
За время работы автору довелось использовать многие инструменты анализа, включая Excel, R и Python. Попробовав PostgreSQL и TimescaleDB, автор поняла, насколько простыми могут быть задачи очистки. Делимся подробностями сравнения PostgreSQL и Python из блога TimescaleDB, пока у нас начинается курс по аналитике данных.
Процесс анализа вкратце
Раньше столбцы и значения данных приходилось редактировать вручную. Приходилось извлекать «сырые» данные из CSV-файла или базы данных, а затем изменять их в Python-скрипте.
Приходилось ждать, пока машина настроит и очистит данные. А чтобы поделиться очищенными данными, нужно было запускать скрипт или передавать его другим людям. Но теперь благодаря PostgreSQL я один раз пишу запрос очистки на SQL прямо в базе данных и сохраняю результаты в таблице.
О наборе данных
Бо́льшую часть работы по очистке я проводила после анализа. Но иногда полезно очистить данные, оценить их и снова очистить. Именно с таким случаем мы и будем работать. В одном из наборов данных Kaggle содержатся показания потребления энергии одной из квартир в Сан-Хосе, штат Калифорния. Данные обновляются каждые 15 минут и следуют приблизительно такой схеме:


Вот что приходит в голову первым в смысле очистки:
Тариф — текстовый тип, а это вызовет проблемы.
Столбцы времени и даты разделены, что может вызвать проблемы при создании графиков или моделей на основе показателей времени.
Может понадобиться отфильтровать данные по временным параметрам, например по дню недели или конкретным праздникам (оба параметра влияют на потребление энергии).
К процессу очистки в PostgreSQL можно подойти по-разному: можно создать таблицу, а затем изменить её при очистке, создать несколько таблиц при добавлении или изменении данных или работать с представлениями. В зависимости от размера данных эти подходы могут иметь смысл, но вычисления будут выполнятся по-разному.
Учитывая состояние данных в energy_usage_staging, я решила поместить их в промежуточную таблицу, очистить с помощью представлений, а затем вставить в таблицу поудобнее. Всё это можно сделать до оценки данных.
Часто при работе с большим объёмом данных изменение таблицы в PostgreSQL может оказаться дорогим. Я покажу, как с помощью представлений и дополнительных таблиц создать чистые данные.
Проблемы структуры
Разделённые столбцы даты и времени надо преобразовать в метку времени, а столбец тарифов— в тип float4. Подробности ниже.
Гипертаблицы TimescaleDB, и почему важна метка времени
В основе эффективности запроса данных временного ряда и управления этими данными лежат гипертаблицы TimescaleDB. Они разделяются по столбцу времени, который вы укажете при создании таблицы.
Данные разделяются по метке времени на «куски», так что каждая строка таблицы принадлежит какому-то куску исходя из диапазона. Позже эти куски используются в запросах строк, чтобы запросы и манипулирование данными по времени были эффективнее. Ниже вы видите разницу между обычной таблицей и гипертаблицей:
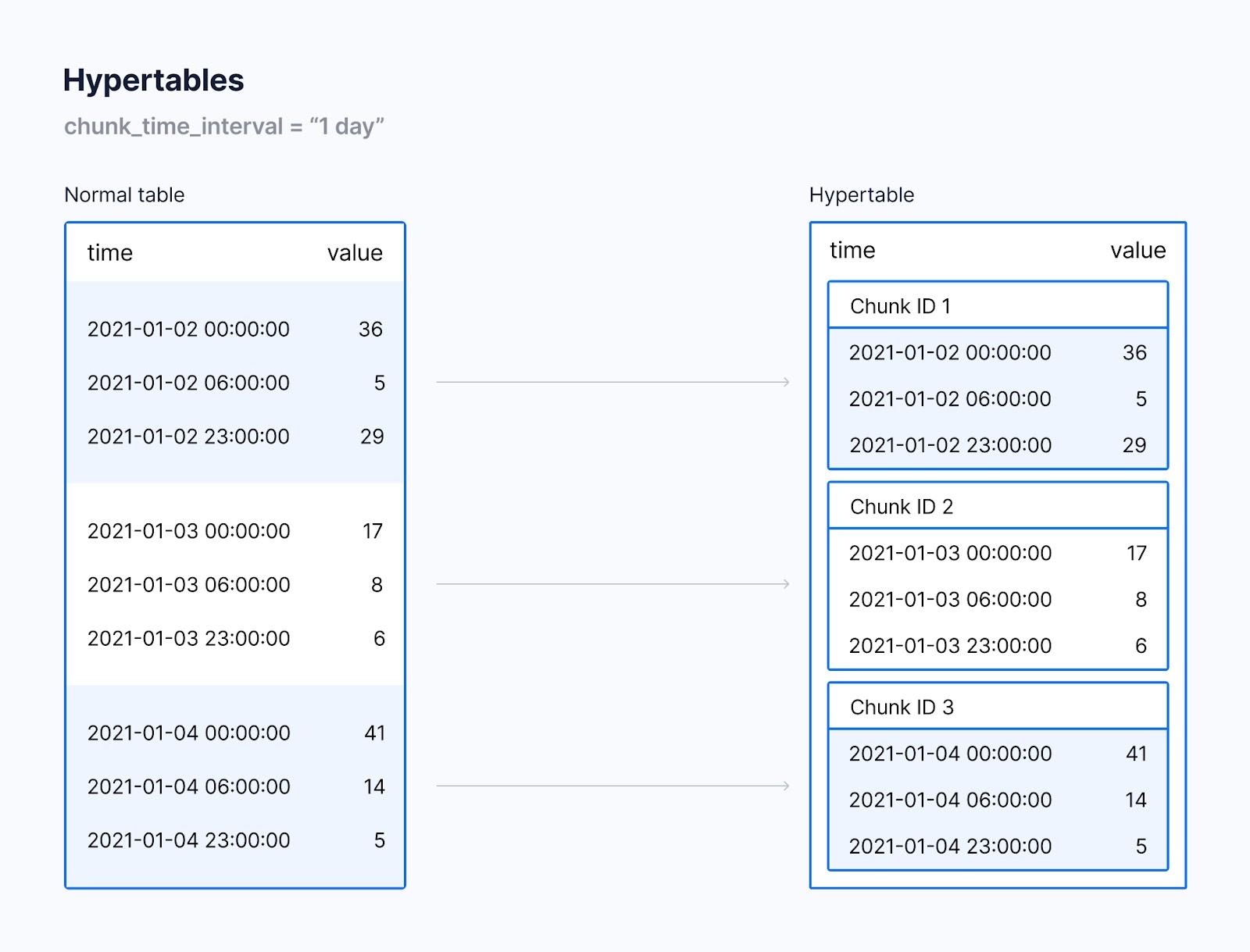
Изменение структуры даты и времени
Чтобы по максимуму использовать функциональность TimescaleDB, например непрерывное агрегирование и ускоренные временные запросы, надо поменять структуру столбцов даты и времени в таблице energy_usage_staging.
Для разделения гипертаблицы можно использовать столбец даты, но тогда будет ограничен контроль над данными по времени. Один столбец с меткой времени даёт больше гибкости и экономит пространство эффективнее, чем отдельные столбцы с датой и временем.
Структура таблицы должна быть такой, чтобы из столбцов date и start_time можно было получать полезное значение метки времени: end_time не даёт столько информации. Иными словами, надо объединить эти два столбца в один с метками времени.
В PostgreSQL можно создать столбец, не вставляя его в базу данных. Поэтому, чтобы создать из этой промежуточной таблицы новую таблицу, добавлять дополнительные столбцы или таблицы пока не нужно. Сначала сравним исходные столбцы с вновь сгенерированным. Для этого просто добавим один столбец к другому. Ключевое слово AS позволяет переименовать столбцы в time.
--добавляем дату в столбец start_time
SELECT date, start_time, (date + start_time) AS time
FROM energy_usage_staging eus;Результаты:

В Python с этой же целью проще всего добавить новый столбец во фрейм данных. Нужно конкатенировать два столбца вместе с определённым пространством, а затем преобразовать этот столбец в datetime.
energy_stage_df['time'] = pd.to_datetime(energy_stage_df['date'] + ' ' + energy_stage_df['start_time'])
print(energy_stage_df[['date', 'start_time', 'time']])Изменение типов данных столбцов
Благодаря функции TO_NUMBER() в PostgreSQL это просто.
Формат функции такой: TO_NUMBER('text', 'format'); format — это специальная строка PostgreSQL, которая создаётся в зависимости от типа текста. Мы имеем дело с символом $ и числовым набором 0,00. Строка формата будет такой: 'L99D99'. L сообщает PostgreSQL, что в начале текста есть символ денег, 9-ки — что есть числовые значения, а D отделяет целую часть от десятичной.
Преобразование ограничим значениями не больше 99,99, поскольку в столбце тарифов нет значений больше 0,65. А что если надо преобразовать столбец с большими числовыми значениями? Тогда добавляем G для запятых.
К примеру, есть столбец тарифов с текстовыми значениями 1,672,278.23. Тогда отформатируем строку так: L9G999G999D99.
--создаём новый столбец cost_new с функцией to_number()
SELECT cost, TO_NUMBER("cost", 'L9G999D99') AS cost_new
FROM energy_usage_staging eus
ORDER BY cost_new DESCРезультаты:
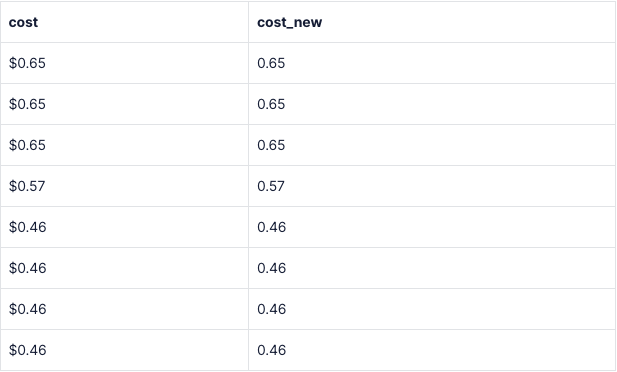
Код на Python:
energy_stage_df['cost_new'] = pd.to_numeric(energy_stage_df.cost.apply(lambda x: x.replace('$','')))
print(energy_stage_df[['cost', 'cost_new']])В случае Python используем лямбда-функцию, которая заменяет все знаки $ пустыми строками. И это снова может быть неэффективно.
energy_stage_df['cost_new'] = pd.to_numeric(energy_stage_df.cost.apply(lambda x: x.replace('$','')))
print(energy_stage_df[['cost', 'cost_new']])Представления PostgreSQL
Представление — это объект PostgreSQL, который позволяет определять запрос и вызывать его по имени представления, как если бы это была таблица БД. Сгенерируем данные и создадим представление:
--запрашиваем нужные данные
SELECT type,
(date + start_time) AS time,
"usage",
units,
TO_NUMBER("cost", 'L9G999D99') AS cost,
notes
FROM energy_usage_stagingРезультаты:
Назовём наше представление energy_view, а при последующей очистке просто укажем его имя в операторе FROM.
--из запроса выше создаём представление
CREATE VIEW energy_view AS
SELECT type,
(date + start_time) AS time,
"usage",
units,
TO_NUMBER("cost", 'L9G999D99') AS cost,
notes
FROM energy_usage_stagingКод Python:
energy_df = energy_stage_df[['type','time','usage','units','cost_new','notes']]
energy_df.rename(columns={'cost_new':'cost'}, inplace = True)
print(energy_df.head(20))Важно: данные внутри представлений PostgreSQL должны пересчитываться при каждом запросе. Вот почему надо вставлять данные представления в гипертаблицу, как только они подготовлены.
Cоздание или генерирование необходимых данных
Столбец примечаний (notes) в этом наборе пуст. Чтобы проверить это, просто включаем оператор WHERE и указываем, где notes не равны пустой строке.
SELECT *
FROM energy_view ew
-- когда notes — не пустые строки
WHERE notes!='';И код на Python:
print(energy_df[energy_df['notes'].notnull()])Столбец примечаний пуст, поэтому заменим его различными наборами дополнительной информации, чтобы использовать эту информацию при моделировании.
Добавим столбец дня недели при помощи EXTRACT() — функции даты/времени PostgreSQL, которая позволяет извлекать из даты и времени различные элементы. У наших колонок в PostgreSQL есть обозначение дня недели DOW (day-of-week): 0 — это воскресенье, а 6 — суббота.
-- извлекаем day-of-week from date и приводим вывод к int
SELECT *,
EXTRACT(DOW FROM time)::int AS day_of_week
FROM energy_viewРезультаты:
Код Python:
energy_df['day_of_week'] = energy_df['time'].dt.dayofweekМожно добавить столбец, где указывается, приходится ли день на выходные или будни. Для этого воспользуемся оператором CASE:
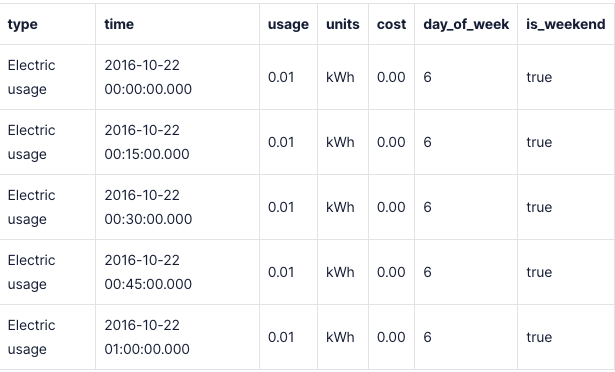
SELECT type, time, usage, units, cost,
EXTRACT(DOW FROM time)::int AS day_of_week,
-- --используйте оператор case, чтобы сделать столбец истинным, если записи выпадают на выходные дни и 6
CASE WHEN (EXTRACT(DOW FROM time)::int) IN (0,6) then true
ELSE false
END AS is_weekend
FROM energy_view ewРезультаты:
Интересный факт: тот же запрос можно выполнить без CASE, но только для столбцов с двоичными данными.
--другой метод создания столбца с двоичными данными
SELECT type, time, usage, units, cost,
EXTRACT(DOW FROM time)::int AS day_of_week,
EXTRACT(DOW FROM time)::int IN (0,6) AS is_weekend
FROM energy_view ewКод Python:
energy_df['is_weekend'] = np.where(energy_df['day_of_week'].isin([5,6]), 1, 0)
print(energy_df.head(20))Обратите внимание: в Python выходные представлены числами 5 и 6, а в PostgreSQL — числами 0 и 6.
А что, если добавить другие параметры? Например, праздники. Люди в праздники чаще всего не работают и проводят время дома, а значит, в эти дни потребление энергии может быть другим. Поэтому включим в анализ определение праздников. Для этого создадим ещё один столбец логических значений, который определяет наступление национального праздника. Для этого используем функцию TimescaleDB time_bucket().
Эта функция нужна, чтобы гарантировать, что учитываются все значения времени за день. Создав таблицу праздников, используем данные из неё в запросе без оператора CASE, но можно написать запрос и с ним.
--создаём таблицу для праздников
CREATE TABLE holidays (
date date)
--вставляем праздники в таблицу
INSERT INTO holidays
VALUES ('2016-11-11'),
('2016-11-24'),
('2016-12-24'),
('2016-12-25'),
('2016-12-26'),
('2017-01-01'),
('2017-01-02'),
('2017-01-16'),
('2017-02-20'),
('2017-05-29'),
('2017-07-04'),
('2017-09-04'),
('2017-10-9'),
('2017-11-10'),
('2017-11-23'),
('2017-11-24'),
('2017-12-24'),
('2017-12-25'),
('2018-01-01'),
('2018-01-15'),
('2018-02-19'),
('2018-05-28'),
('2018-07-4'),
('2018-09-03'),
('2018-10-8')
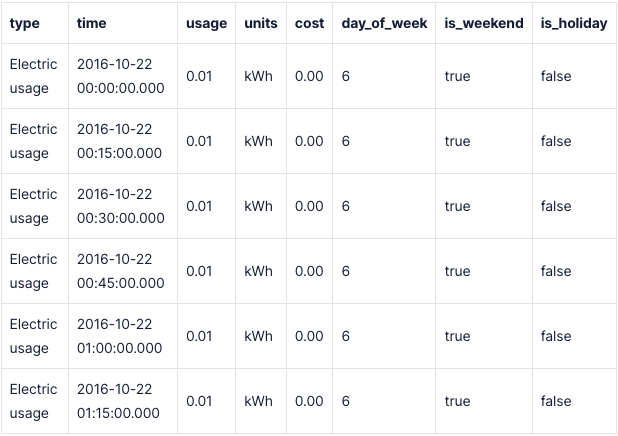
SELECT type, time, usage, units, cost,
EXTRACT(DOW FROM time)::int AS day_of_week,
EXTRACT(DOW FROM time)::int IN (0,6) AS is_weekend,
-- Затем я могу выбрать данные из таблицы прямо внутри IN
time_bucket('1 day', time) IN (SELECT date FROM holidays) AS is_holiday
FROM energy_view ewРезультаты:
Код Python:
holidays = ['2016-11-11', '2016-11-24', '2016-12-24', '2016-12-25', '2016-12-26', '2017-01-01', '2017-01-02', '2017-01-16', '2017-02-20', '2017-05-29', '2017-07-04', '2017-09-04', '2017-10-9', '2017-11-10', '2017-11-23', '2017-11-24', '2017-12-24', '2017-12-25', '2018-01-01', '2018-01-15', '2018-02-19', '2018-05-28', '2018-07-4', '2018-09-03', '2018-10-8']
energy_df['is_holiday'] = np.where(energy_df['day_of_week'].isin(holidays), 1, 0)
print(energy_df.head(20))Пока сохраним эту расширенную таблицу в другом представлении, чтобы воспользоваться представлением позже.
--создаём другое представление с данными из первой очистки
CREATE VIEW energy_view_exp AS
SELECT type, time, usage, units, cost,
EXTRACT(DOW FROM time)::int AS day_of_week,
EXTRACT(DOW FROM time)::int IN (0,6) AS is_weekend,
time_bucket('1 day', time) IN (select date from holidays) AS is_holiday
FROM energy_view ewВы спросите: «Зачем создавать столбцы логических значений?». Для фильтрации. В PostgreSQL благодаря логическим столбцам очень легко фильтровать данные. Например, если нужно показать данные только за выходные и праздничные дни, добавим WHERE вместе с указанными столбцами.
--если используете столбцы с двоичными данными, то фильтровать их можно простым WHERE
SELECT *
FROM energy_view_exp
WHERE is_weekend AND is_holidayРезультаты:

Код Python:
print(energy_df[(energy_df['is_weekend']==1) & (energy_df['is_holiday']==1)].head(10))
Добавление данных в гипертаблицу
Подготовив новые столбцы и организовав таблицу, создадим новую гипертаблицу и вставим очищенные данные.
CREATE TABLE energy_usage (
type text,
time timestamptz,
usage float4,
units text,
cost float4,
day_of_week int,
is_weekend bool,
is_holiday bool,
)
--команда создания гипертаблицы
SELECT create_hypertable('energy_usage', 'time')
INSERT INTO energy_usage
SELECT *
FROM energy_view_expВ случае работы с постоянно поступающими данными можно создать скрипт, который при импорте данных автоматически вносит эти изменения.
Переименование значений
Ещё один ценный метод очистки данных — переименование элементов или повторное отображение категориальных значений.
Его важность подчёркивается популярностью вопроса об анализе данных Python на StackOverflow: «Как во фрейме Pandas поменять одно значение индекса». PostgreSQL и TimescaleDB используют структуры реляционных таблиц, поэтому переименовывать уникальные значения просто.
Определённые значения индекса в таблице переименовываются «на лету» через CASE внутри SELECT. Например, поменяем 0 воскресенья в столбце day_of_week на 7 :
SELECT type, time, usage, cost, is_weekend,
-- чтобы переписать значения, можно воспользоваться CASE
CASE WHEN day_of_week = 0 THEN 7
ELSE day_of_week
END
FROM energy_usageВнимание: код ниже сделает понедельник равным 7, потому что в функции DOW (day-of-week) Python значение понедельника 0, а воскресенья — 6. Но так и обновляется одно значение в столбце. При этом обновлять значения, скорее всего, не придётся, а эквивалент на Python показан просто для справки.
energy_df.day_of_week[energy_df['day_of_week']==0] = 7
print(energy_df.head(250))А если вместо числовых значений использовать названия дней недели? Убираем CASE и создаём таблицу сопоставления. При изменении различных значений будет эффективнее создать её, а затем объединиться с ней командой JOIN.
--создаём таблицу
CREATE TABLE day_of_week_mapping (
day_of_week_int int,
day_of_week_name text
)
--затем добавляем в неё данные
INSERT INTO day_of_week_mapping
VALUES (0, 'Sunday'),
(1, 'Monday'),
(2, 'Tuesday'),
(3, 'Wednesday'),
(4, 'Thursday'),
(5, 'Friday'),
(6, 'Saturday')
--объединяем её с таблицей очистки для повторного отображения дней недели
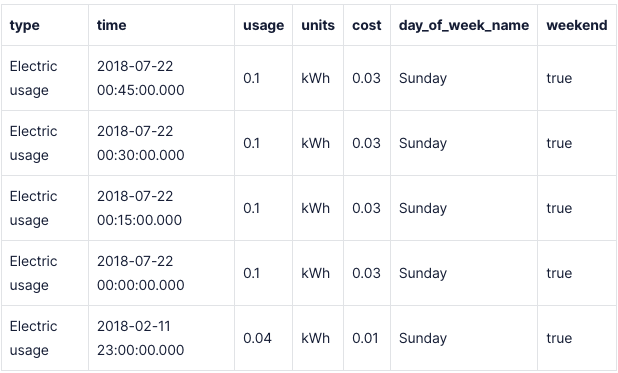
SElECT type, time, usage, units, cost, dowm.day_of_week_name, is_weekend
FROM energy_usage eu
LEFT JOIN day_of_week_mapping dowm ON dowm.day_of_week_int = eu.day_of_weekРезультаты:
Аналогичные функции отображения есть в Python.
energy_df['day_of_week_name'] = energy_df['day_of_week'].map({0 : 'Sunday', 1 : 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday'})
print(energy_df.head(20))Кроме того, помните: поменять название столбца в таблице можно при помощи оператора SELECT.
SELECT type AS usage_type,
time as time_stamp,
usage,
units,
cost AS dollar_amount
FROM energy_view_exp
LIMIT 20;Результаты:

SQL здесь быстрее и элегантнее. На Python переименование столбцов может стать большой проблемой.
energy_df.rename(columns={'type':'usage_type', 'time':'time_stamp', 'cost':'dollar_amount'}, inplace=True)
print(energy_df[['usage_type','time_stamp','usage','units','dollar_amount']].head(20))Заполнение недостающих данных
Другая проблема в процессе очистки данных — это их отсутствие. В нашем наборе нет явно отсутствующих точек данных, но наверняка найдутся недостающие данные по часам, возникающие из-за отключения электроэнергии или других обстоятельств. Здесь и пригодятся функции заполнения TimescaleDB.
Недостающие данные часто оказывают большое и негативное влияние на точность или надёжность модели. Иногда проблема решается заполнением недостающих данных данными, которые получены обоснованными оценками. Чтобы получить такие данные, TimescaleDB предоставляет встроенные функции.
Например, при моделировании потребления энергии в отдельные дни недели по некоторым дням из-за отключения электроснабжения или проблем с датчиком данных нет. Данные можно удалить или заполнить недостающие значения обоснованными оценками.
Для примера я создала данные и назвала таблицу energy_data. В ней нет показаний времени и энергии между 7:45 и 11:30 утра.
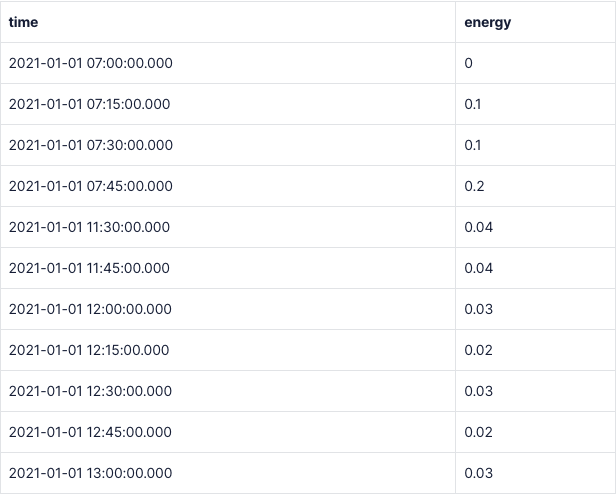
Чтобы добавить эти недостающие значения, используем гиперфункции TimescaleDB; interpolate() — ещё одна гиперфункция TimescaleDB. Она создаёт точки данных, которые следуют линейной аппроксимации с учётом точек данных до и после отсутствующего диапазона.
Есть альтернативная гиперфункция locf(), которая переносит последнее записанное значение вперёд, чтобы заполнить пробел (locf так и расшифровывается: last-one-carried-forward, т. е. «последнее переносимое вперёд»). Обе гиперфункции должны использоваться вместе с time_bucket_gapfill().
SELECT
--новые данные должны появляться каждые 15 минут
time_bucket_gapfill('15 min', time) AS timestamp,
interpolate(avg(energy)),
locf(avg(energy))
FROM energy_data
--чтобы использовать gapfill, придётся удалять любые данные времени, связанные со значениями null. Сделать это можно с помощью оператора IS NOT NULL
WHERE energy IS NOT NULL AND time > '2021-01-01 07:00:00.000' AND time < '2021-01-01 13:00:00.000'
GROUP BY timestamp
ORDER BY timestamp;Результаты:

Код Python:
energy_test_df['time'] = pd.to_datetime(energy_test_df['time'])
energy_test_df_locf = energy_test_df.set_index('time').resample('15 min').fillna(method='ffill').reset_index()
energy_test_df = energy_test_df.set_index('time').resample('15 min').interpolate().reset_index()
energy_test_df['locf'] = energy_test_df_locf['energy']
print(energy_test_df)Следующий вопрос: как игнорировать отсутствующие данные. Я покажу, как легко исключить данные с NULL.
SELECT *
FROM energy_data
WHERE energy IS NOT NULLМожно также использовать оператор WHERE, чтобы указать игнорируемое время.
SELECT *
FROM energy_data
WHERE time <= '2021-01-01 07:45:00.000' OR time >= '2021-01-01 11:30:00.000'
Продолжить изучение SQL и Python вы сможете на наших курсах:

Узнайте подробности здесь.
Другие профессии и курсы
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также