Эта статья является переводом материала «Tackling Complexity in CQRS».
Шаблон CQRS может творить чудеса: он может максимизировать масштабируемость, производительность, безопасность и даже «превзойти» теорему CAP. Тем не менее, например, в своей статье о CQRS Мартин Фаулер утверждает, что шаблон следует применять умеренно и даже осторожно:
«...для большинства систем CQRS добавляет риски»
«...вы должны быть очень осторожны при использовании CQRS»
«Итак, хотя CQRS - это шаблон, который хорошо иметь в наборе инструментов, имейте в виду, что его сложно применять правильно, и вы можете легко пропустить важные части, если неправильно использовать его.»
С моей точки зрения, сложность, вызванная CQRS, в значительной степени случайна, и поэтому ее можно избежать. Чтобы проиллюстрировать свою точку зрения, я хочу обсудить цель CQRS, а затем проанализировать 3 распространенных источника случайной сложности в системах, использующие CQRS.
Цель CQRS
Цель CQRS - обеспечить представление одних и тех же данных с использованием нескольких моделей. Ни масштабируемость, ни доступность, ни безопасность, ни производительность. Одни и те же данные в нескольких моделях. Вот и все. Остальное - это побочные продукты. Не верите мне? Послушайте выступление Грега Янга на конференции DDDEU2016, где он говорит, что CQRS был изобретен для поддержки реализации Event Sourcing. И, как вы, наверное, знаете, модель Event Sourcing хороша для записи данных, но ужасна для чтения. Вот почему ему тогда понадобился CQRS: для представления одних и тех же данных в нескольких моделях.
Как CQRS достигает этой цели? Убедившись, что только одна модель служит источником истины (the source of truth), и все изменения относятся только к этой модели. Давайте посмотрим, как это понимание может помочь нам справиться с некоторыми сложностями.
Ловушка № 1: Односторонние команды или чрезмерное разделение
Все известные мне определения CQRS следуют следующему шаблону:
CQRS основан на принципе CQS, который гласит, что операции следует разделить на две группы: команды, которые изменяют данные, и запросы, возвращающие данные. Как только мы поднимем этот принцип на архитектурный уровень, мы получим систему с вариантами использования, разделенными на те же две группы: команды и запросы. Каждый вариант использования может быть командой или запросом, но не обоими сразу.
Как только варианты использования разделены, мы получаем довольно много преимуществ: несколько моделей, разные механизмы сохранения, независимая масштабируемость и т. д.
Вы чувствуете, что здесь что-то не так? Проблема тонкая: все определения CQRS обычно начинаются с решения - разделения, и только после этого определяют проблему - несколько моделей. Это вызывает слишком большое рвение в отношении разделения: доходит до определения команд как односторонних, когда вы получаете ответ Ack/Nack от сервера, но вам нужно опросить некоторое хранилище модели чтения для фактического результата выполнения команды. Другими словами, появились большие сложности.
Решение: ослабить разделение
Давайте сделаем шаг назад и пересмотрим разделение. Мы видели, что, согласно CQRS, для представления одних и тех же данных в нескольких моделях сценарий использования может либо записывать, либо читать данные. Совершенно очевидно, что модель чтения ничего не должна обновлять, иначе мы получим несколько источников истины. Но стоит ли вам действительно оставлять свои команды не возвращающими результат выполнения?
Не совсем. Не нарушая никаких принципов, команда может безопасно возвращать следующие данные:
Результат выполнения - успех/неудача;
Сообщения об ошибках или ошибки валидации в случае сбоя;
Номер новой версии агрегата, в случае успеха;
Эта информация значительно улучшит пользовательский интерфейс вашей системы, потому что:
Вам не нужно опрашивать внешний источник для получения результата выполнения команды, он у вас есть сразу. Становится тривиальным проверять команды и возвращать сообщения об ошибках; и
если вы хотите обновить отображаемые данные, вы можете использовать новую версию агрегата, чтобы определить, отражает ли модель представления выполненную команду или нет. Больше не нужно отображать устаревшие данные.
Говоря о данных, можем ли мы немного ослабить разделение? Во многих случаях любые данные, содержащиеся внутри затронутого агрегата, могут быть возвращены как часть результата выполнения команды. Однако здесь есть небольшой нюанс: убедитесь, что возвращаемые данные можно будет запросить позже из модели чтения. В противном случае существует небольшой риск потери данных, если ответ не доходит до клиента.
Вы можете увидеть пример такого подхода в блоге Дэниела Уиттакера, где он обсуждает использование объектов выполнения команд для их проверки. Кроме того, в этом примере вы можете увидеть объект результата выполнения команды, который я использую в C #.
Ловушка № 2: Event sourcing
По историческим причинам CQRS тесно связан с шаблоном Event Sourcing. В конце концов, CQRS был изобретен, чтобы сделать возможным Event Sourcing. Но давайте переоценим связь между двумя паттернами.
Как я уже говорил ранее, цель CQRS - обеспечить представление одних и тех же данных в разных моделях. Если вы работаете с Event Sourced Domain Model, вам абсолютно необходим CQRS, чтобы иметь возможность выполнять запросы. Однако есть много других вполне веских причин для реализации CQRS, не связанных с Event Sourcing:
Ваша система должна отображать свои сущности в разных моделях представления.
Вы должны поддерживать разные модели запросов (поиск, графы, документы и т. д.).
Разница между записью и чтением сильно различается, и вы хотите масштабировать их независимо.
Вы ненавидите ORM.
Означает ли это, что во всех этих случаях вам нужен Event Sourcing? Если вы это сделаете, вы окажетесь в ловушке сложности. Event Sourcing - это способ моделирования бизнес-домена. Не просто способ, а, вероятно, самый сложный способ. Следовательно, вам следует использовать Event Sourcing, если и только если ваш бизнес-домен это оправдывает. Давайте посмотрим, как вы можете реализовать CQRS в других случаях.
Решение: CQRS != Event sourcing
Нас научили создавать проекции, написав обработчики событий. Но как реализовать проекции без событий? Есть еще один способ, и я называю его «Проекции на основе состояния» (State Based Projections). Эта тема заслуживает отдельного поста, но я кратко опишу три способа реализации «проекции на основе состояния»:
Первый способ: Флаг «Is Dirty»
Вы можете пометить объект, который был обновлен, с помощью флага IsDirty (выставив его в true), и реализовать механизм проецирования, который будет запрашивать грязные экземпляры и проецировать обновленные данные в отдельные модели.
Второй способ: catch-up
В реляционных базах данных вы можете отслеживать фиксации на уровне таблицы. Например, в SQL Server для этого есть встроенный механизм - столбец «версия строки». Подобная функциональность может быть реализована и для других реляционных баз данных. Механизм проекции будет запрашивать обновленные строки способом, подобным подписке, и проецировать обновленные данные.
Третий способ: представления БД
Если вы используете реляционную базу данных и все, что вам нужно, это представить ее данные в различных моделях, представления БД будут отлично работать. Да, в БД может быть реализована совершенно валидная система CQRS. Возможно, наименее привлекательное решение, но оно не только работает, но и естественным образом следует шаблону CQRS.
Эти способы проецирования моделей могут быть не очень крутыми, но они работают. Я видел довольно много проектов, в которых они были задействованы, и они работали отлично, без неоправданного погружения в сложности, связанные с Event Sourcing.
Подождите, я предлагал любой ценой игнорировать Event Sourcing, потому что это сложно? Конечно нет! Event Sourcing - один из самых важных инструментов. Но, как и любой другой инструмент, используйте его в своем контексте - бизнес-доменах, которые приносят пользу для бизнеса: смысловое ядро (core subdomain). С другой стороны, неспециализированные (generic) и служебные (supporting) поддомены, которые достаточно просты для реализации с помощью Transaction Script или шаблонов Active Record, по-прежнему могут извлечь выгоду из CQRS. В таком случае используйте простейший инструмент, который выполнит эту работу, и извлеките выгоду из CQRS с помощью State Based Projections.
Ловушка №3: слишком много хорошего
Шумиха вокруг микросервисов привлекла большое внимание к CQRS: если у вас есть набор независимых служб, которым необходимо запрашивать данные друг у друга, CQRS является общим решением. Тем не менее, я видел, как этот подход создает чудовищные диаграммы потоков данных служб, проецирующих между собой большие объемы данных.

Это не всегда плохо, но во многих случаях это может быть сигналом к тому, чтобы сделать шаг назад и пересмотреть свою стратегию декомпозиции. Скорее всего, ваши сервисы слишком детализированы и не отражают границ бизнес-домена. В этом случае вы можете значительно упростить свою архитектуру, перенастроив границы сервисов с соответствующими бизнес-доменами.
Резюме
Я хочу подытожить все это схемой CQRS:
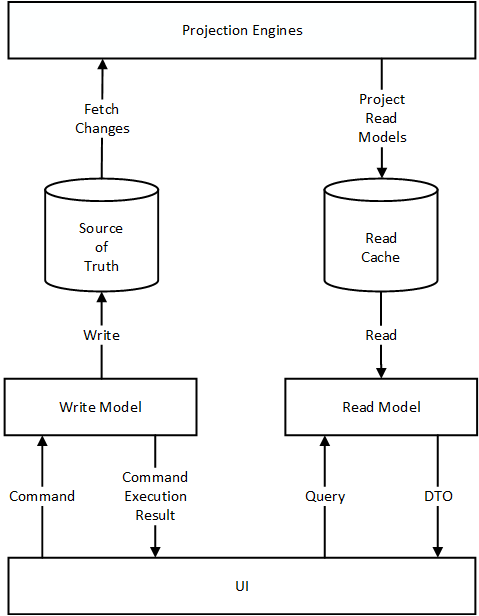
Эта диаграмма отличается от других диаграмм, которые вы можете найти в Интернете:

Это шаблон CQRS, как я его вижу и реализую. Команды имеют ответы. Механизм проецирования определяется абстрактно, без каких-либо деталей реализации. Внутри он может быть основан на событиях, или на состоянии, или даже на представлении БД. И, наконец, нет и намека на Event Sourcing. Моделируйте бизнес-логику системы в соответствии с требованиями бизнес-домена: Active Record, Domain Model или Event Sourced Domain Model.
Как и любой правильно применяемый инструмент, CQRS должен уменьшать сложность, а не вызывать ее. Если сложность вашей архитектуры растет, вы делаете что-то не так.
AlexSpaizNet
Я люблю CQRS. В нашем легаси, как один из шагов в сторону мискросервисов, DDD, евентов + трушный CQRS, мы используем CDC. В нашем случае это Mongo + Kafka connector. И сабскрайберы подписываются на изменения определенных коллекций, и уже создают у себя нуные им вьюшки, в подходящщей базе данных и в подходящей структуре.
Тьфу тьфу работает стабильно и позволяет сделать анкаплинг сервисов и получить реальный профит.
Но нужно заранее думать о том как делать рикавери если что-то пошло не так. И если все делать правильно - рикавери сводится к рисету оффсета сабскрайбера на топик.
PrinceKorwin
CDC делаете через Debezium?
Как решаете ситуацию когда мастер-базу восстанавливаете из бекапа?
AlexSpaizNet
На сколько я знаю, мы делаем не через дебезиум, а через стандартный коннектор - https://docs.mongodb.com/kafka-connector/current/
Этим уже девопсы занимаютсяу нас.
Насчет восстановления базы - интересный вопрос. Вряд ли тут есть генерное решение. Но в принципе можно к этому относиться как частному случаю ресета оффсета опредееленного консьюмера.
Если сама синхронизация очень тупая, в виде простых идемпотентных апсертов на стороне сабскрайберов, то все должно работать out of the box.
Если же вьюшки строятся сложнее (например мерж нескольких стримов или обогащение евентов синхронно (что не очень хорошо) в консьюмере, тут уже нужно конкретно по ситуации смотреть. Возможно что-то умнее придумать при помощи idempotencyId, timestamps, маппинга оффсета на стороне сабскрайбера с данными чтобы и написание умного рикавери процесса.
Есть конечно нюансы. Например в нашем случае используются топики, где храняться несколько месседжей на определенный _id (зависит от настроек топика кафки) и нужно иметь ввиду что когда будет идти восстановление, то в какой-то промежуток времени мы можем иметь во вьюшке не самые последние данные из тех что мы имеем.
Насколько я знаю, можно настроить топик хранить только последнюю копию документа монги.
PrinceKorwin
Там много интересного всплывает. Например то, что нужно кататывать дельты в разных форматах (если модель данных менялась со временем).
И простой CQRS становится не очень простым :)
AlexSpaizNet
Да, главное это понимать. Happy Flow везде простой, а потом начинается...
Если back compatibility не предусмотрено, то танцы с бубном обеспечены.