Если у тебя есть целевая переменная и ты в отчаянии не знаешь, что с ней делать, и потерял всякий покой, потому что метрика не растет, загляни сюда, тебе может понравится...
Постановка задачи
Дан набор наблюдений вида , где
т.е. x,y в нашем случае просто числа, рассматриваем одномерную регрессию с одним параметром. По этому набору мы хотим построить функцию
, которая по заданному
вычисляет значение
. Предпологается, что
- целевая переменная связанна с переменной
таким способом:
где - случайная величина, имеющая нормальное распределение с параметрам
,
- неизвестный коэффициент, который надо оценить из данных. Для упрощения будем считать, чт
, поэтому
. Так же считаем, что все наблюдения в выборке независимы.
Решение задачи
Известно, что если b - это число, а - случайная величина с нормальным распределением
, то сумма
есть так же случайная величина с распределением
, т.е. прибавляя константу к случайной величине мы сдвигаем это распределение. Т.к.
, то
- случайная величина с нормальным распределением
, а плотность распределения будет иметь вид:
Поскольку в нашей выборке есть, то мы хотели бы так подобрать параметр w, чтобы вероятность увидеть именно такую выборку как у нас была бы максимальной (MLE). Поскольку y - непрерывная случайная величина, то максимизировать будем не вероятность, а плотность. Совместная плотность нашей выборки есть произведение плотностей каждой
:
Обозначим это выражение как , которое мы будем рассматривать относительно параметра w.
- называется функцией правдоподобия и ее мы будем максимизировать по параметру w. Теперь мы перемножаем все n слагаемых и упрощаем наше выражение, получив следующее:
Мы можем убрать константу, поскольку это никак не повлияет на максимизацию, а так же взять логарифм натуральный от
, поскольку логарифм это монотонная функция и она так же не повлияет на результаты, но выражение станет чуть приятнее:
Множитель перед суммой так же можем выбросить - не влияет на поиск оптимальных параметров и получим такую задачу - найти такое значение параметра w, которое максимизирует нашу функцию, или кратко:
В контексте нашей темы мы можем сделать следующие полезные выводы:
В нашей модели каждое значение целевой переменной
получено из нормального распределения. Но ни откуда не следует, что построив гистограмму для
она обязательно окажется нормальной мы увидим это дальше в примерах.
В модели не подразумевается, что все
будут различны, а на практике часто так и происходит, что одному
, соответствует сразу несколько
, но гистограмма, построенная на
обязанна с точки зрения нашей модели иметь нормальное распределение.
Далее можем пытаться решить задачу аналитически и найти производную и приравнять к нулю, использовать градиентный спуск или записать функцию правдоподобия в виде функции на python и передать оптимизатору из scipy. Я выбрал последнее и получил:
Настоящий коэффициент: 28.301, r2_score: 0.989
Коэффициент полученный MLE: 28.273, r2_score: 0.989
Коэффициент полученный регрессией из sklearn: 28.274, r2_score: 0.989
Данные генерились с помощью sklearn-функции make_regression. Видим, что коэффициент, полученный методом максимального правдоподобия совпадает либо незначительно отклоняется, если запускать с другим seed, или без него, с коэффициентом из sklearn LinearRegression, и равен реальному коэф.
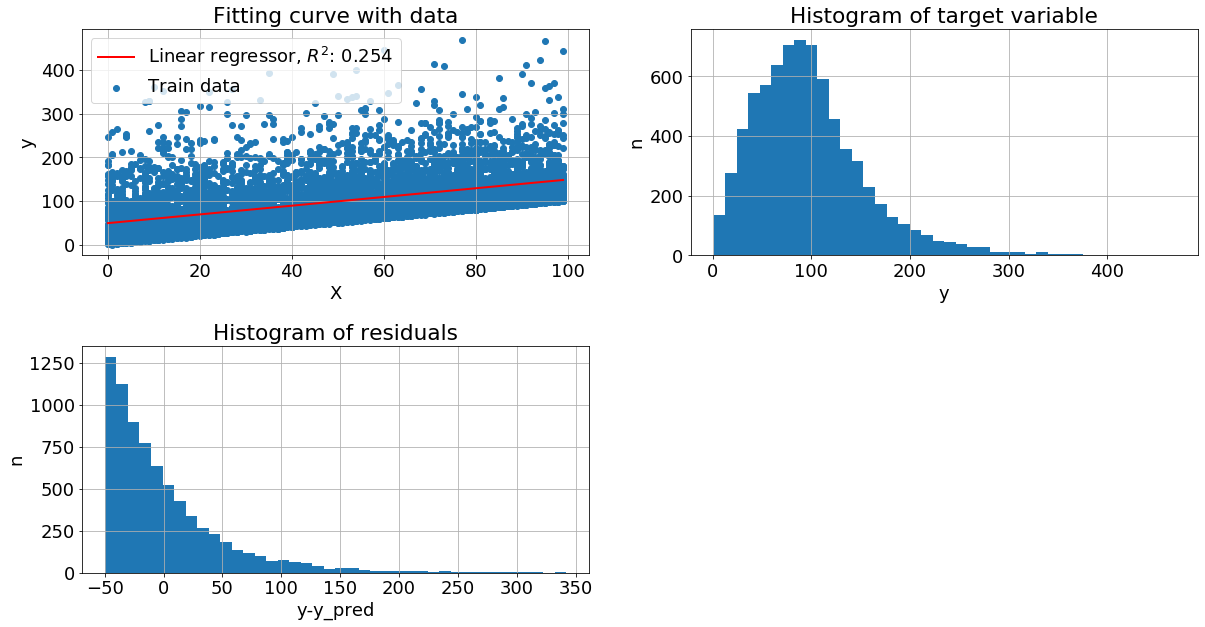
Рассмотрим графики:
Левый верхний - изображена диаграмма рассеяния обучающей выборки и построена линия линейной регрессии
Правый верхний - построена гистограмма распределения целевой переменной, просто plt.hist(y)
Левый нижний - вычислили разность между целевой переменной и прогнозом регресии, далее построили гистограмму остатков plt.hist(y-y_pred)
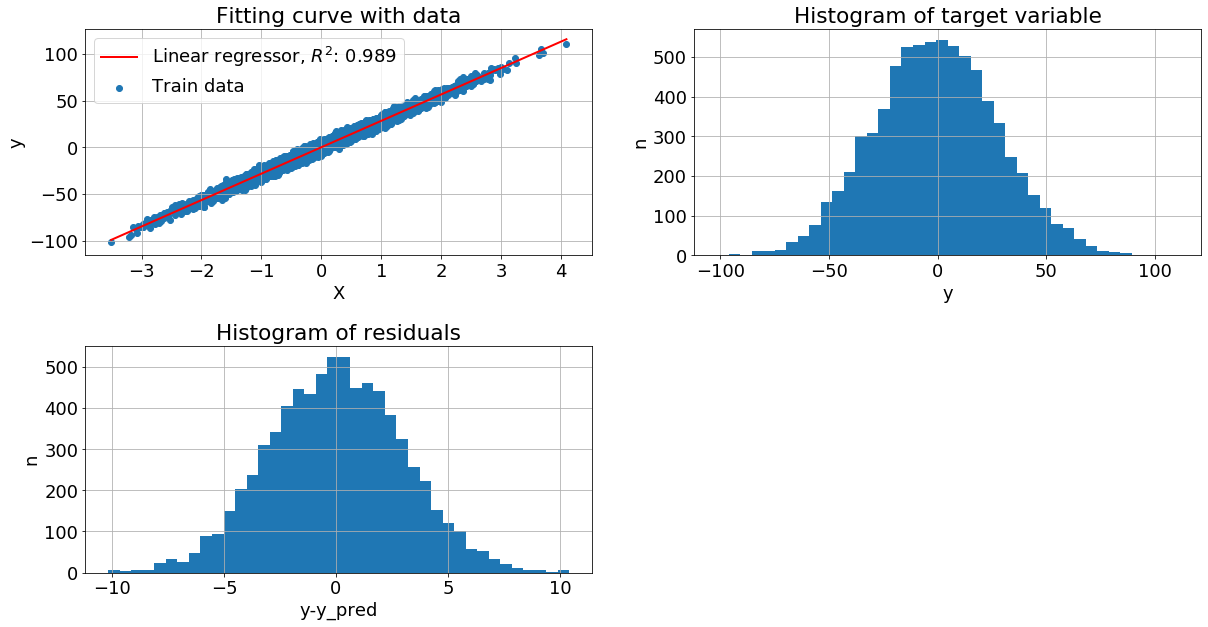
Оценивая "на глаз" распределение как целевой переменной, так и остатков видим, что они близко к нормальному. Теперь рассмотрим другие механизмы порождения данных, не только с нормальным шумом и с более сложной зависимостью y от x.
Различные модели порождения данных
Нормальное распределение целевой переменной. Пусть x - случайное целое число из отрезка [0, 99], а y = x + N(0,1), где N(0,1) - нормальный шум с нулевым средним и стандартным отклонением равным 1.
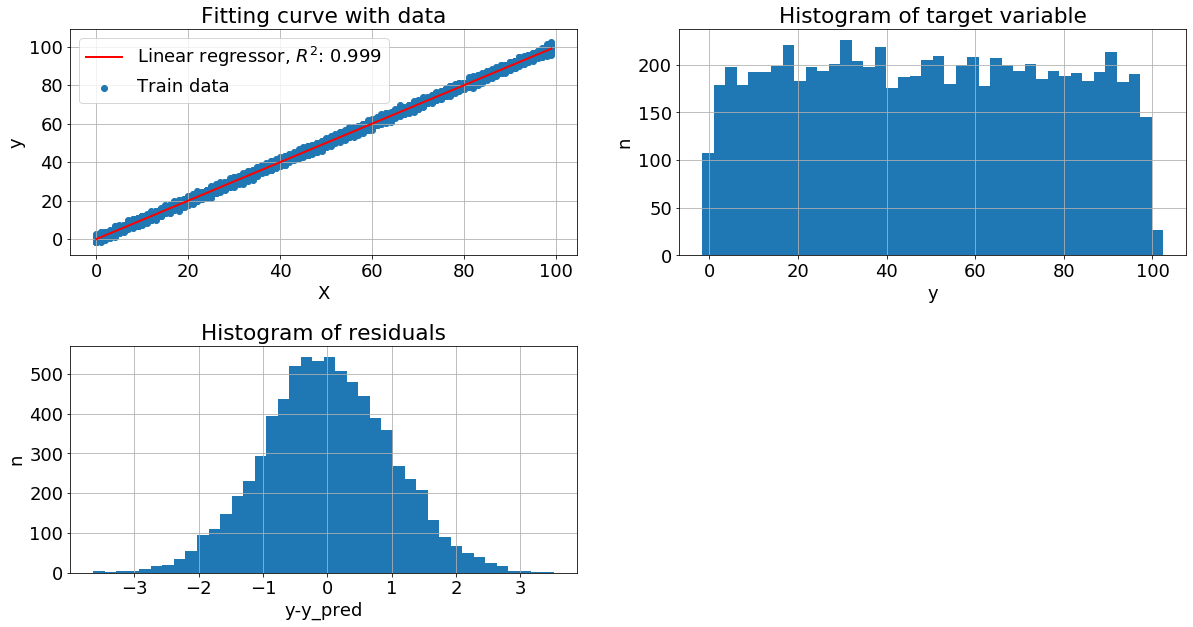
Видим, что у нас очень хорошая метрика качества на тестовых данных при этом целевая переменная более близка к равномерному распределению, чем к нормальному. А вот распределение остатков близко к нормальному.
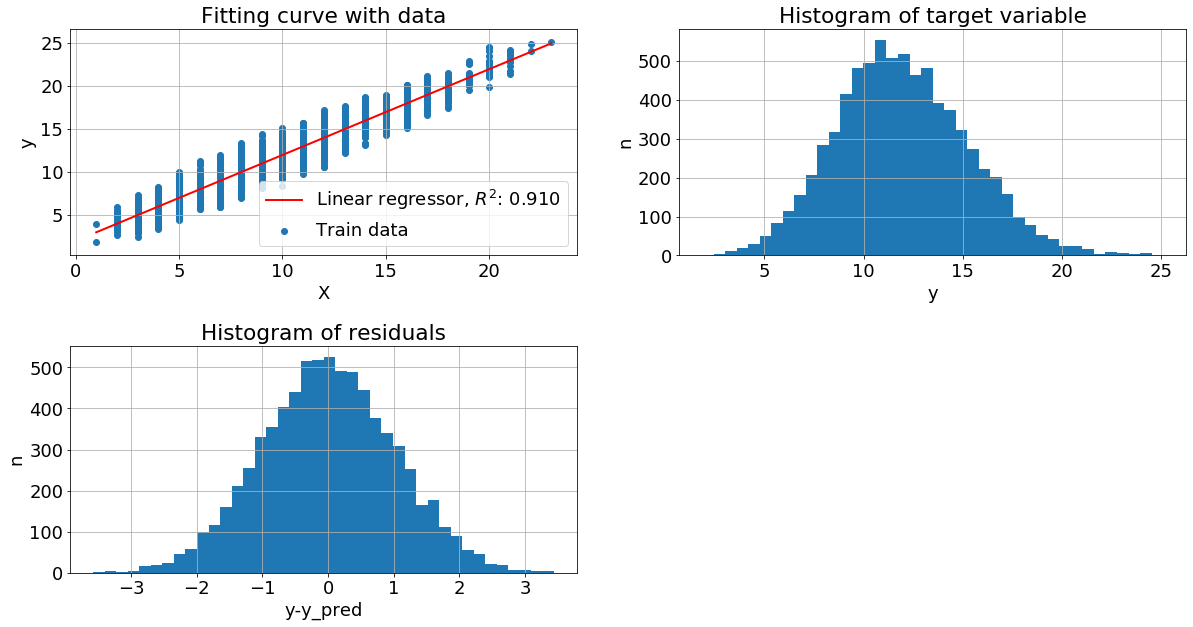
Признак с пуассоновским распределением. Если признак x имеет пуссоновское распределение, а y = x + N(2,1), то распределение целевой переменной близко к нормальному, хотя и немножко смещенно, как и распределение остатков.
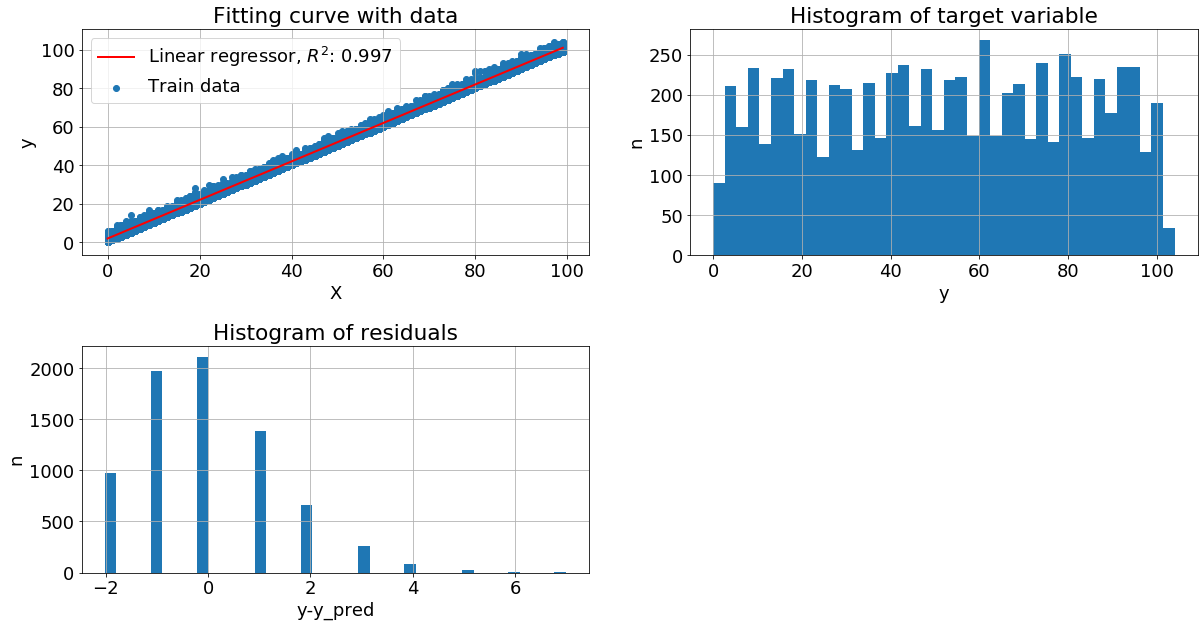
Целевая переменная с пуассоновским шумом. В следующем примере вместо гауссовского шума, мы добавим пуссоновский, при этом гистограмма остатков имеет смещенное распределение с длинным правым хвостом, но метрика качества высока. Можно объяснить это тем, что хвост имеет низкую вероятность и малое смещение не существенно для модели.
Целевая переменная зависит от признака по экспоненциальному закону. Пришло время существенно подпортить данные, пусть теперь y = exp(x+N(0,1)). Диаграмма остатков сильно смещена, метрика качества упала вниз.

Чтобы исправить ситуацию, можем прологарифмировать y и улучшить метрику:
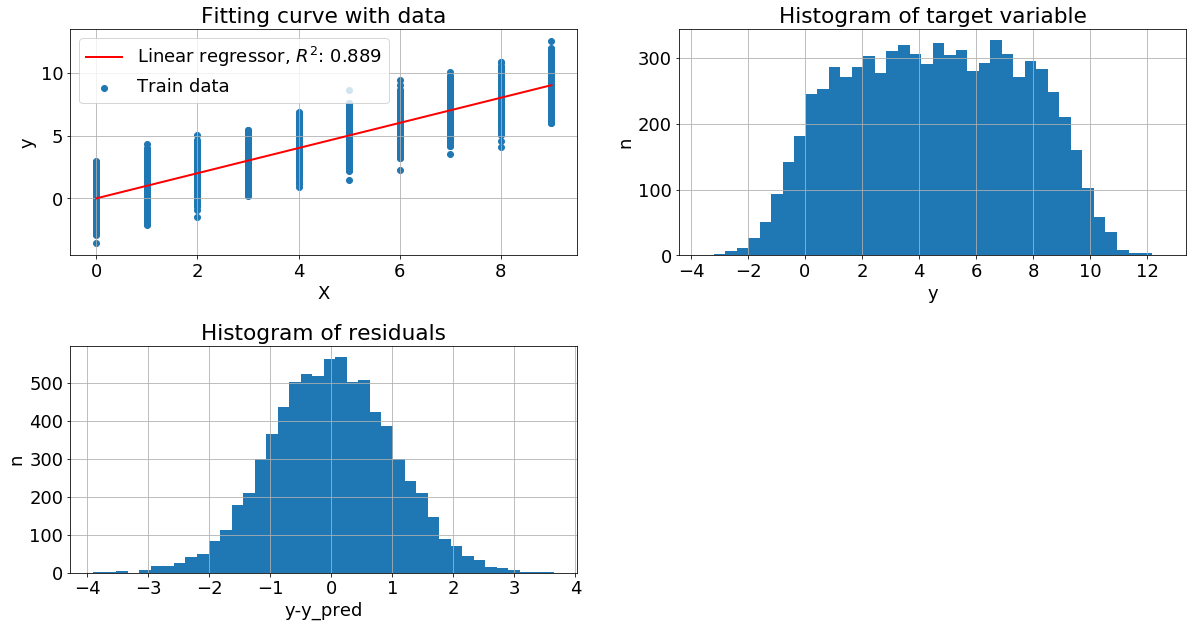
Признак имеет логнормальное распределение. Целевая переменная имеет вид y=x+N(0,10). В этом примере видим хорошее качество, но распределение целевой переменной сильно смещенно влево.
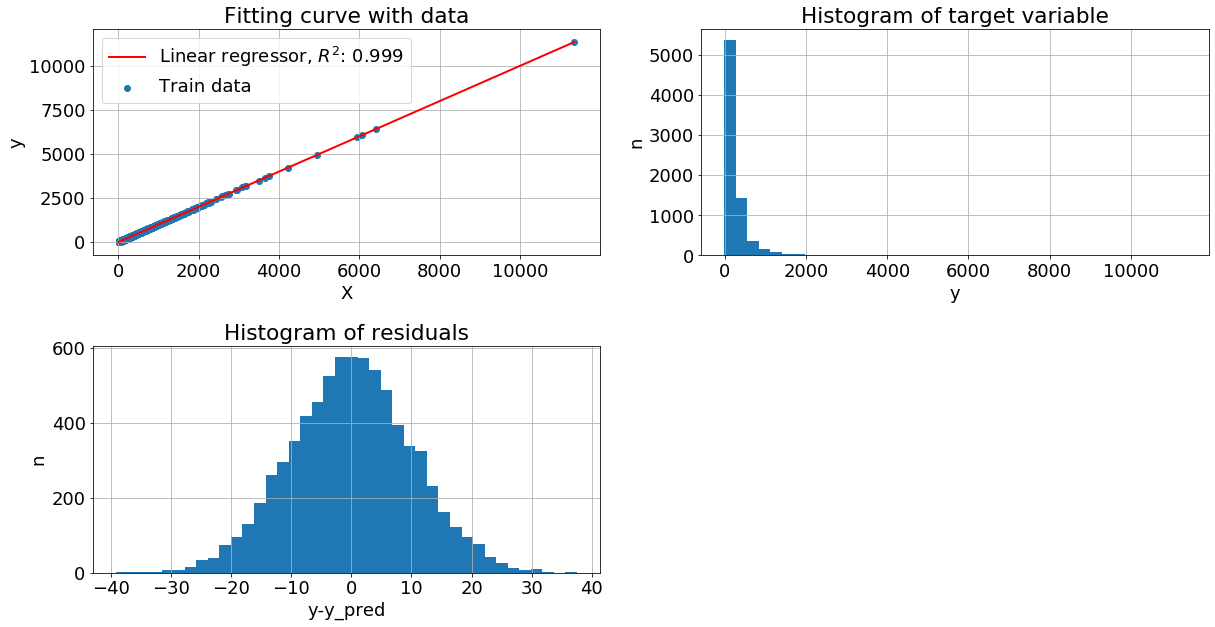
Целевая переменная распределена нормально, но с обратным средним. Здесь

А теперь прологарифмируем y и видим, что метрика качества выросла, а остатки приблизились к нормальному распределению:
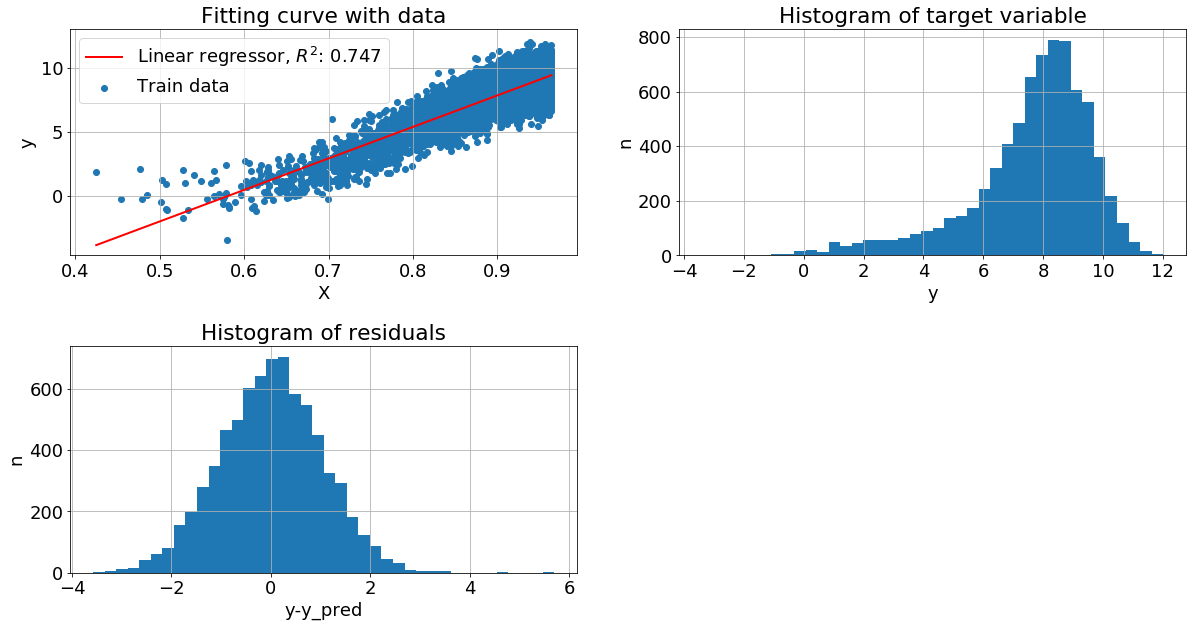
К целевой переменной прибавили Гамма-шум. Без преобразований метрика показывает не очень хорошее качество:
После преобразований метрика увеличилась на 34%:

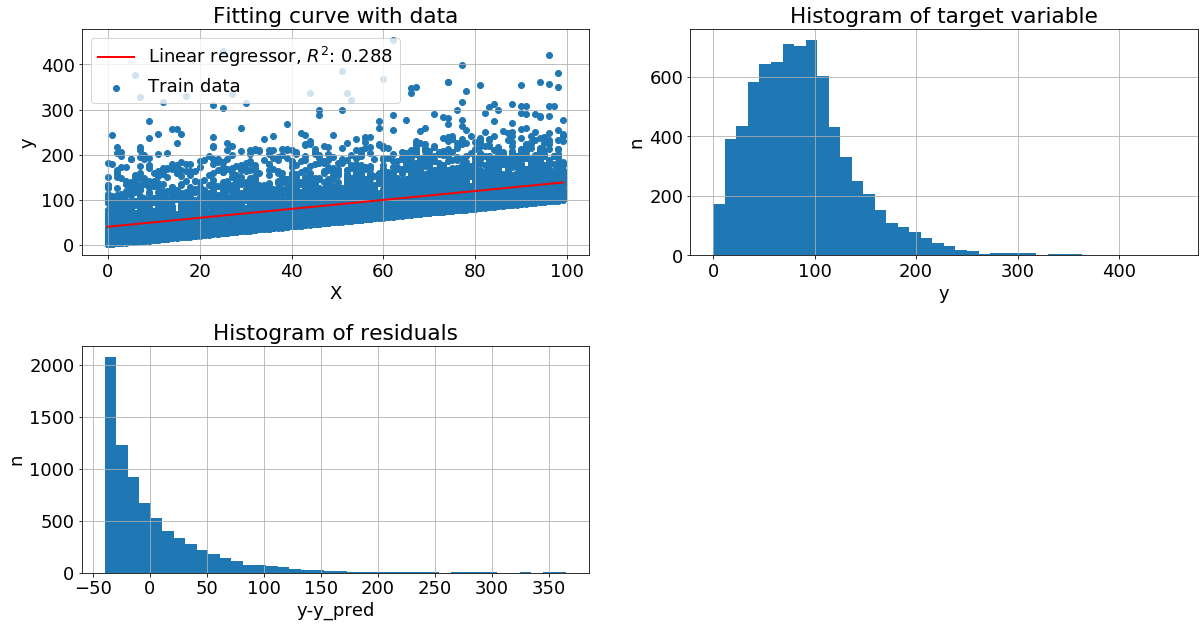
У целевой переменной экспоненциальный шум. Без преобразований:
После преобразований метрика увеличилась:

Связь с рядами Тейлора
Мы видели, что преобразование целевой переменной работает хорошо, когда оно приводит к нормальному распределению в остатках или же является обратной функцией (если y=exp(1+x), то log(y) = 1+x). Можно ли как-то еще понять, какая функциональная зависимость есть между y и x?
Рассмотрим такую зависимость , без шума. Если мы добавим еще столбцы со степенями исходного признака:
и передадим эти данные на вход линейной регрессии, то получим такие коэффициенты:
[5. 10. 10. 5. 1.]
Это не что иное, как коэффициенты соответствующего ряда Тейлора в данном случае можно просто расскрыть скобки по биному и получить тоже самое
Аналогично для, при этом добавим чуть больше степеней, чтобы получить лучшую точность на первых пяти коэффициентах (сравните с настоящими коэф.):
[0.49999918 -0.12497953 0.06228674 -0.03788806 0.02348887 -0.01239518 0.004481 -0.00077948]
Если (сумма геометрической прогрессии), то получим такие коэффициенты:
[-0.99995384 0.99882878 -0.98761435 0.93032518 -0.76396752 0.47829397 -0.19124774 0.03533654]
Видим что первые 4 коэффициента довольно близки к реальным.
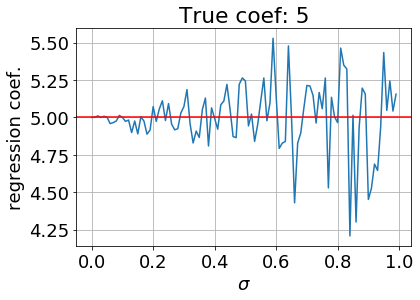
Но даже небольшое добавление шума сильно влияет на коэффициенты. Возьмем и добавим нормальный шум. Посмотрим, как меняется среднеквадратичная ошибка(MSE) определения коэффициентов (берем сумму квадратов разностей между реальными коэф. Тейлора и полученными коэф. линейной регрессии, а далее усредняем) в зависимости от параметра распределения
. Возьмем выборку в 100 тыс. точек.

Видно, что даже в небольшем диапазоне изменения- от 0 до 1.0, среднеквадратичная ошибка существенно возрастает. При этом коэффициенты регрессии все больше отклоняются от своих истинных значений, например, коэффициент при первой степени x:
Выводы
Распределение целевой переменной может быть не нормальным: смещенным, или равномерным. При этом будет хорошая метрика качества и никаких дополнительных преобразований не требуется.
Необходимо следить за распределением остатков и подбирать такое преобразование данных, чтобы это распределение стремилось к нормальному и тогда метрика будет расти.
Очень маловероятно, но все же - если удалось обнаружить какую-либо закономерность в коэффициентах регрессии, то можно попробовать соотнести с каким-нибудь из рядов Тейлора и прямо угадать функциональную зависимость между y и x.
Ноутбук с кодом можно скачать здесь.
StVorpensi
Это как-то связано с предстоящими выборами?
9851754 Автор
Нет, эта статья никак не связанна с предстоящими выборами. Если вам интересно применение статистики в социальных науках, то могу порекомендовать ознакомиться с блогом Эндрю Гельмана.