Вступление
Когда я только начинал свой путь в информационную безопасность, мне нравилось тестировать веб-приложения на проникновение. В основном это были инъекционные атаки, поэтому возникла идея создать свой собственный межсетевой экран, защищающий от инъекционных атак, но с современным подходом, используя машинное обучение. Изучая вопрос о построении межсетевого экрана, я пришел к следующим выводам:
-
Межсетевые экраны прошлого поколения:
Подход черного списка требовал ручного составления правил, которые в итоге обходились злоумышленниками. Происходило это из-за того, что для составления правил обнаружения атак использовалась регулярная грамматика (тип 3 по иерархии грамматик Хомского) [1].
Подход белого списка не может охватывать все вариации вводимых обычными пользователями данных.
-
Межсетевые экраны нового поколения на основе машинного обучения:
Нет необходимости создавать правила детектирования вручную.
Сочетание белых и черных списков одновременно.
Поэтому имеет смысл использовать машинное обучение, потому как таким образом возможно совершить переход от регулярных грамматик к контекстно-зависимым (тип 1 по иерархии грамматик Хомского), при этом избегая трудоёмкого процесса составления правил детектирования вручную [1].
Я решил рассмотреть случай (кейс), где взаимодействие с компонентами микросервиса происходит без использования API-шлюза. Этот случай описывается в свободно распространяемой книге от Майкрософт “.NET Microservices Architecture for Containerized .NET Applications” [2]. Такое прямое клиент-серверное взаимодействие годится для небольшого количества компонентов микросервиса. Моя задумка предполагает RESTful взаимодействие.
Способ внедрения межсетевого экрана
Далее я задумался над способом внедрения своего межсетевого экрана. Существует несколько способов:
Облачные решения третьей стороны (Cloudflare, Imperva) могут оказаться ненадежными, так как эта третья сторона будет обладать TLS-сертификатом и секретным ключом. Таким образом, их межсетевой экран будет расшифровывать и зашифровывать трафик, что приводит к риску конфиденциальности и целостности данных, так как в компании может работать внутренний злоумышленник, сливающий данные.
Аппаратный межсетевой экран требует наличие или аренды физического оборудования.
Интеграция в ПО микросервисов.
Я остановился на последнем варианте. Для того чтобы внедрить межсетевой экран, я воспользовался декоратором, шаблоном проектирования, который добавляет дополнительную функциональность (в моем случае это проверка трафика), которая будет выполняться до оконечной функции микросервиса (рисунок 1).

На рисунке 2 представлена схема, где создаваемый межсетевой экран работает как частичный прокси (half-proxy). Такой способ взаимодействия позволяет провести оптимизацию DSR (Direct Server Return). Это полезно, в случае если с сервера возвращается большой ответ. Таким образом, создаваемый межсетевой экран работает на прикладном уровне модели OSI (L7) для проверки параметров методов HTTP(S). При этом, если от клиента приходит безопасный трафик, то возврат по DSR, иначе пакеты отбрасываются.

Формирование датасетов
Далее я сформировал датасеты, ниже представлен список всех классов, которые может предсказывать модель.
Классические SQL-инъекции (in-band): основанные на ошибке и с использованием union.
Слепые SQL-инъекции (blind): основанные на времени и на основе логического вывода.
Обфусцированные SQL-инъекции (blacklist).
Межсайтовый скриптинг (XSS).
Атака обхода каталога (directory traversal).
Инъекция шаблона на стороне сервера (SSTI).
Безопасный трафик (benign).
В таблице ниже представлено описание датасетов, при этом обучающий датасет был разделен в пропорции 80:20.
Наименование датасета |
Количество элементов в датасете |
Обучение |
400 |
Валидация |
100 |
Тестирование |
500 |
Размер выборок – это 64 элемента формального языка, близкого к естественному (NL). Здесь нужно уточнить, что, по сути, из выборки создаётся формальный язык, близкий к естественному, но при этом методы NLP всё еще применимы.
Реализация модели
Последовательная (tf.keras.Sequential) модель реализована при помощи Python 3, Tensorflow 2 и Keras API. Она представлена на рисунке 3. Обучению подлежат только слои, выделенные пунктирной линией.

Ниже представлено краткое описание:
Слой текстовой векторизации (TextVectorization) нормализует входные данные (декодирует полезную нагрузку, добивает нулями вектора до длины 250) и создает словарь выборки.
Слой вложения слов (Embedding) создаёт плотные вектора и тензор становится трёхмерным.
Слой свёртки (Conv1D) хоть и предназначается для классификации изображений, но я использовал его немного иначе: вместо 4 каналов RGBA, я использовал каналы, полученные от вложения слов, то есть 64 канала. По ним и проходит окно свёртки.
Слой субдискретизации (GlobalMaxPooling1D) уменьшает размерность трехмерного тензора до двумерного, путем поиска максимального элемента во второй оси тензора (в Tensorflow эта ось именуется timesteps [3]).
Полносвязный слой (Dense) умножает входную матрицу на матрицу размером 64x7.
Слой активации производит окончательное предсказание одной из 7 меток класса.
Как говорилось в первом пункте, в данной реализации пришлось создать свой собственный словарь формального языка для создания контекстно-зависимой грамматики, так как готовые подходы, например, word2vec реализуют контекстно-свободную грамматику (контекстно-независимую), а BERT хоть и учитывает контекст, но тяжеловесна и нужна для обработки естественных языков. Более того, я специально вынес слой активации отдельно от полносвязного слоя (Dense). Это нужно по следующим причинам:
График сигмоиды “прижимается” к асимптотам y=1 и y=0 для значений x>2 и x<−2, что позволяет делать четкие предсказания классов. Если бы она была в Dense слое, то нейрон смещения смещал бы функцию активации, а мы этого не хотим.
Вынос функции активации решает и проблему исчезающего градиента: значения производной от сигмоиды находятся ближе к нулю. А по мере обратного распространения ошибки производные умножаются. Умножение малых чисел даёт ещё более малое значение, что останавливает обучение модели.
Оценка точности модели
Далее я оценивал точность разработанной модели. На рисунке 4 представлена матрица ошибок, полученная с помощью mlxtend:
По диагонали представлены TP значения.
В классе “Инъекция шаблона на стороне сервера” (SSTI) произошла FN ошибка, 10% элементов Инъекции на стороне сервера отнесено в Межсайтовый скриптинг.
Целочисленное значение в ячейке – это количество элементов рассматриваемого класса.
Сумма всех целочисленных значений ячеек равна 64.

При этом я использую в качестве метрик микро-усреднение и макро-усреднение (таблица представлена ниже).
Метрика |
Значение |
Micro Precision (Микро Точность) |
0,98 |
Micro Recall (Микро Полнота) |
0,98 |
Micro F1 (Микро F1-мера) |
0,98 |
Macro Precision (Макро Точность) |
0,99 |
Macro Recall (Макро Полнота) |
0,99 |
Macro F1 (Макро F1-мера) |
0,99 |
При этом микро-усреднение описывается следующим образом:
Характеристики TP, FP, FN, TN усредняются по количеству классов, а затем они подставляются в итоговую двухклассовую метрику, например полнота или F-мера.
А макро-усреднение описывается вот так:
Суммируется метрика каждого класса, например полнота, а затем результат усредняется по количеству классов.
Таким образом, разница лишь в том, что в микро-усреднении класс с маленькой мощностью почти не влияет на результат, так как его вклад в средние характеристик TP, FP, FN, TN будет незначителен, а в макро-усреднении каждый класс вносит равный вклад в итоговую метрику, так как используются величины не чувствительные к соотношению размеров классов. Помимо того, что метрика имеет высокие показатели, можно сделать вывод, что используется хорошее перемешивание, так как микро и макро метрики почти сравнялись.
Апробация модели
А после этого я провел апробацию модели на примере микросервиса, написанного на Flask:
Уязвимое к межсайтовому скриптингу приложение выложено на облачный веб-сервер Heroku.
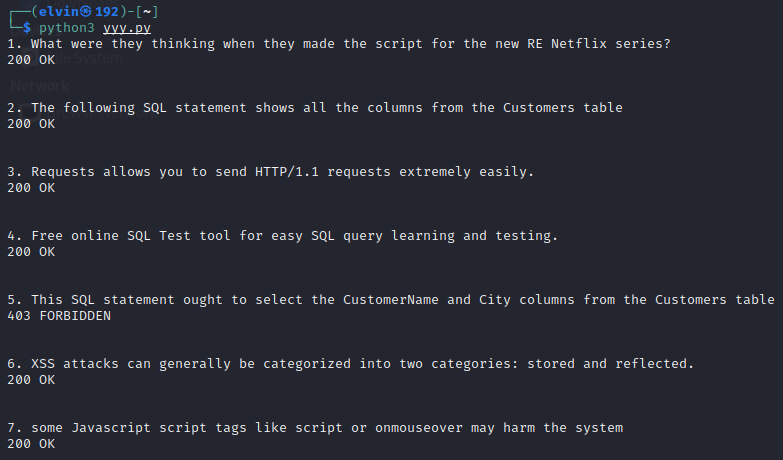
Фаззинг параметра comment методом POST не увенчался успехом, так как с помощью декоратора подключен мой МЭ.
В итоге фаззер-грубой силы пришел к выводу, что параметр неуязвим (рисунок 5).

При этом в логах отображается обнаружение атаки (рисунок 6).

Аналогичное произошло и с SQLmap: фаззер пришел к выводу, что параметр неуязвим, хотя на самом деле к уязвимому приложению был подключен мой межсетевой экран через декоратор.

Вывод
Таким образом, мне удалось создать межсетевой экран с использованием свёрточных нейронных сетей для защиты от инъекционных атак, а также доказать применимость NLP методов для формального языка выборки. Более того, использование машинного обучения нивелирует трудоёмкий процесс составления правил детектирования инъекционных атак. В дальнейшем можно добавить защиту от L7 DDoS, добавить поддержку GraphQL и размещать модель машинного обучения в API-шлюзе.
Список использованных источников
Карпов Ю. Г. Основы построения компиляторов //Учебное пособие. Л.: Изд-во ЛПИ. – 1982. – 28 с.
de la Torre C., Wagner B., Rousos M. .NET microservices: Architecture for containerized .NET applications //Microsoft Developer Division. – 2020. – 40 c.
Введение в тензоры // [Руководство Tensorflow, 2020]. – URL: https://www.tensorflow.org/guide/tensor.
Комментарии (15)

fisher85
16.07.2022 07:20+4Есть вопросы по машинному обучению:
Что есть входные данные для модели. Что за 64 элемента, как они выглядят? Пример бы помог разобраться.
Как собирали датасет? С помощью BruteXSS и SQLmap? И можно посмотреть на датасет?
В матрице ошибок 64 элемента, а в таблице с количеством элементов тестовой выборки - 500. Почему так?
У вас одна единственная ошибка в матрице ошибок, метрики близки к единице. Надо покупать вашу модель. А вы сами знаете слабые места модели? Как поведёт себя в отношении других инструментов атак, какова обобщающая способность?
Будет здорово, если откроете код. Jupyter-блокнот с комментариями и ссылка на него в Google Colab. Это снимет многие вопросы и даст обратную связь по существу.
По оформлению и пояснениям выглядит так, что вы готовы к научной публикации. Идея на перспективу: найти подходящий публичный датасет, повторить исследование на нём, опубликовать статью на paperswithcode и проверить модель в честном, открытом, публичном бою.
Статья отличная, ставлю плюс. Приятно видеть такие исследования в песочнице, успехов!

Elvin_GSNV Автор
17.07.2022 01:00-
Входные данные при обучении, валидации или тестировании - это выборка размером в 64 элемента из пулов размера 400, 100 и 500 соответственно. Но при экспорте модели может подаваться на вход как 1 элемент, так и несколько сразу. По поводу примеров полезных нагрузок злоумышленника: здесь на хабре проходит авто-санация (sanitizing) вводимого, так что в полезную нагрузку атак не вставить))). Поэтому пока выложу скрин с примером

Пример полезных нагрузок Я искал в репозиториях kaggle и гитхабов примеры полезных нагрузок, дополнял их примерами реальных атак с разных форумов и использовал burp cheat sheet xss и SQLmap xml, чтобы увидеть каркас запросов в разных субд. По поводу шаблонизаторов - они все похожи, что Jinja2,FreeMarker, Smarty, Twig, поэтому модель можно обучить одним или примесью нескольких из них
В матрице ошибок 64 элемента, так как это выборка случайных 64 полезных нагрузок из пула, размером в 500 элементов. Естественно seed установлен так, чтобы выборка всегда была разной.
Да, слабые места, конечно, есть. Слой Текстовой Векторизации перегружен callback-функцией, которая реализует обработку входных данных. Злоумышленник может использовать различные кодировки, чтобы остаться незамеченным. Поэтому в callback функции надо получше отлавливать такие моменты, я просто с кодировками плохо знаком, а то tplmap иногда западает
По поводу исходников и датасетов: я выложу их, ток немного причешу код, так как он не очень pythonic way получился, я в основном системным программированием занимался на C++. Это моя вторая попытка писать нейронки. По поводу paperswithcode спасибо за наводку, это что-то типа Hugging face?
-


zloddey
16.07.2022 09:24+2Мило. А как эта штука ведёт себя не на инъекциях, а на обычных, валидных комментариях? Каков процент ложноположительной реакции?
Elvin_GSNV Автор
17.07.2022 17:31+1Редко случается FP ошибка и то только если в тексте специально указывать ключевые слова, очень близкие по контексту к вероятной атаке


tsvetkovpa
16.07.2022 11:04А какой перформанс? Требуется ли GPU?
Elvin_GSNV Автор
17.07.2022 01:06Не требуется, всё обучалось на процессоре Intel Core i7 2.5GHz. Видеокарты у меня нет
Noktis
17.07.2022 17:31Статья неплохая, автору плюсик в карму за то, что не побоялся написать статью и своем исследовании.
НО есть вопросы к реализации и данным:
1) Как уже спросили выше, что есть входные данные? Это http-запрос или что-то иное? Из каких источников собирался датасет?
2) Какое у вас соотношение классов в выборках для модели? В реальном мире на 99.(9)% легитимного трафика будет приходиться 0.(1)% вредоносного трафика, то есть задача МО переходит из классификации в поиск аномалий, поэтому стандартные методы классификации могут давать больше FP сработок.
Во всяком случае было интересно увидеть нестандартный подход, к стандартной проблеме)
Elvin_GSNV Автор
17.07.2022 17:49Входные данные - это параметры методов HTTP, которые лексикографически проверяются моделью. Датасет собирался из открытых источников
Я старался сделать равномерное перемешивание, чтобы метрики не перекосило. А вот с поисками аномалий я не знаком, поэтому спасибо за наводку - ознакомлюсь

qid00000000
18.07.2022 10:18Хорошее исследование вопроса! Понятно даже мало посвященным.
Но, после прочтения статьи, возник вопрос: а сколько такая реализация даёт нагрузки? Насколько она отказоустойчива?
Например: злоумышленник начинает вести ддос атаку с целью вывести из строя микросервис, параллельно с этим делая sql инъекции.
Как на это отреагирует система?
Возможно, у меня не хватает в данной теме понимания, поэтому было бы здорово, если бы вы осветили данный вопрос.
ZlodeiBaal
А зачем вам сверточная сеть? Сверточные сети для объектов обладающих локальной корреляцией (изображение/звук/и.т.д.). А вы на её вход подаете какой-то ембеддинг (если я правильно понял).
Скорее всего если вы будете использовать однослойную полносвязную сеть результат будет не хуже.
FruTb
Наверное это была попытка выразить мысль что важна последовательность токенов чтобы произвести атаку. Наверное тут правильнее это было в GRU/LSTM обернуть что-бы иметь ограниченный контекст по токенам.
Elvin_GSNV Автор
Я увидел в статье Яна Лекуна (https://arxiv.org/pdf/1502.01710.pdf), что он применяет свёрточную нейросеть для распознавания естественных языков на уровне символов, поэтому подумал, что для формальной выборки свёртки тоже могут подойти. А в статье Юна Кима (https://arxiv.org/pdf/1408.5882.pdf) увидел многоканальную CNN для классификации предложений. Более того, Джейсон Браунли тоже использовал CNN для классификации текстов (https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/). Поэтому выбор пал на CNN
ZlodeiBaal
В статье идет сравнение с устаревшими на тот момент подходами. Если вы откроете бенчмарки, то найдете что в те годы были подходы которые выдавали точность не хуже.
В статье был явный акцент на то что «Вот так они тоже умеют». И да, на тот момент это был прикольный факт.
По современным меркам у этих подходов вообще все не очень.
Ну и «machinelearningmastery» это неплохой список примеров. Но не рефенс того «как надо делать продуктовую систему».
А вообще, на будущее, в современном мире ML любая статья старше двух лет должны вызывать подозрения. Писал как-то об этом.
Кроме того, ваше явное отличие в структуре данных от регулярного языка. И что у вас оно применим — надо доказывать.
Я бы начал с более простых/более подходящих сетей;)
lolikandr
Так и вашей статье уже больше 2 лет, пора обновить.
AnikinNN
Сверточные нейросети действительно применяются для пространственных данных, таких как картинки и звук. Если посмотреть на классы в датасете, то можно понять что здесь объектами будут некие тексты или же сообщения. Положение слов в тексте важно для правильного понимания смысла сообщения, поэтому применение свертки оправдано.
Но есть нюанс: окно свертки "видит" только часть текста. В качестве решения можно добавить какие-нибудь слои, которые будут подсказывать нейросети на какое место текста сейчас "смотрит" окно. В данном случае Embedding добавляет к токенам слов гармонический сигнал, который вычисляется из положения слова в сообщении.
Если я не прав, то автор меня, надеюсь, поправит