
Разрабатывая новые продукты, мы зачастую выводим нашу операционную систему — Linux — за рамки общепринятых возможностей. Распространенной темой было использование eBPF для создания технологии, которая в противном случае потребовала бы модификации ядра. Например, мы создали систему защиты от DDoS и балансировщик нагрузки и используем ее для мониторинга нашего серверного парка.
Это программное обеспечение обычно состоит из маленькой программы eBPF, написанной на языке C и выполняемой в контексте ядра, и более крупного компонента пространства пользователя, который загружает eBPF в ядро и управляет его жизненным циклом. Выяснилось, что соотношение кода eBPF и кода пространства пользователя различается на порядок и более. Наша цель — пролить свет на проблемы, с которыми сталкивается разработчик при работе с eBPF, и предложить наши решения для создания надежных, продакшн-реди приложений, содержащих eBPF.
С этой целью мы предоставляем продакшн-инструменты с открытым исходным кодом, которые были созданы для хука sk_lookup, внесенного нами в ядро Linux, под названием tubular. Он существует потому, что мы переросли BSD sockets API. Чтобы поставлять некоторые продукты, нам нужны функции, которые просто невозможно реализовать с помощью стандартного API.
Наши сервисы доступны на миллионах IP-адресов.
Несколько сервисов, использующих один и тот же порт на разных адресах, должны сосуществовать, например, резольвер 1.1.1.1 и наш авторитетный DNS.
Наш продукт Spectrum должен прослушивать все 2^16 портов.
Исходный код tubular находится по адресу https://github.com/cloudflare/tubular, и он позволяет делать все вышеперечисленные вещи. Возможно, самой интересной особенностью является то, что вы можете менять адреса служб на лету — посмотрите видео на странице оригинала.
Принцип работы tubular
tubular располагается в критической точке стека Cloudflare, поскольку ему приходится проверять каждое соединение, прерванное сервером, и решать, какое приложение должно его получить.
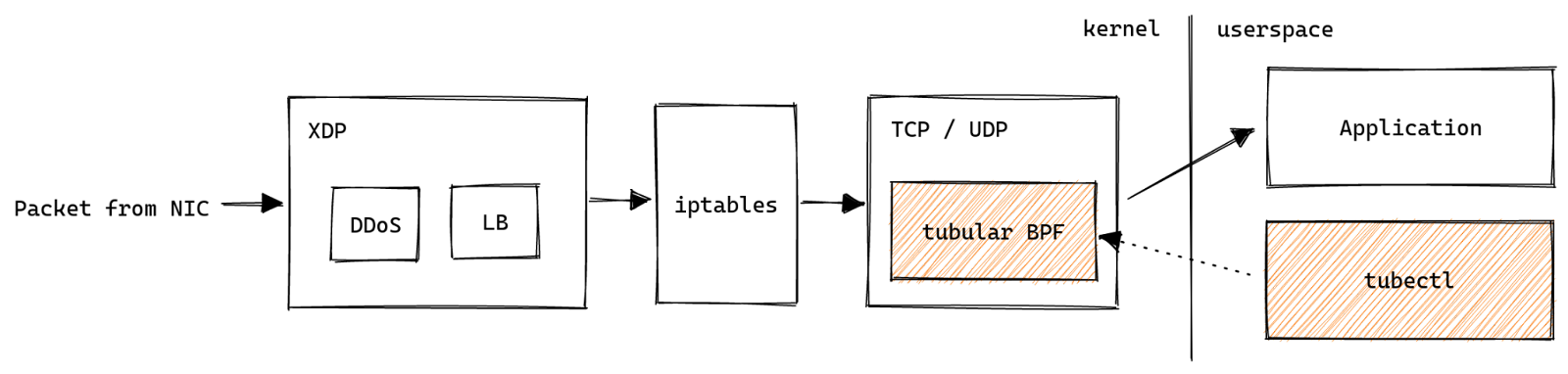
В противном случае соединения будут обрываться или перенаправляться сотни раз в секунду. Поэтому он должен быть невероятно надежным во время повседневной работы. Мы поставили перед tubular следующие цели:
Релизы должны быть автоматизированными, не требующими контроля, и происходить в режиме онлайн. tubular работает на тысячах машин, поэтому мы не можем нянчиться с этим процессом или выводить серверы из продакшна.
Релизы должны быть безопасными. При сбое в процессе необходимо, чтобы была запущена предыдущая версия tubular, иначе мы можем сбросить соединения.
Уменьшить влияние сбоев (в пользовательском пространстве). Когда появляется неизбежная ошибка, нам хочется минимизировать радиус поражения.
В прошлом мы создали пробный вариант концепции управления для sk_lookup под названием inet-tool, который доказал, что можно обойтись без постоянного сервиса, управляющего eBPF. Аналогично, tubular имеет tubectl: кратковременные вызовы производят необходимые изменения, а сохраняющееся состояние обрабатывается ядром в виде карт eBPF. Следуя этой схеме, мы получили устойчивость к сбоям по умолчанию, но при этом нам пришлось решать задачу маппирования пользовательского интерфейса, который мы хотели, с инструментами, доступными в экосистеме eBPF.
Пользовательский интерфейс tubular
tubular состоит из программы BPF, которая подключается к хуку sk_lookup в ядре, и пользовательского кода Go, который управляет программой BPF. Команда tubectl оборачивает обе программы таким образом, чтобы их было легко распределять.
tubectl управляет двумя видами объектов: биндингами и сокетами. Биндинг кодирует правило, по которому осуществляется матчинг входящего пакета. Сокет — это указатель на TCP или UDP сокет, который может принимать новые соединения или пакеты.
Биндинги и сокеты "склеиваются" вместе с помощью произвольных строк, называемых метками. В принципе, биндинг присваивает метку некоторому трафику. Затем метка используется для поиска нужного сокета.

Чтобы создать биндинг, который направляет трафик порта 80 (он же HTTP), предназначенный для 127.0.0.1, на метку "foo", мы используем tubectl bind:
$ sudo tubectl bind "foo" tcp 127.0.0.1 80Благодаря возможностям sk_lookup мы можем использовать гораздо более мощные конструкции, чем BSD API. Например, мы можем перенаправлять соединения со всеми IP-адресами в 127.0.0.0/24 на один сокет:
$ sudo tubectl bind "bar" tcp 127.0.0.0/24 80Побочным эффектом такой способности является вероятность создания биндингов, которые "перекрывают" друг друга:
1: tcp 127.0.0.1/32 80 -> "foo"
2: tcp 127.0.0.0/24 80 -> "bar"Первый биндинг говорит, что HTTP-трафик на localhost должен идти на "foo", а второй утверждает, что HTTP-трафик в подсети localhost должен идти на "bar". Это создает противоречие, какой же из вариантов биндинга выбрать? tubular решает эту проблему, определяя правила приоритета для биндингов:
Префикс с более длинной маской является более специфичным, например, 127.0.0.1/32 превосходит 127.0.0.0/24.
Порт более конкретен, чем подстановочный символ порта, например, порт 80 превосходит значение "все порты" (0).
Применяя это к нашему примеру, HTTP-трафик на все IP-адреса в 127.0.0.0/24 будет направлен на bar, за исключением 127.0.0.1, который идет на foo.
Получение доступа к сокетам
sk_lookup нуждается в указателе на TCP или UDP сокет, чтобы перенаправить на него трафик. Однако сокет обычно доступен только процессу, который создал его с помощью системного вызова socket. Например, HTTP-сервер создает прослушивающий TCP-сокет, привязанный к порту 80. Как мы можем получить доступ к прослушивающему сокету?
Достаточно известное решение — заставить процессы сотрудничать, передавая дескрипторы файлов сокетов через сообщения SCM_RIGHTS демону tubular. Затем этот демон может предпринять необходимые шаги для подключения сокета с помощью sk_lookup. Этот подход имеет несколько недостатков:
Требуется модификация процессов для отправки SCM_RIGHTS.
Требуется демон tubular, который может выйти из строя.
Есть еще один способ получить доступ к сокетам с помощью systemd, при условии, что используется активация сокета. Он работает путем создания дополнительного сервисного юнита с правильной настройкой Sockets. Другими словами: мы можем использовать действие systemd oneshot, выполняемое при создании службы systemd socket, регистрируя сокет в tubular. Например:
[Unit]
Requisite=foo.socket
[Service]
Type=oneshot
Sockets=foo.socket
ExecStart=tubectl register "foo"Поскольку мы можем положиться на systemd в выполнении tubectl в нужное время, нам не нужен никакой демон. Однако реальность такова, что многие популярные программы не используют активацию сокетов systemd. Работа с сокетами systemd сложна и не располагает к экспериментам. Что в итоге приводит нас к финальному приему: pidfd_getfd:
Системный вызов pidfd_getfd() аллоцирует новый файловый дескриптор в рамках процесса вызова. Этот новый файловый дескриптор является дубликатом существующего дескриптора, targetfd, в процессе, на который ссылается PID файлового дескриптора pidfd.
Мы можем использовать его для итерации всех файловых дескрипторов чужого процесса и выбора интересующего нас сокета. Возвращаясь к нашему примеру, мы можем использовать следующую команду, чтобы найти TCP-сокет, привязанный к 127.0.0.1 порту 8080 в процессе httpd, и зарегистрировать его под меткой "foo":
$ sudo tubectl register-pid "foo" $(pidof httpd) tcp 127.0.0.1 8080Если возникнет необходимость, это легко подключить с помощью ExecStartPost от systemd.
[Service]
Type=forking # or notify
ExecStart=/path/to/some/command
ExecStartPost=tubectl register-pid $MAINPID foo tcp 127.0.0.1 8080Хранение состояния в картах eBPF
Как упоминалось ранее, tubular полагается на ядро для хранения состояния, используя структуры данных BPF ключ/значение, также известные как карты. Используя системный вызов BPF_OBJ_PIN, мы можем сохранять их в /sys/fs/bpf:
/sys/fs/bpf/4026532024_dispatcher
├── bindings
├── destination_metrics
├── destinations
├── sockets
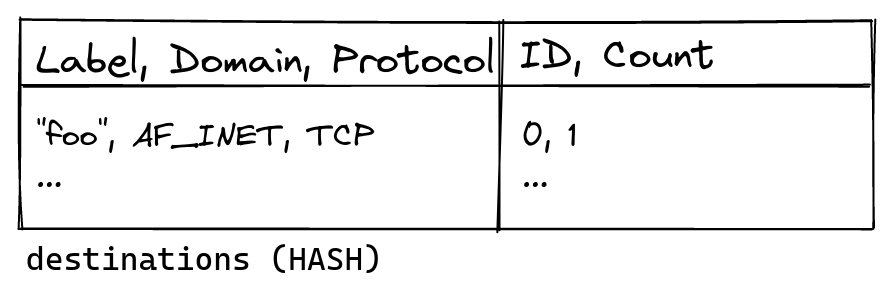
└── ...Характер структуры состояния отличается от того, как интерфейс командной строки представляет его пользователям. Ярлыки типа "foo" удобны для людей, но они имеют переменную длину. Работа с данными переменной длины в BPF громоздка и медленна, поэтому программа BPF вообще не обращается к меткам. Вместо этого код пространства пользователя аллоцирует числовые идентификаторы (ID), которые затем используются в BPF. Каждый идентификатор представляет собой кортеж (label, domain, protocol), который для внутреннего пользования называется destination.
Например, добавление биндинга для "foo" tcp 127.0.0.1 ... аллоцирует идентификатор для ("foo", AF_INET, TCP). Включение (domain) домена и (protocol) протокола в пункт назначения (destination) позволяет использовать более простые структуры данных в BPF. Каждая аллокация также отслеживает, сколько биндингов указывают на пункт назначения, чтобы мы могли повторно использовать неиспользуемые идентификаторы. Эти данные сохраняются в хэш-таблице пунктов назначения, которая имеет ключ (Label, Domain, Protocol) и содержит (ID, Count). Метрики для каждого пункта назначения отслеживаются в destination_metrics в виде счетчиков для каждого процессора.
bindings — это древовидная структура матчинга самого длинного префикса (LPM), которая хранит маппинг от (protocol, port, prefix) до (ID, prefix length). ID используется как ключ к карте сокетов, которая содержит указатели на структуры сокетов ядра. Идентификаторы аллоцированы таким образом, что они могут использоваться в качестве индекса массива, это позволяет использовать более простую BPF sockmap (массив) вместо хэш-таблицы сокетов. Длина префикса дублируется в значении, чтобы обойти недостатки API BPF.

Кодирование приоритета биндингов
Как уже говорилось, биндинги имеют приоритет, ассоциированный с ними. Повторим предыдущий пример:
1: tcp 127.0.0.1/32 80 -> "foo"
2: tcp 127.0.0.0/24 80 -> "bar"Для первого биндинга необходимо сделать матчинг раньше, чем для второго. Необходимо как-то закодировать это в BPF. Одна из идей — сгенерировать код, выполняющий биндинги в порядке убывания их специфичности; этот прием мы с успехом использовали в l4drop:
1: if (mask(ip, 32) == 127.0.0.1) return "foo"
2: if (mask(ip, 24) == 127.0.0.0) return "bar"
...У этого есть обратная сторона: программа становится длиннее, чем больше будет добавлено биндингов, тем медленнее она будет выполняться. Кроме того, такие длинные программы трудно анализировать и отлаживать. Взамен мы используем специализированную карту матчинга самого длинного префикса (LPM) BPF для выполнения тяжелой работы. Это позволяет просмотреть содержимое программы из пространства пользователя и выяснить, какие биндинги активны, что было бы очень сложно, если компилировать их (биндинги) в BPF. Карта LPM использует древовидную структуру в качестве основы, поэтому сложность поиска пропорциональна длине ключа, а не линейна, как в "наивном" решении.
Однако использование карты требует определенных ухищрений для кодирования приоритета биндингов в ключ, который потом можно отыскать. Вот упрощенная версия такого кодирования, которая игнорирует IPv6 и использует метки вместо идентификаторов. Чтобы вставить биндинг tcp 127.0.0.0/24 80 в префиксное дерево (trie), мы сначала преобразуем IP-адрес в число.
127.0.0.0 = 0x7f 00 00 00Поскольку нас интересуют только первые 24 бита адреса, можно записать весь префикс в виде
127.0.0.0/24 = 0x7f 00 00 ??где "?" означает, что значение не определено. Выберем число 0x01 для обозначения TCP и добавим его и номер порта (80 в десятичной системе равно 0x50 в шестнадцатеричной) для создания полного ключа:
tcp 127.0.0.0/24 80 = 0x01 50 7f 00 00 ??Преобразование tcp 127.0.0.1/32 80 происходит точно так же. После того как преобразованные значения вставлены в trie, LPM trie концептуально содержит следующие ключи и значения.
LPM trie:
0x01 50 7f 00 00 ?? = "bar"
0x01 50 7f 00 00 01 = "foo"Чтобы найти биндинг для TCP-пакета, предназначенного для 127.0.0.1:80, мы снова кодируем ключ и осуществляем поиск.
input: 0x01 50 7f 00 00 01 TCP packet to 127.0.0.1:80
---------------------------
LPM trie:
0x01 50 7f 00 00 ?? = "bar"
y y y y y
0x01 50 7f 00 00 01 = "foo"
y y y y y y
---------------------------
result: "foo"
y = byte matchesTrie возвращает "foo", поскольку ее ключ имеет самый длинный общий префикс с входными данными. Обратите внимание, что мы прекращаем сравнивать ключи, как только достигаем неопределенных байтов "?", но концептуально "bar" все еще является валидным результатом. Различие становится очевидным во время поиска биндинга для TCP-пакета на 127.0.0.255:80.
input: 0x01 50 7f 00 00 ff TCP packet to 127.0.0.255:80
---------------------------
LPM trie:
0x01 50 7f 00 00 ?? = "bar"
y y y y y
0x01 50 7f 00 00 01 = "foo"
y y y y y n
---------------------------
result: "bar"
n = byte doesn't matchВ этом случае "foo" отбрасывается, так как последний байт не соответствует входным данным. Однако "bar" возвращается, так как его последний байт не определен и следовательно считается валидным матчингом.
Возможность наблюдения с минимальными привилегиями
В Linux есть мощный инструмент ss (часть iproute2), позволяющий исследовать состояние сокета:
$ ss -tl src 127.0.0.1
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:ipp 0.0.0.0:*С появлением tubular этот вывод уже перестал быть достаточно точным. Биндинги tubectl компенсируют данный недостаток:
$ sudo tubectl bindings tcp 127.0.0.1
Bindings:
protocol prefix port label
tcp 127.0.0.1/32 80 fooЗапуск данной команды требует привилегий суперпользователя, хотя теоретически ее может выполнить любой. Несмотря на то, что такое приемлемо для случайного инспектирования оператором-человеком, это является препятствием для наблюдаемости с помощью пулл-ориентированных систем мониторинга, таких как Prometheus. Стандартный подход заключается в предоставлении метрик через HTTP-сервер, который должен работать с повышенными привилегиями и каким-то образом быть доступным для сервера Prometheus. Вместо этого BPF предоставляет нам инструменты для обеспечения доступа к состоянию tubular только для чтения с минимальными привилегиями.
Ключевым моментом является тщательная установка владельца файла и режим для состояния в /sys/fs/bpf. Создание и открытие файлов в /sys/fs/bpf использует BPF_OBJ_PIN и BPF_OBJ_GET. Вызов BPF_OBJ_GET с BPF_F_RDONLY примерно эквивалентен открытию (O_RDONLY) и позволяет получить доступ к состоянию только для чтения, при условии правильных разрешений на файл. tubular дает полный доступ владельцу, но ограничивает его для группы — только для чтения:
$ sudo ls -l /sys/fs/bpf/4026532024_dispatcher | head -n 3
total 0
-rw-r----- 1 root root 0 Feb 2 13:19 bindings
-rw-r----- 1 root root 0 Feb 2 13:19 destination_metricsЛегко выбрать, какой пользователь и группа должны распоряжаться состоянием при загрузке tubular:
$ sudo -u root -g tubular tubectl load
created dispatcher in /sys/fs/bpf/4026532024_dispatcher
loaded dispatcher into /proc/self/ns/net
$ sudo ls -l /sys/fs/bpf/4026532024_dispatcher | head -n 3
total 0
-rw-r----- 1 root tubular 0 Feb 2 13:42 bindings
-rw-r----- 1 root tubular 0 Feb 2 13:42 destination_metricsЕсть еще одно препятствие, systemd монтирует /sys/fs/bpf таким образом, что он становится недоступным для всех, кроме root. Добавление исполняемого бита в каталог устраняет эту проблему.
$ sudo chmod -v o+x /sys/fs/bpf
mode of '/sys/fs/bpf' changed from 0700 (rwx------) to 0701 (rwx-----x)Наконец, мы можем экспортировать метрики без привилегий:
$ sudo -u nobody -g tubular tubectl metrics 127.0.0.1 8080
Listening on 127.0.0.1:8080
^CК сожалению, есть оговорка: для действительно непривилегированного доступа требуется включение непривилегированного BPF. Во многих дистрибутивах принято отключать его с помощью sysctl unprivileged_bpf_disabled, и в этом случае для скрейпинга метрик требуется CAP_BPF.
Безопасные релизы
tubular распространяется как единый двоичный файл, но на самом деле состоит из двух частей кода с совершенно разным лайфтаймом. Программа BPF загружается в ядро один раз и затем может быть активна в течение недель или месяцев, пока ее явно не заменят. Фактически, упоминание о программе (и ссылка, см. ниже) сохраняется в /sys/fs/bpf:
/sys/fs/bpf/4026532024_dispatcher
├── link
├── program
└── ...Код пространства пользователя выполняется в течение нескольких секунд за раз и заменяется всякий раз, когда бинарный файл на диске изменяется. Это означает, что пользовательское пространство должно быть способно как-то справиться со "старой" программой BPF в ядре. Самый простой способ добиться этого — сравнить то, что загружено в ядро, с BPF, поставляемым в составе tubectl. Если они не совпадают, мы возвращаем ошибку:
$ sudo tubectl bind foo tcp 127.0.0.1 80
Error: bind: can't open dispatcher: loaded program #158 has differing tag: "938c70b5a8956ff2" doesn't match "e007bfbbf37171f0"tag — это усеченный хэш инструкций, составляющих программу BPF, который ядро делает доступным для каждой загруженной программы:
$ sudo bpftool prog list id 158
158: sk_lookup name dispatcher tag 938c70b5a8956ff2
...Сравнивая этот тег, tubular утверждает, что имеет дело с поддерживаемой версией программы BPF. Конечно, простого возврата ошибки недостаточно. Должен быть способ обновить программу ядра, чтобы вновь стало безопасно вносить изменения.
Именно здесь в игру вступает постоянная ссылка в /sys/fs/bpf. bpf_links используются для прикрепления программ к различным BPF-хукам. "Включение" программы BPF — это двухэтапный процесс: сначала загрузите программу BPF, затем прикрепите ее к хуку с помощью bpf_link. После этого программа начнет работать при следующем выполнении хука. Обновляя ссылку, мы можем изменять программу на лету, атомарным образом.
$ sudo tubectl upgrade
Upgraded dispatcher to 2022.1.0-dev, program ID #159
$ sudo bpftool prog list id 159
159: sk_lookup name dispatcher tag e007bfbbf37171f0
…
$ sudo tubectl bind foo tcp 127.0.0.1 80
bound foo#tcp:[127.0.0.1/32]:80За кадром процедура обновления немного сложнее, поскольку помимо ссылки необходимо обновить упоминание о прикрепленной программе. Мы закрепляем новую программу в /sys/fs/bpf:
/sys/fs/bpf/4026532024_dispatcher
├── link
├── program
├── program-upgrade
└── ...После обновления ссылки мы атомарно переименовываем программу-обновление, чтобы заменить программу. В будущем мы сможем использовать RENAME_EXCHANGE, чтобы сделать обновление еще более безопасным.
Предотвращение повреждения состояния
До сих пор мы полностью игнорировали тот факт, что несколько вызовов tubectl могут одновременно модифицировать состояние в /sys/fs/bpf. Очень сложно рассуждать о том, что произойдет в этом случае, так что лучше всего предотвратить подобное. Общим решением для этого являются рекомендательные блокировки файлов. К сожалению, похоже, что карты BPF не поддерживают блокировку.
$ sudo flock /sys/fs/bpf/4026532024_dispatcher/bindings echo works!
flock: cannot open lock file /sys/fs/bpf/4026532024_dispatcher/bindings: Input/output errorЭто заставило нас немного поломать голову. К счастью, вместо отдельных карт можно собрать общий каталог:
$ sudo flock --exclusive /sys/fs/bpf/foo echo works!
works!Каждый вызов tubectl также инициирует flock(), гарантируя тем самым, что изменения вносит только один процесс.
Заключение
Сегодня tubular уже в продакшн у Cloudflare, упростив развертывание Spectrum, а также нашего авторитетного DNS. Он позволил нам отказаться от ограничений API сокетов BSD. Однако самой важной его особенностью является то, что адреса, по которым доступна служба, можно менять на лету. Фактически, мы создали инструментарий, автоматизирующий этот процесс в нашей глобальной сети. Нужно прослушать еще миллион IP-адресов на тысячах машин? Нет проблем, достаточно лишь выполнить HTTP POST.
Приглашаем всех желающих на открытый урок «Виртуализация: KVM», на котором рассмотрим:
Основные виды технологий виртуализации;
Основные обенности виртуализации ядра линукс;
KVMQEMUУправление гипервизором при помощи libvirt;
Основные моменты создания снапшотов (snapshots);
Аспекты работы с сетью.
Регистрация доступна по ссылке.