очень радуют покупателей (черт бы с ним с расходом энергии на десктопе, но тепло-то как-то нужно отводить) и совсем уныло выглядят на фоне процессоров конкурента), может, ещё по какой-то причине.

novice2001
15.07.2021 18:46Ядер там можно сколько угодно разместить, только как отводить огромное количество тепла?
При этом атомные ядра очень маленькие и принципиально на количество больших ядер не влияют вообще, учитывая, что огромную долю кристалла вообще занимает видеоядро и десятки мегабайт кэша.creker
15.07.2021 18:56+1Разве мелкие ядра не включены в общий бюджет TDP? В таком случае свободное место под быстрые ядра и останется.

nixtonixto
15.07.2021 19:40-1Сколько угодно не получится, т.к. у х86/64 при 16 ядрах почти половина тепловыделения приходится на обмен данными между ядрами, и чем больше ядер, тем меньше процент энергии идёт на собственно вычисления. Поэтому они застряли на числах 8...16, в отличие от ARM, где нет таких межядерных связей, поэтому можно создать процессор даже с сотнями тысяч ядер.
creker
15.07.2021 19:57+6В смысле нету? АРМ нынче такие же кэшкогерентные и им нужен быстрый интерконнект, чтобы снупить и инвалидировать кэши. Тот же neoverse, на котором ampere построен, имеет кэшкогерентный mesh интерконнект.
И x86 нигде не застрял. У амд 64 ядра в текущих флагманах. Следующие по последним слухам могут иметь 128 ядер. Даже интел в sapphire rapids планируют 60 или более ядер.

DistortNeo
15.07.2021 22:21Скорее, имелось в виду, что у ARM менее строгая модель памяти, и потому требования к интерконнекту ниже (но когерентность кэшей обязана быть).
creker
15.07.2021 23:20Разве это влияет на интерконнект? Когерентность — тут все понятно. А реордеринг инструкций разве не дело исключительно внутренностей ядра?
DistortNeo
16.07.2021 00:04Реордеринг внутри ядра никого не волнует до тех пор, пока доступ к данным не осуществляется сразу из нескольких потоков. Но в целом да, в алгоритмах когерентностей кэшей в процессорах различных архитектур я не силён.

sHaggY_caT
16.07.2021 00:55+2Покупатель предпочел бы 12 быстрых или сколько там получится разместить.
Многопоточная производительность отдельно, и малопоточная отдельно. Я бы предпочла лаже не big/little, а big/middle/litte, например, (условно! На самом деле помимо частоты есть IPC...) 1x6Ghz/4x5Ghz/20x2Ghz. Некоторые алгоритмы не параллелятся, см. закон Амдала. А те, что параллелятся, для них есть мелкие ядра.
С большой вероятностью, я обновлю свой комп, и куплю именно эту платформу, вместо своего 1920x/64Gb pc3200 текущего
а планировщик задач в линуксе справиться, в крайнем случае я сама напишу скрипты, которые будут биндить нужные процессы на нужные ядра.

dragonnur
27.07.2021 08:261х6 + 4х5 + 20х2? так это уже «почти есть», проц плюс видеокарта, только на 6+ ГГц даже несерийные Нетбёрсты-Техасы (Tejas) загнать не смогли, хотя хотели 9+, пришлось идти другим путём. Хотя, интересно, если вернуть одно такое ядро с HT в архитектуру, с учётом топологии в N nm, где N < 28 вместо оригинальных 90/65, получится ли что-то интересное?
MZjr
03.09.2021 03:21Кстати, да, неясно почему в Intel или MS так упирают на динамическую переброску процессов между ядрами, когда можно было бы наглядно показать, как навешивание фоновых процессов на малые ядра а) снижает потребление энергии; б) освобождает большие ядра для производительных вычислений - тех же игр, которым уже не нужно конкурировать за ресурсы с процессами операционки, антивирусом, почтой, чатиком
drWhy
03.09.2021 09:03Возможно, процессор и ОС по умолчанию жонглируют ядрами для динамического распределения тепловыделения по всей поверхности кристалла — тогда с распространением малых ядер такая практика может потерять актуальность.
creker
03.09.2021 17:13Все не так очевидно. В новых процах интела сам процессор будет рассылать подсказки, куда ОС лучше перекинуть поток. И, судя по демо, там не будет прямо четкого разделения фоновый или производительный поток. Проц будет в реальном времени определять по инструкциям, что делает поток. Если производительный поток вдруг на IO повиснет, то его нет смысла держать на быстрых ядрах. Его скинут на мелкие ядра. Точно также фоновые задачи могут иногда улетать на быстрые ядра. Приложение может указать потоку, на каких ядрах его лучше запускать, но это видимо не более чем подсказка.

Tarakanator
16.07.2021 10:22Вопрос конечно в том, сколько пришлось заплатить за энергоэффективные ядра, но я за. По крайней мере в не топовом сегменте. Это подстегнёт развитие поддержки многопоточности в программах.

beeruser
12.10.2021 02:06На эти медленные ядра тратится драгоценная площадь кристалла. Подобный продукт это нормальное решение для ноутов, но не для настольного сегмента.
Посмотрите что-ли презентации с Intel Architecture Day.
www.anandtech.com/show/16881/a-deep-dive-into-intels-alder-lake-microarchitectures
Во-первых, это не медленные ядра. Они имеют производительность Skylake, занимая при этом гораздо меньшую площадь.
Во-вторых, E-ядра нужны для максимальной производительности в многопотоке.
4 E-ядра занимают площадь 1 большого ядра, но работают в два раза быстрее.

lokkiuni
15.07.2021 20:35Рекомендую запустить handbrake в режиме перекодирования сначала h264, а потом x265, и посмотреть на частоты. Если в биосе не подкручены значения pl - то будут значения близкие к базовой частоте, при том не факт что выше.
dartraiden
15.07.2021 21:18А у кого они не подкручены... у всех более-менее производительных плат. А в дешманские i9-9900K (про базовую частоту которого говорилось в статье) никто в здравом уме не ставит.

DGN
15.07.2021 18:39+5Тяжело прокладывает себе дорогу 10нм техпроцесс от Интела. Ни тебе высоких частот, ни падения потребления... Всего лишь место на кристале, куда можно запихнуть еще ядер.
Мне бы вот была интересна конфигурация x64 + АРМ, раз уж 11 винда собирается выполнять приложения андроида. Наверное, нет ничего невозможного в работе разных потоков на разной архитектуре? Или есть?
Еще одна технология, которая назревает, это выполнения приложений без загрузки в оперативную память. Некое единое адресное пространство для оперативной и постоянной памяти. Скорости PCIe x16 gen4 уже сравнимы, память 3D Xpoint давно есть...

Ritan
15.07.2021 18:43Еще одна технология, которая назревает, это выполнения приложений без загрузки в оперативную память.
А зачем? Размер кода вроде не является такой уж проблемой. Ресурсы и данные приложения занимают гораздо больше
creker
15.07.2021 18:53Наверное, нет ничего невозможного в работе разных потоков на разной архитектуре? Или есть?
Есть, у АРМ модель памяти существенно слабее, чем x64. Андроид приложения скорее всего рекомпиляцией какой-нить запускают, это задача, относительно, не сложная.
Еще одна технология, которая назревает, это выполнения приложений без загрузки в оперативную память. Некое единое адресное пространство для оперативной и постоянной памяти. Скорости PCIe x16 gen4 уже сравнимы, память 3D Xpoint давно есть...
Скорости pcie сравнимы может быть, но там задержки существенно выше. CXL память будет, но у нее юзкейсы несколько другие будут. xpoint же очень специфическая штука. Персистентность сильно меняет условия, плюс ее назначение это быть промежуточным звеном между ssd и оперативкой. Смысл как раз в том, чтобы загружать в оперативку - разные уровни кэширования нужны для ускорения. Собственно, optane memory имеет два режима работа - memory mode, он же режим для легаси приложений, когда optane используется как оперативка, но DRAM все равно выступает в роли кэша перед. Или app direct mode, когда optane всего лишь быстрое хранилище как SSD. Для последнего приложения специально оптимизируются.

pingwinator
15.07.2021 23:04а зачем рекомпилировать апы? там же надо просто вирт машину сделать.
во первый, у интела уже была технология, которая запускала arm код на x86 - обкатали еще на атомных андроидах. во 2х - многие андроид апы с использованием ndk уже и так имеют x86 и x86_64 бинари.
creker
15.07.2021 23:24Чтобы быстро работало. Виртуальная машина и так и так нужна. Вопрос, как она будет исполнять код. Быстрые эмуляторы делают рекомпиляцию, статическую или динамическую. Вон эпл в rosetta 2 оба типа использует для эмуляции x86.
DGN
16.07.2021 02:32-1Задержки растут и у памяти, DDR3-4-5 - везде рост. Ritan - так данные тоже не загружать! Пользоваться ими прямо с диска. Процессор закеширует, так как техпроцесс уже весьма тонкий, а тепло отводить надо, то кеш L3 на каждом ядре может составить сотни мегабайт, а кеш L4 сделать чиплетным и 3D, это будет гигабайт или даже два. И тогда DRAM может стать опциональной, важен сам факт возможности исполнения с накопителя, минуя загрузку в оперативную память. Сейчас данные много лишнего бегают - накопитель-процессор-память и только тогда запускается приложение. Вот nvidia анонсировала загрузку текстур прямо с SSD, но вроде только для 3090 и скорее всего это должна еще поддерживать игра.
DistortNeo
16.07.2021 02:46И тогда DRAM может стать опциональной, важен сам факт возможности исполнения с накопителя, минуя загрузку в оперативную память.
Или же данные с накопителя будут просто отображаться непосредственно в физическое адресное пространство. Например, так сделано в Intel Optane (технология DAX).
Тогда и процессору будет плевать, читает ли он данные из оперативки или же с накопителя, и видеокарте тоже.
creker
16.07.2021 15:11+1Задержки растут и у памяти, DDR3-4-5 - везде рост.
Только это не означает, что мы внезапно ее можем чем-то заменить. Не можем и никто не планирует. Есть вроде планы сменить интерфейс работы с памятью, т.к. текущий занимает слишком много физического пространства на процессоре и материнке и больше не скейлится. Память по PCIE в рамках CXL планируется для специфичных задач в серверном сегменте.
Вот nvidia анонсировала загрузку текстур прямо с SSD
Только это не означает, что данные минуют память и кэши. Миновать оперативку это значит получить нехилую просадку в скорости. Мы имеет множество уровней кэшей, оперативок и дисков не от хорошей жизни, а потом что каждый уровень дает нам какие-то преимущества. Диски - объем. Память - задержки. Нет никакого толка работать напрямую с диском если только паттерн работы с данными не полностью линейный или невероятно параллельный (чтобы забить очереди nvme). В обоих случая задача должна быть не чувствительная к задержкам. Запуск программ под это не подходит. Именно поэтому у нас или бинарник полностью копируется в память, или мапится и копируется по мере надобности.
И тогда DRAM может стать опциональной
Не может. Объем кэша все равно значительно меньше оперативки, а объемы обрабатываемых данных у нас нынче даже в нее не влезают. Все эти уровни останутся и никуда не денутся, так же как загрузку накопитель-процессор-память. Более того, количество уровней продолжит только расти. У нас оптейн вот появился и занял место между оперативной и ssd. Сейчас начнут чиплетный кэш и HBM пихать в процессор - это будет еще один уровнем кэша.
DistortNeo
16.07.2021 15:43Только это не означает, что данные минуют память и кэши.
А если посмотреть на схемы, то означает.
Миновать оперативку это значит получить нехилую просадку в скорости.
А, собственно, почему? Данные же в обоих случаях надо сначала загрузить с накопителя.
creker
16.07.2021 17:11А если посмотреть на схемы, то означает.
А можно пример схем? Технологии вроде GPUDirect, DirectStorage предполагают загрузку данных в видеопамять. И оно логично, никакой накопитель не сможет обеспечить пропускную способность, которая нужна гпу.
А, собственно, почему? Данные же в обоих случаях надо сначала загрузить с накопителя.
Их надо постоянно читать и писать. Поэтому если процессор будет напрямую это делать с накопителя, то весь его пайплайн будет стоять и ждать, пока диск данные получит, запишет, сборку мусора еще может сделает и т.д. и т.п. Не забываем, что память это место синхронизации нескольких процессоров. Т.е. это все участвует в процессах поддержания когерентности. Оперативка сегодня это узкое место в высокопроизводительных системах, а вы диск тут предлагаете использовать. Диск это отличное место для хранения относительно холодных данных, которые можно асинхронно читать и писать.
Это правда если мы говорим об оперативке вообще. Если речь только об исполняемом коде, то вообще весь этот разговор бессмысленный. Доля кода в памяти это жалкие проценты и смысла городить что-то тут никакого.
DistortNeo
16.07.2021 17:29Технологии вроде GPUDirect, DirectStorage предполагают загрузку данных в видеопамять.
Оно и есть. Прямая загрузка в видеопамять без промежуточного буфера в оперативной памяти. Или вы имели в виду работу с текстурами без использования видеопамяти вообще?
Их надо постоянно читать и писать.
Эмм. Один раз подгрузить текстурки и всё.
creker
16.07.2021 21:21Или вы имели в виду работу с текстурами без использования видеопамяти вообще?
Разговор начался с отказа от памяти вообще и прямой работы с диском. Вот и продолжал обсуждение в этом же русле. А так да, для загрузки данных в гпу оперативная память совершенно не нужна и копирование туда сюда только мешает.Эмм. Один раз подгрузить текстурки и всё.
Опять же, тут речь была об оперативной памяти. Гпу это совсем другой юзкейс, тут вопросов нет.DistortNeo
16.07.2021 22:08Разговор начался с отказа от памяти вообще и прямой работы с диском. Вот и продолжал обсуждение в этом же русле. А так да, для загрузки данных в гпу оперативная память совершенно не нужна и копирование туда сюда только мешает.
А теперь представьте себе дальнейшее развитие ситуации, когда память GPU становится просто кэшем. Мы больше не даём явного указания видеокарте загрузить в память текстурку, а работаем с данными накопителя, отображаемыми в общее адресное пространство, а видеокарта сама подгружает данные по необходимости.
Вроде как что-то подобное используется в CUDA Unified Memory, но только с обычной оперативкой.

wataru
16.07.2021 22:18когда память GPU становится просто кэшем.
Плохая идея. Потому что когда видеокарта уже обращается к текстуре уже безнадежно поздно ее загружать.
DistortNeo
16.07.2021 22:31Потому что когда видеокарта уже обращается к текстуре уже безнадежно поздно ее загружать.
Префетч никто не отменял.
wataru
16.07.2021 22:33Ну так зачем городить эту систему с кешем, если итак всегда надо делать префетч? Эта самая DirectStorage технология — и есть этот самый аппаратный prefetch минуя процессор и память.
DistortNeo
16.07.2021 23:001. Удобство. Просто указываешь адрес — и всё, этого достаточно. И не нужно думать о необходимости освобождать память. Кэш сам будет вымываться при его исчерпании.
2. Отсутствие необходимости хранения копий текстур в оперативной памяти на всякий случай.
Минус, правда, тоже есть: станет невозможно хранение текстур на носителе в сжатом виде.
creker
17.07.2021 10:53+11. Игры так не работают. Им нужен полный контроль над содержимым памяти. Может какие-то более простые приложения смогут работать так. DirectX уже когда-то контролировал память гпу — отказались от этой модели. Теперь у разработчиков практически прямой доступ туда, о чем они давно просили.
2. Это и сейчас не нужно делать с приходом новых API, которые перекладывают все управление памятью на разработчика.
3. Минуса нет. Текстуры хранятся и загружаются в гпу в сжатом виде, как правило.
creker
16.07.2021 22:19Видеокарта не может это делать просто потому что она не знает, что ей надо загружать, а когда узнает будет уже поздно. Данные в гпу грузятся заранее перед отрисовкой кадра, чтобы скрыть задержки и успеть подготовить пайплайн — процессор всегда на шаг впереди гпу работает. Игры и прочие приложения и так нормально справляются с этими задачами. Они точно так же могут делать префетчинг, указывая гпу, что ему надо с диска подтянуть.
А общее адресное пространство, насколько я понимаю, в основном используется не для копирования данных, а для обмена информацией — атомарные переменные там, синхронизация и прочие штуки. Когерентная шина между устройствами штука не быстрая, все таки. Если надо что-то скопировать, то DMA с этим лучше справится.

ArtRoman
16.07.2021 18:41Технологии вроде GPUDirect, DirectStorage предполагают загрузку данных в видеопамять. И оно логично, никакой накопитель не сможет обеспечить пропускную способность, которая нужна гпу.
После подготовки данных, т.е. после чтения и распаковки текстур в оперативку, верно?
Сверился по википедии:
Память 1600 МГц (наименьшая частота, определённая стандартом) даёт скорость 1600 × 8 = 12 800 МБ/c.
Память 3200 МГц (наибольшая частота, изначально определённая стандартом) даёт 3200 × 8 = 25 600 МБ/c.
Накопители NVME дают около 3500 МБ/с на чтение. Разница уже меньше одного порядка, всего лишь в разы, что несравнимо с традиционными накопителями, при этом ещё есть запас скорости на шине PCI express. Если данные на диске хранить в правильном формате (частично сжатые текстуры, расположенные линейно и выровненные по блокам), если их закидывать в видеокарту с минимальной нагрузкой оперативки и ЦП, то можно избавиться от долгого этапа подготовки данных, при этом снизив нагрузку на оперативку и проц. Понятно, что есть сложности (не должно быть других задач на доступ к диску – например, винда не должна во время игр ставить обновления), не у всех есть быстрые накопители и т.д. Но и DirectStorage имеет определённые требования, доступные на определённых сочетаниях оборудования.
cepera_ang
16.07.2021 19:35Накопители ещё быстрее — 7Гбайт/сек уже в домашнем сегменте + любой желающий может купить карточку за 150 баксов, куда ставится 4 таких и вот уже 28Гбайт/сек, быстрее одноканальной памяти на 3200МГц.
JerleShannara
17.07.2021 06:39+1А толку, если эта скорость только в том случае, когда данные в DDR кеше самого накопителя (и то, если этот кеш там есть)?
creker
16.07.2021 21:18После подготовки данных, т.е. после чтения и распаковки текстур в оперативку, верно?
Нет, я так понимаю смысл в том, что в оперативку ничего не грузить, а сразу чтобы гпу тянул данные с диска через p2p запросы прямо к pcie диску. Там ведь и распаковывать толком нечего — текстуры в видеопамяти в запакованном виде хранятся. На консолях еще и аппаратные распаковщики нынче стоят, чтобы можно было на лету еще и zlib разжимать.
Вы явно не те цифры смотрели. Берем 3090 для примера — пропускная способность памяти почти 1ТБ/с. У серверной А100 1.5ТБ/с. Т.е. разница на порядки. Дальше только больше будет. Видеопамять, в отличии от оперативной, скейлится очень хорошо.
mistergrim
15.07.2021 19:39+3Мне бы вот была интересна конфигурация x64 + АРМ, раз уж 11 винда собирается выполнять приложения андроида.
А зачем выполнять приложения андроида на ARM?
quwy
16.07.2021 19:40Еще одна технология, которая назревает, это выполнения приложений без загрузки в оперативную память.
Технология отображения накопителей в адресное пространство процессора существует со времен 386 (или даже 286), называется "виртуальная память". Процессор давно может выполнять код прямо с диска, но это дьявольски медленно даже с новейшими SSD.
DrPass
16.07.2021 20:00+3Виртуальная память же не так работает :) Процессор обращается к какой-то странице виртуальной памяти, которая отображается на файл подкачки или там на образ исполняемого файла на винте, ОС выдаёт ошибку страницы. Управление попадает в соответствующий обработчик менеджера памяти, менеджер памяти подгружает эту страницу из файла подкачки или из исполняемого файла в ОЗУ, а дальше всё как обычно — процессор начинает выполнять код из ОЗУ.
quwy
17.07.2021 01:43Все правильно. А что, процессоры уже научились выполнять код не из своего адресного пространства? Как это выглядит с точки зрения тех же CS:IP?
DistortNeo
16.07.2021 22:30+1Ошибаетесь. Механизм виртуальной памяти — это всего лишь отображение виртуального адресного пространства на физическое. А уже в физическое адресное пространство может отображаться как оперативная память, так и флеш-память, память PCI-E устройств и т.д.
То, что вы имеете в виду, это memory mapped files, красивый обман (написано в соседнем комментарии).
quwy
17.07.2021 01:44То, что вы имеете в виду, это memory mapped files
Которые были бы невозможны без механизма виртуальной памяти, не так ли?
А уже в физическое адресное пространство может отображаться как оперативная память, так и флеш-память, память PCI-E устройств...
...содержимое дисков. Именно это я и имел в виду.
DistortNeo
17.07.2021 03:26> Которые были бы невозможны без механизма виртуальной памяти, не так ли?
Почему невозможны?
>… содержимое дисков. Именно это я и имел в виду.
Да, и содержимое дисков как частный случай PCI-E устройств. Вот только оно отображается в физическое адресное пространство, а не виртуальное. Ну а операционная система уже сама потом решает, что с этим делать.
creker
17.07.2021 10:47… содержимое дисков. Именно это я и имел в виду.
Только там не содержимое. Если мы говорим об nvme, то там будут очереди для команд и ответов.

TheRaven
15.07.2021 19:13-3Хотя именно одновременная максимальная чистота на всех ядрах — важнейшая характеристика, если процессор будет использоваться в многопоточных задачах, например, в игровом ПК или при рендере.
Я что-то пропустил или на рынке появились игры умеющие в многопоточность?
Игры, это же типичные однопоточные задачи, которым как раз частоту одного ядра и нужно в космос разгонять, остальная система в фоне на остальных поработает.zxcvbv
15.07.2021 20:09+10Ваши представления устарели минимум на 5 лет.

maxzhurkin
15.07.2021 21:04+6Корректнее было бы сказать "Ваши представления медленно, но верно устаревают вот уже в течение последних пяти лет". А ещё этот процесс, IMHO, будет происходить ещё довольно долго, как минимум, ещё лет 5
umnicode
15.07.2021 21:04+2Лет 8 как. Обычно логика игры идет одним потоком, в то время, как подсистемы движка отдельными
DistortNeo
15.07.2021 22:25+1К слову, медленные ядра для игр вполне востребованы. Например, потоки, которые обмениваются данными с GPU. Большую часть времени они находятся в холостом цикле (busy wait), ожидая, когда GPU завершит обработку запросов.

boblenin
16.07.2021 08:43Теоритически да, а практически - нет. Игры (которые потом идут на PC) пишутся на движках, которые заточены в первую очередь под консоли, а там таких извращений с разными видами ядер пока не предвидится. Я не знаю, что сделали в новом unreal engine, но в том, что попроще отвязать логику отрисовки от основного цикла нетривиально.

Zibx
23.08.2021 16:54Уже на PS3 были разные виды ядер. Одно шустрое и 6 дополнительных.
creker
23.08.2021 23:24Не совсем. Там было как раз одно медленное и 6 быстрых, но неспособных нормально выполнять код общего назначения. А так да, правильно шедулить код на эти 6 ядер было критически важно для производительности. А одно ядро это занималось как раз шедулингом и прочими вспомогательными задачами.
creker
15.07.2021 23:26Нынче в моде еще корутины, где многопоточно абсолютно все, по возможности. Консоли заставили разработчиков пересмотреть архитектуру движков. На 8 медленных ядрах не разгуляешься.

dpytaylo
15.07.2021 21:04+1Со времён появления новых API, таких как DirectX 12 и Vulkan, игры стали рендериться в многопотоке
JerleShannara
15.07.2021 21:07+4Посмотрите на досуге всяких ютуберов-обзорщиков. Всякие Смотри Собак 2, Ведьмак 3, ПолеБоя 5 и прочее вполне себе 8 ядер умудряются утилизировать.
TheRaven
15.07.2021 22:01+1www.youtube.com/watch?v=EXtMjxC0M4U
RDR 2: 2 и 4 ядра разница есть, дальнейшее увеличение выигрыша не даёт
NFS Heat: 2 и 4 ядра разница есть, дальше можно найти под микроскопом
Assassin's Creed Odyssey: 2 и 4 ядра разница есть, дальше есть ощущаемый прирост
BF V: 2 и 4 ядра разница есть, дальнейшее увеличение выигрыша не даёт
Shadow of the Tomb Raider: 2 и 4 ядра разница есть, дальше есть хороший прирост
Far Cry New Dawn: 2 и 4 ядра разница есть, дальше есть ощущаемый прирост
The Witcher 3: 2 и 4 ядра разница есть, дальше есть ощущаемый прирост
Hitman 2: 2 и 4 ядра разница есть, дальше можно найти под микроскопом
Т.е. да, игры действительно пытаются в многопоток, но все ядра с максимальной частотой для них не критичны. Плюс, мне кажется, явная разница между 2 и 4 ядра может быть и в том, что вся остальная система не конкурирует за таймслоты с игрушкой.
А в целом да, действительно мои представления несколько устарели, хотя того же ведьмака я погонял.
Am0ralist
15.07.2021 23:33+1У нас есть свои бородачи, которые не плохо тестируют процы) Или вот такое
Но в принципе есть и те, что даже от 5900х умудряются получить плюсы
creker
15.07.2021 23:46Как-то странно вы смотрели. Во всех перечисленных играх оптимальная конфигурация 6 ядер. Особенно это видно по минимальному FPS. Прирост после 4 ядер существенный именно в этом.
Уже много раз было заключено, что сейчас играм нужно минимум 6 аппаратных потоков. И страдает обычно именно минимальный фпс.Am0ralist
16.07.2021 00:50Уже много раз было заключено, что сейчас играм нужно минимум 6 аппаратных потоков.
Всё ж в тестах на тестовых компах (то есть с достаточной чистой ОС), думаю в реальности, если у вас комп не чисто под игры и на нём установлено и работать в фоне может ещё куча всего — лучше исходить от 8 ядер или 6/12. Ну и 3500X всё таки похуже 3600X выступал и вряд ли только из-за разницы в 0,3 ГГц.
boblenin
16.07.2021 08:39-2Появились с прошлым поколением игровых консолей, куда стали ставить многоядерные процессоры. Но в любом случае игры все еще очень и очень любят когда есть высокая производительность в одном потоке.

WASD1
16.07.2021 14:32Bu
Игры (вернее игровые движки, конечно на сегодня) научили использовать многие ядра через конвейризацию (Там ещё CacheFrendly данные чезер "Structure of Arrays вместо Array of Structures" завезли).
Когда каждая стадия конвейра - отдельный thread, выполняющий одну конкретную задачу над всеми объектами (унификация через SoA помогает).
Ну а ОС уже планирует все твои потоки на процессорные ядра.

gotozero
15.07.2021 19:19Появилась новость, что интел стал первым вместе с эпл на 3нм у TSMC.
До этого момента покупать интел смысла не имеет. Только на десктопах разве чтоboblenin
16.07.2021 08:38+1Не факт. 3 нм TSMC, 10нм Intel, 12нм Global Foundries - это сравнение теплого с мягким, а потом с зеленым.
Надо смотреть на итоговую производительность. Ну или производительность на ватт.Am0ralist
16.07.2021 09:53это сравнение теплого с мягким, а потом с зеленым.
зато примерная плотность транзисторов процессоров на данных нм показывают, что 7+ тсмц и 10 интела — это сравнимые вещи. Вот только на 7+ амд уже делает и монолитные чипы для приставок (8/16 CPU и встроенный GPU уровня 3060 вроде), а интел уже сколько лет не может превзойти 4/8 с видиком уровня 1030. Поэтому был вынужден на 14+(+) 28 ядерные серверные процы с браком в 75% делать. Пока амд просто копеечными чиплетами даже в декстопы 16 ядер отгрузила.
Так что добавить в сравнение «на бакс» ещё нужно.
gotozero
16.07.2021 12:22-4Факт. М1 уже все доказал.
boblenin
16.07.2021 16:08+2M1 доказал, что если использовать другой стандарт инструкций с более эффективным декодером (и с большим их числом), разместить память очень близко к кристалу и обеспечить ее широкой шиной, плюс еще сделать все на более новом тех процессе, запустить на этом всем систему, которая собирается с оптимизацией под один чип, можно получить отличную производительность. Ну так никто и не отрицал. А вот что из факторов повлияло больше на итоговую производительность - я не знаю.
ArtRoman
16.07.2021 17:19запустить на этом всем систему, которая собирается с оптимизацией под один чип
Система универсальна, каждый бинарник может содержать несколько блоков кода с разными оптимизациями. Все системные приложения содержат x86_64 и arm64. В предыдущую смену архитектуры Universal Binary тоже активно использовались: ppc + i386, а позже ppc + i386 + x86_64. На айфонах/айпадах раньше были универсальные бинарники под разные поколения процессоров armv7/armv8, теперь только 64-битные armv8.
gotozero
16.07.2021 18:14Все, что вы перечислили так же является спекуляцией. Длина команд, декодеры, кэши и прочее.
Если опираться на предоставленные данные, то у нас имеется последний райзен на 7нм, который на ноутбуках на 30% дольше живет чем интел в полностью идентичных ноутбуках за исключением процессоров.
И есть 5нм М1, который живет еще дольше чем все, что имеется на рынке.
И здесь вопрос не просто производительности, а производительность на ватт.
Конечно утверждать однозначно нельзя, но тенденция на лицо.
А еще то, что интел пошла на поклон к TSMC за их 3нм как бы намекают, что сами они не осилили. Вот когда мы получим интел, эпл и амд на TSMC, на одинаковом техпроцессе, вот тогда мы и получим более наглядную картину и то не до конца разумеется.boblenin
16.07.2021 21:56Если мы спорим, то я не понимаю о чем. Если о том, что M1 отличная платформа, так я обеими руками за. Если о том, что 10нм TSMC != 10нм intel, то я думаю и вы этого утверждать не будете. Если о том, что более современный тех процесс позволяет инженерам повышать потребительские качества процессора, так ведь и тут сложно не согласиться. Или может быть мы просто соглашаемся по циклу?
Если же речь о том, что 5нм M1 лучше чем 10нм Intel, то я считаю, что пока что говорить рано. Вот пусть выйдут новые камни, там и посмотрим. На 14нм intel вполне долго смогли держать производительность конкурентоспособной с AMD на 7нм. Они вполне возможно смогут больше выжать из своего же 10нм.
Хотя учитывая то, что у них там бутерброды - будет очень интересно посмотреть как всё это будет охлаждаться и не будут ли разные слои расходиться со временем.
creker
16.07.2021 22:09На 14нм intel вполне долго смогли держать производительность конкурентоспособной с AMD на 7нм
Не могли. Интел сливал даже первому зену. Интел мог только за счет частоты в однопотоке что-то. И то сейчас это тоже испарилось. Их микроархитектура устарела, из техпроцесс устарел. Они не смогут обойти конкурента, решив только одну из этих проблем.
А речь банально о том, что М1 сравнивают с процессорами, которые ему не эквивалентны чисто технически. Интел так вообще абсолютно отсталый продукт — их процессоры хоть как-то сопротивляются в настольном сегменте, потому что интел задирает их энергопотребление до невероятных значений и всем на этом пофиг. В ноутах это не катит. Поэтому говорить, что М1 что-то там показал, не получается. Он показал только одно — безбожное отставание интела, но об этом все и так знали.boblenin
16.07.2021 23:33И я о том же. M1 - это вообще-то давно уже назревший отказ от наследия x86. С одной стороны жаль, с другой - закономерно то, что этот отказ происходит только в одной и весьма закрытой экосистеме.
Камни от intel 11-12го поколения очень горячие. Настолько, что уже во время покупки надо задумываться о том, чтобы материнка, на которой он будет работать имела достаточно фаз питания и о том, чтобы корпус достаточно хорошо продувался, плюс чтобы система охлаждения справлялась, что в общем для тех, кто интересуется, не секрет.wataru
16.07.2021 23:57Рано пока x86 хоронить. Вот выпустят на 3нм хоть один проц на x86, тогда и можно будет сравнить.
Am0ralist
18.07.2021 17:04Камни от intel 11-12го поколения очень горячие.
правильно, ведь интел заложник своих зато у нас есть «5 ггц» и монолитных кристаллов, а соперничать ему приходится с амд, которые чхали на монолитные кристаллы и если им надо, то просто отсыпают еще немного чиплетов, пусть и теряя на этом возможно процентов 5 производительности. После чего отсыпают ещё кучу кэшпамяти, чтоб нивелировать проблемы из-за отдельного кристалла ввода-вывода. А ведь у них ещё и 3D кэш анонсирован, благодаря которому на эпиках у них вообще до гигабайта кэша может оказаться. Это не говоря о возможности так же HBM2 рядом с процом располагать. Вот это всё Интелу пока крыть нечем, да и не на чем. те же 28 ядерные на 14+(+) нм они делали с процентом брака эдак в 75, если ссылки, которыми меня на хабре закидывали, не лгут. АМД с чиплетами на это смотрели и посмеивались просто.
При этом в мобильном сегменте АМД таки прекрасно делает монолитные кристаллы, с 8 ядрами, гпу и вводом-выводом на одном кристалле, и там вот выход 8 ядерников у интела позволит сравниться с процами АМД, ибо 10 нм интела таки приблизительно почти равны 7+нм ТСМЦ, но вроде получше 7 нм этого же ТСМЦ. Вот только выпустить их они не могли уже сколько лет? А АМД уже планирует переход на 5 нм ТСМЦ и при переходе на ддр5 ещё и встройку подтянут.
Так что x86 хоронить бессмысленно. Винда вон, уже лет тридцать «мастдай» с точки зрения некоторых пользователей.creker
18.07.2021 22:09sapphire rapids поэтому все и ждут. Там и тайлы будут, и 50+ ядер, и HBM насыпят. Не говоря уже о DDR5, PCIE5, CXL. Правда по слухам АМД чипы все равно быстрее.
Am0ralist
19.07.2021 10:27Да от интела сейчас ждут просто, что она может создавать хотя бы >8/16 на одном чипе, блин, в нормальном количестве на 10 нм и с нормальными ценами.
АМД-то в 22 году (когда sapphire rapids обещан) уже вроде как 96 ядер планируют и за счёт 3d — кэша под гигабайт, с которым HBM2 всё таки не конкурент.
creker
19.07.2021 12:03кэша под гигабайт, с которым HBM2 всё таки не конкурент.
Сложный вопрос. 3d кэш это L3. HBM же будет скорее как L4, если интел чего хитрее не придумает. И он будет явно большего размера, чем L3. Пропускная способность тоже не хромает. Что из этого даст больший профит сказать невозможно без тестов. HBM, по слухам, и амд интересен.
Am0ralist
19.07.2021 12:21Да, только L3 у интела — вроде на порядок меньше АМДшного и как-то на его серьезный рост намёков не было, хотя при переходе на чиплеты его количество улучшает производительность (точнее, немного нивелирует накладные расходы из-за чиплетности).
HBM, по слухам, и амд интересен.
да, уже было, что рассматривают и его для новых поколений эпиков (для ответа интелу, скорей всего), но это ж дороже, чем 3D, вроде как, а интел вряд ли успеет свой ответ на 3D-кэш выкатить.
creker
18.07.2021 22:06M1 это закономерный шаг для эпл. Мерить по ней всю остальную индустрию ошибочно. Эпл и без фейлов интела сделала бы этот шаг, потому что для них главное не только производительность, но и возможность контролировать как можно больше компонентов своих девайсов. Особенно настолько важный, который нельзя просто так поменять как, по сути, все остальные микросхемы. Включая даже гпу. По слухам, интел помимо технологического отставания делала еще и довольно глючные платформы, чем постоянно тормозила эпл.
Если мы посмотрим на серверный рынок, где у АРМ есть хоть какие-то шансы, там никакого особого профита от него нет. Ampere, например, идет примерно на равных с АМД.

SamaRazor
15.07.2021 19:44+2Главный вопрос — зачем человеку (ну мне, например, мой текущий — 10850К), с массивной системой охлаждения, в десктопе, с видеоадаптером еще жрущим очень много — энергоэффективные ядра? В ноутбуки — ясно зачем, у меня розетка тут вроде как.

Alexmaru
16.07.2021 00:03+1По той же причине машины выключают двигатель вообще, или отключают хотя-бы один цилиндр. Экономия, экология. Почему нет? В простое меньше электричества потратит.
boblenin
16.07.2021 08:35Если система - водянка, то при резком всплеске нагрузки вода будет некоторое время прогреваться и в итоге система охлаждения на коротком промежутке сможет себя вести лучше чем могла бы если бы была уже прогретой. Для 10-го поколения intel это не сильно на что-то влияет, а вот 5-е поколение ryzen бустит до тех пор, пока не упирается в возможности системы охлаждения.
Грубо говоря благодаря тому, что система охлаждения была холодной - процессор может сам держать высокую частоту дольше, во время всплеска нагрузки, и в итоге быстрее разрешать пики (практически разгоняя себя).


fedorro
15.07.2021 19:45-2Если ничего сложного — работают E-core, если приложение «тяжелое» — в бой идут P-core.
— ну это ещё нужно планировщики так написать. Винда, например, не умеет, до сих пор, один поток на одно ядро сажать чтобы получить полную Турбо-частоту.
Чтобы хотябы близко к ней подобраться мне пришлось включить «парковку ядер», снизить минимальную частоту с 40 % до 0, закрепить поток на одном ядре, ну и выкрутить Speed Shift на полную — только тогда пару раз мелькнули 4500 Mhz из 4600 турбо (i7-8700).
mvv-rus
15.07.2021 23:15+3Винда, например, не умеет, до сих пор, один поток на одно ядро сажать
Откуда сведения такие интересные?
У меня вот сведения совсем другие, причем — из надежных источников: из книги Windows Internals за авторством Марка Руссиновича со товарищи (товарищи в разных изданиях были разные). То есть — непосредственно от MS (Руссинович, по крайне мере, в те времена, работал именно там):When a thread becomes ready to run, Windows first tries to schedule the thread to run on an idle processor. If there is a choice of idle processors, preference is given first to the thread's ideal processor, then to the thread's previous processor, and then to the currently executing processor (that is, the CPU on which the scheduling code is running).
Это — из 4 издания, которое для Win2K/XP/2K3, но в 6-м издании (у меня есть бумажный вариант) аналогичный текст тоже есть.
Небольшое пояснение: processor, с точки зрения планировщика Windows, — это не микросхема («камень»), а аппаратный поток выполнения, в частности, им для современных процессоров является не только ядро, но и, при включенном hyperthreading, — виртуальный процессор в рамках этго самого hyperthreading.
Ideal processor выбирается при создании потока, губо говоря — для каждого потока им назначается следующий процессор. И Windows, как написано выше, старается запустить поток на этом процессоре. Это делается с простой целью, мало связанной данной статьей и ее обсуждением: не сбрасывать лишний раз TLB и кэши, чтобы не лазить потом за их содержимым повторно в оперативную память (ибо это ме-едленно).
Другое дело, что если процесс время от времени уходит в ожидание чего-то (сети, ввода/вывода), то Windows не дает его идеальному процессору простаивать, а назначает туда какой-нибудь ещё поток, так что по окончании ожидания идеальный процессор может оказаться занятым, и поток будет назначен на другой процессор.
Но если вы — разработчик программы, то вы можете (SetThreadAffinityMask) установить Affinity Mask вашего любимого потока так, чтобы он мог использовать только один процессор (например, в нашем случае — самое быстрое ядро). Или же — установить этот процессор в качестве ideal processor для вашего потока.
А еще в те времена в Windows Server был WSRM, в котором многое в этом плане мог сделать администратор, но сейчас AFAIK его выпилили (чем заменили — не разбирался).
PS Но таки да: частотой ядер Windows вроде как, напрямую, в HAL, не управляетfedorro
16.07.2021 00:25-3Из наблюдений и вопросов со StackOverflow из серии «Покажите мне мой Turbo Boost». Запускал я бенчмарки и числодробилки — врятли они часто в ожидание уходят. Возможно при одном потоке одно ядро постоянно загружено чуть больше, но остальным все равно достается суммарно 50 % нагрузки, а должно быть 0 — и вообще увести их в состояние чуть не сна. Возможно это делается из соображения распределения тепла… Но в тоже время Windows повышает частоту при малейшей нагрузке — страничку обновил в браузере — получай 3 Гц, вместо 0.8. Например для Turbo Boost 3.0 интел поставляет отдельное приложение которое умеет отправлять однопоточную нагрузку на одно ядро — зачем бы им было это делать, если планировщик Windows сам так может?
mvv-rus
16.07.2021 00:51Например для Turbo Boost 3.0 интел поставляет отдельное приложение которое умеет отправлять однопоточную нагрузку на одно ядро — зачем бы им было это делать, если планировщик Windows сам так может
А как оно работает? Неужели в обход планировщика? Подозреваю, что там с помощью SetProcessAffinity у запускаемого процесса просто устанавливается маска с привязкой ровно к одному процессору.
Да, планировщику Windows про такие случаи надо говорить специально — иначе он пытается снизить общее время выполнения, распределяя потоки на все доступные ему процессоры (если что, запаркованные — они недоступные). Но если его попросить специально — то он может, «то он сыграет и не так».
Кстати, лично меня такой режим вполне устраивает: у меня обычно открыто несколько окон браузера, в каждом из которых что-то свое делает JS (ну не могут нынешние фронтэндщики просто оставит страницу в покое — типа, «летит себе помело, и пусть летит, а вы не вмешивайтесь!»©O'Тул), плюс набор вируталок, на которых, к примеру крутится тестовая организация Exchange (а Exchange — он постоянно что-то свое делает, плюс DC дергает)… Короче, всем время от времени нужен прцессор.
creker
16.07.2021 15:18+1Но в тоже время Windows повышает частоту при малейшей нагрузке
Только вот это делает совсем не виндоус, а процессор сам. Винда банально не может с такой скоростью реагировать на изменения внутри процессора.

Viknet
16.07.2021 16:03Вообще нет, этим как раз занимается ОС.
А типичное время frequency ramping — десятки миллисекунд, в самых современных процессорах дошли до единиц.
Был неправ.
ОС только задаёт рамки, в которых CPU может сам динамически менять частоту.
И задержки скейлинга там в микросекундах (пример исследования).cepera_ang
16.07.2021 16:18И микросекунды — это всё равно вечность для процессора, десятки тысяч инструкций потенциально.
DistortNeo
16.07.2021 16:30И да, и нет. Операционная система не управляет частотой процессора напрямую. Но она задаёт для ядер процессора значения P-state. А что дальше с этим фактом делать, процессор решает уже сам.

stalinets
15.07.2021 20:38+1Где-то уже была статья про это. И я тогда писал, что где гарантия, что у хардкорного геймера вдруг FPS в самый ответственный момент не просел с 200 до 10, потому что винда вдруг решила перекинуть процесс игры с нормального ядра на "атомное"? Где гарантия, что не будет странных просадок производительности на ровном месте? Или глюков у программ, которые думают, что все ядра одинаковые, и одинаково параллелят вычисление, а получив сильно разный результат от разных ядер, начнут тупить или вообще вылетят? Мне кажется, будет много проблем и глюков. Хотя сама идея красивая.
Эти энергоэффективные ядра, наверное, стоит запрятать под какое-то новое API, чтобы любой современный и старый софт их не видел и не трогал. И лишь специально написанная программа, умеющая их понимать, могла их занимать когда надо.

Revertis
15.07.2021 22:12В принципе, можно потокам устанавливать разный приоритет. И было бы удобно, если бы планировщик в зависимости от этого перемещал потоки с низким приоритетом на слабые ядра.

wigneddoom
16.07.2021 00:43Может так и будет. Но на планировщик уже и так очень много всего возложили. А каких-то прорывных исследований и новых реализаций я пока не наблюдаю. Планировщик нынче универсальный, поэтому обеспечивает общую температуру по больнице. И все эти энергоэффективные ядра только усложняют ему жизнь. Хотя на ARM много лет как подобное практикуют.
А когда речь заходит, о реальной производительности (это я больше о серверах), то зачастую вырубают HT, прибивают гвоздями потоки и обработчики прерываний к ядрам, NUMA доменам, АМД чиплетам и т.д. Иначе всё печально.
Revertis
16.07.2021 01:06Да, согласен с вами. Ну поживём - увидим. Хорошо, хоть АМД этим вроде пока не страдает, и все ядрышки пока одинаковые.

zxweed
16.07.2021 12:15-2нет, у AMD тоже половина ядер быстрые, а половина — энергоэффективные (кристаллы сортируются), только разница между ними не такая драматическая.
Revertis
16.07.2021 12:24+1У Ryzen 7 3700X все ядра одинаковые. И частоты они держат одинаковые при полной нагрузке. В каких CPU вы видели разные ядра?
zxweed
16.07.2021 13:10-2во всех тех, где больше одного чиплета, т.е. начиная с 3900х
Am0ralist
16.07.2021 15:21+1Там где два чиплета — второй зачастую похуже. Только это не энергоэффективные ядра, а наоборот = энергоНЕэффективные, они слишком много потребляют и поэтому не могут разогнаться автоматом до тех же частот без перегрева (3600 можно разогнать до 3600X, но потребление обычно у первого выше в итоге).
wataru
16.07.2021 13:36+2нет же. Все кристалы произведены по одному шаблону. То, что у них качество разное и есть так называетмая "кремнивая лотерея" — это да. Поэтому какие-то чиплеты могут не держать такую же высокую частоту (и потребление), как остальные. Поэтому будет какая-то минимальная разница. Но это не какие-то энергожффективные ядра. Совсем нет.

arheops
17.07.2021 18:10В планировщике это все уже есть, ибо современные 4+ядерники независимо частоты ядер от перегрева меняют.
cepera_ang
15.07.2021 20:42+10Так как новую литографию Intel так и не освоили, а опять размещать заказ у более успешных TSMC
Так как автор понятия не имеет о чём говорит, а читать собственные ссылки может обвалить репутацию в собственных глазах, было принято решение налить воды на 5ГГц и тепловыделение. Может прикола ради назовёте модель процессора Интел изготовленного в прошлый заказ на TSMC?
Мда, от датацентра как-то ожидаешь серьезнее материалов, это вообще инженеры писали или так нелюбимые автором маркетологи? Всю дорогу как попугай "маркетологи то, маркетологи сё, маркетологи пятое-десятое", а по факту — просто высосанная из пальца вода. Это надо же было так растянуть исходную заметку на три абзаца до трёх страниц, хотя и изначальная заметка также высосана из одной картинки на пять строчек.
Новый техпроцесс (впервые 10нм на десктопе от интела) — пофиг, улучшения микроархитектуры — сложна, подумать/почитать зачем нужны энергоэффективные ядра — вот ещё, новые инструкции, DDR5, PCIe 5.0, целая новая архитектура GPU — зачем всё это упоминать, вот обмусолить 5 гигагерц, как "маркетологи загнали себя в ловушку" или нет — это пожалуйста. Воистину, каждый видит мир в рамках своей компетенции.

transcengopher
16.07.2021 00:24+2У Intel давно реализована система интеллектуального управления множителями, когда материнская плата в автоматическом режиме занижает множитель процессора и его частоту, если в данный момент на камень нет соответствующей мощности нагрузке. И даже в таком виде система была не всегда удобна: в задачах с переменной сложностью, например, в современных играх, эти скачки множителя CPU приводили к потере производительности в самом приложении, так что одним из популярных способов фикса этой «фичи» процессоров Intel стала банальная ручная блокировка множителей в BIOS на желаемом уровне.
Новая идея для стартапов:
Вернуть на законное место кнопку Turbo, которая при нажатии блокирует/разблокирует множители.boblenin
16.07.2021 08:23Для этого теперь есть Ryzen Master или Intel Extreme Tuning Utility. Одним нажатием на кнопку можно выставлять разные профили для процессоров.
transcengopher
16.07.2021 15:27Они все работают только под windows. Кнопка Turbo должна быть независимой от ОС.
alliumnsk
19.07.2021 20:46Подозреваю, что кнопка Turbo, ежели она "вернется", будет иметь вышеуказанный недостаток :)

iproger
16.07.2021 03:48Кто-то может сказать что выгоднее по транзисторному бюджету и меньшему tdp: скажем, 2 быстрых ядра с ht на средних частотах 3ггц или 8 маленьких ядер без гиперпоточности на 2ггц? Частота, количество ядер условные, но при условии что в итоге производительность вариантов равная при полной нагрузке. Очень интересно было бы узнать, это сразу даст понимание есть ли вообще смысл в малых ядер и стоит ли ждать перекос в их сторону в будущем.
Am0ralist
16.07.2021 10:44Вопрос больше, есть ли реальный смысл именно 8 маленьких ядер, имеющих не только меньшие частоты, но и меньший набор поддерживаемых инструкций, с учетом, что распараллеливание и так хромает, а тут ещё получается нужно, чтоб поток при обращении к отсутствующей инструкции на жирное перекидывался или заранее как-то запрещать исполнение на мелких. То есть пока ощущение, что ровно 8 добавили ради «16 ядерный» (напомнить, как люди из-за 8 неполных ядер АМД устраивали споры и даже судились?), а не ради решения действительно каких-то задач. Эпл вот начали с 4-х и я не помню в сливах желания их до 8 увеличивать.
DrPass
16.07.2021 11:31Частота, количество ядер условные, но при условии что в итоге производительность вариантов равная при полной нагрузке.
Я не ошибусь, если скажу, что производительность ядер при схожей архитектуре и техпроцессе очень сильно коррелирует с транзисторным бюджетом и TDP. Поэтому если мы полагаем, что производительность равная, то и tdp у них примерно такой же будет. Разницу мы увидим в частных случаях, например, у первой конфигурации быстродействие всегда будет выше в тех задачах, которые требуют высокой производительности на поток. Зато вторая будет лучше справляться с параллельной обработкой группы задач и может более гибко настраивать энергопотребление под текущую загрузку.
cepera_ang
16.07.2021 12:31Всё зависит от задачи — нет универсального ответа на этот вопрос, существуют нагрузки, которые и первый и второй вариант покажут более быстрым и более эффективным. Именно это и подталкивает Интел и других делать гибридные процессоры и в целом заставляет архитектуру компьютеров становиться всё более гетерогенной — включать и быстрых ядер и медленных, и массивно-параллельных видеоядер, и числодробительных нейропроцессоров и (в больших машинах) fpga какие-нибудь.
Смысл малых ядер в том, чтобы выбрать другую точку на нелинейном графике "производительность/потребление" — если задаче достаточно 80% от пика, при этом потребление может быть 2-3х меньше за счёт того, что энергия растёт реально быстро с частотой и вольтами и кучей кеша. А для "рыхлого" кода, который бегает по памяти и большую часть времени ждёт оттуда данных, так и вообще разницы может и не быть. Поэтому имеет смысл запускать большую часть потоков на экономичных ядрах и апгрейдить только в том случае, если поток показывает, что способен загрузить более мощное (т.е. если по счётчикам производительности видно, что поток использовал все ресурсы ядра и не ждал памяти/ввода-вывода/локов соседних потоков и т.д.). В конечном итоге (как бы не кричали глупцы в комментариях) — энергия является ключевым ограничителем (даже на десктопе и серверах) и если мы можем уменьшить энергопотребление пусть даже для части нагрузки, это освобождает энергетический бюджет для того, чтобы выполнить критическую нагрузку на быстрых ядрах чуть быстрее.
Вот эта шикарная лекция даёт отличный обзор этого принципа, почему он неизбежен и большой картины в целом:
boblenin
16.07.2021 08:18+2Это утверждение легко проверяется, если сходить на ресурс wikichip, который собирает информацию и спецификации процессоров. Вот, для примера характеристики топовых моделей Intel разных поколений на официальном ark.intel для i9-9900K: Turbo-частота — 5,0 ГГц, что активно пиарилось отделом продаж Intel. Базовая частота намного скромнее — 3,6 ГГц. И нигде не указана реальная максимальная производительность всех ядер этого процессора одновременно.
Странно. Почему для примера берется 9-е поколение, если сравнение всего остального идет с 10-м и 11-м? К тому же у меня до недавнего времени трудился на моей боевой станции 8700k, который под разгоном держал 5Gz на все ядра. Насколько я помню из коробки это даже 8086k делал.
В итоге, согласно утечке, флагманы Alder Lake 12-го поколения будут оснащены 8 полноценными, и 8 энергоэффективными ядрами. В маркетинговом буклете получается потребительский 16-ядерный процессор, но по факту — выглядит это не очень хорошо.
Не понятно почему? Так производители SOC для телефонов делают уже давно. В принципе на десктопе при росте числа ядер производительность растет далеко не линейно и в целом гонка 4 ядра против 6 против 8 по большому счету маркетинг сродни мегапикселям в камерах. По-моему очень даже верный шаг делает intel. Если у меня система обрабатывает что-то легкое, то пусть она работает на медленных ядрах и система охлаждения переходит или в бесшумный режим или вообще останавливается.
Опытный пользователь знает, что наибольшая стабильность в производительности приложения достигается равной частотой на всех ядрах.
Стабильность в производительности какого приложения? И почему? Я несколько раз перечитал эту фразу и не понял, что хотел сказать автор. Видимо рассчет на то, что разработчик этого приложения синхронизацию делал через time.Sleep()?
И в случае с новыми Alder Lake таковая будет на уровне самого медленного комплекта ядер, то есть по планке 3,7 ГГц, если спецификации указаны верно.
Не понятно почему. Если у меня есть одно ядро, которое планировщик отдал потоку, который пытается что-то активно посчитать, то оно внизапно начнет работать с такой же скоростью как другое, которое планировщик отдал потоку, который ждет IO?
Если провести аналогию со спортсменами, наибольшая стабильность олимпийских игр достигается равной скоростью всех участников забега на 100 метров, так что-ли?
Как видим, физику обмануть невозможно: новые Alder Lake будут оснащаться теми же 10 нм ядрами, что и 10-11 поколение процессоров intel, флагман будет иметь на борту все те же 8 ядер/16 потоков и не ядром больше.
Либо я не могу правильно прочитать это предложение, либо здесь ошибка. 10 и 11 поколение десктопных intel процессоров не выпускалось на 10нм техпроцессе. Если бы они его выпустили, я бы не перешел на AMD.
Правда, для этого можно купить просто i9-11900K и получить примерно ту же производительность за, вероятно, меньшие деньги и на уже существующем сокете.
Вообще странный вывод. Даже если новый флагман вышел бы с теми же частотами и количеством ядер, что и 11900к, но на 10нм, то он наверняка оказался бы либо холоднее, либо с более высоким IPC, либо был бы какой-то балланс из этих двух показателей. То, что добавляют еще ядер - усложняет балансировку для инженеров, но уж наверняка хуже не будет. Либо процессоры дольше будут работать в бусте (т.к. производительные ядра более энергоэффективными окажутся - просто из за меньшего размера), либо они будут быстрее.
А это, простите, минимум 125 Вт в стоке и до 228 Вт под нагрузкой, когда работают все ядра:
Из статьи не понятно откуда берется 228Вт. Т.е. учитывая, то, насколько горячие процессоры 11-го поколения и то, что интел себя в общем в угол загнала - вполне вероятно. Но только совершенно не очевидно откуда цифра взялась.
Для справки: системы охлаждения, способные по паспорту рассеять 220 Вт тепла в российской рознице стартуют от 9 тысяч рублей или от 100$ на Amazon.
Так ему 220Вт надо будет рассеять в каком случае? Если все 8+8 ядер будут работать в бусте или если в бусте окажется только одно? Или только 8? Явно это будет не потребление когда все сидит на энергоэффективных ядрах.
Вот только не совсем понятно, зачем покупателю флагманского процессора компании, который, ожидаемо, хочет получить максимальную производительность, нужны эти «экологичные» технологии.
Очень даже понятно. Это же не серверный процессор, где нагрузку держат более менее постоянную (когда могут). Это десктоп, где большую часть времени самой медленной частью системы является прокладка из мяса между креслом и клавиатурой. Но иногда на десктопе бывают всплески нагрузки (когда, например, решили код собрать или игру запустить).
И даже в таком виде система была не всегда удобна: в задачах с переменной сложностью, например, в современных играх, эти скачки множителя CPU приводили к потере производительности в самом приложении
В играх были фризы из-за того, что процессор из-за отсутствия нагрузки снизил частоту? Или что имелось ввиду?
одним из популярных способов фикса этой «фичи» процессоров Intel стала банальная ручная блокировка множителей в BIOS на желаемом уровне. Хотя бы на уровне базовой производительности, заявленной по паспорту.
Это на каком поколении было? Что-то мне сдается, что от этого итоговая производительность процессора станет ниже и те же фризы будут чаще.
Как же в многопоточных и сложных приложениях будет происходить переключение между двумя разными процессорами, которые логически пусть и объединены в один блок, остается только догадываться.
Так же как она происходит сейчас. Планировщик будет выдавать кванты процессорного времени различным задачам исходя из своей логики. Судя по презентации Microsoft о Windows 11 там как раз его логику допиливали, чтобы он эффективно использовал энергоэффективные ядра.
Иначе вся суть покупки «флагмана» просто теряется за маркетинговой мишурой.
Наоборот. Отличная технология.

rogoz
16.07.2021 13:52По-моему очень даже верный шаг делает intel. Если у меня система обрабатывает что-то легкое, то пусть она работает на медленных ядрах и система охлаждения переходит или в бесшумный режим или вообще останавливается.
А почему это лёгкое не может работать как сейчас, на полноценных ядрах, но со сниженными частотами и напряжениями?cepera_ang
16.07.2021 14:31Потому что в полноценных ядрах есть куча машинерии, которая будет продолжать работать и потреблять энергию. К тому же, это весьма сложная задача — понять что сейчас обрабатываем "лёгкое" и можно позволить себе снизить частоты и напряжения.
DrPass
16.07.2021 14:46+1Если мы говорим про десктоп, то разницей между потреблением полноценного ядра на низкой частоте, и энергоэффективного ядра, можно (и нужно) пренебречь.
Я склоняюсь к тому, что решение тут было больше маркетинговым. С одной стороны, для достижения более высоких частот мощными ядрами необходимо было уменьшить тепловыделение всего чипа, а как вы верно сказали, полноценное ядро все равно будет что-то значимое выделять. Поэтому единственный способ сэкономить бюджет тепловыдения — выкинуть часть полноценных ядер. Но за это уже 16-ядерные конкуренты съедят с потрохами. Поэтому решили добавить энергоэффективные ядра, реальная польза от которых будет только на мобильных девайсах, но зато процессор номинально останется 16 ядерным, зато в «малопоточных» задачах вроде игровых применений будет рвать конкурентов.cepera_ang
16.07.2021 15:29Смотрите, представим, что у вас есть задача в которой есть параллельные и последовательные секции (а это очень много разных задач) и бюджет в определённое количество ватт. Как бы вы не параллелили параллельную часть, рано или поздно общее время выполнения будет ограничено оставшимися последовательными (закон Амдала, все дела) и в этот момент было бы круто ускорить эту последовательную часть, даже ценой замедления всех остальных. Вот что-то подобное Интел и пытается сделать. Ядра не потребляют энергию всё время, только когда работают и если в конкретный момент для конкретного ядра нет работы, то его можно отключить практически бесследно, с таким же успехом можно сказать, что его "выкинули", только динамически, в процессе работы, а не на заводе. И так же обратно вернуть, когда есть кусок, который нужно максимально быстро посчитать.
В процессоре есть множество ограничений — площадь кристалла, питание и т.д., поэтому нельзя просто сказать "а, кинули бы все ядра полноценные и дело с концом" — это получился бы совсем другой процессор, в другую ценовую категорию. И нельзя так сходу сказать "да там разница между ядрами которой можно пренебречь" — почти все отличия между процессорами укладываются в десятки и сотни решений, каждым из которых можно пренебречь, потому что они дают 0.1% ускорения в какой-то конкретной ситуации.
Вообще, если есть время, потратьте час, гляньте лекцию, которую я выше кидал (правда там только для затравки, следующая, которая раскрывает эти идеи ещё на 2.5 часа).
Если процессор будет рвать конкурентов в каких-то задачах, то есть ли покупателю разница "номинально" он является 16-ти ядерным или не номинально? А если вдруг таких задач окажется множество — отгрузить всю фоновую нагрузку на энергоэффективные ядра, где она будет занимать четверть бюджета по питанию, при этом давать 80% от того, что дали бы полноценные ядра, а полноценные ядра в это время получат 3/4 энергии и будут на 20% быстрее, чем были бы в противном случае и вуаля, у нас процессор, который работает как "номинальные 16 ядер" (все цифры условные, я не знаю что там будет у интела в реальности и, справедливости ради, не жду особых чудес).
DrPass
16.07.2021 15:49Смотрите, представим, что у вас есть задача в которой есть параллельные и последовательные секции (а это очень много разных задач)
Вы мне поверите без фактов и пруфов, если я вам скажу, что 99.9% таких задач — это нечто фоновое, которое вообще не формирует сколь-нибудь значимой нагрузки на процессор? А те задачи, которые его действительно загружают, имеют достаточно выраженную либо однопоточную вычислительную нагрузку, либо параллельную. И в общем-то новая интеловская архитектура хорошо оптимизирована под первые, и плохо под вторые.Если процессор будет рвать конкурентов в каких-то задачах, то есть ли покупателю разница «номинально» он является 16-ти ядерным или не номинально?
Есть же несколько видов покупателей. Например, обыватель, не особо сведущий в технике, зачастую покупает как раз по цифрам. Их больше всего, и это как раз для них. Плюс ещё есть геймеры, которым действительно важна максимальная производительность на несколько потоков.В процессоре есть множество ограничений — площадь кристалла, питание и т.д., поэтому нельзя просто сказать «а, кинули бы все ядра полноценные и дело с концом»
Я же не про это, я как раз писал, что им для получения максимального быстродействия нужен был 8-ядерный процессор, а не 16-ядерный :)Вообще, если есть время, потратьте час, гляньте лекцию, которую я выше кидал (правда там только для затравки, следующая, которая раскрывает эти идеи ещё на 2.5 часа).
Не могу :) Я уже давно не смотрю длинные видеоматериалы, это и долго, и неудобно — статью можно читать с той скоростью, которая лучше подходит для каждого читателя, а не для автора, можно легко передвигаться между блоками информации, пропускать понятное и т.д. Формат видео — это очень уж на любителя.cepera_ang
16.07.2021 16:22Не могу :)
Слайды полистайте :)
Есть же несколько видов покупателей
Обыватель, покупающий по цифрам купит себе что-нибудь простое. Если это конечно не тип покупателя, который как бы разбирается, но в реальности всё равно покупает по цифрам.
В общем, моё мнение, что интел выжимает что может из доступного техпроцесса и его ограничений, а уж что выйдет в конечном итоге и для каких задач будет подходить — посмотрим после выхода, сейчас особо гадать нет смысла.

mikhanoid
17.07.2021 00:20Даже если фоновые задачки мелкие, они могут замусоривать кэши, и они требуют сброса tlb при переключении контекстов. А перезагрузка кэшей и tlb - это довольно дорогие операции. Поэтому, если всю фоновую активность получится вынести на little-ядра, вычисления на big-ядрах можно будет выполнять стабильнее и быстрее. Даже в играх есть куча задач, которые уместно выполнять на little-ядрах: скрипты там всякие, обмен данными со всякими не быстрыми устройствами, вроде аудио или сети, etc.
То есть, в принципе, технология такая имеет смысл для практики.
Но я думаю, что Intel-у это всё не интересно, им интересно научиться делать 3D-сборки чипов, и именно этим обусловлена такая гетерогенная конструкция.

onlinehead
17.07.2021 14:55Все верно. Это бы хорошо работало, если бы не было альтернативы или ядер было больше. А она есть. В продаже вполне есть 32-поточные десктопные камни от AMD, где все ядра быстрые. И есть относительно дешевые 16 поточные, где тоже все ядра быстрые.
Отсюда возникает закономерный вопросы - какой смысл городить отдельный более сложный планировщик, если можно просто взять камень, где все ядра одинаковые и аппаратная платформа сама разберётся с оптимизацией потребления энергии? Работать оно точно будет быстрее и проблем с этим будет меньше.
Am0ralist
18.07.2021 17:09А ещё есть 12/24 поточные процессоры АМД, где все потоки так же — на жирных ядрах. И у меня большие сомнения, что 16/24 интела окажется заметно лучше их.

severgun
16.07.2021 14:48Единственное что нужно от 12го поколения это переход на DDR5
boblenin
16.07.2021 16:16+2PCIE 5? Больше линий PCIE?
severgun
17.07.2021 23:271) PCIE4 никто не смог утилизировать. Но 5 конечно очень надо(нет)
2) Свободные линии уже сейчас тратят просто так на доп М2 слоты и Thunderbolt/USB3.2(при ничтожном количестве устройств на рынке). Лучше бы 10G интерфейс на них вешали.
creker
17.07.2021 23:34+11. pcie диски смогли, но это домашний сегмент. В серверном pcie4 уже давно не хватает.
2. В топовые матери ставят. И как-будто 10гбит в домашнем сегменте будет востребовано. Быстрые диски и usb устройства хотя бы норма вполне.
Am0ralist
18.07.2021 17:131) PCIE4 никто не смог утилизировать. Но 5 конечно очень надо(нет)
Так ведь через неё не только видики гоняют.Свободные линии уже сейчас тратят просто так на доп М2 слоты
Свободные линии есть разве что у тредриперов в домашнем использовании. А вот второй m2 на чипсетах по старым PCIE (b450 от АМД те же самые) — уменьшают количество сата. То есть выбирай — второй m2 или 6, а не 4 сата, ага. Так что PCIE5 в чипсетах, например, востребовано вполне, если у тебя не блок с 1 видиком и 1 pcie m2 диском.

novice2001
Первое, что бросается в глаза — это техническая безграмотность автора.
Даже в статье прямо указано, что экономичные ядра — это gracemont, т.е. развитие энергоэффективных ядер семейства Atom, а не «навешенные на шею i3 или i5».
lokkiuni
Про TDP и PL автор тоже не читал - увидел 228 и ой-страшно-страшно. Не то чтобы 228 было нормально - но они совсем про другое, про ~200А от VRM, и то краткосрочно. Дальше работает куча механизмов вытянуть максимум производительности здесь и сейчас, для этого же и такие сложные схемы буста и такая низкая базовая частота (ниже которой если уж на то пошло процессор тоже может опуститься при тяжёлом AVX, если все лимиты по спекам стоят, а не по разумению вендора МП)
Hait
А ещё стоит вспомнить, что у 11900k PL2 в 250 ...