
Pyramids of Egypt by acrosstars22
Масштабирование нод и узлов в кластере Kubernetes может занять несколько минут, если использовать настройки по умолчанию. Над сокращением этого времени стоит поработать, если возможны периоды взрывного роста нагрузки на сервис.
Команда Kubernetes aaS VK Cloud Solutions перевела статью о том, как задавать размеры узлов кластера, настраивать горизонтальное и кластерное автомасштабирование и выполнять избыточное резервирование ресурсов под кластер для ускорения масштабирования.
Три способа автомасштабирования в Kubernetes
В Kubernetes есть несколько сущностей, относящихся к автомасштабированию, в том числе:
-
Horizontal Pod Autoscaler, HPA,
-
Vertical Pod Autoscaler, VPA,
- Cluster Autoscaler, CA.
Эти автоскейлеры относятся к разным категориям, поскольку решают разные задачи.
Горизонтальный автоскейлер разработан для увеличения количества реплик в развертываниях. При росте трафика автоскейлер может увеличивать количество реплик, чтобы приложение справлялось с растущим числом запросов.
 Горизонтальный автоскейлер регулярно проверяет такие показатели, как память и ЦП
Горизонтальный автоскейлер регулярно проверяет такие показатели, как память и ЦП
Если показатели превышают заданный пользователем порог, то автоскейлер создает дополнительные поды
Вертикальный автоскейлер полезен, когда вы больше не можете создавать копии нод, но необходимость обрабатывать больше трафика не отпала.
Например, вы не можете (легко) масштабировать базу данных, добавив новые ноды. Для базы данных может потребоваться сегментирование или настройка реплик, доступных только для чтения. Но вы можете заставить базу данных обрабатывать больше подключений, увеличив доступную для нее память и ЦП. Именно в этом и заключается цель вертикального автомасштабирования — увеличение размера ноды.

Вам будет недостаточно увеличить количество реплик, чтобы масштабировать БД в Kubernetes

Вы можете создать ноду с бо̒льшим количеством ресурсов. Вертикальный автоскейлер делает это автоматически
Наконец, кластерный автоскейлер подготавливает новую ноду и добавляет ее в кластер, когда в нем заканчиваются ресурсы. Если пустых узлов слишком много, автоскейлер кластера удалит их, чтобы сократить расходы.

При масштабировании нод в Kubernetes может не хватить места

Кластерный автоскейлер предназначен для увеличения количества узлов в кластере
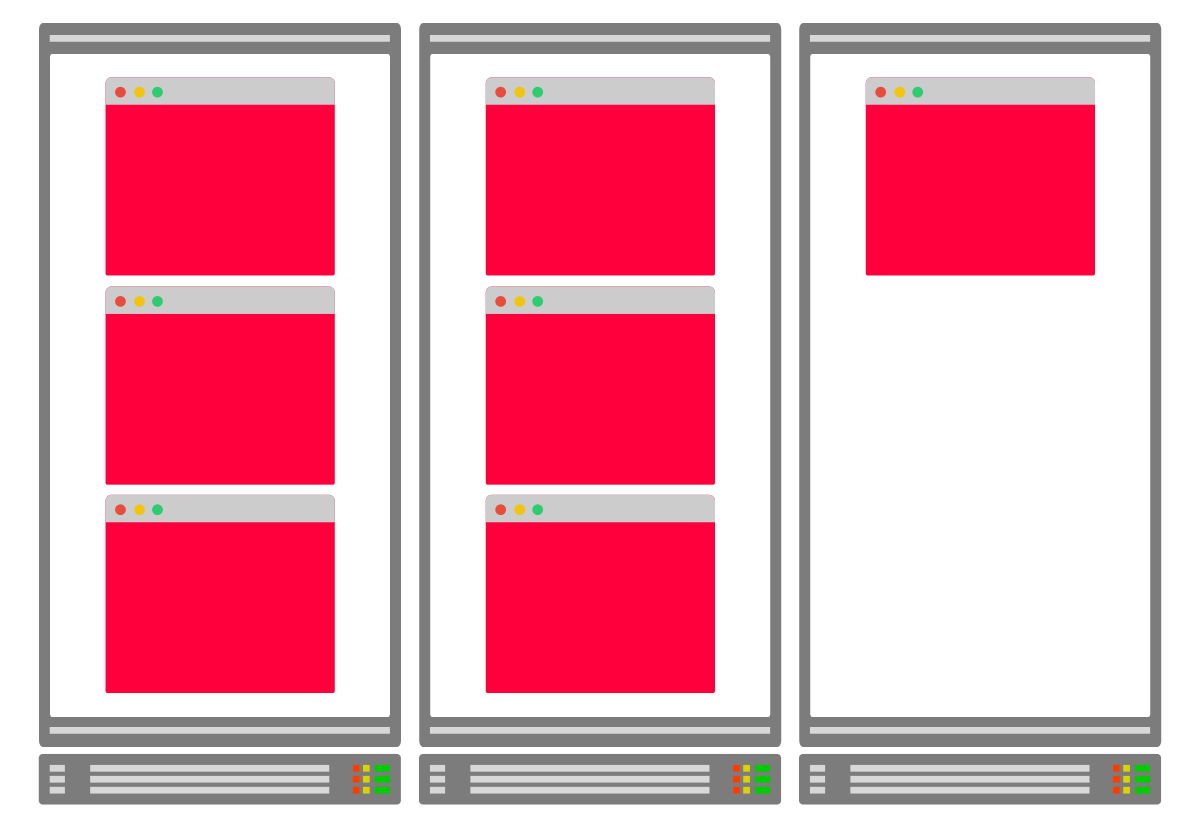
Вы можете увеличивать количество нод, не беспокоясь об узлах, в которых они создаются. Кластерный автоскейлер сам создаст дополнительные узлы
Хотя все эти компоненты что-то «автомасштабируют», они не связаны друг с другом, поскольку решают совершенно разные задачи и используют разные концепции и механизмы. Более того, они разрабатываются как отдельные проекты и могут использоваться независимо друг от друга.
Однако масштабирование кластера требует точной настройки автоскейлеров, чтобы они работали согласованно. Давайте разберем это на примере.
Что-то пошло не так с автоматическим масштабированием нод
Допустим, у вас есть приложение, которое всегда требует и использует 1,5 ГБ памяти и 0,25 vCPU. Вы зарезервировали кластер с одним узлом в 8 ГБ и двумя виртуальными ЦП. Этого как раз должно хватить на четыре ноды, даже с небольшим запасом.
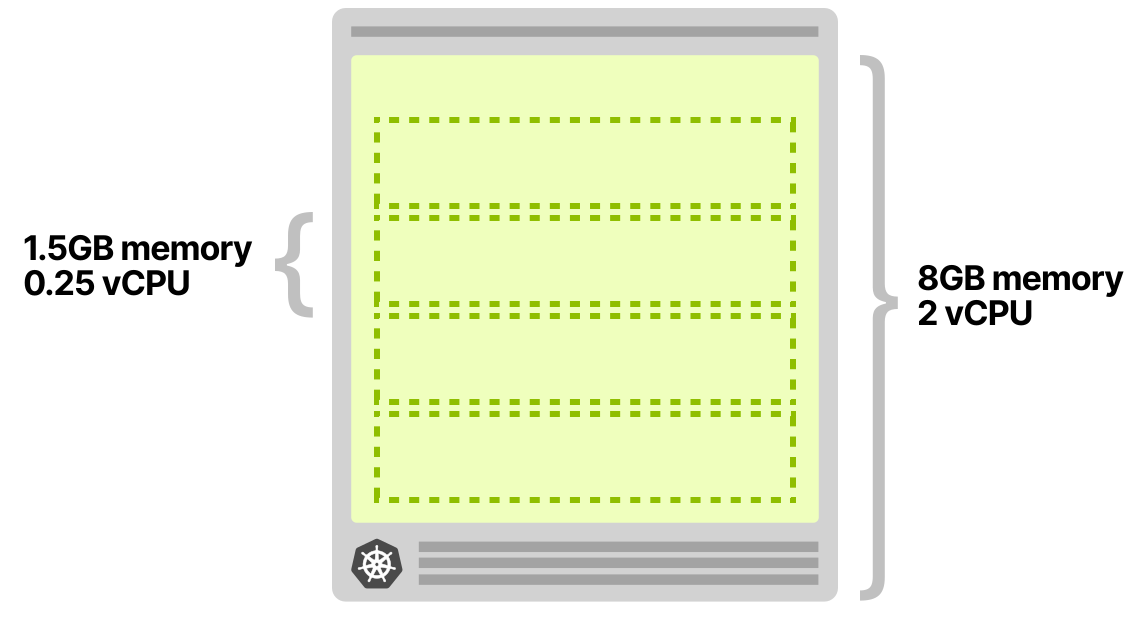
Вы развертываете одну ноду и настраиваете его так:
-
Горизонтальный автоскейлер добавляет реплику каждые 10 входящих запросов. То есть при 40 одновременных запросах он должен масштабироваться до 4 реплик.
-
Кластерный автоскейлер добавляет узлы, когда ресурсы заканчиваются.
Горизонтальный автоскейлер может масштабировать реплики в развертывании с помощью настраиваемых показателей (custom metrics), таких как количество запросов в секунду (RPS) от контроллера Ingress.
Допустим, вы отправляете 30 одновременных запросов в кластер и наблюдаете следующее:
- Горизонтальный автоскейлер начинает масштабирование модулей.
- Созданы две новых ноды.
- Кластерный автоскейлер не срабатывает — в кластере не создается новый узел.
Что логично, поскольку в узле достаточно места для еще одного модуля.

Вы увеличиваете трафик до 40 одновременных запросов и смотрите снова:
- Горизонтальный автоскейлер создает еще одну ноду.
- Нода находится на рассмотрении и не может быть развернута.
- Кластерный автоскейлер запускает создание нового узла.
- Узел подготавливается за 4 минуты. После этого развертывается ожидающая нода.

При масштабировании до четырех реплик четвертая реплика не развертывается на первом узле. Вместо этого она остается «в ожидании» (pending)

Автоскейлер создает новый узел, и нода наконец развертывается
Почему четвертая нода не развернута в первом узле? Модули, развернутые в кластере Kubernetes, потребляют ресурсы: память, ЦП и место на диске. Однако на том же узле есть операционная система и kubelet, которым также нужны память и процессор.
В рабочем узле Kubernetes память и ЦП делятся на:
- ресурсы, необходимые для запуска операционной системы и системных демонов, таких как SSH, systemd и т. д.;
- ресурсы, необходимые для запуска агентов Kubernetes, таких как kubelet, среда выполнения контейнера, детектор неполадок в узлах;
- ресурсы, доступные для нод;
- ресурсы, зарезервированные до порога вытеснения.
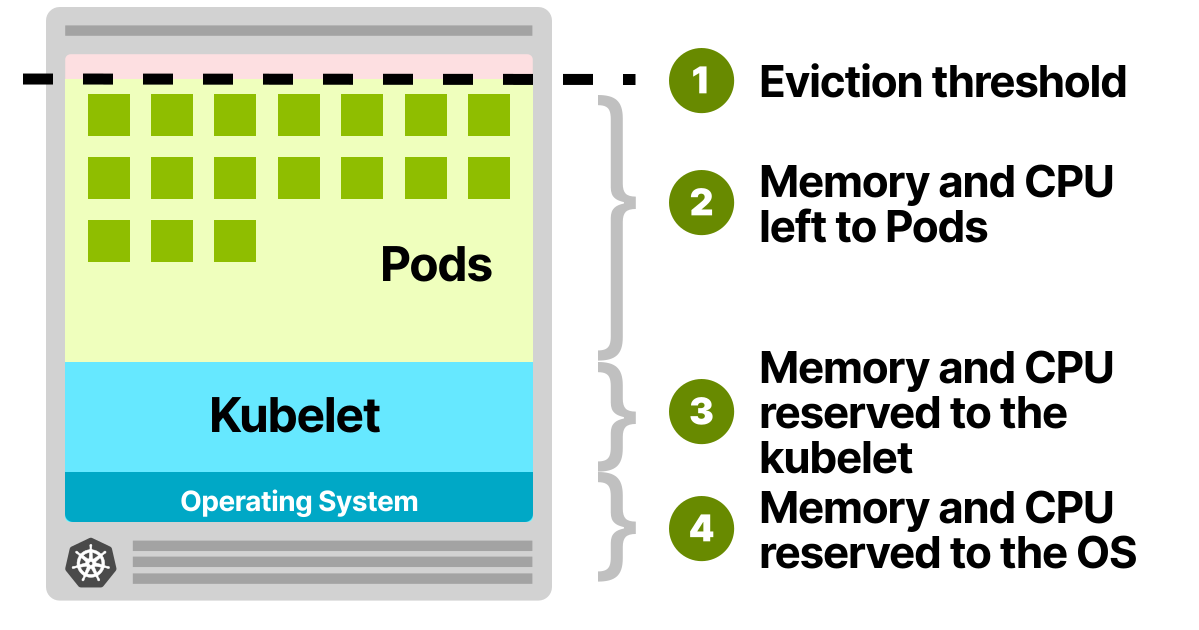
Все эти квоты можно настроить, но вам необходимо их учитывать.
В виртуальной машине с 8 ГБ и двумя виртуальными ЦП вы можете ожидать, что:
- 100 МБ памяти и 0,1 виртуального ЦП зарезервированы для операционной системы;
- 1,8 ГБ памяти и 0,07 виртуального процессора зарезервированы для kubelet;
- 100 МБ памяти зарезервированы для порога вытеснения.
Остальные ~6 ГБ памяти и 1,83 виртуальных ЦП могут использоваться модулями.
Если в кластере запущен DeamonSet, такой как kube-proxy, то вам следует дополнительно уменьшить доступную память и ЦП. Учитывая, что kube-proxy нужно 128 МБ памяти и 0,1 виртуального ЦП, для запуска модулей доступны только ~5,9 ГБ памяти и 1,73 виртуального ЦП.
Использование CNI (например, Flannel) и сборщика журналов (например, Fluentd) еще сильнее снижает объем доступных ресурсов.
После учета всех дополнительных ресурсов у вас остается место только для трех нод.
OS 100MB, 0.1 vCPU +
Kubelet 1.8GB, 0.07 vCPU +
Eviction threshold 100MB, 0 vCPU +
Daemonsets 128MB, 0.1 vCPU +
======================================
Used 2.1GB, 0.27 vCPU
======================================
Available to Pods 5.9GB, 1.73 vCPU
Pod requests 1.5GB, 0.25 vCPU
======================================
Total (4 Pods) 6GB, 1vCPUЧетвертая остается «ожидающей», если ее нельзя развернуть на другом узле.
Поскольку кластерный автоскейлер знает, что для четвертого модуля нет места, почему он не подготавливает новый узел? Почему он ждет статуса «в ожидании» у ноды, прежде чем запускает создание узла?
Как работает кластерный автоскейлер в Kubernetes
Кластерный автоскейлер не смотрит на доступную память или ЦП, когда запускает автомасштабирование. Вместо этого он реагирует на события и каждые 10 секунд проверяет, не появились ли не подлежащие планированию модули.
Нода не подлежит планированию, когда планировщик не может найти узел для ее размещения. Например, если нода запрашивает 1 vCPU, но в кластере доступно только 0,5 vCPU, такая нода помечается как не подлежащая планированию. Именно в этом случае кластерный автоскейлер инициирует создание нового узла.
CA сканирует текущий кластер и проверяет, подходит ли какой-либо из непланируемых модулей для нового узла.
Если у вас есть кластер с несколькими типами узлов (их часто называют группами или пулами узлов), то CA выберет один из них, используя следующие стратегии:
-
Random — выбирает тип узла случайным образом. Эта стратегия используется по умолчанию;
-
Most pods — выбирает группу узлов, которая будет планировать наибольшее количество модулей;
-
Least waste — выбирает группу узлов с наименьшим количеством простоев ЦП после масштабирования;
-
Price — выбирает группу узлов, которая стоит меньше всего;
-
Priority — выбирает группу узлов с наивысшим приоритетом (и вам нужно вручную назначить приоритеты).
После определения типа узла кластерный автоскейлер вызовет соответствующий API, чтобы зарезервировать новый вычислительный ресурс. Если вы используете AWS, то CA создаст новый экземпляр EC2. В Azure он создаст новую виртуальную машину, а в GCP — новый Compute Engine.
Может пройти некоторое время, прежде чем созданные узлы появятся в Kubernetes.
Когда вычислительный ресурс готов, узел инициализируется и добавляется в кластер, где могут быть развернуты незапланированные ноды. К сожалению, новые узлы обычно готовятся медленно: резервирование новой вычислительной единицы может занять несколько минут. Давайте углубимся в цифры.
Сколько времени уходит на автомасштабирование нод
Есть четыре основных фактора, которые определяют время, необходимое для создания нового модуля на новом узле:
- время реакции горизонтального автоскейлера,
- время реакции кластерного автоскейлера,
- время подготовки узла,
- время создания ноды.
По умолчанию kubelet очищает статистику использования ЦП и памяти модулем каждые 10 секунд. Каждую минуту сервер метрик агрегирует эти показатели и делает их доступными остальной части Kubernetes API.
Контроллер горизонтального автоскейлера проверяет показатели и принимает решение о масштабировании реплик в большую или меньшую сторону.
По умолчанию горизонтальный автоскейлер проверяет показатели модулей каждые 15 секунд.

Каждые 10 секунд кластерный автоскейлер проверяет кластер на наличие не подлежащих планированию модулей. Как только один или несколько модулей обнаружены, он запускает алгоритм, чтобы решить:
-
Сколько узлов необходимо для развертывания всех ожидающих нод.
-
Какой тип группы узлов следует создать.
Весь процесс должен занять:
-
не более 30 секунд для кластера, в котором менее 100 узлов, а в каждом из них до 30 модулей. Средняя задержка — около 5 секунд;
-
не более 60 секунд в кластере от 100 до 1000 узлов. Средняя задержка — около 15 секунд.

Кроме того, некоторое время уходит на подготовку узла — в основном, оно зависит от облачного провайдера. Подготовка нового вычислительного ресурса, как правило, занимает от 3 до 5 минут.

Наконец, нода должна быть создана средой выполнения контейнера.
Запуск контейнера не должен занимать более нескольких миллисекунд, но для загрузки образа контейнера может потребоваться несколько секунд.
Если вы не кэшируете образы контейнеров, то загрузка образа из реестра контейнеров может занять от пары секунд до минуты, в зависимости от размера и количества слоев.

Таким образом, общее время для запуска автомасштабирования, когда в текущем кластере нет места, складывается из следующих составляющих:
-
Горизонтальному автоскейлеру может потребоваться до 1 минуты 30 секунд, чтобы увеличить количество реплик.
-
Кластерному автоскейлеру нужно меньше 30 секунд для кластера, в котором менее 100 узлов, и менее минуты — для кластера, в котором более 100 узлов.
-
Поставщику облачных услуг может потребоваться от 3 до 5 минут для создания компьютерного ресурса.
-
Среде выполнения контейнера может потребоваться до 30 секунд для загрузки образа контейнера.
В худшем случае при небольшом кластере получается так:
HPA delay: 1m30s +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m30sВ кластере с более чем 100 узлами общая задержка может составлять до 7 минут.
Готовы ли вы 7 минут ждать появления новых модулей, чтобы справиться с внезапным всплеском трафика? Можно ли настроить автомасштабирование так, чтобы уменьшить длительность подготовки нового узла?
Да, вы можете изменить:
- Время обновления для горизонтального автоскейлера. Его контролирует флаг
--horizontal-pod-autoscaler-sync-period, по умолчанию — 15 секунд.
- Интервал очистки метрик на сервере метрик. Его контролирует флаг
metric-resolution, по умолчанию — 60 секунд.
- Частоту сканирования незапланированных модулей кластерным автоскейлером. Контролирует флаг
scan-interval, по умолчанию — 10 секунд.
- Способ кэширования изображения на локальном узле. Можно изменить с помощью такого инструмента, как kube-fledged.
Но даже если вы зададите значения поменьше, вы все равно будете ограничены длительностью подготовки ресурсов, которое зависит от облачного провайдера.
Можно ли что-то с этим сделать?
Раз длительность подготовки изменить нельзя, придется использовать обходной путь. Вы можете попробовать две вещи:
- По возможности не создавать новые узлы.
- Заранее создавать узлы, чтобы они уже были подготовлены, когда они вам понадобятся.
Давайте рассмотрим эти варианты.
Как выбрать оптимальный размера экземпляра узла Kubernetes
Выбор правильного типа экземпляра для кластера существенно влияет на стратегию масштабирования.
Давайте рассмотрим следующий сценарий. У вас есть приложение, которое запрашивает 1 ГБ памяти и 0,1 виртуального ЦП. Вы подготавливаете узел с 4 ГБ памяти и 1 виртуальным ЦП.
После резервирования памяти и ЦП для kubelet, операционной системы и порога вытеснения у вас остается ~2,5 ГБ памяти и 0,7 виртуального ЦП, которые можно использовать для запуска модулей.
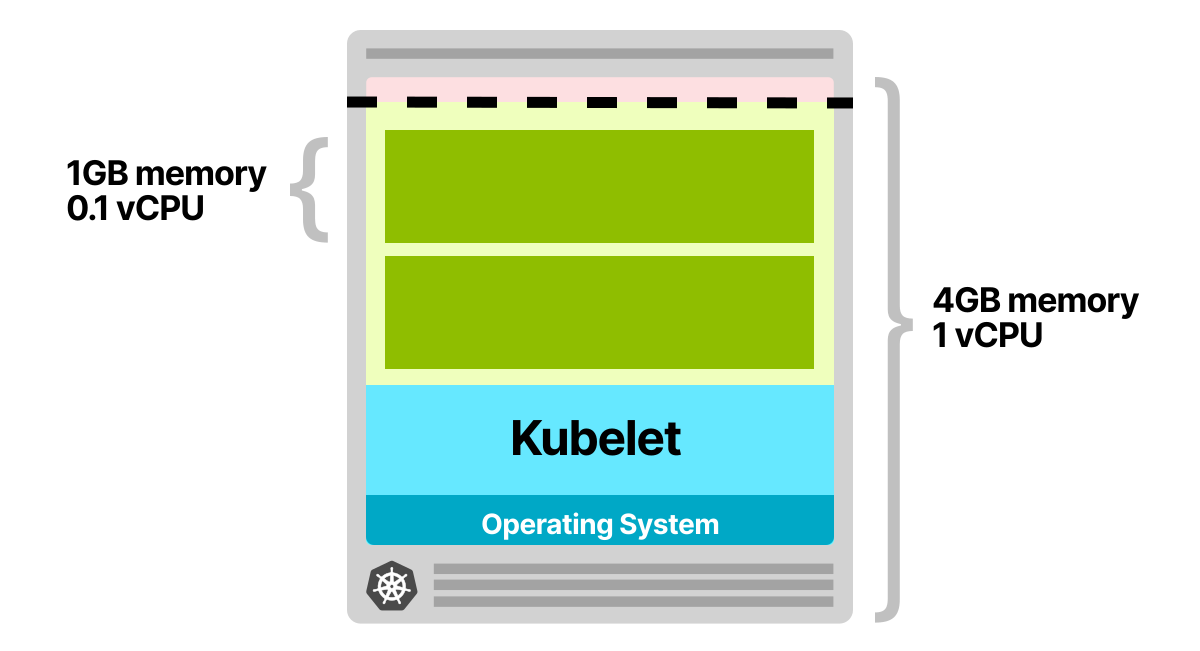
В вашем узле есть место только для двух модулей. При каждом масштабировании реплик вы, скорее всего, столкнетесь с задержкой до 7 минут — столько времени тратится на запуск горизонтального автоскейлера, запуск кластерного автоскейлера и выделение вычислительных ресурсов у облачного провайдера.
Давайте посмотрим, что произойдет, если вы решите использовать вместо этого узел, под который выделено 64 ГБ памяти и 16 виртуальных ЦП. После резервирования памяти и ЦП для kubelet, операционной системы и порога вытеснения у вас остается ~58,32 ГБ памяти и 15,8 виртуальных ЦП, которые можно использовать для запуска модулей. Доступное пространство может вместить 58 модулей, и, скорее всего, вам понадобится новый узел только тогда, когда у вас будет больше 58 реплик.

Кроме того, каждый раз, когда узел добавляется в кластер, можно развернуть несколько модулей. При этом у вас меньше шансов снова запустить кластерный автоскейлер и начать подготовку новых вычислительных ресурсов в облачном провайдере.
У больших экземпляров есть еще одно преимущество: больше соотношение между ресурсами, зарезервированными для kubelet, операционной системы и порога вытеснения, и доступными ресурсами для запуска модулей.
Взгляните на график, где изображена доступная для модулей память.

По мере увеличения размера экземпляра пропорционально растут ресурсы, доступные модулям. Другими словами, вы используете ресурсы эффективнее, чем если бы у вас было два экземпляра в половину этого размера каждый.
Нужно ли всякий раз выбирать самый большой экземпляр? Пик эффективности зависит от того, сколько модулей у вас может быть на узле. Некоторые облачные провайдеры ограничивают количество модулей. Например, у GKE их может быть 110. У других есть ограничения для каждого отдельно взятого экземпляра, продиктованные сетевой инфраструктурой (например, у AWS).
Выбор экземпляра большего размера не всегда хороший вариант. Вам также следует учитывать следующие моменты:
- Радиус взрыва (blast radius) — если у вас всего несколько узлов, то влияние отказавшего узла больше, чем если бы у вас было много узлов.
- Автомасштабирование менее рентабельно, поскольку следующий шаг — создание очень большого узла.
Даже если вы выбрали правильный тип экземпляра для кластера, вы все равно можете столкнуться с задержкой в предоставлении новых вычислительных мощностей. Можно ли обойти и это? А что, если создавать новый узел заранее, а не когда дело дошло до масштабирования?
Избыточное выделение ресурсов под узлы в кластере Kubernetes
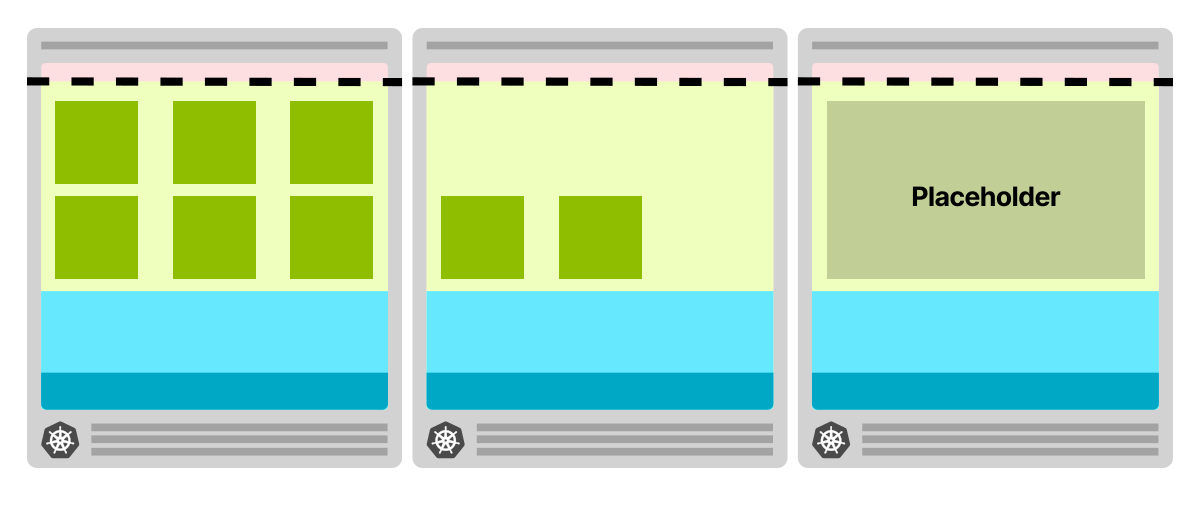
Если вы можете позволить себе всегда иметь запасной узел, то можно:
- Создать узел и оставить его пустым.
- Создать еще один пустой узел, как только в пустом узле появится нода.
Другими словами, вы учите автоскейлер всегда иметь запасной пустой узел на случай необходимости.
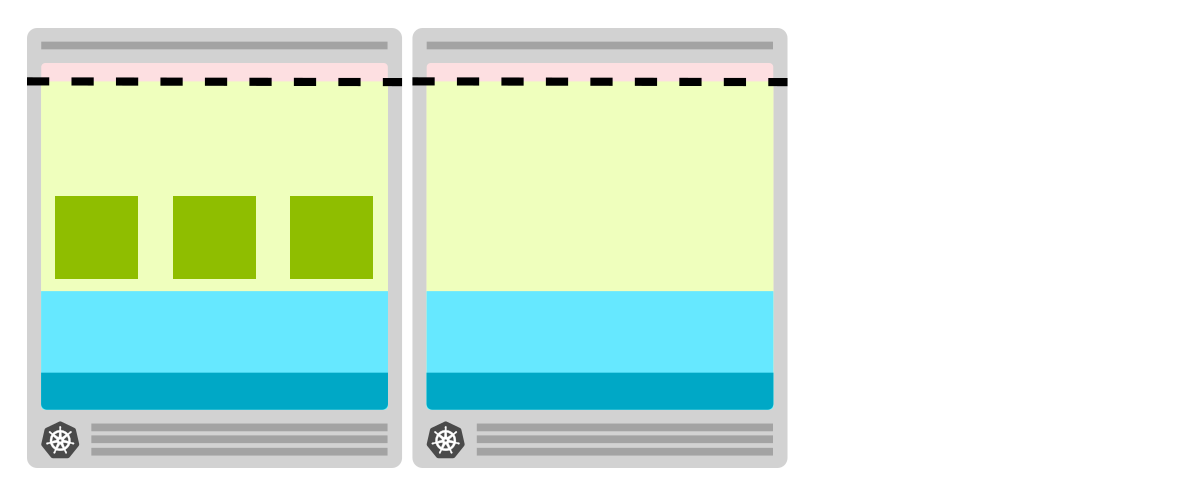
При избыточном выделении ресурсов под кластер узел всегда пуст и готов к развертыванию модулей
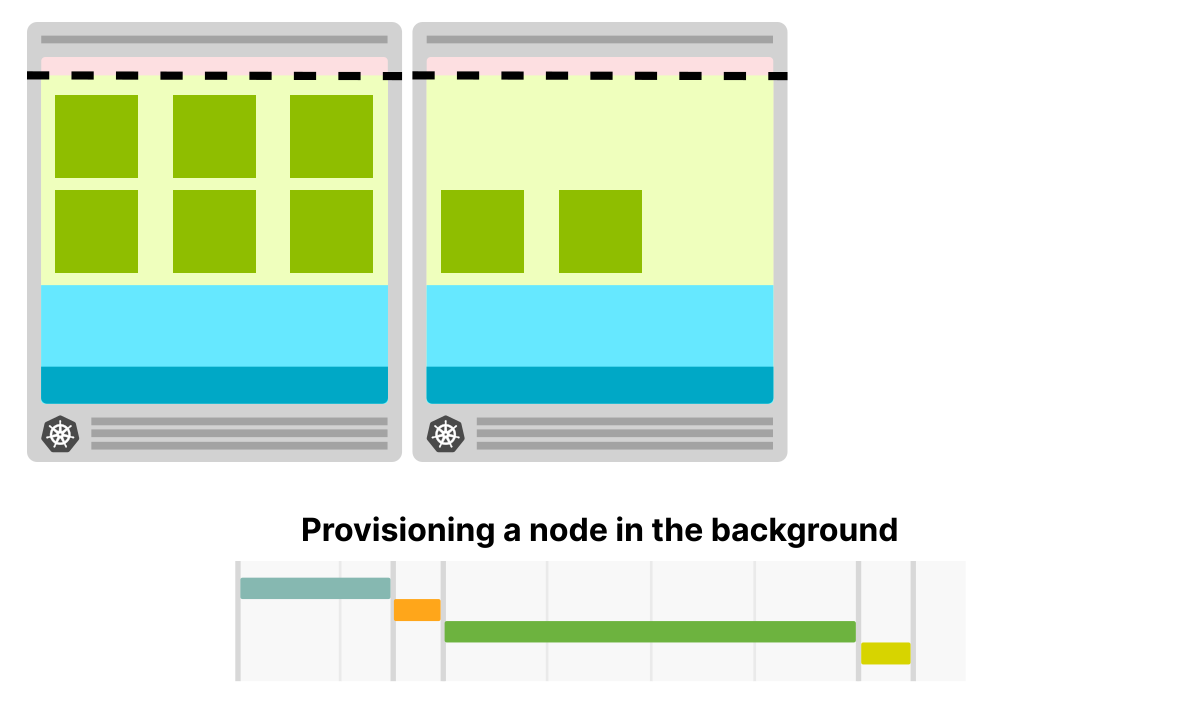
Как только нода создается в пустом узле, кластерный автоскейлер создает новый узел
Поскольку узел создается в фоновом режиме, вы, скорее всего, не заметите подготовки облачной машины
Получается компромисс: вы несете дополнительные расходы (одна пустая вычислительная единица, доступная в любое время), но увеличиваете скорость. Эта стратегия позволяет заметно быстрее масштабировать вычислительную инфраструктуру.
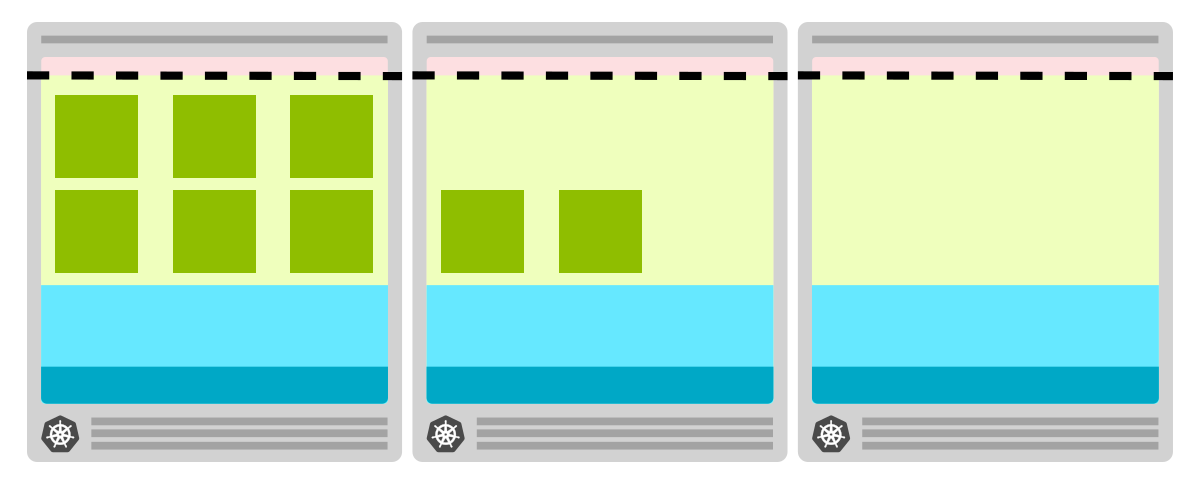
Но тут есть и плохие, и хорошие новости. Плохая новость: в кластерный автоскейлер эта функция не встроена. Его нельзя настроить на проактивную работу, и нет флага, позволяющего всегда предоставлять пустой узел. Хорошая новость: вы можете обойти это ограничение, запустив развертывание с достаточным количеством запросов, чтобы зарезервировать целый узел. Вы можете рассматривать эту ноду как заглушку: он
Как только настоящая нода создана, вы можете удалить заглушку и развернуть ноду.
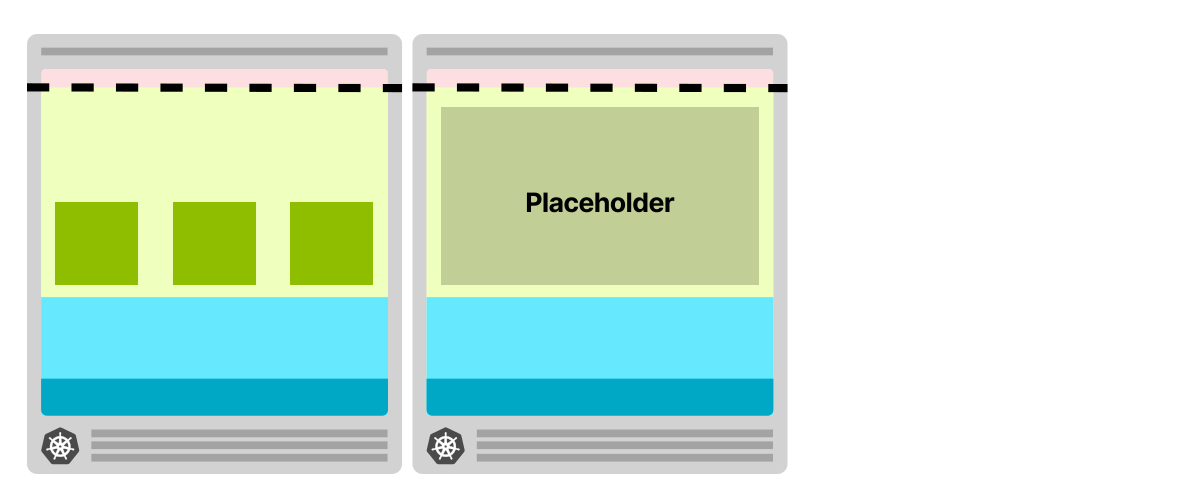
В кластере с избыточным выделением ресурсов у вас есть нода в качестве заглушки с низким приоритетом
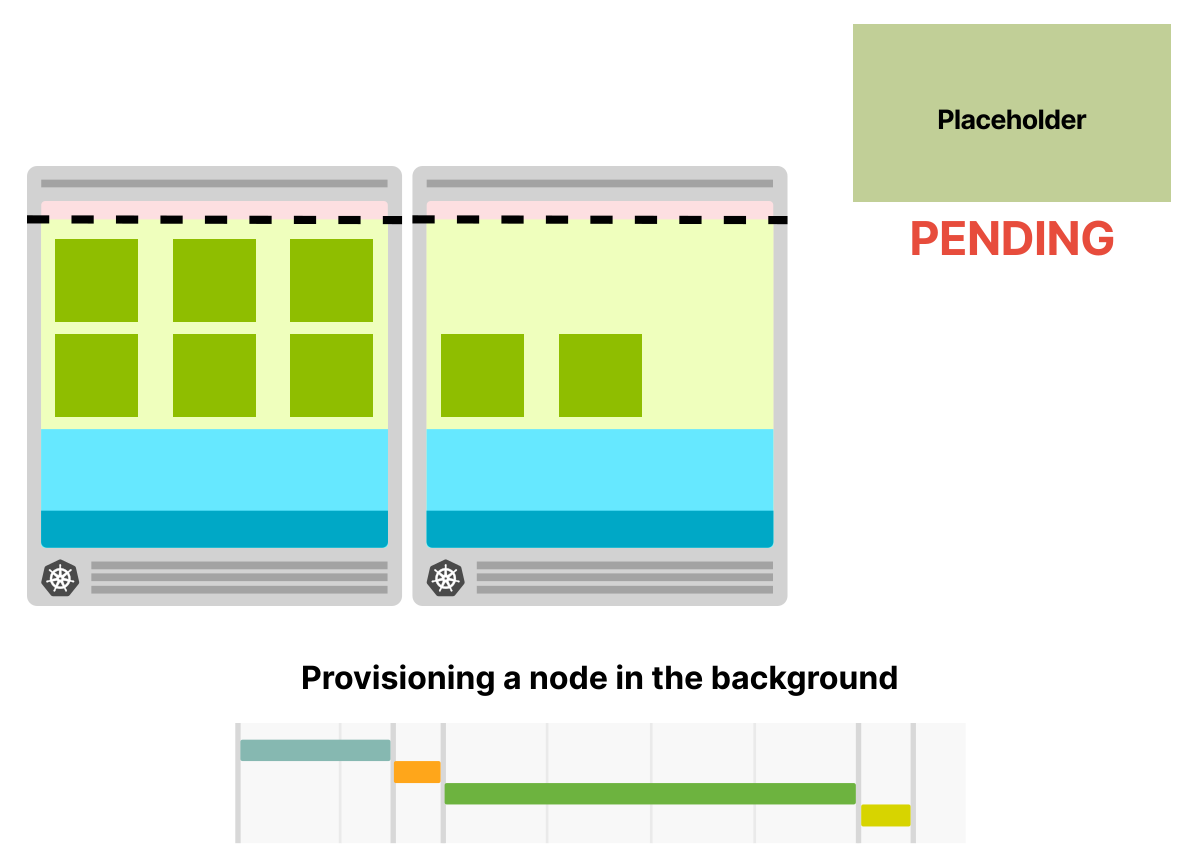
Как только вы создаете больше реплик, планировщик удаляет ноду-заглушку и развертывает новую ноду. Нода-заглушка не подлежит планированию и запускает автоматическое масштабирование кластера
В фоновом режиме подготавливается новый узел, и в нем развертывается нода-заглушка
Обратите внимание, что на этот раз вам все равно придется подождать 5 минут, пока узел будет добавлен в кластер, но при этом вы можете продолжать использовать текущий узел. Тем временем в фоновом режиме создается новый узел.
Как этого добиться? Избыточное выделение ресурсов можно настроить с помощью развертывания, в котором запущена вечно «спящая» нода.
<source>
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'Особое внимание стоит уделить требованиям к памяти и процессору. Планировщик использует эти значения, чтобы решить, где развернуть ноду. В этом конкретном случае они используются для резервирования места.
Вы можете подготовить одну большую ноду, требования которой примерно соответствуют доступным ресурсам узла. Убедитесь, что вы учитываете ресурсы, потребляемые kubelet, операционной системой, kube-proxy и т. д. Если у экземпляра узла есть два виртуальных ЦП и 8 ГБ памяти, а доступные ресурсы для модулей составляют 1,73 виртуальных ЦП и ~5,9 ГБ памяти, то запасная нода должна соответствовать последней паре параметров.

Чтобы гарантировать вытеснение модуля-заглушки при создании настоящего модуля, вы можете использовать приоритеты и вытеснения. Приоритет модуля указывает на важность одного модуля в сравнении с другими. Когда нода не может быть запланирована, планировщик пытается вытеснить ноду с более низким приоритетом, чтобы запланировать ожидающую.
Вы можете настроить приоритеты модуля в кластере с помощью PodPriorityClass:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: 'Priority class used by overprovisioning.'Поскольку по умолчанию приоритет модуля равен
0, а PriorityClass для overprovisioning равен -1, эти модули будут исключены первыми, когда в кластере закончится место.У
PriorityClass есть еще два необязательных поля: globalDefaultи
description.- В поле
descriptionможно вписать памятку, чему посвященPriorityClass.
- Поле
globalDefaultуказывает, что значение этогоPriorityClassдолжно использоваться для модуля безpriorityClassName. В системе может существовать только одинPriorityClassсglobalDefault, установленным вtrue.
Вы можете назначить приоритет модулю-заглушке следующим образом:
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: reserve-resources
image: k8s.gcr.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'Настройка завершена!
Когда в кластере недостаточно ресурсов, нода-заглушка вытесняется, и ее место занимают новые модули. Поскольку нода-заглушка становится непланируемой, она заставляет кластерный автоскейлер добавлять в кластер дополнительные узлы.
Теперь, когда вы готовы к избыточному выделению ресурсов в кластере, стоит взглянуть на оптимизацию приложений для масштабирования.
Как правильно подобрать требования к памяти и ЦП для модулей
Кластерный автоскейлер принимает решение о масштабировании в зависимости от того, есть ли ожидающие модули. Планировщик Kubernetes назначает (или не назначает) ноду узлу, основываясь на ее требованиях к доступной памяти и процессору. Поэтому важно указать правильные требования к рабочим нагрузкам, иначе вы можете запустить автомасштабирование слишком поздно или слишком рано.
Давайте рассмотрим следующий пример. Вы отпрофилировали приложение и выяснили:
- При средней нагрузке приложение потребляет 512 МБ памяти и 0,25 виртуального ЦП.
- На пике приложение, вероятно, потребляет до 4 ГБ памяти и 1 виртуальный ЦП.

Ограничение для вашего контейнера — 4 ГБ памяти и 1 виртуальный ЦП. Но что там с требованиями? Планировщик использует требования модуля к памяти и ЦП, чтобы выбрать лучший узел перед созданием модуля.
Итак, вы могли бы:
- Установить количество запросов ниже фактического среднего использования.
- Подойти к вопросу консервативно и задавать требования ближе к пределу.
- Установить требования в соответствии с фактическими ограничениями.
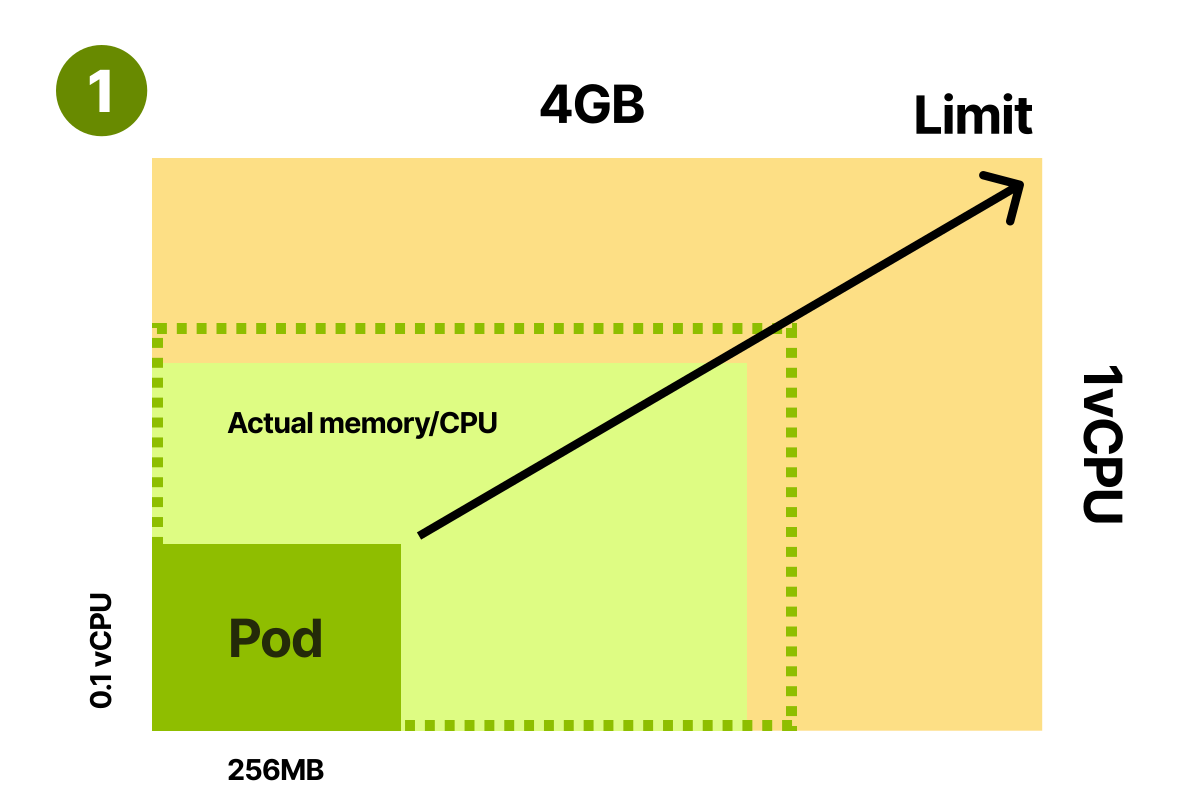
Вы могли бы указывать требования, которые меньше среднего потребления приложения
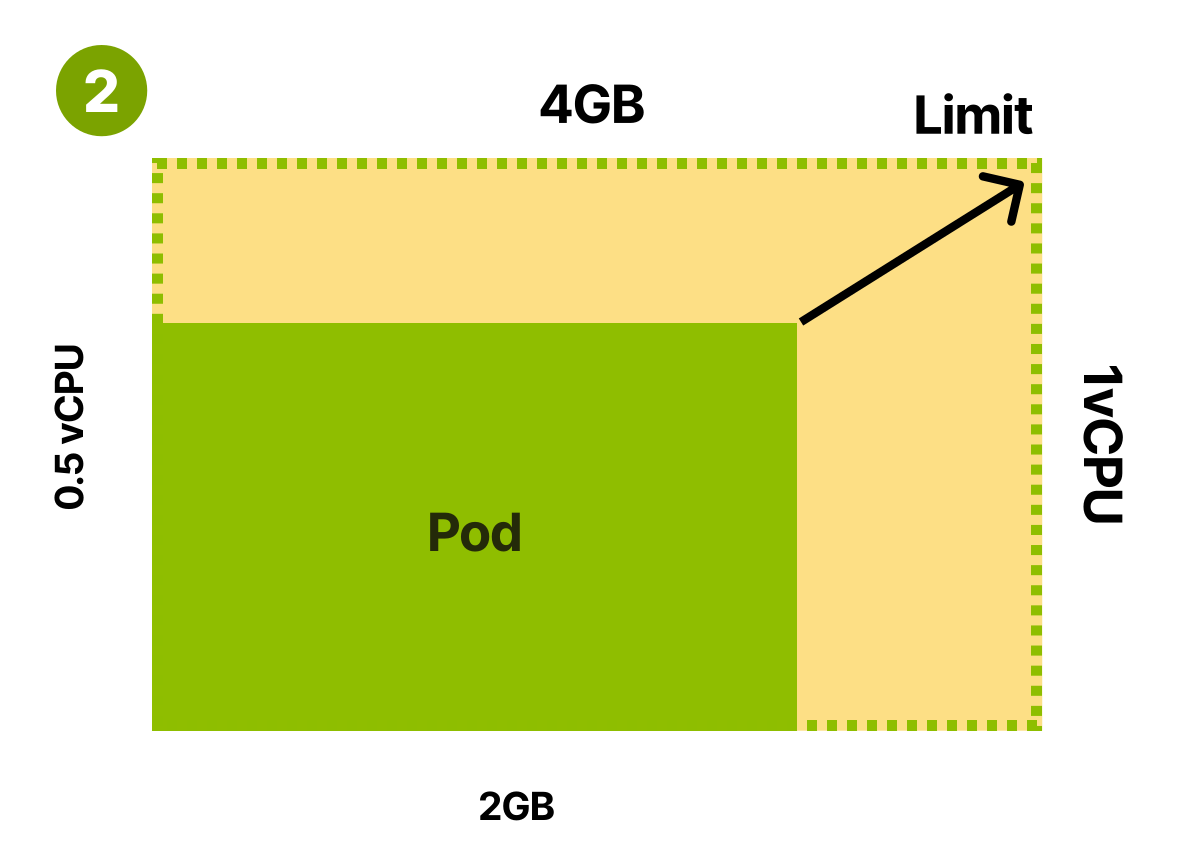
Вы могли бы указывать требования, которые соответствуют фактическому использованию
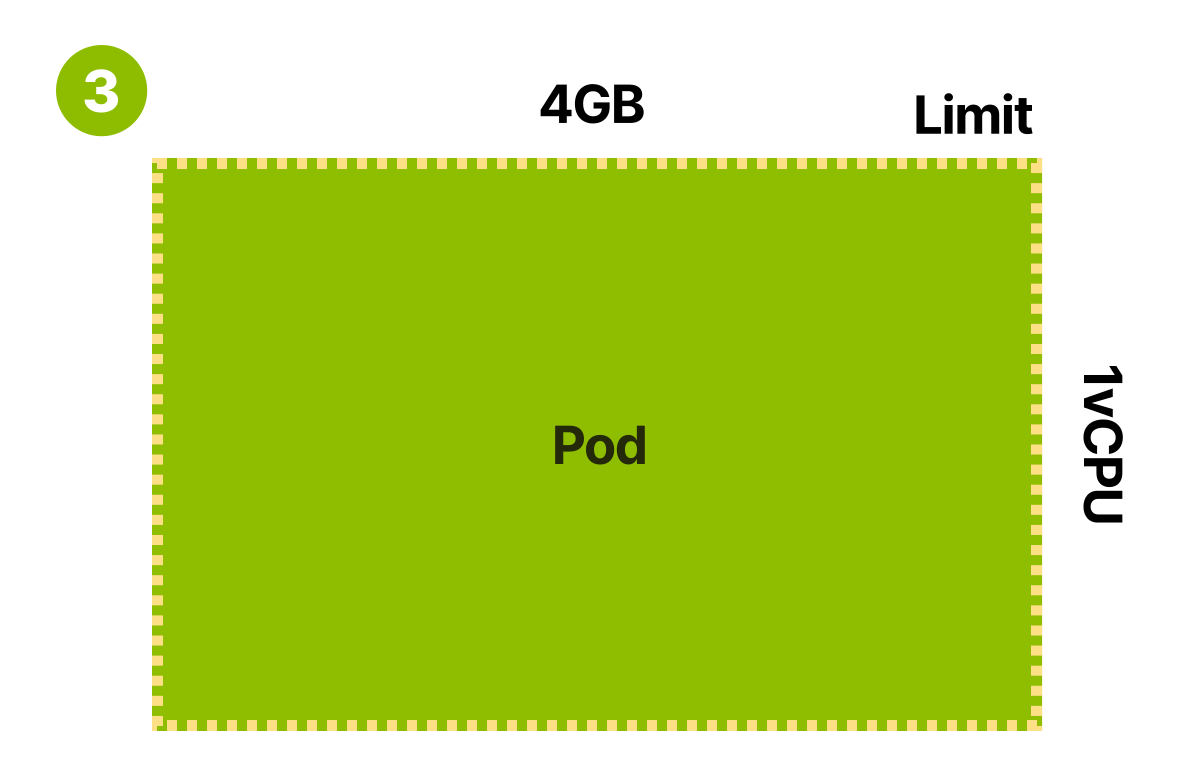
Вы могли бы указывать повышенные требования, которые будут соответствовать лимитам приложения
Задавать требования ниже фактического использования проблематично, поскольку узлы часто будут перегружены. Например, вы можете задать требование к памяти в 256 МБ. Тогда планировщик Kubernetes сможет вместить вдвое больше модулей для каждого узла. Однако на практике модули используют вдвое больше памяти, начинают конкурировать за ресурсы (ЦП) и в итоге вытесняются (недостаточно памяти на узле).

Избыточное резервирование ресурсов под узлы может привести к чрезмерному вытеснению, увеличению объема работы для kubelet и значительному изменению планирования.
Что произойдет, если вы установите требования равными лимитам приложения? В Kubernetes это часто называют классом гарантированного качества обслуживания. По сути, это означает, что вероятность прерывания и вытеснения модуля близка к нулю. Планировщик Kubernetes резервирует весь ЦП и память для модуля на назначенном узле. Модули с гарантированным качеством обслуживания стабильны, но при этом неэффективны. Если ваше приложение использует в среднем 512 МБ памяти, но вы зарезервировали для него 4 ГБ, то большую часть времени у вас остаются неиспользованными 3,5 ГБ.
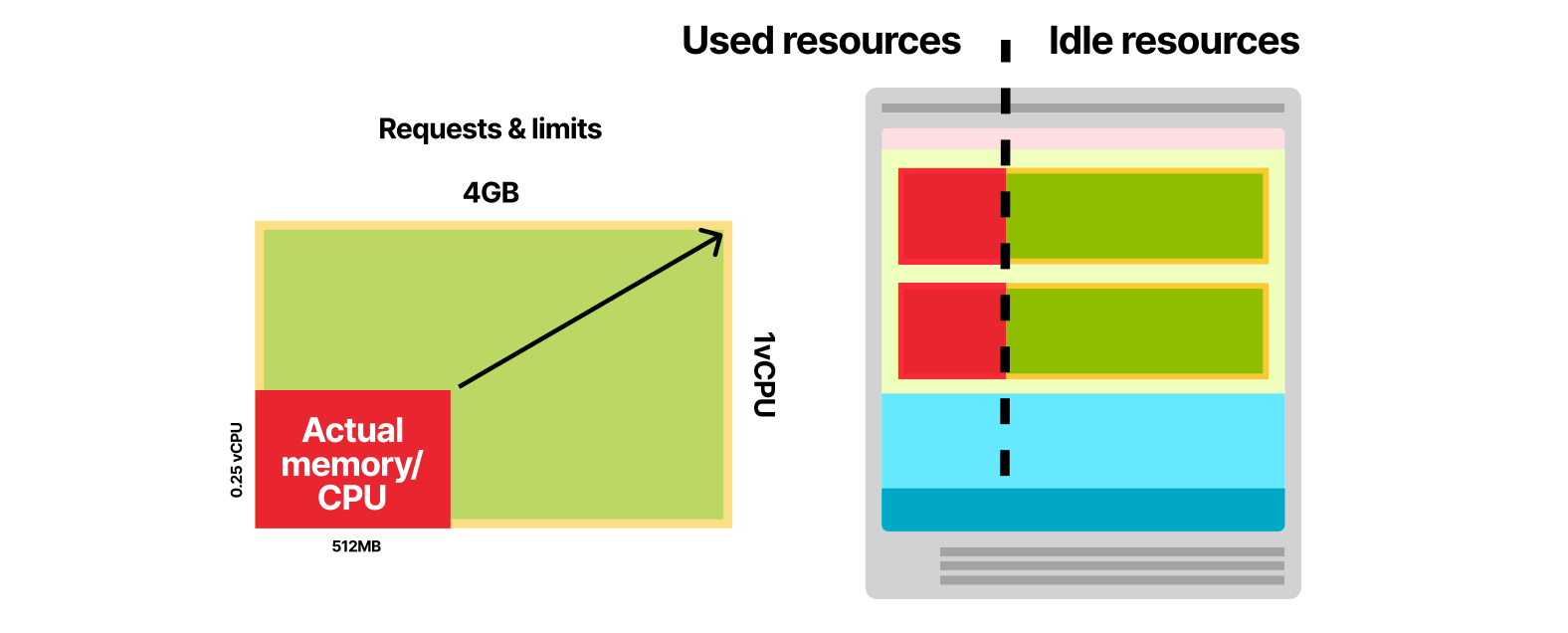
Стоит ли оно того? Если вам нужна дополнительная стабильность — да. Но если вам нужна эффективность, то вы можете понизить требования и оставить промежуток между ними и лимитом. Это часто называют взрывным (burstable) классом качества обслуживания, то есть базовое потребление модуля иногда может резко перерастать в использование большего объема памяти и ЦП.
Когда требования к ресурсам соответствуют их фактическому использованию приложением, планировщик эффективно упаковывает ваши модули в узлы.
Однако иногда приложению может потребоваться больше памяти или ЦП. В этом случае:
- Если в узле есть ресурсы, то приложение будет использовать их, пока не вернется к базовому потреблению.
- Если в узле не хватает ресурсов, то нода будет конкурировать за ресурсы (ЦП), и kubelet может попытаться вытеснить ноду (память).
Что следует использовать — гарантированное или взрывное качество обслуживания? Ориентируйтесь на свои задачи.
- Используйте гарантированное качество обслуживания (требования равны лимитам), если хотите минимизировать перепланирование и вытеснение модуля. Отличный пример — нода для базы данных.
- Используйте взрывное качество обслуживания (требования равны фактическому среднему использованию), когда хотите оптимизировать кластер и разумно использовать ресурсы. Подходит для веб-приложения или REST API.
Как выбрать правильные запросы и значения лимитов? Профилируйте приложение и измеряйте потребление памяти и ЦП в режиме ожидания, под нагрузкой и на пике.
Более простая стратегия состоит в том, чтобы развернуть вертикальный автоскейлер и дождаться, пока он предложит правильные значения. Вертикальный автоскейлер собирает данные из модуля и применяет регрессионную модель для экстраполяции требований и лимитов. Подробности вы можете узнать из этой статьи.
А как насчет уменьшения размера кластера?
Каждые 10 секунд кластерный автоскейлер смотрит, не упало ли потребление ресурсов ниже 50 %, и решает, нужно ли удалить узел. Другими словами, он суммирует запросы к ЦП и памяти для всех модулей в узле. Если они меньше половины емкости узла, то CA рассмотрит возможность уменьшения текущего узла.
Примечание. Кластерный автоскейлер не учитывает фактическое использование, лимиты ЦП и памяти. Вместо этого он рассматривает только запросы ресурсов.
Перед удалением узла CA делает следующее:
-
проверяет модули, чтобы убедиться, можно ли переместить их в другие узлы;
-
проверяет узлы, чтобы предотвратить их преждевременное удаление.
Если проверки пройдены, CA удаляет узел из кластера.
Почему бы не масштабировать автоматически, ориентируясь на память или ЦП?
Кластерные автоскейлеры, которые полагаются на данные ЦП и памяти, не учитывают модули при масштабировании вверх и вниз. Представьте, что у вас есть кластер с одним узлом и настройка автомасштабирования, при которой новый узел создается при достижении расхода 80 % ЦП. Вы решили создать развертывание с тремя репликами. Совместное использование ресурсов для трех модулей достигает 85 % ЦП. Новый узел подготовлен.
А что делать, если вам больше не нужны модули? У вас полный узел на холостом ходу — это не очень хорошо. Поэтому использование автомасштабирования такого типа с Kubernetes не рекомендуется.
Заключение
Чтобы определить и реализовать успешную стратегию масштабирования в Kubernetes, вы должны хорошо разбираться в следующих предметах:
- распределяемые ресурсы в узлах Kubernetes;
- точная настройка интервалов обновления для сервера метрик, горизонтального и кластерного автоскейлеров;
- разработка архитектуры кластера и планирование размеров экземпляров узла;
- кэширование образов контейнера;
- нагрузочное тестирование и профилирование приложений.
Подобрав подходящий инструмент мониторинга, вы можете последовательно тестировать стратегию масштабирования и настраивать скорость работы и стоимость кластера.
Мы развиваем наш собственный Kubernetes aaS, о котором рассказывали в этой статье. Будем признательны, если вы его попробуете и дадите нам обратную связь. Для тестирования пользователям при регистрации начисляется 3000 бонусных рублей.
Что еще почитать:
maxout
смешались в кучу кони, люди, ноды, узлы и поды.
подумал, может и в оригинале сумбур, но нет, там всё нормально.
читайте оригинал :)
stroitskiy
Соглы. Там еще поды иногда и модулями обзывают. Забавно и похоже на переводные книжки по ИТ- когда перевод в целом нелох с тз художественности. Но переводчик душе не ведает о чем речь.