
Большинство известных зловредов уже занесены в базы антивирусов. Это, конечно, сильно мешает злоумышленникам атаковать с их помощью. Поэтому, чтобы скрыть вредоносный код, исполняемые файлы чаще всего сжимают. Сложно ли распаковать исходный файл, и какие есть подводные камни? Чем динамическая распаковка отличается от статической? Можно ли ее автоматизировать? Разбираемся в сегодняшней статье.
Мы продолжаем цикл полезных материалов от экспертного центра безопасности Positive Technologies (PT ESC) о том, какие вредоносные техники применяют злоумышленники и какие технологии есть «под капотом» нашей песочницы PT Sandbox для их детектирования. На повестке дня общие принципы работы упаковщиков и подходы к извлечению и восстановлению исходного файла. Покажем демо и разберемся во всех нюансах динамической и статической распаковки на примере ASPack, одного из широко используемых хакерами упаковщиков.
Спойлер: в финале расскажем, как можно сломать стандартный распаковщик UPX.
Предисловие
О распаковке исполняемых файлов, подходах к их восстановлению и о том, как с ними работать, сейчас мало информации в сети. Более того, очень сложно найти обстоятельный и всеобъемлющий материал, где были бы выделены основные принципы распаковки и описывался инструментарий. Чтобы это исправить, мы решили написать единый мануал, в котором поделились своими знаниями и наработками.
Мы глубоко погрузились в тему упаковщиков еще и потому, что продолжаем улучшать компоненты PT Sandbox — в частности модуль, отвечающий за предобработку входящих файлов. Когда песочница работает в потоке, огромную роль играет то, насколько быстро она способна выявлять и блокировать угрозы. К тому же до того, как файлы уйдут в поведенческий анализ, хотелось бы извлечь фрагменты и для статического анализа. Все-таки не всегда по поведению удается определить, что программа вредоносная. В некоторых случаях как раз распаковка и анализ исполняемых файлов позволяют быстрее принять решение о блокировке зловреда.
Все самое важное об упаковщиках
Для начала разберемся, что такое исполняемые файлы и как они устроены. В Windows для исполняемых файлов, объектного кода и динамических библиотек используется формат Portable Executable (сокр. PE). PE-файл состоит из заголовков и секций — ниже показано, как он выглядит в шестнадцатеричном редакторе.

В первых двух байтах находится сигнатура MZE — это начало DOS-заголовка. Следом идет DOS-заглушка (ее можно определить по строке This program cannot be run in DOS mode), а затем PE-заголовок (определяется по сигнатуре PE). Следующий элемент — заголовок Optional header, который, несмотря на свое название, обязателен для формата Portable Executable. Его структура представлена ниже.
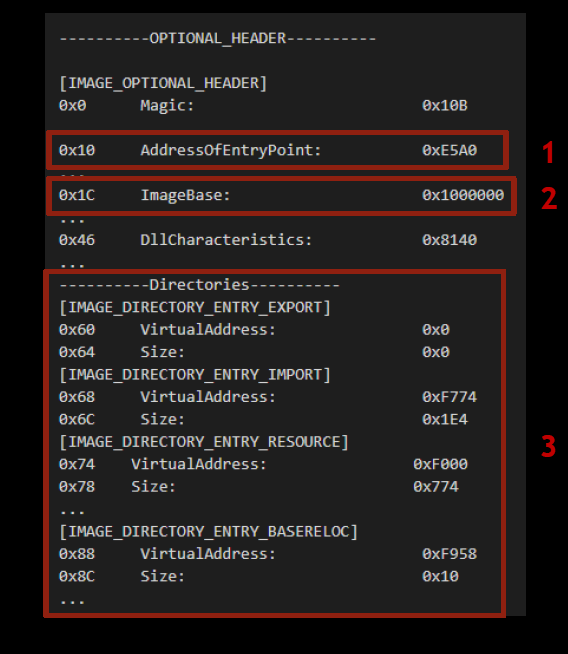
AddressOfEntryPoint — место, с которого начинается выполнение программы. Иначе говоря, точка входа в программу.
ImageBase — адрес памяти, по которому будет загружен файл после запуска.
Помимо этого, Optional header содержит адреса и размеры различных таблиц, необходимых для работы программы — например таблицы экспорта, импорта или ресурсов.
За Optional header следуют заголовки секций, в которых находятся положение и размер секций памяти. На рисунке ниже цифрой 3 выделены флаги, характеризирующие секции. Все флаги хранятся в четырех байтах. Это битовое поле, где каждый байт обозначает одну из характеристик секции — право доступа, содержимое секции или что-то другое.
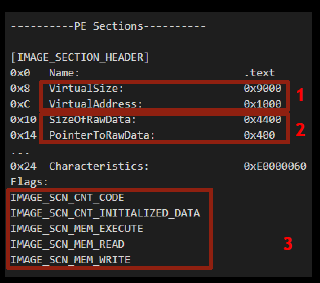
Таблица импорта — один из важных элементов исполняемого файла. Она необходима для приложений, использующих динамические библиотеки. Адрес и размер таблицы импорта можно посмотреть в Optional header.
Она состоит из массива дескрипторов импорта. Каждый дескриптор импорта содержит:
Адрес таблицы имен импорта. Данная таблица — это тоже массив, каждый элемент которого указывает либо на адрес текстового названия импортируемой функции, либо на порядковый номер функции в импортируемой библиотеке (ordinal).
Адрес строки с названием библиотеки.
Адрес таблицы адресов импорта: эта таблица содержит абсолютные адреса импортируемых функций. Именно на таблицу адресов импорта отправляется код к приложению при межмодульном вызове.
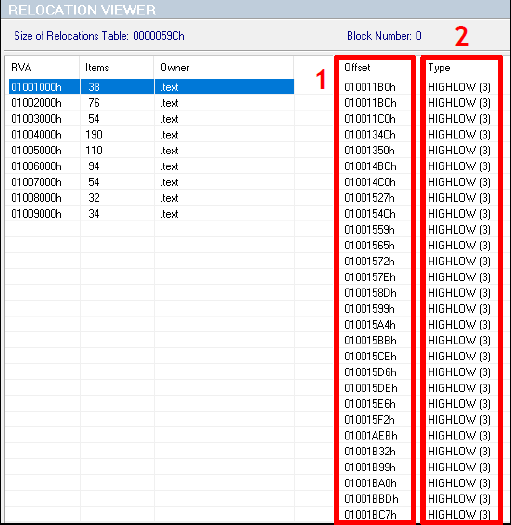
Перейдем к таблице релокаций. В PE-файлах содержатся абсолютные адреса, которые на этапе компиляции выставляются так, как если бы образ был загружен по указанному в Optional header базовому адресу. Если исполняемый файл загружается по другому базовому адресу, необходимо выполнить перебазирование. Как раз для таких случаев и требуется таблица релокаций. Она состоит из блоков, содержащих позицию абсолютных адресов в файле, а также тип релокации. От последнего зависит, каким образом будет обрабатываться каждый абсолютный адрес.
Упаковщики исполняемых файлов: теория
Принцип работы любого упаковщика заключается в сжатии секций и последующем прикреплении к ним кода, отвечающего за распаковку исполняемого файла и передачу на него управления. Соответственно, упаковщики — это программы, которые эти операции выполняют.
Зачем применяют упаковщики:
для защиты кода приложения от реверс-инжиниринга;
для уменьшения размера исполняемого файла;
для сокрытия вредоносного кода — используется злоумышленниками.
Загрузчиком называют тот самый код, который упаковщик прикрепляет к исполняемому файлу. Его главная задача — распаковать содержимое файлов и передать на него выполнение.
Действия загрузчиков делятся на несколько этапов.
Этап первый. Распаковка образа в памяти
Для сжатия исполняемых файлов упаковщики используют сжатие без потерь. Чаще всего встречаются следующие алгоритмы сжатия:
LZMA;
APLib;
Deflate;
NRV;
алгоритм Хаффмана.
Помимо перечисленного, могут использоваться и авторские алгоритмы, которые, по сути, являются модификациями других алгоритмов.
Первоочередная задача загрузчика — распаковка сжатых данных. Давайте рассмотрим часть алгоритма декомпрессии APLib. Красной рамкой выделены его наиболее характерные фрагменты, а именно разбор закодированной последовательности, определение позиций и количество повторений. Кроме того, можно увидеть числа шестнадцатеричной системы — характерные константы для рассматриваемого алгоритма.

Для улучшения степени сжатия применяется фильтрация данных — за счет этого увеличивается коэффициент сжатия. Обычно в исполняемых файлах фильтруют инструкции, которые оперируют относительными адресами. В основном это относительные call и jmp (опкоды 0xE8 и 0xE9, соответственно).
Рассмотрим рисунок «До фильтрации». Относительный call состоит из двух компонентов: опкода 0xE8 и следующих за ним четырех байтов, которые обозначают относительный адрес вызываемой функции. Можно заметить, что два call, вызывающих одну и ту же функцию, но расположенных на разных позициях в коде, имеют разный код. Другими словами, у них отличается относительный адрес.

Идея фильтрации в том, чтобы относительные call, вызывающие одну и ту же функцию, имели одинаковый код (рис. «После фильтрации»). Эта операция позволяет увеличить число повторений в сжимаемых данных, что в свою очередь приводит к возрастанию коэффициента сжатия.
Бывает ли такое, что в коде случайно есть и 0xE8, и 0xE9, однако это на самом деле не инструкция? Как упаковщики проверяют, что действительно нашли опкод, а не случайный байт, который на него похож?
Все зависит от используемого фильтра и самого упаковщика. Если используются простейшие фильтры, то им все равно, действительно ли это инструкция call (либо jmp) или просто случайный опкод 0xE8. Они фильтруют все подряд без разбора. Также есть и более сложные фильтры, которые стараются определить, что является инструкцией, а что нет.
Этап второй. Дефильтрация данных
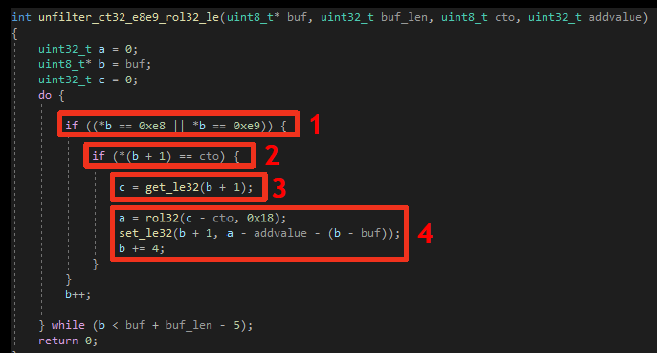
Загрузчик выполняет обратное упаковщикам действие — дефильтрацию данных. Ниже показан код дефильтрации на C. Мы также предлагаем изучить этот же код на ассемблере.
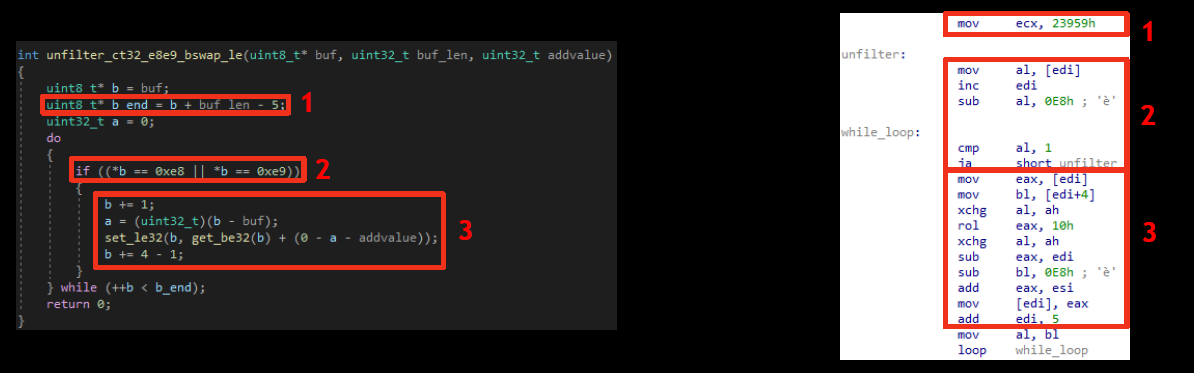
Дефильтрация состоит из следующих шагов:
Получение размера фильтруемых данных.
Считывание байта данных, который сверяется с опкодами дефильтруемых инструкций (0xE8 и 0xE9).
Выполнение различных действий. Отдельно стоит обратить внимание на переменную а, которая содержит адрес текущей инструкции. Эта переменная будет вычитаться из значения, следующего за опкодом, благодаря чему восстановится правильный относительный адрес.
Этап третий. Получение импортов
После распаковки и дефильтрации данных начинается восстановление импортов: загрузчик разбирает таблицу импорта, находит названия необходимых библиотек и загружает их при помощи функции LoadLibrary. Если библиотека уже загружена, загрузчик получает ее адрес с помощью функции GetModuleHandle. Далее он продолжает разбирать таблицу импорта. В этот раз он ищет названия импортируемых функций, получает их адреса и с помощью функции GetProcAddress записывает их на правильные позиции в таблице адресов импорта. Напомним, что на эту таблицу ссылается весь код при межмодульных вызовах.
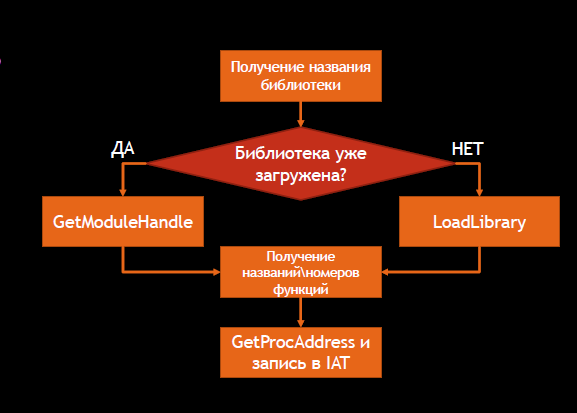
Этап четвертый. Перебазирование образа
Когда образ загружен не по базовому адресу, указанному в Optional header, загрузчику необходимо сделать перебазирование, то есть разобрать таблицу релокаций и исправить абсолютные адреса.
Как уже говорилось ранее, таблица релокаций состоит из блоков. В начале каждого есть структура с информацией о нем (RelocationBlockInfo), где указан размер этого блока и адрес страниц, для которых производится релокация. За этой структурой идет еще массив (RelocationEntry), содержащий сведения о типе и смещении в файле каждой релокации. Предлагаем рассмотреть ассемблерный код разбора релокаций.
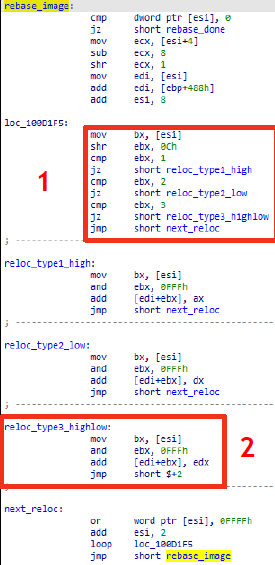
Определение типа релокации: в регистр bx помещаются два байта, после чего отсекаются 12 битов, и полученное значение сравнивают с цифрой (1, 2 или 3), указывающей на тип релокации. От типа релокации зависит способ ее обработки.
Обработка релокации третьего типа.
Немного углубимся в типологию релокаций и скажем несколько слов о том, какой способ обработки подразумевается для каждого типа. Всего для x86-архитектуры обрабатываются четыре типа релокаций: 0, 1, 2 и 3. Все они оперируют значением разницы между предпочтительным адресом загрузки (OPTIONAL_HEADER.ImageBase) и фактическим адресом. В дальнейшем будем для краткости условно называть это значение разницей между адресами.
0 — IMAGE_REL_BASED_ABSOLUTE — релокация пропускается.
1 — IMAGE_REL_BASED_HIGH — к 16 битам релоцируемого адреса прибавляется 16 старших битов разницы между адресами.
2 — IMAGE_REL_BASED_LOW — к 16 битам релоцируемого адреса прибавляется 16 младших битов разницы между адресами.
3 — IMAGE_REL_BASED_HIGHLOW — к 32 битам релоцируемого адреса прибавляется вся разница между адресами.
Важно!
Если программа была загружена не по базовому адресу, указанному в Optional header, без перебазирования она работать не будет.
Этап пятый. Передача выполнения на код исходной программы
Вычисление точки входа в начальную программу (original entry point) и передача на нее управления — последний этап работы загрузчика. Привели примеры, как выглядит этот переход у различных упаковщиков. В основном это различные jmp и возвраты.

Пробуем распаковать вручную
Мы уже изучили, как работает загрузчик, поэтому давайте попробуем распаковать исполняемый файл. Для начала — вручную.
На деле, в этом видео мы вручную провели динамическую распаковку. Еще раз пройдемся по основным моментам: мы запустили программу, позволили ей выполниться до точки входа в оригинальную программу, определили импорты OEP, создали дамп памяти и обработали его. На выходе мы получили рабочую распакованную программу.
Автоматизация динамической распаковки
Попробуем автоматизировать процесс распаковки файлов, которые ранее были упакованы ASPack. Для этого воспользуемся одним из эмуляторов — Speakeasy. Этот фреймворк основан на Unicorn и предназначен для эмуляции пользовательского режима и режима ядра Windows. Его главная задача — провести динамический анализ вредоносного ПО. Доступ к регистрам и памяти, перехваты доступа к памяти, выполнения инструкций, вызовов WinAPI — вот лишь некоторые из возможностей Speakeasy. Помимо того, что с ним удобно работать, Speakeasy предоставляет много готовых обработчиков WinAPI, что избавляет нас от необходимости писать собственные варианты функций VirtualAlloc и LoadLibrary. Хотя можно воспользоваться любым другим эмулятором.
Шаг первый. Получение ОЕР
Окончание процесса распаковки сопровождается переходом в точку входа в изначальную программу (original entry point). Для получения OEP в эмулятор следует добавить перехват на выполнение инструкций (hook_sectionhop), который будет срабатывать после каждой выполненной инструкции.

Внутри эмулятора текущий адрес выполнения будет также проверяться на принадлежность к секции загрузчика. За пределы секции адрес выходит тогда, когда он либо меньше виртуального адреса загрузчика, либо больше суммы виртуального адреса загрузчика и его размера в памяти. Если адрес все-таки вышел за границы секции, то это говорит о том, что мы находимся в точке входа в изначальную программу. Далее следует записать этот адрес и завершить эмуляцию.
Важно!
Предварительная проверка с байтом 0xC3 необходима, чтобы не сбивалась работа эмулятора. Байт 0xC3 — это опкод инструкции Ret (инструкции возврата). Встречаются образцы ASPack, которые в коде загрузчика выполняют вызов на инструкцию Ret в другой секции. Иначе говоря, при выполнении вызова на другую секцию моментально происходит переход обратно, из-за чего сбивается эмулятор.
Шаг второй. Создание дампа памяти
Создать дамп памяти мы могли бы и на предыдущем этапе, если бы не одна сложность: упаковщик ASPack затирает таблицу импорта. Чтобы заново не восстанавливать таблицу импорта, давайте определим момент, когда данные уже будут распакованы, а таблица импорта еще будет цела. Для этого будем ориентироваться на вызов функции GetModuleHandle.
Впервые эта функция вызывается в самом начале работы загрузчика для получения различных служебных функций. Они нужны для распаковки данных. Затем происходит распаковка, дефильтрация и восстановление импортов. В момент восстановления импортов GetModuleHandle вызывается во второй раз. Тогда мы и можем получить дамп памяти с незатертой таблицей импорта. Не забываем определить ее адрес — он содержится в регистре ESI. Загрузчик продолжит вызывать GetModuleHandle, пока не получит адреса всех импортируемых библиотек. Размер таблицы импорта вычисляется как количество вызовов GetModuleHandle, умноженное на размер дескриптора импорта (20 байт, или 14 в шестнадцатеричной системе).
Шаг третий. Перехват GetModuleHandle

При первом вызове функции GetModuleHandle мы устанавливаем значение true (флаг). Это своего рода индикатор, показывающий, что перехват ранее уже выполнялся.
При втором вызове функции считываем адрес таблицы импорта из регистра ESI и создаем дамп памяти модуля. За создание дампа памяти отвечает функция DumpOnHit. Ее задача — считать содержимое памяти, которое занимает программа, и сохранить его в переменную для последующей обработки.
Во втором и последующих вызовах происходит вычисление размеров таблицы импортов путем добавления к переменной (считывающей размер) размера дескриптора импорта.
Шаг четвертый. Исправление дампа памяти
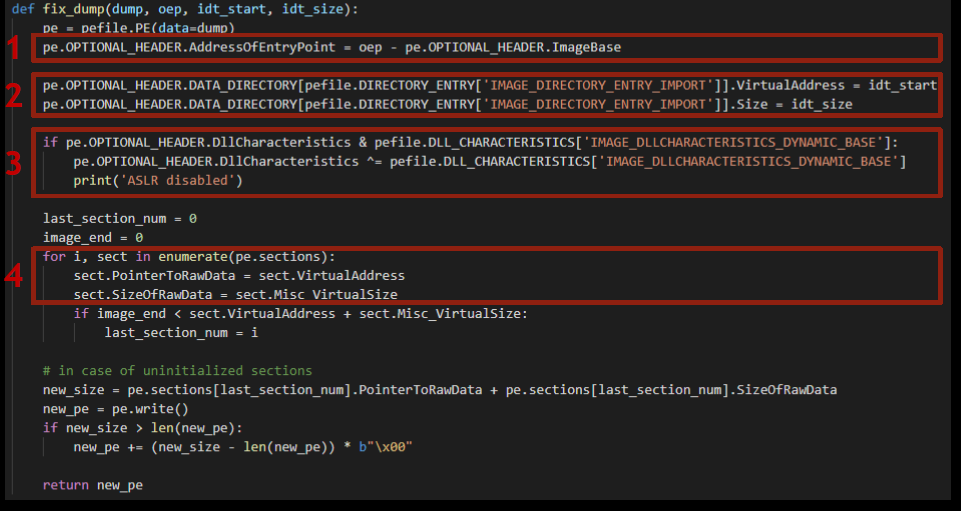
Выполняем следующие действия:
Выставляем в Optional header правильную точку входа.
Указываем адрес и размер таблицы импорта, который мы вычислили на предыдущем шаге.
Отключаем перемещение образа в памяти. Этот код имеет много общего со скриптом на Python, который мы показывали чуть раньше.
Устанавливаем границы секций в файле. Мы создали дамп памяти, поэтому физический размер и положение в файле секций должны быть равны их размеру и положению в памяти ОС в окружении эмулятора. Для этого уравняем эти значения.
Наш эмулятор готов. Давайте его проверим.
Безопасна ли эмуляция, и можно ли ее проводить на рабочем компьютере?
В эмуляторе можно запускать любые программы, даже вредоносные. Это безопасно, так как за пределы эмулятора они выйти не могут. Например, если вы запустите шифровальщик, он будет шифровать только эмулированные файлы (которых на самом деле нет). Доступ к вашим реальным данным он никогда не получит.
Погружаемся в тонкости статической распаковки
Динамический распаковщик написать легко, но у него все же есть один существенный недостаток. На распаковку файлов большого размера может уйти много времени, вплоть до нескольких минут. У статической распаковки гораздо большая производительность, поскольку такие распаковщики восстанавливают исходные файлы, не запуская (эмулируя) их. Предлагаем рассмотреть этот тип распаковки также на примере распаковщика ASPack.
Для статической распаковки необходимо выполнить последовательность действий, указанных на рисунке ниже.
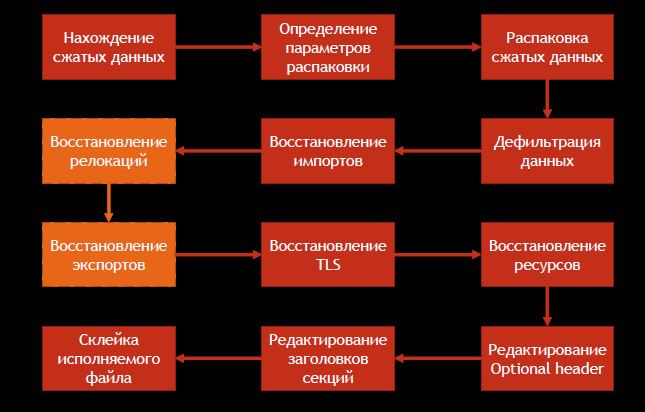
Отметим, что процесс восстановления импортов будет отличаться в зависимости от типа упаковщика. В случае ASPack таблица импорта не меняется и достаточным будет вычислить ее адрес и размер.
То же самое и с процессом восстановления релокаций: часть упаковщиков, если в исходном файле есть таблицы релокации, записывают одно и то же значение во все адреса в расчете на то, что загрузчик в ходе работы эти адреса восстановит. Таким образом увеличивается коэффициент сжатия.
Восстановление экспортов — опциональный шаг, который предпринимают, если упакованный файл является динамической библиотекой.
Нельзя забывать о локальном хранилище потоков (thread-local storage — TLS). TLS — это метод, при котором у каждого потока есть область памяти, в которой хранятся определенные данные. Если приложение использует статическое TLS, изменяется структура исполняемого файла — добавляется секция для данных потока и таблица TLS. Некоторые упаковщики не поддерживают TLS, поэтому универсального метода восстановления TLS нет. В большинстве случаев достаточно перенести таблицу TLS в любую другую секцию исполняемого файла из кода загрузчика.
Схема работы упаковщика ASPack выглядит следующим образом.
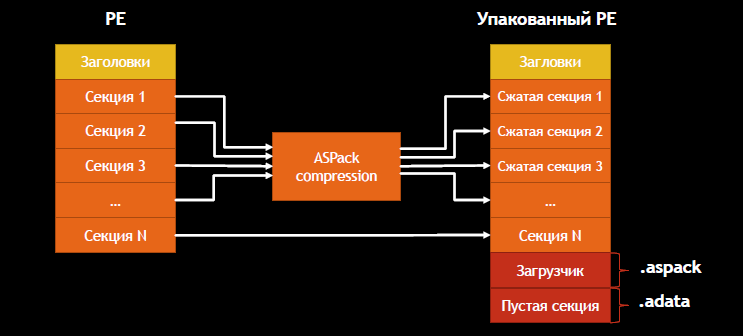
ASPack работает только с 32-битными исполняемыми файлами. В отличие от других упаковщиков, он не изменяет структуру исходных секций, а лишь прибавляет к ним две новые. Секция загрузчика, если не была переименована, называется .aspack. Секция с неинициализированными файлами носит имя .adata. В идеале при статической распаковке хочется убрать эти две секции из получаемого на выходе файла, что, впрочем, может очень сильно затруднить процесс распаковки.
Пишем статический распаковщик
Приступим к написанию статического распаковщика. Начнем с нахождения сжатых секций. Помимо кода, отвечающего за распаковку файла, в ASPack записана информация о блоке сжатых данных. Эта информация включает в себя относительный виртуальный адрес блока, размер блока и права секций (есть только в новых версиях).

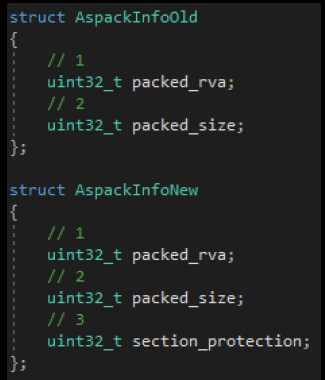
ASPack не прикрепляет вспомогательные данные к упакованному файлу, поэтому всю необходимую информацию о распаковке приходится получать из кода загрузчика. В начале работы загрузчик помещает в регистр EBP адрес. Впоследствии адресация кода загрузчика происходит относительно содержимого этого регистра. Мы можем получить такую информацию, как положение сжатых блоков, адрес таблицы импорта, адрес таблицы релокаций и адрес точки входа, найдя инструкции, которые к ним обращаются.
Когда мы разобрались с расположением сжатых данных, пришло время их распаковать. В упаковщике ASPack авторский алгоритм сжатия данных по словарю. Рассмотрим фрагменты алгоритма декомпрессии.



Больше всего этот алгоритм похож на алгоритм сжатия семейства LZ. Можно заметить такие характерные моменты, как использование ссылок на повторение и разбор длины повторения. Фактически это модифицированный LZ-алгоритм.
Далее проводим дефильтрацию. Применяемая в ASPack фильтрация не сильно отличается от той, которую мы уже описывали в этой статье: все также фильтруется call и jmp. Здесь фильтр действительно пытается определить, настоящий ли это call либо jmp или это просто случайный байт 0xE8 и 0xE9. Отфильтрованные инструкции обозначаются маркером. Он выглядит как байт, который следует за опкодом инструкции.

Давайте рассмотрим подробнее алгоритм дефильтрации на языке C и ассемблера.

Поиск необходимого опкода.
Проверка, была ли инструкция промаркирована. Для этого байт, следующий за опкодом, сравнивается с маркером.
Извлечение того, что находится в инструкции вместо адреса.
Циклический сдвиг на 18 байтов (в шестнадцатеричной системе) извлеченного значения. Затем из этого значения вычитается адрес текущей инструкции, и результат помещается обратно.
Дефильтрация завершена. Процесс немного усложнился, но его суть не изменилась.
После распаковки и дефильтрации данных наступает черед поиска вспомогательной информации. В первую очередь восстанавливаются ресурсы — данные, помещенные в специально отведенную для них область исполняемого файла (обычно .rsrc). К ресурсам относятся картинки, аудиофайлы и текст. У ASPack есть опция, позволяющая сжимать ресурсы. Независимо от того, включена эта функция или нет, ASPack не сжимает:
иконки (RT_ICON);
манифесты (RT_MANIFEST) — иногда они нужны для корректного запуска программ.
Если ресурсы были сжаты, их необходимо собрать заново при статической распаковке, то есть объединить только что распакованные ресурсы с несжатыми, которые находятся в секции загрузчика.
Последний этап включает в себя склейку секций, удаление одной ненужной секции загрузчика и исправление заголовков. Сперва для записи в файл распакованные секции необходимо выровнять по значению, указанному в поле FileAlignment (оно расположено в Optional header), дополнив секции нулями до необходимого размера.
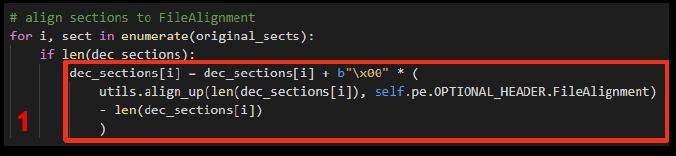
Очевидно, что распакованные файлы занимают больше места, чем сжатые, поэтому стоит также поправить заголовки секций. А для новых версий ASPack еще и установить у секций исходные права.
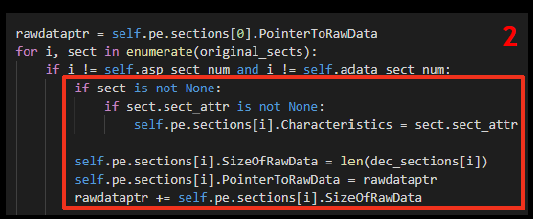
В конце указываем в Optional header правильные точку входа, адреса и размеры таблиц, рассчитываем новый размер образа в памяти. После чего соединяем исправленные заголовки с исправленными секциями и сохраняем их в файл.
И вот у нас готов статический распаковщик.

Он позволяет быстро и надежно выполнять распаковку исполняемых файлов и при этом не настолько сильно зависит от размера сжатых данных, как динамический распаковщик.
На этом мы пока заканчиваем наш рассказ об упаковщиках. Ждем ваших вопросов в комментариях.
Кто-то наверняка вспомнит, что всем дочитавшим статью до конца мы обещали бонус. Переходим к нему.
Бонус: как сломать стандартный распаковщик UPX
Сначала, пожалуй, уместным будет сказать пару слов о UPX. UPX — это упаковщик с открытым исходным кодом и встроенным распаковщиком. Открытый исходный код позволяет любому пользователю менять упаковщик по своему усмотрению, чем и пользуются злоумышленники. Так, фреймворк для эксплуатации Shad0w и утилита удаленного администрирования Gobalt RAT — не что иное, как примеры подобного переиспользования.
Во время сжатия исполняемого файла UPX называет секции в упакованном файле UPX0, UPX1 и далее по аналогии. В дальнейшем стандартный распаковщик будет ориентироваться на эти названия.

Чтобы сбить работу распаковщика UPX, достаточно изменить названия секций. Решить эту проблему очень просто: необходимо переписать распаковщик таким образом, чтобы он перестал ориентироваться на наименования секций, либо вручную указывать правильные названия.

Обычно упаковщик UPX прикрепляет к выходному файлу вспомогательную информацию — так называемый UPX-заголовок. Он начинается с upx_magic. Это четыре байта, в которых записана строка «UPX!». В заголовке также указаны контрольные суммы для упакованных и распакованных данных, а также информация о том, какой метод сжатия и фильтр используются.

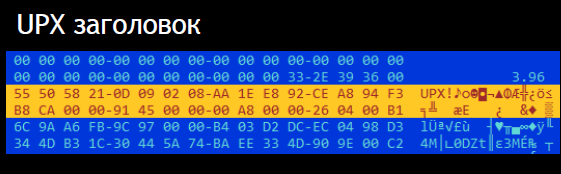
На старте стандартный UPX-распаковщик попытается найти заголовок по upx_magic. Полное либо частичное затирание UPX-заголовка — еще одна уловка злоумышленников. Она сложнее, чем смена названий секций.

Если upx_magic был затерт частично, то это не сильно критично. Для корректной распаковки необходимо знать всего лишь пять полей: метод, алгоритм сжатия, длину упакованных данных и их размер в распакованном виде, а также примененные фильтр и маркер для отметки отфильтрованных инструкций. В этом случае UPX-заголовок можно найти при помощи регулярного выражения.
Когда заголовок был затерт полностью, можно воспользоваться одним из следующих подходов:
посмотреть необходимую информацию в коде загрузчика;
провести динамическую распаковку исполняемого файла.
Изменение названий секций, как и затирание заголовка, не влияет на работоспособность программы, так как загрузчик не использует ни первое, ни второе. Они необходимы только для стандартного упаковщика.
Если вам интересно, какие вредоносные техники, инструменты и уловки используют киберпреступники для целевых и массовых атак, следите за нашими вебинарами и подписывайтесь на наш блог, чтобы не пропустить новые полезные статьи от экспертного центра безопасности Positive Technologies.
Читайте также:
Как не дать злоумышленникам повысить привилегии в системе после успешного заражения
Плагины для системы анализа DRAKVUF. Как с помощью exploitmon выявить попытки эксплуатации ядра ОС
Плагины для системы анализа DRAKVUF. Как обнаруживать вредоносные техники с помощью rpcmon
Авторы:
Алексей Вишняков, руководитель отдела обнаружения вредоносного ПО PT Expert Security Center
Александр Лаухин, специалист отдела обнаружения вредоносного ПО PT Expert Security Center