Эта статья является переводом материала «What is functional programming?».
В этой статье Владимир Хориков попытается ответить на вопрос: что такое функциональное программирование?
Функциональное программирование
Итак, что такое функциональное программирование? Этот термин возникает довольно часто, и каждый автор, пишущий о нем, дает собственное объяснение. На взгляд автора оригинала, самым простым и в то же время точным определением является следующее: функциональное программирование - это программирование с математическими функциями.
Математические функции не являются методами в программном смысле. Хотя мы иногда используем слова «метод» и «функция» как синонимы, с точки зрения функционального программирования это разные понятия. Математическую функцию лучше всего рассматривать как канал (pipe), преобразующий любое значение, которое мы передаем, в другое значение:
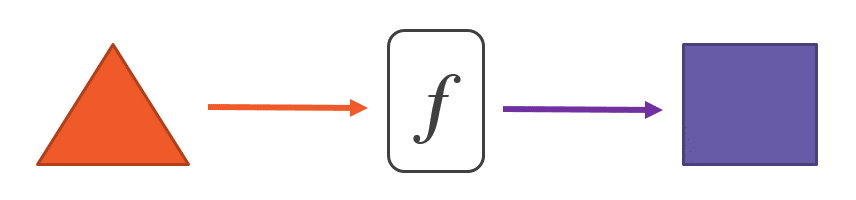
Вот и все. Математическая функция не оставляет во внешнем мире никаких следов своего существования. Она делает только одно: находит соответствующий объект для каждого объекта, который мы ему скармливаем.
Для того чтобы метод стал математической функцией, он должен соответствовать двум требованиям. Прежде всего, он должен быть ссылочно прозрачным (referentially transparent). Ссылочно прозрачная функция всегда дает один и тот же результат, если вы предоставляете ей одни и те же аргументы. Это означает, что такая функция должна работать только со значениями, которые мы передаем, она не должна ссылаться на глобальное состояние.
Вот пример:
public long TicksElapsedFrom(int year)
{
DateTime now = DateTime.Now;
DateTime then = new DateTime(year, 1, 1);
return (now - then).Ticks;
}Этот метод не является ссылочно прозрачным, потому что он возвращает разные результаты, даже если мы передаем в него один и тот же год. Причина здесь в том, что он ссылается на глобальное свойство DatetTime.Now.
Ссылочно прозрачной альтернативой этому методу может быть (Эта версия работает только с переданными параметрами):
public long TicksElapsedFrom(int year, DateTime now)
{
DateTime then = new DateTime(year, 1, 1);
return (now - then).Ticks;
}Во-вторых, сигнатура математической функции должна передавать всю информацию о возможных входных значениях, которые она принимает, и о возможных результатах, которые она может дать. Можно называть эту черту честность сигнатуры метода (method signature honesty).
Посмотрите на этот пример кода:
public int Divide(int x, int y)
{
return x / y;
}Метод Divide, несмотря на то, что он ссылочно прозрачный, не является математической функцией. В его сигнатуре указано, что он принимает любые два целых числа и возвращает другое целое число. Но что произойдет, если мы передадим ему 1 и 0 в качестве входных параметров?

Вместо того, чтобы вернуть целое число, как мы ожидали, он вызовет исключение «Divide By Zero». Это означает, что сигнатура метода не передает достаточно информации о результате операции. Он обманывает вызывающего, делая вид, что может обрабатывать любые два параметра целочисленного типа, тогда как на практике он имеет особый случай, который не может быть обработан.
Чтобы преобразовать метод в математическую функцию, нам нужно изменить тип параметра "y", например:
public static int Divide(int x, NonZeroInteger y)
{
return x / y.Value;
}Здесь NonZeroInteger - это пользовательский тип, который может содержать любое целое число, кроме нуля. Таким образом, мы сделали метод честным, поскольку теперь он не ведет себя неожиданно для любых значений из входного диапазона. Другой вариант - изменить его возвращаемый тип:
public static int ? Divide(int x, int y)
{
if (y == 0)
return null;
return x / y;
}Эта версия также честна, поскольку теперь не гарантирует, что она вернет целое число для любой возможной комбинации входных значений.
Несмотря на простоту определения функционального программирования, оно включает в себя множество приемов, которые многим программистам могут показаться новыми. Посмотрим, что они из себя представляют.
Побочные эффекты (Side effects)
Первая такая практика - максимально избегать побочных эффектов за счет использования иммутабельности по всей базе кода. Этот метод важен, потому что акт изменения состояния противоречит функциональным принципам.
Сигнатура метода с побочным эффектом не передает достаточно информации о фактическом результате операции. Чтобы проверить свои предположения относительно кода, который вы пишете, вам нужно не только взглянуть на саму сигнатуру метода, но также необходимо перейти к деталям его реализации и посмотреть, оставляет ли этот метод какие-либо побочные эффекты, которых вы не ожидали:

В целом, код со структурами данных, которые меняются со временем, сложнее отлаживать и более подвержен ошибкам. Это создает еще больше проблем в многопоточных приложениях, где у вас могут возникнуть всевозможные неприятные условия гонки.
Когда вы работаете только с иммутабельными данными, вы заставляете себя обнаруживать скрытые побочные эффекты, указывая их в сигнатуре метода и тем самым делая его честным. Это делает код более читабельным, потому что вам не нужно останавливаться на деталях реализации методов, чтобы понять ход выполнения программы. С иммутабельными классами вы можете просто взглянуть на сигнатуру метода и сразу же получить хорошее представление о том, что происходит, без особых усилий.
Исключения
Исключения - еще один источник нечестности для вашей кодовой базы. Методы, которые используют исключения для управления потоком программы, не являются математическими функциями, потому что, как и побочные эффекты, исключения скрывают фактический результат операции.
Более того, исключения имеют семантику goto, что означает, что они позволяют легко переходить из любой точки вашей программы в блок catch. На самом деле, исключения работают еще хуже, потому что оператор goto не позволяет выходить за пределы определенного метода, тогда как с исключениями вы можете легко пересекать несколько уровней в своей базе кода.
Примитивная одержимость (Primitive Obsession)
В то время как побочные эффекты и исключения делают ваши методы нечестными в отношении их результатов, примитивная одержимость вводит читателя в заблуждение относительно входных значений методов. Вот пример:
public class User
{
public string Email { get; private set; }
public User(string email)
{
if (email.Length > 256)
throw new ArgumentException("Email is too long");
if (!email.Contains("@"))
throw new ArgumentException("Email is invalid");
Email = email;
}
}
public class UserFactory
{
public User CreateUser(string email)
{
return new User(email);
}
}Что нам говорит сигнатура метода CreateUser? Она говорит, что для любой входной строки он возвращает экземпляр User. Однако на практике он принимает только строки, отформатированные определенным образом, и выдает исключения, если это не так. Следовательно, этот метод нечестен, поскольку не передает достаточно информации о типах строк, с которыми работает.
По сути, это та же проблема, которую вы видели с методом Divide:
public int Divide(int x, int y)
{
return x / y;
}Тип параметра для электронной почты, а также тип параметра для "y" являются более грубыми, чем фактическая концепция, которую они представляют. Количество состояний, в которых может находиться экземпляр строкового типа, превышает количество допустимых состояний для правильно отформатированного электронного письма. Это несоответствие приводит к обману разработчика, который использует такой метод. Это заставляет программиста думать, что метод работает с примитивными строками, тогда как на самом деле эта строка представляет концепцию предметной области со своими инвариантами.
Как и в случае с методом Divide, нечестность можно исправить, введя отдельный класс Email и используя его вместо строки.
Nulls
Еще одна практика в этом списке - избегать nulls. Оказывается, использование значений NULL делает ваш код нечестным, поскольку сигнатура методов, использующих их, не сообщает всю информацию о возможном результате соответствующей операции.
Но тут, конечно, зависит от языка. Автор оригинала работает с C#, в котором до 8 версии нельзя было указывать является ли значение nullable (https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/nullable-value-types). Так как оригинал статьи 2016 года, на тот момент еще не было такой возможности в C#.
Фактически, в C # все ссылочные типы действуют как контейнер для двух типов значений. Один из них является экземпляром объявленного типа, а другой - null. И нет никакого способа провести различие между ними, поскольку эта функциональность встроена в сам язык. Вы всегда должны помнить, что, объявляя переменную ссылочного типа, вы фактически объявляете переменную пользовательского двойного типа, которая может содержать либо нулевую ссылку, либо фактический экземпляр:

В некоторых случаях это именно то, что вам нужно, но иногда вы хотите просто вернуть MyClass без возможности его преобразования в null. Проблема в том, что в C # это невозможно сделать. Невозможно различить ссылочные типы, допускающие значение NULL, и ссылочные типы, не допускающие значения NULL. Это означает, что методы со ссылочными типами в своей сигнатуре по своей сути нечестны.
Эту проблему можно решить, введя тип Maybe и соглашение внутри команды о том, что всякий раз, когда вы определяете переменную, допускающую значение NULL, вы используете для этого тип Maybe.
Почему функциональное программирование?
Важный вопрос, который приходит на ум, когда вы читаете о функциональном программировании: зачем вообще беспокоиться об этом?
Одной из самых больших проблем, возникающих при разработке корпоративного программного обеспечения, является сложность. Сложность кодовой базы, над которой мы работаем, является единственным наиболее важным фактором, влияющим на такие вещи, как скорость разработки, количество ошибок и способность быстро приспосабливаться к постоянно меняющимся потребностям рынка.
Существует некий предел сложности, с которой мы можем справиться за раз. Если кодовая база проекта превышает этот предел, становится действительно трудно, а в какой-то момент даже невозможно что-либо изменить в программном обеспечении без каких-либо неожиданных побочных эффектов.
Применение принципов функционального программирования помогает снизить сложность кода. Оказывается, программирование с использованием математических функций значительно упрощает нашу работу. Благодаря двум характеристикам, которыми они обладают - честности сигнатуры метода и ссылочной прозрачности - мы можем гораздо проще понимать и рассуждать о таком коде.
Каждый метод в нашей кодовой базе - если он написан как математическая функция - можно рассматривать отдельно от других. Когда мы уверены, что наши методы не влияют на глобальное состояние или не работают с исключением, мы можем рассматривать их как строительные блоки и компоновать их так, как мы хотим. Это, в свою очередь, открывает большие возможности для создания сложной функциональности, которую создать ненамного сложнее, чем части, из которых она состоит.
Имея честную сигнатуру метода, нам не нужно останавливаться на деталях реализации метода или обращаться к документации, чтобы узнать, есть ли что-то еще, что нам нужно учесть перед его использованием. Сама сигнатура сообщает нам, что может случиться после того, как мы вызовем такой метод. Модульное тестирование также становится намного проще. Все сводится к паре строк, в которых вы просто указываете входное значение и проверяете результат. Нет необходимости создавать сложные тестовые двойники, такие как mocks, и поддерживать их в дальнейшем.
Резюме
Функциональное программирование - это программирование с использованием математических функций. Для преобразования методов в математические функции нам нужно сделать их сигнатуры честными в том смысле, что они должны полностью отражать все возможные входные данные и результаты, и нам также необходимо убедиться, что метод работает только с теми значениями, которые мы передаем, и ничего больше.
Практики, которые помогают преобразовать методы в математические функции:
Иммутабельность.
Избегать исключения для управления потоком программы.
Избавляться от примитивной одержимости.
Делать nulls явными.
Комментарии (107)

vovikilelik
01.08.2021 10:17-5Может всё же функционное, а не функциональное? Функциональный, по словарю - имеющий практическое применение. А у вас, что-то вроде методологии программирования функциями. (см. аналогию с "векторное...")

sergey-gornostaev
01.08.2021 10:28+7Нет, не может. Функциональное программирование - это термин, ещё в 50-х годах прошлого века рождённый академиками, стоявшими у истоков всей индустрии информационных технологий.

mikhanoid
01.08.2021 10:53+3Академики в те времена этот подход называли процедурным (см. lamba letters, например). Под functional programming тогда понималось нечто вроде APL.
sergey-gornostaev
01.08.2021 11:06+1В "Can Programming Be Liberated from the von Neumann Style? A Functional Style and Its Algebra of Programs" Бэкуса этот подход называется functional programming.
mikhanoid
01.08.2021 11:21+2У Бэкуса идеи были несколько отличными от тех, что мы сейчас называем функциональным программирванием.
sergey-gornostaev
01.08.2021 11:39+1Это уже вопрос досужих споров о чистоте, что считать настоящим функциональным программированием, а что нет. В них я склонен согласится с Одерским, который писал, что основа и необходимый минимум функциональной парадигмы - это функции первого класса без побочных эффектов, а всё остальное - лишь производные от этой простой идеи.
mikhanoid
01.08.2021 12:04Я не спорю. Но хочу уточнить, что академики до середины 80-ых иначе на всё это смотрели. Такое вот определение ФП было практически бессмысленным до появления работ Moggi по монадам.

GospodinKolhoznik
01.08.2021 11:29+3От слова функционал - математический термин, обобщающий понятие функции.


emptycat
01.08.2021 10:39+11Статья неплохая, жаль что в ней нет ни слова о функциональном программировании

Gorthauer87
01.08.2021 11:06+4Только вот функциональное программирование ради достижения ссылочной прозрачности опирается на рекурсию, которая хоть и выглядит изящно, но совершенно не ложится на модель вычислений в компьютерах.
Можно сводить рекурсию к хвостовой, но об этом надо всегда помнить и не всегда это удобно. Да и ленивость фунциональных языков тоже может внезапно отожрать всю память, о чем тоже приходится помнить и где надо подставлять костыли, чтобы сделать вычисления энергичными. В итоге эффективный код на фунциональных языках ничуть не проще писать, чем на императивных, а то и сложнее.

F0iL
01.08.2021 11:29+2Кмк, это именно из-за попыток натянуть сову на глобус. А именно, в ФП один из основных принципов "у нас нет изменяемого состояния", в то время как в реальном мире современной вычислительной техники все наоборот: регистры процессора, ячейки оперативной памяти и сектора на диске -- предназначены именно что для хранения этого самого "изменяемого состояния". А попытки абстрагироваться от этого и переложить всё на плечи компилятора напоминают известную картинку "if I ignore it, maybe it will go away" с соответствующими результатами.
Gorthauer87
01.08.2021 11:47+1Так в итоге пишут, что почти вся стандартная библиотека Хаскеля внутри на самом деле содержит реализации функций через мутабельность.
Короче говоря, пока пишешь нечто высокоуровневое, то все очень круто, но если надо написать нечто числодробильное, то все тлен.

GeorgeII
01.08.2021 20:28+2Конкретно про стандартную библиотеку хаскеля не знаю, но, вообще, локальная мутабельность, которая гарантированно никак не может быть достигнута извне, не противоречит чистоте функции.
В скале, например, куча циклов while и обычных переменных внутри функций стандартной библиотеки и даже у функций/методов иммутабельных коллекций.Короче говоря, пока пишешь нечто высокоуровневое, то все очень круто, но если надо написать нечто числодробильное, то все тлен.
Но ведь про какую-нибудь джаву можно сказать похожим образом :)
mikhanoid
01.08.2021 11:51+4Давно уже известно, как эффективно компилировать функциональный код для машин с регистрами и обычной памятью. Наблюдаемая неизменяемость - это удобство для программиста и для компилятора, который может себе позволить более агрессивно оптимизировать.
Фишка в том, что в реальных программах изменяемое состояние, действительно, локализовано компактно, а большинство преобразований данных можно рассматривать, как функциональные.
Джон Кармак как-то рассказывал, что всё изменяемое состояние в Rage (могу путать title) укладывается, буквально, в кэш процессора (который в те времена был около мегабайта).
GospodinKolhoznik
01.08.2021 11:40+1Странно требовать от фп эффективности, ведь его изначальной задачей, ради которой всё фп создавалось был Уход от диктатуры архитектуры Фон Неймана. Понятно, что за этот уход надо заплатить определенную цену.
И разумеется, невозможно добиться той же эффективности, что и на чистом Си, языке который сделан таким, чтобы программировать на нем по сути в машинных кодах, обернутых синтаксическим сахаром.

RarogCmex
09.08.2021 12:13Тем не менее, оптимизированный Хаскель держит свою скорость на уровне оптимизированного C#, если не уделывает.
mikhanoid
01.08.2021 11:41+3Компиляторы во многих случаях сами могут сводить рекурсию к хвостовой. Есть ещё всякие там deforestation-оптимизации, слияния циклов, дырявые аргументы и т.д. и т.п.
Ленивость, вроде как, может принести сюрпризы, но сейчас во всех языках можно ей управлять.
По опыту большой разницы не видно во вручную не вылизанном коде что на Си, что на Scheme (с компилятором Chez). На Си проще потом ускорить какие-то критические участки, но это всё-равно трудозатраты... Руководство же требует результат уже вчера. Поэтому проще и быстрее нафигачить нечто функциональное, не думая о памяти, сдать MVP, который будет не плох по производительности, а потом уже критичные участки переписать на Си, или в императивном стиле, или используя прямо генераторы машинного кода для конкретных задач.
Методы, в общем, есть.
Gorthauer87
01.08.2021 11:52+1А ещё чисто функциональный подход не работает без иммутабельных структур данных, а они нормально не реализуются без сборщика мусора.
В итоге, на низком уровне вообще не выжить никак без мутабельного состояния и создать функциональный язык для системного программирования невозможно. Можно лишь взять некоторые элементы, как это сделали в плюсах или расте.
mikhanoid
01.08.2021 12:24+4Ну, это некоторый миф, что для низкоуровневого программирования обязателен язык без сборщика мусора. Есть куча контрпримеров (операционки написанные не на условном Си, а на managed языках): JNode, Genera, Mezzano, Inferno, Loko Scheme, Hause, Mirage, Picobit Scheme (это вообще для stm-ок).
Со сборщиком мусора можно жить, даже относительно эффективно: в Mezzano, работающей в виртуальной машине, можно запустить Quake, который оттранслирован в Common Lisp, а потом обратно откомпилирован в машинный код, и относительно комфортно поигать.
Без мутабельности, да, не обойтись. Интерфейс с внешним миром и оборудованием мутабельный.
Gorthauer87
01.08.2021 13:05+2Мифом это перестанет быть когда ось с GC станет активно в проде использоваться.
amarao
01.08.2021 11:41+4Кроме side effects есть ещё и side causes, и я даже не знаю, что сложнее для управления.
Сама модель side effects очень ограничена и не полностью описывает "ожидаемое" от программы.
Вот представьте себе такую программу
fn add_user(email_str: &str) -> User{ let parsed_email = Email::new(email_str); match parsed_email{ Ok(email) => User::new(email) Err(_) => loop{} } }Что тут написано в сигнатуре. Что функция всегда возвращает User по его email. Что эта функция делает? Строго соответствует своей сигнатуре. Когда она завершается, она возвращает пользователя с валидным email'ом. Что происходит, если email на входе не валидный? Функция ...решает проблему, посредством bottom type.
Что полностью соответствует ожиданиям системы типов, но полностью не соответствует ожиданиям пользователей.
Почему такая наглость прокатывает? Потому что time не является side effect для программы в рамках модели. Почему? Потому что так удобнее считать программы.
А ведь в side effects с бытовой точки зрения входит "сожрать батарейку", "зависнуть" и "начать тупить". А с точки зрения теории - не входит.
Gorthauer87
01.08.2021 11:54+3А разве такое можно формально в сигнатуре обозначить? Ведь мы же неизбежно на проблему останова натыкаемся.
amarao
01.08.2021 12:15+2Формально, у
loop{}иsystem.halt()будет одинаковая сигнатура -!(divergence, bottom type).Я свой комментарий оставил не как предложение "переписать систему типов", а как указание на то, что святой грааль чистых функций не такой уж святой и не такой уж грааль, и функции не такие уж чистые.

0xd34df00d
01.08.2021 23:19Или просто раст не является святым граалем ФП.
amarao
02.08.2021 11:10А в какой системе типов bottom тип не является подтипов для всех типов? Кто-то оказался умнее Карри и Хорварда?

mayorovp
02.08.2021 11:56+1Правильнее спрашивать в какой системе типов у bottom-типа нет bottom-значения.
amarao
02.08.2021 13:56+2Ни у какого bottom-типа нет bottom-значения. Или я не совсем понял, о чём вы говорите.
In type theory, a theory within mathematical logic, the bottom type is the type that has no values.
mayorovp
02.08.2021 14:17Ну да, в System F так и есть. А вот в том же Расте или даже Хаскеле этот тип "населён" bottom-значением.
amarao
02.08.2021 14:21+1Вы не можете объяснить это? Я считал, что bottom (`!`) - это divergence, и компилятор может быть уверен, что после первого такого выражения дальше там "ничего не исполняется".
Может быть, я что-то тут не понимаю или не знаю. Что?
mayorovp
02.08.2021 19:49С точки зрения математики функция не может перестать исполняться. Поэтому, чтобы отразить такую возможность, в область значений функции добавляется специальное значение, которое как раз и означает что функция не вернула управления.
amarao
02.08.2021 21:46+1Мне эта интерпретация не звучит. (точнее, если так сделали, я хочу это увидеть в коде). bottom type - это же для арифметики типов, а не для вычисления "значений". Это описание возвращаемого типа, а не доступных ему значений. У unit доступно одно значение (ничего), у bottom типа - никакое значение не доступно.
mayorovp
02.08.2021 22:12В коде вы никакого ⊥-значения не увидите, это математическая абстракция, которая отражает все аномальные (abnormal) способы возврата из чистой функции: бесконечный цикл, завершение процесса, исключение или панику, возникновение UB.
Могу пояснить на примере функции
f(x)=1/x. Забудем ненадолго про IEEE 754 и представим что мы работаем в R, а не в колесе над R.В математике эта функция имеет тип
R \ {0} → R \ {0}. Но в большинстве языков программирования типR \ {0}невыразим, из-за чего эту функцию приходится рассматривать как функцию над R, соответственноf(0)становится легальной конструкцией. Поэтому мы доопределяемf(0) = ⊥и тип функции получаетсяR → R ∪ {⊥}.
amarao
02.08.2021 22:30А вот у меня ощущение, что тут мухлёж.
Предположим, у нас есть функция, которая берёт функцию и её аргументы, и отвечает, завершается ли такая функция.
И какая у неё сигнатура? Не в жалких плебейских языках, а в возвышенной чистой математике.
mayorovp
02.08.2021 22:44Ну, если забыть о том, что такая функция невозможна в силу проблемы останова — то в "возвышенной математике" она будет иметь тип
{ (t, q, f, x) ∀t∈Type ∀q∈Type ∀f∈(t → q) ∀x∈t } → Bool, где Type — (псевдо)категория всех типов языка.А причём тут вообще эта функция?
amarao
03.08.2021 12:35А чем оно тогда будет отличаться от вот этого?
loop{}; trueЯ к тому, что если мы хотим специально выразить поведение
R \ {0} → R \ {0}, то почему мы не хотим специально в системе типов описать проблему остановки? Чем отличается R \ {0} (который мы "по немощи" заменяем наR → R ∪ {⊥}от(t, q, f, x) -> bool ∪ {⊥}?
amarao
03.08.2021 22:32А зачем вообще что-то в системе типов описывать? Всё - числа. Прочитал число, записал число по адресу числа, работа сделана.
0xd34df00d
04.08.2021 00:55В системе типов нужно что-то описывать, чтобы рассуждать о коде без его запуска. Только вот тут смотрите, какая штука получается.
- На практике, когда вы занимаетесь тырпрайз-программированием, факт «функция завершается за конечная время» не является практически интересным сам по себе — тот же Аккерман здесь вполне в тему будет.
- Когда вы занимаетесь всякой теорией, оказывается достаточно удобным работать в системе, где любая типизируемая функция гарантированно завершается, и вопрос решается сам собой.
mayorovp
04.08.2021 00:11Я перестал понимать о чём вы спрашиваете.
Что вы понимаете под "в системе типов описать проблему остановки" и почему вы заранее решили, что "мы" её описывать не хотим?
0xd34df00d
02.08.2021 22:45Зависит от ваших абстракций.
Если вы рассматриваете произвольные функции в рамках нетипизированного лямбда-исчисления или машин Тьюринга, то такой функции не существует по очевидным причинам. Если же вы рассматриваете какую-то strongly normalizing-систему типов, то этой функцией будет ваш тайпчекер. Правда, в этом случае могут быть false negatives: если тайпчекер сказал «нет», то не факт, что функция на самом деле не завершается.
Ну и этот тайпчекер не сможет протайпчекать сам себя по Гёделевым причинам.
mayorovp
02.08.2021 22:29О, вспомнил вот по поводу ⊥-значений в коде. Тут не совсем код, но вот в спецификациях нечто похожее можно увидеть часто.
В LLVM есть такое понятие, как poison value, эта штука является одним из возможных представлений ⊥-значения.
Или вот спецификация ECMAScript — там есть такое понятие как Completion Record. Если поле
[[Type]]этой структуры отлично отnormal— эта структура представляет собой разновидность ⊥-значения.
amarao
02.08.2021 22:36Разве poison - это bottom? Я думал, это средство описания (и ограничения) UB. bottom type - он же вполне себе определённый, более того, иногда весьма полезный. Например, state machine может быть описана целиком внутри одного loop и не иметь выхода (но при этом быть вполне себе рабочей программой для кофе-машины).
mayorovp
02.08.2021 22:45Ну так ⊥-значение точно так же является средством описания любых аномальных условий выхода из функции.
0xd34df00d
02.08.2021 17:52Для этого нужно, чтобы у вас было отношение подтипизации, а это не во всех языках есть, мягко скажем.
Вероятно, вы действительно имели в виду что-то другое — например, в какой системе типов bottom-тип населён (или, что эквивалентно, в какой системе типов можно построить в пустом контексте значение bottom-типа). И это выполняется для любой консистентной системы типов (вроде System F, упомянутой рядом, или, упрощая, систем типов в агде/идрисе/коке). В хаскеле и расте это действительно не выполняется. А за счёт того, что хаскель — полиморфный язык, там каждый тип населён всеми ожидаемыми вами значениями плюс
undefined(но это тоже немного упрощение), поэтому у вас может сложиться ложное впечатление о подтипизации.
mayorovp
02.08.2021 14:21+1Формально, у
loop{}иsystem.halt()будет одинаковая сигнатура — ! (divergence, bottom type).В Расте — да. А вот в том же Хаскеле первая функция — это и правда чистый bottom, в то время как вторая — это скорее
IO<Void>. И, если как-нибудь добавить сюда проверку тотальности, можно "изгнать" первую конструкцию из языка не потревожив вторую.amarao
02.08.2021 15:27+1А как в haskell обрабатывают ошибки аллокации? Допустим, по сигнатуре функции она не может fail. И тут, ррраз, и у нас stack overflow (потому что на стеке нет места для переменных для чистой функции).
На самом деле в rust system.halt - это будет чистый
unsafeи с ним понятно, что всё плохо. Я показал halt как "неспецифичный" пример, потому что на самом деле ошибки аллокации в расте - это panic!, который внутри себя abort!, который пытается сделать сайд-эффект вида "убей меня ОС", но если ОС отказывается, делает illegal instruction, но если это не срабатывает, в финале делает loop{}, чтобы соблюсти сигнатуру.А вот как с этой проблемой обходится Haskell? Т.е. что делать, если в функции, которая не может фейлиться, произошёл фейл не по вине программы?
0xd34df00d
02.08.2021 17:53Обрабатывается это так же, как внезапное выключение компьютера пользователем — никак. Но у этого нет теоретических причин, это исключительно вопрос практичности — вы не захотите, чтобы у вас вообще каждое выражение требовало чего-то вроде
MonadnError-контекста, на таком языке просто невозможно будет писать.amarao
02.08.2021 19:04Ну, например, когда раст попытались затащить в ядро, оказалось, что обрабатывать ошибку аллокации памяти как панику - это плохая идея для ядра операционной системы.
0xd34df00d
02.08.2021 19:55Для таких случаев ИМХО лучше на функциональном языке сделать какой-нибудь (e)DSL и потом о нём рассуждать. Ну, как ivory, например.
mayorovp
02.08.2021 19:55В чистых функциях их не обработать никак, они просто прерываются и всё. Однако, чистая функция на то и чистая, что её можно прерывать в любом месте и окружение от этого не пострадает.
А вот в монаде IO ничто не мешает написать catch — и дальше вопрос ловли исключения перестаёт быть проблемой системы типов, становясь проблемой рантайма.
mikhanoid
01.08.2021 12:26+3Можно запретить нетотальные функции вообще, а потом доказывать в нетривиальных случаях, что функция действительно тотальна. Смотрите, например, язык ATS.
Не уверен, что это практично, но метод существует.
amarao
02.08.2021 14:07+1Тогда любой side effect может быть нетотальным.
`fn out(port : u16, num: u16) -> ()`
И вот что там после записи в порт? Функция может и не вернуться, если какой-то порт - это управление питанием. Или вернуться со значением, если это переключатель режима процессора.
mikhanoid
03.08.2021 11:06+1Эффекты как раз и выделяют отдельно, потому что они могут быть нетотальны. Функция генерирует эффект (тотально), а эффект как-то действует. Базовая идея в этом.
mikhanoid
03.08.2021 11:07В Rust, кстати, с точки зрения теории функций нет. Так что в примерах есть некоторое abuse of notation.
0xd34df00d
01.08.2021 23:19+1Есть языки, где просто нет незавершающихся (вернее, учитывая коданные, непродуктивных) функций. Там если в сигнатуре написано Int, то функция всегда за конечное время возвращает число.
Да, эти языки неполны по Тьюрингу, но оказывается, что это нестрашно.
amarao
02.08.2021 11:12+2Скажите, а фукция Аккермана с параметрами A(4, 2), она тоже будет проходить по signature checking? Я понимаю, что есть глубокая теоретическая разница между
loopиakkerman(4,2), но с практической точки зрения этой вселенной - это одно и то же.0xd34df00d
02.08.2021 17:56+1Скажите, а фукция Аккермана с параметрами A(4, 2), она тоже будет проходить по signature checking?
Для языков с адекватным totality checker'ом — да, будет.
Я понимаю, что есть глубокая теоретическая разница между loop и akkerman(4,2), но с практической точки зрения этой вселенной — это одно и то же.
loopне существует не для того, чтобы программа не зависала, а для того, чтобы нельзя было доказать на самом деле ложные утверждения.Ваш
loopможет вернуть любой тип (или bottom-тип, для полиморфного языка).ackвозвращает число, и вам это совершенно не поможет получить значение типаIO Userиз вашего примера. Вызывать её просто нет смысла.amarao
02.08.2021 19:06Я про другое. loop - это 'false', если утрировать. При этом A(4,2) - это true. Хотя, на самом деле, с точки зрения любых вообразимых вычислений, это false.
0xd34df00d
02.08.2021 20:00Но это не false с точки зрения тайпчекера, и с этой точки зрения A(4, 2) не отличается вообще ничем от какой-нибудь константы вроде 42. Вам же не приходит в голову написать
Err(_) => 42? ЧемErr(_) => A(4, 2)для вас лучше?Иными словами, система типов не разрешает bottom не потому, что она хочет оградить вас от зависания, а потому, что она хочет оградить вас от доказательства ложных утверждений. Как реализован bottom — бесконечным циклом ли, паникой и возвратом управления ОС ли, совершенно неважно.
Совсем иными словами, я пишу код, который вообще никто никогда не будет запускать, и я рад, что в моём языке нет боттомов не потому, что иначе всё зависнет.
mayorovp
02.08.2021 20:01-1С практической точки зрения я вижу проблему так:
Вменяемый программист, который в принципе понимает что он делает, вряд ли напишет настолько неоптимальную программу, что её выполнение будет эквивалентно вычислению A(4,2).
Но при этом легко случайно написать бесконечный цикл или бесконечную рекурсию, например из-за опечатки.
Поэтому есть смысл в системе типов, которая защищает от второго, но пропускает первое.
0xd34df00d
02.08.2021 20:07На самом деле с практической точки зрения довольно легко написать программу, которая будет работать хоть и не несколько возрастов Вселенной, как Аккерман, но достаточно долго для того, чтобы человек её завершения не дождался.
Если вам это на самом деле важно, то все интересные вам операции (скажем, в случае сортировки — сравнения и перестановки) становятся эффектами, и вы просто заворачиваетесь в монаду, после чего доказываете что-то про поведение в этой монаде.
Можно пойти дальше и доказывать, например, независимость количества операций условной функции проверки пароля от того, какая часть пароля совпадает.

worldmind
05.08.2021 10:27эти языки неполны по Тьюрингу, но оказывается, что это нестрашно.
Было бы отлично почитать статейку для далёких от темы о том как оно и почему не страшно, как понимаю речь про тотально функциональные языки
0xd34df00d
05.08.2021 23:28как оно
Вы о том, как там писать код, или о том, как оно так внутри устроено, что всё хорошо и завершимо получается?
почему не страшно
Эмпирические наблюдения. Я ещё не встречался с алгоритмом, который всегда либо завершается, либо выдаёт новую порцию данных за конечное время, и про который невозможно было бы это доказать формально.
Ну, то есть, да, иногда это очень неудобно доказывать, но я бы не сказал, что это прям уж страшно. Неприятно, не более.
worldmind
06.08.2021 06:52Скорее о том как писать код, какие-то примеры того, что трудно реализовывать на тотально функциональном языке и того как это обходится.
0xd34df00d
06.08.2021 23:03+1Я тут что-то писал на тему. Там описано, что делать, когда тайпчекеру неочевидно напрямую (напрямую — это через структурную рекурсию), почему функция завершается.
worldmind
07.08.2021 10:35Единственное о чём жалею - что в вузе не получил правильного матана.
0xd34df00d
07.08.2021 21:49Это, в принципе, можно поправить. Так-то и я в вузе был всего-то приматом, и каких-нибудь матстатов и слупов у меня было порядком, а матлогики и прочих оснований — считайте, толком и не было (семестр семинаров по матлогу на базовой кафедре не считается, это ни о чём).
worldmind
07.08.2021 22:02В теории да, а на практике без шансов, это можно было осилить в студенческие годы, а сейчас только при наличии очень сильной увлечённости, но увлечение моё по сути гуманитарное, да и на него аремени очень мало.
mikhanoid
01.08.2021 11:56+2С точки зрения теории, кстати, применение функции - это тоже эффект. Но о нём всё время забывают.
Тем не менее, всё же полезно разделять код на чистый, который не меняет поддерживаемые программой структуры данных, и тот, который их меняет.
amarao
01.08.2021 12:13Такое сужение определения side effect даёт не очень практичную модель.
Предположим, у вас есть чистая функция, считающая функцию Аккермана. Вызов этой функции на мобильном телефоне (или ноутбуке на батарейке) с достаточно крупными значениями меняет состояние полей в структурах данных или нет? Теория говорит, что нет, практика, что меняет. После "бзз", часа зарядки и последующей загрузки с перезапуском приложения.
mikhanoid
01.08.2021 13:49+2Вы смешиваете понятия, мне кажется, семантики кода и способа его исполнения. Семантика - это интерфейс, описание наблюдаемого поведения. Прагматика - то, как его добиться. Интерфейс с неизменными данными удобен. В реальности, в 95% случаев программист имеет дело с неизменяемыми данными. Интерфейс, построенный на неизменяемых данных позволяет компилятору генерировать гораздо более эффективный код. Например, промежуточное представление в LLVM - это single static assignment, не от балды же так сделано. Просто оптимизировать такой код проще.
Естественно, функция Аккермана компилируется в достаточно эффективный код. Да, теория не описывает севшую батарейку, но и семантика Си её не описывает. Но это не означет, что семантика Си бесполезна, и что бесполезно выделять в коде чистые функции. Это полезно и для производительности. Самая большая боль в компиляции Си-кода это анализ псевдонимов, когда нужно разобраться, куда какие значения пишутся, какие регистры и память можно повторно использовать, а какие - нет.
В Fortran, например, или SISAL, или Rust, или Julia таких проблем нет, поэтому числодробильный код на этих языках получается компилировать в более эффективный машинный код. В Си проблему решить так и не удалось, пришлось вводить модификатор restricted и оставлять всё под ответственность программиста.
У неограниченной мутабельности своя цена.

megahertz
01.08.2021 12:09Последние 10 лет наблюдается огромный хайп вопркг ФП. Фактически, подавляющее большинство проектов где пытаются внедрить ФП пишется на обычных императивных языках в процедурном/структурном стиле, и только малую часть кода действительно можно отнести к ФП. Еще лет 15-20 до этого то-же самое было с ООП. Огромный хайп, но фактически большинство проектов писались в процедурном/структурном стиле с небольшой частью, которую действительно можно было отнести к ООП.
amarao
01.08.2021 12:17+8Я в индустрии немного меньше 20 лет, и хайп вокруг ФП наблюдается всё это время.
Возможно, если придёт дедушка с 40+ лет опыта, то он подтвердит, что хайп с ФП наблюдается ещё со времён lisp-машин.

sshikov
01.08.2021 19:29+2Смотря что считать хайпом. Когда я начинал работать после института, у нас инженеры программировали на фортране. И таких было много. Они делали код для себя, и многие вещи, которые сегодня нас волнуют, вообще не имели значения. При этом мои коллеги, получившие скажем госпремию за расчеты теплозащиты к Бурану, прекрасно понимали, что программирование для них всего-лишь инструмент, причем не самый важный, и в шутку называли себя «программисты от сохи».
Но при этом лисп (в виде скажем reduce) вполне себе существовал, и свои задачи решал успешно. А вот хайп (ну по крайней мере в 80-х годах) — я бы сказал, что скорее нет, чем да. Если и наблюдался — то где-то в другом месте. Когда начался — с ходу не скажу, надо подумать.amarao
01.08.2021 19:54+1Я думаю, разница в индустриальности процесса. Написать программу для рассчётов, на самом деле, можно на компьютере 60ых (они для этого и строились). А вот написать программу, которая интегрируется в окружающий мир (от платёжной системы до своевременного обновления зависимостей у JS'а на сайте) - это же миллионы условностей, многие из которых никогда не становятся отлитыми в бронзе стандартами, т.к. устаревают ещё до начала этого процесса.
Я вот сейчас для компании написал офигенно работающий сервис, который сократил время выполнения весьма часто выполняемой операции с 5 минут до 28 секунд. Он даже прикрыт несколькими интеграционными тестами (т.к. всего секретного соуса там - в правильном решении, когда спать, а когда долбиться). Там даже есть requirements.txt и я сейчас заканчиваю CI/CD под него ваять.
но! Я знаю, что этот код не индустриальный (хоть и работает хорошо). Потому что его нельзя нормально сопровождать, и во многих местах я срезал углы. И код (вместе с тестами) будет выдан профессиональному программисту на рефакторинг.
Ровно так же я после каких-то плейбук программиста (которые вполне работают) делаю их рефакторинг, чтобы сделать их well-engineered.
sshikov
01.08.2021 20:01>Я думаю, разница в индустриальности процесса.
Я об этом в общем-то и говорю. С этой самой индустриальностью было не очень (во всяком случае, то что я наблюдал), как таковой, индустрии программирования в 80-х у нас еще не было. Программирование было — а индустрии нет (ну или поскольку это личный взгляд — то возможно была, но я ее не наблюдал). А за ее пределами — кому интересно ФП? С чего взяться хайпу?

vsh797
01.08.2021 21:15-1Интересно, как изменятся трудозатраты, если, например, контентный сайт или админку писать в ФП стиле? Лично я вообще плохо могу себе представить, как можно избавиться от побочных эффектов, если инъекция зависимостей — де-факто стандарт разбиения на модули во многих ООП проектах.
sergey-gornostaev
01.08.2021 22:23+1Функциональная парадигма не исключается ни DI, ни SOLID, ни других привычных подходов к разработке.
vsh797
01.08.2021 22:44-2Ок, но инжектить тогда надо вручную через аргументы? А если прокидывать нужно далеко? Да и тип прокидываемого сервиса — это скорее часть реализации, а мы по сути добавляем его в интерфейс.
Gorthauer87
01.08.2021 22:52+1Если все на тайпклассах, то можно же любую реализацию подставить, а прокидывание через аргументы, это естественный способ описать архитектуру. Но при этом компоненты все как и положено, будут зависеть от интерфейсов, а не реализаций.
А уж DI в целом, особенно в Java стиле это вообще непонятная со стороны чёрная магия, в результате которой все каким-то образом связывается в готовый код.
vsh797
02.08.2021 21:24Я немного про другое. Допустим у нас есть интерфейс:
interface OrderChecker { public function isActual(Order $order): bool; }В php его реализации могут инжектить через конструктор любое количество дополнительных сервисов. Кому-то для проверки актуальности нужно текущее время, кому-то список пользователей или других заказов и т.п. А что ФП говорит по этому поводу?
P.s. И по поводу ручного прокидывания зависимостей на дальние дистанции все еще непонятно. Неужели в ФП не возникает такая проблема? В каких-то ситуациях, видел, чуть ли не вручную созданные контейнеры прокидывают. По сравнению с этим "черная магия" php и java — очень простая, наглядная и удобная штука.
Gorthauer87
02.08.2021 21:28+4Так это просто функция, просто в нужное место подставляем нужную функцию с этой же сигнатурой и все. Проблема прекрасно решается через композицию функций, комбинаторы, тайпклассы и т.д. Инжектить в ООП стиле вовсе необязательно, да и это коряво, на самом деле.
mayorovp
02.08.2021 21:42+1PHP по этому поводу говорит следующее: интерфейс OrderChecker выглядит как чистый, поэтому его можно использовать в ФП без изменений.
Вот с реализацией нужно будет аккуратнее, потому что получение текущей даты-времени — "грязная" операция, и её лучше бы внедрить как зависимость (в смысле, внедрить текущую дату, а не процесс её получения).
И да, зависимости — часть реализации, а не интерфейса, и внедряться они будут также в реализацию.
mayorovp
01.08.2021 23:41Ок, но инжектить тогда надо вручную через аргументы?
В нормальном DI инъекция тоже через аргументы происходит.
Да и тип прокидываемого сервиса — это скорее часть реализации, а мы по сути добавляем его в интерфейс.
А что вам мешает указывать не конкретный тип, а интерфейс/тайпкласс/трейт/шейп?
sergey-gornostaev
01.08.2021 23:44Например программисты на Play используют для этого cake pattern, а борцы за чистоту говорят, что это не true и предлагают взамен reader monad. Есть варианты.
Gorthauer87
01.08.2021 22:47+3Так иньекция зависимостей это способ сделать композицию, что на ФП языках очень даже естественно само решается. Не обязательно делать именно так как принято в ООП языках, главное решать задачу.

eldog
02.08.2021 13:49-2Писал в своё время, после того, как поиграл немного с ФП:
Функциональное программирование требует отсутствия побочных эффектов (side effects). Собственно, это не является корневым требованием, корневое это ссылочная прозрачность (referential transparency). Но отсутствие побочных эффектов является необходимым следствием. Возможно даже, необходимым и достаточным, тут нужно подумать-почитать. Разумеется, полностью избавиться от побочных эффектов невозможно. Потому что побочные эффекты это то, ради чего мы программируем. Изображение на дисплее, звук, запись в файл, передача данных по сети - всё это побочные эффекты. Программа без них была бы вещью в себе, не взаимодействующей с внешним миром. И в этом, как мне представляется, проблема функционального программирования. Оно требует извращённого выверта мозга, при котором ты перестаёшь видеть свою цель и считать её целью. А в самом конце приходится идти на лицемерный финт, нарушая красоту и благолепие, потому что мы, святые люди, всё ещё не вполне в нирване и не можем отринуть до конца потребности грешного тела. Альбигойская ересь какая-то: это ведь они считали, что духовный мир создан Богом, а материальный - Сатаной.
i360u
>> Оказывается, программирование с использованием математических функций значительно упрощает нашу работу.
ОЧЕНЬ спорное заявление. Я лично встречал кучу кейсов, когда все ровно наоборот. Тот-же Redux - отличный пример. ФП - это хорошо только там, где это уместно и без фанатизма. Фанаты ФП - одни из самых вредных людей на проекте.
mikhanoid
Почему спорное? Оно неверное. Программисты програмиируют процессы (математическое понятие, CSP или pi-исчисление), физические, взаимодействующие сущности, которые нельзя реализовать функциями. Смоделировать функциями можно, но тогда нужно рассматривать все процессы во вселенной одновременно, что при программировании, мягко говоря, проблематично.
Иногда эти процессы действительно работают как функции, но часто - нет. Например, пользователь программы - это внешний процесс, с ним нельзя работать, как с функцией. Стремление упихать поведение процессов в функциональную семантику может быть себе дороже, потому что приводит, как раз, к необходимости рассматривать всю программу со всем миром, как единое целое. Трансформеры монад появляются, которые усложняют код и снижают его эффективность. Или системы эффектов, которые являются просто замаскированными нелокальными выходами (за что боролись тогда?). И прочие такие всякие дела.
Опять же, программирование с процессами сразу экспоненциально увеличивает сложность кода, поэтому и в эту сторону фанатизм не уместен. По идее, нужно уметь аккуратно без фанатизма работать и с процессами, и с функциями, чтобы код оставался адекватным.
i360u
Спорное оно потому, что найдется куча желающих об этом поспорить :)
Ну и, стоит признать, что есть случаи, когда чистые функции действительно упрощают жизнь.
mikhanoid
Злоупотребление процессами увеличивает <b>поведенческую</b> сложность кода.
GospodinKolhoznik
Пользователя достаточно 60 раз в секунду опрашивать какие кнопки он нажал, и куды тыкнул мышкой. А все остальное время программулина работает сама по себе полностью независимо от внешнего мира. 1/60 секунды это почти вечность для программы, во время которых она представляет из себя чистую детерминированную функцию f(нажатые_клавиши, старое_состояние) -> новое_состояние.
А уж если пользователь у программулины не один, так в конкурентном программировании вообще у фп сплошные преимущества перед императивным.
mikhanoid
Время - это тоже не функциональная концепция. Для функций времени нет. А из-за того, что процессор в любой момент времени может выхватить прерывание, его следующее состояние не определяется его текущим состоянием полностью. Добавьте сюда память, в которую по технологичнским соображениям пишут многие устройства. Функциональную модель всего этого хозяйства постороить теоретически можно, но она будет жутко громоздкой.
Так что, в любом случае, придётся говорить о процессах. Может быть, на языке монад, но когда у вас не один пользователь, это слишком топорный язык: монады тензорно не умножаются, придётся костылить нечто дополнительное.
Опять же, процессы не обязательно подразумевают изменение данных. Смотрите, например, Erlang. Переменная часть вычисления - это сам процесс и есть.
0xd34df00d
Нууу, я тут в свободное время ковыряю формальные рассуждения о блокчейнах, и рассуждать об иммутабельном utxo сильно проще, чем о мутабельном в стиле тезоса. Хотя пользователей там сильно больше одного, время есть, и так далее.
0xd34df00d
Это во многом вкусовщина. Я сам не люблю трансформеры, но знаю людей, которые любят.
Моя основная претензия к ним — большинство трансформеров не коммутирует, и ReaderT поверх MaybeT — не то же самое, что MaybeT поверх ReaderT. Но это просто вопрос того, что в одном месте надо быть внимательным (да и при невнимательности там типы не сойдутся).
Это не так. ghc очень неплохо оптимизирует и разворачивает mtl/transformers (по крайней мере, в моей практике).
А вообще есть такие прикольные штуки, как capability.
За то, чтобы в типах все было видно.
Vlad_Murashchenko
Я бы поспорил насчет того, что ФП в redux не уместно. Я считаю, что переход из одного состояния в другое состояние является чистым вычислением по своей природе. И самым очевидным выражением перехода будет:
(state, event) => stateПо этому мне очень нравятся редьюсеры.
Какими бы сложными небыли эти вычисления чистые функции легко масштабируются. Код между ними легко переиспользовать. Ненужные детали легко скрыть в абстракции и положить в другой файл.
Мне в работе встречались сложные переходы не раз (особенно когда я работал над видео редактором) и редьюсеры здесь были как нельзя кстати. Ну а пляски с иммутабельностью легко исправляются в помощью immer. Redux toolkit позволяет сгладить все моменты за которое redux критикуют. Подобные инструменты были и раньше, но качество было хуже и поддержки TS кажется нигде небыло.
i360u
Прежде чем говорить о самом redux, следует заметить, что расходы на аллокацию и очистку памяти при копировании иммутабельных объектов - вполне осязаемые (особенно для жирных состояний в сложных приложениях). С всей спецификой работы с памятью в JS, мы должны понимать, чем мы за это платим. Далее - вы просто подтверждаете мои слова: если для работы с какой-либо штуковиной, выполняющей довольно простую роль, вам требуется еще куча дополнительных либ и зависимостей - с ней что-то явно не так. Меня всегда умиляет, когда в разговорах о redux начинается вот этот этап перечисления модных названий. Вы серьезно? Если ваша либа такая простая и удобная, зачем ей куча разных оберток, без которых ее использование - сплошная боль? А все ваши перечисленные удобства легко достижимы и при совершенно других подходах.
Vlad_Murashchenko
Я согласен, Redux - это очень низкоуровневый инструмент в несколько сток кода, который реализует голую концепцию и оставляет все остальное на усмотрение тех, кто его использует. Весь его код можно изучить за 30 минут.
Он не заботится о DX при работе с ним из коробки и не диктует четких правил за пределами концепции. Такая философия. Можно очень долго спорить о том, правильная она или нет. Тут все очень сильно зависит от того, кому в руки попадет этот инструмент.
Посмотрите, например, на
useReducerиз Реакт. Он ведь работает точно так же. Реакт ничего не предоставляет для удобной работы с иммутабельностью. Почему? Да потому, что это не его зона ответсвенности. Эта ответственность лежит на том, кто использует Реакт.Это не правильно говорить, что инструмент плохой только потому, что он не сделал абсолютно всю работу за нас. Есть другие инструменты которые помогут. На мой взгляд, лучше много маленьких но хороших, чем один огромный посредственный иструмен.
А насчет легко "достижимы и при совершенно других подходах", вот код, покажите мне как достигнуть такого уровня декларативности, с помощью других подходов.
https://codesandbox.io/s/runtime-sun-1qhtw?file=/src/pages/Game/gameSlice.js
Просто форкните и перепишите на MobX или на то, что вам нравится.
PS. если codesandbox по какой-то причине упал, потрогайте какой-то код, это баг на codesandbox. Раньше замечал за ним такое
i360u
https://holiday-js.web.app/?state - вот пример другого подхода. Без иммутабельности. Работает быстрее, весит меньше. Проще некуда. Реакция на асинхронные изменения происходит синхронно, а потому, при использовании, нет ни гонок ни несогласованных состояний. Уровень декларативности - ничем не уступает.
Vlad_Murashchenko
Твои аргументы слишком абстрактны по этому не убедили. Буду благодарен, если ты форкнишь и перепишешь с использованием этой библиотеки. Вот тогда я действительно смогу оценить. К тому же это какой-то фреймворк который я никогда не видел. Я не уверен, что можно найти работу на которой его используют
i360u
Простите, но я не настолько желаю Вас в чем-то убедить, чтобы бросаться что-то форкать и переписывать. Пожалуйста, оставайтесь при своем мнении.
Vlad_Murashchenko
Понимаю Вас. Однако, если не готовы доказать это на деле, не стоит бросаться громкими фразами вроде:
Фанаты ФП - одни из самых вредных людей на проекте.
А доказать что парадигма X лучше парадигмы Y в случае Z, можно лишь переписав код с одной парадигмы на другую без изменений в поведении программы и проанализировав результат.
Позвольте людям писать хороший код на парадигме, которую они любят, или докажите, что их код плохой.
PS. да я знаю, я отношусь к этому слишком серьезно