
Cloud Station — Photoshop Art by PhaseRunner
Принципы построения облачных и On-premise-сетей различаются: в облаке много новых сетевых сущностей и подходов к построению инфраструктуры. Но новое не значит сложное.
Меня зовут Болат Кажкенов, я архитектор VK Cloud Solutions. В этой статье я расскажу, чем различаются облачные и On-premise-сети, какие преимущества и недостатки есть у каждого из решений.
Если раньше вы не работали с облачными сетями и представляете их устройство только в общих чертах, то, надеюсь, моя статья поможет вам восполнить пробелы в знаниях и проконсультировать коллег, если вдруг в вашей компании встанет вопрос о миграции в облако. Все примеры я буду показывать на нашей облачной платформе — VK Cloud Solutions.
Как устроены сети в облаке и чем они отличаются от On-premise-реализации
Чтобы построить автоматизированную облачную платформу, которая будет предоставлять инфраструктуру как сервис (IaaS), нужен минимальный набор OpenStack-компонентов:
- вычислительные узлы (Compute),
- диски (Block Storage),
- образы дисков (Image) и хранилища для них (в данном случае Object Storage),
- компоненты для координации автоматизированного взаимодействия элементов платформы (Orchestration),
- управление учетными записями (Identity),
- веб-интерфейс (Dashboard),
- инструменты мониторинга (Telemetry),
- сеть (Networking).
При этом IaaS — это еще не полный набор облачных услуг, а, скорее, база для их дальнейшего развития и создания платформы. Тем не менее, чтобы обеспечить взаимодействие различных компонентов друг с другом, обязательно нужна сеть. Я не упоминаю, что, кроме сети, еще нужны API и другие средства коммуникации, но в рамках этой статьи мы остановимся именно на сетях.
Для начала знакомства с облачными сетями вспомним сетевую модель OSI.

Модель OSI (тут хороший обзор по сетям и OSI)
С точки зрения инфраструктуры нам интересны два уровня:
-
L2, в котором для коммуникации используются фреймы, а для определения отправителя/получателя — MAC-адреса. В этом случае сетевые устройства должны «жить» в пределах одной физической или логической сети (домена).
-
L3 — привычная IP-сеть, в которой общение уже происходит пакетами, а для адресации используются IP-адреса. Вдобавок есть много дополнительных механизмов вроде маршрутизации, которые позволяют на основе IP-сетей строить большие распределенные системы.
Традиционно для построения нескольких изолированных L2-сетей в рамках одной физической используется технология VLAN. Чтобы обеспечить изолирование сетей между собой, к пакетам во VLAN-сетях добавляются специальные заголовки, в том числе 12 бит, выделенных на адресацию, что позволяет создать до 4093–4094 (по разным показаниям) виртуальных сетей.
Для современных облачных провайдеров, естественно, этого мало. Чтобы обойти эти ограничения, есть несколько решений, среди которых самым распространенным является технология VXLAN — Virtual Extensible LAN, которую придумали ребята из VMware и Cisco как раз для использования в облачных средах. Основное отличие от VLAN-сетей состоит в том, что VXLAN-сети используют для транспорта L3-уровень и на адресацию выделено уже 24 бита, что позволяет создать до 16 миллионов сетей. Сейчас эта технология уже стала стандартом де-факто в мире облачных технологий.
Один из примеров — возможности по обработке трафика: такие сети можно растянуть между дата-центрами, используя обычную IP-маршрутизацию и сети общего пользования, а машины в таких сетях будут думать, что они живут в одном L2-домене, хотя фактически могут быть размещены в разных географических локациях и физически в разных сетях.
Вот как приблизительно устроены сети облачных провайдеров:
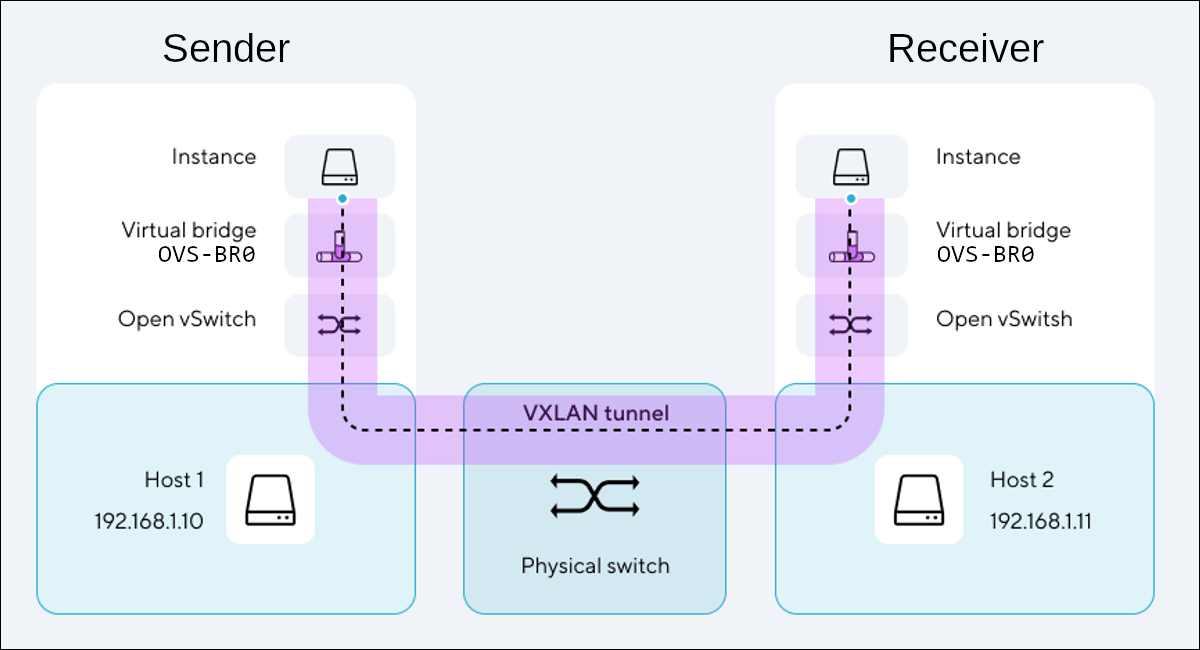
При отправке пакеты сначала проходят через внутренний сетевой стек отправителя, который утилизирует виртуальный сетевой порт ВМ (синяя точка). Затем пакет обрабатывается на локальном сетевом мосте (OVS-BR) гипервизора, с которым коммуницируют все ВМ, запущенные на этом сервере виртуализации. На уровне этого моста происходит фильтрация и дальнейшая маршрутизация трафика. Далее трафик попадает на распределенный виртуальный коммутатор (Open vSwitch), компоненты которого установлены в виде сервисов на каждом сервере виртуализации. Когда пакет долетает до целевой ВМ (в частности, до ее конкретного сетевого адаптера), то он проходит путь, который описан выше, но уже в обратном направлении. Так, целевая ВМ получает пакет, уже очищенный от служебных данных, которые были нужны для его маршрутизации.
В данном случае в качестве Underlay-сетей выступают сети, к которым подключены хосты виртуализации, на рисунке они выделены голубым цветом. Здесь может применяться как физическое оборудование, так и программные средства, обеспечивающие соответствующую функциональность. В нашем случае, кроме наличия самого оборудования и программных средств, обязательно нужен еще и драйвер для OpenStack Neutron — компонент платформы OpenStack, управляющий сетью.
Сиреневым цветом выделены VXLAN-сети (Overlay), которые и позволяют виртуальным машинам общаться между собой. Эти сети доступны пользователям, именно их вы и создаете в рамках ваших проектов.
И немного про изолирование и границы сетей и проектов у нас в облаке. Тегирование трафика, будь то технология VLAN, VXLAN или проприетарный протокол, как упоминалось выше, позволяет обеспечить изолирование сетевого трафика для различных сетей, так же как и ресурсы виртуальных машин изолируются друг от друга за счет механизмов, встроенных в гипервизор (ОС для запуска виртуальных машин). Кроме этого, стоит помнить, что ресурсы в рамках одного проекта также изолируются друг от друга, хотя подробно останавливаться на этом не будем. Просто нужно держать в голове, что тут могут использоваться как механизмы Linux namespaces, так и различные роли и политики IAM — компонента управления учетными записями и доступами.
По сути, проект в нашем облаке — это изолированный теннант. Это означает, что сетевые трафики разных проектов не могут пересечься и у одной и той же учетной записи в рамках разных проектов могут быть совершенно разные роли, права и объекты, на которые они распространяются, собирательно называемые «контекст». Следовательно, в сеть соседнего проекта можно попасть точно так же, как и в любую другую внешнюю сеть: через публичную сеть «Интернет» или, например, организовав VPN-туннель.
Сети, подсети и порты
В OpenStack есть два уровня сетей: сети и подсети. Это распространенная практика большинства облачных провайдеров.
-
Сеть. На этом уровне настраиваются возможности доступа в интернет, использования DHCP-сервиса и локального DNS.
-
Подсеть. Внутри сети создается одна или несколько подсетей. Для них уже нужно указать конкретный диапазон адресов, выдаваемых через DHCP (если DHCP включен на уровне сети); адрес шлюза по умолчанию (если для сети включен доступ в интернет). Также на уровне подсети можно задать статические маршруты, эта настройка автоматически распространится на все ВМ в подсети. По сути, это эквивалент статических маршрутов внутри операционных систем обычных виртуальных машин, но управляемый централизованно.
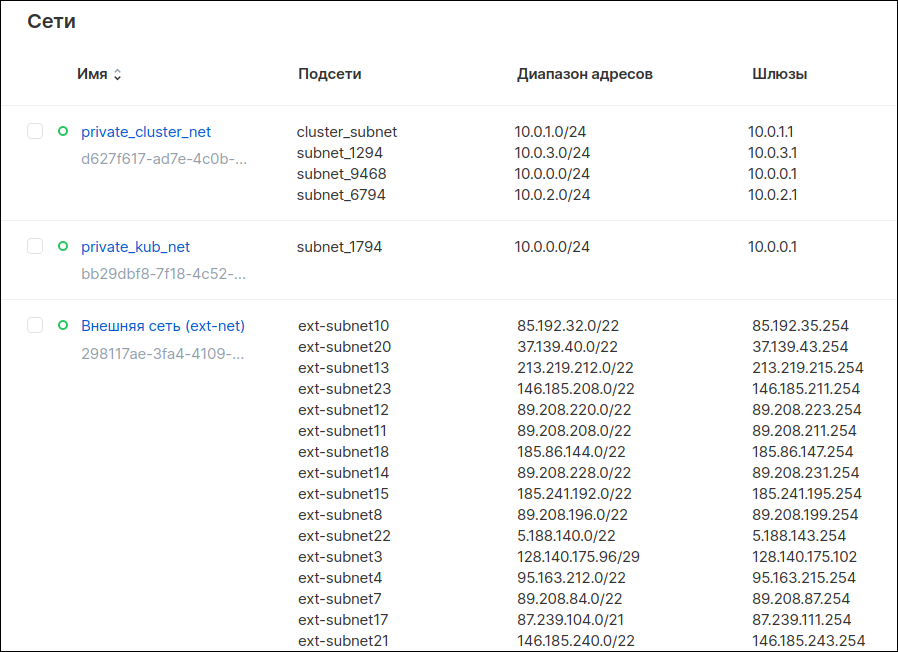
Сети и подсети в панели управления VK Cloud Solutions
В OpenStack нет сетевого порта и виртуального сетевого адаптера в классическом понимании, здесь это все объединено в одну сущность под названием «порт». По сути, порт в такой реализации равноценен сетевому адаптеру + сетевому шнуру + порту на коммутаторе в традиционной физической сети. Для порта можно поменять IP-адрес, но отдельно друг от друга порта и адреса не существует.
В рамках предоставления услуги виртуальных сетей можно сконфигурировать DHCP-сервис, который выделяет адреса автоматически. Такие адреса закрепляются за виртуальным портом / сетевым адаптером, почти как статические IP-адреса закрепляются за MAC-адресом в традиционной сети. То есть можно выключить виртуальную машину и не запускать ее хоть целый год — адрес останется зарезервирован за ней, точнее за ее виртуальным сетевым адаптером.
Механизм распространения статических маршрутов реализован за счет внедрения в образы для создания ВМ специального пакета cloud-init, который представляет собой набор инструментов для преднастройки виртуальной машины, в том числе ее сетевых параметров.
Для управления DNS-записями на нашей платформе можно сконфигурировать целых два DNS-сервиса: приватный DNS позволяет обращаться к инстансам по их именам внутри вашей сети и включается на уровне сетей, а с помощью публичного DNS вы можете создавать глобально доступные DNS-зоны и управлять их ресурсными записями. Записи в приватном DNS создаются автоматически и соответствуют имени ВМ или сетевой сущности, а публичный DNS уже управляется из-под своего выделенного подменю в облачной консоли, так как сервис все-таки глобальный.
Для маршрутизации между своими приватными сетями используется сущность Neutron Router (в интерфейсе она называется просто «маршрутизатор»). На уровне роутера также можно прописать статические маршруты, например, если вам нужно построить сложную цепочку пересылки пакетов с использованием «граничных» сетей. Для коммутации в базовом случае подключают несколько сетей к одному и тому же маршрутизатору.
Так как под подключение к Neutron Router обычно резервируется первый адрес из диапазона DHCP, вам не нужно настраивать параметры маршрутизации для базовых сценариев. Если есть задачи по построению более сложных схем, то обращайтесь, проконсультируем.
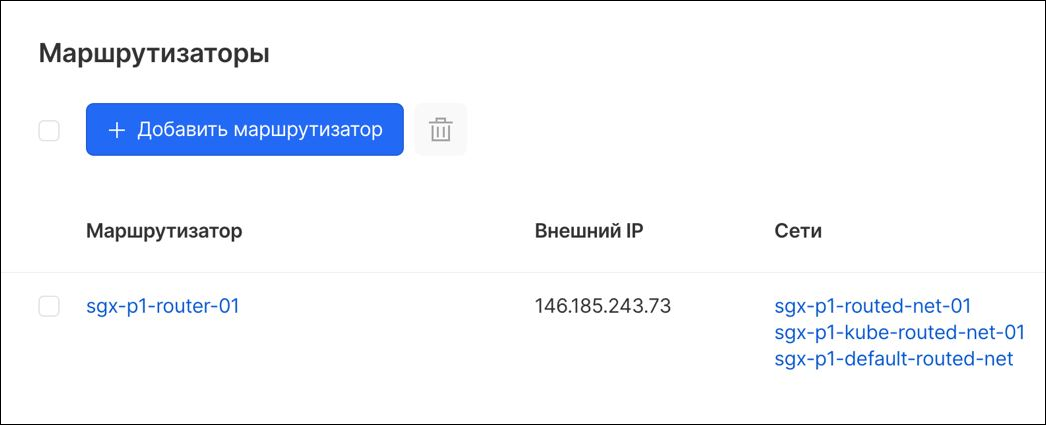
Маршрутизатор в панели управления VK Cloud Solutions
Наличие механизмов, описанных выше, с одной стороны, позволяет сильно упростить управление облачными сетями. С другой стороны, прозрачность этих механизмов гарантирует, что для виртуальных машин в таких средах можно использовать те же самые инструменты и протоколы, которые используются в традиционной среде, но такой подход несет с собой некоторые ограничения. Например, в таких сетях невозможно напрямую реализовать VRRP-протокол, когда на уровне сетевого оборудования создается кластерный IP-адрес, который «ездит» между двумя ВМ. В целом, такая схема чаще не нужна: высокая доступность ВМ обеспечиваются механизмами High Availability платформы. Тем не менее, так как наши сети виртуальные, все же существует возможность использования третьего адреса для организации высокой доступности на уровне ВМ, и если у вас есть такая потребность, приходите, поможем ее реализовать.
Как настраивается Firewall в облаке
В нашем облаке файрвол доступен на двух уровнях: платформы и ОС виртуальных машин. Уровень ОС по понятным причинам из своего повествования я исключаю. Платформенный файрвол работает на уровне виртуального сетевого моста в рамках каждого сервера виртуализации, то есть еще до того, как пакет покинет физический сетевой адаптер. Механизм работы основан на группах безопасности (Security Group), включающих в себя набор правил фильтрации трафика и виртуальные хосты, на которые распространяются эти правила. Они работают по принципу «белого списка»: что не разрешено, то запрещено. Благодаря этому можно не беспокоиться, что правила из разных групп будут конфликтовать.
Всегда существует как минимум одна дефолтная группа правил (default) — в нашем облаке она создается автоматически.
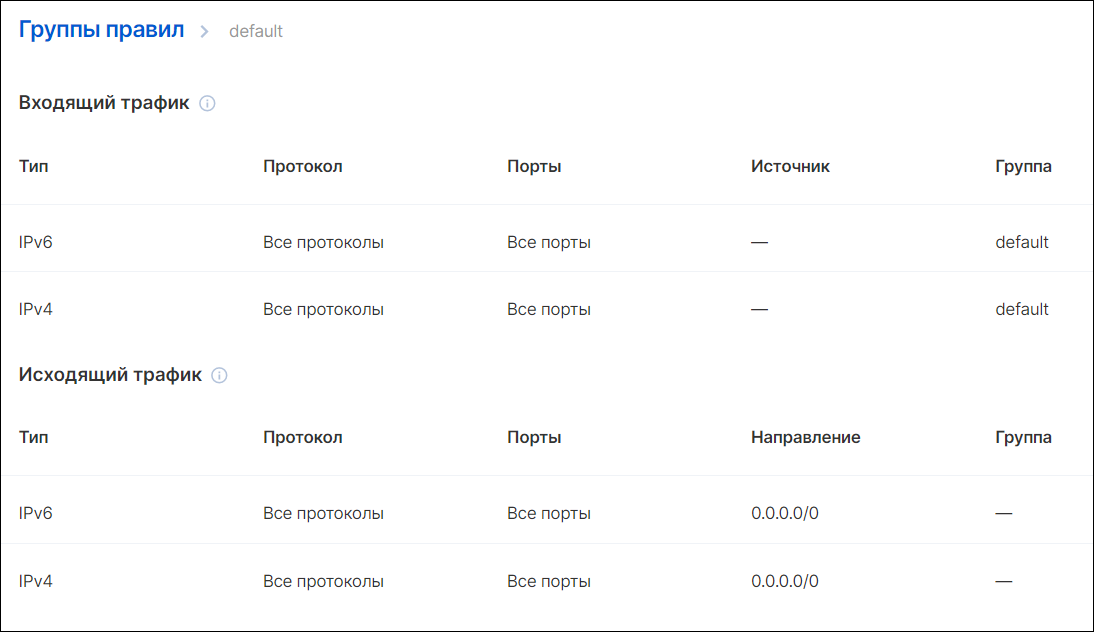
Правила группы безопасности default в консоли управления VK Cloud Solutions
В группе по умолчанию прописаны правила, в том числе разрешающие весь входящий трафик, но пугаться не стоит, и вот почему. В правилах задаются два типа источников трафика: IP-сети (фильтруются на основе того, с какого IP отправлен трафик) и группы безопасности (фильтруются на основе того, в какую группу безопасности входит сервер-отправитель).
Поэтому в группе default разрешен только входящий трафик для самой группы default. Это означает, что все серверы, входящие в группу, смогут отправлять трафик на другие серверы этой же группы. При этом трафик не будет отфильтрован и долетит до цели. Но, например, если трафик придет из той же сети, но от машины, не входящей в ту же группу, то он будет отброшен, так как не удовлетворяет условиям фильтрации.
Соответственно, не рекомендую удалять эти правила, иначе ваши машины в рамках одной сети и в рамках одной группы безопасности не смогут обмениваться трафиком. Напомню: запрещено все, что не разрешено явно.
Если же, например, вам нужно разрешать трафик из других IP-сетей, то тут уже все проще: необходимо лишь создать новые правила с указанием конкретных сетей. При создании нового правила безопасности в качестве адреса можно выбрать:
- «все IP-адреса» — этому соответствует источник/приемник 0.0.0.0;
- задать определенный диапазон;
- создать правило, которое распространяется на серверы, входящие в определенную группу безопасности.
Добавление правила для новой группы безопасности
Если у виртуальной машины несколько сетевых интерфейсов, то настройки групп безопасности можно указать отдельно для каждого из них. Сами правила, входящие в состав групп безопасности, распределены между всеми серверами, участвующими в предоставлении виртуальных ресурсов. То есть можно быть уверенными, что при переезде виртуальной машины на другой физический сервер все правила переедут за ней.
Если вы планируете использовать кастомные сетевые сущности (шлюз, маршрутизатор или Firewall), то имейте в виду, что такие машины в базовом сценарии могут представлять угрозу безопасности, так как их конфигурация позволяет пропускать трафик «сквозь» ВМ. Поэтому изначально такая возможность у нас закрыта, но, разумеется, все можно открыть по запросу в техническую поддержку, и здесь отдельно напомню про настройку.
Настройка VPN на облачной платформе VK Cloud Solutions
VPN для подключения к облаку используется в двух случаях:
- если нужно удаленно управлять инфраструктурой с помощью SSH, RDP или других инструментов, при этом важно, чтобы данные не проходили через публичные каналы передачи данных в открытом виде;
- если у компании распределенная структура (есть филиалы в разных регионах), при этом сети центрального офиса и филиала нужно логически связать.
В нашем облаке для решения этих задач есть VPN-сервис, использующий протокол IPSec с заданным ключом (PSK). Протокол IPSec обеспечивает совместимость с большей частью сетевых устройств и ПО, включая продукцию Cisco, VMware и прочих производителей. Важно помнить, что этот тип VPN-соединений предназначен для сценария site-to-site (то есть только для второго случая из рассматриваемых), так как отдельные подключения здесь не персонифицируются.

Добавление нового VPN. Заполнение IPSec-политики
Нужно иметь в виду, что VPN-сервис всегда привязывается к маршрутизатору и его необходимо указать при настройке. Так как в общем случае требуется соединить VPN-сеть с офисом или другой сетью, у маршрутизатора должен быть внешний интерфейс, то есть это должен быть маршрутизатор с доступом в интернет.
Если же необходим пользовательский VPN, то нужно внедрять специализированные сторонние решения, которые предоставляют каждому клиенту персональную учетную запись, позволяют гибко настраивать правила маршрутизации и доступы, а также могут покрывать аудитом доступа каждую отдельную сессию.
При построении гибридной среды с использованием шифрованных VPN-каналов важно, чтобы на удаленных площадках были либо полные реплики (синхронные или асинхронные в зависимости от критичности), либо кэширующие узлы централизованных систем, чтобы в случае сбоя VPN-канала площадка продолжала работать. Это, например, касается сервисов каталогов, DNS, мониторинга и автоматизации.
Особенности виртуальных сетей на платформе VK Cloud Solutions
Виртуальные машины, кластеры и прочие облачные ресурсы нужно как-то делать доступными через интернет. Обычно для этого используют так называемые провайдерские сети и трансляцию адресов.
Для этого в каждом проекте нашего облака всегда присутствует сеть ext-net, которая используется в качестве провайдерской внешней сети. Наш случай частный, так как мы предоставляем в провайдерской сети прямые, глобально доступные IPv4-адреса. Обычно в OpenStack не имеет значения, какую сеть использовать в качестве провайдерской, это может быть и своя приватная сеть, используемая, например, для публикации внутренних порталов для On-premise OpenStack или DMZ. Чуть ниже я расскажу подробнее о том, какие возможности предоставляет такой подход.
- Для публикации ресурсов вовне также можно использовать сервис «плавающих IP» — механизм полной трансляции адресов (NAT), который позволяет перенаправлять весь трафик, полученный на адрес в провайдерской сети (под «плавающий IP» бронируется адрес из сети ext-net), на адрес в приватной сети клиента.
- При размещении виртуального сетевого адаптера виртуальной машины напрямую в сети ext-net также необходимо для этой ВМ создать и настроить еще и адаптер в созданной пользователем заранее приватной сети, если, конечно, нужно, чтобы эта ВМ могла общаться с другими сетевыми сущностями в рамках этой сети.
- При использовании технологии плавающих IP обязательно должен существовать только адаптер в частной сети, на который через этот механизм и будет перенаправляться трафик. Для этого, как упоминалось выше, будет выделен адрес в диапазоне ext-net, «забронированный» за нашим адаптером в приватной сети, и с него будет перенаправляться весь трафик. То есть дополнительных адаптеров создавать не нужно, ваша машина окажется доступна из интернета и сможет обращаться к ресурсам во внутренней сети, если, конечно, настроен еще и файрвол, но об этом ниже.
- Кроме этого, плавающий IP-адрес можно отвязать от интерфейса в приватной сети и привязать его к другому. Это может быть сетевой интерфейс совершенно другой ВМ в другой сети — очень полезная возможность, особенно при необходимости модифицировать или мигрировать приложение или его компоненты.
Иногда встречаются клиенты с жесткими внутренними политиками безопасности в плане управления сетью и используемых продуктов. Как известно, внутренние политики безопасности компании — это документы, которые очень тяжело и долго корректируются, а многим клиентам нужно переехать в облако поскорее, чтобы начать экономить средства и модернизировать свои информационные системы. Для таких ситуаций при установке соответствующих настроек и самостоятельном разворачивании сетевых сущностей мы позволяем использовать свои роутеры, файрволы, шлюзы или VPN-сервисы в рамках своих пользовательских сетей.
Как упоминалось выше, схема с размещением виртуального адаптера напрямую во внешней сети ext-net несет с собой дополнительные сложности по настройке, в которые всегда выливается наличие у виртуальной машины более одного сетевого адаптера. Но также этот подход довольно гибок для реализации «частных случаев».
Рассмотрим ситуацию, когда, например, вам необходимо использовать свои виртуальные апплаинсы для обеспечения маршрутизации или необходимо на выходе из сети настроить граничный файрвол (причем использовать можно только тот, который разрешен вашей службой ИБ). В этом случае можно:
- создать виртуальную сеть, у которой нет ни доступа к интернету, ни связи с Neutron Router;
- затем развернуть виртуальный appliance с необходимой ролью;
- создать для него как виртуальный адаптер в сети ext-net (если нужен интернет), так и виртуальный адаптер в вашей сети без роутера;
- настроить правила пересылки внутри маршрутизатора/файрвола;
- сделать еще одну настройку.
Таким способом можно реализовать схему по управлению сетью, которая уже принята в вашей компании, и при этом не нужно будет сильно модифицировать Control Plane.
Доступ к Control Plane облака из сетей без доступа в интернет
Все наши сервисы при работе в той или иной мере используют API. Все точки обращения (эндпоинты) к сервисам — публичные, то есть доступны только из интернета. Через эти API endpoint можно отправлять управляющие команды со стороны пользовательских систем (например, виртуальный скрипт-хост, размещенный в сети без доступа к интернету). Но чаще они используются для отработки механизмов автоматизации и других внутренних задач платформы: когда вы создаете любой PaaS-сервис, для выделения ресурсов он обращается к той же точке, чтобы получить данные о том, как тот или иной компонент должен быть сконфигурирован.
Получается, что даже изолированным сетям без выхода в интернет нужно иметь доступ к API endpoint, иначе платформенные сервисы попросту не смогут развернуться. Для решения этой задачи мы разработали технологию shadowport. Чтобы реализовать эту технологию для сетей без выхода в интернет, задействуется один адаптер и подключается к сервисному балансировщику нагрузки внутри проекта (shadow-балансировщик, в консоли его не видно). И когда на этот адаптер приходит запрос к определенной API endpoint, адаптер пробрасывает трафик по внутренним сетям, не выходя в интернет. Куда конкретно перенаправлять запрос, балансировщик «понимает» из DNS-имени, содержащегося в запросе.
Этот механизм можно также использовать и для своих целей, например, если вам нужно отправлять управляющие сигналы в сторону Control Plane нашей платформы из изолированных сетей.

Технология Shadowport
Получается, что даже изолированным сетям без выхода в интернет нужно иметь доступ к API endpoint, иначе платформенные сервисы попросту не смогут развернуться. Для решения этой задачи мы разработали технологию shadowport. Чтобы реализовать эту технологию для сетей без выхода в интернет, задействуется один адаптер и подключается к сервисному балансировщику нагрузки внутри проекта (shadow-балансировщик, в консоли его не видно). И когда на этот адаптер приходит запрос к определенной API endpoint, адаптер пробрасывает трафик по внутренним сетям, не выходя в интернет. Куда конкретно перенаправлять запрос, балансировщик «понимает» из DNS-имени, содержащегося в запросе.
Этот механизм можно также использовать и для своих целей, например, если вам нужно отправлять управляющие сигналы в сторону Control Plane нашей платформы из изолированных сетей.
Технология Shadowport
Балансировка нагрузки в облачных сетях
Один из основополагающих принципов Cloud-Native-подхода к построению приложений — это Decoupling, то есть «слабая связанность компонентов».
Например, если у вас есть стандартная архитектура, состоящая из фронтенд-серверов, серверов приложений и серверов БД, то при таком подходе вместо прямой связи между компонентами нужно использовать проксирующие или балансирующие сущности. То есть напрямую от фронтенда запрос не должен уходить в сервер приложений, для начала он должен прилететь, например, на балансировщик сетевой нагрузки, который распределит запрос на нужный сервер приложений. Здесь, конечно, может стоять и очередь сообщений, и где-то еще сбоку API-шлюз, но это тема для совсем другой статьи.
Этот подход позволяет сильно повысить отказоустойчивость: если один обработчик из группы упадет, другие смогут перехватить задачу и выполнить ее. При этом можно гибко конфигурировать и модифицировать отдельные компоненты: по очереди выводить серверы из балансировки, обслуживать их и переконфигурировать. Поэтому балансировщики сетевого трафика начинают играть уже более заметную роль в облачных средах, так как здесь они используются не только для веб-приложений.
В нашем облаке сервис балансировки LBaaS называется незамысловато — «балансировщики нагрузки», и реализован он на основе двух ВМ с HAProxy в отказоустойчивом режиме (HA-режим). При этом сами ВМ вам недоступны (в консоли вы их не увидите и платить за них не нужно), а вместо управления отдельными машинами вы получаете интерфейс управления всеми политиками балансировки в веб-консоли.
Балансировщику можно назначить внешний IP и настроить разные протоколы балансировки: HTTP, HTTPS и TCP. При выборе HTTPS можно загрузить цепочку SSL-сертификатов, а для TCP также реализован протокол TCP Proxy.
Для чего нужен TCP Proxy? По умолчанию балансировщики большинства облачных провайдеров проксирующие, то есть они отдают бэкенду все пакеты от имени своего приватного адреса. При этом теряется часть исходной информации, вроде IP-адреса клиента, браузера, ОС и так далее.
А протокол TCP Proxy позволяет прокинуть эти данные в отдельных HTTP-заголовках.
Разумеется, бэкенд здесь тоже должен уметь работать с Proxy Protocol. Это может пригодиться приложениям, которым нужно знать IP-адрес клиента для определения его географического положения, например для e-commerce-платформ. Ради удобства в интерфейсе консоли можно быстро настроить отправку самого часто используемого заголовка — X-Forwarded-For. Если нужны другие заголовки, их можно настроить вручную.
Добавление правила балансировщика нагрузки
Методы балансировки стандартные: по наименьшему количеству соединений (Least Connections), по очереди (Round-Robin) и по Source IP (так называемые Sticky-сессии: все запросы от того же клиента будут улетать в тот же бэкенд). Для более тонкой настройки механизма балансировки можно назначить экземплярам веса. Например, если указать для одной машины вес 10, а для другой 1, то большая часть трафика будет уходить на первый бэкенд.
Проверять доступность серверов можно по протоколам TCP и HTTP. С помощью HTTP можно организовать более интеллектуальную проверку, чем с TCP: опрашивать Web-сервис и в зависимости от кода ответа принимать решение о его доступности.
Если VPN недостаточно: как подключить свои VLAN-/VXLAN-сети к облаку
Часто клиенты не могут перестраивать свою сетевую инфраструктуру, либо невозможно сделать это быстро, будь то из-за жестких внутренних политик безопасности или Legacy-софта, который еще не потерял актуальность и все еще бизнес-критичен. В таких ситуациях можно расширить сеть, терминированную на оборудовании клиента (по сути, «растянуть» свой L2-домен) до ресурсов в облаке. Это позволяет оставить в облаке то же самое адресное пространство, которое было в исходной сети.
Для реализации такой конфигурации арендуется приватный канал у оператора связи, присутствующего в наших ЦОДах и в ЦОДе клиента, в котором терминированные на оборудовании клиента сети прокидываются до оборудования в нашем облаке. Далее мы настраиваем железки, чтобы пакеты из сетей клиентов долетали до коммутаторов в стойках с серверами виртуализации, после чего мы помогаем клиентам настроить сети уже в рамках проекта.
Такой подход позволяет перенести в облако сложные системы с минимальными модификациями, чтобы в дальнейшем сильно снизить расходы на эксплуатацию перенесенной системы. Сэкономленные средства затем можно направить на модификацию этих же систем, повышая их доступность, гибкость управления и еще больше снижая стоимость эксплуатации (мы обычно так и рекомендуем делать).
Для таких клиентских «проброшенных» сетей есть несколько ограничений. Например, в клиентских VXLAN-сетях лучше не использовать наш маршрутизатор: из-за особенностей реализации он будет долго восстанавливаться после сбоев, десятки минут или даже часы. Поэтому маршрутизацию лучше оставить на оборудовании, на котором сети терминировались, либо разворачивать в облаке отдельные appliances для управления маршрутизацией.
Обеспечение высокой доступности «кастомных стыков»
Для того чтобы понять, как повысить доступность такой схемы, давайте вернемся к истокам. В рамках рассматриваемой темы нас интересуют базовая статическая и динамическая маршрутизация.
Статическая маршрутизация используется там, где четко определены правила передачи пакетов и топология сети остается неизменной. Она довольно проста и удобна в настройке, но не может сама адаптироваться под изменение конфигурации сети. Например, если в ЦОДе с тремя каналами один оборвется, то будут передаваться только пакеты, подходящие под правила двух цепочек. А поток, который ходил по другой линии, просто перестанет работать.
Для таких ситуаций существует динамическая маршрутизация, которая работает с граничными протоколами, используемыми на стыках сетей провайдеров и в дата-центрах. Один из самых популярных протоколов — BGP (Border Gateway Protocol), именно он и используется у нас внутри инфраструктуры для взаимосвязи различных типов сетей.
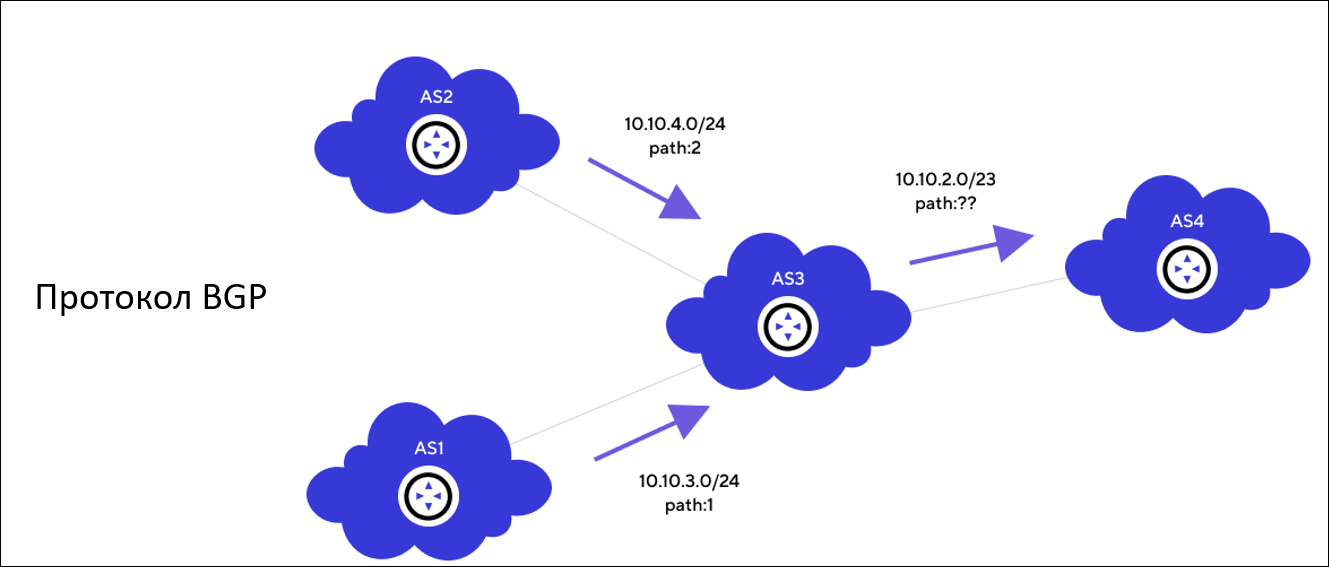
Динамическая маршрутизация
Одно из основных преимуществ BGP — отказоустойчивость и возможность автоматического перестроения маршрутов на всех оставшихся сетевых устройствах в случае сбоев на оборудовании.
Эти же механизмы используются при построении внутренних Underlay-сетей, поэтому на уровне клиентских сетей не нужно реализовывать дополнительную отказоустойчивость. Если физическое оборудование в нашем ЦОДе выйдет из строя, топология перестроится автоматически и прозрачно для вас.
Именно поэтому динамическая маршрутизация используется на стыке между операторскими сетями. Чтобы построить высокодоступное соединение с нашим ЦОДом, клиенту необходимо выбрать оператора, который использует такую же динамическую маршрутизацию при предоставлении внешних точек подключения. Это позволит повысить доступность внешних точек подключения клиента.
Таким образом, подключение к нашему ЦОДу будет защищено механизмами высокой доступности с двух сторон: с нашей стороны и со стороны клиента. В этом случае нет необходимости формировать такую же схему на уровне пользовательских сетей, усложняя коммутацию и увеличивая количество потенциальных точек отказа. Для пользовательских сетей проще и надежней использовать статическую маршрутизацию.
Но иногда бывают ситуации, когда клиент не может реализовать на своей стороне отказоустойчивое подключение, а статическая маршрутизация ему не подходит. Поэтому сейчас мы разрабатываем сервис DirectConnect — это кастомные VLAN-/VXLAN-сети как услуга, которые решат эти проблемы. Подробнее о сервисе мы расскажем ближе к дате релиза.
Тем не менее, если рекомендованную схему реализовать невозможно, но отказоустойчивая схема при этом нужна, расскажите о своей задаче, мы проконсультируем и поможем найти решение.
Нерешаемые проблемы OpenStack Neutron, или Почему мы начали разработку своего SDN
OpenStack Neutron — модуль платформы, который управляет жизненным циклом клиентских виртуальных сетей: созданием, изменением и декомиссией. Он может управлять довольно большим количеством разных решений, начиная с Open vSwitch и Neutron Router и заканчивая управлением физическими свитчами, поддерживающими централизованное управление и имеющими качественно реализованный драйвер для Neutron.
Как правило, клиенты облачных платформ не взаимодействуют с ним напрямую. Но возможно, что многие из вас слышали о проблемах облачных сетей, связанных с Neutron. Например, виртуальные сетевые функции (Network Virtual Function), которые у него исполняются, не любят сохранять свое состояние, или многие вызовы не ждут ответа-подтверждения, что может приводить к коллизиям, рассинхронизации и даже временному отказу сервиса. Также есть несколько других проблем уровня дизайна. Я не буду погружаться в подробности, но в конце статьи дам ссылку на подробный доклад на эту тему.
На текущий момент у нас одна из самых больших и стабильных инсталляций OpenStack Neutron в мире (если не самая большая) — творить такие чудеса позволяет опыт сообщества и квалификация наших специалистов, но, как говорится, не чудесами едиными…
Короче говоря, в итоге у нас появился собственный компонент для управления сетью под названием Sprut. Он решает многие проблемы Neutron и позволяет нам кастомизировать OpenStack-сети так, чтобы предоставлять вам больше гибкости в построении ваших виртуальных сетей. Сейчас у нас работают одновременно Neutron и Sprut, каждый отвечает за определенную область. Сначала мы реализовали в Sprut то, что не умеет Neutron, но постепенно мы будем его дорабатывать и полностью вытеснять Neutron.
И еще один любопытный момент: упомянутый выше механизм Shadowport практически невозможно реализовать с использованием OpenStack Neutron, поэтому у нас он работает на базе Sprut.
Если вы хотите больше узнать о проблемах Neutron и о том, почему мы решили разрабатывать свой SDN, то посмотрите доклад моего коллеги Александра Попова, он рассказывал об этом на HighLoad++ 2019.
Заключение
Мы разобрали, чем сети в облаке отличаются от сетей On-premise. Кратко описали принципы работы технологии VXLAN: альтернативы VLAN, работу сетей, подсетей и портов в облачных сетях. Разобрали настройки Firewall, VPN, балансировки нагрузки и особенности построения виртуальных сетей на примере облака VK Cloud Solutions.
Затронули тему подключения собственных готовых сетей к облаку и повышения доступности такой системы. А также коснулись нерешаемых проблем платформы OpenStack и рассказали, как мы стараемся их решать в VK Cloud Solutions при помощи собственного компонента Sprut.
Нашу платформу VK Cloud Solutions можно протестировать. Для этого при регистрации мы начисляем пользователям 3000 бонусных рублей — приходите, пробуйте и оставляйте обратную связь.
Что еще почитать: