
Сравнение производительности Rust, Delphi и Lazarus (а также Java и Python)
Давно хотел познакомиться с Rust. Язык с экосистемой сборки из коробки, компилятор в машинный код, но самое главное — автоматическое управление памятью, но без сборщика мусора. С учетом того, что управление памятью обещается как zero-cost в runtime — просто сказка! По ходу изучения и возник вопрос – а насколько код Rust быстрее/медленнее компилятора в машинный код давно известного, например, Delphi?
О тесте
Для ответа на вопрос были написаны два простых теста: "обход конем доски" (в основном работа с памятью) и "поиск простых чисел" (в основном целочисленная математика). Ну и раз пошло такое дело, то почему бы не вовлечь в соревнования языки из другой "весовой категории" — чисто для сравнения и забавы. Так, в качестве специально приглашенных гостей, в забеге стали участвовать Java (компилируемый в байт-код) и Python (чистый интерпретатор). Си к соревнованию допущен не был по причине моего слабого знания оного (кто напишет свою реализацию тестов — добро пожаловать, включу в статью).
Алгоритмы сделаны по-простому, главное, чтобы создавалась нужная нагрузка. Для обхода конем доски выбрана доска 4х7, это разумная величина, чтобы тест не проходил слишком быстро, но и не закончился лишь после угасания Солнца. Простые числа ищем начиная со 100 млн, иначе слишком быстро.
Обход конем доски, реализация на java.
/**
* Store for statistic
*/
static class State {
int path_count_total = 0;
int path_count_ok = 0;
}
/**
* Calc and print all full knight's tours over specified board
*
* @param size_x board size x
* @param size_y board size y
* @param x0 tour start cell x
* @param y0 tour start cell y
*/
static void calc_horse(int size_x, int size_y, int x0, int y0) {
System.out.println(String.format("Hello, horse, board %sx%s", size_x, +size_y));
int[][] grid = new int[size_y][size_x];
State state = new State();
Date time_0 = new Date();
step_horce(1, state, x0, y0, grid);
Date time_1 = new Date();
System.out.println(String.format("Board %sx%s, full path count: %s, total path count: %s", size_x, size_y, state.path_count_ok, state.path_count_total));
double duration_sec = (time_1.getTime() - time_0.getTime()) / 1000.0;
System.out.println("duration: " + duration_sec + " sec");
}
private static void step_horce(int step_no, State state, int x0, int y0, int[][] position) {
// ---------------------
// Make my step
position[y0][x0] = step_no;
// ---------------------
// Try to do next 8 steps
int size_y = position.length;
int size_x = position[0].length;
int board_size = size_x * size_y;
int[][] step_diffs = {{1, -2}, {2, -1}, {2, 1}, {1, 2}, {-1, 2}, {-2, 1}, {-2, -1}, {-1, -2}};
int steps_done = 0;
for (int s = 0; s < 8; s++) {
int[] step_diff = step_diffs[s];
int x1 = x0 + step_diff[0];
int y1 = y0 + step_diff[1];
if (x1 < 0 || x1 >= size_x) {
continue;
}
if (y1 < 0 || y1 >= size_y) {
continue;
}
if (position[y1][x1] != 0) {
continue;
}
step_horce(step_no + 1, state, x1, y1, position);
steps_done = steps_done + 1;
}
// ---------------------
// Whe have no more cell to step?
if (steps_done == 0) {
state.path_count_total = state.path_count_total + 1;
}
if (steps_done == 0 && step_no == board_size) {
state.path_count_ok = state.path_count_ok + 1;
System.out.println(String.format("Full path count: %s/%s", state.path_count_ok, state.path_count_total));
print_board(position);
System.out.println();
}
// ---------------------
// Make my step back
position[y0][x0] = 0;
}Поиск простых чисел, реализация на java.
public static void print_primes(int start_from, int count) {
System.out.println("Hello, print_primes!");
int n = start_from;
while (count > 0) {
Date time_0 = new Date();
boolean is_prime = is_prime_number(n);
Date time_1 = new Date();
if (is_prime) {
long duration = (time_1.getTime() - time_0.getTime());
System.out.println(n + ", " + duration + " msec");
count = count - 1;
}
n = n + 1;
}
}
public static boolean is_prime_number(int number) {
int i = 2;
while (i < number) {
if (number % i == 0) {
return false;
}
i = i + 1;
}
return true;
}На всех языках алгоритм одинаковый. Полный комплект тестов выложен на GitHub.
Ожидания
Мои ожидания были такими: первое-второе места разделят Delphi/Lazarus и Rust, с разницей плюс-минус 50% — машинный код он и в Африке машинный код.
С заметным отставанием, от двух раз и более — Java. Все-таки байт-код это дополнительный уровень не бесплатной абстракции.
Ну и в хвосте, задыхающийся и вспотевший, с отставанием в десяток и более раз будет Python.
Тестовая машина
Windows 10
i5-3470, 3.2 ГГц
ОЗУ 8 ГБ
По наблюдениям - каждый тест нагружает одно ядро четырехъядерного процессора (так и должно быть). Сборщику мусора, судя по всему, не приходится срабатывать, т.к. память выделяется небольшая.
Загрузка процессора.


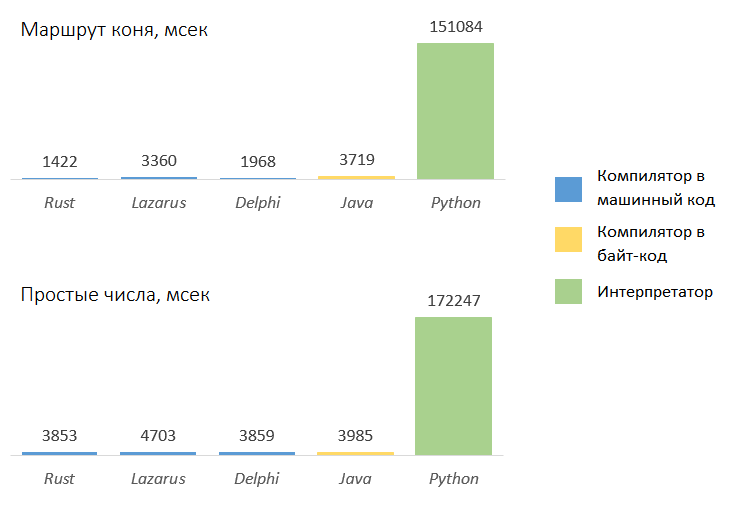
Итог испытаний
Результат лично для меня оказался неожиданным. Вот вы какого результата ожидали бы?

Python не разочаровал, стабильность результата — признак профессионала :-).
Код Rust оказался медленнее на 50%-400%, чем Delphi/Lazarus, что несколько разочаровывает, хотя и в пределах ожиданий.
А вот Java сильно удивила. За много лет работы с ней не доводилось вот так, напрямую, замерять производительность и её скорость оказалась приятным сюрпризом. Нет, мы знаем — JIT творит чудеса и все такое, но, чтобы на равных с машинным кодом...
Итого
Выводы для себя я сделал следующие:
Java рулит;
Если на Java есть кусок тормозного кода, который хочется переписать на чем-нибудь компилируемом — не следует ожидать кратного прироста скорости. Проблема, скорее всего, в другом месте, а не в "тормознутости" Java;
Если хочется чего-нибудь компилируемого и быстрого, но C++ пугает, то использовать Rust вместо Си пока рано. Нужен язык с компилятором и быстрым кодом - это пока все-таки Си или Free Pascal.
UPD 1:
В комментариях справедливо ткнули носом в то, что мои тесты на Rust собраны в отладочном режиме. Каюсь, это огромное упущение. В оправдание скажу, что в языках, с которыми работал до этого (Delphi, Java и Python), скорость "релизной" и "отладочной" версий хоть и различается, но не так драматично. Учет замечания радикально меняет вывод об "отставании" Rust. Собрав тесты в релизе (Rust, Delphi, Lazarus) получаем результат:
Оптимизированный код Rust оказался на 20%-200%, быстрее чем Delphi/Lazarus, что приятно и в пределах ожиданий.
Итого (исправленное):
Java рулит;
Если на Java есть кусок тормозного кода, который хочется переписать на чем-нибудь компилируемом — не следует ожидать кратного прироста скорости. Проблема, скорее всего, в другом месте, а не в "тормознутости" Java;
Если хочется чего-нибудь компилируемого и быстрого, но C++ пугает, то Rust вместо Си — прекрасная альтернатива.
UPD 2:
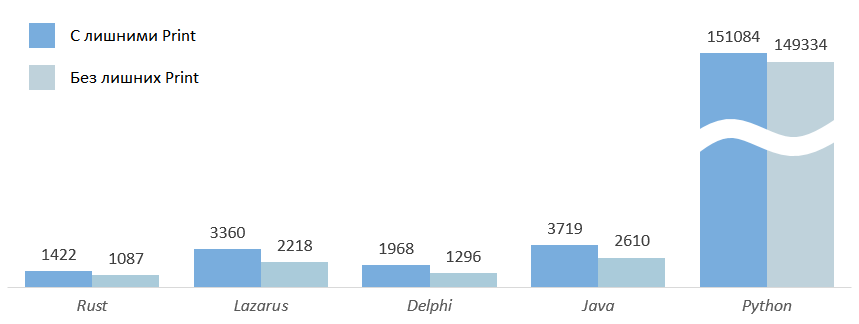
В комментариях указали на влияние лишнего лишнего консольного вывода на результаты. Да, действительно, он заметно влияет на время выполнения, особенно на "быстрые" языки. Согласен, его нужно было сразу убрать, однако лишний вывод влияет одинаково на всех и мало влияет на сравнительные результаты.
Влияние лишнего вывода.
Комментарии (42)

SharplEr
24.07.2022 12:11+69Каждый раз когда вижу такие статьи на хабре понимаю, что надо всё таки дописать мою статью "Почему ваш кросс-языковой бенчмарк вам врёт". У меня там отличный пример есть, где можно на двух "совершенно одинаковых алгоритмах" получить Java сколь угодно быстрее чем Rust :)
Фантастично то, что люди получив измерения вообще не пытаются даже понять почему они такие числа получили. Вот у человека получается что Rust в 10 раз медленнее, чем Java. И ничего в голове не щелкает, человек публикует статью. Насколько странным должен получиться результат, что бы человек начал искать проблему в своем тесте? В 100 раз должен Rust проиграть Java, в 1000? :) А если бы Java на числодробилки бы оказалась медленнее, там наверное пока в миллион раз её не обгонят никто даже и не почешется, что делает что-то не так :)

Armmaster
24.07.2022 12:14+19Любые измерения производительности кода, где используются компиляторы, должны обязательно идти с указанием версий данных компиляторов и опций, с которыми вы собирали код. В случае Java и Python это должны быть версии JVM и Python. Без вышеуказанной информации все полученные цифры могут смело идти в мусорку.

Gordon01
24.07.2022 14:31+8Да они есть в репозитории, но только не смейтесь, там реально отладочные версии тестировали:
https://github.com/SazonovDenis/test-speed/blob/master/make.bat#L13

cepera_ang
24.07.2022 12:15+6Ах да, ещё попробуйте собрать в релиз-режиме, с включенными оптимизациями :)
$rust main_horse.rs && ./main_horse > horse.txt && tail -n 1 horse.txt ==> horse.txt <== Attempts: 3, duration: Some(50.40234s) $rust -O main_horse.rs && ./main_horse > horse.txt && tail -n 1 horse.txt ==> horse.txt <== Attempts: 3, duration: Some(1.398912484s) $rust -C opt-level=3 main_horse.rs && ./main_horse > horse.txt && tail -n 1 horse.txt ==> horse.txt <== Attempts: 3, duration: Some(1.339823275s)C праймами не сильно хуже:
rustc main_primes.rs && ./main_primes 3 5 > primes.txt && tail -n1 primes.txt Attempts: 3x5, duration: Some(5.63107671s) ✗ rustc -C opt-level=2 main_primes.rs&& ./main_primes 3 5 > primes.txt && tail -n1 primes.txt Attempts: 3x5, duration: Some(3.762612137s)Те самые 2х и потерялись. Остальные для сравнения даже лениво запускать.
cepera_ang
24.07.2022 12:30+4Ладно, запустил ещё джаву:
✗ java Horse 3 4 7 > horse.txt && tail -n 1 horse.txt Attempts: 3, duration: 3.557 sec ✗ java Primes 3 5 > prime.txt && tail -n 1 prime.txt Attempts: 3, duration: 3.858 secJIT молодец, но в том, что он способен оптимизировать одну функцию имея информацию в рантайме — никто особо и не сомневался и разница в производительности в реальной системе будет лежать не здесь :)

dvsa Автор
26.07.2022 22:25Вы абсолютно правы, сборка с оптимизацией в корне меняет дело. Дополнил статью.

Groramar
24.07.2022 12:26+5Попробовал лазарь. С выводом: 7 секунд, без: 1.5. Так что да. В таком варианте смысла в тестах мне кажется мало. Лучше вывод 'по ходу' отключить.


youlose
24.07.2022 12:37По умолчанию Rust компилирует без оптимизаций, надо как минимум делать так:
rustc -C opt-level=3 rust/src/main_horse.rsВот документация на эту тему https://docs.rust-embedded.org/book/unsorted/speed-vs-size.html
соотвественно результат у меня на ноутбуке (macbook pro):
rust без оптимизаций:
Attempts: 3, duration: Some(36.852092s)Executed in 36.86 secs fish external
usr time 36.43 secs 0.16 millis 36.43 secs
sys time 0.20 secs 1.94 millis 0.20 secs
rust с оптимизациями (-C opt-level=3):Attempts: 3, duration: Some(1.103816s)
Executed in 1.30 secs fish external
usr time 990.80 millis 0.11 millis 990.69 millis
sys time 113.74 millis 2.05 millis 111.69 millis
java:
Attempts: 3, duration: 2.868 sec
Executed in 3.06 secs fish external
usr time 5.00 secs 0.13 millis 5.00 secs
sys time 0.41 secs 1.99 millis 0.41 secs


Vadim_Aleks
24.07.2022 13:42+2А теперь скомпилируйте раст в релизе, а не дебаге :) в гитхабе ридми указано, что вы компилируете без оптимизаций. Но даже если там опечатка, и вы действительно компилировали в релизе, то у меня локально совершенно другие результаты. Не в пользу джавы
И уберите тест на IO, если хотите увидеть результаты на CPU, а не оптимизаций вывода в stdout

unC0Rr
24.07.2022 14:26+7Free Pascal, к сожалению, по оптимизациям проигрывает современным компиляторам C, несмотря на больший потенциал для оптимизаций со стороны языка. Я писал движок игры на фрипаскале, а затем для облегчения портирования на экзотическую платформу написал к нему транслятор в C. В результате вышло, что движок, скомпилированный через C, быстрее скомпилированного фрипаскалем раза в полтора, очень заметно было даже на глаз.

martein
24.07.2022 16:40-2Вот так просто на коленке взяли и слабали компилятор C? Что ж, верю-верю.

Layan
24.07.2022 16:49+8Компилятор C и транслятор Pascal -> C (для дальнейшей компиляции) это совсем разные вещи по сложности), тем более, если нужно не универсальное решение, а для своего кода, в котором вполне могут не использоваться все возможности языка.
У нас в компании вполне себе живет транслятор PHP -> JS для реализации гибкой валидации полей на стороне пользователя, ничего сложного в нем нет.

IlyaEdrets
25.07.2022 09:38У нас на 4ом курсе университета была курсовая по написанию транслятора с одного языка в другой. Если оба языка относятся к одной парадигме, имеют схожие языковые конструкции и нужно поддержать только ограниченный набор возможностей, то после изучения необходимого теор. минимума и стандартных иструментов типа bison и flex эта задача становится не сложной.

Red_Nose
24.07.2022 15:03+4Фактически неудачный пример статьи для спецолимпиады :)
Автору надо было в НАЧАЛЕ статьи признаться в своей слабой компетенции в части ЯП (кроме "любимого") и предложить аудитории "развенчать" его потуги, т.е. предложить свои варианты решения.

magiavr
24.07.2022 20:15+1Очевидно же, что данный код больше всего времени тратит на вывод. Уж логичнее было всё запихать в массив или строку, а потом уже вывести за раз. Автор бы ещё инкрементально вывод в файл запихал. А уж про оптимизацию забыть при проверке на скорость - это фейл.

Siemargl
24.07.2022 21:24Господа, вы все ломаете...В предыдущем посте пытаетесь рассказать, как раст подходит для начинающих, а теперь такого же новичка пинаете ?
Код открыт, пишите пуллреквесты

AndreyDmitriev
25.07.2022 17:50+4Да никто новичка не пинает, в комментариях довольно продробно и доброжелательно объяснили, что тут не так (и даже определённое количество плюсов поставили и своя польза от статьи тоже есть). Вообще написание статей новичками вполне имеет смысл, потому что у профи взгляд зачастую "замыливается" и многие вещи, очевидные для них, и остающиеся за кадром, совершенно нетривиальны для новичков, но если новичок делает какие-либо выводы, то они должны быть железобетонно непробиваемы, хотя бы в той области, в которой уже разобрался. В данном случае имело смысл расчехлить Си, сделать буквально пару тестов сравнения Раста и Си, затем пойти в "вопросы и ответы" и спросить "почему все твердят, что Раст сравним по производительности с Си, а вот мои тесты этого не показывают?" и всё встало бы на свои места. Затем погонять Раст с разными опциями оптимизации, заглянуть в листинги ассемблера и получилась бы хорошая статья. Кстати, основное преимущество Раста, на мой взгляд даже не столько в эффективности кода, сколько в том, что там можно достаточно легко и безопасно параллелить вычисления. А для новичков Раст, по моему мнению и правда, не очень подходит, именно потому, что "планка вхождения" в подавляющем большинстве туториалов чуть выше, чем в "учебных" языках.
Siemargl
25.07.2022 21:18-3Отличная доброжелательность. -17 кармы и -49 за статью =)
Остальное, сорри, мусор. Идеология заимствования и единоличного владения противоречит параллелизации. Это один из главных гвоздей в гробик раста, ИМХО конечно. Сэд бат тру.

qw1
25.07.2022 21:25+3Идеология заимствования и единоличного владения противоречит параллелизации
Почему так? В идеологии раста как раз заявляется, что если объектом или группой владеет какой-то определённый поток, то синхронизация не требуется, а значит, на неё не надо тратиться при распараллеливании.Siemargl
25.07.2022 22:27-3Капитан Очевидность?
Даже внутри потока так, как раз проблема в разделении
qw1
25.07.2022 22:55+2И в чём проблема? Разные потоки будут владеть разными объектами. И следить за этим будет компилятор, а не ошибающийся кожаный мешок.
А другие языки как с этим справляются, у которых нет гвоздей в гробу?

0xd34df00d
26.07.2022 01:17+3Тут проблема не в том, что человек — новичок в расте, а в том, что человек — новичок в компилируемых языках. Неочевидно, что и сишный код он бы собирал с оптимизациями.

Valkea
25.07.2022 02:26+1У Python есть специальная версия, которая использует JIT называется PyPy. Если вы хотите открыть роман "Война и Мир" и подсчитать сколько слов используется в романе и сколько раз они повторяются, то лучше всего для этого подойдёт PyPy. Он довольно быстро справляется с подобной задачей. А если если использовать оригинальный Python, то на полчаса придётся отойти от компьютера.

alexeishch
25.07.2022 12:26Основное преимущество языков вроде Java и C# в том, что код скомпилированный в debug режиме по скорости мало отличается от кода скомпилированного в release. Причина в том что для JIT библиотеки классов и рантайм библиотеки всегда используются Release. В тех же плюсах рантайм библиотеки для release и debug - разные
qw1
25.07.2022 13:10Такое себе преимущество. Это значит, рантайм библиотеки всегда выполняют дебажные проверки и выключить их нельзя. Хотя, для Enterprise языков, пожалуй, это хорошо. Программы на прод выкладывают в конфиге Release и там будет совершенно не лишним, если в рантайме останутся проверки.

speshuric
25.07.2022 14:49+2Основное преимущество языков вроде Java и C# в том, что код скомпилированный в debug режиме по скорости мало отличается от кода скомпилированного в release.
Неправда, как минимум для C#. В debug он даже не инлайнит (или инлайнит крайне редко), параметры передаёт через стек и вообще кучу всего не пытается оптимизировать, а в release - инлайнит и оптимизирует. В https://sharplab.io/ легко примеры набрать, посмотрите. Если у вас не видно разницы, то у вас не CPU-bound задача. И бывают баги рантайма, специфичные для release или debug. И всё равно C# кучу возможных оптимизаций не делает (по сравнению с C/C++/llvm), особенно это качается оптимизаций, которые могут нарушить call stack (оптимизация хвостовой рекурсии, например, не делается) - иначе при исключениях потом движок не может сказать, где и что случилось.
Для Java ситуация ещё сложнее.
alexeishch
26.07.2022 19:58Всё о чем вы говорите мало влияет на скорость пользовательского кода. Просто потому что никто никогда в здравом уме не делает ни на C# ни на Java задачи требующие серьёзных вычислений. Большая часть вычислений веб-приложений происходит внутри библиотек ASP.NET и Kestrel. Для графического интерфейса в DirectX и их обертках (WPF и WinUI). CPU-bound задачи на C# никто не делает (нужно сделать библиотеку на С++ из которой вытащить функции с нормальными именами и использовать её в C# проекте).
Оптимизации для большинства задач оказывают не такое влияние как многопоточность или SIMD-инструкции. Например я однажды делал графический интерфейс для АЦП. Часть кода преобразующая данные благодаря SSE работала в 6-7 раз быстрее чем написанная на C#. При этом всё на C# могло работать в любой конфигурации что Release что Debug. Если у вас программа на C# сильно замедляется в Debug - это значит что вам нужно оптимизировать hot path чтобы такого не случалось.
speshuric
26.07.2022 20:24Просто потому что никто никогда в здравом уме не делает ни на C# ни на Java задачи требующие серьёзных вычислений.
Это настолько противоречит моему опыту, что я не знаю, как спорить. В банках и в других фин. организациях основная часть хайлоада на jvm. Некоторое количество есть на .net, еще меньшее, но всё еще обнаружимое количество есть на всякой node/js. Следовые количества остального: go, cpp, python и дальше по списку. Немало ресурсов, конечно, съедают "готовые" системы (СУБД, MQ, kafka, мемкеши всякие), но значительная часть вычислений (сожранных процессоров) именно на jvm и .net.
alexeishch
26.07.2022 21:16Мы пробовали один из микросервисов в варианте Debug на где-то около тысячи RPS запускать когда искали утечку памяти на .NET Core 2.1 и 2.2 (её так и не нашли, а переход на 3.1 её волшебным образом убрал). Для этого мы просто в кубере удвоили количество инстансов на всякий случай. И не было никакой ощутимой просадки по выполнению запросов. Разница наверно была, но меньше времени выполнения сетевых запросов, например, обращения к SQL Server. Т.е. на .NET Core 2.1 версия собранная в Debug режиме не особо-то и медленнее чем в Release.

Error1024
Ммм, мне кажется или ввиду наличия Print/Write в циклах это тест скорости стандартного io?
cepera_ang
Не кажется и в Rust’e он не быстрый, с чем сталкивается практически любой, кто пишет такой тест. А всё потому, что он захватывает лок при каждом вызове принта. Можно вынести лок за цикл и будет улучшение в разы, но всё равно это будет тест скорости консольного IO.
А джава такая быстрая, потому что буферизует небось или ещё какие трюки.
VictorF
Да, помимо прямого выполнения, в JVM имеет место быть профайлер ). Конечно, он не успевает отработать на 'коротком' тесте.
Вообще, байт-код не должен вводить в заблуждение - такую композицию можно рассматривать как вынесенный наружу внутренний язык компилятора (в некоторых проектах его называют IL0).
AndreyDmitriev
Не, этот тест эффективности отладочных и неоптимизированных версий. Автору стоит попробовать хотя бы включить оптимизацию rustc -C opt_level=3 ./main_primes.rs и он будет приятно удивлён.
Siemargl
Конечно. Но кто сказал, что стандартный ввод/вывод должен в десятки раз отличаться в разных языках?
Если что, это камень и в сторону C++ iostream
dvsa Автор
Вы правы, что наличие Print/Write имеет влияние и его надо убрать, но на сравнительные результаты не влияет. Дополнил статью.