
Кому не нравится LINQ в C#? Встроенная и уже достаточно старая фича языка C# и рантайма .NET.
Но можем ли мы сделать более эффективную версию этой фичи?
TL;DR (спойлер)
Можем сделать более эффективную, но намного менее универсальную. Github проекта.
Вкратце о том, как работает LINQ
Почти каждый метод LINQ обертывает предыдущую последовательность в новую (но ничего не делает сам). Например, метод Select создает и возвращает SelectEnumerableIterator. И так каждый метод - на основе предыдущего будет создавать новый итератор.
Каждое активное действие - например, foreach - превращается в создание енумератора, который, пока может, делает "шаг" и выдает значение.

Более точно как разворачивается foreach можно проверить на замечательность шарплабе.
Теперь, так как это все - референс типы, то они, конечно, аллоцируются в куче. Более того, это все обмазано виртуальными вызовами, так как MoveNext, конечно, нельзя статически отрезолвить.
Начинаем творить!
Если в обычном LINQ каждый следующий итератор просто хранит поле типа IEnumerable<T> в себе, то у нас каждый следующий енумератор будет хранить всю цепочку итераторов до себя. И я не имею ввиду массив.
Вместо этого, все итераторы будут структурами, а каждый следующий итератор будет точно знать тип предыдущего через generic-и. То есть у нас есть итератор TEnumerator, так вот следующий будет иметь один из type argument-ов - TEnumerator.
Для начала - обертка любого енумератора, это то, что будет возвращено любым нашим методом:

Теперь рассмотрим пример структуры, которую будет возвращать метод Select:
")
Тип предыдущего енумератора, а также тип значений им возвращаемый, нам известен. Еще там же передается тип функтора для отображения из типа T в тип U (это сделано для того, чтобы мы могли передавать более эффективные делегаты).
Заметьте, метод Select все так же почти ничего не делает - всего лишь создает структуру!

А значит, что все работает так же лениво, как и в LINQ.
Аналогично делаются другие итераторы. Например, после вызова Where, Select, SelectMany наш итератор будет выглядить примерно как SelectMany<..., Select<..., Where<..., >>>.
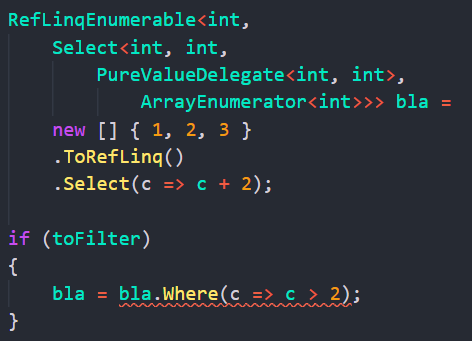
Более точно, вот пример вызова Select и Where, обратите внимание на тип переменной seq:

То есть самый "внутренний" тип - это ArrayEnumerator, и он включен в Select, который в свою очередь включен в Where.
Что получилось?
Таким образом, вместо виртуальных типов и методов, которые есть в обычном LINQ, мы создаем по сути новый тип, который отображает именно ту последовательность операций, которую мы хотим!
А раз нет виртуальных методов, и нет нужды для референс типов, то все у нас хранится на стеке, а многие методы - заинлайнены, что дает неплохое преимущество по производительности и не производит аллокаций в куче.
Почему же так не сделали сам LINQ?
На самом деле, LINQ куда более универсальный чем то, что мы сделали. Давайте рассмотрим проблемы нашей имплементации.
Проблема 1. Копирование неэффективно
Интерфейсы и классы - это референс типы, то есть передавая их туда-сюда мы передаем "указатель" - 4 или 8 байтовое число. А вот чтобы передать наш енумератор, нам придется копировать все его содержимое, все внутренние енумераторы.

Как видно на скрине, нам стоит очень много процессорного времени, чтобы скопировать такую огромную штуку.
Проблема 2. Отсутствие общего интерфейса
В LINQ неважно, какими операциями составлена последовательность - это все равно IEnumerable<T>. Мы можем легко докинуть сверху что-нибудь, если хотим:

Но это не так в нашем случае. bla.Where вернет тип отличный от bla. Поэтому это невозможно в нашей реализации:
Проблема 3. Не все LINQ методы можно так реализовать
Например, SkipLast использует внутренный буффер для хранения элементов, чтобы посетить каждый элемент не более одного раза.
Как такой метод сделать в нашем случае? Я не нашел способа и думаю его нет. Существует stackalloc, конечно, но он валиден только в скоупе, а значит, его придется вызывать пользователю, и, конечно, это обессмысливает все.
Проблема 4. Обжора стека
Помним, что это очень большая структура, особенно если много операций. Поэтому следует измерить количество потребляемой стековой памяти.
Используя собственную тулзу CodegenAnalysis, меряю количество статически аллоцируемой стековой памяти:

288 байтов понадобилось всего лишь для двух операций! Для более длинных цепочек это могут быть килобайты (напомню, что это размер самого енумератора - это число не зависит от длины входной последовательности).
Надо ли это кому-то?
Да, но далеко не всем. Это может быть полезно геймдевам (кто хочет сэкономить на аллокациях в куче), системным разработчикам (опять же, вдруг вы хотите использовать LINQ на микроконтроллере), ну или просто тем, у кого именно такие юзкейсы.
На самом деле, я не изобрел принципиально нового. До меня уже написали целый ряд похожих библиотек: NoAlloq, LinqFaster, Hyperlinq, ValueLinq, LinqAF, StructLinq. Немного разные, но идея та же.
Вывод
Я реализовал все и только те методы, которые могут быть сделаны без аллокаций в куче (и безобразного API). В секции Benchmarks можно увидеть сравнение с другими библиотеками по эффективности.
Таким образом, такая реализация не имеет виртуальных вызовов и аллокаций в куче и не имеет оверхеда с стейт-машинами, написанными вручную (но вручную написанные всякие for-ы все равно будут эффективнее).
Но у нее есть куча недостатков: отсутствие общего интерфейса, не все методы так можно сделать, дорогое копирование, и так далее.
LINQ все так же актуален. Заменить его можно лишь в некоторых нишевых ситуациях, где подобные библиотеки будут более эффективны.
Спасибо за внимание! Мой github/WhiteBlackGoose.
(для анализа эффективности использую BenchmarkDotNet и CodegenAnalysis)
Комментарии (28)

andreyverbin
30.01.2022 14:00+2Меня посетила интересная мысль - а откуда берётся выигрыш в производительности? 1Кб в куче выделяет стандартный LINQ, видимо столько же, но на стеке выделяет ваша версия. Выделение в куче стоит почти столько же, сколько и на стеке. Выделенную в куче память GC, скорее всего, никогда не увидит, то есть стоимость очистки памяти тоже равна стеку.
Дальше теория - львиная доля из 4 и 8 мс это выделение памяти. Если увеличить размер коллекции, то это время станет незначительно на общем фоне и разница станет незаметной.

WhiteBlackGoose Автор
30.01.2022 14:17+4Дальше теория - львиная доля из 4 и 8 мс это выделение памяти
На самом деле нет, память, как вы же сами сказали, стоит очень мало. Правда все-таки побольше, чем на стеке, но все равно немного.
А вот виртуальные вызовы на каждом шагу - вот это я думаю и занимает все время. Если сделать цепочку из N операций в LINQ, то каждый Move.Next это будет N виртуальных вызовов, то есть хождений по случайным местам памяти.
А тут нет виртуальных вызовов, и многие вызовы заинлайнены.

Mingun
30.01.2022 14:24Неужели компилятор настолько глупый, что не может заинлайнить все эти виртуальные вызовы? Он же видит всю Linq-цепочку (в вашем примере).
Также непонятно, откуда такой дикий оверхед по памяти в типе? Все заинлайненные лямбды должен же иметь нулевой размер, они не используют состояние, а размер конечной структуры по идее должен быть максимальным размером всех этих переходных структур? Они же все в одном месте памяти находятся, а после инлайнинга так вообще должна остаться только пара ссылок на источник данных и конечную функцию преобразования.
WhiteBlackGoose Автор
30.01.2022 14:34+3Неужели компилятор настолько глупый, что не может заинлайнить все эти виртуальные вызовы? Он же видит всю Linq-цепочку (в вашем примере).
Пока да. Чтобы девиртуализировать такую длинную цепочку, ему придется буквально выполнить весь код и убедиться, что у нас всегда создаются одни и те же типы, и заинлайнить огромное количество кода. Для подобных вещей это бессмысленно и стоит очень много времени джита (а он, конечно, должен работать очень быстро).
Все заинлайненные лямбды должен же иметь нулевой размер, они не используют состояние
В моем примере я использую тип PureValueDelegate. Это такой value delegate, только для ленивых, потому что в нем я использую обычный Func :). В идеале туда можно передавать настоящий функтор вручную реализуя IValueDelegate, но кажется это никому из пользователей LINQ-а неинтересно такой ужас городить. Вот. То есть это как минимум 8 байт на каждый такой делегат.
а размер конечной структуры по идее должен быть максимальным размером всех этих переходных структур?
Ну, размер каждой следующей - сумма ее полей, то есть "личных" полей и предыдущего енумератора.
Плюс еще инлайнер джита мог уже выйти из бюджета и перестать инлайнить некоторые методы - тогда у нас еще и копирование будет.

DistortNeo
30.01.2022 17:14+1В идеале туда можно передавать настоящий функтор вручную реализуя
IValueDelegate, но кажется это никому из пользователей LINQ-а
неинтересно такой ужас городить.В крайнем случае можно подумать в сторону кодогенерации в рантайме и избавиться от косвенного вызова делегата, ведь
Func— это Method + Target. Заводится словарик, и для каждого метода создаётся своя структура-обёртка, но с прямым вызовом.Это значительно увеличит время создания объекта, но в случае больших коллекций даже выигрыш. Например, я такое проворачивал для обработки изображений, и оно работало весьма неплохо.

Phanto_m
31.01.2022 23:33А в чем смысл этого PureValueDelegate?
WhiteBlackGoose Автор
01.02.2022 00:11+1Во всех методах ожидается структа-делегат реализующая IValueDelegate.
По идее, чтобы выжать максимально скорости работы, нужно написать структуру, реализовав интерфейс и в методе Invoke написать ваш делегат.
Но так как это не слишком интересно никому, я предварительно сделал PureValueDelegate и CapturingValueDelegate, которые работают без аллокаций, но используют обычный дотнетовский делегат.
Phanto_m
01.02.2022 00:17И еще вопрос, у вас структуры реализовывают интерфейсы, а боксинга и callvirt не будет?
WhiteBlackGoose Автор
01.02.2022 07:46+1Неа. Там отдельный type argument на них, и для них тип специализируется

Deosis
31.01.2022 08:44+3Лучше приложите результат сравнения в BenchmarkDotNet для входых массивов размера 10, 100, 1000.
Сразу будет видно, сколько времени отъедают вызовы.
WhiteBlackGoose Автор
31.01.2022 14:02+4Хорошо. Сделал бенчмарк для сравнения простого Select + Where для RefLinq против классического.

Собственно, примерное отношение 1:2 по времени так и сохраняется, как и предполагалось ;).
Исходники бенчмарка тут.
cc @Mingun , @andreyverbin


OkunevPY
30.01.2022 17:52Блин, есть же компилируемые деревья, они для этого созданы, ускорить стандартный Linq
WhiteBlackGoose Автор
30.01.2022 17:57+4Вовсе нет. Стандартный LINQ работает вполне "обычно", без Linq.Expression. Вот здесь можно посмотреть исходники LINQ-а.
Но для работы со всякими базами данных используется IQueryable, и вот там используются Linq.Expression, чтобы переделать лямбду на сишарпе в SQL-запрос (или как это в БД работает). Но это уже совсем другая история.
А еще знакомый пилит компилятор LINQ в обычные циклы/условия и т. д., вот там он использует компиляцию Linq.Expression.

kraidiky
01.02.2022 23:26На сколько я помню, Linq.Expression Маленько стукают по производительности, поэтому мои любители оптимизации рекомендовли использовать его только на стадии отладки, чтобы получать говорящий лог, а на бое отключать по ключу компиляции заменяя на обычный делегат.
Деталей я не знаю, но на меня они чутка поругивались за то что я в своей реализации реактивности их много куда напихал.WhiteBlackGoose Автор
02.02.2022 07:27Так в том и дело, что собрав код в Linq.Expression, его можно собрать в делегат одним методом. А вот этот делегат будет лишь наносекунды медленнее чем если написать тот же код вручную

doctorw
30.01.2022 23:19+2Если я правильно помню, то для generic struct CLR будет генерировать отдельный сконструированный (закрытый) тип с реализацией. Возникает вопрос, как приведённый подход повлияет на потребление памяти процессом в целом?
WhiteBlackGoose Автор
31.01.2022 08:38+1Это хороший вопрос, но я не изучал. Вообще, code bloating — это причина почему, например, CLR не генерирует типы и методы на каждый тип, а только на разные value type. То есть такая проблема явно есть. Но какое именно потребление — наверное можно попробовать померить через EventListener, отследив момент когда JIT специализирует тип
doctorw
31.01.2022 13:28+2CLR не генерирует типы и методы на каждый тип, а только на разные value type.
Потому, что для ссылочных типов там одной реализации достаточно, т.к. переменные ссылочных типов, по сути, представляют с собой адрес постоянной длины, тогда как value type могут существенно отличаться по размерности и для них в случае обобщений должен генерироваться разный машинный код реализации.WhiteBlackGoose Автор
31.01.2022 13:37+1Тем не менее, генерация под каждый тип могла бы позволить девиртуализировать виртуальные типы и методы. То есть все равно есть цена за то, что не специализируем на каждый тип.
DistortNeo
31.01.2022 17:01JIT-компилятор в редких случаях всё-таки делает подставновку обобщённого типа даже для ссылочных типов.

codecity
31.01.2022 03:26+3Благодарю, очень интересно. Так же посмотрел ваше репо и был весьма удивлен - неужели один человек на такое способен? К примеру, скачал ваш проект AsmToDelegate на основе icedland/iced - весьма.
Расскажите как у вас хватает времени на это все, откуда берете мотивацию, энергию? Является ли это вашей личной инициативой или кто-то курирует? Так же является ли это вашей основной деятельностью и удалось ли найти финансирование, чтобы этим заниматься на постоянной основе?
WhiteBlackGoose Автор
31.01.2022 08:44+3Расскажите как у вас хватает времени на это все, откуда берете мотивацию, энергию?
Позитивный фидбек пользователей и читателей дает мотивацию.
Является ли это вашей личной инициативой или кто-то курирует?
Личная. Никто не финансирует.( Но надо сказать, что многие проекты не так-то и много заняли времени. Например, проект, про который эта статья, я сделал наверное дня за два. AsmToDelegate — там моей работы вовсе немного, по сути все, что я делаю, это пишу закодированный машинный код от Iced-а в исполняемую память и возвращаю делегат.
Хотя есть конечно и большие проекты, которые уже не первый год делаю, например этот
codecity
31.01.2022 10:04Еще могли бы рассказать как получили бэкграунд в низкоуровневой разработке? Помогло ли образование (наше или зарубежное?) или же достигали самостоятельно? Возможно порекомендуете какие-либо книги?
Вот реально редко встретишь людей из наших, которые так глубоко копают.
по сути все, что я делаю, это пишу закодированный машинный код от Iced-а в исполняемую память и возвращаю делегатДа, это понятно. Но могу оценить ваш уровень компетентности, так как сам уже больше 10 лет занимаюсь разработкой. Работы не много - можно сказать один удар молотком. Но вот знать куда ударить - дорогого стоит.
WhiteBlackGoose Автор
31.01.2022 10:42+2Еще могли бы рассказать как получили бэкграунд в низкоуровневой разработке? Помогло ли образование (наше или зарубежное?) или же достигали самостоятельно? Возможно порекомендуете какие-либо книги?
Самостоятельно, но не без помощи других людей и проектов. В основном это
C# сервер в дискорде - тут куча крутых людей, очень много чего низкоуровнего можно узнать
Шарплаб
-
Ну и несколько книжек:
CLR via C# 4-th edition
Pro .NET Memory Management
Pro .NET Benchmarking
Вот реально редко встретишь людей из наших, которые так глубоко копают.
А ведь на том сишарп сервере есть люди, которые в этом шарят на порядки больше меня! Вот это реально клад

arTk_ev
01.02.2022 10:20А почему linq в F# почти не генерит мусор и работает быстро?
WhiteBlackGoose Автор
01.02.2022 10:24Да генерит вроде... не мерил, если честно. Точнее мерил, вот здесь, но не сравнивал с LINQ.
kraidiky
01.02.2022 23:27+1Чувак, прикольно! Так прикольно, что захотелось самому воспроизвести ручками из любви к красивым решениям. :) Статью в закладки, обязательно воспользую при удобной возможности.
WhiteBlackGoose Автор
Это перевод моей же статьи на медиуме.
Вопросы, фидбек приветствуются!