Лучше напишите парсер…
Лет десять назад работал в информационном агентстве. В этой сфере менеджменту нужно отслеживать публикации, сделанные в других СМИ на основе подготовленных авторами агентства материалов. Насколько мне известно, запрос на подготовку подобных отчетов существует в PR-агентствах, коммуникационных и digital-агентствах. В организации, на которую работал я, посадили целый отдел сотрудников, которые должны были «пробивать» интересующие статьи с основного сайта организации и составлять .docx отчеты c заголовками статей, а также ссылками на публикации и перепечатки на партнерских площадках (там должна была быть указана и некоторая другая информация, например, дата публикации). У агентства был большой IT-отдел, но почему-то никому не пришло в голову автоматизировать этот процесс. Страшно представить, сколько человеко-часов было потрачено впустую. Я покажу, как можно решить проблему несложным скриптом на PHP, возможно, это кому-то поможет автоматизировать процесс составления отчетов по ссылкам в будущем.
Что нам понадобится?
Обязательно:
1. PHP Word – библиотека для записи данных в документ .docx (Ссылка на документацию).
2. Наличие лимита запросов в api поисковой строки Yandex – Она называется «Яндекс.XML». Если у вас есть домен, то Yandex выделяет вам лимит запросов. Количество доступных скрипту автоматических обращений к поиску зависит от параметров сайта, в интересах которого вы работаете. Если домена нет, api все равно можно воспользоваться. Существует ряд специальных бирж, на которых можно приобрести нужное число запросов, выделенных другим сайтам.

У сайтов с не слишком высокими показателями запросов обычно немного, притом «Yandex» их «размазывает» по всем часам суток с таким расчетом, чтобы вы не могли разом выбрать дневной лимит. Ничего страшного. Ниже я покажу, как можно с помощью метода session_start() и «Планировщика задач» (крона) Open Server за несколько дней собрать в отчет Word нужное количество заголовков и ссылок (лимит обновляется каждые сутки и на следующий день вам снова доступны положенные запросы). Перед использованием, вам придется ввести некоторые данные вашего сайта и настройки в сервисе «Яндекс.XML». Способность после этого посылать скриптом автоматические запросы поисковой системе можно проверить в разделе «Тест».
3. Open Server. Мы будем использовать именно его, потому что работоспособность скрипта на примере Open Server я проверил. Но предположу, что и на других сборках локальных серверов (XAMPP, Denwer) можно реализовать парсер выдачи похожим образом.
4. Факультативно можно подключить через Composer или традиционным способом библиотеки PHP Query и Bootstrap. Факультативно потому, что первую могут заменить и стандартные функции PHP, а вторая поможет дополнить скрипт оформлением, но с практической точки зрения оно не обязательно.
Итак, начнем
1. Запускаем сессию, подключаем библиотеки, проводим парсинг выдачи поисковика
<?php session_start(); ?>
<?php
require_once ('phpQuery-onefile.php');
require_once ('bootstrap.php');
require __DIR__. '/vendor/phpoffice/phpword/src/PhpWord/Style/Language.php';
$url = 'ссылка на карту вашего сайта или другой источник, откуда можно «спарсить» ссылки ';
$file = file_get_contents($url);
preg_match_all('|<li class="wsp-post">(.+)</li>|', $file, $matches);
$tmp = array_slice($matches[0], $_SESSION["time"], -1, true);
$phpWord = new \PhpOffice\PhpWord\PhpWord();
PhpOffice\PhpWord\Settings::setOutputEscapingEnabled(true);
$section = $phpWord->addSection();
$objWriter = \PhpOffice\PhpWord\IOFactory::createWriter($phpWord, 'Word2007');
$hand = fopen('loc.csv', 'a+');
$section->addText('Отчет по публикациям информационного агентства', array('bold' => true, 'size' => 20))Вначале несколькими require_once подключаем Bootstrap и phpQuery. В этом нет ничего сложного, подробнее стоит остановиться на методе session_start(). Сессия позволяет сохранить в переменную прогресс обработки заголовков, после чего повторный запуск можно начать с того, чем вы закончили в прошлый раз. Пока сессию просто нужно создать, а на ее применении мы подробнее остановимся дальше. Сессию необходимо прописать до передачи скриптом любых http-заголовков. Как видно в коде, объявление session_start() предшествует html и объявлению php-кода.
$file = file_get_contents($url);
preg_match_all('|<li class="wsp-post">(.+)</li>|', $file, $matches);Прежде, чем работать с Yandex.XML, нам требуется получить заголовки статей, перепечатки которых нам интересно найти с помощью поиска Yandex. Можно составить обыкновенный список, если он есть. Я просто «выпарсил» веб-страницу с «Картой сайта», на котором изначально вышли интересующие материалы. Затем, мы в цикле будем запрашивать заголовки в поиске и получать выдачу. В нашем примере нужные элементы получаем в переменную $matches с помощью регулярного выражения.
$tmp = array_slice($matches[0], $_SESSION["time"], -1, true);
$phpWord = new \PhpOffice\PhpWord\PhpWord();
Метод array_slice() обрезает массив с заголовками $matches[0] на $_SESSION[“time”] элементов, а в нее мы сохраняем число из счетчика цикла, в котором мы будем запрашивать заголовки в API Яндекса. Второй строчкой кода подключаем библиотеку PHP Word для записи данных в .docx.
PhpOffice\PhpWord\Settings::setOutputEscapingEnabled(true);
$section = $phpWord->addSection();
$objWriter = \PhpOffice\PhpWord\IOFactory::createWriter($phpWord, 'Word2007');
$hand = fopen('loc.csv', 'a+');
$section->addText('Отчет по публикациям информационного агентства', array('bold' => true, 'size' => 20));
Следующий сегмент кода связан с подготовкой .docx файла, в который мы будем сохранять наш отчет. Мы задаем здесь то, что нам нужно выполнить однократно, а не в цикле и то, что нам понадобится для дальнейшей работы. Метод addSection() создает раздел в .docx, куда мы будем записывать «спаршенные» в API заголовки. Переменная $objWriter создает объект, при помощи которого мы будем записывать в файл, а не читать из файла Word. Для записи информации создание этого объекта является обязательным. Далее открываем csv-файл loc.csv. В библиотеке PHP Word нет возможности в цикле записывать новую порцию информации ниже предыдущей. Другими словами, следующая порция данных отчета «затрет» предыдущую. Выйти из этого положения можно, записывая все в csv файл с флагом «a+», помещающим каждый раз «указатель в конец файла». Содержимое csv однократно записывается в .docx, храня все обновления парсинга. Получается, что мы перезаписываем весь файл каждый раз при занесении данных, но файл хранит и всю старую и всю новую информацию, каждый раз у нас свежие данные.
2. Выполнив необходимые подготовительные мероприятия, запускаем в цикле сам парсинг
Однако сначала, в самом конце файла с парсером, перед закрывающим тегом «?>» пропишем следующее:
$_SESSION["time"] = $key;
//session_destroy();Что такое переменная $key? Это ключ в цикле foreach, в которым мы будем попеременно запрашивать у API Яндекс.XML «спаршенные» ранее из «Карты сайта» заголовки. Так как число запросов, которые мы можем сделать ограничено, то внутри цикла мы можем ограничить количество заголовков, которые он должен обработать. Сделать мы это можем очень просто:
if($key % 3 == 1) {
$key += 1;
break;Запросив у API три заголовка, скрипт остановится, предварительно сохранив в сессию значение $key. Далее, раньше цикла при следующем запуске сработает кусок кода, о котором мы уже говорили:
$tmp = array_slice($matches[0], $_SESSION["time"], -1, true);
$phpWord = new \PhpOffice\PhpWord\PhpWord();Он обрежет массив с запрашиваемыми заголовками $tmp на количество уже пройденных итераций при предыдущих запусках в $key. Таким образом, уже записанные в файл Word данные не будут обрабатываться, скрипт начнет работу с новых данных. Итак, сам цикл:
foreach ($tmp as $key => $value) {
$output = 'https://yandex.ru/search/xml?user=&key=&query=' . urlencode($value) . '&lr==ru&sortby=&filter=none&maxpassages=5&groupby=ocs-in-group%3D3';
$result = file_get_contents($output);
$xmlObject = simplexml_load_string($result);
$title = $xml_object->{'response'}->results->grouping->group[0]->doc->title->hlword;
foreach ($title as $word) {
$arr[] = '' . $word . '';
}
$res = implode(" ", $arr);
$arr = [];
for($i = 0; $i<10; $i++) {
$link = $xml_object->{'response'}->results->grouping->group[$i]->doc->url;
$links_by_themes[] = '' . $link . '';
}
array_unshift($links_by_themes, $res);
$forinsertionincsv[] = $links_by_themes;
$links_by_themes = [];
sleep(30);
if($key % 3 == 1) {
$key += 1;
break;
}
}
foreach ($forinsertionincsv as $access => $fields) {
fputcsv($hand, $fields, ";");
}
fclose($hand);
- вставляем заголовки, по которым нужно сформировать отчет .docx в URL запроса к API Яндекс.
foreach ($tmp as $key => $value) {
$output = 'https://yandex.ru/search/xml?user=&key=&query=' . urlencode($value) . '&lr==ru&sortby=&filter=none&maxpassages=5&groupby=ocs-in-group%3D3';
Запрос формируется на сайте Яндекс.XML, его оттуда можно копировать. $tmp – напомню, это массив с заголовками, по которым нужно сформировать отчет, $key – ключ, отсчитывающий пройденные итерации, $value – один заголовок. Как видим, каждый раз новый заголовок попадает в URL.
- получаем xml-выдачу Яндекса по интересующему заголовку и перегоняем ее в объекты simple xml, чтобы из всей выдачи легче получить именно то, что нам нужно, то есть заголовки найденных поиском ссылок и ее url.
$result = file_get_contents($output);
$xml_object = simplexml_load_string($result);
$title = $al->{'response'}->results->grouping->group[0]->doc->title->hlword;
В нижней строчке этого сегмента кода мы как раз и получаем заголовки. В дереве элементов XML Яндекс он хранится в узле «hlword», только в виде ряда элементов, в каждый из которых сохранено по одному слову из заголовка. Чтобы получить все слово. Элементы «hlword» понадобится склеить. За это и отвечает следующая секция кода.
- получаем заголовки выдачи в ответ на переданные заголовки статей.
foreach ($title as $word) {
$arr[] = '' . $sd . '';
}
$res = implode(" ", $arr);
$arr = [];
Результат в нужно формате сохраним в переменную $res, а $arr очистим, чтобы при новой итерации общего большого цикла туда не занеслось старых элементов.
- получаем ссылки, соответствующие заголовкам выдачи.
for($i = 0; $i<10; $i++) {
$link = $al->{'response'}->results->grouping->group[$i]->doc->url;
$links_by_themes[] = '' . $link . '';
}На каждой итерации одна ссылка лежит у нас в массиве $links_by_themes при желании, можно легко увеличить количество собираемых ссылок по каждому заголовку, поскольку на каждой итерации вы получаете всю выдачу по нужной статье.
- соединяем заголовок и ссылку (ссылки) в один массив, чтобы записать их в .csv, откуда потом будем писать их в отчет Word.
array_unshift($links_by_themes, $res);
$forinsertionincsv[] = $links_by_themes;
$links_by_themes = [];
sleep(30);функция sleep с задержкой каждой итерации цикла, перебирающего заголовки статей нужна для того, чтобы API Яндекс.XML не выдал ошибку, слишком частые запросы системой отсекаются.
- тут ничего сложного, просто запись получившихся результатов в файл loc.csv:
foreach ($forinsertionincsv as $access => $fields) {
fputcsv($hand, $fields, ";");
}
fclose($hand);
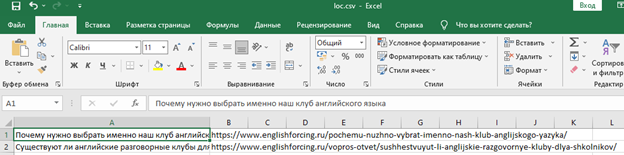
Помните, до цикла мы открывали файл loc.csv для записи с флагом «a+», теперь мы его закрываем.
3. Пишем обновляемую скриптом информацию о выдаче в Word.
С каждым запуском программы, нам нужно однократно перезаписать файл .docx, с отчетом, поскольку, как ни странно, в библиотеке нет функций, позволяющих осуществлять дописывание файла, возможна только перезапись.
WriteInDocx($section, $objWriter);
function WriteInDocx($section, $objWriter)
{
if ($readingcsv = fopen('loc.csv', 'r')) {
while (($data = fgetcsv($readingcsv, 1000, ";")) !== FALSE) {
$section->addText('' . $data[0] . '', array('size' => 19));
}
$objWriter->save('Отчет по публикациям.docx');
fclose($readingcsv);
}
}
Запись текста из массива в библиотеке PHPWord делается с помощью метода addText(), массивом внутри этого метода можно устанавливать стили текста. У если вы хотите записать, что-то в .docx с помощью PHPWord, нужно создать «писателя». То есть, объект Writer, который мы инициировали вначале, еще до создания цикла перебора заголовков.
Вуаля! Вот что у нас получилось:

Итак, наш скрипт каждый новый запуск обрабатывает и записывает в Word несколько новых заголовков, но не будем же мы вручную запускать его каждый час. Нужно просто поставить его на cron.
4. Запускаем скрипт автоматически каждый час
Модуль cron интегрирован в Open Server. В его инфраструктуре он называется «Планировщик заданий» и находится в разделе «Настройки».
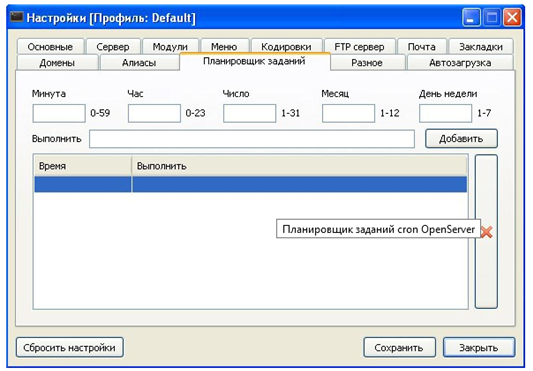
В окне минута можем поставить значение «1****», тогда скрипт будет запускаться каждую первую минуту часа. В строке «Выполнить» следует прописать «explorer http://localhost/par.php».
В моем случае «par.php» - это название файла парсера, лежащего на localhost.
Директива «explorer» будет запускать парсер каждую первую минуту часа новой вкладкой в браузере Explorer, выбрал его, так как вряд ли он вам понадобится, и его смело можно выделить под такую задачу. Не беспокойтесь, достаточно свернуть браузер, и он не будет каждый раз разворачиваться при пуске par.php. Окно будет свернуто, а в браузере прибавится новая вкладка, говорящая о том, что очередная порция в три заголовка была программой обработана. Отчет docx будет увеличиваться. За расходом лимита запросов к Яндекс.XML следите разделе «Лимиты» личного кабинета:
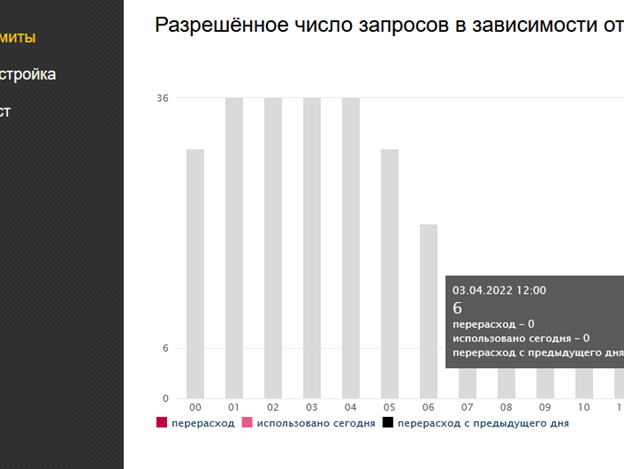
Вот и все, проблема составления медиааналитических отчетов решена без необходимости отвлекать от другой работы тех или иных сотрудников. А как сходные проблемы решали вы? Напишите, пожалуйста, в комментариях.
Валентин Рахманов
Администратор сайта Разговорного клуба английского языка "Инглиш Форсаж"