Для чего
Всем привет. В своей предыдущей статье я описал общую идею создания площадки, где люди смогут объединяться в одну общую железячную сеть и использовать мощности друг друга. В основе этой идеи лежит идея создания распределенного кластера Kubernetes, к разворачиванию которого я планирую в скором времени приступить.
Но на начальном этапе важно подготовить сеть из однородных линукс машин, на которых стоит абсолютно одинаковый линукс, чтобы не пришлось решать одни и те же проблемы по несколько раз. А это может быть, т.к. все дистрибутивы линуксов имеют свои особенности, например, в плане того, какие модули ядра стоят как модули, а какие вкомпилены в ядро.
Поскольку ожидается, что изъявить желание подключиться к этой сети может любой пользователь с любыми железом и операционной системой (например, не только линукс, но и bsd системы и андроид, который является сильно урезанными линуксом), то хотелось бы иметь скрипт / программу / проект, который сможет сравнять все системы до одинаковых однородных линуксов по причинам, описанным выше. При этом в качестве реального железа может выступать и виртуальное, когда человек на своем оборудовании отрезает под виртуальные нужды часть своих мощностей и отдает их в сеть hardware банкинга.
Общее описание
Я назвал этот проект reoser (re-operation-system-er), т.к. он призван изменять операционную систему без физического доступа к оборудованию, и разместил его код в гитлабе. Работа над проектом не закончена и сейчас там еще много задач , но общий вектор развития уже ясен. Ниже я буду стараться делать оговорки в тех местах, где проект еще на что-то не способен.
Итак, приступим. Визуально мы хотим сделать следующее: из произвольного состава железа с произвольными операционными системами привести все к однообразному виду с системами идентичными, хотя бы в плане софта.
Исходим из того, что слева у нас может быть одна из следующих операционных систем:
Ubuntu
Fedora
OpenSuse
Archlinux
Alpine
Raspeberry Pi OS
Android [не закончено]
FreeBsd [не закончено]
И мы хотим превратить каждую из них в Debian 11 Bullseye. Сразу оговорюсь, что список планируется расширять и что с последними двумя пока есть проблемы. Но цель одна - превратить каждую из этих систем в Debian, чтобы все системы стали идентичны.
Debian выбран, в первую очередь, по причине наличия такого инструмента как debootstrap для создания chroot-окружения, а также потрясной статье, в которой автор @ioannes разобрал по косточкам процесс полной переустановки линукс без физического доступа к серверу. Когда я натолкнулся на этом материал то понял, что это то, что мне нужно. Только важно было все это автоматизировать и загнать в скрипт и адаптировать под новые версии операционных систем, а также под разные дистрибутивы, чтобы можно было использовать не только для переустановки debian в debian, но и преобразования НЕ debian систем в debian.
Подготовка оборудования
На начальном этапе нужно подготовить среду, где мы будем экспериментировать. Сейчас это все будут виртуальные машины, позже планирую провернуть это на сети "малинок" raspberrypi, но пока к этой задаче не приступал.
Сеть виртуальных машин будет следующая. Все они подняты в VirtualBox на Windows

И каждую из них нужно снабдить ssh и rsync сервисами, чтобы к ним можно было подключаться, подкидывать файлы и прогонять shell-скрипты.
У каждый системы свои особенности установки, но в большинстве случаев они банальны и не требуют детального описания. Пожалуй, сложности могут быть только в установке android и archlinux, но это тема отдельных публикаций. Однако в проекте reoser по каждой операционной системе есть README по установке и поднятию ssh и rsync сервисов, поэтому повторить мой эксперимент сможет каждый. Вот, например, README по установке и поднятию ssh / rsync для ArchLinux.
Теперь системы почти готовы для "удаленной" работы с ними. "Удаленной" пишется в кавычках, потому что эксперимент проводится на одной и той же машине. Последнее, что нужно сделать, это через настройки виртуального адаптера прокинуть порты. Покажу на примере ArchLinux
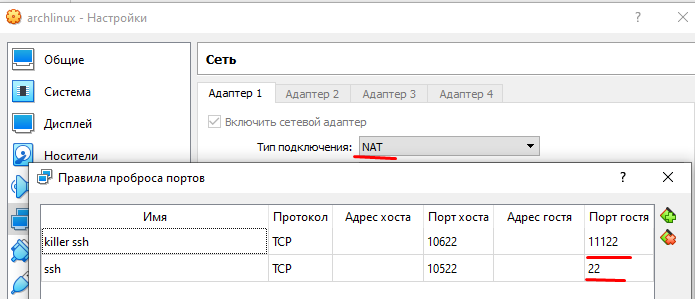
Из портов нужно прокинуть только 22-ой (стандартный порт ssh) и 11122 (порт ssh в промежуточной операционной системе убийце, речь о которой пойдет ниже). Термин "система убийца" взят из статьи, которую я уже упомянул выше. Дело в том, что в процессе замены исходной системы на новую, у нас будет создана временная операционная система убийца, которая будет существовать исключительно в оперативной памяти. Именно эта система в оперативной памяти и будет приоткрывать порт 11122, а чтобы к нему подсоединиться в виртуальной машине, разумеется нужен проброс портов.
Структура проекта reoser
Рассмотри из чего состоит проект reoser

Начну с простого: есть общий README, где описываются общие цели и моменты по проекту. По каждой используемой в виртуальном пространстве машине создана папочка в подкаталоге virtualbox. И в каждой из этих подпапочек есть свои файлы README, где рассматриваются особенности и проблемы, с которыми можно столкнуться при подготовке виртуальной машины к эксперименту. К сожалению, положить в репозиторий гитлаб готовый образ виртуальной машины я не могу, т.к. он весит порядка гигабайта, поэтому желающим повторить эксперимент, придется ставить системы самостоятельно. В этом деле, надеюсь, и помогут README файлы и именно поэтому я специально останавливаюсь на их обсуждении в этом абзаце.
Теперь перейдем к сути. Рабочими элементами проекта являются 3 файла:
docker-compose.yml
Dockerfile
entrypoint.sh
Когда запускается docker-compose, он собирает docker-образ проекта reoser, описанный в Dockerfile. А Dockerfile по сути занимается тем, что кладет в debian-систему файлик скрипта entrypoint.sh. Но это технические тонкости, просто мне лично удобно работать через docker-compose. Вся суть проекта reoser находится в файлике entrypoint.sh, т.к. именно там описан shell-скрипт превращения любого дистрибутива операционной системы в Debian 11 Bullseye. Именно по этой причине ниже и выше по тексту я могу reoser называть то проектом, то скриптом. По своей сути - это скрипт, остальное обвязка.
Перед тем, как мы перейдем к разбору файлика entrypoint.sh, приведем ниже Dockerfile
FROM debian:stable-slim
COPY entrypoint.sh /root/entrypoint.sh
ENTRYPOINT ~/entrypoint.shи описание одного из сервисов в docker-compose.yml. Полный состав сервисов можно посмотреть на гитлабе, каждый из которых нацелен на свою виртуальную машину из показанных на картинке выше
version: "3.8"
services:
reoser-archlinux:
build:
context: docker
dockerfile: Dockerfile
image: reoser
environment:
# my virtual box ports forwarding
PORT: 10522
KILLER_PORT: 10622
# initial user credentials
INITIAL_USER_NAME: peaceful-coder
INITIAL_USER_PASSWORD: 1
# debian releases
KILLER_DEBIAN_RELEASE_NAME: bullseye
NEW_DEBIAN_RELEASE_NAME: bullseyeМожно видеть, что в скрипт передаются такие параметры как PORT и KILLER_PORT - это как раз те самые форвард-порты, которые проброшены на скрине выше и через которые будут идти преобразования исходной системы в новую. Параметры INITIAL_USER_NAME и INITIAL_USER_PASSWORD - это логин и пароль для подключения по ssh в исходную систему. А параметры KILLER_DEBIAN_RELEASE_NAME и NEW_DEBIAN_RELEASE_NAME - указывают на имена debian-дистрибутивов, которые будут развернуты для создания промежуточной системы убийцы в оперативной памяти и новой операционной системы, соответственно.
Самое сладкое
Пора перейти к самому главному, а именно, к скрипту entrypoint.sh, где и содержится суть проекта reoser. Не устану повторять, что отдаю должное статье, которая легла в основу этого скрипта. Благодаря этой статье и в процессе повторения действий ее автора, я узнал многое о линуксе на практике, чего не знал ранее, т.к. сразу оговорюсь, что я не заядлый линуксоид и приходилось экспериментировать на ходу.
Также сразу скажу, что скрипт длинный и в статью все писать не рационально. Полную версию всегда можно посмотреть на гитлаб, а тут будут рассмотрены принципиально важные блоки.
Итак. Первое что делает скрипт, это закидывает необходимые переменные окружения в исходную систему. Сделано это через создание файла environment.sh, а закидывание происходит через rsync. Именно поэтому выше я писал, что в исходной системе должны быть подняты сервисы ssh и rsync
#!/bin/bash -xe
# установка на стороне клиента rsync и утилиты для передачи пароля
apt update;
apt install -y sshpass rsync;
# создание файла с переменными окружения environment.sh
printf "#!/bin/bash -xe\n\n" > ~/environment.sh;
echo "INITIAL_USER_PASSWORD=${INITIAL_USER_PASSWORD};" >> ~/environment.sh;
echo "KILLER_DEBIAN_RELEASE_NAME=${KILLER_DEBIAN_RELEASE_NAME};" >> ~/environment.sh;
echo "NEW_DEBIAN_RELEASE_NAME=${NEW_DEBIAN_RELEASE_NAME};" >> ~/environment.sh;
# закидывание файла environment.sh в операционную систему на виртуальной машине
rsync --inplace --rsh="sshpass -p ${INITIAL_USER_PASSWORD} ssh -o StrictHostKeyChecking=no -p ${PORT}" ~/environment.sh ${INITIAL_USER_NAME}@host.docker.internal:~/environment.sh; Лучшего способа, как в рамках единого shell-скрипта закинуть переменные из докера в удаленную систему, которая запущена в virtualbox, я не нашел. Возможно, тут мне как раз поможете вы, как люди, которые гораздо лучше понимают линукс, чем я. Проблема передачи параметров связана с тем, что для прогона скрипта по удаленной виртуальной машине мне приходится использовать конструкции вида
sshpass -p ${INITIAL_USER_PASSWORD} ssh -o StrictHostKeyChecking=no ${INITIAL_USER_NAME}@host.docker.internal -p ${PORT} 'bash -xe' <<'ENDSSH'
# тут пишутся действия, которые нужно выполнить для создания временной операционной системы убийцы в оперативной памяти
ENDSSHИ таких конструкций будет 3: для подключения к исходной системе, для подключения к системе убийце, для подключения к новой операционной системе и проверки ее работоспособности.
Определим ОС, в которую мы попали
Рассмотрим первый такой блок. После подключения к исходной операционной системе, первое, что нужно сделать - это прогнать переданный скрипт с переменными среды и определить в какую операционную систему мы попали
# прогоняем скрипт для создания переменных окружения
chmod u+x ~/environment.sh;
. ~/environment.sh;
# определяем дистрибутив, в котором находимся
if test -f "/etc/os-release"; then
distribution=$(cat /etc/os-release | grep ^ID= | sed 's/^ID=//');
else
distribution=$(uname -a | tr '[:upper:]' '[:lower:]');
fiДалее в зависимости от операционной системы настраиваются alias-ы к пакетному менеджеру, т.к. по большей части основное отличие всех дистрибутивов линукса заключается именно в командах по запуску пакетного менеджера. Также отличие заключается в именах пакетов, которые нужно предварительно установить в исходную систему. Ниже покажем этот if-блок в урезанном виде на примере двух систем (полную версию всегда можно увидеть в гитлабе)
if [[ "$distribution" == *"fedora"* ]]; then
needUnmounting=true;
osKernelType=linux;
alias sudo="echo -n ${INITIAL_USER_PASSWORD} | sudo -S";
alias sudoSPackageManagerUpdate="sudo dnf upgrade --refresh";
alias sudoSPackageManagerInstall="sudo dnf install -y dpkg util-linux perl debootstrap";
elif [[ "$distribution" == *"freebsd"* ]]; then
needUnmounting=false;
osKernelType=freebsd;
alias sudo="echo -n ${INITIAL_USER_PASSWORD} | sudo -S";
alias sudoSPackageManagerUpdate="sudo pkg update";
alias sudoSPackageManagerInstall="sudo pkg install -y dpkg util-linux perl5 debootstrap";
else
echo "Couldn't define linux distribution";
exit 1;
fiКроме установки alias-ов также выставляется переменная флаг needUnmounting о необходимости отмонтирования дисков. Дело в том, что не все операционные системы позволяют заменить себя, пока диски примонтированы к исходной системе. Также запоминается тип операционной системы в переменной osKernelType, которая понадобится ниже.
Определим платформу, на которую мы попали
Далее создается функция detectArchitecture, которая призвана определить платформу, на которую мы попали. Пока там только amd64 и x86, но состав будет расширяться. В обязательном порядке там появятся ARM-ы.
function detectArchitecture {
architecture=$(uname -m);
correctedArchitecture=$(echo -n $architecture | awk -F'-' '{print $NF}');
# в таких системах как termux-андроид программа dpkg работает не так как везде. Результат нужно корректировать
if [ "$correctedArchitecture" = "x86_64" ] || [ "$correctedArchitecture" = "amd64" ]; then
correctedArchitecture=amd64;
elif [ "$correctedArchitecture" = "x86" ] || [ "$correctedArchitecture" = "i386" ] || [ "$correctedArchitecture" = "386" ] || [ "$correctedArchitecture" = "i686" ] || [ "$correctedArchitecture" = "686" ]; then
correctedArchitecture=i386;
else
echo "Couldn't detect architecture for $correctedArchitecture";
exit 1;
fi
echo $correctedArchitecture;
}Создание временной операционной системы "убийцы" в оперативной памяти
Теперь нам нужно создать переходную операционную систему в оперативной памяти. Поясню для чего это нужно делать. Чтобы заменить существующую систему на новую, нужно на диски полностью залить нашу новую операционку. Но пока диски держит текущая операционка, сделать мы этого не сможем. Поэтому для начала нам нужно уйти с дисков в оперативку через chroot, и находясь в оперативке произвести отрыв дисков. Когда отрыв дисков от исходной системы будет завершен то, все еще находясь в оперативке, можно будет подключиться к дискам и залить на них новую операционную систему, что и является целью нашего проекта reoser.
Для начала создаем папку /target, которая целиком будет в оперативной памяти
# Создаем каталог и файловую систему для «Системы убийцы», монтируем её
sudo mkdir -p /target;
sudo mount -t tmpfs -o size=1G none /target/;И сразу же помещаем в этот каталог в оперативной памяти переменные окружения, которые были переданы из докера и которые были подготовлены выше
sudo mkdir -p /target/root;
sudo cp ~/environment.sh /target/root/environment.sh;
# передача переменных в систему "убийцу"
printf "#!/bin/bash -xe\n\n" > ~/environment_from_origin.sh;
echo "osKernelType=${osKernelType};" >> ~/environment_from_origin.sh;
sudo cp ~/environment_from_origin.sh /target/root/environment_from_origin.sh;Здесь также как и при создании файла environment.sh формирование файла environment_from_origin.sh происходит на лету через printf-ы и echo-и.
Теперь просто апдейтим систему и устанавливаем то, чего в ней не хватает, через алиасы sudoSPackageManagerUpdate и sudoSPackageManagerInstall, созданные выше.
Понимая, что читатель изрядно подустал, я буду немного сокращать изложение, т.к. мы помним, что полный код скрипта можно найти в гитлабе, но по базовым вехам мы, конечно, пройдемся.
Если выше переменная needUnmounting была выставлена в true, то далее скрипт занимается отмонтированием всех дисков, которые были примонтированы.
Теперь нам нужно включить в работу функционал ядра исходной операционной системы по работе с файловой системой ext4 и по работе с LVM, т.к. новую операционную систему мы будем создавать именно в этой парадигме. Для этого нам и понадобится переменная osKernelType, которую мы определили ранее. Например, в случае, если мы находимся в линуксе и osKernelType=linux, то далее подключаются нужные модули, если они еще не включены
sudo modprobe ext4;
sudo modprobe dm_mod;Далее при помощи инструмента debootstrap в папке /target в оперативке разворачивается почти полноценный линукс. "Почти", потому что есть нюансы. И после его разворачивания берем и выполняем туда переход через chroot
sudo debootstrap --arch=$(detectArchitecture) ${KILLER_DEBIAN_RELEASE_NAME} /target/ http://ftp.debian.org/debian/;
sudo chroot /target bin/bash -xe;где $(detectArchitecture) - это вызов функции, определенной выше, а ${KILLER_DEBIAN_RELEASE_NAME} - это переменная, которая была определена при запуске docker-compose.
Запуск ssh-сервера в системе "убийце"
Теперь нам нужно подготовить систему "убийцу" к тому, чтобы войти в нее по ssh. Напомню, что выше я писал про проброс порта 11122. Вот его то мы и заиспользуем под эти нужды. И тут вы можете увидеть в моем скрипте много шаманства.
Например, для случая, когда мы находимся в андроиде, создается ряд групп с GID-ами, которые зарезервированы в андроиде и только состоя в этих группах наш пользователь сможет иметь доступ к оборудованию. Если позволите, то уточню, что только пользователи, состоящие в группе с GID=3003, могут выходить в интернет из андроида. Поэтому мне пришлось добавить таких пользователей как _apt и sshd именно в эту группу. Иначе ни скачать софт из интернета, не открыть порт для работы с системой убийцей по ssh не получится.
После создания групп и пользователей в таких системах, как андроид, нужно примонтировать в систему "убийцу" функционал ядра исходной системы. Для этого выполняется следующий ряд команд, которые могут несколько отличаться в зависимости от osKernelType. Ниже приведу для linux
mount none -t proc /proc/;
mount none -t sysfs /sys/;
mount none -t devtmpfs /dev/;
mount none -t devpts /dev/pts/;Без монтирования подобных виртуальных файловых систем не получится ни оторвать диски от исходной системы, ни прицепить их к новой системе.
Последнее что осталось сделать перед разлогином и входом в систему "убийцу" - это установить пару сервисов: sshd и atd. Sshd - нужно по очевидным причинам, а atd понадобится чуть позднее, когда потребуется сделать отложенный рестарт удаленной системы (к этому вопросу вернемся чуть позже, пока просто все настроим).
apt install -y openssh-server openssh-client at --no-install-recommends;
# запуск atd сервиса, через который работает команда at
/etc/init.d/atd restart;
# Создаем ssh-конфиги. Ставим альтернативный порт для ssh демона, чтобы мы могли зайти на chroot систему по ssh.
# И разрешаем доступ для root. Можно не давать доступ root, а создать пользователя и дать ему sudo права, но тут я сознательно упрощаю.
echo "Port 11122" > /etc/ssh/sshd_config;
echo "PermitRootLogin yes" >> /etc/ssh/sshd_config;
# запуск ssh сервиса
/etc/init.d/ssh restart;
# Дальше надо задать пароль для root (я поставил в качестве пароля 2), так как по умолчанию debootstrap не устанавливает никакие пароли
echo root:2 | chpasswd;Пора добить старую систему
Выходим на финишную прямую. Если все до этого отработало без ошибок, а особенное внимание следует уделить монтированию виртуальных файловых систем выше, то осталось совсем немного: оторвать диски и заполнить их новой системой. Поехали.
sshpass -p 2 ssh -o StrictHostKeyChecking=no root@host.docker.internal -p ${KILLER_PORT} 'bash -xe' <<'ENDSSH'
# все вырезки из скрипта далее находятся в этом блоке
ENDSSHСначала ставим весь необходимый софт
apt install -y lvm2 debootstrap parted arch-install-scripts;где
lvm2 устанавливается, т.к. мы будем использовать именно LVM в нашей новой системе
parted потребуется для создания новых дисковых разделов
arch-install-scripts нужен, чтобы позже воспользоваться такой крутой утилитой из arch-линукса как genfstab, для создания таблицы монтирования fstab
Далее нужно произвести очистку дисков, оторвать их от исходной системы и заново подхватить, но уже в системе "убийце"
# функция для получения списка дисков
function getDisks {
echo $(lsblk --output NAME,TYPE,MOUNTPOINT --noheadings | grep disk | grep -vi swap | sed 's/disk//g');
}
# Находим все диски
disks=$(getDisks);
# Затираем диски, чтобы они ни в коем случае не подцепились LVM-ом
for disk in $disks; do
dd if=/dev/zero of=/dev/${disk} bs=1M count=100;
done
# Отрываем диски
for disk in $disks; do
echo 1 > /sys/block/${disk}/device/delete;
done
# Подключаем диски обратно
for scsiHost in /sys/class/scsi_host/host?; do
echo "- - -" > ${scsiHost}/scan;
doneТеперь нужно создать новые разделы с учетом того, что далее на дисках будет разворачиваться LVM
# На загрузочном диске необходимо создать один первичный раздел размером на весь диск, и этот раздел отдать LVM-у, для того чтобы на него смог встать grub.
# Все остальные диски можно отдавать LVM-у целиком, не создавая систему разделов.
# Создаем таблицу разделов и один первичный раздел типа 8e (Linux LVM) на весь диск:
counter=0;
for disk in $disks; do
# Удаление разделов
echo "Removing partitions";
wipefs -a /dev/${disk};
partprobe /dev/${disk};
# Создание новых разделов
echo "Creating partitions";
if [ $counter = 0 ]; then
# нужен отдельный микрораздел под grub
parted -a optimal /dev/${disk} --script mklabel gpt unit MiB mkpart primary ext2 0% 2MiB mkpart primary ext4 2MiB 100%;
else
parted -a optimal /dev/${disk} --script mklabel gpt mkpart primary ext4 0 100%;
fi
partprobe /dev/${disk};
# Задание типов разделов
echo "Setting types for partitions";
if [ $counter = 0 ]; then
parted /dev/${disk} set 1 bios_grub on; # нужен отдельный микрораздел под grub
parted /dev/${disk} set 2 lvm on;
else
parted /dev/${disk} set 1 lvm on;
fi
partprobe /dev/${disk};
counter=$((counter +1));
doneРазмечаем диски под LVM
# Создание LVM в 1-ом разделе 1-ого диска
# Внимание надо обратить на порядок создания точек монтирования и собственно монтирования разделов.
counter=0;
for disk in $disks; do
if [ $counter = 0 ]; then
# создание физического вольюма
pvcreate --force /dev/${disk}2;
# создание вольюм-группы vg_root
vgcreate vg_root /dev/${disk}2;
# создание логического вольюма lv_swap0
lvcreate -Zn -L500M -n lv_swap0 vg_root;
# создание логического вольюма lv_root
lvcreate -Zn -L1G -n lv_root vg_root;
# создание логического вольюма lv_usr
lvcreate -Zn -L2G -n lv_usr vg_root;
# создание логического вольюма lv_var
lvcreate -Zn -L2G -n lv_var vg_root;
# создание логического вольюма lv_var_log
lvcreate -Zn -L1G -n lv_var_log vg_root;
# создание логического вольюма lv_home
lvcreate -Zn -L1G -n lv_home vg_root;
else
# создание физического вольюма
pvcreate --force /dev/${disk}1;
fi
counter=$((counter +1));
doneОстался последний шаг перед разворачиванием новой системы на подготовленных дисках. Давайте отформатируем созданные разделы и примонтируем их
# форматирование созданных логических вольюмов
mkswap /dev/vg_root/lv_swap0;
mkfs.ext4 /dev/mapper/vg_root-lv_root;
mkfs.ext4 /dev/mapper/vg_root-lv_usr;
mkfs.ext4 /dev/mapper/vg_root-lv_var;
mkfs.ext4 /dev/mapper/vg_root-lv_var_log;
mkfs.ext4 /dev/mapper/vg_root-lv_home;
# монтируем LVM
mkdir /target;
mount /dev/mapper/vg_root-lv_root /target/;
mkdir /target/usr;
mount /dev/mapper/vg_root-lv_usr /target/usr;
mkdir /target/var;
mount /dev/mapper/vg_root-lv_var /target/var;
mkdir /target/var/log;
mount /dev/mapper/vg_root-lv_var_log /target/var/log;
mkdir /target/home;
mount /dev/mapper/vg_root-lv_home /target/home;Создаем новую систему
Снова используем debootstrap, но теперь для разворачивания нового debian уже на диске, который мы только что примонтировали
debootstrap --arch=$(detectArchitecture) ${NEW_DEBIAN_RELEASE_NAME} /target/ https://ftp.debian.org/debian/ где функцию определения платформы $(detectArchitecture) мы обсудили ранее, а ${NEW_DEBIAN_RELEASE_NAME} - переменная, переданная при запуске docker-compose.
Создаем дисковые конфиги /etc/fstab для новой системы при помощи утилиты от arch linux из пакета arch-install-scripts, который портирован в debian и который мы поставили выше
genfstab -U /target >> /target/etc/fstab;Переходим в новую систему через chroot
chroot /target /bin/bash -xe;и первым делом подготавливаем сетевые конфиги для новой системы, вручную создавая сервис, настраивающий сетевые карты или wlan
# Создаем сетевые конфиги (без них не получится попасть в переустановленную систему)
# Причем на данном этапе нам не известны реальные имена сетевых устройств в новой системе
# в этой точке мы все еще видим имена сетевых устройств исходной системы
# поэтому просто готовим скрипт и сервис, который отработает при перезагрузке системы и настроит сеть
echo "#!/bin/bash" > /usr/bin/network-prepare.sh;
echo "" >> /usr/bin/network-prepare.sh;
echo "networkDevices=\$(ls -al /sys/class/net/ | grep ^l | sed 's/\(.*\)\/\(.*\)/\2/' | grep \"^\(eth\|enp\|wlan\)\");" >> /usr/bin/network-prepare.sh;
echo "networkDevicesCount=\$(echo \${networkDevices} | wc -w);" >> /usr/bin/network-prepare.sh;
echo "if [ \$networkDevicesCount != 1 ]; then" >> /usr/bin/network-prepare.sh;
echo " echo \"Network devices count is $networkDevicesCount but must be 1\";" >> /usr/bin/network-prepare.sh;
echo " exit 1;" >> /usr/bin/network-prepare.sh;
echo "fi" >> /usr/bin/network-prepare.sh;
echo "" >> /usr/bin/network-prepare.sh;
echo "echo \"auto \${networkDevices}\" > /etc/network/interfaces;" >> /usr/bin/network-prepare.sh;
echo "echo \"iface \${networkDevices} inet dhcp\" >> /etc/network/interfaces;" >> /usr/bin/network-prepare.sh;
echo "" >> /usr/bin/network-prepare.sh;
echo "/etc/init.d/networking restart;" >> /usr/bin/network-prepare.sh;
chmod +x /usr/bin/network-prepare.sh;
echo "[Unit]" > /etc/systemd/system/network-prepare.service;
echo "Description=/usr/bin/network-prepare.sh" >> /etc/systemd/system/network-prepare.service;
echo "" >> /etc/systemd/system/network-prepare.service;
echo "[Service]" >> /etc/systemd/system/network-prepare.service;
echo "ExecStart=/usr/bin/network-prepare.sh" >> /etc/systemd/system/network-prepare.service;
echo "" >> /etc/systemd/system/network-prepare.service;
echo "[Install]" >> /etc/systemd/system/network-prepare.service;
echo "WantedBy=multi-user.target" >> /etc/systemd/system/network-prepare.service;
# альтернатива вызову 'systemctl enable network-prepare.service', который в незапущенной системе невозможен
ln -s /etc/systemd/system/network-prepare.service /etc/systemd/system/multi-user.target.wants/network-prepare.service;Из-за многих echo-команд, код выше сложно читать. Вероятно, это стоит как-то переделать. Но пока так...
Теперь виртуальные файловые системы монтируем и в новую систему
mount none -t proc /proc/;
mount none -t sysfs /sys/;
mount none -t devtmpfs /dev/;
mount none -t devpts /dev/pts/;Устанавливаем ssh-сервер в новую систему
apt install -y openssh-server openssh-client --no-install-recommends;Настраиваем ssh-сервер и выставляем пароль для root
echo "Port 22" > /etc/ssh/sshd_config;
echo "PermitRootLogin yes" >> /etc/ssh/sshd_config;
# есть планы задавать параметром при запуске docker-compose, но пока ставлю 3 :)
echo root:3 | chpasswd;У нас осталось 2 глобальных шага, после которых можно рестартить систему, получив после рестарта свеженький Linux Debian 11 Bullseye с выходом в интернет и готовый к подключению в кубер-кластер нашего hardware-банкинга. Эти 2 шага такие:
установить в наше debootstrap окружение ядро линукса debian системы. Это очень важный шаг, т.к. простая debootstrap установка работает через ядро исходной системы, а мы ее снесли. Нам нужно новое ядро под нашу платформу
установить и настроить grub-загрузчик
# Устанавливаем пакеты, без которых не обойтись
apt install -y nano sudo linux-image-$(detectImageArchitecture) lvm2 psmisc vlan grub-pc-bin grub2-common dnsutils;
# Настраиваем grub
mainDisk=$(getDisks | head -n 1);
grub-install /dev/${mainDisk};
update-grub;Осталось выйти из chroot-окружения новой системы в систему убийцу
exit;и выполнить рестарт системы
# Активируем SysRq (он, скорее всего, активирован, но нам же надо убедиться).
echo 1 > /proc/sys/kernel/sysrq;
# И перезагружаемся, отстрелив фоновый процесс, чтобы потом успеть выйти из ssh-соединения
echo "sleep 10; echo b > /proc/sysrq-trigger;" | at now;
exit;По коду выше видно для чего мы устанавливали сервис atd. Он нужен, чтобы запустить рестарт системы в фоновом процессе через 10 секунд. Если этого не сделать, то скрипт не сможет дойти до команды exit и закрытия ssh-соединения с системой убийцей. То есть система рестартанется и там будет рабочий Debian, но наш скрипт зависнет. Таким образом, фоновость тут нужна исключительно для избегания подвисания скрипта.
Далее скрипт выполняет проверки, что все прошло удачно. Тут я эти проверки приводить не буду, т.к. статья итак изрядно затянулась. Все желающие могут увидеть эти проверки в коде проекта reoser.
Выводы
Проект reoser, описанный выше и расположенный тут, создан как первый шаг к созданию harware-банкинга. На этом первом шаге любой ваш ресурс: реальный или виртуальный - может быть отдан в банк и превращен в часть системы. Но пока это только превращение в операционную систему пригодную для разворачивания кубер-кластера, что будет выполнено на втором шаге. Поэтому пока в банкинг будет добавлено лишь моё железо и по мере развития площадки я начну предоставлять свои мощности в общее пользование всем, кто готов стать ее бета-тестерами. А людям, которые помогут писать код по нашим задачам тут, мощности будут предоставлены в безвозмездное пользование на все время существования проекта. Помощь понадобится после MVP, когда будет запущена в паблик версия 0.0.1 платформы PaaP.
Дальнейшие шаги
Когда у нас есть сеть из машин с однородными операционными системами, у нас все готово для разворачивания поверх всех этих машин облачной операционной системы, которой я дал рабочее название kubos. В основе этой системы лежит kubernetes, на поды которого будет ставиться все, что мы с вами захотим.
Захотим SonarQube - поставим свой сонар, захотим GitLab - поставим свой гитлаб. Так со временем мы соберем с вами настоящий облачный дистрибутив "операционной" облачной системы, которую сможем использовать для разработки, вычислений и заработка в рамках банкинга, который будет создаваться на базе этой "операционки".
P.S.
Основную информацию по проекту PaaP буду публиковать тут на хабре. Мелкую оперативную информацию скидываю в телеграм канал.
Как всегда, жду обратной связи и собираю людей, которые помогут создать будущее.
1dNDN
Что будете делать, если кто-нибудь на вашем сервере разместит что-нибудь не очень законное и к вам приедут маски-шоу?
Как фиксится проблема с произвольным частым выпаданием нод?