
Подобные вопросы заставляют меня сразу же открыть Python REPL и проверить код, потому что я думаю, что знаю правильный ответ, но не очень в нём уверен.
Вот как я рассуждал, когда впервые увидел этот вопрос:
- Строка
flagсодержит один символ. -
[::-1]переворачивает строкуflag. - Строка, обратная строке с одним символом, будет такой же, как и исходная.
- Следовательно,
reversed_flagдолжна быть равна " ".
".
Это совершенно общезначимое утверждение. Но верен ли вывод? Давайте взглянем:

Что тут вообще происходит?
Действительно ли строка содержит один символ?
Если вывод из общезначимого утверждения ложно, одна из предпосылок обязана тоже быть ложной. Давайте начнём сверху:
Строка
flag содержит один символ.Так ли это? Как понять, сколько символов содержится в строке?
В Python можно использовать встроенную функцию
len(), чтобы получить общее количество символов в строке:
Ой.
Это странно. Мы видим только один элемент в строке "
", а именно флаг США, но длина 2 изменяет результат flag[::-1]. Так как обратным для значения "" является " ", это подразумевает, что
", это подразумевает, что  .
.Как понять, какие символы находятся в строке?
Просмотреть все символы строки с помощью Python можно несколькими разными способами:

Эмодзи с флагом США — не единственный эмодзи с флагом из двух символов:
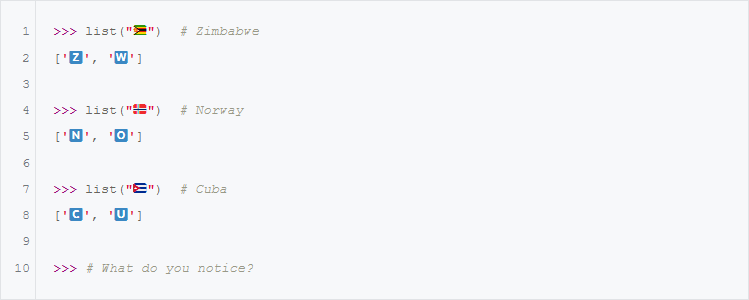
А вот флаг Шотландии:

Что тут происходит?
???????? Задание: сможете найти строки, не являющиеся эмодзи и при этом выглядящие как один символ, но на самом деле содержащие два или более символов?
Пугает в этих примерах то, что они подразумевают, что мы не можем сказать, какие символы находятся в строке, просто посмотрев на экран.
Или, в более фундаментальном смысле, они заставляют задуматься о понимании термина «символ».
Что такое символ?
Термин character в computer science может сбивать с толку. Его обычно смешивают со словом symbol, которое является синонимом слова character в английском просторечии.
Когда я загуглил
character computer science, то первым результатом я получил ссылку на статью в Technopedia, дающую следующее определение character:«Единица отображаемой информации, эквивалентная алфавитной букве или символу». — Technopedia, «Character (Char)»
Это определение кажется ошибочным, особенно в свете примера с флагом США, показывающим, что один symbol может состоять как минимум из двух characters.
Вторым результатом в Google стала ссылка на Википедию. В этой статье определение character чуть более вольное:
«Character — это единица информации, приблизительно соответствующая графеме, графемоподобной единице или символу, например, алфавита или слоговой азбуки, в письменной форме естественного языка». — Википедия, «Character (computing)»
Хм… Использование слова «приблизительно» в определении делает его, я бы сказал, неопределённым.
Однако в статье Википедии объясняется, что термин character исторически «обозначал определённое количество смежных битов».
Затем идёт важная подсказка о том, как строка с одним символом может содержать два или более characters:
«Сharacter сегодня чаще всего принимается равным 8 битам (одному байту)… Все символы могут быть представлены как один или несколько 8-битных единиц в формате кодировки UTF-8». — Википедия, Character (computing).
Отлично! Кажется, всё становится чуть более логичным. Character обозначает единицу текста и часто хранится как один байт информации. Symbols, которые мы видим в строке, могут состоять из нескольких 8-битных (1-байтных) единиц кодировки UTF-8.
Characters — не то же самое, что symbols. Теперь кажется логичным, что один symbol может состоять из нескольких characters, как флаги-эмодзи.
Но что такое единица кодировки UTF-8?
Чуть ниже в статье Википедии о characters есть раздел под названием Кодировка, в которой объясняется:
«Компьютеры и коммуникационное оборудование описывают characters при помощи кодировки, присваивающей каждый character чему-нибудь (обычно целочисленной величине, представленной последовательностью чисел), что можно хранить или передавать по сети. Примерами стандартных кодировок являются ASCII и кодировка UTF-8 для Unicode». — Википедия, Character (computing)
Ещё одно упоминание UTF-8! Но теперь мне нужно понять, что же такое кодировка.
Что же такое кодировка символов?
Согласно Википедии, character encoding сопоставляет каждый character с числом. Что это значит?
Не значит ли это, что можно создать пары character-число? Например, можно сопоставить каждую заглавную букву английского алфавита с целым числом от 0 до 25.

Это сопоставление можно задать при помощи кортежей Python:

Остановимся на минуту и зададимся вопросом: «Можно ли создать список кортежей наподобие показанного выше без явной записи каждой пары?»
Одним из вариантов является использование функции
enumerate() Python. enumerate() получает аргумент, называемый iterable, и возвращает кортеж, содержащий счётчик, по умолчанию имеющий значение 0, и значения, полученные итерацией по iterable.Вот как работает
enumerate():
Существует и более простой способ сделать все буквы.
В модуле
string Python есть переменная под названием ascii_uppercase, указывающая на строку, содержащую все заглавные буквы английского алфавита:
Итак, мы привязали characters к целочисленным значениям. Это значит, что теперь у нас есть кодировка символов!
Но как её использовать?
Чтобы закодировать строку
"PYTHON" как последовательность целых чисел, нам нужен способ поиска целого числа, связанного с каждым character. Однако поиск элементов в списке кортежей — сложная задача. К тому же очень неэффективная. (Вопрос для читателя: почему?)Для поиска элементов хороши словари. Если мы преобразуем
enumerated_letters в словарь, то сможем быстро находить букву, связанную с числом: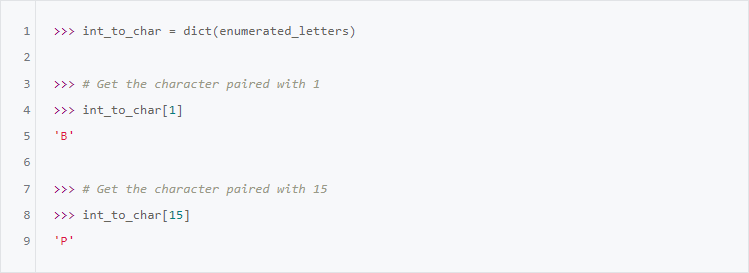
Однако чтобы закодировать строку
"PYTHON" требуется возможность поиска целого числа, связанного с character. Требуется функция, обратная int_to_char.Как поменять местами ключи и значения в словаре Python?
Можно использовать функцию
reversed(), чтобы поменять местами пары «ключ-значение» из словаря int_to_char:
Можно написать выражение-генератор, меняющее местами все пары в
int_to_char.items() и использовать это выражение-генератор для заполнения словаря:
Хорошо, что мы сопоставили каждую букву с уникальным целым числом. В противном случае смена пар местами не сработала бы. (Вопрос для читателей: почему?)
Теперь мы можем кодировать строки как список целых чисел при помощи словаря
char_to_int и спискового включения:
И можно преобразовать список целых чисел в строку заглавных символов с помощью
int_to_char в выражении-генераторе при помощи метода string .join() Python:
Однако есть проблема.
Кодировка не может обрабатывать строки с такими элементами, как знаки препинания, строчные буквы и пробелы:

Можно исправить это, создав кодировку при помощи строки, содержащей все строчные буквы, знаки препинания и пробелы.
Но в Python почти всегда есть способ получше. Модуль
string языка Python содержит переменную printable, дающую строку, содержащую весь набор печатаемых символов:>>> string.printable
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'Добавили ли бы вы все эти characters, если бы создавали собственную строку с нуля?
Теперь мы можем создать новые словари для кодирования и декодирования characters из
string.printable:
Итак, мы создали две разные кодировки! И они на самом деле отличаются. Просто посмотрите, что произойдёт, когда мы закодируем один и тот же список целых чисел при помощи обеих кодировок:

Вообще непохоже!
Теперь мы кое-что знаем о кодировках:
- Кодировки сопоставляют characters с уникальными целыми числами.
- Из некоторых кодировок исключены characters, включённые в другие кодировки.
- Две разные кодировки могут кодировать одинаковые целые числа в разные строки.
Как всё это связано с UTF-8?
Что такое UTF-8?
В статье Википедии о characters упоминаются две кодировки:
«Примерами стандартных кодировок являются ASCII и UTF-8 для Unicode». — Википедия, «Character (computing)»
Отлично, то есть ASCII и UTF-8 — это конкретные виды кодировок.
Вот что написано в статье Википедии про ASCII:
«ASCII была самой популярной кодировкой в World Wide Web до декабря 2007 года, когда её обогнала UTF-8; UTF-8 имеет обратную совместимость с ASCII». — Википедия, «ASCII»
UTF-8 — не просто основная кодировка в вебе. Она также является основной кодировкой операционных систем Linux и macOS, а также стандартной для кода на Python.
На самом деле, можно увидеть, как UTF-8 кодирует characters в целые значения, при помощи метода
.encode() со строковыми объектами Python. Однако .encode() не возвращает список целых чисел. Он возвращает объект bytes:
В документации Python объект
bytes определяется как «неизменяемая последовательность integer в интервале 0 <= x < 256». Это кажется немного странным, учитывая, что объект encoded_string отображает characters в строке "PYTHON", а не набор целых чисел.Но давайте смиримся с этим и посмотрим, сможем ли как-нибудь вытащить целые числа.
В документации Python говорится, что
bytes — это «последовательность», а в глоссарии Python последовательность (sequence) определяется как «iterable, поддерживающий эффективный доступ к элементам при помощи целочисленных индексов»".То есть, похоже, мы можем индексировать объект
bytes точно так же, как мы можем индексировать объект list Python. Давайте попробуем:
Ага! Что произойдёт, если мы преобразуем
encoded_string в список?
Бинго. Похоже, UTF-8 присваивает букве
"P" целое значение 80, букве "Y" — целое значение 89, букве "T" целое значение 84, и так далее.Давайте посмотрим, что произойдёт, если мы закодируем строку "
" с помощью UTF-8:
Ого. Кто-то ожидал, что "
" закодируется восьмью целыми числами?"
" состоит из двух characters, а именно " " и "
" и " ". Давайте посмотрим, как они кодируются:
". Давайте посмотрим, как они кодируются: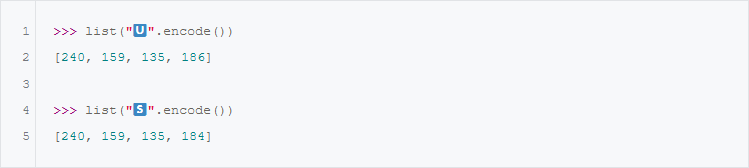
Хорошо, теперь мы начинаем видеть логику. "
" и "" кодируются четырьмя целыми числами, и числа, соответствующие "", стоят первыми в списке целых чисел, соответствующих "", а четыре числа, соответствующие "", стоят вторыми.Однако при этом возникает вопрос.
Почему UTF-8 кодирует некоторые Characters как четыре числа, а другие как одно?
"
" кодируется в UTF-8 как последовательность из четырёх целых чисел, а "P" кодируется как одно число. Почему так получается?В начале статьи Википедии про UTF-8 есть подсказка:
«UTF-8 способна кодировать все 1 112 064 допустимые кодовые точки символов в Unicode при помощи от одной до четырёх однобайтовых (8-битных) кодовых единиц. Кодовые точки с меньшими числовыми значениями, которые встречаются чаще, кодируются меньшим количеством байтов». — Википедия, «UTF-8»
Итак, похоже, UTF-8 кодирует characters не в integer, а во нечто под названием «кодовая точка Unicode». Каждая кодовая единица может состоять из одного-четырёх байтов.
Теперь нам нужно ответить на пару вопросов:
- Что такое байт?
- Что такое кодовая точка Unicode?
Мы часто используем в статье слово «байт», так что давайте, наконец, дадим ему определение.
Бит — это наименьшая единица информации. Бит имеет два состояния, «включен» и «выключен», которые обычно представлены целыми числами
0 и 1. Байт — это последовательность из восьми бит.Можно интерпретировать байты как целые числа, рассматривая составляющие их биты как выражающие число в двоичной записи.
Поначалу двоичная запись может выглядеть довольно экзотично, но во многом она похожа на привычную нам десятичную запись. Разница в том, что каждая цифра может быть только 0 или 1, а значение каждого разряда в числе — это степень 2, а не 10:
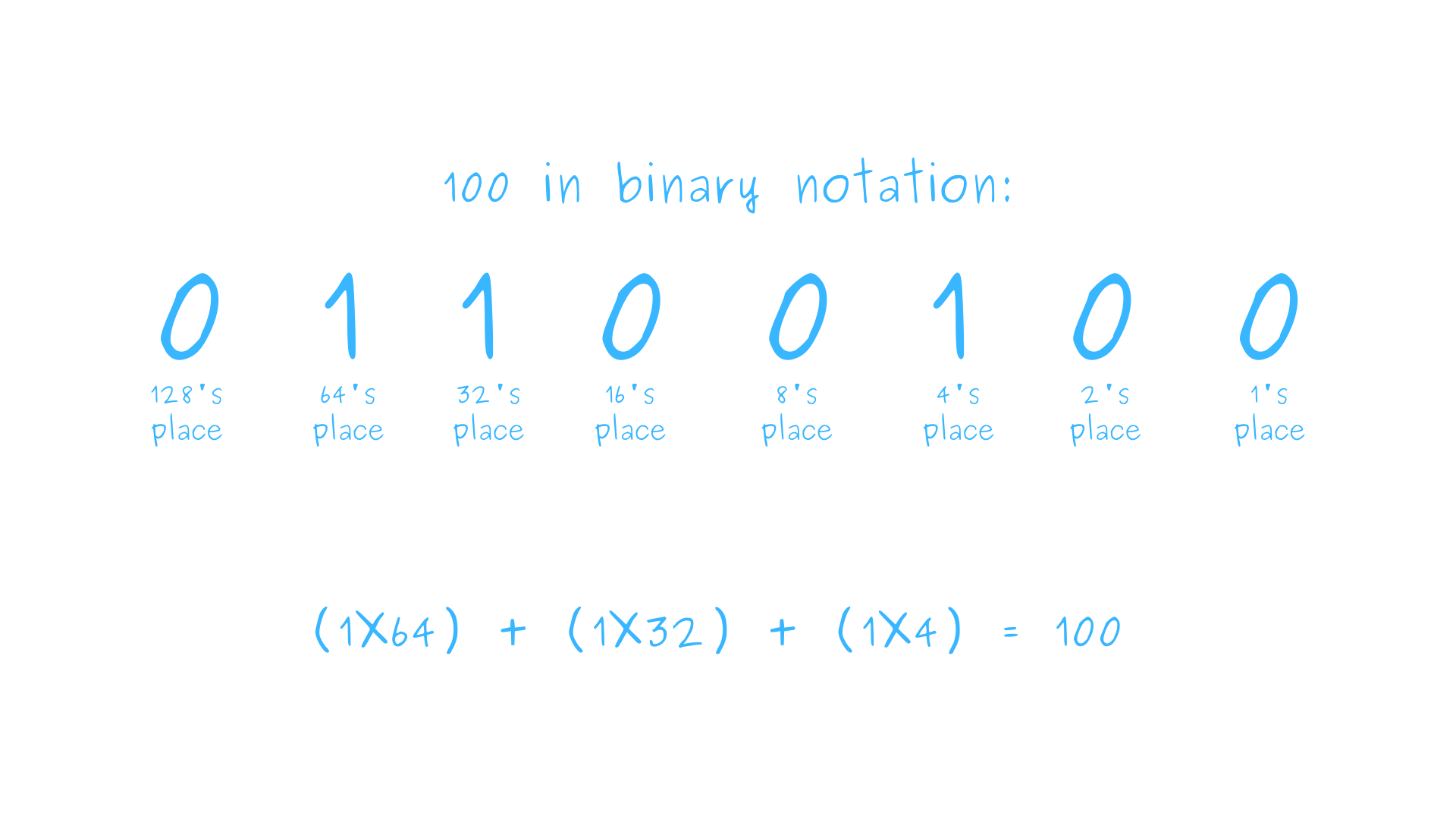
Так как байт содержит восемь бит, самым большим числом, которое можно записать одним байтом, является
11111111 в двоичной или 255 в десятчной записи.
Кодировка, использующая по одному байту на каждый character, может закодировать не более 256 characters, потому что максимальным 8-битным целым числом является
255, а возможные значения начинаются с 0.256 characters достаточно, чтобы закодировать все символы английского языка. Однако мы нкак не сможем закодировать ими все characters и symbols, используемые при письме и электронной связи.
Что же нам делать? Логично было бы кодировать characters несколькими байтами, и именно так сделано в UTF-8.
UTF-8 расшифровывается как Unicode Transformation Format — 8-bit. И мы снова встречаем слово Unicode.
Вот что написано на сайте Unicode:
«Unicode обеспечивает уникальное число для каждого character, вне зависимости от платформы, программы и языка». — Веб-сайт Unicode, «What is Unicode?»
Unicode огромен. Задача Unicode — обеспечить универсальное описание всех письменных языков. Каждому character назначается кодовая точка, иными словами, «целое число» с некой дополнительной структурой, и всего существует 1112064 возможных кодовых точки.
Однако кодирование кодовых точек Unicode зависит от обстоятельств. UTF-8 — это лишь одна кодировка, реализующая стандарт Unicode. Она разделяет кодовые точки на группы из одного-четырёх 8-битных чисел.
Существуют и другие кодировки для Unicode. UTF-16 разделяет кодовые точки Unicode на одно или два 16-битных числа, она является стандартной кодировкой Microsoft Windows. UTF-32 может кодировать каждую кодовую точку Unicode как одно 32-битное число.
Но постойте, UTF-8 кодирует символы как кодовые точки при помощи одного-четырёх байтов. Хорошо, но… почему символ
закодирован восьмью байтами?
Вспомним, что эмодзи с флагом США состоит из двух characters:
и . Эти characters называются символами указателей регионов. В стандарте Unicode есть двадцать шесть указателей регионов, обозначающих английские буквы A–Z. Они используются для кодирования двухбуквенных кодов стран по ISO 3166-1.Вот что о символах указателей регионов написано в Википедии:
«Они были введены в октябре 2010 года в рамках реализации в Unicode 6.0 поддержки эмодзи в качестве альтернативы кодированию отдельных characters для флага каждой страны. Хотя они могут отображаться как буквы латиницы, предполагается, что в их реализации они могут отображаться иным способом, например, при помощи флагов стран. В Unicode FAQ говорится, что этот механизм должен использоваться и что символы для флагов стран не будут кодироваться напрямую». — Википедия, Regional indicator symbol
Иными словами, символ
, да и символ флага любой страны, не поддерживается напрямую Unicode. В операционных системах, веб-браузерах и других местах, где используется цифровой текст, пары указателей регионов могут рендериться как флаги.Давайте упорядочим всё то, что узнали:
- Строки символов преобразуются в последовательности целых чисел кодировкой, обычно UTF-8.
- Некоторые characters кодируются одиночным 8-битным целым числом в UTF-8, а другим требуется два, три или четыре 8-битных целых числа.
- Некоторые символы, например, флаги-эмодзи, не кодируются Unicode напрямую. Это рендеры последовательностей символов Unicode, которые могут и не поддерживаться на каждой платформе.
То есть когда мы переворачиваем строку, она действительно переворачивается? Переворачивается вся последовательность чисел в кодировке или переворачивается порядок кодовых точек, или что-то ещё?
Как же на самом деле перевернуть строку?
Можете попробовать ответить на этот вопрос самостоятельно при помощи эксперимента с кодом?
Ранее мы видели, что UTF-8 кодирует строку
"PYTHON" как последовательность шести целочисленных значений:
Что произойдёт, если мы закодируем переворот строки
"PYTHON"?
В данном случае порядок целых чисел в списке перевернулся. Но как насчёт других символов?
Ранее мы видели, что символ "
" кодируется последовательностью четырёх чисел. Что произойдёт, если мы закодируем его переворот?
Хм. Порядок чисел в обоих списках остался одинаковым!
Давайте попробуем перевернуть строку с флагом США:

Порядок чисел не перевернулся! Вместо этого поменялись местами группы из четырёх чисел, представляющих кодовые точки Unicode
и . Порядок чисел в каждой из кодовых точек остался неизменным.Что всё это значит?
В названии статьи ложь! Строку с флагом-эмодзи перевернуть можно. Но переворот символов, состоящих из нескольких кодовых точек, может привести к неожиданным результатам. Особенно если вы раньше никогда не слышали о кодировках и кодовых точках.
Но правильно ли поступает Python, переворачивая порядок кодовых точек? Не будет ли логичнее оставить неизменными символы, представленные несколькими кодовыми точками? На самом деле, это зависит от обстоятельств. Не существует канонического способа переворота строк, или, по крайней мере, он мне неизвестен.
???????? Задача: как бы вы реализовали функцию, переворачивающую строку, но при этом сохраняющую неизменными символы, закодированные как последовательности кодовых точек? Сможете ли вы сделать это с нуля? Есть ли в вашем языке программирования пакет, способный сделать это? Как этот пакет решает данную задачу?
Почему это вообще важно?
Из этого расследования можно сделать пару важных выводов.
Во-первых, если мы не знаем, какую кодировку использовали для кодирования некоего текста, то не можем гарантировать, что декодированный текст будет точно совпадать с исходным.
Во-вторых, несмотря на распространённость UTF-8, существует множество систем, использующих другие кодировки. Помните об этом, считывая текст из файла, особенно если он создан в другой операционной системе или в другой стране. Всегда явным образом указывайте, какая кодировка использовалась для кодирования или декодирования текста.
Например, функция
open() Python имеет параметр encoding, задающий кодировку, используемую при чтении или записи текста в файл. Пользуйтесь им.Что дальше?
Мы раскрыли большой пласт информации, но есть ещё множество неотвеченных вопросов. Запишите вопросы, которые у вас остались, и воспользуйтесь приведёнными в этой статье техниками расследования, чтобы ответить на них самостоятельно.
???? На написание этой статьи меня вдохновил вопрос Уилла Макгугана в Twitter. Пост Уилла можно прочитать здесь, в нём есть куча примеров безумия кодировок.
Вот некоторые вопросы, которые вам могут показаться интересными:
- При преобразовании
"????????????????????????????"в список мы получим набор строк, начинающихся с"\U". Что это за строки и что они означают? - Закодированный в UTF-8
"????????????????????????????"содержит аж целых 28 байт информации. Чем ???????????????????????????? отличается от? Какие другие флаги кодируются 28 байтами? - Что произойдёт при переворачивании
 ? Учитывая то, что мы узнали о флагах-эмодзи, как вы можете объяснить этот переворот? Какие другие флаги имеют похожий переворот?
? Учитывая то, что мы узнали о флагах-эмодзи, как вы можете объяснить этот переворот? Какие другие флаги имеют похожий переворот? - Существуют ли флаги-эмодзи, кодируемые одной кодовой точкой?
- Многие платформы поддерживают эмодзи разного цвета, например, эмодзи «палец вверх», который может рендериться с разным цветом кожи. Как один символ кодируется с разными цветами?
- Как проверить, является ли содержащая эмодзи строка палиндромом?
Комментарии (18)

v1000
09.02.2022 11:25Великолепно!
Еще, наверное, похожая свистопляска с датой и временем, начиная с 100500 вариантов формата даты, заканчивая часовыми поясами и дополнительными секундами (leap seconds).

Xeldos
09.02.2022 12:27+5https://habr.com/ru/post/146109/
PS Сколько же в заметке воды! Мне интересно, люди действительно так думают, вот процесс мышления он именно так организован, или это специально для статьи размазывают белую кашу по чистому столу?

Color
09.02.2022 12:37+2Американские авторы такие американские... скажите спасибо, что статься не начинается с рекламы статьи и как читатель сможет лихо вертеть флагами к концу прочтения

tbl
09.02.2022 11:34Странно, как же bidi и shape работают в ICU? Они же как раз заточены находить и суррогатные символы, и теги, и прочие штуки, определяющие кодирование в стандарте.



alcanoid
09.02.2022 11:46+5Какая-то идеологическая провокация! Переверните американский флаг и получите Советский Союз. :)

Andy_U
09.02.2022 14:40+2Вы напомнили мнемоническое правило запоминания цветов Российского флага: КГБ, т.е. красный, голубой, белый, но поскольку у нас все через одно место, порядок цветов нужно инвертировать.

domix32
09.02.2022 19:09Останется с пространственной ориентацией цветов не напутать дабы не стать атлетом с фамилией а ля Бженчишчикевич.

kovserg
10.02.2022 10:38Вы видимо не в курсе что сама операция переворачивания строки не является целью.
Обычно после переворачивание проводятся некоторые операции и затем строка переворачивается еще раз.
ps: меня больше печалит то что при выводе моноширинным шрифтом имеем разную ширину символов. 1234567 | 1 アイウエオカキ | 2 あいうえおかき | 3 АБВГДЕЁ | 4 ΑΒΓΔΕΖΗ | 5 ABCDEFG | 6 ???????????????????????????? | 7 ???????????????????????????? | 8 ???????????????????????????? | 9 ⒶⒷⒸⒹⒺⒻⒼ | A ❶❷❸❹❺❻❼ | B ➀➁➂➃➄➅➆ | C ???????????????????????????? | D ???????????????????????????? | E ⬛⬜⬛⬜⬛⬜⬛ | F | G □■□■□■□ | H ⬠⬟⬠⬟⬠⬟⬠ | I ???????????????????????????? | J ░▒▓█▓▒░ | . 1234567 |

staticmain
Multibyte-кодировки нельзя переворачивать, какой сюрприз.
rsashka
Нельзя, толькое если строка интерпретируется как последовательность байтов.
petropavel
Можно, в статье это есть. Просто она совершенно нереально разбавлена, тут столько воды, что можно 95% выкинуть и статья только выиграет. А так, конечно, редкий читатель долетит до середины.
Совет, начинайте читать с «Но как насчёт других символов». Там показывается, что utf8 символы переворачивать можно. И что "флаг" он особенный.
staticmain
Да всё равно нельзя, даже если вы посимвольно это делаете. Потому что нонче человек + мужчина + борода = мужчина с бородой, а наоборот это не работает.
ShadowTheAge
Представление текста это большая пирамида уровней над уровнями над уровнями. На каждом этапе уровни можно перевернуть, но на следующем этапе получится мусор
Байты можно перевернуть, но на этапе utf8 (или другой кодировки) получится мусор
utf8 code points можно перевернуть но на этапе эмодзи или других составных символов (диактрика и т.п) получится мусор (тема статьи)
графем кластеры можно перевернуть но на этапе слов получится мусор
Слова можно перевернуть но на этапе предолжений получится мусор
Предложения можно перевернуть но на этапе параграфа получится мусор
Даже биты в байте можно перевернуть!
и т.п.
petropavel
ну да. и статья по сути о том, что питон переворачивает символы. Не байты. И не группы символов То есть multibyte-кодировки, в принципе, работают. Какая-нибудь sjis, например. А комбинации из символов переворачиваются посимвольно.
äперевернётся сам в себя, когда это один символ. И испортится, если этоa+̈только этот простой факт там так закопан в тексте, что не найдёшь.
ShadowTheAge
"символ" плохое слово потому что все его по разному понимают и когда начинают обсуждать начинаются проблема из-за вкладывания разных смыслов. Поэтому в спецификации utf8 есть конкретно: