Поговорим про инциденты и инцидент-менеджмент. Буквально погрузимся в них, разберём основные черты и характер. Рассмотрим типовые ситуации из моего опыта, как этот процесс работает в Авито, как мы измеряем наши инциденты, как их фиксируем, какие есть тонкие моменты и каких результатов мы в этом добились.
Меня зовут Дмитрий Химион, я работаю в компании Авито и в последнее время занимаюсь механизмом, который автоматизировано детектирует деградации продуктов Авито, определяя потери и собирая информацию по сбоям.

Погружение в проблематику
Давайте разберемся, как этот механизм появился и для чего используется. Чтобы было понятно, с чем мы имеем дело, немного расскажу про размер Авито. Год назад у нас было 40 кросс-функциональных команд разработки, но их количество постоянно растет. Они объединены в юниты, в каждом из которых от 2 до 5 фиче-тим, в которых сидит по 3-5 разработчиков.
Разработка весьма интенсивная — сотни релизов сервисов и несколько релизов нашего монолита в день, плюс мобильные релизы. Из-за этого достаточно интересное и большое количество инцидентов, которые мы начали автоматизировано фиксить.

Процесс автоматизации инцидентов в Авито зародился в марте 2018 года. До этого они заводились вручную, примерно по 15-20 в месяц. Они отмечены желтыми столбиками на диаграмме. Потом мы начали фиксировать больше 30 инцидентов в месяц, а значит приблизительно по 1 сбою в день. Если сравнить с количеством команд на 2020 год, то выходит около 1 инцидента на команду разработки в месяц.
Обработка вручную такого количества инцидентов с поиском концов и оценкой потерь — затратный процесс с множеством коммуникаций. Уже на тот момент было понятно, что масштабировать его будет дорого. Поэтому мы решили его автоматизировать. Так появился MVP, который за 3 квартала достиг хороших результатов в обнаружении инцидентов. Покрытие достигло 95+%. Можно сказать, что сейчас любой значимый сбой в Авито становится видим, что дает нам возможность их анализировать, а собранные данные использовать в различных целях. Например, на диаграмме видно, что в последние два месяца был прирост инцидентов. В это время мы масштабировали наш инструмент на новый продукт, поэтому получили небольшой поток дополнительных инцидентов.
В 2020 году у нас уже получалось 250-270 инцидентов. На таких статистически значимых величинах можно было проводить глобальный анализ и выделять общности. Это давало инструменты, например, какие технические цели нам брать в нашей Objectives and Key Results, в цели технических и продуктовых команд.
Благодаря автоматизации мы понимаем частоту, серьёзность инцидентов и их влияние на бизнес. Теперь попробуем понять, какие они бывают и на какие когорты их можно разделить.
Прозрачность
Инциденты можно делать в разные градации, одна из них — понятность\прозрачность:
Яркие и понятные. Это инциденты, в которых абсолютно понятно что случилось. Они прозрачны с точки зрения мониторинга. Мы видим падение тех или иных метрик и понимаем, что нужно чинить, после чего чиним это или откатываем, и видим, что метрики пришли в норму.
Само появилось, само прошло, никому не интересно. Инциденты, про которые никто не знает, как их воспринимать. Например, начало трясти какую-то ноду в кластере Kubernetes, инстансы сервиса начали «пятисотить» или у них выросло response time, поды упали, их отключили и переподняли на другой ноде. А пока разбирались, что происходило, оно само починилось.
Полтергейст. Дата-центру или чему-то внутри него стало плохо. Потом это переключилось на базы или в транспорт, упала сеть, еще что-то, а что происходит и как это починить — совершенно непонятно. Благо, такие кейсы бывают очень редко.
Видимость&Опасность
Еще интересно понимать про видимость и опасность сбоев. Разберем пару кейсов, чтобы понимать, что это такое.
Например, у нас есть пользователь, который хочет купить лыжи или продать шкаф на Авито. При этом должны собираться аналитические данные в рантайме. Но иногда аналитические события меняются, теряются или перестают отправляться. С точки зрения пользователя и с точки зрения наших технических метрик — продукт работает идеально. С точки зрения аналитических данных и возможности построения mission critical отчетов — это катастрофа. Такие инциденты невидимы, но опасны. Они не вызывают сбоев в работе продукта как такового, но «ослепляют» бизнес в выводах или в принятии решений.
Следующий пласт инцидентов более технический.

Например, есть микросервис и прокси, который занимается направлением запросов в Redis. Мастер Redis перестал работать, но у нас есть Stand by, мы на него переключились, и все снова начало работать. В это время поднялся новый мастер, и на него начали идти новые connections. А после поднятия нового мастера старые connections почему-то не переключились на новый Redis.
Мы увидели эту проблему на маленьком сервисе с небольшой нагрузкой и низкой важностью. Дело было в конфигурировании HAProxy, которую мы используем много где, и есть бага в конфигурации, которая автоматизирована для всех сервисов и всех конструкций, которые используют HAProxy в Авито. Мы поняли, что если произойдет сбой подобного масштаба в mission critical сервисе, то у нас будут большие проблемы.
Так мелкий инцидент помог нам увидеть общую проблему на уровне HAProxy. На его основе мы смогли предотвратить появление этой проблемы в будущем и пофиксили конфиг в HAProxy.
Проблема вроде бы маленькая, но ее потенциальная опасность высокая. На опыте разбора инцидентов, мы сделали простой и наверное очевидный вывод: «Инцидентов не избежать – учись с ними работать!».

Некоторые говорят, что нужно писать «код без багов», очень много тестировать и будет меньше инцидентов. Скорее всего так и будет, но надо принять одну простую истину — сколько бы мы ни тестировали, как бы хорошо ни покрывали наши сервисы тестами, у нас все равно будут инциденты (ибо исчерпывающее тестирование слабо реализуемо в больших системах. См. 7 принципов тестирования). Это нормально. Их не надо избегать, но надо стремиться их минимизировать. То есть, если мы упали, надо уметь очень быстро подняться — «быстро поднятое упавшим не считается».
Понимать, какие есть узкие места и где у нас пока плохо с мониторингом или еще с чем-то, нам помогает автоматизированный анализ и сбор данных по инцидентам.
Процесс Live Site Review

Есть еще один способ разделения инцидентов на внешние и внутренние. Внешние инциденты — это когда какой-нибудь эквайринг внешнего провайдера, например, платежный шлюз или еще какая-то интеграция с внешней системой доставки “отъехала”. Мы на таком концентрироваться не будем, а поговорим про внутренние инциденты, которые зависят только от нас и на которые мы однозначно можем повлиять.
Концептуально процесс Live Site Review выглядит так:
Инцидент;
Устранение проблемы. Первое, что нужно делать — это устранять проблему, а не заводить тикеты. Вроде капитанская штука, но anyway.
Описание post-mortem;Автоматизировано собирается контекст инцидента и производится его автоматизированная оценка (какого размера он был, длительность, глубина, какие метрики пострадали, что мы потеряли и т.д.)
Оценка post-mortem и встреча;У нас есть специальный человек, который хороводит все наши инциденты, устраивает встречи, где мы обсуждаем, что можно сделать, чтобы предотвратить подобное в будущем.
Выполнение action items;Дальше мы фиксируем определенный набор action items в виде задач с конкретными исполнителями, который позволяет нам не допустить этой проблемы в будущем.
Выполнение action items и закрытие post-mortem;
Дополнение базы знаний.
Для простых и мелких инцидентов мы никакие разборы не делаем:

После инцидента мы собираем статистику и в принципе на этом работа с ним заканчивается. Мы их видим и учитываем в анализе инцидентов на больших временных промежутках. Если у вас есть практика разбора внутренних инцидентов, можете взять это на вооружение.
Как процесс происходит внутри? Post-mortem у нас заводит не какой-то конкретный человек, хотя чаще всего это делают ребята из Problem Mangement, его может завести кто угодно. Инцидент, как таковой, уже можно не заводить, не описывать и не обсчитывать — это все делается автоматизировано:

После того, как появился автоматизированный инцидент и по нему собрались все метрики, скриншоты, мы анализируем работу сервисов, все деплойменты в Kubernetes, которые пострадали, все это выписываем в тикет в Jira. После чего смотрим на этот тикет, оценивая его и принимая решение — является ли он ложно положительным срабатыванием или это валидный сбой.
Это значит, что иногда замеченный инцидент — это не инцидент, а случайно сложившееся обстоятельство, которое не является инцидентом. Но такое бывает не часто.
Ключевые моменты в тикете
Ключевая информация, которую мы автоматически собираем по каждому инциденту, нужна чтобы разобраться, что случилось же случилось. Чтобы понять какие сервисы подскочили в response time, какие показали ошибки в момент сбоя, а какие чувствовали себя нормально, какое было нод в кластерах Kubernetes у нас есть восемь пунктов ключевой информации.
Давайте разберём каждый подробнее.
Влияние. Чтобы понимать, стоит ли обратить внимание на инцидент, всегда смотрим на его влияние на работу бизнеса. Влияние мы измеряем: в пострадавших пользователях, потенциально недополученных деньгах и потерянных данных.
Первопричина. Это то, что необходимо лечить во избежание повторения истории в будущем. Мы стараемся погружаться в наш бэкенд и метрики со всех сторон для того, чтобы собрать всю информацию и быстрее понять первопричины:
Не протестировали;
Нет анализа изменений;
Нет обратной совместимости;
Кривая конфигурация;
Игнорировали риск.
Триггер. Что послужило триггером? Какие исследования нужно проводить для создания определенных механизмов, какие факторы и какие ситуации в реальности приводят к проявлению проблем? Например, баг может быть посажен в продукт хоть год назад. Но фактором его проявления — «триггером» может быть всё, что угодно.
Сочленение первопричин появления проблемы и триггера фактически является взрывоопасным коктейлем, который приводит к сбоям. Но надо сказать, что триггер и первопричина — это разные вещи. Если вы занимаетесь инцидент-менеджментом, возьмите себе на вооружение, что их необхоимо разделять и отдельно описывать.
Как ликвидировали. Нам важно знать, что мы делали, в какой последовательности и сколько это времени заняло устранение инцидента:

Это позволяет понимать, что мы делаем правильно или неправильно. Если time line ликвидации инцидента был быстрым, с короткими коммуникациями по таймингу, значит реакция на сбой у нас работает идеально. Другая ситуация, если у нас нет каких-то метрик или мы не сможем понять, в чем проблема, это всегда дает зазор между действиями в time line и устранением проблем.
Как обнаружили. Варианты от лучших к худшим:
Обнаружили при выкатке канареечного релиза, затронули минимум пользователей, соответственно, все откатили;
Заметили быстрее, чем пользователи успели заметить;
Узнали из мониторинга;
Получили сообщение от саппорта;
Узнали от руководителя;
Узнали из СМИ.
Худший вариант — узнать о проблеме из СМИ, это лютое фиаско. Но пока что я не припомню таких случаев.
Action items. Дальше мы должны выделить action items (задачи на доработку) по всей этой информации: что нам сделать, как устранить первопричины и как повлиять на триггеры, чтобы не наступить на те же грабли в следующий раз. Для этого настраиваем мониторинг и алерты, пишем авто-тесты, добавляем активности в грумминг, изменяем инженерные практики и рефакторинг компонентов продукта.
Платформа. Технические данные мы собираем по областям появления проблем, чтобы использовать их для аналитики:
Android;
iOS;
Web;
API;
Service layer;
Storage layer;
Hardware layer;
Kubernetes layer.
Команда. Интересно понимать, в области какой команды чаще всего происходят инциденты. Это помогает выявить проблемы с инженерией, тестированием или разработкой, и дает возможность зайти в конкретную команду, решить проблему и сократить количество инцидентов.
Что измеряем?
Давайте подробнее рассмотрим, что мы измеряем, из чего строится понимание влияния инцидента на бизнес:
Клиентский капитал. Например, во время инцидента у нас был баг, и мы можем посчитать, сколько пользователей его видели и посмотреть, как мы просели по различным продуктовым конверсиям, регистрациям и авторизациям. Таким образом мы видим, как еще мы повлияли на пользователей.
Финансовые потери. Терминологически это не финансовые потери, а недополученная и потенциально недополученная ликвидность и прибыль. Фин. потери достаточно сложно считать, но, тем не менее, мы считаем: недополученную прибыль, провалы в биллинге и монетизационные инструменты. Мы видим, что в нашу компанию приносит revenue, и из этого считаем, что недополучили.
Потеря данных. Мы считаем, какое количество mission critical данных для аналитики и принятия бизнес-решений потеряли в процессе технических сбоев. Это могут быть аналитические, пользовательские и технические данные. Это большая область, которая не сильно развита, потому как пока не хватает ресурсов. Но это у нас в планах. Мы эту область развиваем и будем развивать.
И вот что из ключевых параметров мы измеряем в наших инцидентах, чтобы понимать их размер.
Оценка бизнес-метрики
Я сделал несколько обезличенных скриншотов из Grafana, которые демонстрируют описание наших инцидентов. У нас есть механизм, который показывает деградацию по ключевым метрикам. Если деградация этих метрик определенным образом коррелирует, то есть метрики из разных когорт, и если деградация метрик из этих когорт совпадает по временному интервалу, то мы говорим, что здесь деградация и нужно дальше копать, чтобы разобраться — это реально инцидент или нет. Соответственно, мы ведем подсчеты по метрикам и записываем в тот или иной вид потерь.
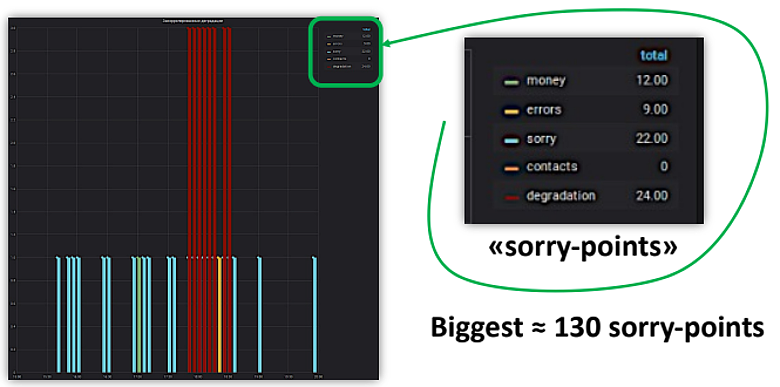
Мы измеряем те же потери данных, например в миллионах запросов от пользователей. Это происходит при углублении в инцидент, то есть, когда у нас есть тайминг инцидента, мы начинаем копать, как какая метрика себя вела в этот промежуток времени, из чего у нас и получаются потери.

После того, как по нашему инциденту определили время начала и окончания, можем взять какую-то метрику и увидеть просадку.

В данном случае это регистрация пользователя на платформе. Можно увидеть, что за время инцидента у нас недозарегистрировалось около 90 пользователей. Это бизнесовая потеря, потому что маркетинг кропотливо работал над маркетинговой компанией, чтобы привести пользователей на регистрацию. А из-за инцидента этого не случилось.
Примерно так выглядит оценка бизнес-метрики по потерям данных, клиентского капитала и пользователям.
Тонкие моменты
Распространение практики. Если вы у себя сейчас делаете инцидент-менеджмент или что-то близкое, наберитесь терпения. Эта практика должна созреть и врасти в культуру разработки, стать частью top of mind, чтобы превратиться в бытность. Нашему инструменту то же не сразу начали доверять, считали, что он неправильно работает, что-то не так считает и находит фейковые штуки, но со временем мнение изменилось.
Временной ресурс. Часто на закрытие action items необходимо выбивать ресурс. Раньше у нас это вызывало сопротивление людей, так как не всем, не всегда и не во всем было понятно, какая ценность в закрытии action items. Со временем это размылось. Для того, чтобы полноценно вести этот процесс Live Site Review (инцидент-менеджмент), part time человека не хватит. Если вы хотите нормально этим заниматься, то нужен dedicated человек, который будет строить этот процесс.
«Люркинг» людей. Когда мы начинаем в неправильной форме выяснять, почему люди что-то не сделали, происходит «люркинг». Они стараются скрыть свои инциденты. Это происходит из-за неправильной подачи самих инцидентов, когда их называют позором, а не процессом по борьбе с проблемами в разработке. Процесс нужно направить не на поиск виноватых, а подавать с ракурса: «Всем привет, у нас есть такая то проблема, давайте ее обсудим», и обсуждать не людей, а как эта проблема появилась и что менять в процессах. Тогда проблему «люркинга» можно сильно снизить, что повысит выхлоп всего процесса.
Драйвер процесса. Естественно, это капитанская вещь, но если у процесса нет идеолога, то есть человека, который видит горизонт его развития, то процесс либо стагнирует, либо развалится.
Итоги
Что же дает инцидент-менеджмент?
Для инженеров:
Это очень простой набор действий:
Инцидент?! — «Устраняй ➜ Описывай ➜ Обсуждай». Ещё инцидент? — «Устраняй ➜ Описывай ➜ Обсуждай».
А еще пропагандирование культуры, в которой мы не стараемся закрыть все баги и сделать 100% покрытие, а хотим быть готовы к инциденту, чтобы уменьшить его влияние на работу компании. Тестирование — не краеугольный камень всего и вся, оно лучше работает в связке с мониторингом.
Оцененные количественно инциденты - это источник аргументов для приоритезации технических задач и проектов. Например, когда у вас есть 150 инцидентов, которые указывают на одну и ту же проблему, а еще лучше, когда вы говорите с продакт менеджерами на уровне бизнес метрик, конверсий в пользователей и показываете количественную оценку, то сможете продвинуть продуктовые и технические инициативы и их value для компании.
Для руководителей:
Для технических руководителей - это хороший термометр для понимания, насколько все хорошо или плохо с инженерией. Показатель того, в какие-то моменты можно и ускорить разработку, не слишком ли мы сильно перестраховываемся при разработке, тестируя избыточно много. Или обратная ситуация, что мы слишком быстро летим и устраиваем резню на production и надо вдарить по тормозам.
В такой большой организации, как Авито, автоматизация инцидент-менеджмента позволяет понимать, каково состояние продукта, видеть сбои, которые у нас происходят. Это формирует картину, насколько все хорошо или плохо, может быть, не в рантайме, но на горизонте временных промежутков.
Имея на руках автоматизировано собранный и оцененный большой инцидент или видя какой-то тренд по инцидентам, можно своевременно принять сложное решение. Например, остановить релизы, решить проблемы, которые могут привести к коллапсу, восстановить работу и начать релизить снова. Это весьма ценное, на мой взгляд, свойство процесса, которое позволяет принимать сложные решения.
Видео моего выступления на эту тему:
Конференция об автоматизации тестирования TestDriven Conf 2022 пройдёт в Москве, 28-29 апреля 2022 года. Кроме хардкора об автоматизации и разработки в тестировании, будут и вещи, полезные в обычной работе.
Расписание уже готово, а купить билет можно здесь. С 1 января будет повышение цен!
Комментарии (5)

OlegZH
21.12.2021 19:28Можно ли на основании трудного опыта придумать более устойчивую к отказам архитектуру ПО и, вообще, более эффективную в плане восстановлания.

dkhimion Автор
21.12.2021 21:13+1Можно конечно и многое уже сделано или делается. Могу дать наводки на правильные инженерные практики:
graceful degradation
circuit breaker
throttling
MTTR
MTBF
Stress testing
Stability testing
Я тут не особо силен, но думаю это уже поможет
AlexSpaizNet
Рассказали обо всем кроме самой информации об автоматизации. Как оно работает? Какие инструменты используются? Кто решает, стала ли проблема блокером или можно продолжать спать?
Смотрю на наши проблемы в продакшене, и они настолько разные, что человеку тяжело понять что вообще пострадало в результате, и что теперь делать.
dkhimion Автор
Уже готовлю доклад про то, как внутри работает наша автоматизация.
Отвечу на вопросы:
1. Какие инструменты используются?
инструменты мониторинга (Graphite + Grafana, Prometheus), плюс интеграции с k8s и разными внутренними инструментами (трейсингом, сервисов дежурств и прочими прелестями) остальное всёсамописное
Кто решает, стала ли проблема блокером или можно продолжать спать? - есть конмада 24/7, которая смотрит за работой наших продуктов. Автоматизацию сейчас больше нацелена на постфактумный сбор инормации, это не система алертинга, а система анализа. Однако надо признать, что мы ее уже начали использовать и в целях "более рантаймовой" детекции инцидентов.
"Смотрю на наши проблемы в продакшене, и они настолько разные, что человеку тяжело понять что вообще пострадало в результате, и что теперь делать." - именно поэтому мы и сделали автоматизацию, руками собирать информацию, ходить по людям, отвлекать их от дел чтобы собрать достойный инцидент - было хлопотно, поэтому навалились на автоматизацизацию... на как навалились, запустили пилот, а потом пошло поехало.