Эта статья ориентирована на начинающих Back-end программистов, в частности на Java, т.к. здесь будет рассмотрен процесс планирования и программирования сервера на Java Spring Boot с базой данных PostgreSQL
Предметом разбора будет выступать моя командная проектная работа за 2-ой курс ВУЗа:
приложение для создания и просмотра артхаусного кино
Приложение взял на себя мой напарник, таким образом, мне ничего не оставалось кроме как смотреть кино обеспечить его сервером
Планирование
Отобрав основной функционал, рождается MVP, цель которого определить интерес пользователей к подобным фильмам
Для реализации этих требований мы решили показать пользователю следующие экраны:
регистрацию/логин
страницу аккаунта
каталог фильмов
страницу с фильмом с плеером
чат для обсуждения
И предусмотреть следующее взаимодействие: добавление фильмов в избранное, комментарии и лайки/дизлайки у комментариев
Дальше вместе с напарником обсудили:
сущности фильма и пользователя
необходимые запросы к сущностям
безопасность
Проговорив всё это, не терпелось приступить к создании архитектуры БД. Для этого понадобилось только знание о типах связей между сущностями [1:1, 1:N, M:N]


Программирование
Я пойду по своему коду в хронологическом порядке

TangoApplication
Точка входа в приложение. В начале тут ничего нет, однако, стоит заметить 1 любопытную деталь: очень многое в Spring Boot делается через аннотации
@SpringBootApplicaion - аннотация, которая создаётся автоматически и конфигурирует настройки по умолчанию
Помимо метода main В этом классе можно определить commandLineRunner, чтобы сделать какие-либо действия при старте сервера, в данном случае там закидываются стартовые значения в базу
@Bean — указывает Spring'у, чтобы он учитывал этот метод у себя под капотом
@Transactional — нужен для методов, содержащих логику работы с базой данных, которая должна быть выполнена от начала и до конца. В случае ошибки, изменения не будут применены
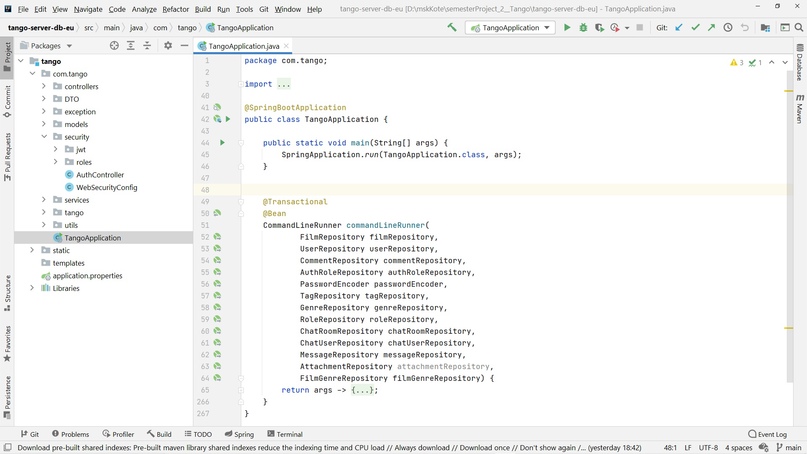
Контроллеры
Это API, к которой будет общаться специалист на Front-end через запросы. Её функционал был определен на этапе планирования
Контроллер на картинке из себя представляет самый обычный класс, со специальной аннотацией @RestController(path="api/common")
Внутри этого класса определяются методы, к которым можно обратиться с определённой целью, на сленге они называются "ручки". Чтобы определить ручку, используется ряд аннотаций для разных типов запросов: @GetMapping,@PostMapping итд
Чтобы использовать их корректно, следует посмотреть такие темы:
типы запросов
принятие аргументов и параметров запроса
получение тела запроса

Стоит вспомнить, что специалист с Front-end пока ничего не получил. И это неудивительно, не была создана ни база данных, ни сущности. Тем не менее, для создания функционала с его стороны не обязательны настоящие данные
Фальшивые данные в нужном формате называются Mock'ом. Можно возвращать заранее сгенерированный объект или, если ответ не большой, поля в подобном виде:
Map<String, Object> response = new HashMap<>();
response.put("message", "Test data");
response.put("number", 1)
return ResponseEntity.ok(response);Не сложно сделать такие заглушки для хотя бы какой-то части API. Развернув сервер, Back-end и Front-end станут менее зависимы друг от друга. Сленг: развёртывание == деплой
Пускай, API известно, однако, фронтендер не станет лезть в код сервера для выяснения вопроса: "Как им пользоваться?"
Нам было удобно держать API в Postman, где я создал коллекцию, в которой содержались запросы со всеми аргументами и их телом

Models
Переходим к самому главному, сущностям и БД
В первую очередь подключаемся к БД. Определяем нужные поля в application.properties и затем, при помощи вкладки Database справа в IntelliJ к самой базе. В community-версии IntelliJ придётся прибегать к помощи других статей/видео для решения этой проблемы

На картинке ниже представлена сущность пользователя
Часть аннотаций здесь от библиотеки Lombok, которая призвана сократить код объекта, тем самым сделав его более читабельным
@Data - определяет getter и setter к каждой сущности, добавляет методы toString, equals, hashcode
@NoArgsConstructor — создаёт конструктор без аргументов

К сущности:
@Entity — обозначается сущность
@Table — таблица
@Data @NoArgsConstructor — аннотации Lombok. Реализуют некоторые методы
@JsonIncude(JsonInclude.NON_NULL) — при сериализации в JSON попадают все поля, которые не NULL
К полю:
@JsonProperty(value="название") — при сериализации будет указывать тебе определённое имя
@Column(name = "колонка") — нужно, чтобы задать название для колонки в базе данных
@Transient — означает, что это поле будет вычисляться во время запроса
К ID:
@Id, @SequenceGenerator, @GeneratedValue — нужно для того, чтобы создать ID
Отношения между сущностями:
@OneToOne, @ManyToOne, @OneToMany, @ManyToMany,
@JsonBackReference, @JsonManagedReference Про@JoinTable и отношения между сущностями лучше прочитать на Baeldung
А как писать запросы к БД PostgreSQL без SQL?
→ Современный подход к построению запросов к базе в Spring Boot реализован через специальные интерфейсы - репозитории
@Repository — указывает на то, что это репозиторий
@JpaRepository<сущность, тип_её_ID> — включает все заготовленные запросы, чтобы обращаться к определённой сущности
Чтобы создавать авторские запросы, нужно в специальном формате называть функции, либо же с помощью аннотации @Query писать SQL
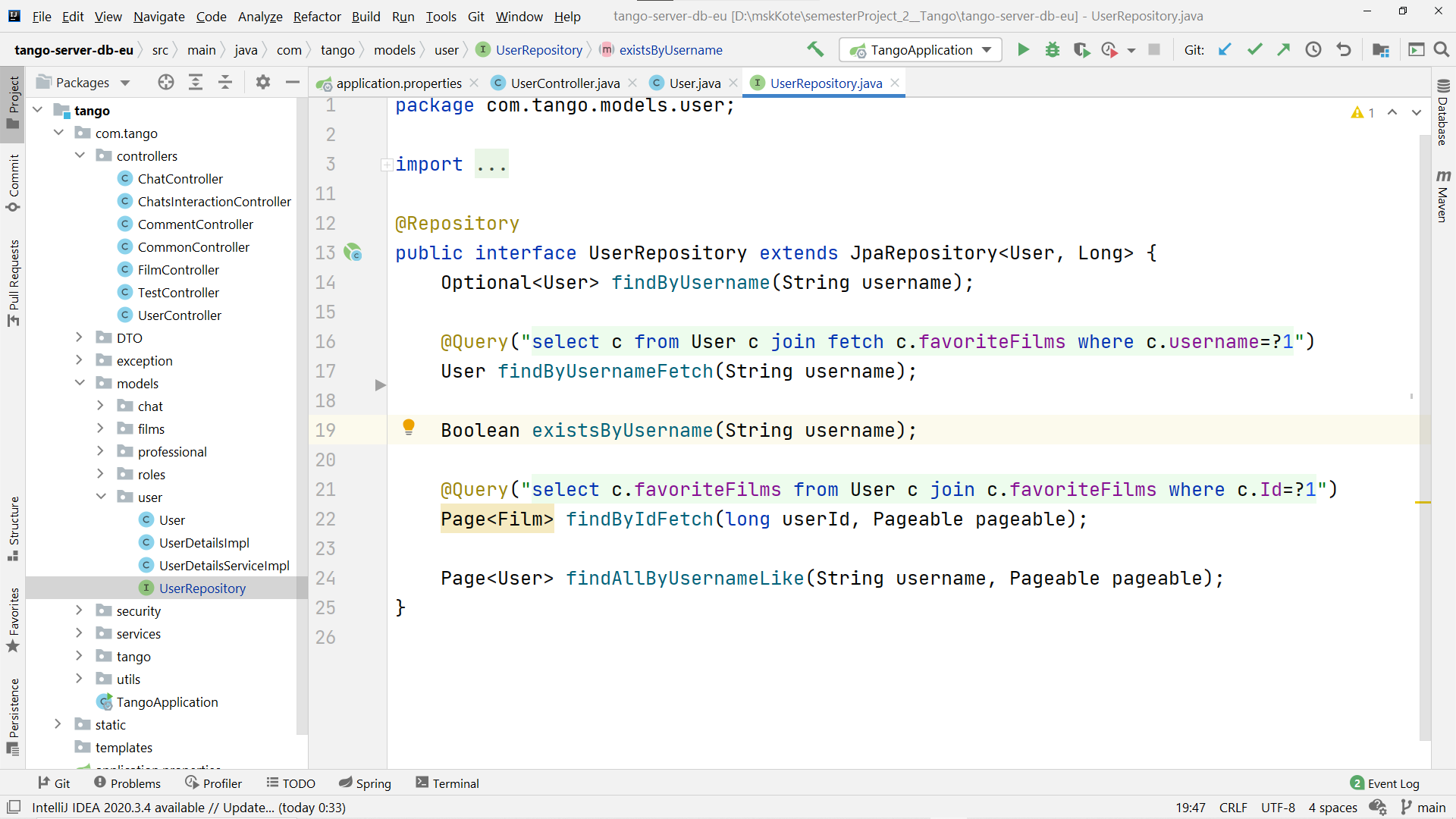
Чтобы сделать пагинацию, нужно использовать Page<сущность> — контейнер для нескольких экземпляров сущности и добавлять в аргументы функции Pageable pageable
DTO
→ Data Transfer Object — нужны, чтобы перекидывать уменьшенные по полям сущностями внутри сервера. Например, оперировать ими в запросах API
Их использование обусловлено тем, что язык типизированный и нельзя налету убрать свойство из объектов
// Пример DTO: Тело запроса на регистрацию
@Data
public class SignupRequestDTO {
private String email;
private String username;
private String password;
private LocalDate date_of_birth;
private LocalDate sub_deadline;
private Set<String> roles;
private String avatar;
public User fromWithoutRoles() {
return new User(email, username, password, date_of_birth, sub_deadline);
}
}Сервисы
В контроллерах слишком громоздко писать логику, поэтому считается правильным держать её в специальных классах с аннотацией @Service и оттуда уже вызывают нужный метод для определённого запроса
Хорошей практикой считается сделать интерфейс с нужными методами рядом с сущностью, а затем написать класс, реализующий этот интерфейс, с постфиксом Impl
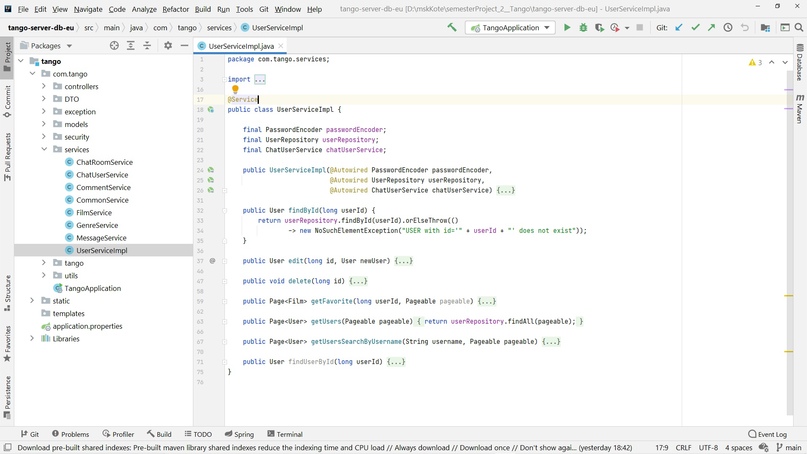
@Autowired — это одна из ключевых концепций Spring «Dependency Injection»: внутри Spring регистрируются все эти зависимости и затем их можно куда-то вставить через аннотацию
Сервисы используют репозитории, либо же более старые вариации логики для запросов к базе
Тесты
В 1 момент я почувствовал, что есть функционал, который я не хочу проверять через запросы. Эта мысль стала отправной точкой к написанию тестов

Безопасность
Тема безопасности невероятно обширна и начать стоит с вопроса: "Какие вообще возможности аутентификации бывают?"
В github репозитории лежит мой вариант имплементации работы с JWT, основанный на добавлении MiddleWare для авторизации
MiddleWare — это функция, в которую попадают запросы, прежде чем оказаться в контроллерах, таким образом, туда удобно положить проверку на JWT-токен
Utils
→ Логика, которая используется в разных местах, но не связана напрямую с сущностями
В проекте я вынес внутреннюю логику зашифровки/расшифровки JWT-токена, функции для загрузки картинок на Imgur
Где хранить секреты?
→ В файлике application.properties
Там определяются константы, к которым можно потом обратиться через аннотацию @Value
Причём сервер может стартовать с определёнными аргументами, которые включают в себя значения для этих самых констант
// Где-либо
@Value("${jwt.jwtSecret}")
private String jwtSecret;
@Value("${jwt.jwtExpirationMs}")
private int jwtExpirationMs;
// В application.properties
jwt.jwtSecret=секрет
jwt.jwtExpirationMs=86400000Заключение
В github-репозитории остался код для некоторого количества незатронутых тем:
Создание сайта чатика на Front-end при помощи JS, CSS и HTML
Чатик на WebSocket со стороны браузера, который правда, мне сейчас не очень нравится
Безопасность с JWT
Свой класс ошибки
Это был общий взгляд на создание небольшого проекта со стороны Back-end.
Комментарии (10)

LeshaRB
28.10.2021 23:54+4Честно не годится даже для учебного материала
Вы описываете модель , для работой с бд. Далее у вас
Data Transfer Object — нужны, чтобы перекидывать уменьшенные по полям сущностями внутри сервера: оперировать ими в запросах / получать из БД и тому подобное
Так что у вас с БД работает? Модели или дто?
@Data @NoArgsConstructor — аннотации Lombok. Реализуют некоторые методы. Какой метод реализует NoArgConstructor? И зачем данная аннотация вам?
Для чего вы используете вместе @Entity и Json аннотации?
ДИ лучше делать через конструктор
И многое другое....

mskKote Автор
29.10.2021 00:25Непосредственно с базой работают Entity и Repository. В моём понимании, DTO нужны для удобства представления данных. Не всегда хочется прокидывать сущность со всеми полями или в случае, когда для запроса понадобилась определённая структура. Я ошибаюсь в этом? UPD: осмотрел проект, в Repository я не использую DTO. Действительно, этот момент был глупостью, вы правы. Изменил этот кусок в статье, спасибо)
NoArgConstructor реализует конструктор без параметров. Требуется, соответственно, для создания экземпляра этого класса
Json аннотации нужны для сереализации, Entity для базы. На ваш взгляд, для каждой сущности стоит выделять отдельную DTO для API? Или каково ваше представление?
ДИ лучше делать через конструктор
Я и так делаю Dependency Injection через конструктор. Насколько я знаю, можно к полю в классе задать аннотацию Autowired, однако, в этом проекте я это вроде не использовал / что, впрочем, не возбраняется

hello_my_name_is_dany
29.10.2021 05:06Так в конструкторе можно и не указывать autowired, как у вас на фото UserServiceImpl
mskKote Автор
29.10.2021 07:43final PasswordEncoder passwordEncoder; final UserRepository userRepository; final ChatUserService chatUserService; public UserServiceImpl(@Autowired PasswordEncoder passwordEncoder, @Autowired UserRepository userRepository, @Autowired ChatUserService chatUserService) { this.passwordEncoder = passwordEncoder; this.userRepository = userRepository; this.chatUserService = chatUserService; }Я не совсем корректно вас понял, в данном конструкторе Autowired указан. Вы имеете ввиду, что его необязательно указывать вовсе? Или что-то иное?


lastrix
29.10.2021 07:53+2Использовать Page нежелательно, потому что это всегда 2 запроса к БД - 1 выбор данных, 2 подсчет числа доступных элементов. В вашем случае нет фильтров, но в если они будут, то можно легко повесить БД под нагрузкой таким образом.
Есть в спринге класс Slice - это тот же Page, но без вычисления количества страниц и элементов, желательно использовать именно его. Работать будет быстрее, а если нужно вычислять количество подходящих страниц и элементов, то фронту лучше делать 1 запрос в специальный эндпоинт для этого.
Правда в спринге как-то странно поддержка этого класса сделана, в последний раз когда с ним работал приходилось делать свою имплементацию репозитория, что бы спеку поддерживать:
@NoRepositoryBean public class JpaSpecificationRepositoryWithSliceImpl<T, ID extends Serializable> extends SimpleJpaRepository<T, ID> implements JpaSpecificationRepositoryWithSlice<T, ID> { private final EntityManager em; public JpaSpecificationRepositoryWithSliceImpl(JpaEntityInformation<T, ?> entityInformation, EntityManager em) { super(entityInformation, em); this.em = em; } @Transactional(readOnly = true) @Override public Slice<T> sliceAll(Specification<T> spec, Pageable pageable) { var list = this.getQuery(spec, pageable) .setFirstResult((int) pageable.getOffset()) .setMaxResults(pageable.getPageSize()) .getResultList(); return new SliceImpl<>(list); } @Transactional(readOnly = true) @Override public Slice<T> sliceAll(Pageable pageable) { var cb = em.getCriteriaBuilder(); var q = cb.createQuery(getDomainClass()); var f = q.from(getDomainClass()); q.select(f); q.orderBy(QueryUtils.toOrders(pageable.getSort(), f, cb)); var list = em.createQuery(q) .setFirstResult((int) pageable.getOffset()) .setMaxResults(pageable.getPageSize()) .getResultList(); return new SliceImpl<>(list); } }Разница между Page и Slice на 1 000 000 элементов даже без фильтров будет весьма ощутимой уже на глаз. В первом случае вся БД всегда читается, во втором только кусочек ограниченный размером страницы.

Capri
30.10.2021 18:31Можно взять любой произвольный класс и представить, что вы принимаете участие в Code Review. Возьмём класс UserServiceImpl. Вопросы:
*Какой интерфейс имплементирует данный класс?
*Почему поля класса package-private?
* Зачем нужна аннотация @Autowired в параметрах конструктора?
mskKote Автор
30.10.2021 22:40Спасибо за code review! Вы указали на ошибки, на которые я бы, вероятно, не обратил внимание в дальнейшем
UserServiceImpl не имплементирует никакой интерфейс/не наследует никакой класс. Под конец работы понял, что это не есть хорошо
Это мой плохой код, нужно добавлять private
В комментариях выше писали о том, что аннотация Autowired необязательна
p-oleg
Безопасность
А почему не Spring Security?
А, посмотрел код, есть.