
Эта пятничная история началась еще пять лет назад. Один мой друг, который в то время помогал запускаться разным стартапам, пожаловался на производительность базы данных, размещенной в Azure. По его словам, они провозились почти все выходные, но добиться приемлемого времени отклика от БД им не удалось, несмотря на все попытки. Даже переход на существенно более дорогой тариф не принес ощутимых результатов. Помню, я тогда еще подумал, что было бы неплохо протестировать все это самому, но времени не было и идея осталась не реализованной, хотя сам разговор я запомнил хорошо.
И вот, спустя пять лет случается флешбэк — выходит статья о нагрузочном тестировании Azure, в которой автор добивается 4 запроса в секунду за 250$ в месяц. Тут уж я просто не мог пройти мимо. Ведь не может такого быть, чтобы второе по величине облако давало так мало за не самые маленькие деньги, правильно? Поэтому я очень быстро набросал простейшее веб приложение на .NET, накатил базу StackOverflow за 2010 год, запустил туда скромную нагрузку в 100 RPS и стал судорожно протирать свои глаза. Даже такую нагрузку мое приложение не держало, причем вообще. 50 RPS тоже оказались слишком высокой планкой, как, впрочем, и 25. И тут я понял, что так дело не пойдет — к вопросу надо подходить системно.
Итак, кому интересно сколько стоит 100 RPS в Azure с .NET Core MVC + .NET 5 + MSSQL на Kestrel — берите кофей и прошу под кат.
Статья написана в пятничном формате и не претендует на абсолютную полноту и достоверность. И, хотя я и пытался получить наиболее точные результаты, они, естественно, могут отличаться от вашего случая. Поэтому я прошу не делать сколь-либо далеко идущих выводов на основании данной статьи, а воспринимать ее скорее, как информацию к размышлению.
Перед тем как начинать тестирование, неплохо было бы понимать, что мы будем тестировать, как мы будем тестировать и чем. Если этап подготовки вам не слишком интересен, смело пропускайте следующую часть.
Что тестируем
Для тестирования я создал .NET Core 5 MVC приложение с двумя Razor страницами. Первая страница практически пуста, без логики, с минимальной разметкой и CSS, который добавляется по умолчанию. С помощью этой страницы я хочу узнать сколько RPS приложение держит в принципе. Вторая страница содержит список из 25 пользователей имена (DisplayName) которых начинаются со случайно выбранных трех букв английского алфавита. Пользователей я буду брать из базы данных StackOverflow за 2010 год, всего в ней насчитывается 299_398 пользователей, что не очень много. Дополнительно я создал индекс на соответствующую колонку.
В коде это выглядит примерно так:
var size = _symbols.Length;
var randomSymbols = new char[] {
_symbols[_rnd.Next(size)]
, _symbols[_rnd.Next(size)]
, _symbols[_rnd.Next(size)]
};
var key = new string(randomSymbols);
var users = _ctx.Users
.Where(x => x.DisplayName.StartsWith(key))
.OrderBy(x => x.DisplayName)
.Take(25)
.ToArray();
Тест немного искусственный, но сам сценарий поиска пользователя по имени (а не первичному ключу) вполне реален. Так что как некая попугаемерка тест подойдет.
Как тестируем
Тестировать я буду в два этапа. Сначала я запущу все локально, чтобы получить ориентировочные значения. После этого я задеплою проект в Azure и начну тестировать там, повышая или понижая мощность конфигурации пока не достигну 100 RPS. Характеристики моего ноутбука не самые топовые (Core i5-9400H @ 2.50GHz, 16GB RAM и SDD), так что будет интересно сравнить
Само тестирование будет идти по примерно следующему алгоритму:
- Даем желаемую нагрузку
- Если приложение с нагрузкой справляется, фиксируем результат
- Если приложение с нагрузкой не справляется, уменьшаем нагрузку в два раза
- Если приложение справляется с уменьшенной нагрузкой — увеличиваем ее на ~25% и повторяем цикл до тех пор, пока не зафиксируем значительное проседание RPS, после чего фиксируем предыдущий результат.
- Если приложение не справляется с уменьшенной нагрузкой, снова уменьшаем ее в два раза и переходим в п. 4. Если после повторного уменьшения приложение все равно не справляется — фиксируем результат
Такой подход позволит нам более точно определить нагрузку, которую держит наше приложение. К тому же, я заметил, что после изменения тарифного плана базы данных производительность всегда падает (возможно умирает кэш самой БД или статистика). Подача нагрузки постепенно также нивелирует эту проблему.
Чем тестируем
Инструментов для тестирования немало — тут и Gatling и JMeter. Я же давно хотел попробовать NBomber — очень простой фреймворк для нагрузочного тестирования, который написан на 100% F#. Как язык, F# мне давно нравится, и идея использовать его хоть как-то показалась мне очень заманчивой (спойлер — кода на F# было написано максимум десять строк, так что поиграться с F# так и не вышло)
Собственно, сам NBomber прост. Сначала мы описываем “шаги” нагрузочного тестирования, в которых указываем ресурсы, которые мы хотим "дернуть", а затем, на основе шагов, конфигурируем сценарий, указывая количество запросов и длительность тестирования.
let step = Step.create("index.html",
timeout = seconds 5,
clientFactory = HttpClientFactory.create(),
execute = fun context ->
Http.createRequest "GET" url
|> Http.withHeader "Accept" "text/html"
|> Http.send context)
let scenario =
Scenario.create "simple_http" [step]
|> Scenario.withWarmUpDuration(seconds 1)
|> Scenario.withLoadSimulations [
InjectPerSec(rate = rate, during = seconds loadingTimeSeconds)
] В результате мы получаем пять файлов — логи, результаты в текстовом прдеставлении, те же результаты в маркдаун, в csv и html с красивыми графиками
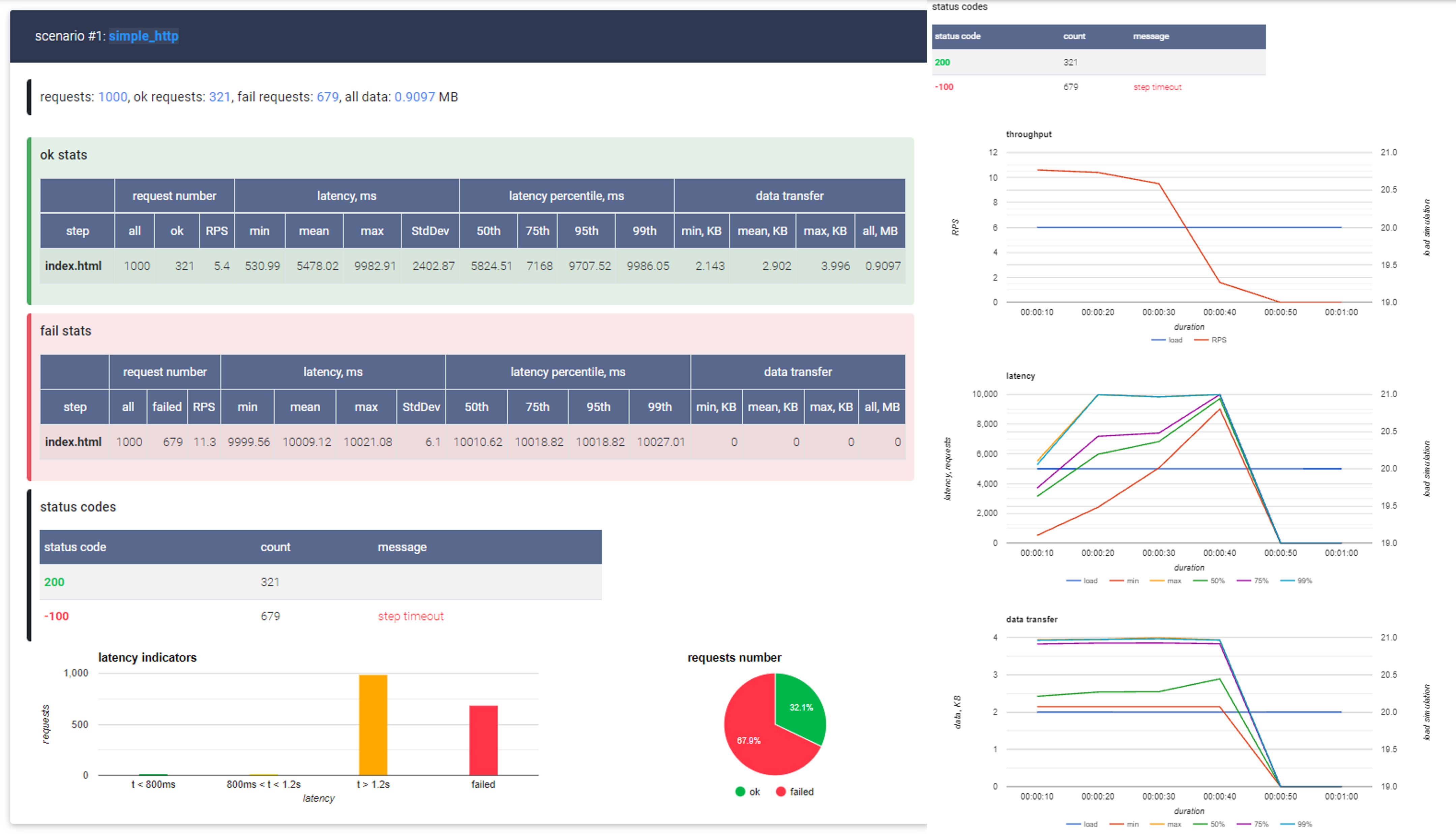
От себя я написал какой-то унылый код, который парсит аргументы консольной строки в лоб, но гордиться тут особо нечем.
У меня локально все работает
Перед тем как тестировать локально, не забудьте включить ноутбук в розетку. Это может улучшить результаты (если план потребления электроэнергии настроен на экономию батареи) и буквально не оставит вас с черным экраном, если батарея вдруг сядет. Звучит смешно, но все случается впервые.
Итак, я подключил ноут к электросети, стартовал приложение и открыл страничку, чтобы проверить приложение. Сюрпризов не было, страница с пользователями открывалась за 250-300мс. Убедившись, что все работает, я начал давать нагрузку на пустую страницу. И вот первый результат: NBomber работает, мы уверенно держим 1000 RPS:
| step | ok stats |
|---|---|
| request count | all = 60000, ok = 60000, RPS = 1000
|
| latency | min = 0.64, mean = 152.91, max = 857.91, StdDev = 145.81
|
| latency percentile | 50% = 120.32, 75% = 174.34, 95% = 527.87, 99% = 788.99
|
Тут мне стало интересно, какой максимум я смогу выжать из своего ноута и это оказалось около 2000 RPS (на самом деле нет)
| step | ok stats |
|---|---|
| request count | all = 120000, ok = 118669, RPS = 1977.8
|
| latency | min = 0.96, mean = 250.03, max = 5486.01, StdDev = 460.46
|
| latency percentile | 50% = 176.26, 75% = 259.71, 95% = 454.14, 99% = 3129.34
|
После этого мне пришлось приостановить тестирование, так как кулера уже гудели как шмели, и я начал опасаться троттлинга. Дав ноутбуку передохнуть, я начал тестировать страницу с пользователями. Давать 1000 RPS я как-то постеснялся и решил начать с сотни. Результат меня удивил — под нагрузкой в 100 RPS успешно завершилось всего 10% запросов:
| step | ok stats |
|---|---|
| request count | all = 5561, ok = 580, RPS = 9.7
|
| latency | min = 228.51, mean = 3030.77, max = 4965.96, StdDev = 1223.88
|
| latency percentile | 50% = 3094.53, 75% = 3872.77, 95% = 4935.68, 99% = 4968.45
|
— Сюююююрприз — сказал бы мой ноутбук, если бы мог говорить, и добавил бы, что 100 RPS держать он не собирается.
Тут я понял, что совершил типичную ошибку дилетанта — тестирую дебаг версию да еще и подключился не к той базе данных (это была вторая база данных, без индекса). Позор и еще раз позор мне. Но лучше признавать свои ошибки чем гордо делать вид что так и должно быть.
Выбрав правильную БД, и запустив приложение в режиме релиза я смог добиться почти 150RPS:
| step | ok stats |
|---|---|
| request count | all = 8976, ok = 8976, RPS = 149.6
|
| latency | min = 24.44, mean = 1080.12, max = 2173.79, StdDev = 399.85
|
| latency percentile | 50% = 1029.63, 75% = 1117.18, 95% = 2068.48, 99% = 2146.3
|
На пустой странице, максимальное количество запросов в секунду которых удалось добиться, составило 2784 (релиз нам принес почти +40%, разница очевидна):
| step | ok stats |
|---|---|
| request count | all = 180000, ok = 167058, RPS = 2784.3
|
| latency | min = 0.39, mean = 339.22, max = 7625.08, StdDev = 1242.98
|
| latency percentile | 50% = 12.16, 75% = 31.76, 95% = 3411.97, 99% = 6942.72
|
Так что можем фиксировать результаты: локально мой ноутбук держит 2.7K RPS на пустой странице и 150 RPS на странице с выборкой пользователей из базы данных. Время двигаться к облакам, ведь там "все будет хорошо" (С)
Облачно — тучи сгущаются
Теперь, когда есть от чего отталкиваться, можно посмотреть, что предлагает Azure. Интересно же сравнить свое родное железо с тем, облачным.
Для начала нужно создать "Web App" — "слот" для размещения веб приложения и выбрать для него тариф. От тарифа зависит вычислительные мощности, которые мы сможем использовать и некоторые дополнительные возможности, например геобалансировку. Я взял самый дешевый тарифный план, который поддерживает выделенные ресурсы — B1 со следующими характеристиками:
- Вычислительная мощность — 100 ACU
- Память — 1.75GB
- Цена — 32$
Что такое ACU — никому не понятно. Рабочая частота, тип процессора, тип памяти, тип диска — все это тщательно скрыто. Единственное что понятно, что ACU это некие попугаи в которых можно сравнивать производительность между разными тарифными планами внутри самой Azure. Естественно, сравнить производительность, например с Amazon, не выйдет. Понятно зачем это сделано, но раздражает сильно.
После разворота самого приложения нам нужно еще развернуть SQL сервер и SQL базу данных. Здесь все аналогично предыдущему пункту, только вместо CPU и Memory мы имеем DTU и размер хранилища. Несмотря на наличие бенчмарков от Microsoft, что такое DTU понятно чуть менее чем никак. Т.е. ничего не понятно кроме того, что 1 DTU стоит 1.5 доллара в месяц, а для базы данных которую ожидает серьезная нагрузка на CPU нужно брать уровень S3 или выше. S3 это 100 DTU, 150$ в месяц только за одну базу. Ну что ж, поверим специалистам и возьмем сразу S3, посмотрим, насколько она превзойдет мой ноутбук.
Подняв SQL сервер и восстановив базу из бэкапа (я так же накатил индекс, проверил его наличие и увеличил максимальное кол-во соединений с БД на всякий случай) я запустил еще чистенькую виртуалку в том же регионе. Для виртуалки я взял B4ms с 4 ядрами и 16GB оперативной памяти с Windows Server 2019 Datacenter gen 1 на борту. По идее это должно дать более-менее честную картинку, и мы не встрянем в проблему исчерпания TCP/IP соединений.
Облачно — начинается ливень
Приложение я поднял, базу данных развернул, страницу открыл — все работает как надо. Страница с пользователями открывается даже быстрее чем на моем ноутбуке — 200-250мс, что внушает надежду. Напомню, что мой ноут держит 2700 RPS на пустой странице и 150RPS на тестовой странице с пользователями. Предлагаю с чего-то подобного и начать:
Даем нагрузку в 2000 RPS на пустую страницу и… ничего. Такую нагрузку B1 не держит от слова совсем. Что хотя и обидно, но понятно, B1 все-таки рекомендуется для разработки, а не для нагрузочного тестирования. После нескольких итераций оказалось, что B1 справляется только с 300RPS
| step | ok stats |
|---|---|
| request count | all = 18000, ok = 18000, RPS = 300
|
| latency | min = 3.95, mean = 419.46, max = 2070.85, StdDev = 198.27
|
| latency percentile | 50% = 375.81, 75% = 419.58, 95% = 935.94, 99% = 1068.03
|
Что, ж не будем мучать котов, и возьмем тариф посерьезнее, например P1V2 — 210 ACU, 3.5GB оперативной памяти за 49.57$.
На этом тарифном плане мы держим уже 1000RPS с наихудшим результатом в 1833мс. (а вот 1200 уже не держим)
| step | ok stats |
|---|---|
| request count | all = 60000, ok = 60000, RPS = 1000
|
| latency | min = 3.21, mean = 565.14, max = 2547.46, StdDev = 338.81
|
| latency percentile | 50% = 549.89, 75% = 605.18, 95% = 1319.94, 99% = 1833.98
|
Не так хорошо, как мой ноутбук (надеюсь это прозвучало достаточно пафосно), но для экспериментов хватит. Зато наглядно видно, как смена тарифа влияет на способность держать нагрузку — в данном конкретном случае 20$ увеличили потолок по нагрузке более чем на 200%.
После этого я попробовал нагрузить страницу с пользователями на тестовые 50 RPS и опять меня ждал сюрприз — несмотря на то, что мы взяли рекомендованный (пусть и минимальный) тариф для интенсивных вычислений, количество успешно выполненных запросов составило целых 0 единиц:
| step | ok stats |
|---|---|
| request count | all = 2750, ok = 0, RPS = 0
|
Оказывается, что для сетапа за почти 200$ (150$ БД + 49.57$ веб сайт) 50RPS это слишком много. И дело 100% не в самом веб приложении, оно держит и 1000 RPS — проблема явно в той части за 150$ т. е. в базе данных и проверить это не сложно — Azure предоставляет большое количество метрик в том числе и по расходу DTU и это было первое что я пошел проверять:
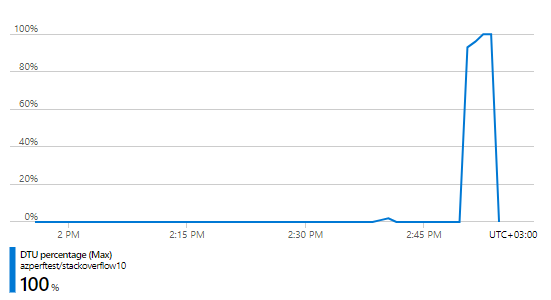
Использование DTU — 100%. Получается, что проблема действительно с тарифом базы данных. Возможно, нужно просто дать еще сантик? К счастью, у нас выделяют бюджет на подобные эксперименты и я могу не опасаться за свой кошелек. Поэтому я просто увеличил тариф в четыре раза до S6 с 400 DTU за каких-то несчастных 600$ долларов в месяц и снова нагрузил его в 50 RPS. Спустя несколько заходов выяснилось, что сетап за 650$ такую нагрузку держит, а иногда вывозит даже целых 60RPS:
| step | ok stats |
|---|---|
| request count | all = 3597, ok = 3597, RPS = 60
|
| latency | min = 641.15, mean = 1184.47, max = 2440.76, StdDev = 453.31
|
| latency percentile | 50% = 990.72, 75% = 1434.62, 95% = 2073.6, 99% = 2265.09
|
Сказать, что я был счастлив означает ничего не сказать. Это же просто "вау" думал я в тот момент. Всего 650 баксов в месяц и это работает "почти" как мой ноут (правда в случае с Azure не надо обслуживать железо, ОС и возиться с лицензиями что конечно плюс). Но даже с учетом этого радужными эти цифры не были. А ведь наша цель не 50, а 100 RPS.
Поэтому я снова пошел смотреть на метрики. Как выяснилось, в этот раз мы не исчерпали все выделенные DTU — судя по тому же графику, в пике мы использовали только 82% от их максимального количества. Но это наверняка не проблема с самим веб приложением, т. к. как мы уже знаем, что оно держит более 1000 запросов в секунду. Конечно, трансляция LinQ в SQL, десериализация, рендер самой страницы тоже занимает какое-то время, но вот не верю я в то, что проблема на уровне веб приложения. Тем более что проверить это достаточно просто — достаточно бросить еще одну монетку и взять тариф подороже. Если я прав — мы увидим рост производительности. Если нет — все останется, как и было и тогда я попробую взять побольше мощностей уже для веб приложения.
Сказано — сделано, берем тариф еще дороже: S7, 800 DTU, 1200$ в месяц. И нагружаем ее с тех же несчастных 50 RPS. Спустя несколько попыток результат получился следующий:
| step | ok stats |
|---|---|
| request count | all = 6574, ok = 6574, RPS = 109.6
|
| latency | min = 692.16, mean = 968.23, max = 2067.65, StdDev = 288.53
|
| latency percentile | 50% = 911.36, 75% = 989.18, 95% = 1766.4, 99% = 1941.5
|
109RPS, максимальное время ожидания 1941мс, отличные результаты и за всего ничего — 1200$. Причем, если посмотреть графики потребления DTU/CPU/IOPS у нас везде есть запас. Например, DTU мы выбрали всего на 70%.
Почему так? Возможно, я просто выбрал неправильный подход? Ведь Azure предоставляет тарифы, основанные как на DTU, так и на виртуальных ядрах. За 1140$ можно взять 10 VCore и это явно стоит попробовать. Поэтому я поменял тип плана с DTU на VCore и снова дал нагрузку. Результат не удивил: меньше платишь — меньше получаешь. Теперь приложение держит только 97.6 RPS да и наихудшее время ожидания выросло до 2326мс:
| step | ok stats |
|---|---|
| request count | all = 5853, ok = 5853, RPS = 97.6
|
| latency | min = 774.8, mean = 1154.58, max = 2362.44, StdDev = 423.61
|
| latency percentile | 50% = 983.04, 75% = 1180.67, 95% = 2121.73, 99% = 2326.53
|
Больше 97 RPS выжать мне не удалось, так что предлагаю зафиксировать следующий результат:
Для того, чтобы держать 100 RPS, используя Azure, ASP .NET Core MVC, .NET Core 5, и MS SQL на запросе вида
var users = _ctx.Users
.Where(x => x.DisplayName.StartsWith(key))
.OrderBy(x => x.DisplayName)
.Take(25)
.ToArray();Нам нужно потратить 49.57$ на хостинг самого веб приложения и 1200$ на БД. Много это или мало пусть каждый решает сам, но, если что — мое мнение обо всем происходящем можно найти в тегах.
Облачно — проглядывает солнце
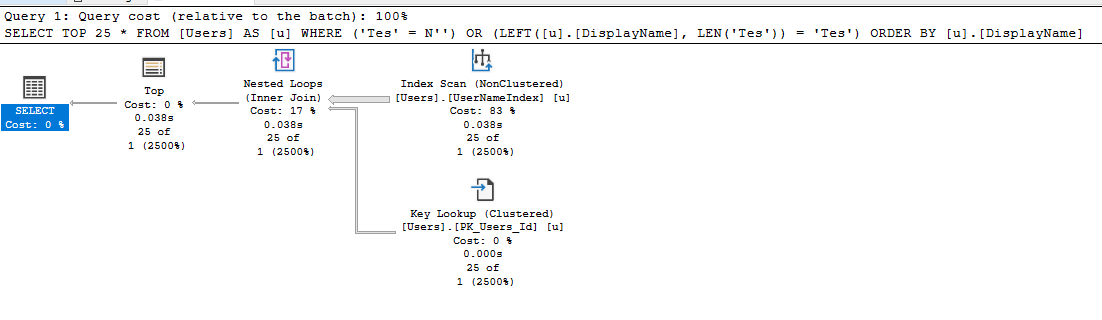
1250$ за 100RPS звучит откровенно прискорбно. И, если честно, если бы я не видел это все своими глазами, то первым моим предположением было бы что кто-то изрядно накосячил. С другой стороны, быть может, я действительно где-то накосячил? Если вы помните, то проблема на относительно дешевом тарифе S3 была связана с исчерпанием квоты вычислительных ресурсов, что намекает на интенсивные вычисления на уровне БД. Но разве StartsWith такое уж сложное выражение? Давайте посмотрим запрос, в который было транслировано наше LinQ выражение (это можно сделать и в самом Azure или просто вызвав .ToQueryString()):
(@__key_0 nvarchar(4000),@__p_1 int)
SELECT TOP(@__p_1) *
FROM [Users] AS [u]
WHERE (@__key_0 = N'') OR (LEFT([u].[DisplayName], LEN(@__key_0)) = @__key_0)
ORDER BY [u].[DisplayName]Вам не кажется, что WHERE выглядит немного сложно? Наверняка Entity Framework знает лучше меня (где я, а где зубры из EntityFramework) но что если переписать этот запрос на что-то попроще и выполнять его напрямую вместо трансляции из LinQ выражения, например на такое:
var p1 = new SqlParameter("@DisplayName", $"{key}%");
var query = _ctx.Users.FromSqlRaw(
$"SELECT TOP 25 * FROM USERS WITH (NOLOCK) WHERE DisplayName LIKE @DisplayName ORDER BY DisplayName", p1
);Да, я еще и схитрил, добавив NOLOCK конструкцию, но чего не сделаешь ради красивых цифр. Кстати, вместо того что бы писать SQL напрямую, можно было бы использовать Microsoft.EntityFrameworkCore.EF.Functions.Like для подсказки EF что нужно использовать именно Like конструкцию вместо Left/Len.
Так что я изменил код, передеплоил приложение и снова вернулся к старо доброй S3 базе за 150$. Даю нагрузку в 50RPS и — база держит, и держит весьма неплохо — наихудший результат всего 540мс:
| step | ok stats |
|---|---|
| request count | all = 3000, ok = 3000, RPS = 50
|
| latency | min = 107.72, mean = 228.22, max = 617.06, StdDev = 110.14
|
| latency percentile | 50% = 197.89, 75% = 295.17, 95% = 491.01, 99% = 540.67
|
Использование DTU тоже резко снизилось, на 50RPS мы используем всего 23%.
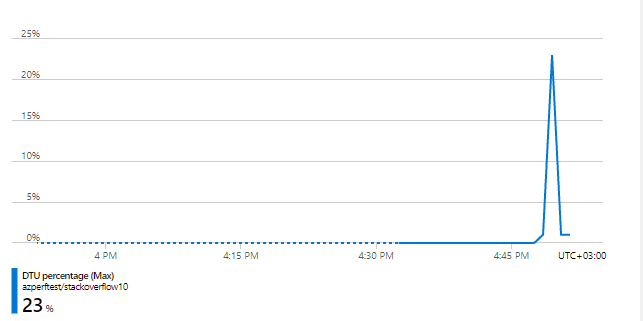
Похоже, что проблема действительно была в запросе, но с этим можно будет разобраться попозже. А сейчас я просто добавлю еще нагрузку и посмотрим сколько она сможет выдержать: 75RPS, 100RPS, 150RPS, 300RPS! Нет, до 300 мы все-таки не дотянули, но 283 запроса в секунду вытянуть смогли. И это на тарифе, который до этого не держал даже 50RPS:
| step | ok stats |
|---|---|
| request count | all = 17018, ok = 17018, RPS = 283.6
|
| latency | min = 217.56, mean = 1572.22, max = 4386.47, StdDev = 882.05
|
| latency percentile | 50% = 1172.48, 75% = 2332.67, 95% = 3295.23, 99% = 4112.38
|
Но нам же столько не надо! Если вы помните, задача стояла выяснить цену 100RPS, так что я начал поэтапно уменьшать тарифный план и выяснил, что с новым запросом, для 100RPS достаточно и базы данных уровня S1 — 20 DTU за 30$, причем с не самым плохим временем отклика — 776мс в наихудшем случае.
| step | ok stats |
|---|---|
| request count | all = 6000, ok = 6000, RPS = 100
|
| latency | min = 212.99, mean = 376.42, max = 1219.67, StdDev = 153.35
|
| latency percentile | 50% = 320.51, 75% = 445.44, 95% = 736.77, 99% = 776.7
|
При этом мы почти уперлись в лимит DTU, использовав около 84%, так что похоже я нашел оптимальный план для выбранной нагрузки.
Выводы?
С выводами все неоднозначно. С одной стороны, мне понадобилась 1250$ для того, чтобы выдержать с виду вполне безобидный запрос на не самой большой нагрузке. С другой стороны, с помощью той же Azure мне удалось сначала решить задачу и получить свои 100 RPS (пусть это и стоило денег), а потом уже найти узкое место и исправить его. С третьей :) стороны даже полторы тысячи долларов в месяц — это не самая большая сумма для предприятия. С четвертой стороны, 100 запросов в секунду тоже не хайлоад.
Одно понятно точно — с базой данных и EF нужно быть осторожным, положить свое собственное приложение совсем не сложно.
Спасибо за внимание, надеюсь было интересно. Для желающих повторить мои приключения исходники доступны по ссылке на GitHub.
Для Entity Framework:
Для прямого SQL: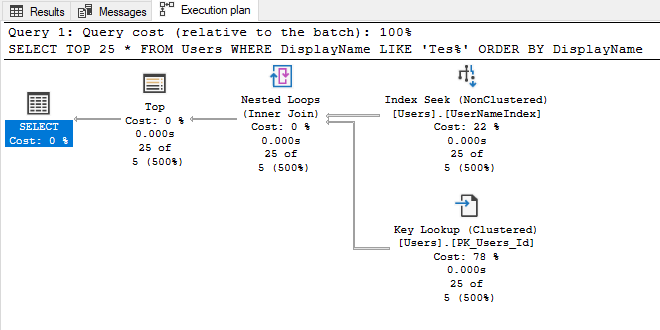
EF ASYNC
| step | ok stats |
|---|---|
| request count | all = 9523, ok = 9523, RPS = 158.7
|
| latency | min = 31.1, mean = 1018.09, max = 3319.5, StdDev = 461.32
|
| latency percentile | 50% = 978.94, 75% = 1325.06, 95% = 1795.07, 99% = 2140.16
|
SQL Sync
Rate: 2300, during: 00:01:00
| step | ok stats |
|---|---|
| request count | all = 138000, ok = 125883, RPS = 2098
|
| latency | min = 3.1, mean = 698.66, max = 8232.34, StdDev = 1336.41
|
| latency percentile | 50% = 125.38, 75% = 479.49, 95% = 3049.47, 99% = 7213.06
|
| step | fail stats |
|---|---|
| request count | all = 138000, fail = 12117, RPS = 202
|
| latency | min = 378.79, mean = 5606.03, max = 8208.32, StdDev = 1144.1
|
| latency percentile | 50% = 5529.6, 75% = 6074.37, 95% = 7249.92, 99% = 7536.64
|
SQL Async
Rate: 2400, during: 00:01:00
| step | ok stats |
|---|---|
| request count | all = 144000, ok = 136391, RPS = 2273.2
|
| latency | min = 1.91, mean = 1308.2, max = 7596.02, StdDev = 1579.3
|
| latency percentile | 50% = 492.03, 75% = 1988.61, 95% = 4415.49, 99% = 6520.83
|
| step | fail stats |
|---|---|
| name | index.html |
| request count | all = 144000, fail = 7609, RPS = 126.8
|
| latency | min = 181.63, mean = 6122.8, max = 7573.97, StdDev = 762.05
|
| latency percentile | 50% = 6316.03, 75% = 6590.46, 95% = 7204.86, 99% = 7340.03
|
status codes for scenario: simple_http
Апдейт
Cтатья обновлена в части локального тестирования из-за допущеных ошибок. Часть, посвященная облачному тестированию, перепроверена и осталась без изменений. Я так же благодарю mvv-rus, nobody8, @Fullborg и других хабровчан, которые своими детальными комментариями подтолкнули меня протестировать все еще раз и найти ошибку.
Спасибо вам большое!
Комментарии (78)


devlev
15.10.2021 14:20+3MSSQL и EF это отдельный, уникальный и дивный мир! Я в вебе с тех самых времен, когда верстали еще под IE6, и навыки верстака оценивались знаниями как выравнить блочный элемент по центру, как сделать прозрачность или как не словить баг с margin.
Прошло 15 лет и ничего не поменялось. Я по прежнему занимаюсь шаманством. Переписываю запрос LINQ c `.where(n => n.PropABool && !n.PropBBool)` на `.where(n => n.PropABool == true && n.PropBBool == false)`
Запрос вроде вашего `.Where(x => x.DisplayName.StartsWith(key))` это вообще не позволительная роскош! Нет, тут только полнотекстовый поиск, там все норм со скоростью работы, а обычный like использовать на больших полях опасно!
Вот еще такой пример: `.Where(n => !n.Items.Any())` или `.Where(n => n.Items.Count() == 0)`. Вопрос к знатокам, какой будет работать шустрее?

read_maniak
15.10.2021 15:40Я бы предположил, что n.Items.Any() будет быстрее. По логике там не требуется весь "список" просчитывать, достаточно наличия первого совпадения. Так ведь?

dimuska139
15.10.2021 16:26Надо смотреть, что там за запрос генерируется в обоих случаях, иначе это гадание на кофейной гуще. Если !n.Items.Any() превращается в NOT EXISTS, то это будет самый оптимальный вариант.
devlev
15.10.2021 16:53+1В моем случае
.Where(n => n.Items.Count() == 0)работало шустрее в разы. Да и в дальнейшем я понял что лучше в LINQ Any вообще не использовать и делать все на Count. К сожалению пока нет возможности сделать ToString обоих запросов.
force
15.10.2021 19:13+1Отрицание с Any - это мина замедленного действия. На подобном запросе разваливался MySQL, Postgre в зависимости от фазы луны, оптимизатор MSSQL обычно догадывается до LEFT JOIN, но видно не всегда.
Вообще, если есть возможность и нужна скорость - то пробовать именно классические джойны, всё-таки на этой логике базы гораздо лучше работают.
Ну и иногда стоит играться с First/Single - в зависимости от ORM и базы данных могут весьма разные результаты получаться.

navferty
15.10.2021 15:05+2Я бы еще предложил проверить, как повлияет на производительность изменение выборки на асинхронную:
await <...>.ToArrayAsync()вместо блокирующего.ToArray().Синхронный вызов к БД блокирует поток, что теоретически может привести к исчерпанию потоков в пуле, и так же к таймаутам входящих HTTP-запросов.

Drag13 Автор
15.10.2021 16:56Локально на EF ничего не дало. Впрочем вечером сделаю еще два теста локально, посмотрим.
Drag13 Автор
15.10.2021 19:07В конце статьи под спойлером еще статистика.
Если кратко то:
На SQL разогнались почти до 75 RPS
Асинк на РПС не влияет. Видимо все таки упираемся в базу, а не количество запросов.
Drag13 Автор
16.10.2021 11:04+1Часть про локальное тестирование была отредактирована из-за допущеной во время локальных тестов ошибки.
Свежие тесты показали что локально:
На EF мы держим 150RPS
EF Async - 160 RPS
На SQL Sync - 2098 при нагрузке в 2300
На SQL Async - 2273.2 при нагрузке в 2400
На планах исполнения теперь отчетливо видно использования Index scan для EF и Index seek для SQL что и объясняет разницу.
Прошу прощения за путаницу, больше времени уделялось перепроверки облака, а вот с локальным тестированием получилась оплошность хотя для сравнения это не менее важно.

MDiMaI666
15.10.2021 16:25Можете на основе своего опыта придумать формулу приведения этих двух попугаев в rps? Хоть я и видел их калькулятор, для рядового разработчика не хватает чакры понять. Чтобы примерно прикинуть остальные тарифы. Хотя бы очень приблизительно
Drag13 Автор
15.10.2021 17:07Нет, это очень большой риск всех ввести в заблуждение. Максимум что можно - написать N самых популярных сценариев и провести тестирование на них. Но:
Что такое "популярные" сценарии не сильно понятно
Потом они обновят железо и/или конфигурации и все, тесты будут только обманывать
Но вашу боль я прекрасно понимаю - как узнать наперед бюджет который нужен для заданого RPS да еще и без миграции в облако (пусть даже и в конкретном случае и пусть даже приблизительно) - ХЗ.

granit1986
15.10.2021 19:52Попробуйте сделать ApiController с асинхронным методом и вызывать ArrayToAsync + AsNoTracking.
Кстати, для Like есть EF.Functions.Like()
Drag13 Автор
15.10.2021 20:47.ToArrayAsync()не принес особой пользы, детали под последним катом.А что касается использования подсказки так я же об этом прямо в статье писал)

vagon333
16.10.2021 00:27+1Обычные домашние проекты, которые неспеша выходят на коммерческие.
https://www.ebay.com/itm/353200398868 x2 и старые SAS SSD с большим остаточным ресурсом.

jakobz
15.10.2021 20:30+2По моим ощущениям, аренда железа в облаке стоит столько же в месяц, сколько стоит эквивалентный потребительский комп на рынке. Тут тоже примерно совпало.
vagon333
15.10.2021 22:06Намучались с переносом .Net приложения с ORM NHibernate c дата центра в облако - ORM генерит массу запросов и если в облаке веб сервер и бд на разных машинах (а всегда на разных) то latency предсказать невозможно.
Облака замечательны, но для своих пет-проектов за $120/мес разместил в датацентре 2 стареньких сервера на 40 ядер, 1.5тб памяти и 10тб SSD диска, 15 статических IP и давно отбил начальное вложение в б/у серверы. Все железо под моим контролем и производительность адекватна нагрузкам.

tmin10
15.10.2021 23:58Как-то хостил бота для скайпа в azure с использованием botframework. На пробном аккаунте ничего не делающий бот съел 7 тысяч рублей за месяц. С тех пор очень осторожно отношусь к облакам для личных проектов, vps выглядит куда как экономичнее (но больше настроек руками, конечно)
MDiMaI666
16.10.2021 04:20У меня была аналогичная ситуация. С тех пор использую только VPS с фиксированной ценой.

Netforspeed
20.10.2021 06:53А свою железку, в качестве сервера, так ни не попробовали? и зря. за 7 тысяч рублей можно 8 ядерный ноут купить с рук, SSD прикупить к нему, и радоваться.
dimuska139
20.10.2021 10:15Так а смысл? Технической поддержки никакой, всё делаешь сам, в том числе и настраиваешь бэкапы (их же бэкапить надо на другой комп всё равно). Также этот ноут-сервер должен быть постоянно включён и подключён к домашнему интернету (от него целиком и полностью зависит). Кроме того, нужно у провайдера всё равно платить за внешний IP адрес.
tmin10
20.10.2021 10:43Ботам может быть не нужен белый IP, если они работают через лонг пулинг. И хостить что-то на своём NAS вполне себе идея, если не нужен 99.99999% аптайм, конечно (или интернет упадёт или электричества не станет).
Netforspeed
20.10.2021 20:35Бэкап только на другой комп? А что с облаками? А что со вторым диском? Или внешним диском? Бесплатный скрипт и все автоматически. Так вот по моему опыту ноут без электричества не оставался на долго за пару-тройку лет. В нашем плотненько населенном микрорайоне это исключено, а вот vps арендованный, был недоступен двое суток, что и привело меня к закрытию вопроса аренды.
Ip стоит 80 рублей в месяц, ну что об этом говорить...
На счёт тех поддержки - вы один раз запустите у себя все необходимые компоненты, и будете быстрее любой поддержки решать проблемы, которых и нет, если не лезть с собственными идеями, периодически возникающими.
tmin10
20.10.2021 10:41К счастью это были не реальные деньги, а пробный месячный кредит, да и бот мне особо был не нужен, просто пробовал технологию. А так конечно, для реального бота just 4 fun разумнее завести VPS за 100-200р в месяц.

AlanDenton
18.10.2021 16:00Если честно такая дичь... не буду дублировать что люди ранее писали. Хочется ускорить запрос... избавляемся от любых преобразований на индексном поле... добавляем покрывающий индекс + вычиляемое поле... помечаем что оно имеет бинарный коллейшен.
Краткий пример о чем речь:
USE AdventureWorks2014 GO SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%' ------------------------------------------------------------------ USE [master] GO IF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE test END GO CREATE DATABASE test COLLATE Latin1_General_100_CS_AS GO ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB) GO ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB) GO USE test GO CREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL ) GO ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) INSERT INTO t SELECT v, v FROM ( SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8 ) t GO ------------------------------------------------------------------ ALTER TABLE t ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_BIN2 ALTER TABLE t ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2 CREATE NONCLUSTERED INDEX ansi ON t (ansi) CREATE NONCLUSTERED INDEX unicod ON t (unicod) CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin) CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin) GO ------------------------------------------------------------------ SET STATISTICS TIME, IO ON SELECT COUNT_BIG(*) FROM t WHERE ansi LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE unicod LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SELECT COUNT_BIG(*) FROM t WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SET STATISTICS TIME, IO OFFDrag13 Автор
18.10.2021 17:17+2Наверное я не очень внятно объяснил цель статьи. Задача не стоит выжать максимум любой ценой. Задача стоит оценить какую нагрузку держит облако в +- типичном сценарии с использованием типичных инструментов. И, заодно, посмотреть как изменятся результаты если поменять запрос, который создает ORM, на не сложный SQL. Все остальное - совсем за рамками этой статьи.
За пример спасибо, за дичь обидно

edo1h
18.10.2021 17:20+1Задача стоит оценить какую нагрузку держит облако в +- типичном сценарии
я бы не сказал, что сканирование большой таблицы — это типичный сценарий, скорее это то, чего на проде стараются избегать.
Drag13 Автор
18.10.2021 17:33+1Да я согласен :)
Но с меня как с .NET программиста взятки гладки - код работает, я даже индекс накатил. А то, что вместо index seek получился index scan мы узнаем в лучшем случае из мониторинга, а в худшем от заказчиков, т.к. в план выполнения все кто не DBA смотрят, скажем так, не часто. Поэтому для меня этот код вполне подходит как типичный.
Ну и DBA не всегда есть в команде, особенно если ты вообще один.

mvv-rus
18.10.2021 20:21я бы не сказал, что сканирование большой таблицы — это типичный сценарий, скорее это то, чего на проде стараются избегать.
Все правильно вы пишете, но это, похоже, не тот случай, про который в статье: по крайней мере, в запросе, сгенеренном EF, у него Index Seek (который, подозреваю, ещё идет не с начала индекса, а сразу с нужного места и сразу выбирает запрошенные TOP N записей как раз в запрошенном в ORDER BY порядке то есть явлется практически оптимальным — но для проверки стоило бы посмотреть свойства этого оператора плана)+KeyLookup (потому что у него SELECT * ..., т.е. он забирает и те поля, которых нет в индексе).
В первоначальном выложенном варианте — да, было полное сканирование таблицы, потому что автор тогда выложил планы запросов по таблице без индекса по полю, по начальной части которого у него идет отбор.
PS Я не вижу, к сжалению, код шаблона для страницы, но если там выводятся только имена пользователей (поле DisplayName), то от KeyLookup, скорее всего, можно избавиться даже в сгенернном EF запросе, добавив в цепочку вызовов функций LINQ .Select(x=>x.DislplayName), чтобы получить в запросе SELECT [DisplayName]… (ну, и код шаблона для страницы подправить, чтобы учесть, что в него передаются только строки со значениями DisplayName).mvv-rus
18.10.2021 20:52По поводу PS я, возможно, погорячился: не исключено, что там потребуется больше переделок, чтобы избавиться от SELECT * и KeyLookup, как его следствия.
Netforspeed
18.10.2021 17:17Пару - тройку лет назад, в комментарии под статьей на тему " выбора vps" сервера, я написал, что по моему личному опыту, для mvc, нет ничего лучше собственного ноутбука, а в случае роста нагрузки - собственного сервера с оптикой в дом. После этого заявления я узнал о себе столько нового, нелицеприятного.
Вы ещё забыли упомянуть самую главную боль - негарантированность даже вот этого убогого результата.
Drag13 Автор
18.10.2021 17:19У хостинга под личным ноутбуком очень много нюансов. И если для петпроектов это может быть да, то для чего-то существенного скорее нет (или надо понимать конкретный случай).
Вы ещё забыли упомянуть самую главную боль - негарантированность
Ну какой-то SLA там есть, но результаты чуток прыгают, это да.
Netforspeed
20.10.2021 06:34Честно говоря я готов сказать спасибо вам огромное, за тех, кто решает проблему первичного размещения своего стартапа, например, поскольку вопрос раскрыт, и кто-то, как я, в свое время, не будет искать ответ, и не попадет в зависимость от убогой аренды, и не будет перебирать арендаторов, и страны их места расположения, и нервничать в 100500 раз, когда сервер недоступен или перегружен. Я прошел через этот дурдом, и сожалею о потраченном времени и нервах.
Netforspeed
20.10.2021 06:41ноут бук это мини сервер с ИБП, которого хватает на полчаса работы при отключенной электросети. это просто подарок судьбы, за смешные деньги, как тут не порадоваться. если ваш портал не несет большую нагрузку, такую как в вашем примере - 100 соединений в секунду, но, жизненно важно держать постоянное соединение, то нет ничего лучше ноутбука.
TheAndrey
18.10.2021 17:17@Drag13, не понял почему локально "плохой" код EF, так хорошо отрабатывал по сравнению с тем же плохим кодом на Azure.
Drag13 Автор
18.10.2021 17:21Потому что ресурсы которые выделяет облако на выбраном тарифе меньше, чем у меня на ноутбуке. Хотите что бы код работал быстрее - или платите больше, или оптимизируйте код.
mvv-rus
18.10.2021 20:03Обновленные планы выполнения запросов
Похоже, вы вместо «Прямого запроса» повторно выложили план для варианта, сгенеренного EF.
Проверьте, пожалуйста.Drag13 Автор
18.10.2021 20:24Так и есть, выложил правильный. Спасибо.
mvv-rus
18.10.2021 20:49Вот так лучше: теперь видно, где сгенеренный EF запрос проигрывает, и примерно понятно, почему: видимо, на скорости сканирования индекса сказывается сложность выражения в WHERE, вычисляемого на основе значения индексированного поля.
PS Но для полноценного сравнения было бы лучше, если бы число возвращаемых записей совпадало, а то сейчас у вас сгенеренный EF запрос возвращает 1 запись, а сделанный вручную (с другими параметрами, видимо) — 5

kemsky
22.10.2021 20:58Это очень, очень хороший пример того как внешне "простая" операция оказывается непростой внутри. Самое смешное, ваше ускорение добавило как минимум баг, а фактически уязвимость. Выражение для like надо эскейпить, иначе юзер может заслать вам строку которая начнется с %, например, и отключит индекс или придумает еще варианты для DDOS. В том числе и по этой причине EF Core и генерирует такой странный код. Можно почитать тут https://github.com/dotnet/efcore/issues/474. Расплатой становится не sargable WHERE, а значит в лучшем случае Index Scan вместо Seek, так как надо вычислять LEFT/LEN для каждого ряда. Нагрузка на IO растет в разы, растет и CPU и идет перерасход DTU.
Drag13 Автор
22.10.2021 21:10Самое смешное, ваше ускорение добавило как минимум баг, а фактически уязвимость.
SQL инъекции это не смешно, так что спасибо что обратили на это внимание.
Но в данном случае уязвимости нет, т.к. используется SQL параметры:var p1 = new SqlParameter("@DisplayName", $"{key}%"); var query = _ctx.Users.FromSqlRaw( $"SELECT TOP 25 * FROM USERS WITH (NOLOCK) WHERE DisplayName LIKE @DisplayName ORDER BY DisplayName", p1 );Документация подтверждает безопасность данного подхода:
Вы также можете создать DbParameter и указать его в качестве значения параметра. Поскольку используется обычный заполнитель параметров SQL, а не строковый заполнитель, можно безопасно использовать FromSqlRaw.
kemsky
22.10.2021 21:23Если строка будет начинаться с % то перестанет использоваться Index Seek и сервер ваш снова не сможет отдавать 100RPS, отказ в обслуживании, деградация. Попутно можно использовать другие фичи like чтобы еще сильнее нагрузить базу.
Drag13 Автор
22.10.2021 21:28Ну да, но это же тест, а не разбор полетов продакшн базы. Если по сильно большому счету, то все равно какой код брать, главное что бы можно было сравнить с облако и локальную машину. А так можно и %test% и test% и даже test, но, наверное, последнее было бы не столь показательно.
dimuska139
Чего-то странно вообще. У меня сейчас VPS за 519 рублей в месяц. Там болтается пет-проект с PostgreSQL и API (NestJS) - прямо рядом. Сейчас через ab дёрнул один из API-эндпоинтов - 215.23 rps. Запрос в БД тоже есть, и я там даже с оптимизацией не заморачивался вообще никак. У меня там правда не like, а просто выборка по индексу. Цена вопроса - 519 рублей в месяц. У вас как-то всё слишком дорого вышло. Либо я что-то не так понял.
Drag13 Автор
Да, есть такое. Я мог бы даже статью переназвать так :)
Но, думаю тут проблема в самом запросе от EF. Как видите, даже с LIKE мы уже вывозим сотню за 30 долларов. А на индексах, когда мы проверяем полное вхождение, будет еще быстрее.
dimuska139
Если вы говорите об индексах и LIKE, то при чём тут EF? EF же только генерирует запрос и маппит его результаты на объекты, а сам запрос выполняет БД, и индексы участвуют именно в момент выполнения запроса в БД (на её стороне). Тем более, если у вас LIKE по началу значения поля DisplayName, то индекс и так может использоваться, если у вас он есть, и выполняются условия для того, чтобы БД решила его использовать.
И опять-таки даже это крайне дорого для такой производительности. Особенно учитывая, что БД у вас на отдельном хосте и с API за ресурсы не борется.
Drag13 Автор
Потому что EF не генерит LIKE код для того c# с которого я начинал.
Может быть, тут спорить не буду. Но цель и была выяснить какую реуальную нагрузку мы можем получить. А мало это или много каждый оценивает сам.
Drag13 Автор
Да, кстати. Побуду адвокатом
дьяволаAzure, в эту сумму входит лицензия, апдейты, и метрики всякие полезные. Я бы это тоже учитывал.dimuska139
А вот этого не знал, кстати
dimuska139
Может быть, у вас пул соединений для БД не используется?
Drag13 Автор
Тогда мы бы не держали 300 RPS на s1. Я думаю, что дело все таки в выделеных мощностях.
Szer
ADO.net пулит коннекшны сам
andreyverbin
Ничего странного, запрос автора делает full table scan, так как он просит StartsWith(x). Потому БД и стала узким горлышком. 10 vCore не помогли потому, что БД не умеет выполнять запрос на нескольких ядер. Судя по данным, запрос автора все читал с диска. Ваш запрос работает с индексом, который, скорее всего, полностью помещается в памяти.
Drag13 Автор
Наверное я что-то не понимаю, но в плане выполнения указан Clustered Index Scan. Разве это не означает был использован индекс?
sergix
Scan -прохождение по липесточкам осенью чтобы найти желтый красивый среди дерева, seek поиск в желтых липесточках красивых.
Сделайте вычисляемую колонку с хранением(PERSISTED) и сделайте по ней индекс назовите StartWith и сравните с этим полем Users.Where(x=>x.StartWithFromBase==key). Ну или прям на вводе данных выделите эту логику.
Раз у вас така операция произошла то почему бы не разделить эти ключи в отдельное поле? Как так получилось что в реляционном виде вам нужна операция над строками? В общем похоже на ошибку БЛ.
p.s. ещё есть жаркие споры по поводу возможности использовать full text index для такого дела, но я не уверен точно на счет результатов для лайка. Слышал разное мнение.
Drag13 Автор
Нет, ошибки тут нет. Приложение тестовое, и я специально не использовал PK, что бы сильнее нагрузить базу.
Fulborg
Clustered Index — по сути определяет то как данные хранятся на диске, и содержит в себе все данные таблицы. С точки зрения выполнения Scan по нему — это почти аналогично Table Scan'у (который на MSSQL будет только в случае таблицы без кластерного индекса).
Странно что SQL не пытается использовать созданный индекс по DisplayName. Зависит от таблицы, объема столбцов и селективности выборки конечно, но как вариант, для полноты эксперимента — можно попробовать указать его в запросе хинтом принудительно и посмотреть план исполнения. Возможно что-то не так с индексом, и он не подходит для этого запроса.
Drag13 Автор
О как, не знал что скан по кластерному индексу так плох. Спасибо за наводку.
По поводу игнорирования индекса я встречал мнение что при Like запросах индексы не используются, правда встречал и обратные утверждения. Надо будет помучать, еще раз спасибо.
Fulborg
В случае Like — индекс не выйдет использовать, если like написан как «like '%a%'». В случае «like 'a%'» — он может быть использован. Это ограничение исходит из того, что индекс — по сути справочник со ссылками на «части» данных. Для строк — он строится начиная с начала строки, грубо говоря:
— index root.
— s[0]<«n» — go to index_1
— s[0] == «n» — go to index_2
— s[0] > «n» — go to index_3
В случае like %a% — неизвестно с чего начинается строка и SQL не может пойти в нужное поддерево индекса, надо обойти все записи в таблице.
В случае like a% — начало известно, по нему можно отсечь те ветки индекса которые точно не подходят, и проверить только оставшиеся.
andreyverbin
Читайте тут - https://sqlservergeeks.com/sql-server-clustered-index-scan-operator/
mvv-rus
Сложно сказть точно, не имея перед глазами структуры таблицы, но, судя по картинкам, у вас первичный ключ таблицы не DisplayName, по началу (первым 3 символам) которого вы отбираете записи, а некий Users_ID. Если так, то индексно-последовательная структура хранения таблицы (в порядке первичного ключа) ничем вам в отборе нужных записей помочь не может, и Clustered Index Scan — он только называется так красиво, а по сути в данном случае он полностью аналогичен Full Table Scan.
Для оптимизации ваших запросов (на выборку) можно попробовать добавить индекс по DisplayName — благо обновлений этой таблицы у вас, как я понял, нет, а потому и нет накладных расходов на ведение этого индекса (но в реальной жизни они иногда существенны).
При создании БД можно было бы указать EF на необходимость создания этого индекса, добавив атрибут [Index] к свойству DisplayName вашего класса данных (он называется Users, если таблица в БД создавалась с имене по умолчанию).
Поможет ли это добавление при уже созданной базе без выполнения миграции — это я сказать не возьмусь.
PS Посмотреть в плане запроса, используется ли кластерный индекс именно как индекс, можно по свойству Ordered его элемента в плане (в статье по ссылке в комментарии от andreyverbin выше про это хорошо показано)
.
Drag13 Автор
Первичный ключ в таблице просто Id, на DisplayName создан индекс,
Это подтверждается с помощью:
Который показывает наличие двух индексов.
Что касается создания БД - она создавалась из бекапа и только потом создавался контекст.
mvv-rus
Ну да, не видя струтуры базы, ошибиться в предположениях мне было несложно. Тем более, что вы EF используете как database-first, где ytdtljvfz vyt структура БД определяет все.
А почему этот имеющийся индекс по DisplayName не используется в запросах (по плану выполнения это видно) — это я действительно не понимаю.
Впрочем, у планировщика запросов СУБД всегда могут быть свои резоны. Например (но ваш ли это случай — я это утверждать не готов), он не может оценить селективность индекса по начальной подстроке, по которой идет выборка, и действует из наихудшего предположения, что она крайне низкая — а потому последовательный просмотр таблицы лучше и планировщик выбирает его. А не будучи DBA, я даже не знаю, как с этим бороться (и можно ли вобще) в вашей конкретной СУБД.
Drag13 Автор
Я разобрался с планами благодаря вашей подсказке. У меня локально поднято несколько БД, одна из них без индекса, как вы и предполагали. Скриношты планов были сделаны именно нее. А наличие индекса я проверял на облачной БД, там он действительно есть. Сейчас я сделал скриншоты планов из БД в Azure, там совсем другая картина.
Приношу свои извинения за путаницу.
dimuska139
А где тут связь? При использовании StartsWith разве не может быть задействован индекс? Это ж по сути LIKE 'blabla%'. Там ещё вопрос правда в количестве записей. Если их мало, БД может и не использовать индекс, посчитав, что фулскан таблицы будет оптимальнее. По крайней мере, в PostgreSQL так, насчёт MSSQL не знаю.
andreyverbin
StartsWith превратился в какое-то выражение, которое надо вычислить для каждого пялка таблицы. Поэтому индекс тут не поможет.
granit1986
если сделать Like 'blabla%' то поможет
Drag13 Автор
11k это пик, так-то ~6.1k
Возможно это причина почему я не смог загрузить на 100% дорогую базу. В случае когда мы видим полное исчерпание DTU — значит увеличение кол-ва запросов к ней ничего не даст и async нам тут бонусов не даст.
mvv-rus
У автора, судя по всему, кластерный индекс — не по тому полю, по которому происходит выборка: кластерный индекс всегда хранит данные, упорядоченные по первичному ключу (это еще называется индексно-последовательная схема хранения)
Drag13 Автор
До AWS в ближайшее время руки точно не дотянуться. А вот async-и я тестировал на варианте с EF:
Но разницы не увидел. Возможно это связано с тем что мы быстро исчерпывали вычислительную мощность БД и наличие свободных потоков ничего не давало, т.к. им все равно никто не мог ответить.
На самом деле, если заглянуть в код, там есть следы и других тестов, но включать в статью я их уже не стал, она и так вышла поболее чем я ожидал.
А по StackOverflow — у них и кеш есть, и 4 SQL сервера. Я на их фоне как бедный родственник :)