Поскольку я люблю футбол и получать зачеты в вузе, то настало время объединить это и написать обзор статьи специально для https://github.com/spbu-math-cs/ml-course.
О чем, зачем и почему?
Как известно, к победе в футбольном матче приводит грамотное использование ошибок оппонента и минимизация собственных. Авторы статьи задаются вопросом — как следует себя вести футболисту, находящемуся в критической ситуации, то есть моменте, когда высоки шансы потери мяча или забитого гола. Считается, что в этих эпизодах нельзя отдать пас, можно лишь сфолить, выбить мяч в аут, отправить его в сторону ворот или совершить ошибку. Основной метрикой успеха являются ожидаемые голы (популярная модель xG). Все просто: чем показатель больше, тем лучше.
Если оптимальное решение отличается от того, которое принято футболистом во время матча, то это может говорить о неправильной тактике тренера или техническом браке со стороны игрока, поэтому такая модель может быть крайне полезна для спортивных аналитиков.
Основные идеи
Марковская модель владения мячом
Спектральная кластеризация для моделирования прессинга
CNN-LSTM нейросеть для получения вероятностного распределения на возможных действиях
Новая функция вознаграждения, основанная на оценках нейросети
Нахождение оптимальной стратегии с помощью off-policy Deep RL
Что нового?
Это одна из первых работ, в которой применяется reinforcement learning для анализа футбольного матча и оценки ожидаемых голов. До этого исследователи использовали сверточные нейросети для оценки вероятности возможных пасов, RL для оценки качества позиционирования игроков и ценности каждого действия игрока.
Модель владения
Для подсчета владений авторы опираются на данные InStat (https://instatsport.com/football), определяя владение команды как последовательность действий, начинающуюся осмысленным касанием мяча одним из игроков команды и заканчивающуюся голом, потерей мяча, перехватом, выносом его в аут, словом, приостановкой игры.
На картинке ниже приведено описание модели: владение начинается в стартовой вершине и заканчивается потерей мяча или ударом. Между этим команда сохраняет мяч, а переходы между состояниями это удар, фол, выбивание или ошибка.

Прессинг
Футбольные тренеры выделяют три зоны прессинга: игроков, находящихся в непосредственной близости мяча (intervention zone), игроков, находящихся вне первой зоны, но все еще около мяча (mutual help zone) и оставшихся соперников, не принимающих участия в эпизоде (cooperation zone)
На основе данных можно было бы применить K-means кластеризацию, но этот подход приведет к посредственным результатам, поскольку не учитывает направления движения футболистов и их скорость (опирается лишь на евклидово расстояние между положениями игроков), а зоны получаются приближенно сферическими, что на деле не так. Поэтому было решено использовать спектральную кластеризацию, о которой подробнее написано здесь.
Суть заключается в построении графа, вершинами которого являются 4хмерные точки (координаты игрока, а также горизонтальная и вертикальная составляющая его скорости) и получении центров с помощью применения K-means к собственным векторам лапласиана графа, относящимся к нулевому собственному числу.
Для реализации алгоритма используется K-means из scikit (весь код тут), поэтому смены метрики не происходит. Таким образом, метод потенциально неустойчив к смене единиц измерения, что вызывает вопросы.

Формирование и отбор признаков
Помимо 44 признаков, соответствующих координатам и скоростям игроков, в исследовании учитывают:
расстояние до ворот
угол между штангами (при взгляде с точки владения)
часть тела, которой совершено действие
время до конца тайма
результат действия
команда, владеющая мячом
количество соперников в каждой из зон прессинга
Обучать пробовали тремя способами:
Не используя данные о прессинге, позициях и скорости, максимально сократив размерность вектора признаков
Не используя данные о прессинге
Не используя данные о позициях и скорости
Таким образом, каждое владение длины n может быть описано набором из n пар векторов {признаки действия — one-hot описание действия}.
Нейросеть
Были использованы разные сети, но лучшие результаты показала CNN-LSTM сеть с архитектурой, представленной ниже.

CNN используется для выделения пространственных признаков, а LSTM учитывает предыдущие действия, сохраняя последовательную структуру владения.
Важно отметить, что для достижения фиксированной размерности (длины владения) короткие владения дополнялись нулевыми состояниями, а длинные обрезались. Итоговая длина владения выбрана равной 10.
От себя добавлю, что можно было бы вместо LSTM добавить Attention layer, с помощью которого определить оптимальное ограничение длины, а не брать с потолка.
Reinforcement learning
В качестве функции награды используется концепция ожидаемых голов. Для каждого действия во время владения считается Possession Value(PV), равная вероятности удалить и забить гол в данной ситуации:
Первый множитель мы умеем получать, поскольку это выход нейросеть, а второй считаем при помощи логистической регрессии (решает задачу классификации гол/нет, обучена на 15000 ударов).
В случае, если был нанесен удар, мы получаем награждение PV(X), если удара не последовало, но удалось сохранить владение — разность между PV внешнего и следующего состояния, при потере мяча отнимается 0.1.
Награда каждого владения — сумма наград по всем действиям внутри него. Определим игровой эпизод как непрерывную последовательность владений одной команды. Его награда будет вычисляться как взвешенное среднее наград всех действий каждого владения, подсчет которых был описан выше (с учётом discount factor γ = 0.99).
Обучение проходит с помощью метода policy gradient (градиентный спуск для марковских процессов принятия решений, подробнее тут и в самой статье).
Результаты и выводы
Поскольку провести футбольный матч повторно невозможно, для оценки качества используется off-policy policy evaluation(OPE, подробнее).

Как было сказано выше, обучать пытались на трех наборах признаков. Наиболее успешным оказался тот, в котором не учитывались позиции игроков, но присутствовали данные о прессинге. Это было ожидаемо, поскольку размерность вектора стала значительно меньше, а контекст учитывался.
В сравнении с действиями футболистов во врем матча модель показывает очень хороший результат:
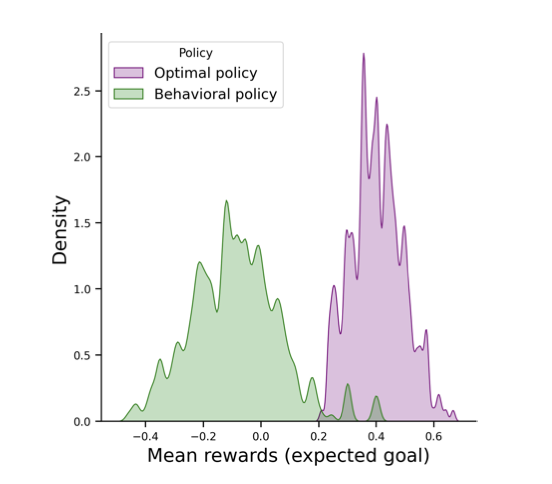
Ожидаемая средняя награда сместилась с -0.1 в настоящем матче до +0.45 у модели, а дисперсия уменьшилась.
На примере из реального матча: игрок теряет мяч и команда пропускает гол, нейросеть советует выбить мяч вместо продолжения контроля.

Таким образом, полученная модель позволяет оценить все ошибки и возможные варианты их исправления, а также улучшить тактику.
Комментарии (6)


Maratinhos
26.05.2022 23:08а что если реальный футбол поменять на виртуальный? применение же более реалистичным будет. наверняка вы знаете что в симуляторах футбольных есть ИИ и он тоже "как-то" работает. а для реального футбола есть еще слишком много всего что аффектит и что не анализируется в статье.

Bolda13
26.05.2022 23:08+1Добрый день статья великолепна. Есть одно но когда игрока прессингуют он не просто мяч выбивает а отдаёт передачу вперёд за спину защитникам. Это пас. А не то что советует нейросеть просто отдать мяч противнику. Да нужно мяч выбивать тогда когда ты находишься спиной к другим воротам а вратарю отдать пас очень опасно. Если я не ошибаюсь есть термин moneyball. Очень похоже что он взят за основу. Не смотря на то что ссылаются авторы совершенно на другие источники. И ещё как по мне одна ошибка. Тут написано что есть 3 вида прессинга. Это не так. Прессинг либо есть, либо это позиционная оборона. Очень надеюсь что я написал вполне грамотно. Если же есть вопросы по деталям и аргументам которые я привёл. То готов привести их. Потому что в своё время я окончил футбольную школу ФШМ. И играл в любительской лиге России и поло любительской футбольной лиги Польше.

app1606 Автор
26.05.2022 23:44Добрый вечер!
Спасибо за развернутый комментарий)
Про 3 вида прессинга согласен, выбрал неточную формулировку: в статье, на которую опираются авторы (тут: https://global-uploads.webflow.com/5f1af76ed86d6771ad48324b/5f6a6920624a527f2e4ac845_SLOAN-Peralta-Final-submission.pdf) выделяют три игровые зоны, с помощью которых оценивается давление противников на игрока с мячом.
К сожалению, в данной модели принятия решений не предусмотрен пас (авторы делают предположение, что в критическом состоянии нельзя отдать передачу, но в будущем собираются добавить и это), поэтому нейросеть выбирает вариант выбивания.
axtrace
интересно. Напоминает Футболоматику