Часть 6 Масштабируемые данные @ Databricks

Это шестой пост из серии статей о том, как выполнять сложную аналитику потоковой передачи с помощью Apache Spark.
Традиционно, когда люди думают о потоковой стриминговой обработке, на ум приходят такие термины, как "real-time", "24/7" или "always on". У вас могут возникнуть ситуации, когда данные поступают только через фиксированные интервалы времени неравномерно. То есть они появляются каждый час или раз в день. Для таких юзкейсов по-прежнему целесообразно выполнять инкрементную обработку этих данных. Однако было бы расточительно поддерживать кластер в рабочем состоянии 24 часа в сутки 7 дней в неделю только для того, чтобы осуществлять небольшой объем работы раз в день.
К счастью, используя новую триггер-фичу Trigger.Once, добавленную в Structured Streaming в версии Spark 2.2, вы получите все преимущества Catalyst Optimizer, инкрементально увеличивающего вашу рабочую нагрузку, а также экономию средств за счет того, что не придется держать незадействованный кластер. В этой заметке мы рассмотрим, как использовать триггеры для достижения обеих целей.
Triggers в Structured Streaming
В Structured Streaming триггеры используются для управления размером микробатча . Как только срабатывает триггер, Spark проверяет, есть ли новые данные. Если они есть, то обрабатывается новая пачка данных. Если новых данных нет, то поток "спит" до следующего триггера.
По умолчанию Structured Streaming работает с минимально возможной задержкой, поэтому следующий триггер срабатывает сразу же после завершения предыдущего. Для случаев использования с более низкими требованиями к задержке Structured Streaming поддерживает триггер ProcessingTime, который срабатывает через заданный пользователем интервал, например, каждую минуту.
Хотя это уже неплохо, но кластер будет по-прежнему продолжать работу 24 часа в сутки 7 дней в неделю. В отличие от этого, триггер RunOnce сработает только один раз, например в 4 часа и обработает накопившиеся данные за полчаса, таким образом это будет всего 3 часа занятых ресурсов
Триггеры определяются когда вы начинаете передачу потоков.

import org.apache.spark.sql.streaming.Trigger
// Load your Streaming DataFrame
val sdf = spark.readStream.format("json").schema(my_schema).load("/in/path")
// Perform transformations and then write…
sdf.writeStream.trigger(Trigger.Once).format("parquet").start("/out/path")Почему потоковая стриминговая обработка и RunOnce лучше Batch
Вы можете спросить, чем это отличается от простого выполнения задания по обработке пакетных файлов (batch job)? Давайте рассмотрим преимущества выполнения Structured Streaming перед батч-джобом.
Bookkeeping
Когда вы запускаете батч-джоб, выполняющий инкрементные обновления, то приходится разбираться с тем, какие из поступающих данных являются новыми, что следует обрабатывать, а что нет. Structured Streaming уже делает все это за вас. При написании обычных приложений для потоковой стриминговой обработки вы должны заботиться только о бизнес-логике, а не о низкоуровневом учете использования ресурсов (bookkeeping).
Атомарность на уровне таблиц
Наиболее важной характеристикой механизма обработки больших данных является то, как он способен переносить сбои и отказы. ETL-джобы могут (на практике часто так и происходит) давать сбои. Если ваш джоб завершился неудачно, то необходимо обеспечить очистку результатов работы, иначе после следующего успешного выполнения задания вы получите дубликаты или мусорные данные.
При использовании Structured Streaming для написания таблицы на основе файла, Structured Streaming коммитит все файлы, созданные джобом, в журнал (лог) после каждого успешного триггера (срабатывания). Когда Spark считывает таблицу, он использует этот лог, чтобы определить, какие файлы являются валидными. Это гарантирует, что мусор, появившийся в результате сбоев, не будет потребляться последующими приложениями.
Стейтфул-операции между запусками
Если ваш пайплайн данных имеет возможность генерировать дубликаты записей, но вам нужна семантика ориентированная на выполнение определенного задания “строго один раз” (exactly once), как вы добиваетесь этого при пакетной обработке? С Structured Streaming это так же просто, как установить водяной знак (watermark) и использовать dropDuplicates(). Настраивая водяной знак достаточной длины, чтобы охватить несколько циклов задания по потоковой стриминговый обработке, вы будете уверены, что не получите дублирующихся данных между запусками.
Экономия затрат
Выполнение заданий по потоковой стриминговой обработке в режиме 24/7 — это затратное испытание. У вас могут быть случаи, когда допустима задержка в несколько часов, либо данные поступают ежечасно или ежедневно. Чтобы получить все преимущества Structured Streaming, описанные выше, может показаться, что вам нужно постоянно поддерживать кластер в рабочем состоянии. Но теперь, с триггером "выполнить один раз" (execute once), вам это не нужно!
В Databricks у нас был двухэтапный пайплайн данных, состоящий из одного инкрементного задания, делающего доступной последнюю информацию, и другого в конце дня, которое обрабатывало данные за все время, выполняло дедупликацию и перезаписывало результаты инкрементного задания. Второе задание использовало бы значительно больше ресурсов, чем первое (4x), и выполнялось бы значительно дольше (3x). Мы смогли избавиться от второго задания во многих наших пайплайнах, что дало 10-кратное сокращение общих затрат. Мы также смогли навести порядок в нашей кодовой базе с помощью нового триггера "выполнить один раз". Такая экономия затрат, безусловно, радует руководителей финансовых и инженерных отделов!
Планирование выполняется c помощью Databricks
Планировщик заданий от Databricks позволяет пользователям составлять расписание производственных заданий при помощи нескольких обычных щелчков мыши. Он идеально подходит для планирования заданий Structured Streaming, которые запускаются с помощью триггера "выполнить один раз".
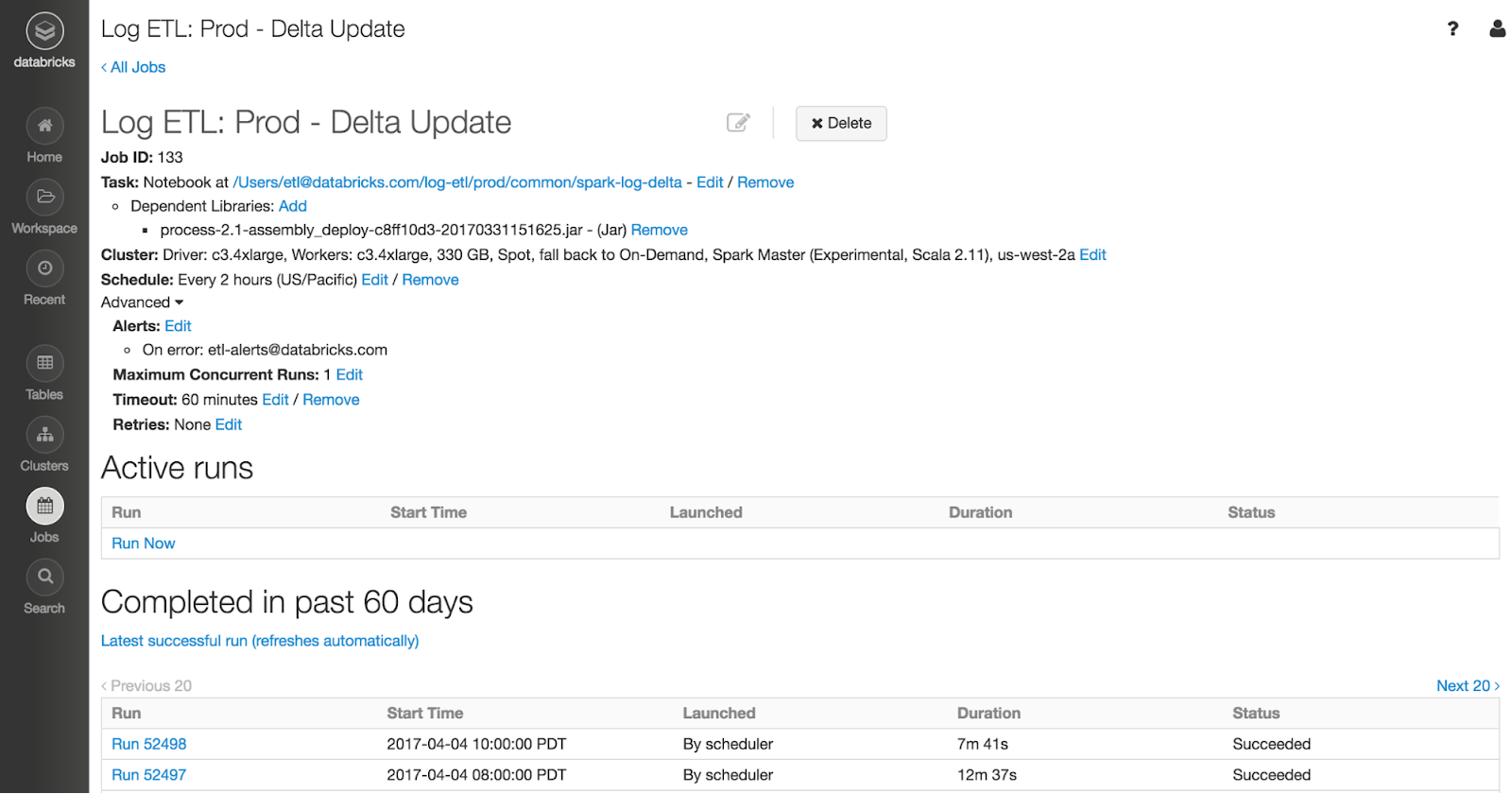
В Databricks мы используем планировщик для запуска всех наших производственных заданий. Как разработчики, мы гарантируем, что бизнес-логика в ETL-джобе хорошо протестирована. Мы загружаем наш код в Databricks в виде библиотеки и настраиваем блокноты для установки конфигураций ETL-джоба, таких как каталог входного файла. Остальное зависит от Databricks, которая управляет кластерами, планирует и выполняет задания, а Structured Streaming выясняет, какие файлы являются новыми, и обрабатывает поступающие данные. Конечным результатом является сквозной - от источника до хранилища данных, не только внутри Spark - ровно один пайплайн данных. Ознакомьтесь с нашей документацией о том, как лучше всего запускать Structured Streaming с заданиями.
Резюме
В этой статье блога мы представили новый триггер "выполнить один раз" (execute once) для Structured Streaming. Хотя execute once напоминает запуск задания по обработке пакетных файлов (batch job), мы обсудили все преимущества его использования по сравнению с батч-джобом, а именно:
Управление всем учетом данных для обработки.
Обеспечение атомарности на уровне таблиц для ETL-джобов в хранилище файлов.
Обеспечение стейтфул-операций между циклами заданий, что позволяет облегчить дедупликацию данных.
Помимо всех этих преимуществ по сравнению с пакетной обработкой, вы также получаете экономию средств благодаря отсутствию неработающего 24/7 кластера при выполнении нерегулярных заданий по потоковой стриминговой обработке. Лучшее из двух областей для пакетной и потоковой стриминговой обработки теперь в вашем распоряжении.
Всех желающих приглашаем на открытое занятие «Дата инженер и Spark в новых реалиях», на котором разберем:
Как изменятся источники и получатели данных, объемы данных, языки для ETL, кластера, облака и IDE.
Как изменится потребность на рынке в дата инженере и к чему нужно быть готовым.
Обсудим open source технологии, примеры миграционных проектов.