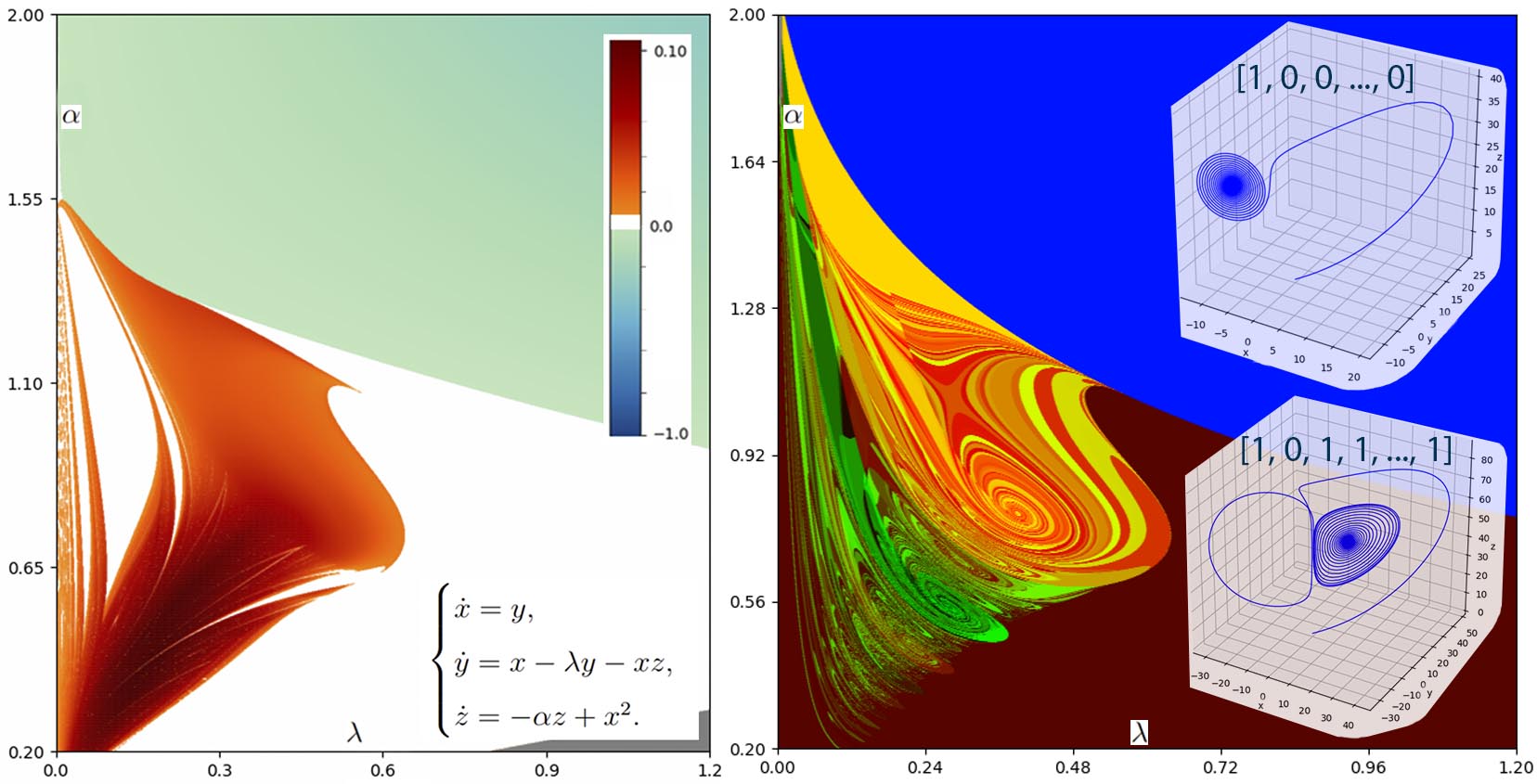
Наш программный комплекс позволяет проводить численные исследования хаотической динамики в системах, задаваемых обыкновенными дифференциальными уравнениями и точечными отображениями, с использованием методов параллельного программирования и мощных вычислительных серверов. Основные инструменты исследования программного комплекса реализуют методы ляпуновского анализа (расчет двухпараметрических диаграмм показателей Ляпунова и минимальных углов между подпространствами сжатия и растяжения объемов) для выявления и исследования хаотической динамики, а также методы символической динамики (диаграммы нидинг-инвариантов) для исследования гомоклинических и гетероклинических бифуркаций.
Вспомогательные модули, такие как модуль визуализации, модуль ввода пользовательских систем реализованы на языке Python, с использованием соответствующих библиотек. Основное вычислительное ядро комплекса (вся математика) реализовано на языке Си++, с использованием CUDA framework для параллельных вычислений. Численные эксперименты мы проводим на сервере, оснащенном двумя 28ми ядерными (56ти поточными) процессорами Intel Xeon Platinum, 2.7 GHz, а также восемью видеокартами Nvidia Tesla V100. На нем же, как правило, происходит и сборка вычислительного ядра комплекса.
В рамках совместного проекта с компанией Intel перед нами стояла задача портирования параллельных вычислений комплекса с технологии CUDA на Intel® oneAPI DPC++. Об Intel® oneAPI DPC++ можно найти довольно много информации в интернете, в том числе, на их официальном сайте, поэтому на этом останавливаться не будем, отметим лишь, что DPC++ включает в себя SYCL, а также расширения, разработанные открытым сообществом. Итак, поехали.
Несмотря на то, что среди нас и не было коллег, кто имел бы опыт работы с DPC++ или SYCL, процесс миграции на универсальную платформу для параллельных вычислений от Intel не оказался для нас трудоемким. А все потому, что Intel предоставляет DPC++ Compatibility Tool, которая, как заявляется, автоматически переводит код проекта CUDA на DPC++. Поэтому все, что нам нужно, это прогнать через данную утилиту наш проект и собрать его. Звучит заманчиво.
Для начала нужно установить необходимое программное окружение. С этим у Intel все в порядке. С официального сайта можно скачать oneAPI Base Toolkit, который уже содержит в себе упомянутую выше DPC++ Compatibility Tool, а еще необходимые для миграции oneAPI DPC++/C++ Compiler, oneAPI DPC++ Library и многое другое. Так как сервер для сборки и запуска нашего комплекса работает под управлением Windows OS (хотя мы используем CMake для сборки проекта), то Intel® oneAPI Base Toolkit for Windows был успешно установлен на сервер. Удобно, что были автоматически установлены плагины для Visual Studio для работы с DPC++. Это, например, позволило создать тестовый проект на DPC++ в Visual Studio «из коробки».
На сайте есть подробный гайд для работы с DPC++ Compatibility Tool для различных платформ, а так же примеры использования утилиты. Есть пример миграции CMake проекта целиком (как раз наш случай), но только для Linux. Для Windows же мигрировать весь проект можно через .vcxproj файл. Кстати, DPC++ Compatibility Tool также встраивается в Visual Studio как плагин и весь процесс можно выполнить с помощью интерфейса Visual Studio, это удобно. Но в нашем случае .vcxproj файла нет, так как мы используем CMake, поэтому пришлось запускать утилиту из командной строки, указывая необходимые аргументы. Из обязательных аргументов: путь до проекта, папки\файлы для миграции и пути для поиска хедер файлов. Строка запуска выглядит примерно так:
>dpct.exe --in-root=path_to_source --process-all --extra-arg="-I path_to_include" --extra-arg="-I additional_path_to_include"«Process-all» здесь означает, что утилита должна проанализировать все файлы в указанной директории, можно задать файлы перечислением. Выглядит опять удобно. Стоит сказать, что первые запуски DPC++ Compatibility Tool для нашего проекта выдавали огромное количество ошибок. Все дело в том, что наш проект обладает довольно большим функционалом и как следствие использует сторонние библиотеки, например библиотеку линейной алгебры. С этим и было связанно большое количество ошибок. Утилита находила ошибки не в «нашем коде» и отказывалась продолжать миграцию. Вероятно, можно было бы настроить исключения через дополнительные аргументы к утилите, но существовал риск, что проблемы на этом могут не закончиться. Еще проект содержит ненужные для миграции модули для нагрузочного и юнит тестирования. Поэтому, для экономии времени было принято решение мигрировать не весь проект целиком, а выделить один инструмент – построение диаграмм показателей Ляпунова – и одну исследуемую модель – система Шимицу-Мориока. Как говорится, начать с малого. К тому же, так проще проверять работу утилиты, запускать, и отлаживать новый код. Был создан новый проект с самой базовой функциональностью без лишних библиотек и модулей. Это не избавило полностью от ошибок миграции, но значительно их сократило, оставались в основном косметические правки. Стоит отметить, что Compatibility Tool довольно информативно делает свою работу. Ошибки и предупреждения довольно информативны, генерируемый код содержит комментарии в местах, где необходимо делать ручные правки. Самое частое предупреждение для кода нашего проекта (да и, наверное, любого проекта на CUDA):
DPCT1003:6: Migrated API does not return error code. (*, 0) is inserted. You may need to rewrite this code.
Это связанно с тем, что функции oneAPI не возвращают коды ошибок, как в случае с CUDA API, а бросают исключения. Но утилита генерирует код-заглушку, который позволяет собрать проект «как есть» и убедиться в его работоспособности, а многочисленные правки оставить на потом. Итак, наш урезанный код проекта был успешно мигрирован, все .cu и .cuh файлы были заменены на .dp.cpp и .dp.hpp с DPC++ кодом внутри, оставалось дело за малым, собрать все это и запустить.
Как я уже писал выше, oneAPI Toolkit при установке компонент встраивает соответствующие плагины в IDE (в нашем случае это Visual Studio), что позволяет оперативно создавать DPC++ проекты из Visual Studio, без необходимости заморачиваться над настройкой окружения для сборки проекта. Поэтому нам показалось, что самый простой способ собрать разрозненные файлы в проект, это создать новый DPC++ проект в VS и добавить туда наши файлы. Интеграцию с CMake решили оставить на потом.
Дальше мы приступили к сборке проекта. Естественно, что с первого раза собрать ничего не получилось (хотя не скрою, была надежда), пришлось и с этим немного повозиться. Сразу стало понятно, что утилита для миграции отработала не идеально, почему-то были пропущены файлы c расширением .cpp, но в которых был CUDA код. Пришлось данные файлы отдельно прогонять через утилиту еще раз. Но спишем это на то, что мы просто не умеем правильно пользоваться утилитой и не указали нужные аргументы. Со второй попытки проект был полностью мигрирован на oneAPI DPC++. По крайней мере, компилятор уже не ругался на незнакомый ему CUDA код. Но ошибки при сборке все еще оставались. В основном надо было подкрутить немного настройки проекта, связанные с указанием путей до нужных хедеров.
Но была и одна любопытная вещь, на которой стоит заострить внимание. Компилятор ругался на использование указателей на функции в нашем коде. Мы их используем, для динамического добавления объектов в фабрику. Но SYCL работать с ними не умеет. Переписывать код не очень хотелось, и тут мы вспомнили, что, когда смотрели информацию про oneAPI DPC++ и SYCL, заметили, что одним из достоинств oneAPI DPC++ было то, что там реализована поддержка указателей на функции. Google помог найти правильный аргумент для компилятора, чтобы активировать данную фичу - -fsycl-enable-function-pointers. Наши старания были вознаграждены, проект успешно собрался и запустился. Дальше замеры скорости расчетов на oneAPI DPC++ и сравнение их с CUDA. Intel заявляет, что может получиться небольшой выигрыш в скорости, посмотрим как получится на самом деле.
Кураторы проекта:
Казаков Алексей Олегович, доктор физико-математических наук
Овчинников Артем Александрович
Участники проекта:
Бобровский Андрей Александрович, магистратура ФМ, 1й курс
Бурдыгина Татьяна Кирилловна, магистратура ФМ, 2й курс
Кайнов Максим Николаевич, аспирантура ФМ, 1й курс
Каратецкая Ефросиния Юрьевна, аспирантура ФМ, 1й курс
Корякин Владислав Андреевич, бакалавриат ФМ, 3й курс
Самылина Евгения Александровна, аспирантура ФМ, 3й курс
Солдаткин Константин Алексеевич, бакалавриат, ФМ, 3й курс
Чигарев Владимир Геннадьевич, аспирантура ФМ, 3й курс
Шыхмамедов Айкан Ильгар Оглы, магистратура ФМ, 2й курс
belch84
Очень давно занимаюсь развитием приложения для численного исследования динамических систем. Не пытался реализовать параллельные вычисления, поэтому хотел бы оценить, насколько медленно работает моё приложение. Вот уравнения для модели Аизава
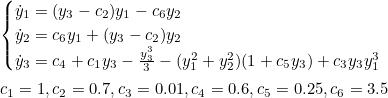
 ,
,

Это — изображение фазовой траектории системы
а это — график зависимости показателей Ляпунова системы от параметра c3, меняющегося от 0.02 до 0.1
Построение последнего графика заняло примерно 7 мин 20 сек на ноутбуке с процессором Intel® Core(TM) i7-4810MQ CPU @ 2.80GHz и памятью 16,0 ГБ. Интересно, сколько такое построение займет у вашей системы, и вообще, правильный ли у меня получился график?
Un_ka
Какой тип памяти и сколько памяти потребляла программа во время работы?
belch84