Надоели нестабильные баги в многопоточном коде? Попробуй воспользоваться модел-чекерами! Ведь больше не надо бояться неверифицированных модел-чекеров, работающих либо за экспоненциальное время, либо неоптимально. Все это в прошлом: в Max Planck Institute for Software Systems разработали новый алгоритм под названием TruSt, который решает эти проблемы и, кроме того, верифицирован на Coq.
Меня зовут Владимир Гладштейн. Этим летом я проходил стажировку в MPI-SWS в группе, которая придумала алгоритм нового модел-чекера для поиска багов в многопоточных программах. Этот алгоритм является оптимальным и truly stateless (вследствие чего работает с линейными затратами по памяти). В этом посте я расскажу, как работают модел-чекеры, в каких случаях их можно использовать, и что за алгоритм придумали мои коллеги. А еще как я проверял доказательства его корректности на Coq.

О себе
Я учусь на 4-ом курсе программы «Математика, алгоритмы и анализ данных» факультета математики и компьютерных наук СПбГУ, а также работаю в Лаборатории языковых инструментов JetBrains Research. Я больше двух лет изучаю формальную верификацию программ и в основном пишу на языке Coq.
О стажировке
Этим летом мне посчастливилось пройти стажировку в Max Planck Institute for Software Systems. Попал я туда неслучайно. Дело в том, что Лаборатория языковых инструментов JBR тесно сотрудничает с этим институтом. В частности, руководитель моей группы Антон Подкопаев был постдоком у профессора MPI Виктора Вафеядиса. Поэтому с рекомендацией от Антона на меня быстро обратили внимание и устроили собеседование с Виктором. В итоге меня зачислили стажером на два месяца — с июля по август 2021 года. Стажировка проходила дистанционно.
О проекте, в котором я работал
В начале лета команда в MPI-SWS, к которой я присоединился, готовилась к подаче статьи на конференцию POPL. Если вкратце, они придумали алгоритм нового модел-чекера (далее МС) для поиска багов в многопоточных программах и предложили мне формально проверить доказательства его корректности на Coq. Этой задачей я и занимался.
Но давайте обо всем по порядку. Начнем с Coq.
O Coq
Coq — это функциональный язык программирования с очень мощной системой зависимых типов. С помощью нее по соответствию Карри-Говарда в Coq удается формулировать и на специальном языке записывать доказательства теорем, которые он сможет проверить. Примеры формулировок теорем в Coq у нас еще будут, а пока, чтобы представлять о чем речь, можно почитать начало мягкого введения. Главное, что тут надо понять — на этом языке можно написать доказательство теоремы, и он его проверит. Среди CS сообщества считается, что теоремы, проверенные на Coq, не содержат ошибок в доказательствах.
О багах в многопоточном коде
Думаю хаброжители знают, что многопоточные программы — это штука сложная. Иногда в них появляются баги, которые очень тяжело отловить тестами. Такие баги могут появляться пару раз на тысячу запусков программы, однако, если ей ежедневно пользуется порядка десяти тысяч человек, то хочется как-то баг отловить и исправить. Одним из решений как раз являются MC.
Давайте разберем пример такой программы. Пример довольно объемный, но он поможет понять, в каких случаях разумно использовать модел-чекеры. Если хотите пропустить пример, жмите сюда.
Представьте себе любимый банк. А теперь представьте, что вас назначили программистом в этом банке и попросили написать код для обслуживания очередей. Человек приходит в банк, берет номерок и ждет своей очереди.
Условно ваша программа должна уметь:
Хранить номер билетика, который будет выдан следующему человеку;
Хранить номер билета человека, которого сейчас обслуживают;
Выдавать новые билеты;
Менять номер обслуживающегося билета.
Давайте попробуем написать такое на C, используя многопоточность. Сначала заведем структуру, описывающую память нашего автомата по выдаче билетов:
struct ticketlock_s {
atomic_int next; // номер билета, который будет выдан следующему человеку
atomic_int owner; // номер билета у человека, которого сейчас обслуживают
};Так как мы будем писать многопоточный код, в котором поля данной структуры будут шариться между потоками, нам необходимо сделать их не просто int, a atomic_int.
Теперь давайте опишем процедуру выдачи билета человеку с его последующим ожиданием своей очереди:
static inline void ticketlock_lock(struct ticketlock_s *l)
{
int ticket = atomic_load(&l->next); // получаем номер следующего билета
atomic_store(&l->next, ticket + 1); // увеличиваем номер следующего билета на 1
while (atomic_load(&l->owner) != ticket) { // человек ждет своей очереди
}
}Теперь можно описать процедуру перехода очереди от одного человека к другому:
static inline void ticketlock_unlock(struct ticketlock_s *l)
{
int owner = atomic_load(&l->owner); // получаем номер обслуживаемого человека
atomic_store(&l->owner, owner + 1); // увеличиваем номер
}Для простоты будем считать, что обслуживание человека заключается в том, что он кладет одну денежку на некоторый счет x, а потом происходит проверка, что значение x действительно увеличилось на один:
int thread(void* unused) {
ticketlock_lock(&lock); // человек получает номерок и ждет
int y = x++; // сохраняем значение x в y и кладем 1 денег на x
assert(x == y + 1); // проверка, что на x было положено 1 денег
ticketlock_unlock(&lock); // зовем следующего
return 0;
}Однако наш банк должен обслуживать много людей, поэтому, чтобы смоделировать его работу, надо запустить процедуру thread в нескольких потоках одновременно:
void test() {
ticketlock_init(&lock); // инициализируем поля нулями
thrd_t threads[N_THREADS]; // создаем несколько потоков
for (int i = 0; i < N_THREADS; ++i) {
int err = thrd_create(&threads[i], thread, NULL); // запускаем во всех потоках thread
if (err) {
abort();
}
}
// сливаем потоки
for (int i = 0; i < N_THREADS; ++i) {
thrd_join(threads[i], NULL);
}
}Как мы хотим, чтобы работала наша программа? Рассмотрим на примере двух потоков (N_THREADS = 2).
Будем придерживаться модели памяти Sequential Consistency (то есть можно считать, что при запуске программы инструкции разных потоков перемешиваются, сохраняя свой порядок внутри одного потока, и запускается однопоточный код).
Допустим в банк пришли Петя (первый поток) и Вася (второй поток). В нормальной ситуации они находятся сначала на строке:
ticketlock_lock(&lock);Предположим, что сначала работает первый поток (то есть Петя первый взял билетик):
int ticket = atomic_load(&l->next);
atomic_store(&l->next, ticket + 1)Он получает билет номер 0, и следующий билет будет уже иметь номер 1. Потом, например, сюда может встроиться Васин (второй) поток и оттуда выполнится три строчки (Вася возьмет свой билет и сядет в очередь):
int ticket = atomic_load(&l->next); // Вася получает билет номер 1
atomic_store(&l->next, ticket + 1); // следующий билет теперь имеет номер 2
while (atomic_load(&l->owner) != ticket) { // owner равен 0, поэтому Вася ждет, пока не продолжит работать Петин поток
}Наконец встраивается первый поток: Петя спокойно перескакивает бесконечный цикл (а не садится туда ждать), потому что номер его билета совпадает с номером билета, который будут обслуживать.
while (atomic_load(&l->owner) != ticket) { // условие не срабатывает, потому что owner = 0, а у Пети как раз билет номер 0
}Далее первый поток выходит из ticket_lock и начинается обслуживание Пети:
int y = x++; // Петя положил денежку на счет x
assert(x == y + 1); // все хорошо: x = 1, y = 0
ticketlock_unlock(&lock); // зовем ВасюТут Васин поток не может никуда встроиться до того, как мы выполним ticketlock_unlock(&lock), потому что пока в Петином потоке не выполнится ticketlock_unlock(&lock), номер Васиного билета (1) не совпадет с номером обслуживаемого человека (0), и Вася не сможет выйти из цикла . Также ясно, что assert не нарушится, потому что сначала Петя увеличит значение x (там будет 1, а в y — 0), потом то же самое сделает Вася.
Это хорошее поведение программы, так как хоть потоки и исполняются параллельно, мы не можем начать обслуживать Васю, пока не закончим обслуживать Петю.
Теперь вопрос: может ли когда-то нарушится проверяемый assert? И ответ: к сожалению, да. На самом деле этот assert нарушается ровно тогда, когда в процесс обслуживания одного клиента встраивается обслуживание другого. Давайте посмотрим, как это может произойти в случае, если у нас два потока.
Предположим теперь, что сначала в первом потоке выполняется первая инструкция ticketlock_lock:
int ticket = atomic_load(&l->next); // Петя получает билет с номером 0Потом сразу вмешивается второй поток, и там выполняются первые две инструкции:
int ticket = atomic_load(&l->next); // Вася тоже получает билет с номером 0
atomic_store(&l->next, ticket + 1); // номер следующего номера теперь 1Наконец, выполняется следующая инструкция первого потока:
atomic_store(&l->next, ticket + 1); // в номер следующего потока снова записывается 1Далее ни один из потоков не зависает в цикле while, и они оба выходят из ticketlock_lock. Это плохо, потому что теперь мы можем случайно начать обслуживать их одновременно, а это иногда приводит к разного рода ошибкам (в частности, нарушения assert’a).
События могут развиваться как-то так: сначала, первый поток продолжает
int y = x++; // Петя положил денежку на счет xТут сразу встроился Вася:
int y = x++; // обслужили Васю: увеличили xИ в итоге в первом потоке в y находится 0, а х уже равен 2, что ведет к невыполнению assert’a.
Ясно, что тут возникла проблема, потому что Вася получил свой билет до того, как наша программа успела до конца обработать получение билета Петей. Поэтому чтобы ее решить, надо просто сделать так, чтобы один поток не мог влезть между двумя инструкциями, отвечающими за выдачу билета, пока их исполняет другой поток. А именно:
int ticket = atomic_load(&l->next);
atomic_store(&l->next, ticket + 1);Для этого можно их объединить в одну атомарную инструкцию:
int ticket = atomic_fetch_add(&l->next, 1);«Плохой» способ выполнения программы происходит достаточно редко, так что тестами его отловить непросто. Именно поэтому тут нужен какой-нибудь другой путь проверки ее корректности.
О Model Checker
Чтобы ловить такие баги, можно использовать MC. Что они делают? Это специальные программы, которые на вход берут ваш многопоточный код и стараются некоторым способом обойти все возможные сцены его исполнения (может быть по модулю некоторой эквивалентности). Для того чтобы понять, как они работают, давайте обратимся к семантике многопоточных программ.
О семантике многопоточных программ
Каждой многопоточной программе можно поставить в соответствие некоторый «граф исполнения». Каждый такой граф описывает определенное множество исполнений программы, ведущих к одному и тому же результату. То есть если у вас есть на руках такой граф, вы можете «почти» сказать, как исполнилась программа, но этого «почти» хватает, чтобы например понять, нарушались ли какие-то assert’ы или нет.
Пример: рассмотрим программу на неком псевдоязыке:
x := 0
x:= 1 || x:= 2
r := x
assert (r!=1)Тут мы сначала записываем в x 0, потом в двух разных потоках пишем 1 и 2, и в конце читаем из x.
Этой программе соответствует несколько «графов исполнения». Например, такой:
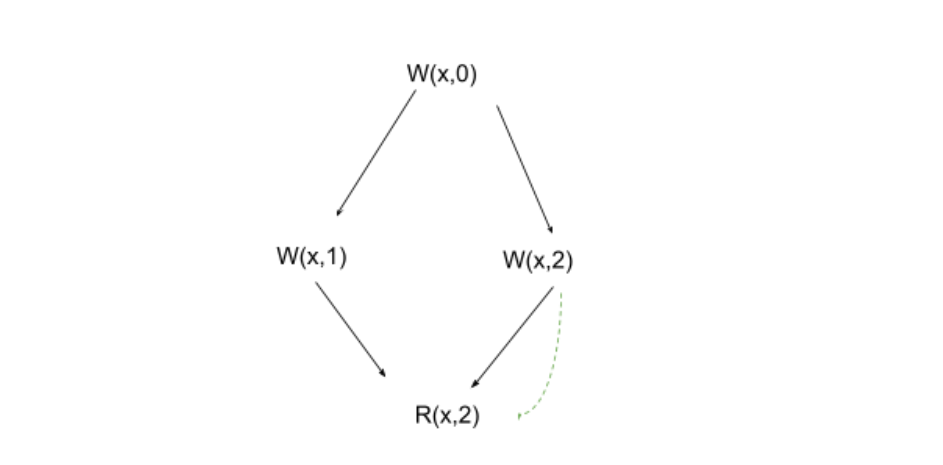
В этом графе есть два типа вершин, они называются событиями:
W(x,i)— запись в переменную x числа i (например, инструкцииx := 0соответствуетW(x,0));R(x,j)— чтение из переменной x числа j (например, если мы вr := xпрочитали 2, то этому будет соответствовать R(x,2)).
И два типа ребер:
Серые — program order. Они соответствуют порядку инструкций (например x:=1 идет после x:=0, поэтому между ними стоит стрелка);
Зеленые — reads from. Они показывают, откуда событие чтения берет свое значение (в данном случает r := x читает из x:= 2).
Смотря на этот граф, легко понять, что assert не срабатывает.
О моделях памяти
Запуская один и тот же код на разных языках или на разных процессорах, мы можем наблюдать разные поведения. Почему так происходит? Дело в том, что над вашим кодом компилятор, а потом и сам процессор могут проявлять разного рода оптимизации. Эти оптимизации изначально были написаны для однопоточного кода, поэтому они могут привести к тому, что программа поведет себя совсем не так как вы хотите (подробнее тут). Ну и отличия в поведениях программ как раз обуславливаются тем, что при разных энвайронментах эти оптимизации разные. Модели поведения многопоточных программ называются моделями памяти (далее MM). Самая простая и известная MM — это Sequential Consistency.
Если мы хорошо изучим конкретную ММ, то сможем по графу исполнения программы говорить, допустим он или нет при данной ММ. Поэтому ММ часто моделируются просто предикатами на графах.
О проблемах model checker
Итак, задача MC заключается в переборе всех возможных графов соответствующих данной программе.
MC можно оценивать по большому количеству параметров, вот три из них:
Оптимальность: так как MC занимается обходом графов, можно говорить, что он оптимален если обходит каждый граф соответствующий программе ровно один раз
Stateless/explicit-state: MC может хранить какие-то данные о графах, которые он уже обошел. Если он вообще никакой информации не хранит, то будем называть его Stateless.
Параметричность по MM: будем говорить, что МС параметричен по MM, если он работает для различных MM. Математически это моделируется так, что MC принимает на вход некоторый предикат на графах исчисления
consи дальше исследует графы, соответствующие этому предикату.
Самые успешные существующие MC являются параметричными по модели памяти, оптимальными и почти Stateless. То есть они не посещают одни и те же графы несколько раз, однако, хранят какую-то информацию о своей предыдущей работе, что ведет к экспоненциальным затратам по памяти.
О TruSt
Наконец, новый алгоритм, который был разработан в MPI-SWS, является первым оптимальным, параметричным по модели памяти и в то же время Stateless (вследствие чего имеет линейные затраты по памяти). Поэтому он и называется TruSt (Truly Stateless).
Tут, однако, стоит отметить, что он работает не для всех моделей памяти, а лишь для тех, которые удовлетворяют некоторым условиям. Сюда подходят такие модели памяти, как Sequential consistency (SC), Total store ordering (TSO) (еще про эту модель можно почитать тут), Partial store ordering (PSO), а также фрагмент модели памяти языка С/С++ (RC11).
MC ищет ошибки в многопоточной программе, но кто гарантирует, что в самом алгоритме МС нет ошибок? Ведь если они есть, model checker может ввести пользователя в заблуждение. Поэтому важно формально верифицировать МС. Как раз этим я и занимался. Я взял псевдокод, на котором алгоритм был представлен в статье, закодировал это в Coq и формально проверил некоторые теоремы о корректности этого алгоритма.
К сожалению, сам алгоритм устроен довольно сложно, и я не смогу его здесь описать. Все подробности можно найти в статье. А сейчас я расскажу достаточно общую схему того, как он был закодирован на языке Coq.
Зафиксируем для начала некоторый предикат модели памяти на графах сons:
procedure Verify(P) // Главная процедура: берет на вход программу P и запускает вспомогательную процедуру Visit
Visit(P, G0) // Visit запускается от нашей программы и пустого графа и рекурсивно исследует все соответствующие графы
procedure Visit(P, G) // описание процедуры исследование графов
if !cons G then return // если граф не удовлетворяет предикату консисетности то выходим из цикла
a := next(P, G) // выбираем какую инструкцию в программе надо исполнить следующей и записываем соответствующее событие a в G
switch a do
case a = ⊥ // если в a ничего не записалось, значит мы исполнили все инструкции
return “OK”
case a ∈ error // если а соответствует нарушению assert’а или какой-то ошибке то вернем сообщение об ошибке
exit(“error”)
… // в иных случаях мы будем хитро рекурсивно вызываться на каких-то других графахПримерно так этот алгоритм и реализован. Посмотрим, как его кодировать в Coq.
Будем говорить, что граф G1 связан отношением ⇒ с графом G2 (и писать G1 ⇒ G2) если Visit(P, G1) вызовет Visit(P, G2) на верхнем уровне рекурсии. Далее введем некоторые обозначения:
G1 ⇒k G2 будет значить, что G1 ⇒ ..k раз... ⇒ G2
G1 ⇒* G2 будет значить, что существует некоторый k такой, что G1 ⇒k G2
О том, что я проверил на Coq
Корректность
Theorem TruSt_Correct : forall G, G0 ⇒* G -> cons G
Эта теорема говорит о том, что если мы за какое-то количество шагов можем дойти из начального графа в граф G, то граф G является консистентным. Эта теорема доказывается тривиально, так как алгоритм явно на каждом шаге проверяет графы на консистентность.
Терминируемость
Theorem TruSt_Terminate : exists B, forall G, G0 ⇒k G -> k < B
Есть некоторая оценка на количество вложенных вызовов рекурсии алгоритма. Тут надо пояснить, что весь этот метод работает только для конечных программ. То есть это должны быть программы без бесконечных циклов и рекурсий (если в нашей программе есть потенциально бесконечный цикл, то мы просто разворачиваем его на наперед заданную глубину и верификация происходит по модулю этой глубины). Далее можно доказать, что есть некоторые события, которые никогда не удаляются (а только добавляются) в ходе рекурсивных вызовов алгоритма. Из этого легко следует терминируемость.
Полнота
Theorem TruSt_Complete : forall G, cons G /\ p_sem G -> G0 ⇒* G
Тут написано, что если
cons G— граф G консистентенp
_sem G— граф G кодирует некоторое исполнение нашей программы,
то мы этот граф встретим на каком-то рекурсивном вызове. То есть эта теорема гарантирует, что мы точно проверим все возможные исходы.
Это одна из самых сложных теорем. Для ее доказательства пришлось построить обратный алгоритм для Visit: Prev. То есть Prev каждому консистентному графу (относительно cons) сопоставляет его непосредственного предка относительно ⇒ (если он существует). Prev получается записать намного проще, чем Visit, более того, он будет детерминированным, так что доказывать теоремы для него проще. Далее показываются две вещи:
если
Prev G = G’, тоG’ ⇒ Gесли
cons Gиp_sem G, то последовательно применяяPrevкGмы всегда придем к пустому графу.
Из этого легко следует теорема.
Оптимальность
В Coq ее сформулировать не очень просто, поэтому покажу схематично. Пусть
G0 ⇒ G1 ⇒ G2 ⇒ … ⇒ Gnесть последовательность шагов из пустого графа в некоторый GnG0 ⇒ H1 ⇒ H2 ⇒ … ⇒ Hnесть последовательность шагов из пустого графа в некоторый Hn иHn = Gn
Тогда и все промежуточные графы тоже будут равны. То есть мы не посетим один и тот же граф два раза.
Эта теорема тоже очень непростая и следует из того, что обратная процедура к Visit детерминирована.
Итоги
В итоге я проверил на Coq полный набор теорем про корректность представленного алгоритма. В ходе этой проверки было:
Найдена куча ошибок и неточностей в доказательствах на бумажке. Некоторые леммы не доказывались в том виде, в котором они были сформулированы, и пришлось придумывать новые формулировки.
Некоторые теоремы (например, теорема об оптимальности) были переформулированы, чтоб точнее ухватить суть вещи, которую мы хотим доказать.
Также в ходе формализации я заметил, что одно место в алгоритме является избыточным, и его убрали. Если вкратце, то в этом месте делалась проверка, которая следовала из других проверок. Так как на корректность алгоритма это не влияло, то понять, что оно лишнее, было непросто. Я заметил, что в доказательствах оно не играет роли, и предложил его убрать.
Заключение
В этом проекте мне пришлось во многом выйти из своей зоны комфорта: я писал его на новом для себя диалекте языка Coq, общался с людьми на английском, пользовался GitLab’ом и т.д... Это однозначно ценный опыт, но самое главное, что мне удалось поработать с мега крутыми специалистами в области Weak Memory. Надеюсь, что я смогу продолжить сотрудничать с ними в будущем. Это была очень крутая стажировка!
Мой код на GitHub
Комментарии (37)

powerman
16.11.2021 22:11-1И всё это из-за того, что кто-то решил писать приложение на C и атомиках. А ведь можно же было взять Go, использовать более высокороувневые примитивы чем атомики, запускать тесты с
go test -race… и скольких проблем бы удалось избежать! :)
sashagil
16.11.2021 22:26+3Скорее, MC полезен для авторов библиотек - тех самых высокоуровневых примитивов. Угадайте, что внутри реализаций высокоуровневых примитивов? Код на Go, высокоуровневые примитивы, вы думаете? И так turtles all the way down? Я так не думаю.
powerman
16.11.2021 22:47-1Ну, вообще-то почти. Внутри примитивов всё ещё код на Go (https://cs.opensource.google/go/go/+/refs/tags/go1.17.3:src/sync/mutex.go;l=72) а под ним буквально 6 строк на ассемблере (https://cs.opensource.google/go/go/+/refs/tags/go1.17.3:src/runtime/internal/atomic/atomic_amd64.s;l=22-36).
Но Вы упустили главное - в конце моего комментария стоял смайлик.
sashagil
16.11.2021 23:01+1Ну вот, 226 строк низкоуровневого Go плюс внизу 6 строк на ассемблере - проверены вручную или формально, разница существенна. Про смайлик - в очном разговоре иронию легче уловить благодаря интонации и мимике, на письме (особенно в общении с случайным собеседником) - сложнее; да, смайлик я пропустил.
Автору - спасибо, интересно - про GenMC раньше не слышал (последний раз искал по теме - нашлись книги по TLA+ и Alloy, довольно старые системы).powerman
16.11.2021 23:28-2Сколько времени займёт формальная проверка всего этого низкоуровневого кода? И сколько времени будет требоваться на её обновление и перепроверку при каждом изменении (в основном - нетривиальных оптимизациях)?
Мне интересна данная тема, но в практическую применимость этого подхода в реальных проектах я не очень верю, даже если это не средний коммерческий
говнокодпроект а вполне себе крутой и вылизанный рантайм языка Go.Точнее, практическая применимость доступная на сегодняшний день - это как раз вышеупомянутый
go test -race. Который работает сам, из коробки, и не требует от разработчиков ни одной лишней строки кода (не считая обычных тестов). Да, его результаты не настолько совершенны, но зато от него уже сегодня есть польза реальным проектам.
northzen
17.11.2021 00:57Здесь был товарищ, который себе на Coq'е, вроде, вполне себе денежку в Америках зарабатывает:
@0xd34df00d
0xd34df00d
17.11.2021 01:21+1Не, я кок вообще не осилил, он странный. Мне как-то больше агды-идрисы ближе, и тут с зарабатыванием денюжки одними ими на самом деле есть некоторые проблемы (компания, готовая платить за идрис и сделавшая мне оффер, закрылась в 2020-м на волне кризиса).
northzen
17.11.2021 01:49Спасибо за комментарий. А могли бы вы подробнее написать, чем занимались, какие задачи решали, и как вы вообще видите рынок труда в этой области сегодня и завтра?
0xd34df00d
17.11.2021 19:32+3Немножко ковырял формальную верификацию всяких трейдинговых стратегий, но там NDA.
Последнее время в основном занимаюсь формализацией одной системы типов (ну там, progress и preservation) плюс доказательством существования её преобразования в обычные завтипы, сохраняющего big-step operational semantics. Но за это мне как-то не особо платят, увы.
Рынок труда и задачи сегодня — скорее академические. Да, есть компании, которые фигачат на коках-агдах что-то в прод (вроде во всяких боингах-BAE было что-то), но в чистом ресёрче больше шансов этим заниматься. Ну и плюс последнее время — блокчейн, там стараются применять формальные методы (например, чуваки из iohk систематически что-то доказывают на агде про свой блокчейн).
Что там будет завтра — не знаю. Мне кажется, что те инструменты, которые есть сегодня — это как ассемблер в обычном программировании в середине прошлого века. Слишком низкоуровнево, слишком много деталей надо выражать явно. Надо пилить инструменты.
sashagil
17.11.2021 01:07+1Я не хотел бы ввязываться в жаркий спор о рантайме Go, с которым я не знаком и не собираюсь знакомиться в ближайшее время. Тем не менее, считаю беседу достаточно содержательной для добавлении ещё одной реплики.
Я бегло просмотрел информацию про "go test -race" - вещь, безусловно, полезная и доступная - однако, насколько я понял, она хороша настолько, насколько хорошо тестовое покрытие. Да, документация с осторожностью рекомендует возможность запускать каких-то случаях (поиск production багов, не пойманных тестами?) и в production - предупреждая, что "The cost of race detection varies by program, but for a typical program, memory usage may increase by 5-10x and execution time by 2-20x."
Насчёт баланса стоимости и эффекта статического анализа: просмотрел довольно объёмную статью про использование MC-анализа для real world проблемы (не вникая в детали - я сам TLA+ не использовал, знаком с этим инструментом вприглядку - но кое-где не очень далеко от моего места работы этот инструмент содержательно использовался). Идёт речь о ловле и исправлении deadlock бага в реализации condition variable в стандартной библиотеке C. Может, вам тоже будет любопытно просмотреть. Стандартная библиотека C - довольно критически важная и стабильная база кода (впрочем, я подозреваю, что корректность реализации mutex.go тоже довольно критически важна, а последнее изменение в mutex.go было внесено 3 года назад). Статья годичной давности: Using TLA+ in the Real World to Understand a Glibc Bug | Probably Dance. Автор, скорее всего, работает в геймдеве, и с проблемой работал не из досужего интереса.powerman
17.11.2021 01:46-1Поправьте меня, если я что-то не так понял, но "применимость в реальном мире" звучит примерно так:
Есть буквально 2-3 экрана кода, где есть сложноуловимый баг, и глазами мы его найти не в состоянии.
Мы тратим дофига времени переводя эти 2-3 экрана кода в запись, которую можно проверить формально…
Профит! Ещё не прошло и месяца, а баг найден.
Если я всё понял правильно, то у меня для Вас плохая новость: обычно есть гораздо более простой способ решения этой проблемы.
Есть две основные причины, по которым баг не получается обнаружить не смотря на все прилагаемые усилия: недостаточная квалификация (из-за которой в голове некорректная картина как всё работает) и неспособность понять весь алгоритм целиком (не влазит в голову). Первая причина лечится обучением (или передачей задачи тому, кто лучше ориентируется в теме). Вторая причина лечится переписыванием алгоритма так, что он стал проще для понимания и поместился в голову. Оба лекарства крайне положительно сказываются и на разработчике и на коде, поэтому я бы не рекомендовал прибегать к формальной верификации кода с целью избежать приёма этих лекарств. :)
northzen
17.11.2021 02:22+1А еще есть алгоритмы, которые целиком в голову не помещаются. Или помещаются, но только в очень умные головы, которые уже нашли применение своим головам где-то в других стратосферах.
powerman
17.11.2021 02:29-2Нету таких. Любой алгоритм можно и нужно декомпозировать до состояния, пока он не поместится в абсолютно среднюю голову. И пока он не помещается - его рано даже начинать кодить!
Что до очень умных голов, то на этот счёт есть очень хорошее наблюдение (цитируя Кернигана): "Отладка кода вдвое сложнее, чем его написание. Так что если вы пишете код настолько умно, насколько можете, то вы по определению недостаточно сообразительны, чтобы его отлаживать.". Так что нет, очень умная голова - это не решение, это плюс ещё одна проблема. Потому что код-то она напишет, а вот что с этим кодом потом дальше делать…
northzen
17.11.2021 04:09+2Если бы отладка была бы сложнее, чем написание, то как бы я смог отладкой довести до ума алгоритмы, которые не осилил написать с первого раза правильно?
sashagil
17.11.2021 02:55+2Что вы, наличие более простого способа решения проблемы - всегда хорошая новость! Жаль, никто не смог в данном случае этого сделать... Так что, увы, хорошей новости не случилось.
В этом случае (deadlock баг в реализации conditional variable в glibc), похоже, простой способ почему-то не сработал. Сложный - сработал. И это не единственный случай, когда для решения реальной проблемы пришлось прибегнуть к сложному способу.
Для меня это (необходимость применения в некоторых сложных случаях сложных способов) - не новость. Для вас - плохая новость?
sashagil
17.11.2021 02:59+1Сожалею, что оставил реплику со ссылкой на статью по проблеме с glibc - получил порцию нотаций от незнакомого человека, которых почему-то решил снисходительно поучить меня жизни и профессии.
Всего доброго.powerman
17.11.2021 05:32+1Я прошу прощения, если Вы так это восприняли - ни нотаций ни снисхождения я в этот комментарий не вкладывал и не имел в виду ничего подобного.
Я действительно пытаюсь разобраться в пределах применимости описанного в статье подхода. Поэтому я и начал с "поправьте меня, если я что-то не так понял" - это была не фигура речи а просьба. Я не владею данным инструментом и действительно могу чего-то важного не понимать - это вообще-то нормально при настолько поверхностном знакомстве, было бы странно, если бы я, наоборот, сходу в нём разобрался.
Тон того комментария действительно провоцирующий, но цель этого не обидеть Вас, а… спровоцировать доказывать свою точку зрения, показать где я неправ, поделиться Вашим опытом. Не на всех это действует именно так, но тут сложно угадать с первой попытки, в каком тоне с кем надо общаться для максимально продуктивной беседы.
На данный момент мне действительно кажется, что сложные для понимания алгоритмы полезнее декомпозировать и упрощать, а не применять ещё более сложные инструменты для компенсации своей неспособности разобраться. И да, я искренне уверен, что декомпозировать и упростить возможно всегда - это не всегда легко получается, но если принять что это обязательно и пока это не будет проделано код писать нельзя - обычно решение находится. И я очень хочу услышать где я ошибаюсь, какие альтернативные подходы в каких ситуациях работают лучше. Ну или не лучше, а просто хоть как-то работают, в отличие от всех остальных подходов включая вышеупомянутый.
Тем не менее, не смею настаивать на продолжении беседы и ещё раз прошу прощения.
sashagil
17.11.2021 07:02+4Хорошо, давайте обсудим, и я извиняюсь за эмоциональность. Давайте оставим в стороне кейс с glibc. Я поясню, почему интересуюсь именно TLA+ (по названию инструмента нашёл кейс).
Один повод - тот факт, что высоконагруженная система не всегда даёт лучшие показатели с высокоуровневыми примитивами параллелизма. Приходится использовать lock-free структуры данных (не знаю, как с ними в Go, на C в стандартную библиотеку не входят), и я не уверен, что мне не придётся ловить / отлаживать баг, подобный описанному в том блог посте про glibc. Да, пока обходился без глубокого знакомства с инструментом, но знаю, что он использовался неподалёку - именно из-за сложностей с редко воспроизводящимися, но причиняющими постоянную боль багами с параллелизмом.
Далее, любопытный фрагмент истории инструмента (тут я могу быть не вполне точным, печатаю без проверки каждого фактоида). TLA+ разработал Лесли Лампорт (автор среди прочего LaTeX, но в данной истори более кстати тот факт, что он автор алгоритма distributed consensus под названием Paxos). Ему нужно было средство автоматической верификации алгоритмов такого рода и, скорее всего, ни одно из существующих на тот момент не подходило. Реализовав инструмент, он написал книгу, поясняя, как им пользоваться (также, как до этого написал книгу про LaTeX). Другой автор продолжил (хоть инструмент старый, недавняя книга вышла в 2018-м). Короче, я решил хотя бы шапочно познакомиться с TLA+, буду готов, если прийдётся применять (ну и, интересная тема - в школе и институте приходилось формально корректно доказывать теоремы на зачёт / сдачу экзамена).
Давайте для проверки тезиса, что алгоритм (довольно базовый - что может быть базовей достижения консенсуса в распределнной системе, да?) такого класса не будет воспринят серьёзно без формальной верификации, рассмотрим более недавнюю альтернативу Paxos-у, Raft. Да, быстро нашлась статья по верификации Raft-а - верифицировали с использованием Coq, кстати (как в работе автора статьи, в комментариях к которой мы находимся).
Нужно ли это программистам в повседневной работе? Хорошо, если нет! Но, когда всё-таки "не повезло" и таки-нужно, улучшение инструментов не помешает.
Вспомнился другой случай, более прозаический - баг в стандартном алгоритме сортировки Python, TimSort (используемом также в Java-системах, в стандартных коллекциях). Баг существовал в коде алгоритма (портированного вместе с багом для Java) лет 12-13, прикидочно. Его нашли и исправили только тогда, когда computer scientist-ы (уровня аспирантов, я так понимаю) попробовали верифицировать алгоритм (в рамках более крупного проекта верификации стандартных библиотек Java). На Хабре были заметки про это, вот, например (переводная): https://habr.com/ru/post/251751/. Баг, скорее всего, проявлялся довольно редко. Тем не менее, лучше всё-таки, если он исправлен, и корректность исправленного алгоритма, наконец, доказана? Это подводит к тезису, что доказывать корректность стабильных базовых библиотек (в частности, реализующих высокоуровневые примитивы для многопоточного программирования) - неплохая идея.
Насколько это дорого? Учёные делают это "за кредиты" (статьи), и при этом улучшают инструменты (о чём статья, в комментариях к которой мы находимся). Иногда за инструмент приходится браться программисту (пример - случай с glibc). Дороговизну применения инструмента в конкретном случае следуют делить на массовость применения проверяемого алгоритма с учётом возможной высокой стоимости его отказа. Иногда знаменатель оказывается достаточно большой.sashagil
18.11.2021 08:33+1Мне стало любопытно - первым делом нашлась документация о том, как это делается с Coq:
https://www.cis.upenn.edu/~plclub/blog/2020-10-09-hs-to-coq/
powerman
17.11.2021 07:59Формальное доказательство алгоритмов вроде Raft и Paxos - это вполне уместное применение, согласен. В основном потому, что алгоритм не меняется с каждым коммитом, и доказать его достаточно один раз. В отличие от конкретной реализации.
Развлечения учёных тоже вполне штатный кейс, там никогда вопрос цены не был определяющим фактором, а шанс на получение практической пользы всегда был довольно непредсказуемым.
А вот для практических задач, включая кейс с glibc - цена явно не выглядит адекватной и подход явно не рекомендован к применению со всеми сложными багами.
Я как-то писал сервис, который тянул миллион одновременных подключений на одном сервере - это было давно, но, если не путаю, то там было достаточно отказаться от совсем уж высокоуровневых примитивов Go (каналов), использовать вместо них обычные мьютексы плюс применить lock striping (названия этой техники я тогда не знал, но идея очевидная и придумалась сама). В целом, по моим наблюдениям, этого подхода хватает с головой для абсолютного большинства задач с высокими нагрузками. Тормоза обычно (по крайней мере, во всех известных мне случаях) вызваны кривым проектированием данных и алгоритмов, а вовсе не тем, что мьютексы не справляются. Я понимаю, что наверняка существует небольшое количество проектов-исключений из вышесказанного, но абсолютное большинство разработчиков с такими никогда не столкнётся.
Иными словами, больше всего пока похоже на то, что знать о возможности что-то формально доказать любопытно, но практическое применение в ежедневной разработке софта для него отсутствует. :(

alsoijw
17.11.2021 11:34Формально доказан анализатор, а не анализируемый софт. Даже если запуск анализатора будет занимать длительное время, его можно запускать для анализа ночных сборок, чтобы не гонять его после каждого коммита.
На данный момент мне действительно кажется, что сложные для понимания алгоритмы полезнее декомпозировать и упрощать, а не применять ещё более сложные инструменты для компенсации своей неспособности разобраться.
Это нужно, чтобы не полагаться на добросовесность разработчиков(вдруг кто-то бекдор послал в виде испралвения?), а так же на то, что разработчики не действовали в спешеке, выспались и так далее.
sashagil
18.11.2021 09:08+2Хорошо. Мы соглашаемся о пользе доказательства правильности каких-то стабильных алгоритмов. Однако, используемые для этого средства приносят пользу и в ежедневной рутине, и я попробую привести простой пример.
Что вы говорите, пишете коллеге, реализовавшем цикл, в котором непонятно, почему произойдёт завершение, и будет ли при завершении гарантирован какой-либо результат?
Используете ли вы в таком случае в диалоге термины вроде "инвариант цикла", "условие завершения"? Не предлагаете ли вы такому коллеге от греха подальше пользоваться более выскоуровневыми конструкциями типа range loop (специально проверил, что в Go есть такой)?
Если да, то - и для вашей практической пользы "учёные развлекались не зря" (какое-то время назад эти понятия не существовали, и какое-то время заняло признание их полезности большинством активных программистов, имеющих дело с циклами).
Однако, у вас где-то проведена черта: до неё учёные развлекались не зря, а после неё - ну вот это уже выпендриваются. И вы считаете, что эта черта должна у всех программистов в голове наличествовать, и проходить достаточно близко к той, которая в голове у вас. Мы зацепились из-за этого, похоже.
Сознаюсь, мой интерес к теме обусловлен тем, что такие темы, как в этой статье, поддерживают мой интерес к профессии в целом. Мотивирую себя чтением интересных мне статей не бросать эту профессию - даже если практического применения в моей сегодняшней работе нет. И, кстати, прогресс наблюдаю - тот же ваш любимый Go с его замечательными высокоуровневыми примитивами не возник бы без предшествующей продуктивной работы учёных и интереса промышленных программистов к их наработкам.
Обратный пример, отрицательный, но он вам должен быть близок. Perl - замечательный язык программирования, с высокоуровневыми конструкциями и компактной записью программ. Практичный (мой любимый пример - в "научной" терминологии ассоциативный массив, словарь или map - честно назван в ядре языка hash, ну чтобы сразу практичному программисту было понятно, что там внутри). У него были замечательные перспективы, активная аудитория практикующих программистов. На нём было легко создавать работающие программы! Более того, этот язык был создан начинающим программистом - и исходя из его практических потребностей (замечу, эта история создания языка программирования отличается от истории создания Go). Когда и что с Perl пошло не так, как вы считаете? Я недавно узнал, язык переименовали... зачем - может быть, чтобы сбросить балласт каких-то отрицательных коннотаций? Но что конкретно?! У вас есть мнение на этот счёт? Мне, честно говоря, Perl не нравился, но я никогда на нём не программировал, так что моё мнение - неквалифицированное. Однако, могу вздохнуть свободно - ныне это название языка могу смело выкидывать из головы (а переименованное даже не трудиться запоминать).
powerman
18.11.2021 16:11Вы не совсем правильно меня поняли. У меня в голове никакой черты в отношении того, стоит ли учёным "развлекаться" нет, слово "развлекаются" описывает их работу без какой-либо отрицательной коннотации. Зря/не зря просто описывает тот факт, что далеко не всегда результат их работы понятно как использовать на практике, но "зря" никоим образом не подразумевает, что "развлекаться" не стоило.
Просто лично меня интересует не процесс и не все подряд результаты, а только те, которые можно применить на практике. Здесь черта действительно есть, но она не про учёных, а про меня - есть ли для меня польза.
Не совсем понял, зачем Вы притянули в это обсуждение Perl. Это был, по тем временам, отличный язык. Просто он был не столько про ясный и надёжный код, сколько про самовыражение. Созданный лингвистом, он в этом плане был намного ближе к обычным языкам, чем большинство других языков программирования. И убили его не проблемы самого языка, а проблемы управления - пока развитие языка определялось его автором (вплоть до Perl 5) всё было отлично, но когда он передал руль коммьюнити, то слишком долго (уже более 20 лет) идёт обсуждение новой версии (Perl 6) без выпуска самой этой версии. За столько лет и язык успел заметно устареть, и многие разработчики (включая меня), так и не дождавшись более современного Perl 6, ушли на другие языки. Это проблема из серии "дорога ложка к обеду", а не про то, как всё разваливается из-за недостатка на проекте учёных.
volodeyka
17.11.2021 11:53+1Мы тратим дофига времени переводя эти 2-3 экрана кода в запись, которую можно проверить формально…
Подождите, а зачем переписывать что-то? Модел-чекер, который я описываю, работает с уже готовым кодом на языках поддерживающих компиляцию в llvm. То есть по факту там надо написать ту же строку по типу `go test -race`
powerman
17.11.2021 20:52О, это уже интересно. Для Go вроде бы есть рабочий компилятор в LLVM https://go.googlesource.com/gollvm. Как будет выглядеть пример использования этого модел-чекера на практике? Допустим, возьмём пример из статьи, напишем на Go, компилируем в LLVM. На выходе в LLVM будет море кода (включая Go-шный рантайм с шедулером горутин, сборщиком мусора, etc.). И вот есть у нас подозрение, что в текущей версии нашего кода есть баг с блокировками. Дальше что нужно делать?
volodeyka
17.11.2021 23:08+2Ну смотрите, конечно, Вам придется один раз немножко поработать, чтоб связать Ваш рантайм и главную процедуру TruSt. В общем случае надо помочь функции
next(см выжимку из алгоритма в посте). Но так как это не совсем связано с темой верификации самого алгоритма и является немного оффтопом здесь, я просто дам ссылку на статью в которой это написано https://plv.mpi-sws.org/genmc/cav21-paper.pdf (страница 6). Эта статья про GenMC -- предыдущую версию TruSt, но часть про поддержку языков с компиляцией в llvm не менялась так что, то что там написано остается релевантным.
volodeyka
17.11.2021 10:45Если честно не совсем понял Ваш комментарии. Используя TruSt проверка низкоуровневого кода займет как раз не очень много времени и памяти. Так что раз в какой-то момент низкоуровневый код нам придется писать, почему бы не воспользоваться хорошим тулом?
Один из поинтов статьи был как раз в том, что появляются новые методы и с ними то, что раньше на практике были неприменимо совершенствуются и становятся все более и более доступным

anonymous
00.00.0000 00:00
JekaMas
17.11.2021 13:56+3И дальше будет "как повезёт". Никаких гарантий отлова состояний гонок race не дает. Кроме того он будет ровно настолько хорош, насколько хороши ваши тесты. И всякие редкие граничные случаи останутся, как правило, жить.
Если надо гарантий, то надо не golang.

WASD1
25.11.2021 23:27Простите, но про вынесенную в заголовок, и самую содержательную \ интересную часть статьи: алгоритм TruSt ничего не написано (к стати и про чекеры моделей - тоже ничего не написано).
Можете в следующих статьях описать?
П.С.
Для примера оставшиеся вопросы:
- Как добились точности (это отсутствие false postitve и false negative ?) вычислительной оптимальности и линейности по памяти?
- Какая она вообще вычислительная оптимальность в этой задаче?
- На коде какой сложности (по числу потоков, ветвлений в потоках) \ размера (понятно, что не очень больших, но каких) алгоритм работает за приемлемое время?
...volodeyka
26.11.2021 13:26Спасибо за Ваш комментарий!
Простите, но про вынесенную в заголовок, и самую содержательную \ интересную часть статьи: алгоритм TruSt ничего не написано
Согласен, в этом плане, может заголовок получился не самым информативным. Однако моей главной задачей было описание верификации данного алгоритма. Остальная информация была дана скорее для того, чтобы было понятно какие конкретно леммы гарантируют корректность алгоритма и как примерно они доказываются.
В этом плане, в основной статье (которая на POPL) про верификацию алгоритма и где конкретно его можно применить написано достаточно мало, так что этот пост скорее надо рассматривать как дополнение к статье, а не попытку перевести ее на русский язык :)
Касательно оставшихся вопросов: все это очень хорошо освещено в основной статье. Но думаю, что если у Вас действительно есть такой запрос, то я могу попробовать, как только будет время, продолжить эту тему (хоть я и не особо вижу смысл в таком дублировании)
PS Я не очень понял чтобы вы хотели услышать про оптимальность? В самом посте описано, что оптимальным алгоритм является, если он не посещает одни и те же графы исполнения несколько раз.
WASD1
26.11.2021 15:32>> Но думаю, что если у Вас действительно есть такой запрос, то я могу попробовать, как только будет время, продолжить эту тему (хоть я и не особо вижу смысл в таком дублировании)
Ну тут сами понимаете: если тяготит - не надо. Если вам интересно написать, думаю найдутся читатели, кому интересно написать.
>> Я не очень понял чтобы вы хотели услышать про оптимальность? В самом посте описано, что оптимальным алгоритм является, если он не посещает одни и те же графы исполнения несколько раз.
Боюсь я вообще ничего не понял начиная вот с этой строчки:a := next(P, G) // выбираем какую инструкцию в программе надо исполнить следующей и записываем соответствующее событие a в G
Какая такая "следующая" инструкция в многопоточном программировании?
Когда сама суть того, что мы проверяем - выполнение констстентности при отсутствии полной упорядоченности инструкций, и отсутствии полной упорядоченности в наблюдаемых эффектах выполнения инструкций.volodeyka
27.11.2021 01:41Какая такая "следующая" инструкция в многопоточном программировании?
Когда сама суть того, что мы проверяем - выполнение констстентности при отсутствии полной упорядоченности инструкций, и отсутствии полной упорядоченности в наблюдаемых эффектах выполнения инструкций.Отличный вопрос! Если думать о том, что потоки в программе упорядоченны слева направо, то в данном месте проще всего считать что
nextпросто выбирает доступную инструкцию в самом правом потоке.
shuhray
А вот Глобуляром овладейте, это гораздо веселее
https://golem.ph.utexas.edu/category/2015/12/globular.html
Я с начала 90-х был увлечён теорией типов. И последнее время ощущение "хватит, так нельзя, это НЕКРАСИВО". С этим бухгалтером мы ещё намучаемся, как сказал Бисмарк, прочитав "Капитал".
youngmysteriouslight
Прошу прощения за лёгкий оффтоп.
Где можно найти живую площадку по этому инструменту? А то начал смотреть и у меня возникли вопросы, например, почему на диаграмме cusp 1 (3-клетка между 2-клетками CupBR и CupRB, которые имеют вид B→R и R→B, соответственно, где B и R — выделенные 1-клетки общей 0-клетки) в режиме Project 1 весь фон, в том числе между CupBR и CupRB, закрашен в красный, то есть в R, а не в синий (B), как того ожидал бы я?
shuhray
Площадку не знаю, но сам автор мне на технический вопрос ответил, можно спросить у него
https://www.cl.cam.ac.uk/~jv258/