Для чего нужен стриминг данных GA в свою базу
Работая с типовыми клиентскими задачами, мы в CreativePeople достаточно быстро столкнулись с ограничениями Google Analytics (версия Universal Analytics), которые не позволяли нам решать их качественно.
Например, на первых этапах работы с проектом нам часто требуются данные о конверсиях по событиям, по которым на проекте не были настроены ранее цели. Или были настроены, но нам нужна конверсия только по некоторым подтипам событий от большой группы, по которой может быть настроена цель.
Это теоретически можно сделать при помощи рассчитываемых показателей в Google Data Studio, но на практике коннектор Universal Analytics к Data Studio начинает сильно искажать данные, занижая размеры выборки, при сложных детальных запросах.
Вот пример данных о числе пользователей по событиям на определенной странице с 8 апреля по 7 июня:

А вот все то же самое, но за больший период времени в запросе — с 9 марта по 7 июня:
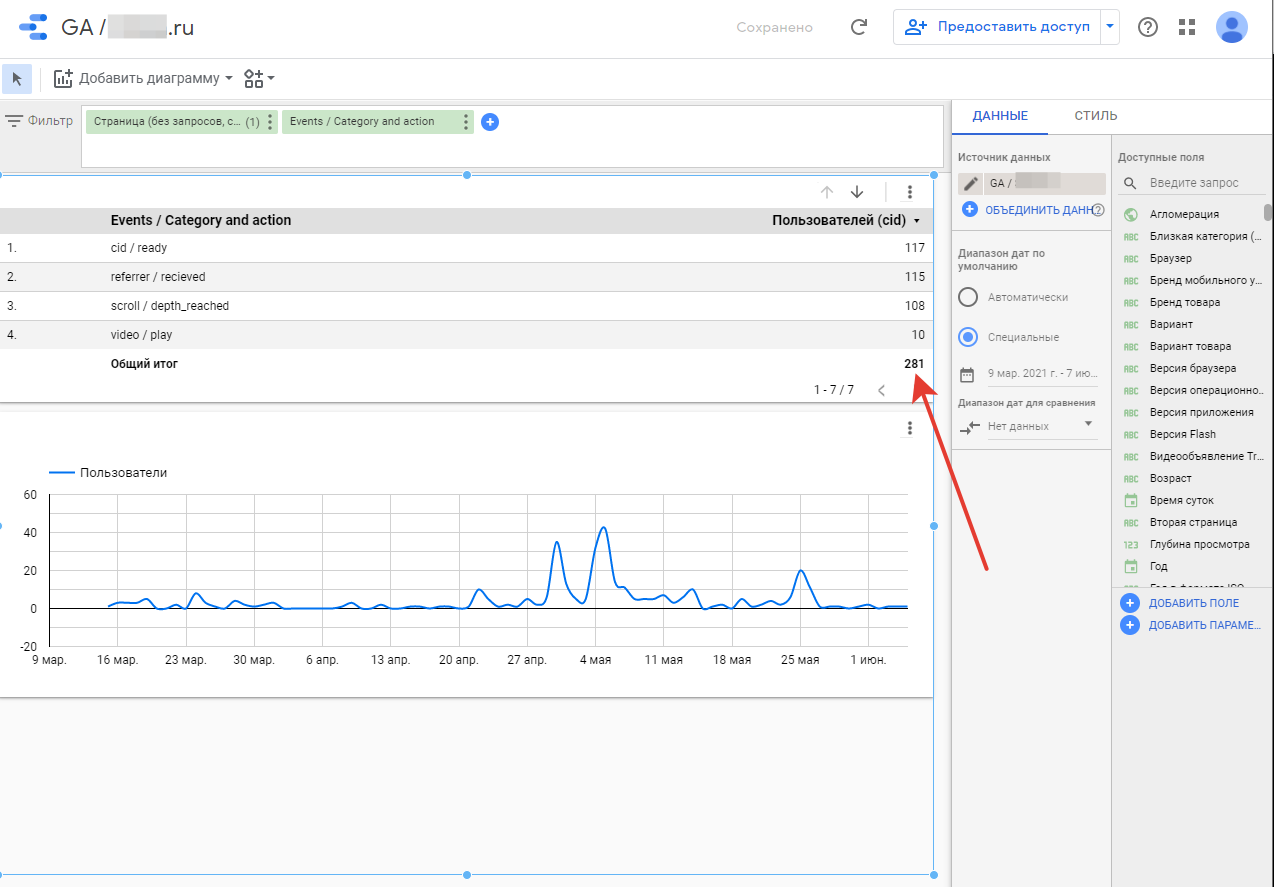
Вторым ярким примером являются ситуации, когда данные необходимо объединить с информацией из внешних источников, например CRM. В этом случае наличие данных в базе становится критичным для получения нормальных результатов при выводе в BI, поскольку никакое моделирование связи сеансов с записи в CRM по более-менее сложным логическим условиям на стороне BI невозможно.
Еще одним важным моментом является возможность работать с историей пользователя в рамках любого ретроспективного окна. В Google Analytics существует ограничение в 90 дней, тогда как в некоторых случаях нам бывает необходимо заглянуть на несколько лет назад для подсчетов кумулятивных итогов.
Это лишь несколько базовых случаев. Их число, наработанное нами за последние годы, значительно больше.
Если обобщить, то в целом стриминг снимает проблему неполноты данных и позволяет работать с информацией гораздо гибче, чем стандартные коннекторы Google Analytics к любым BI-системам.
Как работает стриминг
Стриминг можно организовать и при помощи готовых решений, например OWOX BI. Использование таких сервисов, с одной стороны, избавляет от необходимости построения всей архитектуры и последующего моделирования данных: разбивки строки на параметры, обогащения расчетными показателями и параметрами, группировки в сеансы и т.д. С другой стороны, эти сервисы платные и их стоимость может оказаться заметной для проектов с большой аудиторией.
Для большинства проектов мы используем собственное решение. Оно работает следующим образом.
Прежде чем отправить информацию на точку сбора данных Google Analytics, скрипт GA выполняет серию заданий.
И эти задания можно модифицировать и добавить отправку всех данных, отправляемых на точку сбора данных Google Analytics, на произвольный URL.

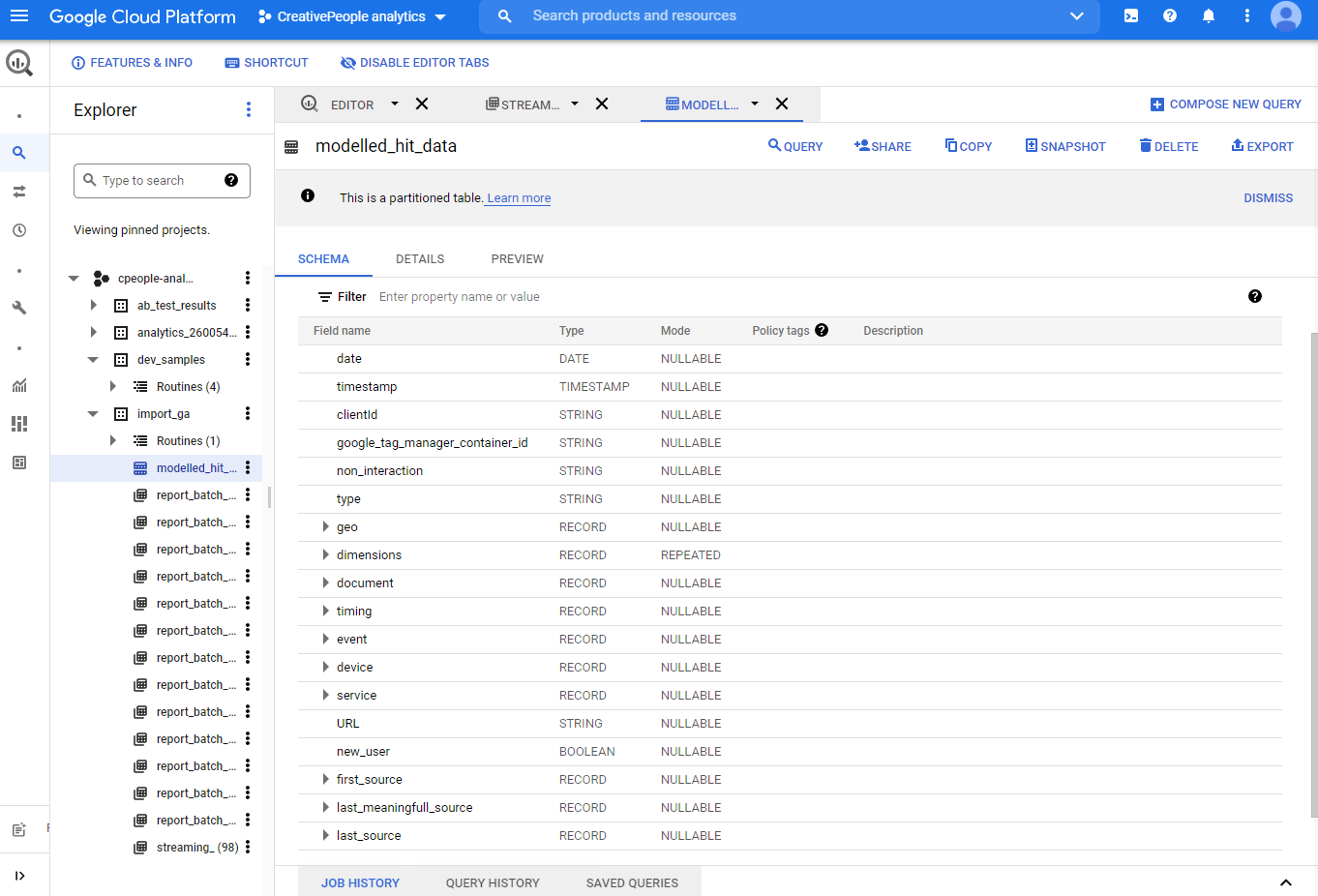
Мы настраиваем собственное решение так: при помощи Google Functions создается endpoint, который принимает get-запрос и, при помощи Streaming API, пишет эти данные и данные http-заголовков в базу Google BigQuery. Дальше эти данные в базе проходят через моделирование, которое из подобных строк стриминга

позволяет получить набор данных для подключения к BI:
Настройка отправки данных в GTM
Все изменения вносятся в customTask (подробнее про работу с customTask можно прочесть в гайде Simo Ahava). Для отправки данных достаточно добавить следующий код:
var custom_tracking_url = 'https://{адрес гуглфукнции для endpoint}',
// добавляем в запрос все данные GA.
// Исходим из того что на объект модели GA ссылается переменная model
hitPayLoad = '?' + model.get('hitPayload'),
// дополняем информацией о user agent
user_agent = '&us_ag='+ encodeURIComponent(navigator.userAgent),
// дополняем информацией о реферерре
referrer = '&ref='+encodeURIComponent(document.referrer),
// добавим данные о размере окна браузера пользователя
window_dimensions = '&wdm='+encodeURIComponent({{User window width}}+'x'+{{User window height}});
// Формируем итоговый url и отправляем.
var final_url = custom_tracking_url + hitPayLoad + user_agent + referrer + window_dimensions;
var xhr = new XMLHttpRequest();
xhr.open('GET', final_url, true);
xhr.send();Иногда, по соображениям безопасности, мы не можем добавлять отправку прямо в customTask. В таком случае мы добавляем в customTask пуш всех данных в dataLayer и на этот пуш добавляем триггер GTM и тег, отправляющий все данные на нашу точку.
Настройка точки сбора данных в Google Functions
Функция реализована на Python с использованием официальной библиотеки Google.
Если не брать в расчет обвес для CORS, то весь функционал умещается в одну функцию:
def stream_bq(uri, headers_json_string):
client = bigquery.Client()
table = client.get_table(f"""{PROJECT}.{DATASET}.{TABLE}""")
content = [{'URL': uri,
'timestamp': datetime.datetime.now(),
'headers': headers_json_string
}]
errors = client.insert_rows(table, content)
print(f"added {content}")
if errors:
logging.error(errors)Весь код функции:
from google.cloud import bigquery
import datetime
import logging
import urllib.parse
import datetime
import json
import re
PROJECT = 'cpeople-analytics'
DATASET = 'import_ga'
TABLE = 'streaming_' + datetime.datetime.today().strftime("%Y%m%d")
def stream_bq(uri, headers_json_string):
client = bigquery.Client()
table = client.get_table(f"""{PROJECT}.{DATASET}.{TABLE}""")
content = [{'URL': uri,
'timestamp': datetime.datetime.now(),
'headers': headers_json_string
}]
errors = client.insert_rows(table, content)
print(f"added {content}")
if errors:
logging.error(errors)
def entry_point(request):
request_host = request.headers["Origin"]
patterns = [r'.+\.cpeople.ru',
r'.+\.devw.cpeople.ru',
r'.+\.devh.cpeople.ru']
matches = [re.match(p, request_host) is not None for p in patterns]
origin = 'https://cpeople.ru'
if any(matches):
origin = request.headers["Origin"]
# Set CORS headers for the preflight request
if request.method == 'OPTIONS':
# Allows GET requests from any origin with the Content-Type
# header and caches preflight response for an 3600s
headers = {
'Access-Control-Allow-Origin': origin,
'Access-Control-Allow-Methods': 'GET',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600'
}
return ('', 204, headers)
# Set CORS headers for the main request
headers = {
'Access-Control-Allow-Origin': origin
}
request_headers_dictionary = {k: v for k, v in request.headers.items()}
if request.url:
stream_bq(request.url, json.dumps(request_headers_dictionary))
return ("Ok", 200, headers)Важно заметить, что, во избежание потерь, мы никак не модифицируем данные, полученные на входе, а просто записываем их в базу. Дальнейшие преобразования происходят уже на стороне моделирования.
Сборка модели в BigQuery
Модель собирается одной процедурой, запускаемой раз в сутки. Мы не будем приводить здесь весь код процедуры, но опишем ее логику.
Сначала данные извлекаются из строки и собираются в структуру. Делается это следующим образом:
1) Для декодирования данных используем функцию:
CREATE TEMP FUNCTION urldecode(url STRING) AS ((
SELECT STRING_AGG(
IF(REGEXP_CONTAINS(y, r'^%[0-9a-fA-F]{2}'),
SAFE_CONVERT_BYTES_TO_STRING(FROM_HEX(REPLACE(y, '%', ''))), y), ''
ORDER BY i
)
FROM UNNEST(REGEXP_EXTRACT_ALL(url, r"%[0-9a-fA-F]{2}(?:%[0-9a-fA-F]{2})*|[^%]+")) y
WITH OFFSET AS i
));2) Для извлечения данных задается еще одна функция:
# Извлекает из строки значение при помощи регулярного выражения.
CREATE TEMP FUNCTION get_value(name STRING, url STRING)
AS (
urldecode(REGEXP_EXTRACT(url, r'[&\?]'||name||'=([^&]+)'))
);3) При помощи перечисленных выше функций из строки извлекаются данные:
# Разбираем URL стриминга на отдельные параметры.
SELECT
PARSE_DATE("%Y%m%d", _TABLE_SUFFIX) as date,
timestamp,
get_value('cid', URL) clientId,
get_value('gtm', URL) google_tag_manager_container_id,
get_value('ni', URL) non_interaction,
get_value('t', URL) type,
STRUCT(
REGEXP_REPLACE( JSON_QUERY(headers, '$.X-Appengine-Country'), '"', "" ) as country,
REGEXP_REPLACE( JSON_QUERY(headers, '$.X-Appengine-Citylatlong'), '"', "" ) as location,
REGEXP_REPLACE( JSON_QUERY(headers, '$.X-Appengine-User-Ip'), '"', "" ) as ip,
REGEXP_REPLACE( JSON_QUERY(headers, '$.X-Appengine-City'), '"', "" ) as city
) geo,
ARRAY(
SELECT AS STRUCT
REGEXP_EXTRACT(dimension, r'(cd\d+)') number,
urldecode(REGEXP_EXTRACT(dimension, r'cd\d+=(.+)$')) value
FROM UNNEST(REGEXP_EXTRACT_ALL(URL, r'[&\?](cd\d+=[^&]+)')) dimension
) dimensions,
STRUCT (
get_value('dt', URL) as title,
get_value('dl', URL) as url,
get_value('ref', URL) as referrer,
get_value('dr', URL) as external_referrer
) document,
...
FROM `cpeople-analytics.import_ga.streaming_*`
WHERE _TABLE_SUFFIX BETWEEN FORMAT_DATE("%Y%m%d", date_start) and FORMAT_DATE("%Y%m%d", date_end)4) Добавляем к ним в подзапросе данные об устройстве пользователя, разбирая userAgent с помощью библиотеки https://github.com/woothee/woothee-js
CREATE TEMPORARY FUNCTION decode_user_agent(ua STRING)
RETURNS STRING
LANGUAGE js AS """ return JSON.stringify(woothee.parse(ua));
"""OPTIONS(library="gs://model_hit_data/woothee.js");Пример того, что вернет функция:
{
"name":"Chrome",
"vendor":"Google",
"version":"91.0.4469.0",
"category":"smartphone",
"os":"Android",
"os_version":"10"
}Далее мы моделируем дополнительные параметры и показатели, которых изначально нет в стриминге, но которые можно получить, имея историю: новизна пользователя, первый источник в рамках установленного ретроспективного окна, последний источник, поcледний значимый и так далее.
Эти параметры и показатели могут вообще не иметь аналогов в Google Analytics, например: статус квалификации пользователя в CRM на момент сессии.
Некоторые вещи отличаются от традиционных из GA. Например, возвраты на сайт в течение дня все еще будут помечены как действия нового пользователя.
Вот пример определения статуса новизны пользователя:
SELECT
DISTINCT date, clientId,
# Если по истории есть данные о пользователе или в стриминге в более ранних датах,
# то помечаем пользователя как вернувшегося new_user = false.
if(new_user_history and new_user_streaming, true, false) new_user
FROM
(SELECT
date, clientId,
# Ищем есть ли в истории данные о clientId:
(
SELECT if(count(m.date) > 0, false, true)
FROM cpeople-analytics.import_ga.modelled_hit_data m
WHERE m.clientId = r.clientId
# берем только ту часть модели, что попадает в ретроспективное окно для поиска статуса пользователя.
and (m.date between DATE_SUB(r.date, INTERVAL days_user_status_retrospective DAY) and DATE_SUB(r.date, INTERVAL 1 DAY))
# также проверяем, чтобы если мы обновляем кусок, который ранее был смоделирован, то мы не брали данные из модели
and (m.date not between date_start and date_end)
) new_user_history,
# Добавим также данные обновляемого/добавляемого куска стриминга за прошедшие дни, если там были ранее упоминания о пользвателе, то
# сегодня он уже стал вернувшимся.
if(FIRST_VALUE(r.date) OVER(PARTITION BY r.clientId ORDER BY date asc) != r.date, false, true) new_user_streaming
FROM raw_streaming rМногие из таких параметров и показателей будут некорректными, если стриминг не включался с самого старта проекта. Чтобы этого избежать, мы выкачиваем исторические данные Google Analytics при помощи Reports API, складываем их в отдельные таблицы

и далее собираем из таких отчетов данные в таблицу со схемой, аналогичной той что получается в процессе моделирования стриминга.
Количественные отличия от данных в Google Analytics
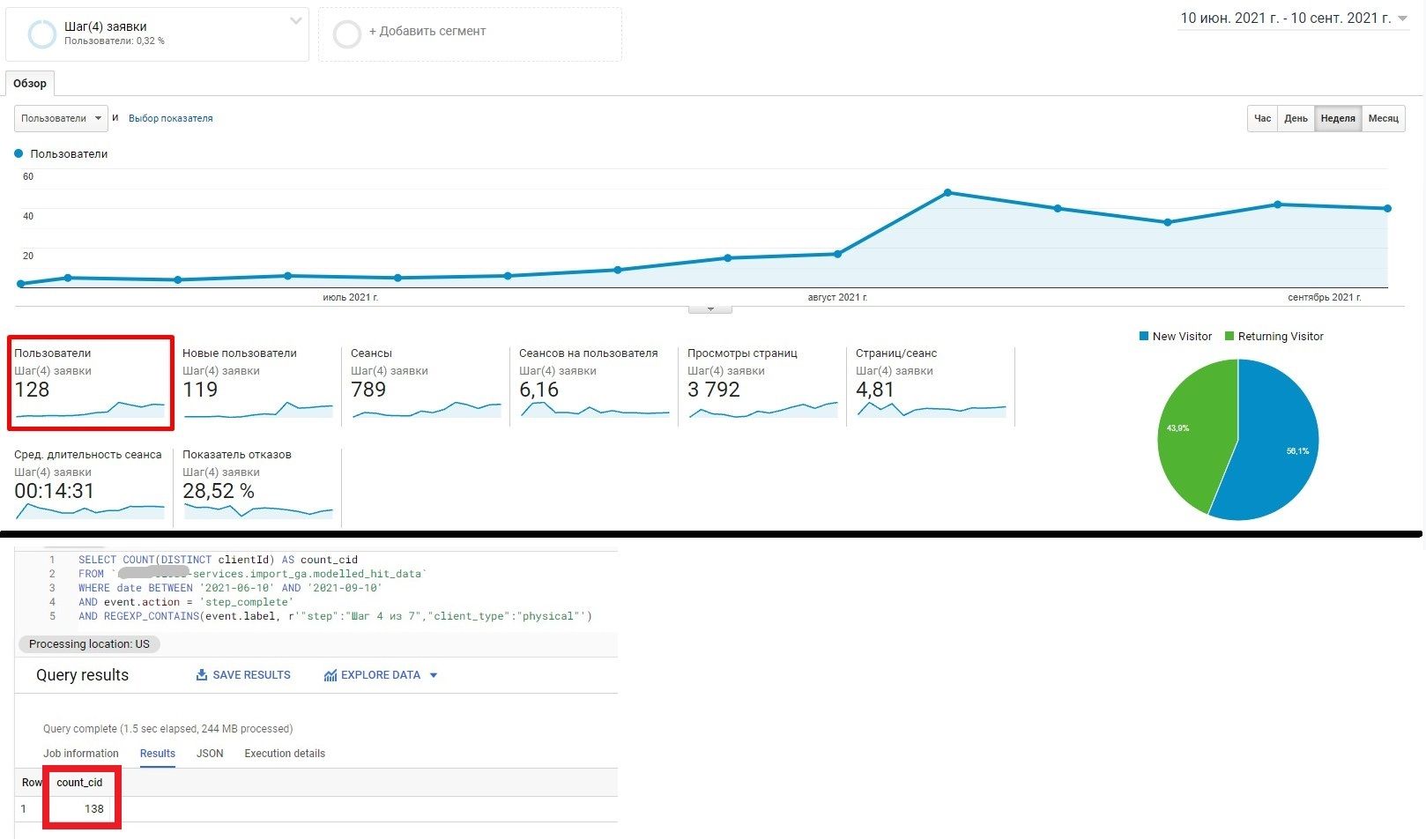
Кроме того что мы получаем данные с бОльшим набором информации, мы также часто видим расхождения в количестве событий и пользователей по событиям между Google Analytics и данными стриминга.
Вот несколько примеров:

Отличия от выгрузки сырых данных Google Analytics 4
В новой версии GA по умолчанию предусмотрен бесплатный экспорт сырых данных в BigQuery. Не прибегая к дополнительным настройкам, не создавая никакой дополнительной инфраструктуры вы получаете все преимущества наличия данных в собственной базе.
Тем не менее, на большинстве проектов мы все же оставляем стриминг даже после перехода на Google Analytics 4.
Связано это со следующими нюансами:
чтобы не упираться в лимиты Google Analytics 4
чтобы иметь доступ к данным, которые не были никем обработаны
чтобы собирать в том числе и те данные, которые запрещено отправлять в Google Analytics по корпоративным правилам безопасности
чтобы использовать данные стриминга для realtime контроля
Здесь особенно важен пункт 3, поскольку точке сбора данных все равно пришла ли информация в виде модели Google Analytics, или это был GET-запрос, который мы сделали отдельно при наступлении определенных событий на сайте.
Более того, в силу особенностей самой GA4, эти данные иногда будут более полными, чем данные стриминга:

Так происходит потому что отправка, зашитая в customTask, целиком зависит от корректной инициализации и исполнения скриптов Google Analytics, которые в версии Universal Analytics иногда подводят в определенных обстоятельствах: в некоторых версиях браузеров, устройств, ос и настроек безопасности браузеров пользователей.
В таких случаях мы все равно инициализируем Google Analytics, но вместо clientId, который в этих обстоятельствах при каждом просмотре страницы будет новый, мы задаем единое значение "everything_blocked".
Потому ключевое изменение, которое предстоит сделать для данного функционала — это перевести отправку из customTask версии Universal в полноценную собственную отправку данных, копирующую отправку в GA4, но, при этом, при невозможности идентифицировать пользователя по cookies и недоступности localStorage, назначать пользователю ID исходя из дополнительных данных об устройстве, IP и локации постфактум при моделировании, что даст возможность более корректно сгруппировать пользователей без clientId.
Это позволит заметно нивелировать потери информации, которые скорее всего присутствуют и в новой версии Google Analytics в том числе.